SolrCloud(solr集群+zookeeper集群)
一、集群介绍
1. 什么是SolrCloud
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
2. Solr集群的系统架构
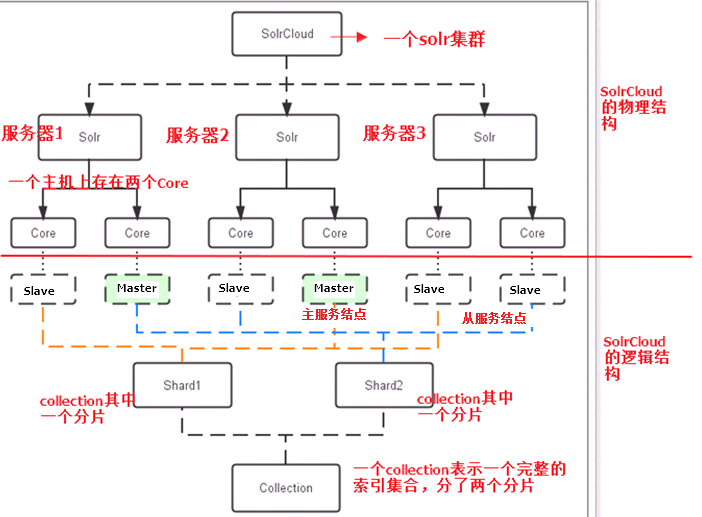
2.1. 物理结构
三个Solr实例( 每个实例包括两个Core),组成一个SolrCloud。
2.2. 逻辑结构
索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
2.2.1. collection
Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。
比如:针对商品信息搜索可以创建一个collection。
collection=shard1+shard2+....+shardX
2.2.2. Core
每个Core是Solr中一个独立运行单位,提供 索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成所以collection一般由多个core组成。
2.2.3. Master或Slave
Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。
2.2.4. Shard
Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader。
2.3. 需要实现的solr集群架构
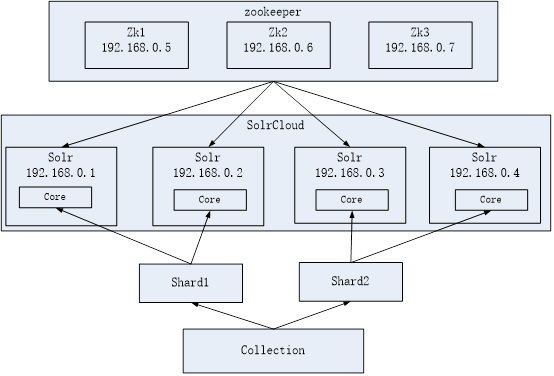
Zookeeper作为集群的管理工具。
1、集群管理:容错、负载均衡。
2、配置文件的集中管理
3、集群的入口
需要实现zookeeper 高可用。需要搭建集群。建议是奇数节点。需要三个zookeeper服务器。
搭建solr集群需要7台服务器。
搭建伪分布式:
需要三个zookeeper节点
需要四个tomcat节点。
建议虚拟机的内容1G以上。
二、安装步骤:
1.环境:
CentOS-6.5-i386-bin-DVD1.iso
jdk-7u72-linux-i586.tar.gz
apache-tomcat-7.0.47.tar.gz
zookeeper-3.4.6.tar.gz
solr-4.10.3.tgz
2.步骤:
Zookeeper集群步骤:
第一步:需要安装jdk环境。
第二步:把zookeeper的压缩包上传到服务器。
第三步:解压缩。
第四步:把zookeeper复制三份。
[root@localhost ~]# mkdir /usr/local/solr-cloud
[root@localhost ~]# cp -r zookeeper-3.4.6 /usr/local/solr-cloud/zookeeper01
[root@localhost ~]# cp -r zookeeper-3.4.6 /usr/local/solr-cloud/zookeeper02
[root@localhost ~]# cp -r zookeeper-3.4.6 /usr/local/solr-cloud/zookeeper03
第五步:在每个zookeeper目录下创建一个data目录。
第六步:在data目录下创建一个myid文件,文件名就叫做“myid”。内容就是每个实例的id。例如1、2、3
[root@localhost data]# echo 1 >> myid
[root@localhost data]# ll
total 4
-rw-r--r--. 1 root root 2 Apr 7 18:23 myid
[root@localhost data]# cat myid
1
第七步:修改配置文件。把conf目录下的zoo_sample.cfg文件改名为zoo.cfg
修改dataDir,取新创建的data目录
修改clientPort,每个配置文件的端口不冲突。
增加下面配置
server.1=192.168.232.101:2881:3881
server.2=192.168.232.101:2882:3882
server.3=192.168.232.101:2883:3883
第八步:启动每个zookeeper实例。
启动bin/zkServer.sh start
查看zookeeper的状态:
bin/zkServer.sh status
Solr集群步骤:
第一步:创建四个tomcat实例。每个tomcat运行在不同的端口。8180、8280、8380、8480
第二步:部署solr的war包。把单机版的solr工程复制到集群中的tomcat中。
第三步:为每个solr实例创建一个对应的solrhome。使用单机版的solrhome复制四份。
第四步:需要修改solr的web.xml文件。把solrhome关联起来。
第五步:配置solrCloud相关的配置。每个solrhome下都有一个solr.xml,把其中的ip及端口号配置好。
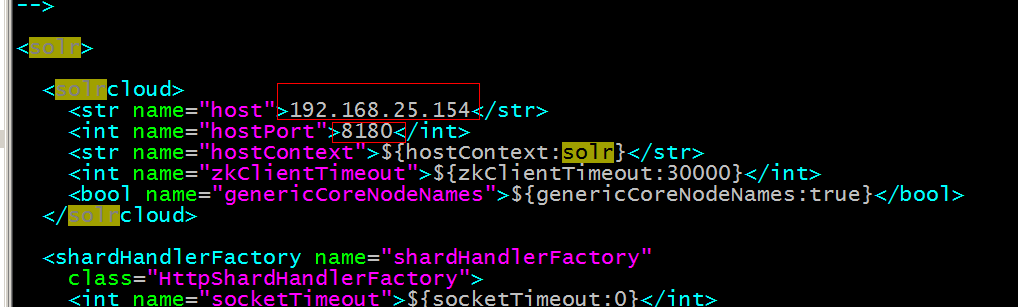
第六步:让zookeeper统一管理配置文件。需要把solrhome/collection1/conf目录上传到zookeeper。上传任意solrhome中的配置文件即可。
使用工具上传配置文件:/root/solr-4.10.3/example/scripts/cloud-scripts/zkcli.sh
|
./zkcli.sh -zkhost |
查看zookeeper上的配置文件:
使用zookeeper目录下的bin/zkCli.sh命令查看zookeeper上的配置文件:
[root@localhost bin]# ./zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[configs, zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /configs
[myconf]
[zk: localhost:2181(CONNECTED) 2] ls /configs/myconf
[admin-extra.menu-top.html, currency.xml,
protwords.txt, mapping-FoldToASCII.txt, _schema_analysis_synonyms_english.json,
_rest_managed.json, solrconfig.xml,
_schema_analysis_stopwords_english.json, stopwords.txt, lang, spellings.txt,
mapping-ISOLatin1Accent.txt, admin-extra.html, xslt, synonyms.txt,
scripts.conf, update-script.js, velocity, elevate.xml,
admin-extra.menu-bottom.html, clustering, schema.xml]
[zk: localhost:2181(CONNECTED) 3]
退出:
[zk: localhost:2181(CONNECTED) 3] quit
|
使用以下命令连接指定的zookeeper服务: ./zkCli.sh -server 192.168.25.154:2183 |
第七步:修改tomcat/bin目录下的catalina.sh 文件,关联solr和zookeeper。
把此配置添加到配置文件中:
JAVA_OPTS="-DzkHost=192.168.25.154:2181,192.168.25.154:2182,192.168.25.154:2183"
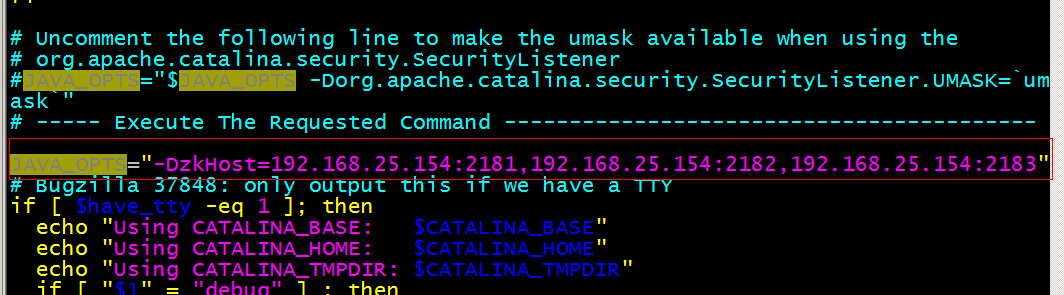
第八步:启动每个tomcat实例。要包装zookeeper集群是启动状态。
第九步:访问集群
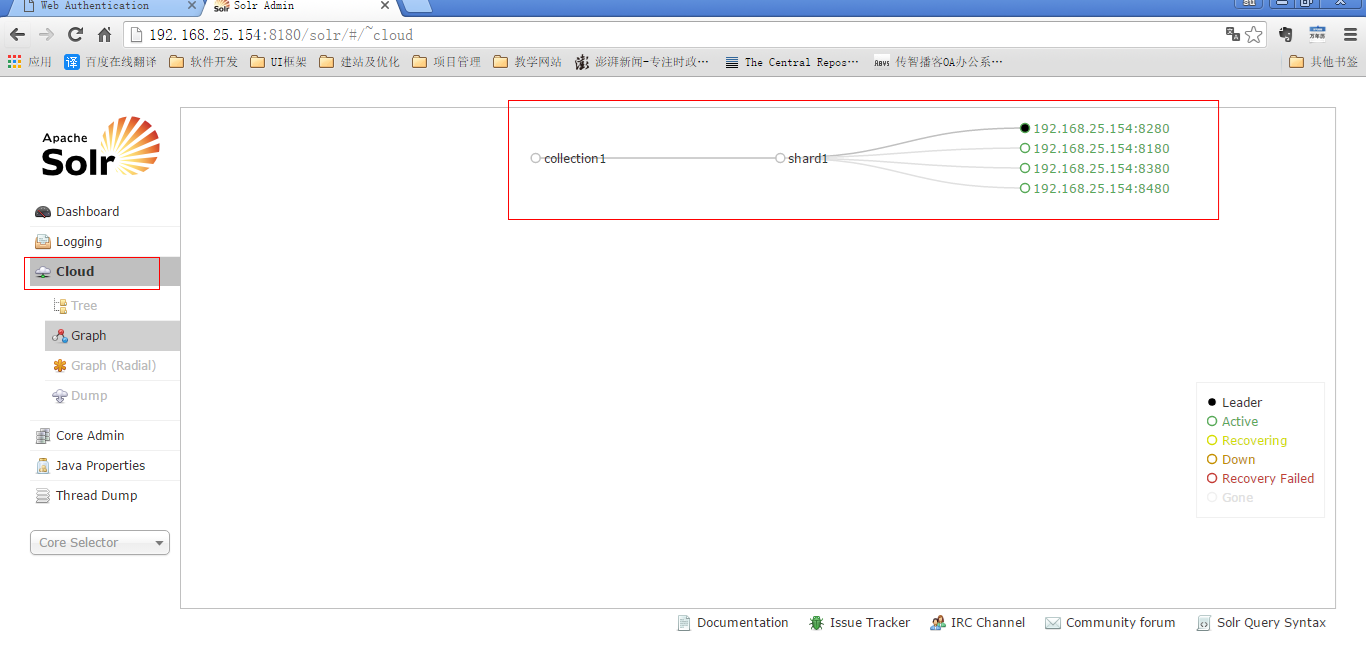
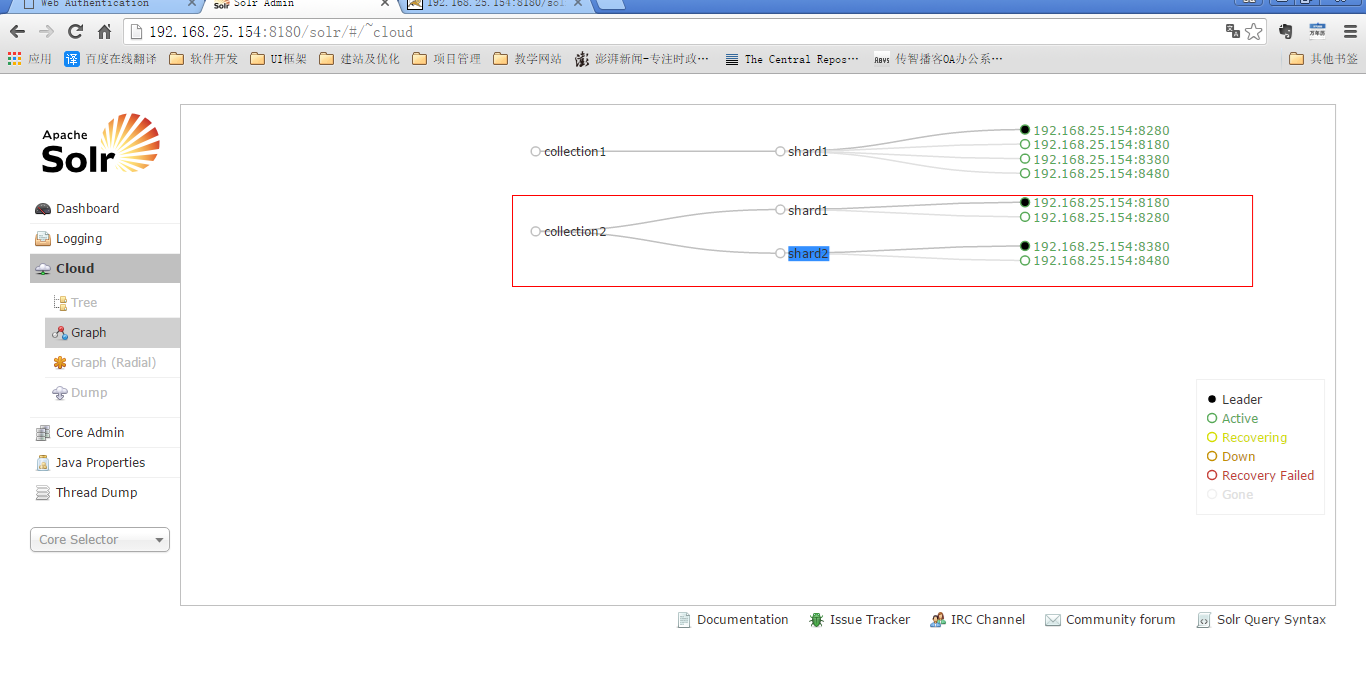
第十步:创建新的Collection进行分片处理。
http://192.168.25.154:8180/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=2

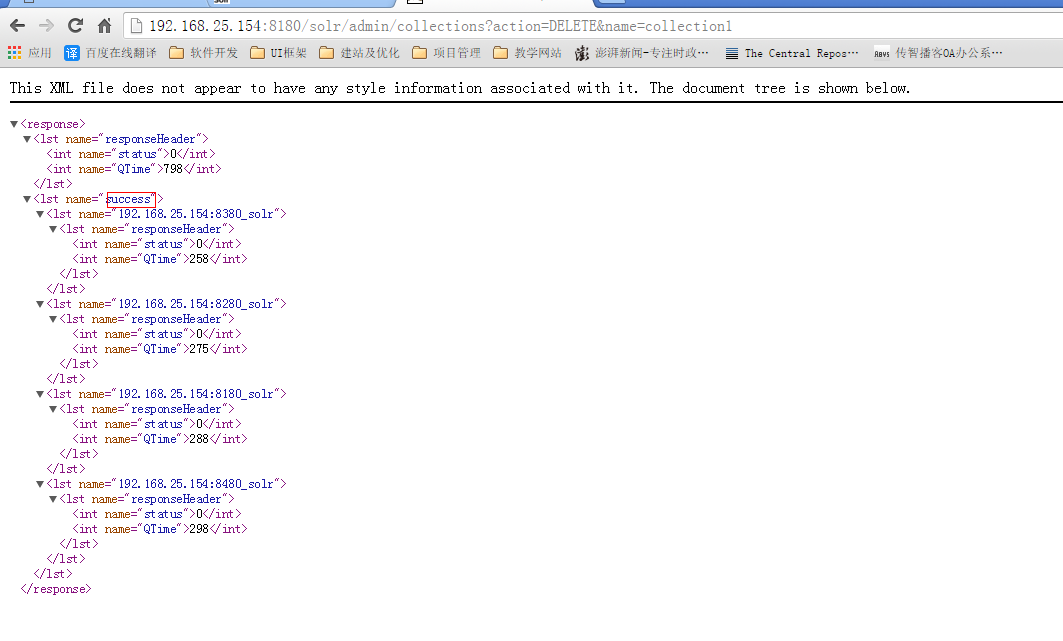
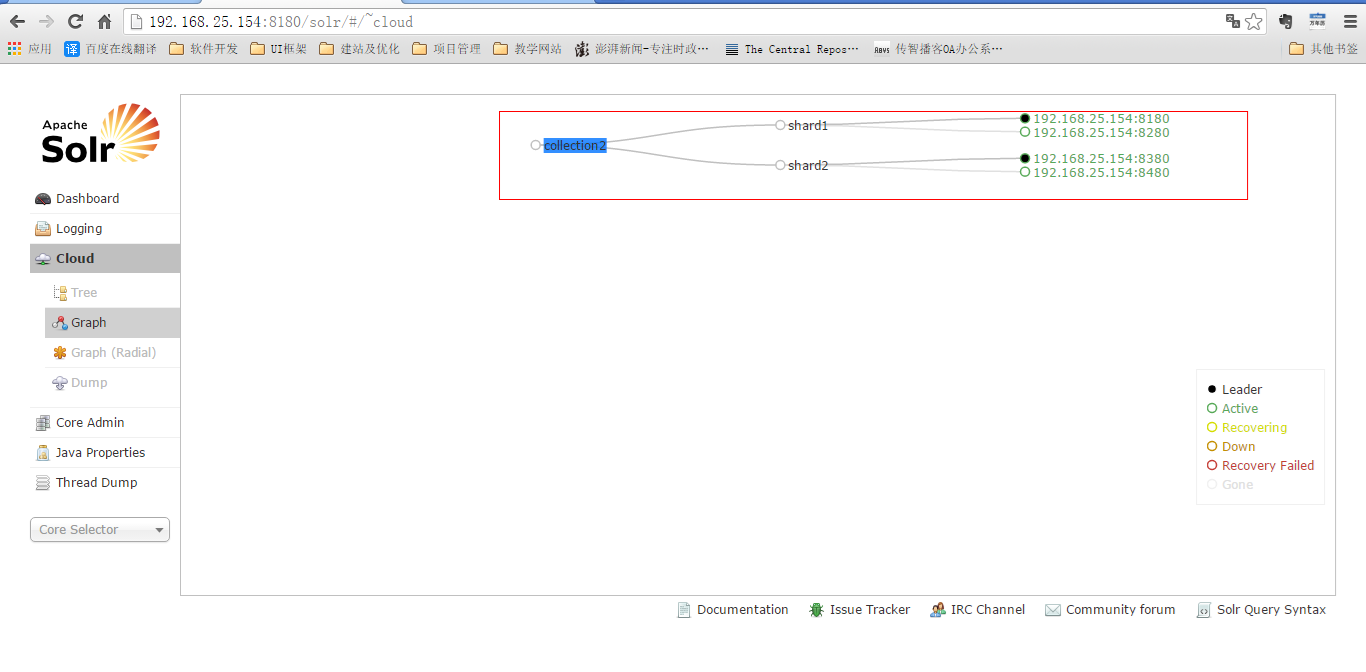
第十一步:删除不用的Collection。
http://192.168.25.154:8180/solr/admin/collections?action=DELETE&name=collection1
SolrCloud(solr集群+zookeeper集群)的更多相关文章
- kafka环境搭建2-broker集群+zookeeper集群(转)
原文地址:http://www.jianshu.com/p/dc4770fc34b6 zookeeper集群搭建 kafka是通过zookeeper来管理集群.kafka软件包内虽然包括了一个简版的z ...
- 第八章 搭建hadoop2.2.0集群,Zookeeper集群和hbase-0.98.0-hadoop2-bin.tar.gz集群
安装配置jdk,SSH 一.首先,先搭建三台小集群,虚拟机的话,创建三个 下面为这三台机器分别分配IP地址及相应的角色:集群有个特点,三台机子用户名最好一致,要不你就创建一个组,把这些用户放到组里面去 ...
- 基于 SOA 架构,创建 ego-search-web 项目-solr集群-zookeeper集群
项目架构 Ego-search-web 服务的消费者,ego-rpc 服务提供者 建立 ego-search-web 项目 继承:ego 依赖:ego-common ego-rpc-service ...
- kafka集群zookeeper集群详细配置
http://www.cnblogs.com/luotianshuai/p/5206662.html
- motan负载均衡/zookeeper集群/zookeeper负载均衡的关系
motan/dubbo支持负载均衡.zookeeper有集群的概念.zookeeper似乎也能做负载均衡,这3者是什么关系呢? 3个概念:motan/dubbo负载均衡.zookeeper集群.zoo ...
- hbase和ZooKeeper集群安装配置
一:ZooKeeper集群安装配置 1:解压zookeeper-3.3.2.tar.gz并重命名为zookeeper. 2:进入~/zookeeper/conf目录: 拷贝zoo_sample.cfg ...
- Zookeeper集群搭建(单机多节点,伪集群,docker-compose集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
- Zookeeper集群搭建(多节点,单机伪集群,Docker集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
- solr java api 使用solrj操作zookeeper集群中的solrCloud中的数据
1 导入相关的pom依赖 <dependencies> <dependency> <groupId>org.apache.solr</groupId> ...
随机推荐
- VS2019 C++动态链接库的创建使用(3) - 如何导出类
如何在动态链接库里导出一个类? ①在库头文件里增加一个类声明,class DLL1_API Point是将类内所有成员都导出,如果只导出某个成员函数,则只需在对应的成员函数前加DLL1_API即可: ...
- ChaosTool,iOS添加垃圾代码工具,代码混淆工具,代码生成器,史上最好用的垃圾代码添加工具,自己开发的小工具
最近在H5游戏项目中需要添加垃圾代码作混淆,提高过审机率.手动添加太费时费力,在网上并没有找到合适的比较好的工具,就自己动手写了一个垃圾代码添加工具,命名为ChaosTool. 扣扣交流群:81171 ...
- 遍历集合的常见方式,排序,用lambda表示是怎样的
Collection集合的功能: Object[] toArray() 将集合转成数组 Iterator iterator() 通过方法的调用 获取I ...
- 强智教务系统验证码识别 Tensorflow CNN
强智教务系统验证码识别 Tensorflow CNN 一直都是使用API取得数据,但是API提供的数据较少,且为了防止API关闭,先把验证码问题解决 使用Tensorflow训练模型,强智教务系统的验 ...
- git 更换push 提交地址
git 删除远程地址 1.找到对应项目 右键点击 GIT Bash Here 2.输入命令 git remote rm origin 3.对应项目 右键点击 GIT Sync..... 4.点击Man ...
- python学习之BeautifulSoup模块爬图
BeautifulSoup模块爬图学习HTML文本解析标签定位网上教程多是爬mzitu,此网站反爬限制多了.随意找了个网址,解析速度有些慢.脚本流程:首页获取总页数-->拼接每页URL--> ...
- 实例演示:如何简化生产中的Pod安全策略?
Pod安全策略对于强化K8S集群安全至关重要.本文将延续之前的文章继续深入介绍Pod安全策略. 首先,简单介绍了如何将Pod与Pod安全策略相关联,并使用RBAC来展示具体步骤.然后介绍如何在Ranc ...
- 知识图谱里的知识存储:neo4j的介绍和使用
一般情况下,我们使用数据库查找事物间的联系的时候,只需要短程关系的查询(两层以内的关联).当需要进行更长程的,更广范围的关系查询时,就需要图数据库的功能. 而随着社交.电商.金融.零售.物联网等行 ...
- python3读取excel实战
'''参数化'''import xlrd,xlwt,jsonfrom api实现.读取参数化接口说明 import TestApiclass ReadFileData: def __init__(se ...
- Spring Framework之IoC容器
Spring IoC 概述 问题 1.什么是依赖倒置? 2.什么是控制反转? 3.什么是依赖注入? 4.它们之间的关系是怎样的? 5.优点有哪些? 依赖倒置原则 (Dependency Inversi ...