Python 操作mysql数据库之 SQLAlchemy 案例详解
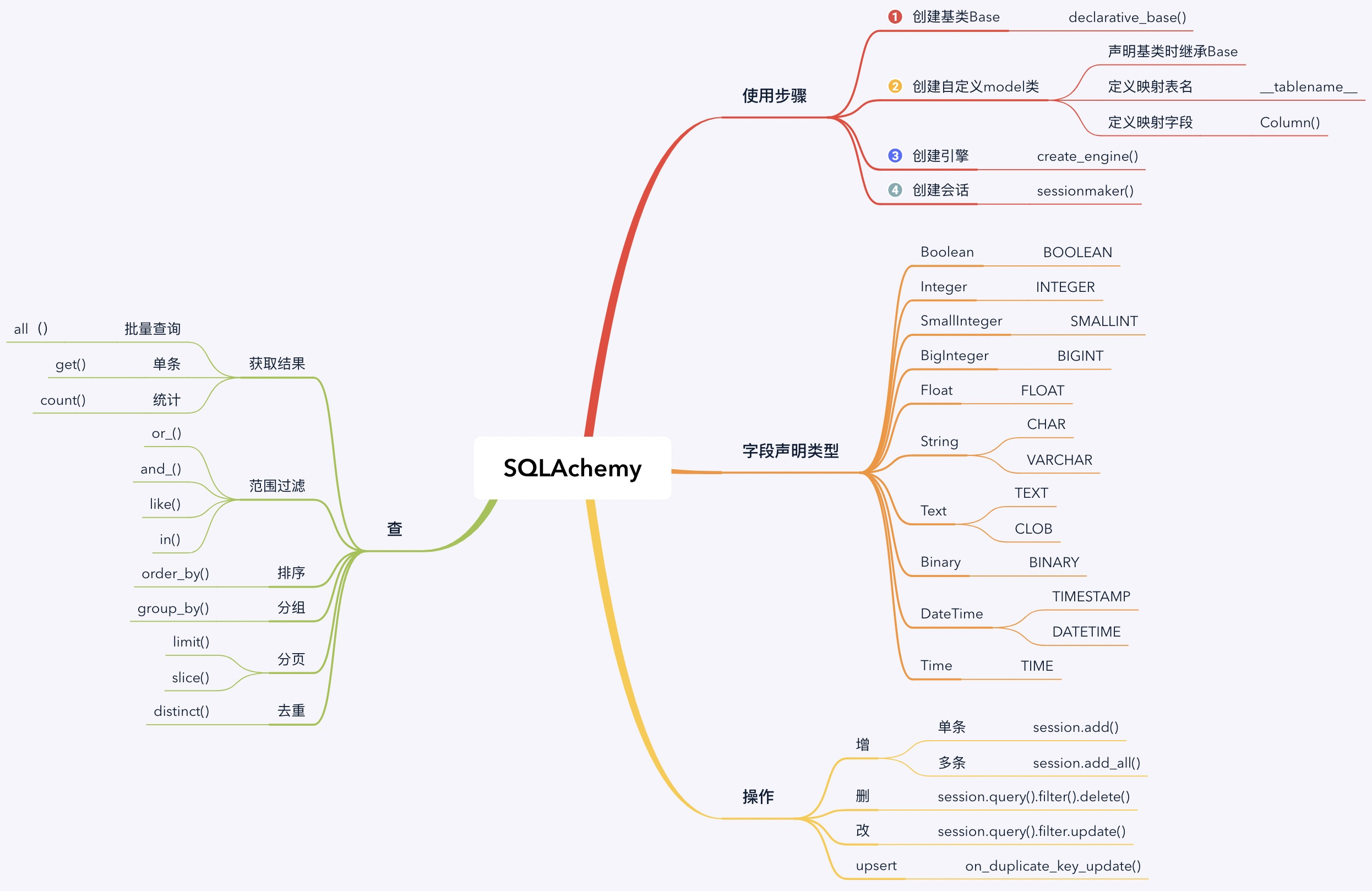
- 字段声明类型中,最右边的是数据库中对应的字段,我们依然可以使用,其左边的的 SQLAchemy 则是其自身封装的自定义类型。
- 本篇不会讲太多的理论知识,因为这个实用性更强,所以通篇全部都是案例,每个案例都会输出对应的 sql , 这样你也能更清晰的明白自己写出的代码最终都转化成什么样的 sql 了。
- 本篇的最后一个案例是 upsert “存在则更新,不存在则插入”的高级用法。
- 本篇中的所有案例都亲测可用
- CREATE TABLE `student` (
- `id` int(2) NOT NULL AUTO_INCREMENT,
- `name` char(20) NOT NULL,
- `code` char(64) NOT NULL,
- `sex` char(4) NOT NULL,
- PRIMARY KEY (`id`) USING BTREE
- ) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8;
数据库中的值
- Id name code sex
- ------------------------------------
- 1 Bob AU dddd
- 2 Bob BR girl
- 3 Hua CA boy
- 4 Lan CN girl
- 5 Hua RU girl
- 6 Smith US boy
- 7 Bob AU boy
- 8 Smith BM girl
- 9 Hub BU boy
- 10 Hip HK boy
ps: 下面的例子全部是依据这
创建自定义类,后面的所有操作的 session,都根据此案例的 session 来操作的。
- from sqlalchemy import create_engine, Column, INT, VARCHAR
- from sqlalchemy.ext.declarative import declarative_base
- from sqlalchemy.orm import sessionmaker
- # 创建基类,返回一个定制的metaclass 类
- Base = declarative_base()
- # 自定义类
- class Student(Base):
- # 表名
- __tablename__ = 'student'
- # 字段映射
- id = Column('id', INT, primary_key=True)
- name = Column('name', VARCHAR)
- code = Column('code', VARCHAR)
- sex = Column('sex', VARCHAR)
- def to_dict(self):
- """
- 将查询的结果转化为字典类型
- Student 对象的内容如下 {'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x10174c898>, 'sex': 'nan', 'name': 'ygh', 'code': 'AU', 'school': 'hua'}
- 获取其值剔除 "_sa_instance_state 即可。但不能在self.__dict__上直接删除”_sa_instance_state” 这个值是公用的。
- :return:
- """
- return {k: v for k, v in self.__dict__.items() if k != "_sa_instance_state”}
- # 创建引擎 , echo=True ,表示需要开启 sql 打印,调试的以后特别好用
- engine =create_engine("mysql+mysqldb://root:123qwe@192.168.1.254:3306/yinguohai", pool_size=2, max_overflow=0, echo=True
- # 创建会话对象,用于操作数据库
- Session = sessionmaker(bind=engine)
- session = Session()
- result = session.query(Student).all()
- for i in result:
- # i是一个Student对象,所以可以使用其 to_dict() 去格式化其对象的值
- if isinstance(i, Student):
- print(i.to_dict())
- -------------------------结果-------------------------
- {'sex': 'dddd', 'name': 'Bob', 'id': 1, 'code': 'AU'}
- {'sex': 'girl', 'name': 'Bob', 'id': 2, 'code': 'BR'}
- {'sex': 'boy', 'name': 'Hua', 'id': 3, 'code': 'CA'}
- {'sex': 'girl', 'name': 'Lan', 'id': 4, 'code': 'CN'}
- {'sex': 'girl', 'name': 'Hua', 'id': 5, 'code': 'RU'}
- {'sex': 'boy', 'name': 'Smith', 'id': 6, 'code': 'US'}
- {'sex': 'boy', 'name': 'Bob', 'id': 7, 'code': 'AU'}
- {'sex': 'girl', 'name': 'Smith', 'id': 8, 'code': 'BM'}
- {'sex': 'boy', 'name': 'Hub', 'id': 9, 'code': 'BU'}
- {'sex': 'boy', 'name': 'Hip', 'id': 10, 'code': 'HK'}
- SELECT
- student.id AS student_id,
- student.NAME AS student_name,
- student.CODE AS student_code,
- student.sex AS student_sex
- FROM
- student
- result = session.query(Student.id, Student.name).all()
- for i in result:
- # 此时返回的是一个tuple ,而不是一个Student对象
- print(i)
- -------------------------结果-------------------------
- (1, 'Bob')
- (2, 'Bob')
- (3, 'Hua')
- (4, 'Lan')
- (5, 'Hua')
- (6, 'Smith')
- (7, 'Bob')
- (8, 'Smith')
- (9, 'Hub')
- (10, 'Hip')
- SELECT
- student.id AS student_id,
- student.NAME AS student_name
- FROM
- student
案例四:多条件查询, or_ , and_
- result = session.query(Student).filter(or_(Student.name == "Bob", Student.sex != "aa")).first()
- print(result.to_dict())
- -------------------------结果-------------------------
- {'sex': 'dddd', 'name': 'Bob', 'id': 1, 'code': 'AU'}
对应Sql:
- SELECT
- student.id AS student_id,
- student.NAME AS student_name,
- student.CODE AS student_code,
- student.sex AS student_sex
- FROM
- student
- WHERE
- student.NAME = % s
- OR student.sex != % s ( 'Bob', 'aa', 1 )
- result = session.query(Student).filter(and_(Student.name == "Bob" , Student.sex != "aa")).first()
- print(result.to_dict())
- -------------------------结果-------------------------
- {'sex': 'dddd', 'name': 'Bob', 'id': 1, 'code': 'AU'}
对应Sql:
- SELECT
- student.id AS student_id,
- student.NAME AS student_name,
- student.CODE AS student_code,
- student.sex AS student_sex
- FROM
- student
- WHERE
- student.NAME = % s
- AND student.sex != % s
- LIMIT % s ( 'Bob', 'aa', 1 )
- result = session.query(Student).filter(Student.sex.like('%bo%')).first()
- print(result.to_dict())
- -------------------------结果-------------------------
- {'sex': 'dddd', 'name': 'Bob', 'id': 1, 'code': 'AU'}
- SELECT
- student.id AS student_id,
- student.NAME AS student_name,
- student.CODE AS student_code,
- student.sex AS student_sex
- FROM
- student
- WHERE
- student.sex LIKE % s
- LIMIT %s ('%bo%', 1)
- result = session.query(Student).filter(Student.name.in_(["Bob", "Smith"])).all()
- for i in result:
- print(i.to_dict())
- -------------------------结果-------------------------
- {'code': 'AU', 'id': 1, 'name': 'Bob', 'sex': 'dddd'}
- {'code': 'BR', 'id': 2, 'name': 'Bob', 'sex': 'girl'}
- {'code': 'US', 'id': 6, 'name': 'Smith', 'sex': 'boy'}
- {'code': 'AU', 'id': 7, 'name': 'Bob', 'sex': 'boy'}
- {'code': 'BM', 'id': 8, 'name': 'Smith', 'sex': 'girl'}
对应Sql:
- SELECT
- student.id AS student_id,
- student.NAME AS student_name,
- student.CODE AS student_code,
- student.sex AS student_sex
- FROM
- student
- WHERE
- student.NAME IN (% s, % s ) ( 'Bob', 'Smith' )
- #result = session.query(Student).order_by(Student.id.desc()).all()
- result = session.query(Student).order_by(Student.id.asc()).all()
- for i in result:
- print(i.to_dict())
- -------------------------结果-------------------------
- {'sex': 'dddd', 'name': 'Bob', 'id': 1, 'code': 'AU'}
- {'sex': 'girl', 'name': 'Bob', 'id': 2, 'code': 'BR'}
- {'sex': 'boy', 'name': 'Hua', 'id': 3, 'code': 'CA'}
- {'sex': 'girl', 'name': 'Lan', 'id': 4, 'code': 'CN'}
- {'sex': 'girl', 'name': 'Hua', 'id': 5, 'code': 'RU'}
- {'sex': 'boy', 'name': 'Smith', 'id': 6, 'code': 'US'}
- {'sex': 'boy', 'name': 'Bob', 'id': 7, 'code': 'AU'}
- {'sex': 'girl', 'name': 'Smith', 'id': 8, 'code': 'BM'}
- {'sex': 'boy', 'name': 'Hub', 'id': 9, 'code': 'BU'}
- {'sex': 'boy', 'name': 'Hip', 'id': 10, 'code': 'HK'}
对应Sql:
- SELECT
- student.id AS student_id,
- student.NAME AS student_name,
- student.CODE AS student_code,
- student.sex AS student_sex
- FROM
- student
- ORDER BY
- student.id ASC
- result = session.query(Student).limit(2).all()
- for i in result:
- print(i.to_dict())
- -------------------------结果-------------------------
- {'sex': 'dddd', 'name': 'Bob', 'id': 1, 'code': 'AU'}
- {'sex': 'girl', 'name': 'Bob', 'id': 2, 'code': 'BR'}
- SELECT
- student.id AS student_id,
- student.NAME AS student_name,
- student.CODE AS student_code,
- student.sex AS student_sex
- FROM
- student
- LIMIT % s (2,)
- result = session.query(Student).order_by(Student.id.asc()).slice(2, 3).all()
- for i in result:
- print(i.to_dict())
- -------------------------结果-------------------------
- {'sex': 'boy', 'code': 'CA', 'id': 3, 'name': 'Hua'}
对应Sql:
- SELECT
- student.id AS student_id,
- student.NAME AS student_name,
- student.CODE AS student_code,
- student.sex AS student_sex
- FROM
- student
- ORDER BY
- student.id ASC
- LIMIT % s,% s ( 2, 1 )
- result = session.query(Student).count()
- print(result)
- -------------------------结果-------------------------
- 10
- SELECT
- count(*) AS count_1
- FROM
- ( SELECT student.id AS student_id, student.NAME AS student_name, student.CODE AS student_code, student.sex AS student_sex FROM student ) AS anon_1
- result = session.query(Student.name).distinct(Student.name).all()
- -------------------------结果-------------------------
- ('Bob',)
- ('Hua',)
- ('Lan',)
- ('Smith',)
- ('Hub',)
- ('Hip',)
对应Sql:
- SELECT DISTINCT
- student.NAME AS student_name
- FROM
- student
- result = session.query(Student.id, Student.code, Student.name, Country.population).join(Country, Student.code == Country.code).all()
- for i in result:
- print(i)
- -------------------------结果-------------------------
- (1, 'AU', 'Bob', 18886000)
- (2, 'BR', 'Bob', 170115000)
- (3, 'CA', 'Hua', 1147000)
- (4, 'CN', 'Lan', 1277558000)
- (5, 'RU', 'Hua', 146934000)
- (6, 'US', 'Smith', 278357000)
- (7, 'AU', 'Bob', 18886000)
对应Sql:
- SELECT
- student.id AS student_id,
- student.CODE AS student_code,
- student.NAME AS student_name,
- a_country.population AS a_country_population
- FROM
- student
- INNER JOIN a_country ON student.CODE = a_country.CODE
- result = session.add(Student(name="Bob", code="AU", sex="boy"))
- print(result)
- #事务需要提交才能生效,有别与查询
- session.commit()
- -------------------------结果-------------------------
- None
- BEGIN
- INSERT INTO student (name, code, sex) VALUES (%s, %s, %s) ('Bob', 'AU', 'boy')
- COMMIT
- result = session.add_all([
- Student(name="Smith", code="BM", sex="girl"),
- Student(name="Hub", code="BU", sex="boy"),
- Student(name="Hip", code="HK", sex="boy"),
- ])
- session.commit()
- print(result)
- -------------------------结果-------------------------
- None
对应Sql:
- BEGIN
- INSERT INTO student (name, code, sex) VALUES (%s, %s, %s) ('Smith', 'BM', 'girl')
- INSERT INTO student (name, code, sex) VALUES (%s, %s, %s) ('Hub', 'BU', 'boy')
- INSERT INTO student (name, code, sex) VALUES (%s, %s, %s) ('Hip', 'HK', 'boy')
- COMMIT
案例十三: 更新,update()
- result = session.query(Student).filter(Student.id == 1).update({Student.sex: "dddd”})
- # 如果想回滚,则使用 session.rollback() 回滚即可
- session.commit()
- # 返回修改的记录函数
- print(result)
- -------------------------结果-------------------------
- 1
对应Sql:
- BEGIN
- UPDATE student SET sex=%s WHERE student.id = %s ('dddd', 1)
- COMMIT
- insert_smt = insert(Student).values(id=1, name="bb", code="AA", sex="boy").on_duplicate_key_update(sex="aaaaa",code="uuuuu")
- result = session.execute(insert_smt)
- session.commit()
- print(result.rowcount)
- -------------------------结果-------------------------
- 1
注意事项:
- 需要引入 一个特别函数 , insert( ) , 它是mysql包下的。from sqlalchemy.dialects.mysql import insert
- 使用 on_duplicate_key_update( ) 这个函数进行异常处理,别用错了
- 使用execute , 执行insert( ) 函数创建的 Sql 语句即可
- 最后一定要记得 commit( ) 一下。
- BEGIN
- INSERT INTO student ( id, NAME, CODE, sex )
- VALUES (% s, % s, % s, % s )
- ON DUPLICATE KEY UPDATE code = %s, sex = %s
- (1, 'bb', 'AA', 'boy', 'uuuuu', 'aaaaa')
- COMMIT
Python 操作mysql数据库之 SQLAlchemy 案例详解的更多相关文章
- python操作mysql数据库的常用方法使用详解
python操作mysql数据库 1.环境准备: Linux 安装mysql: apt-get install mysql-server 安装python-mysql模块:apt-get instal ...
- python接口自动化(三十八)-python操作mysql数据库(详解)
简介 现在的招聘要求对QA人员的要求越来越高,测试的一些基础知识就不必说了,来说测试知识以外的,会不会一门或者多门开发与语言,能不能读懂代码,会不会Linux,会不会搭建测试系统,会不会常用的数据库, ...
- python操作mysql数据库的相关操作实例
python操作mysql数据库的相关操作实例 # -*- coding: utf-8 -*- #python operate mysql database import MySQLdb #数据库名称 ...
- Windows下安装MySQLdb, Python操作MySQL数据库的增删改查
这里的前提是windows上已经安装了MySQL数据库,且配置完成,能正常建表能操作. 在此基础上仅仅需安装MySQL-python-1.2.4b4.win32-py2.7.exe就ok了.仅仅有1M ...
- 使用python操作mysql数据库
这是我之前使用mysql时用到的一些库及开发的工具,这里记录下,也方便我查阅. python版本: 2.7.13 mysql版本: 5.5.36 几个python库 1.mysql-connector ...
- python操作三大主流数据库(1)python操作mysql①windows环境中安装python操作mysql数据库的MySQLdb模块mysql-client
windows安装python操作mysql数据库的MySQLdb模块mysql-client 正常情况下应该是cmd下直接运行 pip install mysql-client 命令即可,试了很多台 ...
- python操作mysql数据库增删改查的dbutils实例
python操作mysql数据库增删改查的dbutils实例 # 数据库配置文件 # cat gconf.py #encoding=utf-8 import json # json里面的字典不能用单引 ...
- python 操作mysql数据库之模拟购物系统登录及购物
python 操作mysql数据库之模拟购物系统登录及购物,功能包含普通用户.管理员登录,查看商品.购买商品.添加商品,用户充值等. mysql 数据库shop 表结构创建如下: create TAB ...
- 【Python】使用python操作mysql数据库
这是我之前使用mysql时用到的一些库及开发的工具,这里记录下,也方便我查阅. python版本: 2.7.13 mysql版本: 5.5.36 几个python库 1.mysql-connector ...
随机推荐
- git提交更改都是一个作者
为什么提交到github的commit都是一个作者 参考链接 重要知识点讲解 问题如下所示 git是分布式去中心化的管理系统 ssh秘钥对生成.并把id_rsa.pub加入github.com中(这个 ...
- Natas32 Writeup(Perl 远程代码执行)
Natas32: 打开后和natas31相似的界面,并且提示,这次您需要证明可以远程代码执行,Webroot中有一个二进制文件可以执行. my $cgi = CGI->new; if ($cgi ...
- 使用 Docker 部署 Spring Boot 项目
Docker 介绍 Docker 属于 Linux 容器的一种封装,提供简单易用的容器使用接口.它是目前最流行的 Linux 容器解决方案. Docker 将应用程序与该程序的依赖,打包在一个文件里面 ...
- jquery 获取url携带的参数
url= "/page/employee/employeeUpdate.html?id="+data.id 获取 url携带的参数 -> $.getUrlParam = fu ...
- FormData/Go分片/分块文件上传
FormData 接口提供了一种表示表单数据的键值对的构造方式,经过它的数据可以使用 XMLHttpRequest.send() 方法送出,本接口和此方法都相当简单直接.如果送出时的编码类型被设为 & ...
- win7系统下的Nodejs开发环境配置
此处不推荐使用msi安装包直接安装nodejs,我们应该知道它里面做了哪些事情,这样以后出问题的时候,可以更快速地定位问题点.另一方面,直接安装的情况,以后更新了版本的话会很麻烦,因为如果我们想体验新 ...
- hdu1045 炮台的配置 dfs
只要炮台在同一行或者同一列,就可以互相摧毁,遇到墙则无法对墙后的炮台造成伤害,可以通过dfs搜索n*n的方格,全部搜完算一轮,计算炮台数,并保存其最大值. 其中对于t编号的炮台,位置可以计算出是(t/ ...
- 通过源码理解Spring中@Scheduled的实现原理并且实现调度任务动态装载
前提 最近的新项目和数据同步相关,有定时调度的需求.之前一直有使用过Quartz.XXL-Job.Easy Scheduler等调度框架,后来越发觉得这些框架太重量级了,于是想到了Spring内置的S ...
- 移动端H5调试
背景:开发PC页面的时候使用chrome浏览器的开发者工具,可以很容易的捕获到页面的dom元素,并且可以修改样式,方便调试:但是手机上却很麻烦,因为手机上没有办法直接打开开发者工具查看元素.其实可以通 ...
- RocketMQ调研
一.发展历程 早期淘宝内部有两套消息中间件系统:Notify和Napoli. 先有的Notify(至今12历史),后来因有序场景需求,且恰好当时Kafka开源(2011年),所以参照Kafka的设计理 ...