论文翻译——Character-level Convolutional Networks for Text Classification
Abstract
Open-text semantic parsers are designed to interpret any statement in natural language by inferring a corresponding meaning representation (MR – a formal representation of its sense).
开放文本语义分析器被设计为通过推断相应的意义表示(MR -其意义的正式表示)来解释自然语言中的任何语句。
Unfortunately, large scale systems cannot be easily machine-learned due to a lack of directly supervised data.
不幸的是,由于缺乏直接监督的数据,大型系统不容易进行机器学习。
We propose a method that learns to assign MRs to a wide range of text (using a dictionary of more than 70,000 words mapped to more than 40,000 entities) thanks to a training scheme that combines learning from knowledge bases (e.g. WordNet) with learning from raw text.
我们提出了一种方法,通过结合从知识库(如WordNet)学习和从原始文本学习的培训计划,学习如何将MRs分配到广泛的文本中(使用映射到超过40,000个实体的超过70,000个单词的字典)。
The model jointly learns representations of words, entities and MRs via a multi-task training process operating on these diverse sources of data.
该模型通过在这些不同数据源上运行的多任务训练过程,联合学习单词、实体和MRs的表示形式。
Hence, the system ends up providing methods for knowledge acquisition and word sense disambiguation within the context of semantic parsing in a single elegant framework.
因此,该系统最终在一个简洁的框架中提供了知识获取和词义消歧的方法。
Experiments on these various tasks indicate the promise of the approach.
对这些不同任务的实验表明了该方法的可行性。
1 Introduction
Text classification is a classic topic for natural language processing, in which one needs to assign predefined categories to free-text documents.
文本分类是自然语言处理的一个经典主题,在这个主题中,需要为自由文本文档分配预定义的类别。
The range of text classification research goes from designing the best features to choosing the best possible machine learning classifiers.
文本分类研究的范围从设计最好的特征到选择最好的机器学习分类器。
To date, almost all techniques of text classification are based on words, in which simple statistics of some ordered word combinations (such as n-grams) usually perform the best [12].
到目前为止,几乎所有的文本分类技术都是基于单词的,其中一些有序单词组合(例如n-gram)的简单统计通常执行最佳的[12]。
On the other hand, many researchers have found convolutional networks (ConvNets) [17] [18] are useful in extracting information from raw signals, ranging from computer vision applications to speech recognition and others.
另一方面,许多研究人员发现卷积网络[17][18]在从原始信号中提取信息方面很有用,从计算机视觉应用到语音识别等。
In particular, time-delay networks used in the early days of deep learning research are essentially convolutional networks that model sequential data [1] [31].
特别是,在早期的深度学习研究中使用的时延网络本质上是对序列数据[1][31]进行建模的卷积网络。
In this article we explore treating text as a kind of raw signal at character level, and applying temporal (one-dimensional) ConvNets to it.
在本文中,我们将文本作为一种字符级的原始信号来处理,并将时域(一维)卷积应用于此。
For this article we only used a classification task as a way to exemplify ConvNets, ability to understand texts.
在这篇文章中,我们只使用了一个分类任务来举例说明卷积神经网络,即理解文本的能力。
Historically we know that ConvNets usually require large-scale datasets to work, therefore we also build several of them.
历史上我们知道,ConvNets通常需要大型数据集才能工作,因此我们也构建了几个这样的数据集。
An extensive set of comparisons is offered with traditional models and other deep learning models.
与传统模型和其他深度学习模型进行了广泛的比较。
Applying convolutional networks to text classification or natural language processing at large was explored in literature.
文献中探讨了将卷积网络应用于文本分类或自然语言处理。
It has been shown that ConvNets can be directly applied to distributed [6] [16] or discrete [13] embedding of words, without any knowledge on the syntactic or semantic structures of a language.
已有研究表明,卷积神经网络可以直接应用于分布式[6] [16]或离散的单词嵌入[13],而不需要了解语言的句法或语义结构。
These approaches have been proven to be competitive to traditional models.
这些方法已被证明与传统模型具有竞争力。
There are also related works that use character-level features for language processing.
还有一些相关的作品使用字符级的特性来进行语言处理。
These include using character-level n-grams with linear classifiers [15], and incorporating character-level features to ConvNets [28] [29].
这些方法包括使用带有线性分类器[15]的字符级n-gram,以及将字符级特征合并到[28] [29]中。
In particular, these ConvNet approaches use words as a basis, in which character-level features extracted at word [28] or word n-gram [29] level form a distributed representation.
特别是,这些ConvNet方法使用单词作为基础,在单词[28]或单词n-gram[29]级别提取的字符级特征形成分布式表示。
Improvements for part-of-speech tagging and information retrieval were observed.
对词性标注和信息检索进行了改进。
This article is the first to apply ConvNets only on characters.
本文是第一个仅将ConvNets应用于字符的文章。
We show that when trained on large- scale datasets, deep ConvNets do not require the knowledge of words, in addition to the conclusion from previous research that ConvNets do not require the knowledge about the syntactic or semantic structure of a language.
我们发现,当在大规模数据集上进行训练时,deep ConvNets不需要词汇知识,此外,从以前的研究中得出的结论是,ConvNets不需要语言的句法或语义结构的知识。
This simplification of engineering could be crucial for a single system that can work for different languages, since characters always constitute a necessary construct regardless of whether segmentation into words is possible.
这种简化的工程可能是至关重要的单一系统,可以工作在不同的语言,因为字符总是构成一个必要的结构,不管分割成单词是否可能。
Working on only characters also has the advantage that abnormal character combinations such as misspellings and emoticons may be naturally learnt.
只研究汉字也有一个好处,那就是可以很自然地学会拼写错误和表情符号等不正常的字符组合。
An early version of this work entitled “Text Understanding from Scratch” was posted in Feb 2015 as arXiv:1502.01710. The present paper has considerably more experimental results and a rewritten introduction
2015年2月,“文本理解从零开始”作为arXiv:1502.01710发布。本论文有大量的实验结果和一个重写的介绍
2 Character-level Convolutional Networks
In this section, we introduce the design of character-level ConvNets for text classification. The design is modular, where the gradients are obtained by back-propagation [27] to perform optimization.
在这一节中,我们将介绍用于文本分类的字符级卷积神经网络的设计。设计是模块化的,其中梯度是通过反向传播[27]进行优化。
2.1 Key Modules
The main component is the temporal convolutional module, which simply computes a 1-D convolution.
主要的组成部分是时域卷积模块,它简单地计算一个一维卷积。
Suppose we have a discrete input function g(x)->R and a discrete kernel function f(x).
假设我们有一个离散的输入函数g(x)->R和一个离散的核函数f(x)
The convolution h(y) between and g(x) with stride d is defined as
定义h(y)与g(x)与stride d的卷积为
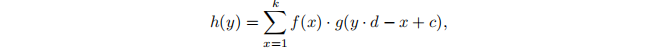
where c = k - d+l is an offset constant.
其中c = k - d+l为偏移常数。
Just as in traditional convolutional networks in vision, the module is parameterized by a set of such kernel functions (i = 1,2, m and j = 1,2, ,n) which we call weights, on a set of inputs gi(x) and outputs hj(y).
就像传统的卷积网络一样,该模块是由一组这样的内核函数(i = 1,2, ... , m和j = 1,2, ... ,n)参数化的,我们称这些函数为权值,对一组输入gi(x)和输出hj(y)。
We call each g_i (or h_j) input (or output) features, and m (or n) input (or output) feature size.
我们将每个g_i(或h_j)输入(或输出)特性称为g_i,将m(或n)输入(或输出)特性称为m。
The outputs h_j is obtained by a sum over i of the convolutions between g_i and f_ij.
输出h_j是通过g_i和f_ij之间的卷积对i求和得到的。
One key module that helped us to train deeper models is temporal max-pooling.
帮助我们训练更深层次模型的一个关键模块是时间最大池。
It is the 1-D version of the max-pooling module used in computer vision [2].
它是计算机视觉[2]中使用的最大池模块的一维版本。
Given a discrete input function g(x) , the max-pooling function h(y) of g(x) is defined as
给定离散输入函数g(x),定义g(x)的最大池函数h(y)为
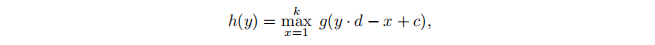
where c = k - d + 1 is an offset constant.
其中c = k - d + 1是偏移常数。
This very pooling module enabled us to train ConvNets deeper than 6 layers, where all others fail.
这个池化模块使我们能够训练超过6层的卷积神经网络,而其他的都失败了。
The analysis by [3] might shed some light on this.
[3]的分析可能会对此提供一些启示。
The non-linearity used in our model is the rectifier or thresholding function h(x) = max(0, x), which makes our convolutional layers similar to rectified linear units (ReLUs) [24].
我们模型中使用的非线性是整流器或阈值函数h(x) = max(0, x),这使得我们的卷积层类似于整流线性单元(ReLUs)[24]。
The algorithm used is stochastic gradient descent (SGD) with a minibatch of size 128, using momentum [26] [30] 0.9 and initial step size 0.01 which is halved every 3 epoches for 10 times.
该算法采用随机梯度下降法(SGD),最小批量为128,利用动量[26][30]0.9和初始步长0.01,每3个周期减半10次。
Each epoch takes a fixed number of random training samples uniformly sampled across classes.
每个epoch取固定数量的随机训练样本,这些样本均匀地跨类采样。
This number will later be detailed for each dataset sparately.
这个数字稍后将对每个数据集进行详细说明。
The implementation is done using Torch 7 [4].
实现是使用Torch 7[4]完成的。
2.2 Character quantization
Our models accept a sequence of encoded characters as input.
我们的模型接受一个编码字符序列作为输入。
The encoding is done by prescribing an alphabet of size m for the input language, and then quantize each character using 1-of-m encoding (or “one-hot" encoding).
编码是通过为输入语言指定一个大小为m的字母表,然后使用1-of-m编码(或“one-hot”编码)对每个字符进行量化来完成的。
Then, the sequence of characters is transformed to a sequence of such m sized vectors with fixed length /0- Any character exceeding length /0 is ignored, and any characters that are notin the alphabet including blank characters are quantized as all-zero vectors.
然后,将字符序列转换为具有固定长度/0的m大小的向量序列——忽略任何超过长度/0的字符,将不属于字母表的任何字符(包括空白字符)量化为全零向量。
The character quantization order is backward so that the latest reading on characters is always placed near the begin of the output, making it easy for fully connected layers to associate weights with the latest reading.
字符量化顺序是向后的,因此对字符的最新读取总是放在输出的开头附近,这使得完全连接的层很容易将权重与最新读取关联起来。
The alphabet used in all of our models consists of 70 characters, including 26 english letters, 10 digits, 33 other characters and the new line character. The non-space characters are:
我们所有的模型中使用的字母表由70个字符组成,包括26个英文字母、10个数字、33个其他字符和新行字符。非空格字符为:
Later we also compare with models that use a different alphabet in which we distinguish between upper-case and lower-case letters.
稍后,我们还将与使用不同字母表的模型进行比较,在这些模型中,我们将区分大小写字母。
2.3 Model Design
We designed 2 ConvNets - one large and one small.
我们设计了两个卷积神经网络——一个大的,一个小的。
They are both 9 layers deep with 6 convolutional layers and 3 fully-connected layers.
它们都是9层,6个卷积层,3个全连接层。
Figure 1 gives an illustration.
图1给出了一个说明。

The input have number of features equal to 70 due to our character quantization method, and the input feature length is 1014.
由于我们的字符量化方法,输入的特征数等于70,输入的特征长度为1014。
It seems that 1014 characters could already capture most of the texts of interest.
似乎1014个字符已经可以捕获大多数感兴趣的文本。
We also insert 2 dropout [10] modules in between the 3 fully-connected layers to regularize.
我们还插入了两个dropout[10]模块之间的3个全连接层,以规范。
They have dropout probability of 0.5.
它们的dropout 概率是0。5。
Table 1 lists the configurations for convolutional layers, and table 2 lists the configurations for fully-connected (linear) layers.
表1列出了卷积层的配置,表2列出了全连接(线性)层的配置。
Table 1: Convolutional layers used in our experiments.
表1:实验中使用的卷积层。
The convolutional layers have stride 1 and pooling layers are all non-overlapping ones, so we omit the description of their strides.
卷积层有stride 1,池化层都是非重叠的,所以我们省略了对它们的stride的描述。
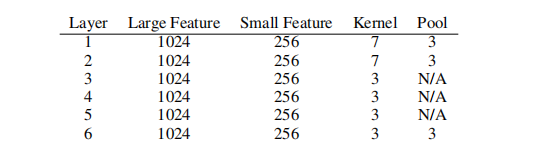
We initialize the weights using a Gaussian distribution.
我们使用高斯分布初始化权值。
The mean and standard deviation used for initializing the large model is (0,0.02) and small model (0,0.05).
初始化大模型的均值和标准偏差分别为(0,0.02)和(0,0.05)。
Table 2: Fully-connected layers used in our experiments.
表2:我们实验中使用的全连通层。
The number of output units for the last layer is determined by the problem.
最后一层的输出单元的数量由问题决定。
For example, for a 10-class classification problem it will be 10.
例如,对于一个10类的分类问题,它将是10。
For different problems the input lengths may be different (for example in our case = 1014), and so are the frame lengths.
对于不同的问题,输入长度可能不同(例如在本例中为1014),帧长度也可能不同。
From our model design, it is easy to know that given input length the output frame length after the last convolutional layer (but before any of the fully-connected layers) is l_6 = (l_o — 96)/27.
从我们的模型设计中,很容易知道给定的输入长度,在最后一个卷积层(但在任何一个全连接层之前)之后的输出帧长度是l_6 = (l_o - 96)/27。
This number multiplied with the frame size at layer 6 will give the input dimension the first fully-connected layer accepts.
这个数字与第6层的帧大小相乘,将为第一个全连接层提供输入维度。
2.4 Data Augmentation using Thesaurus
Many researchers have found that appropriate data augmentation techniques are useful for controlling generalization error for deep learning models.
许多研究者发现适当的数据扩充技术对于控制深度学习模型的泛化误差是有用的。
These techniques usually work well when we could find appropriate invariance properties that the model should possess.
当我们能够找到模型应该具有的适当的不变性时,这些技术通常是有效的。
In terms of texts, it is not reasonable to augment the data using signal transformations as done in image or speech recognition, because the exact order of characters may form rigorous syntactic and semantic meaning.
在文本方面,使用图像或语音识别中的信号转换来扩充数据是不合理的,因为字符的精确顺序可能形成严格的语法和语义意义。
Therefore, the best way to do data augmentation would have been using human rephrases of sentences, but this is unrealistic and expensive due the large volume of samples in our datasets.
因此,进行数据扩充的最佳方法是使用人类的语句重述,但是由于我们的数据集中有大量的样本,这是不现实和昂贵的。
As a result, the most natural choice in data augmentation for us is to replace words or phrases with their synonyms.
因此,我们在数据扩充时最自然的选择就是用同义词替换单词或短语。
We experimented data augmentation by using an English thesaurus, which is obtained from the mytheas component used in LibreOffice project.
我们使用英语同义词典进行数据扩充实验,该同义词典来自LibreOffice项目中使用的mytheas组件。
That thesaurus in turn was obtained from Word- Net [7], where every synonym to a word or phrase is ranked by the semantic closeness to the most frequently seen meaning.
而同义词词典则是由Word- Net[7]获得的,在那里,一个单词或短语的每个同义词都根据其最常出现的语义的紧密程度进行排序。
To decide on how many words to replace, we extract all replaceable words from the given text and randomly choose r of them to be replaced.
为了确定要替换多少个单词,我们从给定的文本中提取所有可替换的单词,并随机选择要替换的单词r。
The probability of number r is determined by a geometric distribution with parameter p in which P[r]〜 pr.
数r的概率由参数p的几何分布决定,其中p [r] ~ pr为参数。
The index s of the synonym chosen given a word is also determined by a another geometric distribution in which P[s].
给定一个词所选择的同义词的索引s也由另一个几何分布决定,其中P[s]。
This way, the probability of a synonym chosen becomes smaller when it moves distant from the most frequently seen meaning.
通过这种方式,当一个同义词与最常见的意思相距较远时,它被选择的可能性就会变小。
We will report the results using this new data augmentation technique with p = 0.5 and q = 0.5.
我们将使用p = 0.5和q = 0.5的新数据扩展技术报告结果。
3 Comparison Models
To offer fair comparisons to competitive models, we conducted a series of experiments with both traditional and deep learning methods.
为了与竞争模型进行公平的比较,我们用传统和深度学习方法进行了一系列的实验。
We tried our best to choose models that cp provide comparaple and competitive results, and the results are reported faithfully without any model selection.
我们尽量选择cp提供比较和竞争结果的模型,结果如实报告,没有任何模型选择。
3.1 Traditional Methods
We refer to traditional methods as those that using a hand-crafted feature extractor and a linear classifier.
我们将传统的方法称为使用手工制作的特征提取器和线性分类器的方法。
The classifier used is a multinomial logistic regression in all these models.
在所有这些模型中使用的分类器是一个多项逻辑回归。
Bag-of-words and its TFIDF.
For each dataset, the bag-of-words model is constructed by selecting 50,000 most frequent words from the training subset.
对于每个数据集,通过从训练子集中选择50,000个最频繁的单词来构建单词袋模型。
For the normal bag-of-words, we use the counts of each word as the features.
对于普通的单词包,我们使用每个单词的计数作为特征。
For the TFIDF (term-frequency inverse-document-frequency) [14] version, we use the counts as the term-frequency.
对于TFIDF (term-frequency inverse-document-frequency)[14]版本,我们使用计数作为term-frequency。
The inverse document frequency is the logarithm of the division between total number of samples and number of samples with the word in the training subset.
逆文档频率是训练子集中样本总数与样本个数之比的对数。
The features are normalized by dividing the largest feature value.
通过分割最大的特征值来标准化特征。
Bag-of-ngrams and its TFIDF.
The bag-of-ngrams models are constructed by selecting the 500,000 most frequent n-grams (up to 5-grams) from the training subset for each dataset.
通过从每个数据集的训练子集中选择50万个最频繁的n-g(最多5个)来构建神经网络包模型。
The feature values are computed the same way as in the bag-of-words model.
特征值的计算方法与bag-of-words模型相同。
Bag-of-means on word embedding.
We also have an experimental model that uses k-means on word2vec [23] learnt from the training subset of each dataset, and then use these learnt means as representatives of the clustered words.
我们还建立了一个实验模型,该模型从每个数据集的训练子集中获取word2vec[23]上的k-means,然后将这些k-means作为聚类词的代表。
We take into consideration all the words that appeared more than 5 times in the training subset.
我们考虑了所有在训练子集中出现超过5次的单词。
The dimension of the embedding is 300.
嵌入的尺寸是300。
The bag-of-means features are computed the same way as in the bag-of-words model.
均值袋装特征的计算方法与词语袋装模型的计算方法相同。
The number of means is 5000.
平均数是5000。
3.2 Deep Learning Methods
Recently deep learning methods have started to be applied to text classification.
近年来,深度学习方法开始应用于文本分类。
We choose two simple and representative models for comparison, in which one is word-based ConvNet and the other a simple long-short term memory (LSTM) [11] recurrent neural network model.
我们选择了两种简单而有代表性的模型进行比较,一种是基于单词的ConvNet,另一种是简单的长短时记忆[11]递归神经网络模型。
Word-based ConvNets.
Among the large number of recent works on word-based ConvNets for text classification, one of the differences is the choice of using pretrained or end-to-end learned word representations.
在最近大量基于单词的文本分类的ConvNets著作中,区别之一是选择使用预先训练的或端到端学习的单词表示。
We offer comparisons with both using the pretrained word2vec [23] embedding [16] and using lookup tables [5].
我们提供与使用预先训练的word2vec[23]嵌入[16]和使用查找表[5]的比较。
The embedding size is 300 in both cases, in the same way as our bag- of-means model.
在这两种情况下,嵌入的大小都是300,与我们的经济能力袋模型相同。
To ensure fair comparison, the models for each case are of the same size as our character-level ConvNets, in terms of both the number of layers and each layer's output size.
为了确保公平的比较,每种情况的模型在层数和每个层的输出大小方面都与我们的字符级ConvNets相同。
Experiments using a thesaurus for data augmentation are also conducted.
还进行了使用同义词库进行数据扩充的实验。
Long-short term memory.
We also offer a comparison with a recurrent neural network model, namely long-short term memory (LSTM) [11].
并与递归神经网络模型即长短时记忆(LSTM)[11]进行了比较。
The LSTM model used in our case is word-based, using pretrained word2vec embedding of size 300 as in previous models.
在我们的例子中使用的LSTM模型是基于单词的,使用预先训练的word2vec嵌入,大小为300,与以前的模型一样。
The model is formed by taking mean of the outputs of all LSTM cells to form a feature vector, and then using multinomial logistic regression on this feature vector.
该模型对所有LSTM细胞的输出取均值形成一个特征向量,然后对该特征向量进行多项逻辑回归。
The output dimension is 512.
输出维度是512。
The variant of LSTM we used is the common “vanilla” architecture [8] [9].
我们使用的LSTM的变体是常见的“香草”架构[8][9]。
We also used gradient clipping [25] in which the gradient norm is limited to 5.
我们还使用了梯度裁剪[25],其中梯度范数限制为5。
Figure 2 gives an illustration.
图2给出了一个说明。
Figure 2: long-short term memory
3.3 Choice of Alphabet
For the alphabet of English, one apparent choice is whether to distinguish between upper-case and lower-case letters.
对于英语字母表,一个明显的选择是是否区分大小写字母。
We report experiments on this choice and observed that it usually (but not always) gives worse results when such distinction is made.
我们报告了关于这个选择的实验,并观察到,当做出这样的区分时,通常(但不总是)会得到更糟糕的结果。
One possible explanation might be that semantics do not change with different letter cases, therefore there is a benefit of regularization.
一种可能的解释是,语义不会随着字母的不同而改变,因此正则化是有好处的。
4 Large-scale Datasets and Results
Previous research on ConvNets in different areas has shown that they usually work well with large- scale datasets, especially when the model takes in low-level raw features like characters in our case.
以前在不同领域对ConvNets的研究表明,它们通常可以很好地处理大规模数据集,特别是当模型采用低级原始特性(如我们的示例中的字符)时。
However, most open datasets for text classification are quite small, and large-scale datasets are splitted with a significantly smaller training set than testing [21].
然而,大多数用于文本分类的开放数据集都非常小,而且大型数据集的训练集比测试[21]小得多。
Therefore, instead of confusing our community more by using them, we built several large-scale datasets for our experiments, ranging from hundreds of thousands to several millions of samples.
因此,我们没有使用它们来迷惑我们的社区,而是为我们的实验建立了几个大规模的数据集,范围从数十万到数百万个样本。
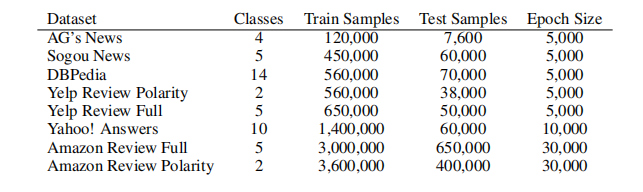
Table 3 is a summary.
表3是总结。
Table 3: Statistics of our large-scale datasets.
表3:大型数据集的统计数据。
Epoch size is the number of minibatches in one epoch
Epoch 大小是指在一个Epoch 内的小批数量
AG's news corpus.
We obtained the AG's corpus of news article on the web.
我们在网上获得了AG的新闻语料库。
It contains 496,835 categorized news articles from more than 2000 news sources.
它包含来自2000多个新闻来源的496835篇分类新闻文章。
We choose the 4 largest classes from this corpus to construct our dataset, using only the title and description fields.
我们从这个文集中选择4个最大的类来构建我们的数据集,只使用标题和描述字段。
The number of training samples for each class is 30,000 and testing 1900.
每个班的训练样本数量为30000个,测试1900个。
Sogou news corpus.
This dataset is a combination of the SogouCA and SogouCS news corpora [32], containing in total 2,909,551 news articles in various topic channels.
该数据集是SogouCA和SogouCS新闻语料库[32]的组合,包含了各种主题频道的2909 551篇新闻文章。
We then labeled each piece of news using its URL, by manually classifying the their domain names.
然后,我们使用其URL标记每条新闻,通过手动分类它们的域名。
This gives us a large corpus of news articles labeled with their categories.
这就为我们提供了一个巨大的新闻语料库,上面标注着它们的类别。
There are a large number categories but most of them contain only few articles.
类别很多,但大多数只包含很少的文章。
We choose 5 categories - “sports”,“foiance” “entertainment”, “automobile” and "technology”.
我们选择了5个类别——“体育”、“越轨”、“娱乐”、“汽车”和“科技”。
The number of training samples selected for each class is 90,000 and testing 12,000.
每个班选择的培训样本数量为90,000个,测试12,000个。
Although this is a dataset in Chinese, we used pypinyin package combined with jieba Chinese segmentation system to produce Pinyin - a phonetic romanization of Chinese.
虽然这是一个中文的数据集,但是我们使用了pypinyin package和jieba Chinese segmentation system来产生拼音,拼音是汉语的拼音。
The models for English can then be applied to this dataset without change.
然后,可以将英语模型应用于此数据集而无需更改。
The fields used are title and content.
使用的字段是标题和内容。
Table 4: Testing errors of all the models.
表4:各模型的测试误差。
Numbers are in percentage.
数字以百分数表示。
“Lg” stands for Targe” and “Sm” stands for “small”.
Lg代表Targe, Sm代表small。
“w2v" is an abbreviation for “word2vec”,and "Lk” for "lookup table”.
“w2v”是“word2vec”的缩写,“Lk”是“查找表”的缩写。
“Th” stands for thesaurus.
" Th "代表同义词词典。
ConvNets labeled "Full” are those that distinguish between lower and upper letters
标记为“Full”的ConvNets是那些区分上下字母的

DBPedia ontology dataset.
DBpedia is a crowd-sourced community effort to extract structured information from Wikipedia [19].
DBpedia是一个众包社区,旨在从Wikipedia[19]中提取结构化信息。
The DBpedia ontology dataset is constructed by picking 14 nonoverlapping classes from DBpedia 2014.
DBpedia本体数据集是通过从DBpedia 2014中选择14个不重叠类来构建的。
From each of these 14 ontology classes, we randomly choose 40,000 training samples and 5,000 testing samples.
从这14个本体类中,我们随机选择40000个训练样本和5000个测试样本。
The fields we used for this dataset contain title and abstract of each Wikipedia article.
我们为这个数据集使用的字段包含每个Wikipedia文章的标题和摘要。
Yelp reviews.
This dataset contains 1,569,264 samples that have review texts.
该数据集包含1,569,264个示例,其中包含审查文本。
Two classification tasks are constructed from this dataset - one predicting full number of stars the user has given, and the other predicting a polarity label by considering stars 1 and 2 negative, and 3 and 4 positive.
从这个数据集可以构造两个分类任务——一个是预测用户给出的完整的星数,另一个是通过考虑星1和2为负,星3和4为正来预测一个极性标签。
The full dataset has 130,000 training samples and 10,000 testing samples in each star, and the polarity dataset has 280,000 training samples and 19,000 test samples in each polarity.
完整的数据集在每个星上有130,000个训练样本和10,000个测试样本,而极性数据集在每个星上有280,000个训练样本和19,000个测试样本。
Yahoo! Answers dataset.
Answers Comprehensive Questions and Answers version 1.0 dataset through the Yahoo!
回答全面的问题和答案版本1.0的数据集通过雅虎!
Webscope program.
Webscope程序。
The corpus contains 4,483,032 questions and their answers.
语料库包含了4,483,032个问题及其答案。
We constructed a topic classification dataset from this coipus using 10 largest main categories.
我们使用10个最大的主要类别从这个coipus构建了一个主题分类数据集。
Each class contains 140,000 training samples and 5,000 testing samples.
每班包含14万个训练样本和5000个测试样本。
The fields we used include question title, question content and best answer.
我们使用的字段包括问题标题、问题内容和最佳答案。
Amazon reviews.
We obtained an Amazon review dataset from the Stanford Network Analysis Project (SNAP), which spans 18 years with 34,686,770 reviews from 6,643,669 users on 2,441,053 products [22].
我们从斯坦福网络分析项目(SNAP)获得了一个Amazon评论数据集,该数据集跨越18年,涉及2,441,053个产品[22]的6,643,669个用户的34,686,770条评论。
Similarly to the Yelp review dataset, we also constructed 2 datasets - one full score prediction and another polarity prediction.
与Yelp评论数据集类似,我们也构建了两个数据集——一个满分预测和另一个极性预测。
The full dataset contains 600,000 training samples and 130,000 testing samples in each class, whereas the polarity dataset contains 1,800,000 training samples and 200,000 testing samples in each polarity sentiment.
完整的数据集包含60万个训练样本和13万个测试样本,而极性数据集包含180万个训练样本和20万个测试样本。
The fields used are review title and review content.
使用的字段是评论标题和评论内容。
Table 4 lists all the testing errors we obtained from these datasets for all the applicable models.
表4列出了我们从这些数据集中获得的所有适用模型的所有测试错误。
Note that since we do not have a Chinese thesaurus, the Sogou News dataset does not have any results using thesaurus augmentation.
注意,由于我们没有中文同义词典,搜狗新闻数据集没有使用同义词典扩充的任何结果。
We labeled the best result in blue and worse result in red.
我们用蓝色标出最好的结果,用红色标出最差的结果。
5 Discussion
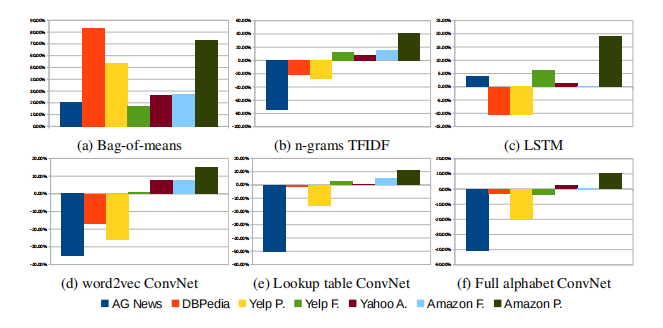
Figure 3: Relative errors with comparison models
To understand the results in table 4 further, we offer some empirical analysis in this section.
为了进一步理解表4中的结果,我们在本节中提供了一些实证分析。
To facilitate our analysis, we present the relative errors in figure 3 with respect to comparison models.
为了便于分析,我们在图3中给出了相对于比较模型的相对误差。
Each of these plots is computed by taking the difference between errors on comparison model and our character-level ConvNet model, then divided by the comparison model error.
每个图的计算方法是取比较模型和我们的字符级ConvNet模型的误差之差,然后除以比较模型误差。
All ConvNets in the figure are the large models with thesaurus augmentation respectively.
图中所有的ConvNets是大模型分别与同义词典扩增。
Character-level ConvNet is an effective method.
The most important conclusion from our experiments is that character-level ConvNets could work for text classification without the need for words.
从我们的实验中得出的最重要的结论是,字符级卷积神经网络可以在不需要单词的情况下进行文本分类。
This is a strong indication that language could also be thought of as a signal no different from any other kind.
这是一个强有力的迹象,表明语言也可以被认为是一个信号,没有不同于任何其他类型。
Figure 4 shows 12 random first-layer patches learnt by one of our character-level ConvNets for DBPedia dataset.
图4显示了12个随机的第一层补丁,它们是由DBPedia数据集的一个字符级卷积神经网络学习到的。

Figure 4: First layer weights. For each patch, height is the kernel size and width the alphabet size
Dataset size forms a dichotomy between traditional and ConvNets models.
The most obvious trend coming from all the plots in figure 3 is that the larger datasets tend to perform better.
从图3的所有图中可以看出,最明显的趋势是较大的数据集往往表现得更好。
Traditional methods like n-grams TFIDF remain strong candidates for dataset of size up to several hundreds of thousands, and only until the dataset goes to the scale of several millions do we observe that character-level ConvNets start to do better.
像n-grams TFIDF这样的传统方法仍然是大到几十万的数据集的有力候选者,只有当数据集达到几百万的规模时,我们才能观察到字符级的ConvNets开始做得更好。
ConvNets may work well for user-generated data.
User-generated data vary in the degree of how well the texts are curated.
用户生成的数据在文本管理的程度上各不相同。
For example, in our million scde datasets, Amazon reviews tend to be raw user-inputs, whereas users might be extra careful in their writings on Yahoo!
例如,在我们的一百万个scde数据集中,Amazon评论往往是原始的用户输入,而用户在Yahoo!
Answers, Plots comparing word-based deep models (figures 3c, 3d and 3e) show that character-level ConvNets work better for less curated user-generated texts.
答案,比较基于单词的深层模型的图(图3c, 3d和3e)表明,字符级的ConvNets更适合于管理较少的用户生成文本。
This property suggests that ConvNets may have better applicability to real-world scenarios.
这一特性表明,ConvNets可能对现实场景具有更好的适用性。
However, further analysis is needed to validate the hypothesis that ConvNets are truly good at identifying exotic character combinations such as misspellings and emoticons, as our experiments alone do not show any explicit evidence.
然而,我们还需要进一步的分析来验证这样的假设,即ConvNets确实擅长识别外来字符组合,如拼写错误和表情符号,因为我们的实验没有任何明确的证据。
Choice of alphabet makes a difference.
Figure 3f shows that changing the alphabet by distinguishing between uppercase and lowercase letters could make a difference.
图3f显示,通过区分大写字母和小写字母来改变字母表可能会有所不同。
For million-scale datasets, it seems that not making such distinction usually works better.
对于数百万规模的数据集,似乎不做这样的区分通常效果更好。
One possible explanation is that there is a regularization effect, but this is to be validated.
一种可能的解释是存在正则化效应,但这有待验证。
Semantics of tasks may not matter.
Our datasets consist of two kinds of tasks: sentiment analysis (Yelp and Amazon reviews) and topic classification (it others).
我们的数据集包括两类任务:情感分析(Yelp和Amazon评论)和主题分类(it其他)。
This dichotomy in task semantics does not seem to play a role in deciding which method is better.
这种任务语义上的二分法似乎并不能决定哪种方法更好。
Bag-of-means is a misuse of word2vec [20].
One of the most obvious facts one could observe from table 4 and figure 3a is that the bag-of-means model performs worse in every case.
从表4和图3a中可以观察到的一个最明显的事实是,均值袋装模型在每种情况下的性能都更差。
Comparing with traditional models, this suggests such a simple use of a distributed word representation may not give us an advantage to text classification.
与传统的模式相比,这表明如此简单地使用分布式单词表示可能不会给我们文本分类带来优势。
However, our experiments does not speak for any other language processing tasks or use of word2vec in any other way.
然而,我们的实验不涉及任何其他语言处理任务或以任何其他方式使用word2vec。
There is no free lunch.
Our experiments once again verifies that there is not a single machine learning model that can work for all kinds of datasets.
我们的实验再次证明,没有一个单一的机器学习模型可以适用于所有类型的数据集。
The factors discussed in this section could all play a role in deciding which method is the best for some specific application.
本节中讨论的因素都可能在决定哪种方法最适合某些特定的应用方面发挥作用。
6 Conclusion and Outlook
This article offers an empirical study on character-level convolutional networks for text classification.
本文对用于文本分类的字符级卷积网络进行了实证研究。
We compared with a large number of traditional and deep learning models using several large- scale datasets.
我们使用几个大规模的数据集与大量的传统和深度学习模型进行了比较。
On one hand, analysis shows that character-level ConvNet is an effective method.
分析表明,字符级卷积神经网络是一种有效的方法。
On the other hand, how well our model performs in comparisons depends on many factors, such as dataset size, whether the texts are curated and choice of alphabet.
另一方面,我们的模型在比较中的表现取决于许多因素,如数据集的大小、文本是否编排和字母的选择。
In the future, we hope to apply character-level ConvNets for a broader range of language processing tasks especially when structured outputs are needed.
在未来,我们希望将字符级的卷积神经网络应用于更广泛的语言处理任务,特别是在需要结构化输出的情况下。
Acknowledgement
We gratefully acknowledge the support of NVIDIA Corporation with the donation of 2 Tesla K40 GPUs used for this research.
我们非常感谢英伟达公司的支持,捐赠了2台用于本研究的特斯拉K40 gpu。
We gratefully acknowledge the support of Amazon.com Inc for an AWS in Education Research grant used for this research.
我们非常感谢亚马逊公司对本次研究使用的AWS教育研究补助金的支持。
References
[1] L. Bottou, F. Fogelman Soulie, P. Blanchet, and J. Lienard. Experiments with time delay networks and dynamic time warping for speaker independent isolated digit recognition. In Proceedings of EuroSpeech 89, volume 2, pages 537–540, Paris, France, 1989.
[2] Y.-L. Boureau, F. Bach, Y. LeCun, and J. Ponce. Learning mid-level features for recognition. In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, pages 2559–2566. IEEE, 2010.
[3] Y.-L. Boureau, J. Ponce, and Y. LeCun. A theoretical analysis of feature pooling in visual recognition. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), pages 111–118, 2010.
[4] R. Collobert, K. Kavukcuoglu, and C. Farabet. Torch7: A matlab-like environment for machine learning. In BigLearn, NIPS Workshop, number EPFL-CONF-192376, 2011.
[5] R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, and P. Kuksa. Natural language processing (almost) from scratch. J. Mach. Learn. Res., 12:2493–2537, Nov. 2011.
[6] C. dos Santos and M. Gatti. Deep convolutional neural networks for sentiment analysis of short texts. In Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers*, pages 69–78, Dublin, Ireland, August 2014. Dublin City University and Association for Computational Linguistics.
[7] C. Fellbaum. Wordnet and wordnets. In K. Brown, editor, Encyclopedia of Language and Linguistics, pages 665–670, Oxford, 2005. Elsevier.
[8] A. Graves and J. Schmidhuber. Framewise phoneme classifification with bidirectional lstm and other neural network architectures. Neural Networks, 18(5):602–610, 2005.
[9] K. Greff, R. K. Srivastava, J. Koutn´ık, B. R. Steunebrink, and J. Schmidhuber. LSTM: A search space odyssey. CoRR, abs/1503.04069, 2015.
[10] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012.
[11] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Comput., 9(8):1735–1780, Nov. 1997.
[12] T. Joachims. Text categorization with suport vector machines: Learning with many relevant features. In Proceedings of the 10th European Conference on Machine Learning, pages 137–142. Springer-Verlag, 1998.
[13] R. Johnson and T. Zhang. Effective use of word order for text categorization with convolutional neural networks. CoRR, abs/1412.1058, 2014.
[14] K. S. Jones. A statistical interpretation of term specifificity and its application in retrieval. Journal of Documentation, 28(1):11–21, 1972.
[15] I. Kanaris, K. Kanaris, I. Houvardas, and E. Stamatatos. Words versus character n-grams for anti-spam filtering. International Journal on Artifificial Intelligence Tools, 16(06):1047–1067, 2007.
[16] Y. Kim. Convolutional neural networks for sentence classifification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1746–1751, Doha, Qatar, October 2014. Association for Computational Linguistics.
[17] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, Winter 1989.
[18] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, November 1998.
[19] J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P. N. Mendes, S. Hellmann, M. Morsey, P. van Kleef, S. Auer, and C. Bizer. DBpedia - a large-scale, multilingual knowledge base extracted from wikipedia. Semantic Web Journal, 2014.
[20] G. Lev, B. Klein, and L. Wolf. In defense of word embedding for generic text representation. In C. Biemann, S. Handschuh, A. Freitas, F. Meziane, and E. Mtais, editors, Natural Language Processing and Information Systems, volume 9103 of Lecture Notes in Computer Science, pages 35–50. Springer International Publishing, 2015.
[21] D. D. Lewis, Y. Yang, T. G. Rose, and F. Li. Rcv1: A new benchmark collection for text categorization research. The Journal of Machine Learning Research, 5:361–397, 2004.
[22] J. McAuley and J. Leskovec. Hidden factors and hidden topics: Understanding rating dimensions with review text. In Proceedings of the 7th ACM Conference on Recommender Systems, RecSys ’13, pages 165–172, New York, NY, USA, 2013. ACM.
[23] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Weinberger, editors, Advances in Neural Information Processing Systems 26, pages 3111–3119. 2013.
[24] V. Nair and G. E. Hinton. Rectifified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), pages 807–814, 2010.
[25] R. Pascanu, T. Mikolov, and Y. Bengio. On the diffificulty of training recurrent neural networks. In ICML 2013, volume 28 of JMLR Proceedings, pages 1310–1318. JMLR.org, 2013.
[26] B. Polyak. Some methods of speeding up the convergence of iteration methods. {USSR} Computational Mathematics and Mathematical Physics, 4(5):1 – 17, 1964.
[27] D. Rumelhart, G. Hintont, and R. Williams. Learning representations by back-propagating errors. Nature, 323(6088):533–536, 1986.
[28] C. D. Santos and B. Zadrozny. Learning character-level representations for part-of-speech tagging. In Proceedings of the 31st International Conference on Machine Learning (ICML-14)*, pages 1818–1826, 2014.
[29] Y. Shen, X. He, J. Gao, L. Deng, and G. Mesnil. A latent semantic model with convolutional-pooling
structure for information retrieval. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, pages 101–110. ACM, 2014.
[30] I. Sutskever, J. Martens, G. E. Dahl, and G. E. Hinton. On the importance of initialization and momentum
in deep learning. In S. Dasgupta and D. Mcallester, editors, Proceedings of the 30th International Conference on Machine Learning (ICML-13), volume 28, pages 1139–1147. JMLR Workshop and Conference Proceedings, May 2013.
[31] A. Waibel, T. Hanazawa, G. Hinton, K. Shikano, and K. J. Lang. Phoneme recognition using time-delay neural networks. Acoustics, Speech and Signal Processing, IEEE Transactions on, 37(3):328–339, 1989.
[32] C. Wang, M. Zhang, S. Ma, and L. Ru. Automatic online news issue construction in web environment. In Proceedings of the 17th International Conference on World Wide Web, WWW ’08, pages 457–466, New York, NY, USA, 2008. ACM.
论文翻译——Character-level Convolutional Networks for Text Classification的更多相关文章
- VGGNet论文翻译-Very Deep Convolutional Networks for Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition Karen Simonyan[‡] & Andrew Zi ...
- 论文解读(DropEdge)《DropEdge: Towards Deep Graph Convolutional Networks on Node Classification》
论文信息 论文标题:DropEdge: Towards Deep Graph Convolutional Networks on Node Classification论文作者:Yu Rong, We ...
- 图像处理论文详解 | Deformable Convolutional Networks | CVPR | 2017
文章转自同一作者的微信公众号:[机器学习炼丹术] 论文名称:"Deformable Convolutional Networks" 论文链接:https://arxiv.org/a ...
- 目标检测论文阅读:Deformable Convolutional Networks
https://blog.csdn.net/qq_21949357/article/details/80538255 这篇论文其实读起来还是比较难懂的,主要是细节部分很需要推敲,尤其是deformab ...
- [论文理解] Learning Efficient Convolutional Networks through Network Slimming
Learning Efficient Convolutional Networks through Network Slimming 简介 这是我看的第一篇模型压缩方面的论文,应该也算比较出名的一篇吧 ...
- 论文学习:Fully Convolutional Networks for Semantic Segmentation
发表于2015年这篇<Fully Convolutional Networks for Semantic Segmentation>在图像语义分割领域举足轻重. 1 CNN 与 FCN 通 ...
- #论文阅读# Universial language model fine-tuing for text classification
论文链接:https://aclweb.org/anthology/P18-1031 对文章内容的总结 文章研究了一些在general corous上pretrain LM,然后把得到的model t ...
- 论文翻译:Ternary Weight Networks
目录 Abstract 1 Introduction 1.1 Binary weight networks and model compression 2 Ternary weight network ...
- [论文阅读]VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION(VGGNet)
VGGNet由牛津大学的视觉几何组(Visual Geometry Group)提出,是ILSVRC-2014中定位任务第一名和分类任务第二名.本文的主要贡献点就是使用小的卷积核(3x3)来增加网络的 ...
随机推荐
- PAT Advanced 1003 Emergency (25) [Dijkstra算法]
题目 As an emergency rescue team leader of a city, you are given a special map of your country. The ma ...
- python查找数组中出现次数最多的元素
方法1-np.argmax(np.bincount()) 看一个例子 array = [0,1,2,2,3,4,4,4,5,6] print(np.bincount(array)) print(np. ...
- Sequence Models Week 1 Character level language model - Dinosaurus land
Character level language model - Dinosaurus land Welcome to Dinosaurus Island! 65 million years ago, ...
- POJ 1094:Sorting It All Out拓扑排序之我在这里挖了一个大大的坑
Sorting It All Out Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 29984 Accepted: 10 ...
- Python自学之路---Day01
目录 Python自学之路---Day01 注释 单行注释 多行注释 print()函数 语法 参数 实例 input()函数 语法 参数 实例 查看Python的关键字 代码 变量与常量 变量 如何 ...
- 系统学习python第一天学习笔记
1.计算机认识 1.常见的操作系统 win xp win7 win10 window server(服务器) linux centos,图形化界面差 ubuntu , 个人开发(图形化比较好) red ...
- .NET 软件下面win10自动启动配置
1.设置所有用户登录都能启动,打开文件夹 C:\ProgramData\Microsoft\Windows\Start Menu\Programs\StartUp 2.给要启动的应用程序创建快捷方式, ...
- 一个算法题--Self Crossing
You are given an array x of n positive numbers. You start at point (0,0) and moves x[0] metres to th ...
- 【十日冲刺计划】第一日 星遇Sprint1计划会议成果
——小组成员 赵剑峰 张傲 周龙海 Sprint 计划会议1:定出 Sprint 目标和既定产品Backlog. 会议进程(1小时) • 首先对sprint目标进行总体介绍,概括星遇的backlog, ...
- 2019年Unity3D游戏开发前景预测及总结
由于现在随着互联网时代的到来,人们上网玩游戏的越来越多,导致游戏开发人才供不应求,如果你想成为一名优秀的开发者,那么掌握Unity3D开发技术是不可跳过的一环.随着移动互联网的发展,移动端游戏日益盛行 ...