Django_前介
Django
1.软件框架
一个公司是由公司中的各部部门来组成的,每一个部门拥有特定的职能,部门与部门之间通过相互的配合来完成让公司运转起来。
一个软件框架是由其中各个软件模块组成的,每一个模块都有特定的功能,模块与模块之间通过相互配合来完成软件的开发。
软件框架是针对某一类软件设计问题而产生的。
2.MVC框架
2.1 MVC简介
MVC最初是由施乐公司旗下的帕罗奥多研究中心中的一位研究人员给 smalltalk语言发明的一中软件设计模式。
MVC的产生理念: 分工。让专门的人去做专门的事。
MVC的核心思想: 解耦
MVC的思想被应用在的web开发的方面,产生了web MVC框架。
2.2 Web MVC框架模块功能
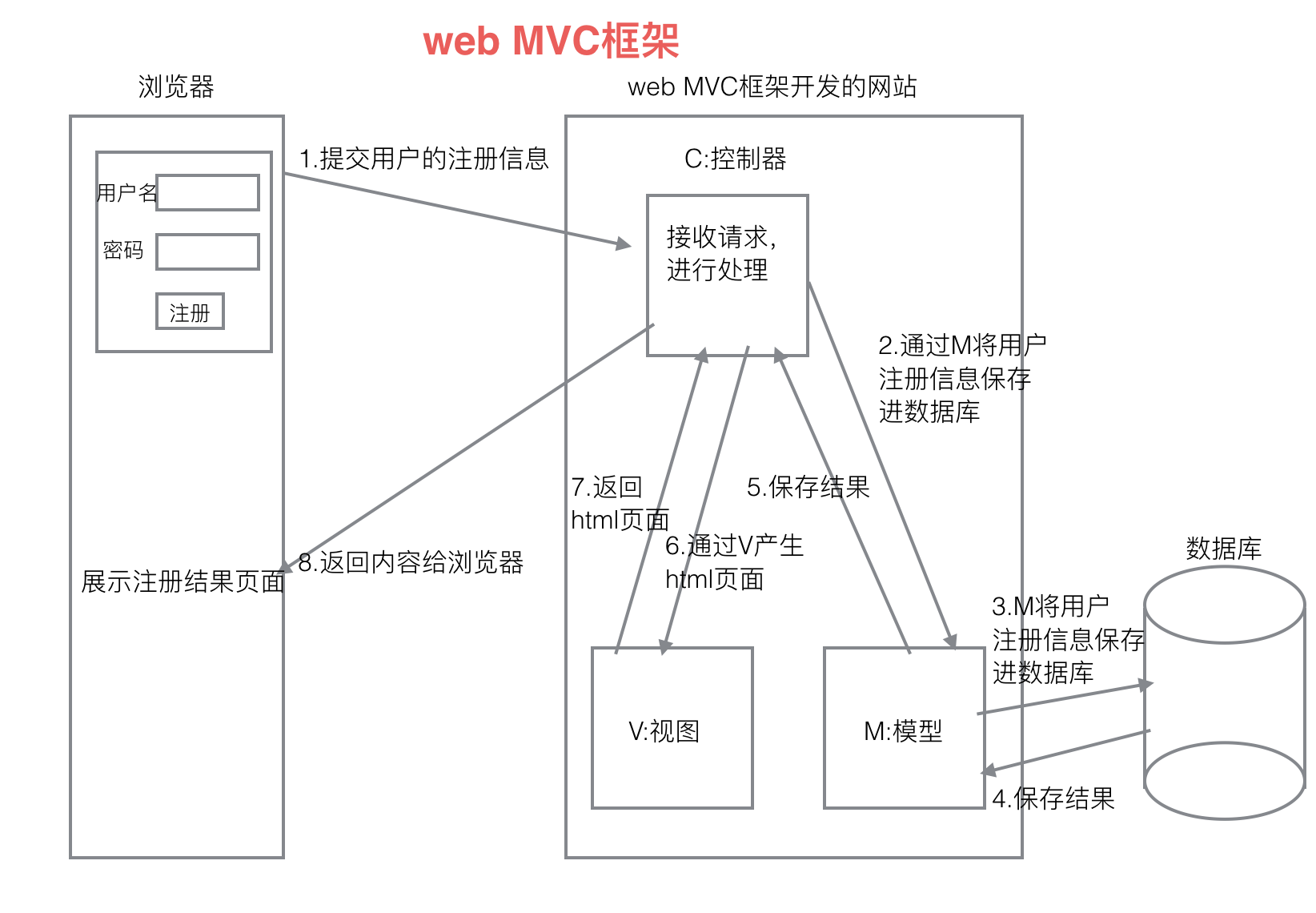
M:Model,模型, 和数据库进行交互。
V:View,视图, 产生html页面。
C:Controller,控制器, 接收请求,进行处理,与M和V进行交互,返回应答。
3.MVT
Django 劳伦斯出版集团 新闻内容网站。Python MVC
快速开发和DRY原则。Do not repeat yourself.不要自己去重复一些工作。
M:Model,模型,
V: View,视图,
T: Template,模板,
4.虚拟环境
之前安装python包的命令:pip3 insstall 包名
包的安装路径:/usr/local/lib/python3.5/dist-packages
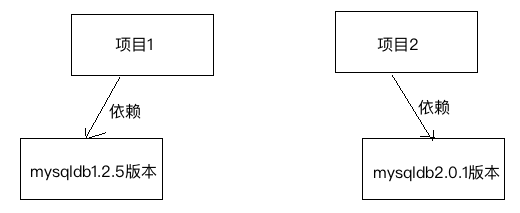
安装同一个包的不同版本,后安装的包会把原来安装的包覆盖掉。这样,如同一个台机器上两个项目依赖于相同包的不同版本,则会导致一些项目运行失败。
解决的方案就是:虚拟环境。
虚拟环境是真实python环境的复制版本。
centos7安装Python虚拟环境:
更新pip
pip install --upgrade pip
升级pip失败,可以尝试以下的命令
python -m pip install --upgrade pip -i https://pypi.douban.com/simple
创建一个隐藏目录.virtualenvs
- mkdir /root/.virtualenvs
安装虚拟环境
确认pip: whereis pip3
pip3 install virtualenv
pip3 install virtualenvwrapper --default-timeout=1000 #安装虚拟环境扩展包
pip3 list
- 可以看见 virtualenv的三个文件
配置环境变量
- whereis virtualenvwrapper.sh
- vim ~/.bashrc
export WORKON_HOME=~/.virtualenvs #指定virtualenvwrapper环境的目录 export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3 #指定virtualenvwrapper通过哪个python版本来创建虚拟环境 source source /usr/local/python3/bin/virtualenvwrapper.sh #每个人的位置可能不一样,通过find查找一下 find /usr/local -name 'virtualenvwrapper.sh'
root用户下创建链接
- cd /usr/bin/
- ln -s /usr/local/python3/bin/virtualenv
使用source.bashrc使其生效一下。
创建虚拟环境(联网):
创建虚拟环境命令:
mkvirtualenv 虚拟环境名
创建python3虚拟环境:
mkvirtualenv -p python3 bj11_py3
进入虚拟环境工作:
workon 虚拟环境名
查看机器上有多少个虚拟环境:
workon 空格 + 两个tab键
退出虚拟环境:
deactivate
删除虚拟环境:
rmvirtualenv 虚拟环境名
虚拟环境下安装包的命令:
pip install 包名
注意:不能使用sudo pip install 包名,这个命令会把包安装到真实的主机环境上而不是安装到虚拟环境中。
apt-get install 软件
pip install python包名
安装django环境:
pip install django==1.11.28
查看虚拟环境中安装了哪些python包:
pip list
pip freeze
5.项目创建
创建项目
命令:django-admin startproject 项目名
注意:创建应用必须先进入虚拟环境。
项目目录介绍:
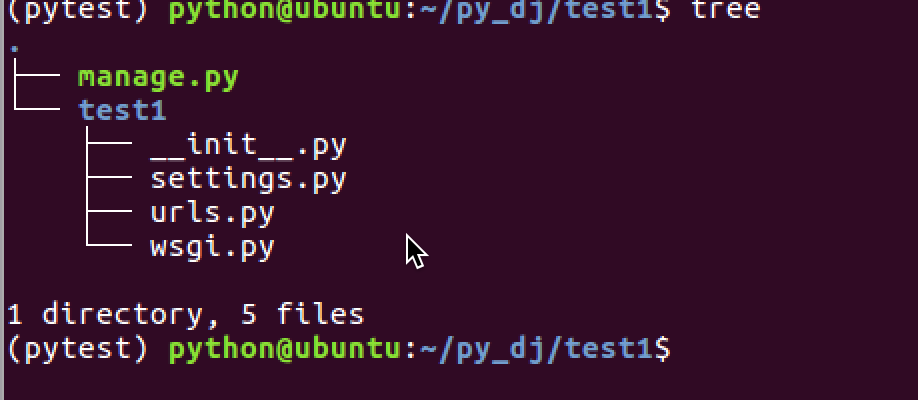
init.py: 说明test1是一个python包。
settings.py: 项目的配置文件
urls.py: 进行url路由的配置
wsgi.py: web 服务器和Django交互的入口
manage.py: 项目的管理文件
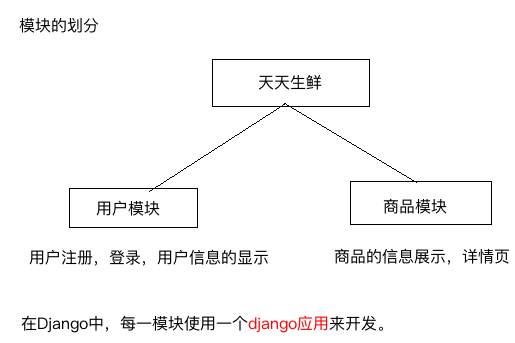
一个项目由很多个应用组成的,每一个应用完成一个特定的功能。
创建应用:
python manage.py startapp 应用名
注意:创建应用时需要先进入项目目录。
应用目录如下:
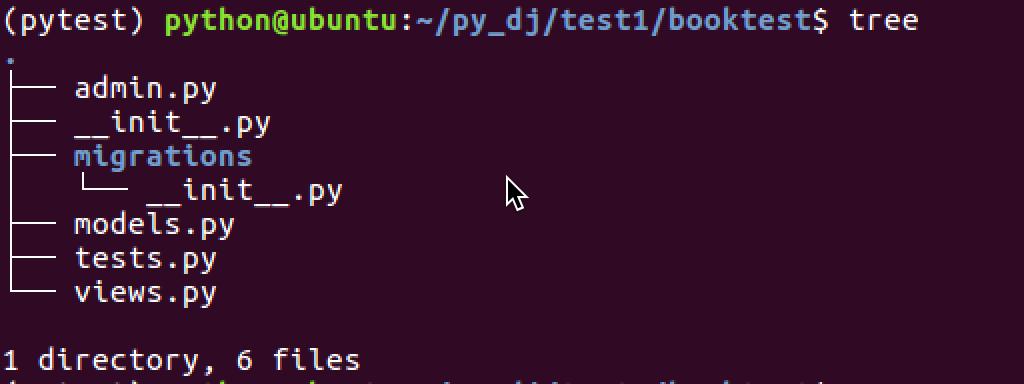
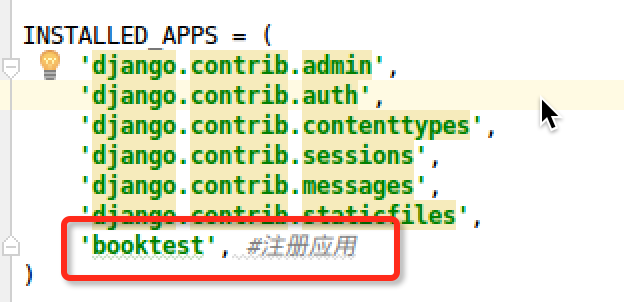
建立应用和项目之间的联系,需要对应用进行注册。
修改settings.py中的INSTALLED_APPS配置项。
运行开发web服务器命令:
python manage.py runserver
6. 模型类
django中内嵌了ORM框架,ORM框架可以将类和数据表进行对应起来,只需要通过类和对象就可以对数据表进行操作。
设计类:模型类。
ORM另外一个作用:根据设计的类生成数据库中的表。
模型设计
在应用models.py中设计模型类。
必须继承与models.Model类。
- 设计BookInfo类。
- 设计HeroInfo类。
Models.ForeignKey可以建立两个模型类之间一对多的关系,django在生成表的时候,就会在多的表中创建一列作为外键,建立两个表之间一对多的关系。
模型类生成表
1) 生成迁移文件
命令:python manage.py makemigrations
 迁移文件是根据模型类生成的。
迁移文件是根据模型类生成的。
2) 执行迁移生成表
命令:python mange.py migrate
根据迁移文件生成表。
生成表名的默认格式:
应用名_模型类名小写
通过模型类操作数据表
进入项目shell的命令:
python manage.py shell
以下为在相互shell终端中演示的例子:
首先导入模型类:
from booktest.models import BookInfo,HeroInfo
1)向booktest_bookinfo表中插入一条数据。
b = BookInfo() #定义一个BookInfo类的对象
b.btitle ='天龙八部' #定义b对象的属性并赋值
b.bpub_date = date(1990,10,11)
b.save() #才会将数据保存进数据库
2)查询出booktest_bookinfo表中id为1的数据。
b = BookInfo.objects.get(id=1)
3)在上一步的基础上改变b对应图书的出版日期。
b.bpub_date = date(1989,10,21)
b.save() #才会更新表格中的数据
4)紧接上一步,删除b对应的图书的数据。
b.delete() #才会删除
5)向booktest_heroInfo表中插入一条数据。
h = HeroInfo()
h.hname = '郭靖'
h.hgender = False
h.hcomment = ‘降龙十八掌’
b2 = BookInfo.objects.get(id=2)
h.hbook = b2 #给关系属性赋值,英雄对象所属的图书对象
h.save()
6)查询图书表里面的所有内容。
BookInfo.objects.all()
HeroInfo.objects.all()
关联操作

1)查询出id为2的图书中所有英雄人物的信息。
b = BookInfo.objects.get(id=2)
b.heroinfo_set.all() #查询出b图书中所有英雄人物的信息
7.后台管理
1) 本地化
语言和时区的本地化。
修改settings.py文件。
LANGUAGE_CODE = 'zh-hans' #使用中文
TIME_ZONE = 'Asia/Shanghai' #中国时间
2) 创建管理员
- python manage.py createsuperuser
- python manage.py runserver
- 网页访问127.0.0.1:8000/admin,输入自己上一步命令执行后添加的超级用户名和密码
3) 注册模型类
在应用下的admin.py中注册模型类。
告诉djang框架根据注册的模型类来生成对应表管理页面。
b = BookInfo()
str(b) str
4) 自定义管理页面
自定义模型管理类。模型管理类就是告诉django在生成的管理页面上显示哪些内容。需要修改admin.py文件。
8.视图
在Django中,通过浏览器去请求一个页面时,使用视图函数来处理这个请求的,视图函数处理之后,要给浏览器返回页面内容。
视图函数的使用
1)定义视图函数
视图函数定义在views.py中。
例:
from django.http import HttpResponse
def index(request):
#进行处理。。。
return HttpResponse('hello python')
视图函数必须有一个参数request,进行处理之后,需要返回一个HttpResponse的类对象,hello python就是返回给浏览器显示的内容。
2)进行url配置

url配置的目的:是让建立url和视图函数的对应关系。url配置项定义在urlpatterns的列表中,每一个配置项都调用url函数。
url函数有两个参数,第一个参数是一个正则表达式,第二个是对应的处理动作。
配置url时,有两种语法格式:
a) url(正则表达式,视图函数名)
b) url(正则表达式,include(应用中的urls文件))
注意:在应用的urls文件中进行url配置的时候,严格匹配开头和结尾。
工作中在配置url时,首先在项目的urls.py文件中添加配置项时,并不写具体的url和视图函数之间的对应关系,而是包含具体应用的urls.py文件,在应用的urls.py文件中写url和视图函数的对应关系。
url匹配的过程解析
在项目的urls.py文件中包含具体应用的urls.py文件,应用的urls.py文件中写url和视图函数的对应关系。

当用户输入如http://127.0.0.1:8000/aindex时,去除域名和最前面的/,剩下aindex,拿aindex字符串到项目的urls文件中进行匹配,配置成功之后,去除匹配的a字符,那剩下的index字符串继续到项目的urls文件中进行正则匹配,匹配成功之后执行视图函数index,index视图函数返回内容hello python给浏览器来显示。
9.模版
模板不仅仅是一个html文件。
模版文件的使用
1) 创建模板文件夹
2) 配置模板目录,是项目的settings.py

- 使用模板文件
a) 加载模板文件,去模板目录下面获取html文件的内容,得到一个模板对象。
b) 定义模板上下文,向模板文件传递数据。
c) 模板渲染,得到一个标准的html内容。
打开项目的view.py文件进行修改
from django.template import loader,RequestContext # 同一级目录创建template的目录
# 1、加载模版文件,模版对象
temp = loader.get_template('模版文件的路径')
# 2、定义模版上下文:给模版文件传递数据
RequestContext(request,{}) #{}里面是字典键值对
# 3、模版渲染:产生标准的html内容
res_html = temp.render(context)
# 4、返回给浏览器
return HttpResponse(res_html)
给模版文件传递数据
模板变量使用:{{ 模板变量名 }}
模板代码段:{%代码段%}
for循环:
{% for i in list %}
{% endfor %}
10.案例完成
编码之前的准备工作:
1) 设计出访问页面的url和对应的视图函数的名字,确定视图函数的功能。
2) 设计模板文件的名字。
以下为案例中的简单设计过程:
1)完成图书信息的展示:
a) 设计url,通过浏览器访问 [http://127.0.0.1:8000/books/ 时显示图书信息页面](http://127.0.0.1:8000/books/ 时显示图书信息页面)。
# 修改项目的url文件(urls.py)
# 新增一行url路径
url(r'^books$',views.show_books), # 显示图书信息
b) 设计url对应的视图函数show_books。查询出所有图书的信息,将这些信息传递给模板文件。
# 修改项目的视图文件(views.py)
# 导入图书模型类
from booktest.models import BookInfo
def show_books(request):
'''显示图书的信息'''
# 1、通过M超找图书表中的数据
books = BookInfo.objests.all()
# 2、使用模版,模版文件可以自己能区分的名字自己新建一个模版文件
return render(request,'模版文件的路径',{'books':books})
c) 编写模板文件show_books.html。遍历显示出每一本图书的信息。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>显示图书信息</title>
</head>
<body>
图书信息如下:
<ul>
{% for book in books %}
<li>
<a href="/books/{{ book.id }}">{{ book.btitle }}</a>
</li>
{% endfor %}
</ul>
</body>
</html>
2) 完成点击某本图书时,显示出图书里所有英雄信息的页面。
a) 设计url,通过访问http://127.0.0.1:8000/books/数字/时显示对应的英雄信息页面。
这里数字指点击的图书的id。
b)设计对应的视图函数detail。
接收图书的id,根据id查询出相应的图书信息,然后查询出图书中的所有英雄信息。
# 修改项目的视图文件(views.py)
# 增加:
def detail(request,bid):
'''查询图书相关联英雄信息'''
# 1.根据bid查询图书信息
book = BookInfo.objects.get(id=bid)
# 2.查询和book关联的英雄
heros = book.heroinfo_set.all()
# 3.使用模版
return render(request,'booktest/detail.html',{'book':book,'heros':heros})
c) 编写模板文件detail.html。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>显示图书关联的英雄信息</title>
</head>
<body>
<h1>{{ book.btitle }}</h1>
英雄信息如下:<br />
<ul>
{% for hero in heros %}
<li>{{ hero.hname}}---{{hero.hcomment}}</li>
{% empty %}
<li>没有英雄信息</li>
{% endfor %}
</ul>
</body>
</html>
d) 定义url路径
# 编辑项目的url.py文件
# 增加一个路由
url(r'^books/(\d+)$',views.detail),# 显示英雄信息 (\d+)是分组
12.模型
Django ORM

O:(objects)->类和对象。
R:(Relation)->关系,关系数据库中的表格。
M:(Mapping)->映射。
ORM框架的功能
a) 能够允许我们通过面向对象的方式来操作数据库。
b) 可以根据我们设计的模型类帮我们自动生成数据库中的表格。
c) 通过方便的配置就可以进行数据库的切换。
数据库配置
mysql命令回顾:
登录mysql数据库:mysql –uroot –p
查看有哪些数据库:show databases;
创建数据库:create database test2 charset=utf8
切记:指定编码
使用数据库:use test2;
查看数据库中的表:show tables;
Django配置使用mysql数据库:
修改settings.py中的DATABASES。

注意:django框架不会自动帮我们生成mysql数据库,所以我们需要自己去创建。
切换mysql数据库之后不能启动服务器:
安装mysqlPython包:
python2:
pip install mysql-python
python3:
安装pymysql:
pip install pymysql
在test2/init.py中加如下内容:
import pymysql
pymysql.install_as_MySQLdb()
复习案例
- 设计模型类并生成表
a) 设计BookInfo,增加属性bread和bcomment,另外设置软删除标记属性isDelete。
b) 设计HeroInfo类,增加软删除标记属性isDelete。
软删除标记:删除数据时不做真正的删除,而是把标记位置1表示删除,防止重要的数据丢失。
- 编写视图函数并配置URL。

页面重定向:服务器不返回页面,而是告诉浏览器再去请求其他的url。
3)创建模板文件。
*拆解功能:*
- 图书信息展示页。
a) 设计url,通过浏览器访问 [http://127.0.0.1:8000/index/ 时显示图书信息页面](http://127.0.0.1/index/ 时显示图书信息页面)。
b) 设计url对应的视图函数index。
查询出所有图书的信息,将这些信息传递给模板文件。
c) 编写模板文件index.html。
遍历显示出每一本图书的信息并增加新建和删除超链接。
2)图书信息新增。
a)设计url,通过浏览器访问 http://127.0.0.1:8000/create/时向数据库中新增一条图书信息。
b) 设计url对应得视图函数create。
3)图书信息删除。
a)设计url,通过浏览器访问 http://127.0.0.1:8000/delete数字/删除数据库中对应的一条图书数据。
数字是点击的图书的id。
b) 设计url对应得视图函数delete。
字段属性和选项
属性命名限制:
1)不能是python的保留关键字。
2)不允许使用连续的下划线,这是由django的查询方式决定的。
3)定义属性时需要指定字段类型,通过字段类型的参数指定选项,语法如下:
属性名=models.字段类型(选项)
字段类型
使用时需要引入django.db.models包,字段类型如下:
AutoField:自动增长的IntegerField,通常不用指定,不指定时Django会自动创建属性名为id的自动增长属性。
BooleanField:布尔字段,值为True或False。
NullBooleanField:支持Null、True、False三种值。
CharField(max_length=字符长度):字符串。参数max_length表示最大字符个数。
TextField:大文本字段,一般超过4000个字符时使用。
IntegerField:整数。
DecimalField:(max_digits=None, decimal_places=None):十进制浮点数。参数max_digits表示总位数。参数decimal_places表示小数位数。
FloatField:浮点数。
DateField:[auto_now=False, auto_now_add=False]):日期。
- 参数auto_now表示每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为false。
- 参数auto_now_add表示当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为false。
- 参数auto_now_add和auto_now是相互排斥的,组合将会发生错误。
TimeField:时间,参数同DateField。
DateTimeField:日期时间,参数同DateField。
FileField:上传文件字段。
ImageField:继承于FileField,对上传的内容进行校验,确保是有效的图片。
选项
通过选项实现对字段的约束,选项如下:
null:如果为True,表示允许为空,默认值是False。
blank:如果为True,则该字段允许为空白,默认值是False。
对比:null是数据库范畴的概念,blank是表单验证证范畴的。
db_column:字段的名称,如果未指定,则使用属性的名称。
db_index:若值为True, 则在表中会为此字段创建索引,默认值是False。
default:默认值。
primary_key:若为True,则该字段会成为模型的主键字段,默认值是False,一般作为AutoField的选项使用。
unique:如果为True, 这个字段在表中必须有唯一值,默认值是False。
查询
查看mysql的日志文件
1) sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf 68 69行
2) sudo service mysql restart 重启mysql服务
3) /var/log/mysql/mysql.log #mysql操作的记录文件。
4) sudo tail -f /var/log/mysql/mysql.log #实时查看mysql文件的内容。
get():返回表中满足条件的一条且只能有一条数据。
如果查到多条数据,则抛异常:MultipleObjectsReturned
查询不到数据,则抛异常:DoesNotExist
例:查询图书id为3的图书信息。
all():返回模型类对应表格中的所有数据。QuerySet类型,查询集
例:查询图书所有信息。
filter():参数写查询条件,返回满足条件的数据。QuerySet
条件格式:
模型类属性名__条件名=值
查询图书评论量为34的图书的信息:
1.判等 exact
例:查询编号为1的图书。
BookInfo.objects.get(id=1)
BookInfo.objects.get(id__exact=1)
2.模糊查询
例:查询书名包含'传'的图书。contains
BookInfo.objects.filter(btitle__contains='传')
例:查询书名以'部'结尾的图书 endswith 开头:startswith
BookInfo.objects.filter(btitle__endswith='部')
3.空查询isnull
select * from booktest_bookinfo where title is not null;
例:查询书名不为空的图书。isnull
BookInfo.objects.filter(btitle__isnull=False)
4.范围查询 in
select * from booktest_bookinfo where id in (1,3,5)
例:查询编号为1或3或5的图书。
BookInfo.objects.filter(id__in = [1,3,5])
5.比较查询
例:查询编号大于3的图书。gt(greate than) lt(less than)小于 gte(equal) lte
BookInfo.objects.filter(id__gt = 3)
6.日期查询
例:查询1980年发表的图书。
BookInfo.objects.filter(bpub_date__year=1980)
例:查询1980年1月1日后发表的图书。
from datetime import date
BookInfo.objects.filter(bpub_date__gt = date(1980,1,1))
exclude:返回不满足条件的数据QuerySet例:查询id不为3的图书信息。
BookInfo.objects.exclude(id=3)
F 对象
作用:用于类属性之间的比较条件。
使用之前需要先导入:
from django.db.models import F
例:查询图书阅读量大于评论量图书信息。
BookInfo.objects.filter(bread__gt = F('bcomment'))
例:查询图书阅读量大于2倍评论量图书信息。
BookInfo.objects.filter(bread__gt = F('bcomment')*2)
Q对象
作用:用于查询时的逻辑条件。not and or,可以对Q对象进行&|~操作。
使用之前需要先导入:
from django.db.models import Q
例:查询id大于3且阅读量大于30的图书的信息。
BookInfo.objects.filter(id__gt=3, bread__gt=30)
BookInfo.objects.filter(Q(id__gt=3)&Q(bread__gt=30))
例:查询id大于3或者阅读量大于30的图书的信息。
BookInfo.objects.filter(Q(id__gt=3)|Q(bread__gt=30))
例:查询id不等于3图书的信息。
BookInfo.objects.filter(~Q(id=3))
order_by QuerySet
作用:进行查询结果进行排序。
例:查询所有图书的信息,按照id从小到大进行排序。
BookInfo.objects.all().order_by('id')
BookInfo.objects.order_by('id')
例:查询所有图书的信息,按照id从大到小进行排序。
BookInfo.objects.all().order_by('-id')
例:把id大于3的图书信息按阅读量从大到小排序显示;
BookInfo.objects.filter(id__gt=3).order_by('-bread')
聚合函数
作用:对查询结果进行聚合操作。
sum count max min avg
aggregate:调用这个函数来使用聚合。 返回值是一个字典
使用前需先导入聚合类
from django.db.models import Sum,Count,Max,Min,Avg
例:查询所有图书的数目。Count
BookInfo.objects.aggregate(Count('id'))
返回值类型:
{'id__count': 5}
例:查询所有图书阅读量的总和。
BookInfo.objects.aggregate(Sum('bread'))
{'bread__sum': 126}
count函数 返回值是一个数字
作用:统计满足条件数据的数目。
例:统计所有图书的数目。
BookInfo.objects.count()
例:统计id大于3的所有图书的数目。
BookInfo.objects.filter(id__gt=3).count()
查询相关函数返回值总结:
get:返回一个对象
all:QuerySet 返回所有数据
filter:QuerySet 返回满足条件的数据
exclude:QuerySet 返回不满条件的数据
order_by:QuerySet 对查询结果进行排序
aggregate:字典 进行聚合操作
count:数字 返回查询集中数据的数目
get,filter,exclude参数中可以写查询条件。
查询集
all, filter, exclude, order_by调用这些函数会产生一个查询集,可以在查询集上继续调用这些函数。
查询集特性:
1) 惰性查询:只有在实际使用查询集中的数据的时候才会发生对数据库的真正查询。
2) 缓存:当使用的是同一个查询集时,第一次的时候会发生实际数据库的查询,然后把结果缓存起来,之后再使用这个查询集时,使用的是缓存中的结果。
限制查询集:
可以对一个查询集进行取下标或者切片操作来限制查询集的结果。
b[0]就是取出查询集的第一条数据,b[0:1].get()也可取出查询集的第一条数据。如果b[0]不存在,会抛出IndexError异常,如果b[0:1].get()不存在,会抛出DoesNotExist异常。多条时抛MultiObjectsReturned
对一个查询集进行切片操作会产生一个新的查询集,下标不允许为负数。
exists:判断一个查询集中是否有数据。True False
模型类关系
1) 一对多关系
例:图书类-英雄类
models.ForeignKey() 定义在多的类中。
2) 多对多关系
例:新闻类-新闻类型类 体育新闻 国际
models.ManyToManyField() 定义在哪个类中都可以。
3) 一对一关系
例:员工基本信息类-员工详细信息类. 员工工号
models.OneToOneField定义在哪个类中都可以。
关联查询(一对多)
在一对多关系中,一对应的类我们把它叫做一类,多对应的那个类我们把它叫做多类,我们把多类中定义的建立关联的类属性叫做关联属性。
例:查询图书id为1的所有英雄的信息。
book = BookInfo.objects.get(id=1)
book.heroinfo_set.all()
通过模型类查询:
HeroInfo.objects.filter(hbook_id=1)
例:查询id为1的英雄所属图书信息。
hero =HeroInfo.objects.get(id=1)
hero.hbook
通过模型类查询:
BookInfo.objects.filter(heroinfo__id=1)
格式:

由一类的对象查询多类的时候:
一类的对象.多类名小写_set.all() #查询所用数据
由多类的对象查询一类的时候:
多类的对象.关联属性 #查询多类的对象对应的一类的对象
由多类的对象查询一类对象的id时候:
多类的对象. 关联属性_id
通过模型类实现关联查询:
例:查询图书信息,要求图书中英雄的描述包含'八'。
BookInfo.objects.filter(heroinfo__hcomment__contains='八')
例:查询图书信息,要求图书中的英雄的id大于3.
BookInfo.objects.filter(heroinfo__id__gt=3)
例:查询书名为“天龙八部”的所有英雄。
HeroInfo.objects.filter(hbook__btitle='天龙八部')
通过多类的条件查询一类的数据:
一类名.objects.filter(多类名小写__多类属性名__条件名)
通过一类的条件查询多类的数据:
多类名.objects.filter(关联属性__一类属性名__条件名)
插入,更新和删除
调用一个模型类对象的save方法的时候就可以实现对模型类对应数据表的插入和更新。
调用一个模型类对象的delete方法的时候就可以实现对模型类对应数据表数据的删除。
自关联

自关联是一种特殊的一对多的关系。
案例:显示广州市的上级地区和下级地区。
地区表:id, title, parenteid;
mysql终端中批量执行sql语句:source areas.sql;
管理器
BookInfo.objects.all()->objects是一个什么东西呢?
答:objects是Django帮我自动生成的管理器对象,通过这个管理器可以实现对数据的查询。
objects是models.Manger类的一个对象。自定义管理器之后Django不再帮我们生成默认的objects管理器。
自定义一个管理器类,这个类继承models.Manger类。
再在具体的模型类里定义一个自定义管理器类的对象。
自定义管理器类的应用场景:
1) 改变查询的结果集。
比如调用BookInfo.books.all()返回的是没有删除的图书的数据。
2) 添加额外的方法。
管理器类中定义一个方法帮我们创建对应的模型类对象。
使用self.model()就可以创建一个跟自定义管理器对应的模型类对象。
元选项
Django默认生成的表名:
应用名小写_模型类名小写。
元选项:
需要在模型类中定义一个元类Meta,在里面定义一个类属性db_table就可以指定表名。
Django_前介的更多相关文章
- Redis_大保健
Redis redis命令参考网址: http://doc.redisfans.com/ redis主从: 集群:一组通过网络连接的计算机,共同对外提供服务,像一个独立的服务器. 一.简介 nosql ...
- linux中sed命令(全面解析)
目录 一:linux中sed命令介绍 1.sed作用 2.sed命令格式 3.参数 4.sed的编辑模式 5.sed参数解析用法 二:sed 参数 -f 案例实战解析 1.前介 2.引入简介 3.方法 ...
- C# 的 Dictionary 寫入前應注意事項
一個已上線.用戶龐大的系統,幾個月來第一次出現這個系統錯誤訊息 : 「已經加入含有相同索引鍵的項目」「已添加了具有相同键的项」An item with the same key has already ...
- Browser 與 Server 持續同步的作法介紹 (Polling, Comet, Long Polling, WebSocket)长连接
對 Comet 的懵懂 記得兩年多前,第一次看到 Gmail 中的 GTalk 覺得很好奇:「咦?線上聊天且是 Google 的熱門系統,只用傳統的 AJAX 應該會操爆伺服器吧?」很幸運的,當時前公 ...
- Linux Kernel 排程機制介紹
http://loda.hala01.com/2011/12/linux-kernel-%E6%8E%92%E7%A8%8B%E6%A9%9F%E5%88%B6%E4%BB%8B%E7%B4%B9/ ...
- PCB成型製程介紹
PCB成型製程在電子構裝中所扮演的角色 下圖是電腦主機的內部組成 我們將以插在主機板上的一片 USB擴充卡來說明PCB成型製 程在電子構裝中所扮演的角色 PCB成型製程的子製程 USB擴充卡要插入主機 ...
- QR Code於台灣各行業的行銷應用案例介紹
當走在東京的大街小巷時,在五花八門的廣告看板.雜誌.護照簽證.海關.宣傳品.廣告.旅遊和導覽手冊.產品包裝.甚至在餐廳菜單上,皆可看到上面有一組黑色神秘二維條碼圖案:QR Code,當看到有興趣的商品 ...
- 用批处理文件删除n天前的文件
原文:http://blog.csdn.net/leehq/archive/2007/08/03/1723743.aspx 公司服务器用来备份数据的硬盘过段时间就会被备份文件占满,弄得我老是要登录到服 ...
- 容器加載Web工程的Web.xml文件介紹
转 容器加載Web工程的Web.xml文件介紹 [-] 这篇文章主要是综合网上关于webxml的一些介绍希望对大家有所帮助也欢迎大家一起讨论 ---题记 一 Webxml详解 一 ...
随机推荐
- wget 403 forbidden
CMD: wget --user-agent="Mozilla" down_url wget -U Mozilla 下载地址 wget -U NoSuchBrowser/1.0 下 ...
- sed -i添加到第一行
用sed的i\命令在第一行前面插入即可,加上 -i 选项直接操作文件. sed -i '1i\要添加的内容' yourfile 查看插入第一行是否成功 sed -n '1,1p' yourfile
- 精选干货 在java中创建kafka
这个详细的教程将帮助你创建一个简单的Kafka生产者,该生产者可将记录发布到Kafka集群. 通过优锐课的java学习架构分享中,在本教程中,我们将创建一个简单的Java示例,该示例创建一个Kafka ...
- Android自定义View——贝塞尔曲线实现水波纹效果
我们使用到的是Path类的quadTo(x1, y1, x2, y2)方法,属于二阶贝塞尔曲线,使用一张图来展示二阶贝塞尔曲线,这里的(x1,y1)是控制点,(x2,y2)是终止点,起始点默认是Pat ...
- Unity 协程运行时的监控和优化
我是快乐的搬运工: http://gulu-dev.com/post/perf_assist/2016-12-20-unity-coroutine-optimizing#toc_0 --------- ...
- Windows添加远程访问用户
Windows远程访问 命令:mstsc ------------------------------------------------------------------------------- ...
- JS-语句二
for循环的4个要素: 1.初始值 2.条件判断 3.状态改变 4.循环体 for循环的写法: for(var i=0;i>10;i++) ...
- KVM以及其虚拟机安装
一.KVM安装 安装:yum -y install kvm python-virtinst libvirt tunctl bridge-utils virt-manager qemu-kvm-tool ...
- 对PHP-GC(垃圾回收)的一点理解
一直对php的垃圾回收机制不明不白故自己开贴记录下. 首先,说到垃圾回收,得先知道什么情况下才能产生垃圾. 如果一个变量refcount在增加,说明在被使用,不是垃圾. 如果一个变量的refcount ...
- Swagger注解及参数细节的正确书写。
今天新开了一个api文件,结果怎么搞也在swagger里显示不出来,浪费半天后,去问老员工了. 一般有俩原因, 1.idea缓存,重启idea即可. 2.注解和参数上的修饰有问题,或者请求method ...