nodejs实现定时爬取微博热搜
The summer is coming
”
我知道,那些夏天,就像青春一样回不来。 - 宋冬野
青春是回不来了,倒是要准备渡过在西安的第三个夏天了。
废话
我发现,自己对 coding 这件事的称呼,从敲代码 改为 写代码 了。
emmm....敲代码,自我感觉,就像是,习惯了用 const 定义常量的我看到别人用 var 定义的常量。
对,优雅!
写代码 这三个字,显得更为优雅一些,更像是在创作,打磨一件精致的作品。
改编自 掘金站长 的一句话:
”
子非猿,安之 coding 之乐也。
看完本文的收获
ctrl + c ctrl + v nodejs 入门级爬虫
为何写爬虫相关的文章
最近访问 艾特网 的时候发现请求有点慢。
后来经过一番检查,发现首页中搜索热点需要每次去爬取百度热搜的数据并当做接口返回给前端,由于是服务端渲染,接口堵塞就容易出现访问较慢的情况。
就想着对这个接口进行一次重构。
解决方案
设置定时任务,每隔 1分钟/3分钟/5分钟爬取新浪微博实时热搜(新浪微博热搜点击率更高一些)爬取到数据后不直接返回给前端,先写入一个 .json格式的文件。服务端渲染的后台接口请求并返回给前端 json文件的内容
需求捋清楚以后就可以开干了。
创建工程
初始化
首先得找到目标站点,如下:(微博实时热搜)
https://s.weibo.com/top/summary?cate=realtimehot
创建文件夹 weibo
进入文件夹根目录
使用 npm init -y 快速初始化一个项目
安装依赖
创建app.js文件
安装以下依赖
npm i cherrio superagent -D
关于superagent和cherrio的介绍
”
superagent 是一个轻量级、渐进式的请求库,内部依赖 nodejs 原生的请求 api,适用于 nodejs 环境。
”
cherrio 是 nodejs 的抓取页面模块,为服务器特别定制的,快速、灵活、实施的 jQuery 核心实现。适合各种 Web 爬虫程序。node.js 版的 jQuery。
代码编写
打开 app.js ,开始完成主要功能
首先在顶部引入cheerio 、superagent 以及 nodejs 中的 fs 模块
const cheerio = require("cheerio");
const superagent = require("superagent");
const fs = require("fs");
通过变量的方式声明热搜的url,便于后面 复用
const weiboURL = "https://s.weibo.com";
const hotSearchURL = weiboURL + "/top/summary?cate=realtimehot";
superagent
使用 superagent 发送get请求
superagent 的 get 方法接收两个参数。第一个是请求的 url 地址,第二个是请求成功后的回调函数。
回调函数有俩参数,第一个参数为 error ,如果请求成功,则返回 null,反之则抛出错误。第二个参数是请求成功后的 响应体
superagent.get(hotSearchURL, (err, res) => {
if (err) console.error(err);
});
网页元素分析
打开目标站对网页中的 DOM 元素进行一波分析。

对 jQuery 比较熟的小老弟,看到下图如此简洁清晰明了的 DOM 结构,是不是有 N 种取出它每个 tr 中的数据并 push 到一个 Array 里的方法呢?
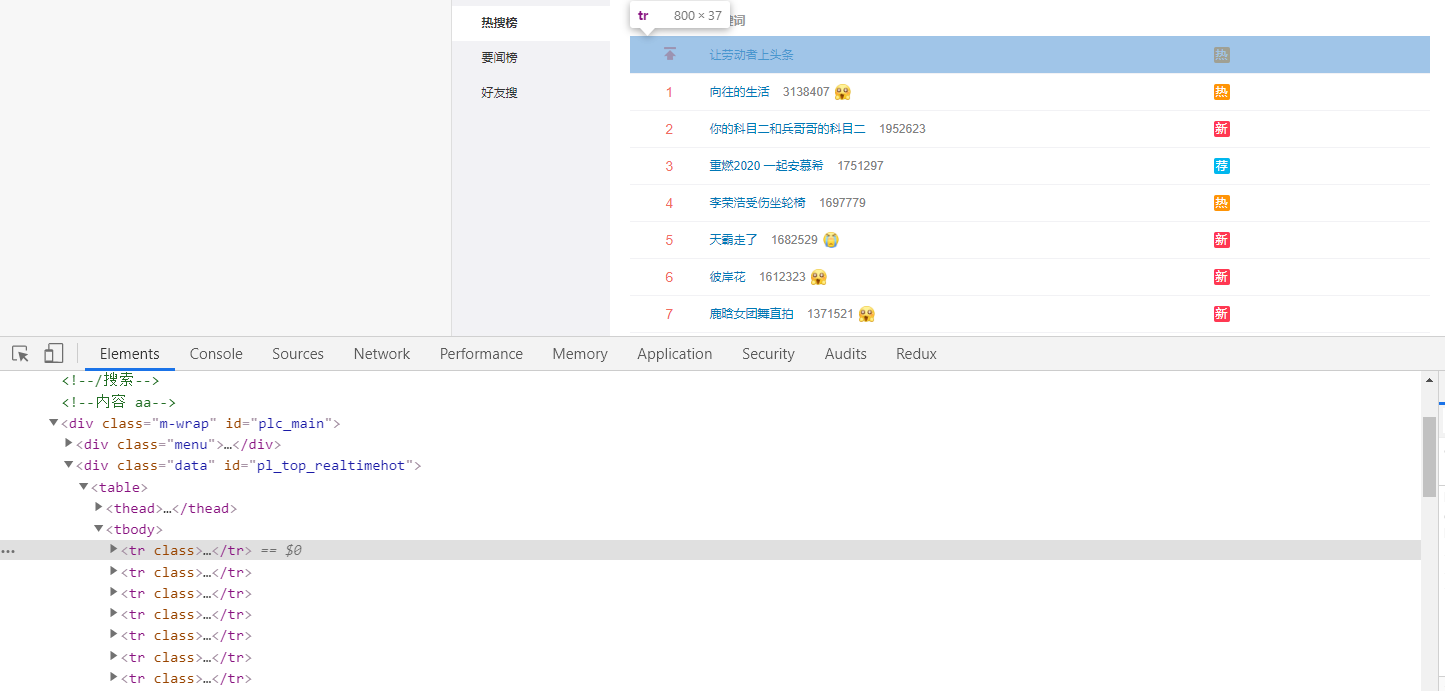
对!我们最终的目的就是要通过 jQuery 的语法,遍历每个 tr ,并将其每一项的 热搜地址 、热搜内容 、 热度值 、序号 、表情等信息 push 进一个空数组中
再将它通过 nodejs 的 fs 模块,写入一个 json 文件中。

jQuery 遍历拿出数据
使用 jQuery 的 each 方法,对 tbody 中的每一项 tr 进行遍历,回调参数中第一个参数为遍历的下标 index,第二个参数为当前遍历的元素,一般 $(this) 指向的就是当前遍历的元素。
let hotList = [];
$("#pl_top_realtimehot table tbody tr").each(function (index) {
if (index !== 0) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $td.find("span").text();
const icon = $td.find("img").attr("src")
? "https:" + $td.find("img").attr("src")
: "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
cheerio 包装请求后的响应体
在 nodejs 中,要想向上面那样愉快的写 jQuery 语法,还得将请求成功后返回的响应体,用 cheerio 的 load 方法进行包装。
const $ = cheerio.load(res.text);
写入 json 文件
接着使用 nodejs 的 fs 模块,将创建好的数组转成 json字符串,最后写入当前文件目录下的 hotSearch.json 文件中(无此文件则会自动创建)。
fs.writeFileSync(
`${__dirname}/hotSearch.json`,
JSON.stringify(hotList),
"utf-8"
);
完整代码如下:
const cheerio = require("cheerio");
const superagent = require("superagent");
const fs = require("fs");
const weiboURL = "https://s.weibo.com";
const hotSearchURL = weiboURL + "/top/summary?cate=realtimehot";
superagent.get(hotSearchURL, (err, res) => {
if (err) console.error(err);
const $ = cheerio.load(res.text);
let hotList = [];
$("#pl_top_realtimehot table tbody tr").each(function (index) {
if (index !== 0) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $td.find("span").text();
const icon = $td.find("img").attr("src")
? "https:" + $td.find("img").attr("src")
: "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
fs.writeFileSync(
`${__dirname}/hotSearch.json`,
JSON.stringify(hotList),
"utf-8"
);
});
打开终端,输入 node app,可看到根目录下多了个 hotSearch.json 文件。
定时爬取
虽然代码可以运行,也能爬取到数据并存入 json 文件。
但是,每次都要手动运行,才能爬取到当前时间段的热搜数据,这一点都 不人性化!
最近微博热搜瓜这么多,咱可是一秒钟可都不能耽搁。我们最开始期望的是每隔多长时间 定时执行爬取 操作。瓜可不能停!

接下来,对代码进行 小部分改造。
数据请求封装
由于 superagent 请求是个异步方法,我们可以将整个请求方法用 Promise 封装起来,然后 每隔指定时间 调用此方法即可。
function getHotSearchList() {
return new Promise((resolve, reject) => {
superagent.get(hotSearchURL, (err, res) => {
if (err) reject("request error");
const $ = cheerio.load(res.text);
let hotList = [];
$("#pl_top_realtimehot table tbody tr").each(function (index) {
if (index !== 0) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $td.find("span").text();
const icon = $td.find("img").attr("src")
? "https:" + $td.find("img").attr("src")
: "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
hotList.length ? resolve(hotList) : reject("errer");
});
});
}
node-schedule 详解
定时任务我们可以使用 node-schedule 这个 nodejs库 来完成。
https://github.com/node-schedule/node-schedule
先安装
npm i node-schedule -D
头部引入
const nodeSchedule = require("node-schedule");
用法(每分钟的第 30 秒定时执行一次):
const rule = "30 * * * * *";
schedule.scheduleJob(rule, () => {
console.log(new Date());
});
规则参数:
* * * * * *
┬ ┬ ┬ ┬ ┬ ┬
│ │ │ │ │ │
│ │ │ │ │ └ day of week (0 - 7) (0 or 7 is Sun)
│ │ │ │ └───── month (1 - 12)
│ │ │ └────────── day of month (1 - 31)
│ │ └─────────────── hour (0 - 23)
│ └──────────────────── minute (0 - 59)
└───────────────────────── second (0 - 59, OPTIONAL)
6 个占位符从左到右依次代表:秒、分、时、日、月、周几
* 表示通配符,匹配任意。当 * 为秒时,表示任意秒都会触发,其他类推。
来看一个 每小时的第20分钟20秒 定时执行的规则:
20 20 * * * *
更多规则自行搭配。
定时爬取,写入文件
使用定时任务来执行上面的请求数据,写入文件操作:
nodeSchedule.scheduleJob("30 * * * * *", async function () {
try {
const hotList = await getHotSearchList();
await fs.writeFileSync(
`${__dirname}/hotSearch.json`,
JSON.stringify(hotList),
"utf-8"
);
} catch (error) {
console.error(error);
}
});
哦对,别忘了 捕获异常
下面贴上完整代码(可直接 ctrl c/v):
const cheerio = require("cheerio");
const superagent = require("superagent");
const fs = require("fs");
const nodeSchedule = require("node-schedule");
const weiboURL = "https://s.weibo.com";
const hotSearchURL = weiboURL + "/top/summary?cate=realtimehot";
function getHotSearchList() {
return new Promise((resolve, reject) => {
superagent.get(hotSearchURL, (err, res) => {
if (err) reject("request error");
const $ = cheerio.load(res.text);
let hotList = [];
$("#pl_top_realtimehot table tbody tr").each(function (index) {
if (index !== 0) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $td.find("span").text();
const icon = $td.find("img").attr("src")
? "https:" + $td.find("img").attr("src")
: "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
hotList.length ? resolve(hotList) : reject("errer");
});
});
}
nodeSchedule.scheduleJob("30 * * * * *", async function () {
try {
const hotList = await getHotSearchList();
await fs.writeFileSync(
`${__dirname}/hotSearch.json`,
JSON.stringify(hotList),
"utf-8"
);
} catch (error) {
console.error(error);
}
});
各种玩法
以上代码可直接集成进现有的
expresskoaeggjs或者原生的 nodejs 项目中,作为接口返回给前端。集成进 Serverless,作为接口返回给前端。
对接微信公众号,发送
热搜关键字即可实时获取热搜数据。集成进 微信机器人 ,每天在指定的时间给自己/群里发送微博热搜数据。
other......
都看到这里啦,就很棒! 点个赞 再走嘛。
程序员导航站:https://iiter.cn
下面是咱的公众号呀 前端糖果屋

代码 github 已开源:
https://github.com/isnl/weibo-hotSearch-crawler
nodejs实现定时爬取微博热搜的更多相关文章
- Python网络爬虫-爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url=https://s.weibo.com/top/summary?Refer=top_hot&topnav=1& ...
- BeautifulSoup爬取微博热搜榜
获取url 设定请求头 requests发出get请求 实例化BeautifulSoup对象 BeautifulSoup提取数据 import requests 2 from bs4 import B ...
- Python爬取微博热搜以及链接
基本操作,不再详述 直接贴源码(根据当前时间创建文件): import requests from bs4 import BeautifulSoup import time def input_to_ ...
- 【网络爬虫】【java】微博爬虫(一):小试牛刀——网易微博爬虫(自定义关键字爬取微博数据)(附软件源码)
一.写在前面 (本专栏分为"java版微博爬虫"和"python版网络爬虫"两个项目,系列里所有文章将基于这两个项目讲解,项目完整源码已经整理到我的Github ...
- 2020不平凡的90天,Python分析三个月微博热搜数据带你回顾
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:刘早起早起 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 第一个nodejs爬虫:爬取豆瓣电影图片
第一个nodejs爬虫:爬取豆瓣电影图片存入本地: 首先在命令行下 npm install request cheerio express -save; 代码: var http = require( ...
- python3爬取微博评论并存为xlsx
python3爬取微博评论并存为xlsx**由于微博电脑端的网页版页面比较复杂,我们可以访问手机端的微博网站,网址为:https://m.weibo.cn/一.访问微博网站,找到热门推荐链接我们打开微 ...
- C#爬取微博文字、图片、视频(不使用Cookie)
前两天在网上偶然看到一个大佬OmegaXYZ写的文章,Python爬取微博文字与图片(不使用Cookie) 于是就心血来潮,顺手撸一个C#版本的. 其实原理也很简单,现在网上大多数版本都需要Cooki ...
- 纯前端实现词云展示+附微博热搜词云Demo代码
前言 最近工作中做了几个数据可视化大屏项目,其中也有用到了词云展示,以前做词云都是用python库来生成图片显示的,这次用了纯前端的实现(Ctrl+V真好用),同时顺手做个微博热搜的词云然后记录一下~ ...
随机推荐
- dis反汇编查看实现
dis库是python(默认的CPython)自带的一个库,可以用来分析字节码 >>> import dis >>> def add(a, b = 0): ... ...
- wifi无线桥接
考虑到不同路由器配置上或许有细微差别,我此处路由器是水星(牌子)路由器. 首先需要2台路由器,一台已经能够上网,作为主路由器:另一台啥都没有配置,将来用作副路由器,与主路由器桥接. 步骤: 获取主路由 ...
- java 根据图片文字动态生成图片
今天在做热敏打印机打印二维码,并有文字描述,想到的简单的方法就是根据热敏打印机的纸张宽度和高度,生成对应的图片,如下: package com.orisdom.utils; import lombok ...
- ceph概述
ceph概述 基础知识 什么是分布式文件系统 • ...
- C语言 文件操作(三)
1.fputs() int fputs(const char *s, FILE *stream); s 代表要输出的字符串的首地址,可以是字符数组名或字符指针变量名. stream 表示向何种流中输出 ...
- flask 入门之 logging
如想看详细说明,请到: 1.https://www.cnblogs.com/yyds/p/6901864.html 2.https://docs.python.org/2/library/loggin ...
- android所有颜色
<?xml version="1.0" encoding="utf-8" ?> <resources> <color name=& ...
- java集合中的一个移除数据陷阱(遍历集合自身并同时删除被遍历数据)
下面是网上的其他解释,更能从本质上解释原因:Iterator 是工作在一个独立的线程中,并且拥有一个 mutex 锁. Iterator 被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量 ...
- File类心得
File类心得 在程序中设置路径时会有系统依赖的问题,java.io.File类提供一个抽象的.与系统独立的路径表示.给它一个路径字符串,它会将其转换为与系统无关的抽象路径表示,这个路径可以指向一个文 ...
- AJ学IOS 之UIDynamic重力、弹性碰撞吸附等现象
AJ分享,必须精品 一:效果 重力和碰撞 吸附现象 二:简介 什么是UIDynamic UIDynamic是从iOS 7开始引入的一种新技术,隶属于UIKit框架 可以认为是一种物理引擎,能模拟和仿真 ...