Kubernetes 中 搭建 EFK 日志搜索中心
简介
Elastic 官方已经发布了Elasticsearch Operator ,简化了 elasticsearch 以及 kibana的部署与升级,结合 fluentd-kubernetes-daemonset,现在在kubernetes 部署 EFK 已经非常方便。
部署 Elasticsearch Operator 和 一些必要的资源
这个yaml 文件比较大 我放了个链接,我这里主要修改了 namespace
kubectl apply -f https://download.elastic.co/downloads/eck/1.1.2/all-in-one.yaml
部署 Elasticsearch 集群
先创建几个 PersistentVolume StorageClass,我这里用的是localpv,我会部署3个data节点 所以创建三个pv,默认 elastic 用户 的密码是自动生成的 可以到 secrect 中查看,这个secret 名字以 elastic-user 结尾,用base64 解压就行。
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage-es-test
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: es-test-pv-
namespace: efk
spec:
capacity:
storage: 100G
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage-es-test
local:
path: /data/elasticsearch-test
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-node-
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: es-test-pv-
namespace: efk
spec:
capacity:
storage: 100G
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage-es-test
local:
path: /data/elasticsearch-test
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-node-
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: es-test-pv-
namespace: efk
spec:
capacity:
storage: 100G
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage-es-test
local:
path: /data/elasticsearch-test
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-node-
---
然后创建es集群,文件里对不好理解的我写了注释
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: cluster-test
namespace: efk
spec:
version: 7.3.
http:
tls:
selfSignedCertificate:
## 取消默认的tls
disabled: true
nodeSets:
## master 节点 名称
- name: master
count:
podTemplate:
spec:
volumes:
- name: elasticsearch-data
emptyDir: {}
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
containers:
- name: elasticsearch
readinessProbe:
exec:
command:
- bash
- -c
- /mnt/elastic-internal/scripts/readiness-probe-script.sh
failureThreshold:
initialDelaySeconds:
periodSeconds:
successThreshold:
timeoutSeconds:
env:
## jvm 内存
- name: ES_JAVA_OPTS
value: -Xms1g -Xmx1g
- name: READINESS_PROBE_TIMEOUT
value: ""
resources:
requests:
cpu: 100m
limits:
cpu: 1000m
config:
## 是不是master节点 ,节点这里可以看文档,一个节点既可以是master 也可以是 data
node.master: "true"
node.data: "false"
node.ingest: "false"
- name: data
count:
volumeClaimTemplates:
- metadata:
name: elasticsearch-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100G
## 我定义的 sc
storageClassName: local-storage-es-test
podTemplate:
spec:
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
- name: increase-fd-ulimit
securityContext:
privileged: true
command: ["sh", "-c", "ulimit -n 65536"]
containers:
- name: elasticsearch
readinessProbe:
exec:
command:
- bash
- -c
- /mnt/elastic-internal/scripts/readiness-probe-script.sh
failureThreshold:
initialDelaySeconds:
periodSeconds:
successThreshold:
timeoutSeconds:
env:
- name: ES_JAVA_OPTS
value: -Xms1g -Xmx1g
- name: READINESS_PROBE_TIMEOUT
value: ""
resources:
requests:
cpu: 100m
limits:
cpu: 1000m
config:
node.master: "false"
node.data: "true"
node.ingest: "true"
部署 Kibana 与 ingress
这里我主要设置了 Kinana Prefix 访问路径
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: kibana-test
namespace: efk
spec:
version: 7.3.
http:
tls:
selfSignedCertificate:
disabled: true
count:
elasticsearchRef:
name: cluster-test
podTemplate:
spec:
containers:
- name: kibana
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: SERVER_BASEPATH
value: "/kibana-test"
- name: SERVER_REWRITEBASEPATH
value: 'true'
readinessProbe:
failureThreshold:
httpGet:
path: /kibana-test/login
port:
scheme: HTTP
initialDelaySeconds:
periodSeconds:
successThreshold:
timeoutSeconds: ---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-kibana-test
namespace: efk
annotations:
# use the shared ingress-nginx
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: ks.***.cn
http:
paths:
- path: /kibana-test
backend:
serviceName: kibana-test-kb-http
servicePort:
部署 Fluentd
这里贴一下 kubernetes_metadata 使用部分的源码,默认支持几个kubernetes_metadata的配置,所有配置看文档,这是一个 fluentd filter ,这个细节也可以不看。
<filter kubernetes.**>
@type kubernetes_metadata
@id filter_kube_metadata
kubernetes_url "#{ENV['FLUENT_FILTER_KUBERNETES_URL'] || 'https://' + ENV.fetch('KUBERNETES_SERVICE_HOST') + ':' + ENV.fetch('KUBERNETES_SERVICE_PORT') + '/api'}"
verify_ssl "#{ENV['KUBERNETES_VERIFY_SSL'] || true}"
ca_file "#{ENV['KUBERNETES_CA_FILE']}"
skip_labels "#{ENV['FLUENT_KUBERNETES_METADATA_SKIP_LABELS'] || 'false'}"
skip_container_metadata "#{ENV['FLUENT_KUBERNETES_METADATA_SKIP_CONTAINER_METADATA'] || 'false'}"
skip_master_url "#{ENV['FLUENT_KUBERNETES_METADATA_SKIP_MASTER_URL'] || 'false'}"
skip_namespace_metadata "#{ENV['FLUENT_KUBERNETES_METADATA_SKIP_NAMESPACE_METADATA'] || 'false'}"
</filter>
这里贴一下 kubernetes 日志 tail input 使用部分的源码,默认路径为 /var/log/containers/*.log ,这里需要注意一些 fluentd pod volumes 的配置,保证在pod内 可以拿得到日志文件 。
<source>
@type tail
@id in_tail_container_logs
path /var/log/containers/*.log
pos_file /var/log/fluentd-containers.log.pos
tag "#{ENV['FLUENT_CONTAINER_TAIL_TAG'] || 'kubernetes.*'}"
exclude_path "#{ENV['FLUENT_CONTAINER_TAIL_EXCLUDE_PATH'] || use_default}"
read_from_head true
<parse>
@type "#{ENV['FLUENT_CONTAINER_TAIL_PARSER_TYPE'] || 'json'}"
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
这里是 fluentd DaemonSet 的配置 由于我的 docker 主目录在 /Data/docker 下 ,而且/var/log/ 下的文件只是一个链接 ,所以 我特意加了一个 volume ,总之要保证获取到文件。还有 es 的账号密码 我建议自己创一个,因为默认生成的elastic 用户密码是随机的(我之前创建集群的时候还不能自定义初始用户密码,我写这篇文章的时候没有特意去查,因为对我来说这点不是特别重要)。
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: efk
labels:
app: fluentd
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: efk
---
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-test
namespace: efk
labels:
app: fluentd-test
spec:
selector:
matchLabels:
app: fluentd-test
template:
metadata:
labels:
app: fluentd-test
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.11.0-debian-elasticsearch7-1.0
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "cluster-test-es-http.efk.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_USER
value: "admin"
- name: FLUENT_ELASTICSEARCH_PASSWORD
value: ""
- name: FLUENT_ELASTICSEARCH_PORT
value: ""
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
- name: FLUENT_KUBERNETES_METADATA_SKIP_CONTAINER_METADATA
value: 'true'
- name: FLUENT_KUBERNETES_METADATA_SKIP_MASTER_URL
value: 'true'
- name: FLUENT_KUBERNETES_METADATA_SKIP_NAMESPACE_METADATA
value: 'true'
- name: FLUENT_KUBERNETES_METADATA_SKIP_LABELS
value: 'true'
- name: FLUENT_ELASTICSEARCH_INCLUDE_TIMESTAMP
value: 'true'
- name: K8S_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/log/containers
readOnly: true
- name: varlibdockercontainers-kube-path
mountPath: /var/log/pods
readOnly: true
- name: varlibdockercontainers-real-path
mountPath: /data/docker/containers
readOnly: true
terminationGracePeriodSeconds:
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/log/containers
- name: varlibdockercontainers-kube-path
hostPath:
path: /var/log/pods
- name: varlibdockercontainers-real-path
hostPath:
path: /data/docker/containers
查看日志
进入 kibana ,查看 所有 index 可以看到以下界面
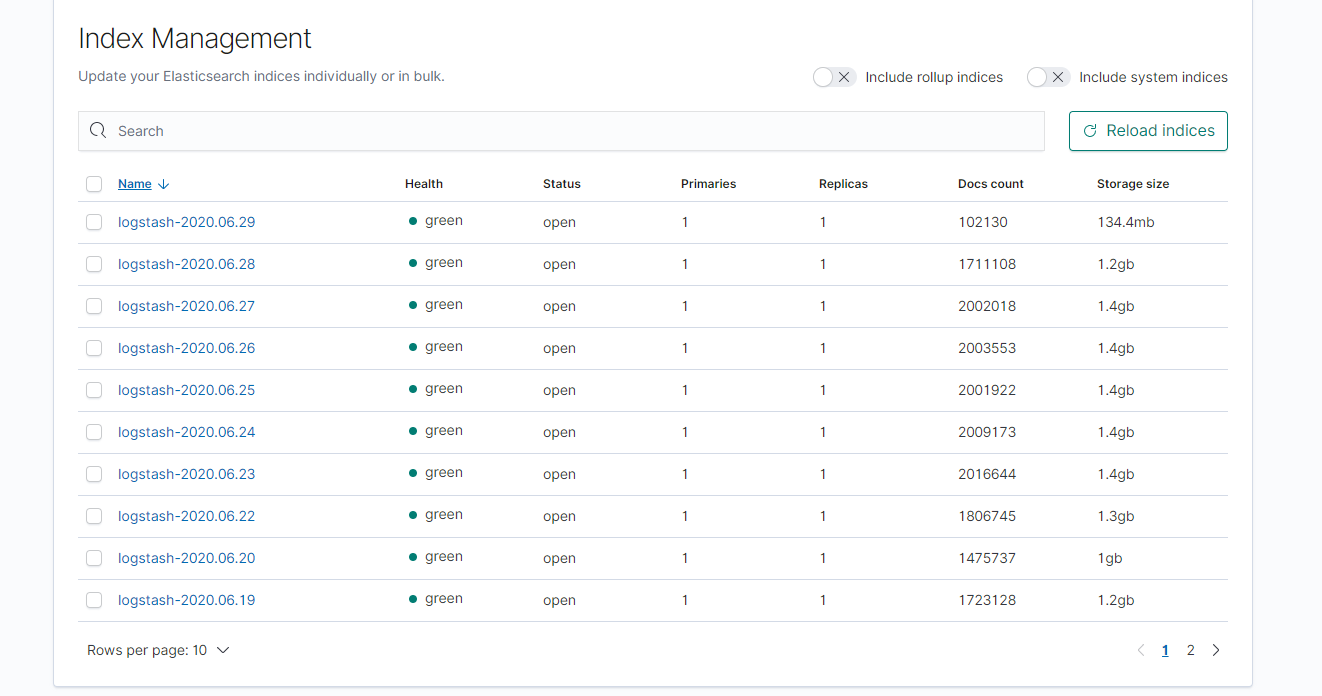
这个名字什么的是可以改的,贴源码
<match **>
@type elasticsearch
@id out_es
@log_level info
include_tag_key true
host "#{ENV['FLUENT_ELASTICSEARCH_HOST']}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT']}"
path "#{ENV['FLUENT_ELASTICSEARCH_PATH']}"
scheme "#{ENV['FLUENT_ELASTICSEARCH_SCHEME'] || 'http'}"
ssl_verify "#{ENV['FLUENT_ELASTICSEARCH_SSL_VERIFY'] || 'true'}"
ssl_version "#{ENV['FLUENT_ELASTICSEARCH_SSL_VERSION'] || 'TLSv1_2'}"
user "#{ENV['FLUENT_ELASTICSEARCH_USER'] || use_default}"
password "#{ENV['FLUENT_ELASTICSEARCH_PASSWORD'] || use_default}"
reload_connections "#{ENV['FLUENT_ELASTICSEARCH_RELOAD_CONNECTIONS'] || 'false'}"
reconnect_on_error "#{ENV['FLUENT_ELASTICSEARCH_RECONNECT_ON_ERROR'] || 'true'}"
reload_on_failure "#{ENV['FLUENT_ELASTICSEARCH_RELOAD_ON_FAILURE'] || 'true'}"
log_es_400_reason "#{ENV['FLUENT_ELASTICSEARCH_LOG_ES_400_REASON'] || 'false'}"
logstash_prefix "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_PREFIX'] || 'logstash'}"
logstash_dateformat "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_DATEFORMAT'] || '%Y.%m.%d'}"
logstash_format "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_FORMAT'] || 'true'}"
index_name "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_INDEX_NAME'] || 'logstash'}"
type_name "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_TYPE_NAME'] || 'fluentd'}"
include_timestamp "#{ENV['FLUENT_ELASTICSEARCH_INCLUDE_TIMESTAMP'] || 'false'}"
template_name "#{ENV['FLUENT_ELASTICSEARCH_TEMPLATE_NAME'] || use_nil}"
template_file "#{ENV['FLUENT_ELASTICSEARCH_TEMPLATE_FILE'] || use_nil}"
template_overwrite "#{ENV['FLUENT_ELASTICSEARCH_TEMPLATE_OVERWRITE'] || use_default}"
sniffer_class_name "#{ENV['FLUENT_SNIFFER_CLASS_NAME'] || 'Fluent::Plugin::ElasticsearchSimpleSniffer'}"
request_timeout "#{ENV['FLUENT_ELASTICSEARCH_REQUEST_TIMEOUT'] || '5s'}"
<buffer>
flush_thread_count "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_FLUSH_THREAD_COUNT'] || '8'}"
flush_interval "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_FLUSH_INTERVAL'] || '5s'}"
chunk_limit_size "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_CHUNK_LIMIT_SIZE'] || '2M'}"
queue_limit_length "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_QUEUE_LIMIT_LENGTH'] || '32'}"
retry_max_interval "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_RETRY_MAX_INTERVAL'] || '30'}"
retry_forever true
</buffer>
</match>
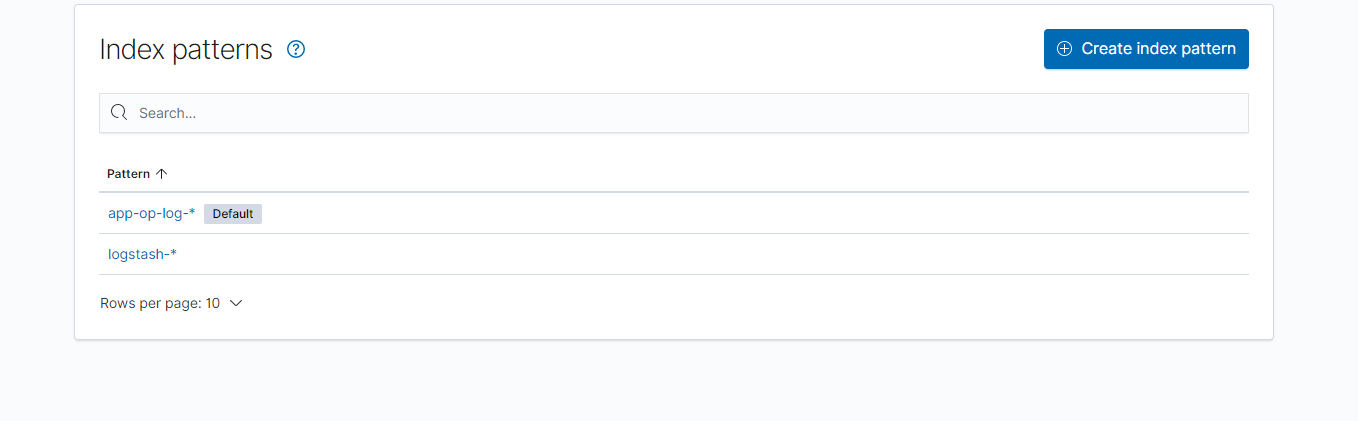
创建 Index patterns。
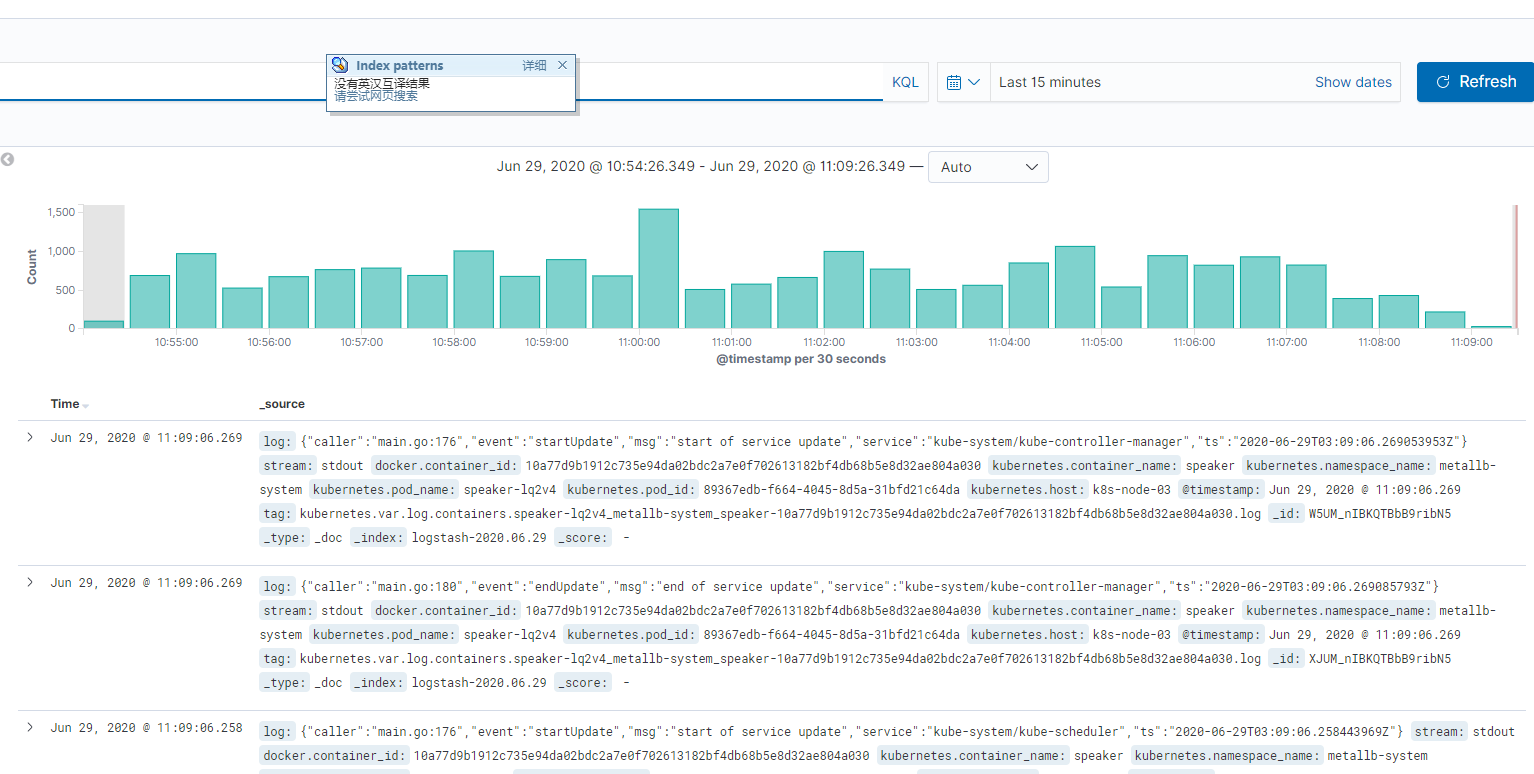
然后就可以查看了
Kubernetes 中 搭建 EFK 日志搜索中心的更多相关文章
- kubernetes集群EFK日志系统搭建
日志收集架构 Kubernetes 集群本身不提供日志收集的解决方案,一般来说有主要的3种方案来做日志收集: 在节点上运行一个 agent 来收集日志 在 Pod 中包含一个 sidecar 容器来收 ...
- centos7搭建EFK日志分析系统
前言 EFK可能都不熟悉,实际上EFK是大名鼎鼎的日志系统ELK的一个变种 在没有分布式日志的时候,每次出问题了需要查询日志的时候,需要登录到Linux服务器,使用命令cat -n xxxx|grep ...
- Kubernetes 系列(八):搭建EFK日志收集系统
Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch.Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案. Elasticsearch 是一个 ...
- Kubernetes 日志:搭建 EFK 日志系统
Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch.Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案. Elasticsearch 是一个 ...
- 十九,基于helm搭建EFK日志收集系统
目录 EFK日志系统 一,EFK日志系统简介: 二,EFK系统部署 1,EFK系统部署方式 2,基于Helm方式部署EFK EFK日志系统 一,EFK日志系统简介: 关于系统日志收集处理方案,其实有很 ...
- Docker搭建EFK日志收集系统,并自定义es索引名
EFK架构图 一.EFK简介 EFK不是一个软件,而是一套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前主流的一种日志系统. EFK是三个开源软件的缩写,分 ...
- k8s集群搭建EFK日志平台:ElasticSearch + Fluentd + Kibana
k8s集群 kubectl get node EFK简介 ElasticSearch:分布式存储检索引擎,用来搜索.存储日志 Fluentd:日志采集 Kibana:读取es中数据进行可视化web界面 ...
- 在kubernetes中搭建harbor,并利用MinIO对象存储保存镜像文件
前言:此文档是用来在线下环境harbor利用MinIO做镜像存储的,至于那些说OSS不香吗?或者单机harbor的,不用看了.此文档对你没啥用,如果是采用单机的harbor连接集群MinIO,请看我的 ...
- k8s-搭建 EFK 日志系统
搭建 EFK 日志系统 大家介绍了 Kubernetes 集群中的几种日志收集方案,Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch.Fluentd 和 Kibana( ...
随机推荐
- 题解 P5329 【[SNOI2019]字符串】
用栈的做法来水一发. 首先我们有一个暴力的做法,枚举每个被删除的字符,然后排序输出,时间复杂度:$ O ( N \times N \times LogN ) $ . 然后我们观察一下数据,发现有一个数 ...
- Java实现 蓝桥杯VIP 算法提高 解二元一次方程组
算法提高 解二元一次方程组 时间限制:1.0s 内存限制:256.0MB 问题描述 给定一个二元一次方程组,形如: a * x + b * y = c; d * x + e * y = f; x,y代 ...
- 点击 button 自动刷新页面
问题:为什么点击 button 会刷新页面 ? 原因:你代码的写法可能如下图,把 <button> 按钮 写在 <form> </form> 标签里边啦. < ...
- 设计模式系列之建造者模式(Builder Pattern)——复杂对象的组装与创建
说明:设计模式系列文章是读刘伟所著<设计模式的艺术之道(软件开发人员内功修炼之道)>一书的阅读笔记.个人感觉这本书讲的不错,有兴趣推荐读一读.详细内容也可以看看此书作者的博客https:/ ...
- Java线程变量问题-ThreadLocal
关于Java线程问题,在博客上看到一篇文章挺好的: https://blog.csdn.net/w172087242/article/details/83375022#23_ThreadLocal_1 ...
- Vue入门 — Vue + vuetifyjs应用实践
分享一个以前学vue时自己练手的一个小项目,项目使用vue-cli3创建,UI库用的是vuetifyjs,vuetifyjs官网:https://vuetifyjs.com/ 数据来源是网上随便找的一 ...
- C#数据结构与算法系列(二):稀疏数组(SparseArray)
1.介绍 当一个数组中大部分元素为0,或者为同一个值的数组时,可以使用稀疏数组来保存该数组. 稀疏数组的处理方法是: 1.记录数组一共有几行几列,有多少个不同的值 2.把具有不同值的元素的 ...
- 跟着视频学python,Day1
python介绍 发展史 安装 Hello World程序 变量 用户输入 模块初识 数据类型初识 条件表达式if...elif...else 循环表达式while 循环表达式for python介绍 ...
- 用python复制文件夹
用python复制文件 1. 根据文件夹的名称复制 需要复制的文件夹编号文件中,每一行表示一个编号,如下所示: > cat id.txt 1 2 3 ... > 目标文件的目录结构树如下所 ...
- mysql字符串类型(枚举类型)
原文链接:https://blog.csdn.net/qq_34530405/article/details/81738907 本文记录MySql数据库中enum类型数据的使用细节和注意事项. 首先在 ...