java并发编程 --并发问题的根源及主要解决方法
并发问题的根源在哪
首先,我们要知道并发要解决的是什么问题?并发要解决的是单进程情况下硬件资源无法充分利用的问题。而造成这一问题的主要原因是CPU-内存-磁盘三者之间速度差异实在太大。如果将CPU的速度比作火箭的速度,那么内存的速度就像火车,而最惨的磁盘,基本上就相当于人双腿走路。
这样造成的一个问题,就是CPU快速执行完它的任务的时候,很长时间都会在等待磁盘或是内存的读写。
计算机的发展有一部分就是如何重复利用资源,解决硬件资源之间效率的不平衡,而后就有了多进程,多线程的发展。并且演化出了各种为多进程(线程)服务的东西:
- CPU增加缓存机制,平衡与内存的速度差异
- 增加了多个概念,CPU时间片,程序计数器,线程切换等,用以更好得服务并发场景
- 编译器的指令优化,希望在内部充分利用硬件资源
但是这样一来,也会带来新的并发问题,归结起来主要有三个。
- 由于缓存导致的可见性问题
- 线程切换带来的原子性问题
- 编译器优化带来的有序性问题
我们分别介绍这几个:
缓存导致的可见性
CPU为了平衡与内存之间的性能差异,引入了CPU缓存,这样CPU执行指令修改数据的时候就可以批量直接读写CPU缓存的内存,一个阶段后再将数据写回到内存。
但由于现在多核CPU技术的发展,各个线程可能运行在不同CPU核上面,每个CPU核各有各自的CPU缓存。前面说到对变量的修改通常都会先写入CPU缓存,再写回内存。这就会出现这样一种情况,线程1修改了变量A,但此时修改后的变量A只存储在CPU缓存中。这时候线程B去内存中读取变量A,依旧只读取到旧的值,这就是可见性问题。
线程切换带来的原子性
为了更充分得利用CPU,引入了CPU时间片时间片的概念。进程或线程通过争用CPU时间片,让CPU可以更加充分得利用。
比如在进行读写磁盘等耗时高的任务时,就可以将宝贵的CPU资源让出来让其他线程去获取CPU并执行任务。
但这样的切换也会导致问题,那就是会破坏线程某些任务的原子性。比如java中简单的一条语句count += 1。
映射到CPU指令有三条,读取count变量指令,变量加1指令,变量写回指令。虽然在高级语言(java)看来它就是一条指令,但实际上确是三条CPU指令,并且这三条指令的原子性无法保证。也就是说,可能在执行到任意一条指令的时候被打断,CPU被其他线程抢占了。而这个期间变量值可能会被修改,这里就会引发数据不一致的情况了。所以高并发场景下,很多时候都会通过锁实现原子性。而这个问题也是很多并发问题的源头。
编译器优化带来的有序性
因为现在程序员编写的都是高级语言,编译器需要将用户的代码转成CPU可以执行的指令。
同时,由于计算机领域的不断发展,编译器也越来越智能,它会自动对程序员编写的代码进行优化,而优化中就有可能出现实际执行代码顺序和编写的代码顺序不一样的情况。
而这种破坏程序有序性的行为,在有些时候会出现一些非常微妙且难以察觉的并发编程bug。
举个简单的例子,我们常见的单例模式是这样的:
public class Singleton {
private Singleton() {}
private static Singleton sInstance;
public static Singleton getInstance() {
if (sInstance == null) { //第一次验证是否为null
synchronized (Singleton.class) { //加锁
if (sInstance == null) { //第二次验证是否为null
sInstance = new Singleton(); //创建对象
}
}
}
return sInstance;
}
}
即通过两段判断加锁来保证单例的成功生成,但在极小的概率下,可能会出现异常情况。原因就出现在sInstance = new Singleton();这一行代码上。这行代码,我们理解的执行顺序应该是这样:
- 为Singleton象分配一个内存空间。
- 在分配的内存空间实例化对象。
- 把Instance 引用地址指向内存空间。
但在实际编译的过程中,编译器有可能会帮我们进行优化,优化完它的顺序可能变成如下:
- 为Singleton对象分配一个内存空间。
- 把instance 引用地址指向内存空间。
- 在分配的内存空间实例化对象。
按照优化完的顺序,当并发访问的时候,可能会出现这样的情况
- A线程进入方法进行第1次instance == null判断。
- 此时A线程发现instance 为null 所以对Singleton.class加锁。
- 然后A线程进入方法进行第2次instance == null判断。
- 然后A线程发现instance 为null,开始进行对象实例化。
- 为对象分配一个内存空间。
6.把Instance 引用地址指向内存空间(而就在这个指令完成后,线程B进入了方法)。 - B线程首先进入方法进行第1次instance == null判断。
- B线程此时发现instance 不为null ,所以它会直接返回instance (而此时返回的instance 是A线程还没有初始化完成的对象)
最终线程B拿到的instance 是一个没有实例化对象的空内存地址,所以导致instance使用的过程中造成程序错误。解决办法很简单,可以给sInstance对象加上一个关键字,volatile,这样编译器就不会乱优化,有关volatile的具体内容后续再细说。
主要解决办法
通过上面的介绍,其实可以归纳无论是CPU缓存,线程切换还是编译器优化乱序,出现问题的核心都是因为多个线程要并发读写某个变量或并发执行某段代码。那么我们可以控制,一次只让一个线程执行变量读写就可以了,这就是互斥。
而在某些时候,互斥还不够,还需要一定的条件。比如一个生产者一个消费者并发,生产者向队列存东西,消费者向队列拿东西。那么生产者写的时候要保证存的时候队列不是满的,消费者要保证拿的时候队列非空。这种线程与线程间需要通信协作的情况,称为同步,同步可以说是更复杂的互斥。
既然知道了并发编程的根源以及同步和互斥,那我们来看看有哪些解决的思路。其实一共也就三种:
- 避免共享
- Immutability(不变性)
- 管程及其他工具
下面我们分别说说这三种方案的优缺点
避免共享
我们先来说说避免共享,其实避免共享说是线程本地存储技术,在java中指的一般就是Threadlocal。ThreadLocal会为每个线程提供一个本地副本,每个线程都只会修改自己的ThreadLocal变量。这样一来就不会出现共享变量,也就不会出现冲突了。
其实现原理是在ThreadLocal内部维护一个ThreadLocalMap,每次有线程要获取对应变量的时候,先获取当前线程,然后根据不同线程取不同的值,典型的以空间换时间。
所以ThreadLocal还是比较适用于需要共享资源,且资源占用空间不大的情况。比如一些连接的session啊等等。但是这种模式应用场景也较为有限,比如需要同步情况就难以胜任。
Immutability(不变性)
Immutability在函数式中用得比较多,函数式编程的一个主要目的是要写出无副作用的代码,有关什么是无副作用可以参考我以前的文章Scala函数式编程指南(一) 函数式思想介绍。而无副作用的一个主要特点就是变量都是Immutability即不可变的,即创建对象后不会再修改对象,比如scala默认的变量和数据结构都是不可变的。而在java中,不变性变量即通过final修饰的变量,如String,Long,Double等类型都是Immutability的,它们的内部实现都是基于final关键字的。
那这又和并发编程有什么关系呢?其实啊,并发问题很大部分原因就是因为线程切换破坏了原子性,这又导致线程随意对变量的读写破坏了数据的一致性。而不变性就不必担心这个问题,因为变量都是不变,不可写只能读的。在这种编程模式下,你要修改一个变量,那么只能新生成一个。这样做的好处很明显,但坏处也是显而易见,那就是引入了额外的编程复杂度,丧失了代码的可读性和易用性。
因为如此,不变性的并发解决方案其实相对而已没那么广泛,其中比较有代表性的算是Actor并发编程模型,我以前也有讨论过,有兴趣可以看看Actor模型浅析 一致性和隔离性,这种编程模型和常规并发解决方案有很显著的差异。按我的了解,Acctor模式多用在分布式系统的一些协调功能,比如维持集群中多个机器的心跳通信等等。如果在单机并发环境下,还是下面要介绍的管程类工具才是利器。
管程及其他工具
其实最早的操作系统中,解决并发问题用的是信号量,信号量通过两个原子操作wait(S),和signal(S)(俗称P,V操作)来实现访问资源互斥和同步。比如下面这个小例子:
//整型信号量定义
int S;
//P操作
wait(S){
while(S<=0);
S--;
}
//V操作
signal(S){
S++;
}
虽然信号量方便有效,但信号量要对每个共享资源都实现对应的P和V操作,这使得并发编程中可能要出现大量的P,V操作,并且这部分内容难以抽象出来。
为了更好地实现同步互斥,于是就产生了管程(即Monitor,也有翻译为监视器),值得一提的是,管程也有几种模型,分别是:Hasen模型,Hoare模型和MESA模型。其中MESA模型应用最广泛,java也是参考自MESA模型。这里简单介绍下管程的理论知识,这部分内容参考自进程同步机制-----为进程并发执行保驾护航,希望了解更多管程理论知识的童鞋可以看看。
我们来通过一个经典的生产-消费队列来解释,如下图
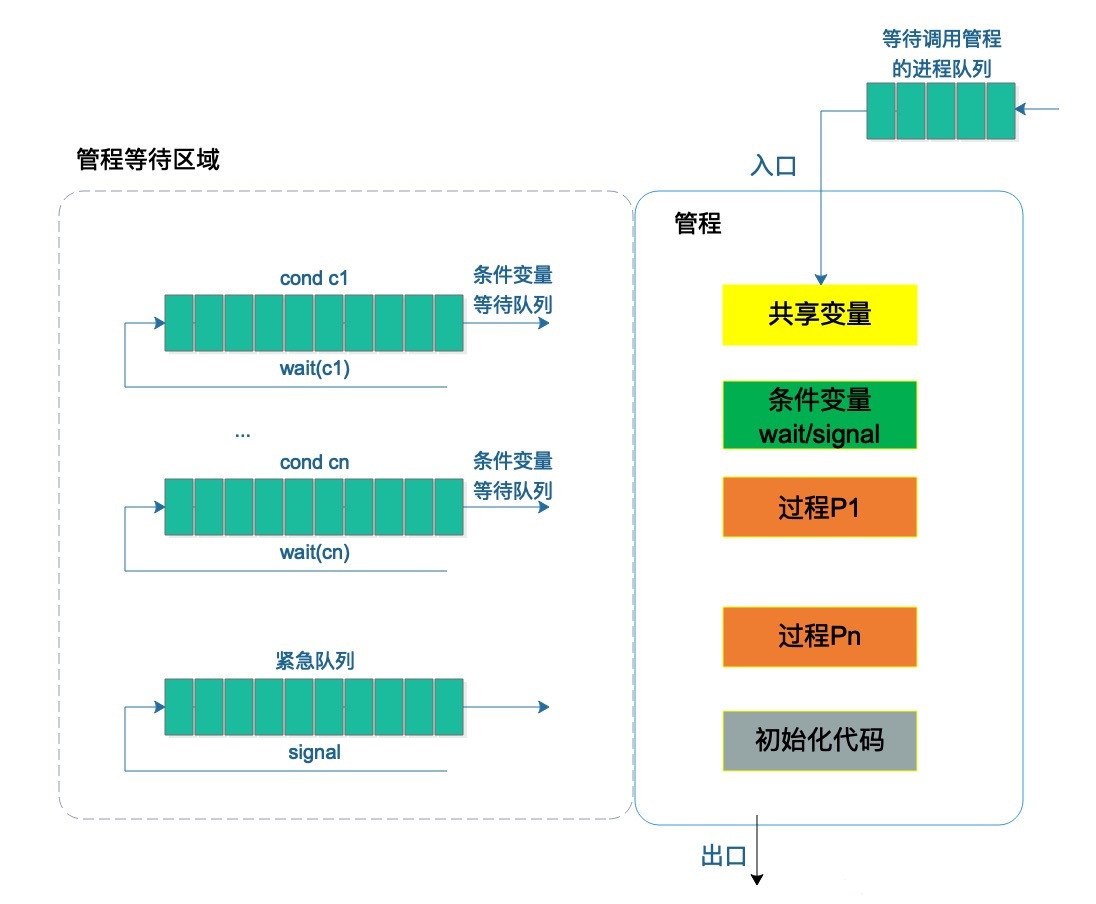
我们先解释下图中右半部分的内容,右上角有一个等待调用的线程队列,管程中每次只能有一个线程在执行任务,所以多个任务需要等待。然后是各个名词的意思,生产-消费需要往队列写入和取出东西,这里的队列就是共享变量,对共享资源进行操作称之为过程(入队和出队两个过程)。而向队列写入和取出是有条件的,写入的时候队列必须是非满的,取出的时候队列必须是非空的,这两个条件被称为条件变量。
然后再来看看左半部分的内容,假设线程T1读取共享变量(即队列),此时发现队列为空(条件变量之一),那么T1此时需要等待,去哪里等呢?去条件变量队列不能为空对应的队列中去等待。此时另一个线程T2向共享变量队列写数据,通过了条件变量队列不能满,那么写完后就会通知线程T1。但因为管程的限制,管程中只能有一个线程在执行,所以T1线程不能立即执行,它会回到右上角的线程等待队列等待(不同的管程模型在这里是有分歧的,比如Hasen模型是立即中断T2线程让队列中下一个线程执行)。
解释完这个图,管程的概念也就呼之欲出了,
hansen对管程的定义如下:一个管程定义了一个数据结构和能力为并发进程所执行(在该数据结构上)的一组操作,这组操作能同步进程和改变管程中的数据。
本质上,管程是对共享资源以及对共享资源的操作抽象成变量和方法,要操作共享变量仅能通过管程提供的方法(比如上面的入队和出队)间接访问。所以你会发现管程其实和面向对象的理念是十分相近的,在java中,主要提供了低层次了synchronized关键字和wait(),notify()等方法。同时还提供了高层次的ReenTrantLock和Condition来实现管程模型。
以上~
java并发编程 --并发问题的根源及主要解决方法的更多相关文章
- Python并发编程-并发解决方案概述
Python并发编程-并发解决方案概述 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.并发和并行区别 1>.并行(parallel) 同时做某些事,可以互不干扰的同一个时 ...
- 编程中遇到的Python错误和解决方法汇总整理
这篇文章主要介绍了自己编程中遇到的Python错误和解决方法汇总整理,本文收集整理了较多的案例,需要的朋友可以参考下 开个贴,用于记录平时经常碰到的Python的错误同时对导致错误的原因进行分析, ...
- 出现 java.lang.OutOfMemoryError: PermGen space 错误的原因及解决方法
一.原因及解决方法[1] 1.原因:堆内存的永久保存去区内存分配不足(缺省默认为64M),导致内存溢出错误. 2.解决方法:重新分配内存大小,-Xms1024M -Xmx2048M -XX:PermS ...
- Java并发编程-并发工具包(java.util.concurrent)使用指南(全)
1. java.util.concurrent - Java 并发工具包 Java 5 添加了一个新的包到 Java 平台,java.util.concurrent 包.这个包包含有一系列能够让 Ja ...
- java并发编程——并发容器
概述 java cocurrent包提供了很多并发容器,在提供并发控制的前提下,通过优化,提升性能.本文主要讨论常见的并发容器的实现机制和绝妙之处,但并不会对所有实现细节面面俱到. 为什么JUC需要提 ...
- Java多线程编程——并发编程原理(分布式环境中并发问题)
在分布式环境中,处理并发问题就没办法通过操作系统和JVM的工具来解决,那么在分布式环境中,可以采取一下策略和方式来处理: 避免并发 时间戳 串行化 数据库 行锁 统一触发途径 避免并发 在分布式环境中 ...
- 并发编程>>并发级别(二)
理解并发 这是我在开发者头条看到的.@编程原理林振华 有目标的提升自己会事半功倍,前行的道路并不孤独. 1.阻塞 当一个线程进入临界区(公共资源区)后,其他线程必须在临界区外等待,待进去的线程执行完成 ...
- 对于高并发短连接造成Cannot assign requested address解决方法
https://www.cnblogs.com/dadonggg/p/8778318.html 感谢这篇文章给予的启发 在tcp四次挥手断开连接时,主动释放连接的一方最后会进入TIME_WAIT状态, ...
- (class file version 53.0), Java Runtime versions up to 52.0错误的解决方法
遇到这个错误是在Apache Tomcat上部署应用程序的时候遇到的,具体的错误描述是: java.lang.UnsupportedClassVersionError: HelloWorld has ...
随机推荐
- var、let、const三者的区别
var定义的变量,没有块的概念,可以跨块访问, 不能跨函数访问. let定义的变量,只能在块作用域里访问,不能跨块访问,也不能跨函数访问. const用来定义常量,使用时必须初始化(即必须赋值),只能 ...
- vue配置环境参考
转 https://www.cnblogs.com/tu-0718/p/7521099.html 转 https://www.jianshu.com/p/1626b8643676 $ vue ini ...
- uiautomator2通过wifi操作手机
参考来源:https://www.cnblogs.com/c-x-a/p/11176066.html,有部分不适合当前版本的做了修改 1.手机通过USB连接电脑,先开启远程adb模式,操作如下(可以指 ...
- [PHP学习教程 - 数字]001.数字补0(Num padding)
引言:在日常工作中,经常要用到数字前后补0的操作,如:日期格式yyyy-MM-dd等等. 在php中有多种前后填充函数——今天,我们就介绍常用的两种,实现数字补零: str_pad sprintf 大 ...
- ZooKeeper未授权漏洞
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作.最终, ...
- [03]HTML基础之行内标签
1.<ruby>标签 显示东亚字符的发音(如中文,日文等),与<rp>,<rt>标签搭配. //<ruby>为单个发音字符的容器,<rp>为 ...
- Beta冲刺——5.24
这个作业属于哪个课程 软件工程 这个作业要求在哪里 Beta冲刺 这个作业的目标 Beta冲刺 作业正文 正文 github链接 项目地址 其他参考文献 无 一.会议内容 1.安排每个人进行为期3天的 ...
- Rocket - tilelink - SRAM
https://mp.weixin.qq.com/s/-z9n6SHyAiK2OE7mOSvC2Q 简单介绍SRAM的实现. 1. 基本介绍 实现一个支持读写的静态存储器.存取的 ...
- Rocket - diplomacy - LazyModule
https://mp.weixin.qq.com/s/FBU8fE4u9-UK6mRGQOlvbQ 介绍LazyModule的实现. 1. children LazyModu ...
- jchdl - RTL实例 - And
https://mp.weixin.qq.com/s/86d_sFN0xVqk1xRaRyoAkg 使用rtl语法,实现简单的与门. 参考链接 https://github.com/wjcdx ...