Dubbo的配置过程,实现原理及架构详解
一. Dubbo是什么?Dubbo能做什么?
随着互联网的发展,市场需求快速变更,业务持续高速增长,网站早已从单一应用架构演变为分布式服务架构及流动计算架构。在分布式架构的背景下,在本地调用非本进程内(远程)的资源就变得在所难免。因此,后期涌现出了很多RPC(远程过程调用)的框架,如 Apache Thrift、Hessian、gRPC 等。然而,随着 RPC 框架的推广和使用的日益深入,服务越来越多的情况也衍生出了新的业务需求:
(1)如何管理过多的服务URL
(2)消费者要想使用服务,就必须直接知道和了解服务提供方的服务地址。后台服务地址一旦改变,则需要一一通知消费者,这种高度耦合的关系很不利用维护。
(3)海量的服务会延伸出很多的错误,如何对这些常见失败案例提供服务治理的功能。
在这个背景下,阿里巴巴集团推出了Dubbo分布式框架,来解决和缓和目前RPC框架下的这些需求和瓶颈。具体措施如下:
(1)通过引入服务注册中心Registry来管理服务的依赖关系,并通过在消费方获取服务提供方地址列表,实现软负载均衡和 Failover,降低对 F5 硬件负载均衡器的依赖。
(2)在注册中心提供订阅发布机制,使得消费者只需要关心服务本身,而不再需要写死服务提供方地址。注册中心基于接口名查询服务提供者的ip地址,然后将服务提供方的地址动态的回传给服务消费者。
(3)专门独立出一个服务治理中心,统一对集群各节点的服务做在线治理,提升治理效率.
二. Dubbo 的工作原理(参照官方文档:https://github.com/apache/dubbo)

1) 节点说明:
Provider:暴露服务的服务提供方
Consumer:调用远程服务的服务消费方
Registry:服务注册与发现的注册中心
Monitor: 统计服务的调用次数和调用时间的监控中心
Container:服务运行容器
2) 调用过程及工作原理:
0. 服务容器Container启动,加载,运行服务提供者,通过 main 函数初始化 Spring 上下文,根据服务提供者的XML配置文件将每个服务按照指定的协议发布(每个服务都有自己对应的协议端口号protocol,port),从而完成多个服务的初始化工作。


1. 服务提供者Provider在启动时,根据配置的服务注册中心地址连接服务注册中心Registry,将服务提供者信息发布到注册中心(如zookeeper),向注册中心注册自己提供的服务(如上图)。
2. 服务消费者Consumer在启动时,消费者根据服务消费者XML配置文件的服务引用信息,连接到注册中心,向注册中心订阅自己所需的服务。

3. 服务注册中心根据消费者的服务订阅关系,返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送最新的服务地址信息给消费者(这个监听过程是由Dubbo另外提供的NotifyListrener辅助完成的,具体可以看下一节的介绍)。
4. 服务消费者调用远程服务时,根据路由策略,从本地缓存的服务提供者地址列表中选择选一台提供者进行,然后根据协议类型建立链路,跨进程调用服务提供者,如果调用失败,再选另一台调用。
5. 服务消费者Consumer和提供者Provider,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心Monitor。
三.Dubbo的底层架构解读(参考文档:http://dubbo.apache.org/zh-cn/docs/dev/design.html)
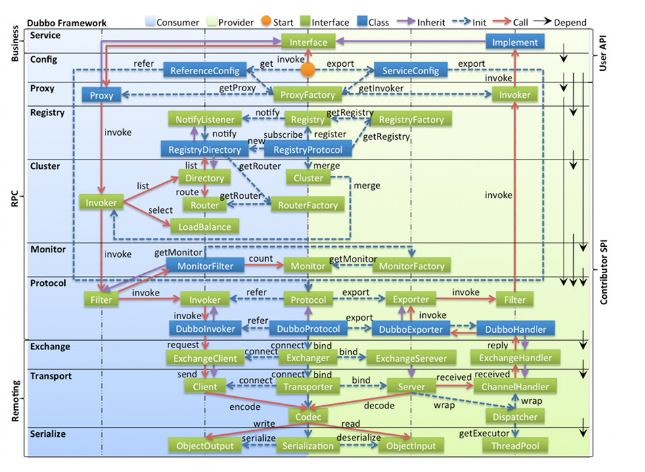
(1)从图上前两层,我们可以很容易的分析出左边蓝色部分是服务消费者(ReferenceConfig),右边是服务提供者(implement接口,ServiceConfig)。
(2)其中在左边的接口表示是扩展给消费者单独使用的,右边的接口表示是扩展给服务者单独使用的。而中间的接口是服务者和消费者两者都可以使用的。
(3)从上到下按照dubbo的工作过程,一共分为10层。各部分的介绍参照(http://crazyfzw.github.io/2018/06/10/dubbo-architecture/)
服务接口层(Service):该层是与实际业务逻辑相关的,根据服务提供方和服务消费方的业务设计对应的接口和实现。
配置层(Config):对外配置接口,以 ServiceConfig 和 ReferenceConfig 为中心,可以直接 new 配置类,也可以通过 spring 解析配置生成配置类。
服务代理层(Proxy):服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton,以 ServiceProxy 为中心,扩展接口为 ProxyFactory。
服务注册层(Registry):封装服务地址的注册与发现,以服务URL为中心,扩展接口为 RegistryFactory、Registry 和 RegistryService。可能没有服务注册中心,此时服务提供方直接暴露服务。
集群层(Cluster):封装多个提供者的路由及负载均衡,并桥接注册中心,以Invoker为中心,扩展接口为 Cluster、Directory、Router 和 LoadBalance。将多个服务提供方组合为一个服务提供方,实现对服务消费方来透明,只需要与一个服务提供方进行交互。
监控层(Monitor):RPC 调用次数和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory、Monitor 和 MonitorService。
远程调用层(Protocol):封将 RPC 调用,以 Invocation 和 Result 为中心,扩展接口为 Protocol、Invoker 和 Exporter。Protocol 是服务域,它是 Invoker 暴露和引用的主功能入口,它负责 Invoker 的生命周期管理。Invoker 是实体域,它是 Dubbo 的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,可向它发起 invoke 调用,它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现。
信息交换层(Exchange):封装请求响应模式,同步转异步,以 Request 和 Response 为中心,扩展接口为 Exchanger、ExchangeChannel、ExchangeClient 和 ExchangeServer。
网络传输层(Transport):抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为 Channel、Transporter、Client、Server 和 Codec。
数据序列化层(Serialize):可复用的一些工具,扩展接口为 Serialization、 ObjectInput、ObjectOutput和ThreadPool。
大致的工作流程是:
1.读取配置文件,生成代理对象
2.代理对象负责将其注册到注册中心进行备份
3.下层monitor层对双方进行业务监控。
在 RPC 中,Protocol 是核心层,也就是只要有 Protocol + Invoker + Exporter 就可以完成非透明的 RPC 调用,然后在 Invoker 的主过程上 Filter 拦截点。
需要注意的是:为了底层可以使用NIO来传输数据,所有的公共api接口都应该实现Serializable.
四.Dubbo的缺点
因为是阿里出品,所以其目前只支持Java语言,对语言的支持性不是很好。
Dubbo的配置过程,实现原理及架构详解的更多相关文章
- zabbix实现原理及架构详解
想要用好zabbix进行监控,那么我们首要需要了解下zabbix这个软件的实现原理及它的架构.建议多阅读官方文档. 一.总体上zabbix的整体架构如下图所示: 重要组件说明: 1)zabbix se ...
- SSH免密登陆配置过程和原理解析
SSH免密登陆配置过程和原理解析 SSH免密登陆配置过很多次,但是对它的认识只限于配置,对它认证的过程和基本的原理并没有什么认识,最近又看了一下,这里对学习的结果进行记录. 提纲: 1.SSH免密登陆 ...
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
- NopCommerce源码架构详解--初识高性能的开源商城系统cms
很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从中学习很多企业系统.软件开发的规范和一些新的技术.技巧,可以快速地提高我们 ...
- 领域驱动设计(Domain Driven Design)参考架构详解
摘要 本文将介绍领域驱动设计(Domain Driven Design)的官方参考架构,该架构分成了Interfaces.Applications和Domain三层以及包含各类基础设施的Infrast ...
- hdfs文件系统架构详解
hdfs文件系统架构详解 官方hdfs分布式介绍 NameNode *Namenode负责文件系统的namespace以及客户端文件访问 *NameNode负责文件元数据操作,DataNode负责文件 ...
- NopCommerce源码架构详解
NopCommerce源码架构详解--初识高性能的开源商城系统cms 很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从 ...
- RESTful 架构详解
RESTful 架构详解 分类 编程技术 1. 什么是REST REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征)性状态转移. 它首次 ...
- Zookeeper系列二:分布式架构详解、分布式技术详解、分布式事务
一.分布式架构详解 1.分布式发展历程 1.1 单点集中式 特点:App.DB.FileServer都部署在一台机器上.并且访问请求量较少 1.2 应用服务和数据服务拆分 特点:App.DB.Fi ...
随机推荐
- AttributeError: 'Word2Vec' object has no attribute 'vocab'
在 Gensim 1.0.0 版本后移除了 vocab,需使用 model.wv.vocab
- build hadoop, spark, hbase cluster
1,something: 1,arc land 506 git branch 507 git status 508 git reset multicloud/qcloud/cluster_man ...
- 2 CSS盒子模型&边框&轮廓&外边距&填充&分组嵌套&尺寸&display与visibility
盒子模型 Box Model 所有HTML元素可以看做盒子,CSS模型本质上是一个盒子,封装周围的HTML元素 包括:边距,边框,填充和实际内容 盒子模型允许我们在其他元素和周围元素边框之间的空间放 ...
- KNN-学习笔记
仅供学习使用 练习1 # coding:utf-8 # 2019/10/16 16:49 # huihui # ref: import numpy as np from sklearn import ...
- 【PAT甲级】1033 To Fill or Not to Fill (25 分)(贪心,思维可以做出简单解)
题意: 输入四个正数C,DIS,D,N(C<=100,DIS<=50000,D<=20,N<=500),分别代表油箱容积,杭州到目标城市的距离,每升汽油可以行驶的路程,加油站数 ...
- linux 部署java 项目命令
1:服务器部署路径:/home/tomcat/tomcat/webapps (用FTP工具链接服务器把包上传到此目录) 2:进入项目文件夹 cd /home/tomcat/tomcat/webapp ...
- Java - 使用hibernate配置文件 + JPA annotation注解操作数据库
本程序运行环境:IDEA. 实际上我对hiberbate与注解的关系还不是太清晰.据我所知注解都是Java JPA的,那么我的理解是:hibernate就应该只是通过这些JPA标识及hibernate ...
- Mysql 锁定 读情况
在一个事务中,标准的SELECT语句是不会加锁,但是有两种情况例外. SELECT ... LOCK IN SHARE MODE SELECT ... FOR UPDATE SELECT ... LO ...
- Python之第一次自夸
有一个好玩的代码 import win32com.client g = win32com.client.Dispatch("SAPI.SPVOICE") g.Speak(" ...
- SpingBoot学习(一)
一.概述 Spring Boot是为了简化Spring应用的创建.运行.调试.部署等而出现的,使用它可以做到专注于Spring应用的开发,而无需过多关注XML的配置. 简单来说,它提供了一堆依赖打包, ...