【Hadoop】hdfs,剖析文件上传
文件上传原理图
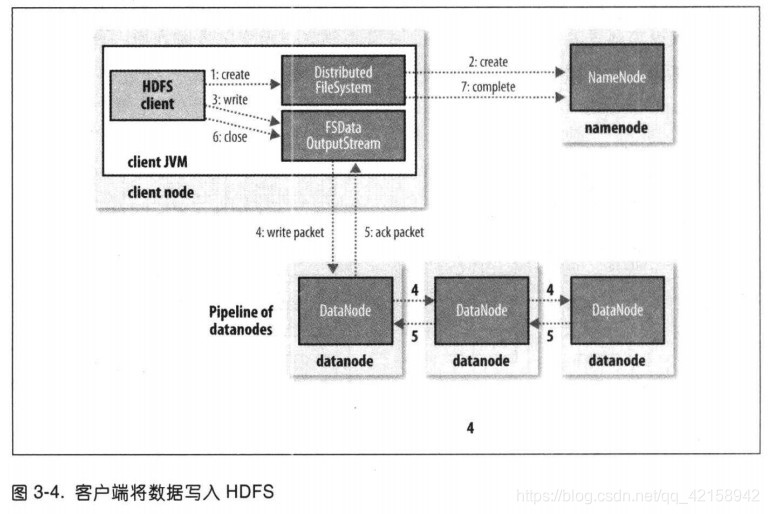
剖析文件写入
1.客户端(client)通过对DistributedFileSystem对象调用create()来新建文件;
FSDataOutputStream outputStream = fileSystem.create(new Path("/test.txt"));
2.DistributedFileSystem对namenode创建一个RPC调用,在文件系统的命名空间新建一个文件,此时该文件还没有相应的数据块;
namenode会执行各种不同的检查以确保这个文件不存在以及客户端有新建该文件的权限。
如果通过检查
namenode就会创建新文件记录的一条记录
否则
文件创建失败并向客户端抛出一个IOException异常
DistributedFileSystem向客户端返回一个FSDataOutputStream对象,由此客户端可以开始写入数据。
就像读取事件一样,FSDataOutputStream封装一个DFSoutPutstream对象,该对象负责处理datanode与namenode之间的通信
public FSDataOutputStream create(Path f, final FsPermission permission, final EnumSet<CreateFlag> cflags, final int bufferSize, final short replication, final long blockSize, final Progressable progress, final ChecksumOpt checksumOpt) throws IOException {
this.statistics.incrementWriteOps(1);
Path absF = this.fixRelativePart(f);
return (FSDataOutputStream)(new FileSystemLinkResolver<FSDataOutputStream>() {
public FSDataOutputStream doCall(Path p) throws IOException, UnresolvedLinkException {
DFSOutputStream dfsos = DistributedFileSystem.this.dfs.create(DistributedFileSystem.this.getPathName(p), permission, cflags, replication, blockSize, progress, bufferSize, checksumOpt);
return DistributedFileSystem.this.dfs.createWrappedOutputStream(dfsos, DistributedFileSystem.this.statistics);
}
public FSDataOutputStream next(FileSystem fs, Path p) throws IOException {
return fs.create(p, permission, cflags, bufferSize, replication, blockSize, progress, checksumOpt);
}
}).resolve(this, absF);
}
3.在客户端写入数据时,DFSOutpuStream将它分成一个个的数据包,并写入内部队列,称为“数据队列”(data queue)。
4.DataStreamer处理数据队列,它的责任是挑选出适合存储数据复本的一组datanode,并据此来要求namenode分配新的数据块。这一组datanode构成一个管线----我们假设副本数为3,所以管线中有3个节点。
5.DFSOutputStream也维护着一个内部数据包队列来等待datanode的收到确认回执,称为“确认队列”。收到管道中所有datanode确认信息后,该数据包才会从确认队列删除。
如果某一个datanode凉了(宕机),怎么办?

6.客户端完成数据写入后,对数据流调用close()方法。
7.该操作将所有的数据包写入datanode管线,并在联系到namenode告知其文件在写入之前,等待确认。
【Hadoop】hdfs,剖析文件上传的更多相关文章
- Hadoop 代码实现文件上传
本项目主要实现Windows下利用代码实现Hadoop中文件上传至HDFS 实现上传文本文件中单词个数的计数 1.项目结构 2.相关代码 CopyFromLocalFile 1 package com ...
- HDFS操作--文件上传/创建/删除/查询文件信息
1.上传本地文件到HDFS //上传本地文件到HDFS public class CopyFile { public static void main(String[] args) { try { C ...
- Hadoop之HDFS原理及文件上传下载源码分析(上)
HDFS原理 首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来. 楼主的环境: 操作系统:Ubuntu 15.10 hadoop版本:2.7.3 HA:否(随 ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- Hadoop生态圈-Azkaban实现文件上传到hdfs并执行MR数据清洗
Hadoop生态圈-Azkaban实现文件上传到hdfs并执行MR数据清洗 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如果你没有Hadoop集群的话也没有关系,我这里给出当时我 ...
- springMVC + hadoop + httpclient 文件上传请求直接写入hdfs
1.首先是一个基于httpclient的java 应用程序,代码在这篇文章的开头:点击打开链接 2.我们首先写一个基于springMVC框架的简单接收请求上传的文件保存本地文件系统的demo,程序代码 ...
- hadoop学习记录--hdfs文件上传过程源码解析
本节并不大算为大家讲接什么是hadoop,或者hadoop的基础知识因为这些知识在网上有很多详细的介绍,在这里想说的是关于hdfs的相关内容.或许大家都知道hdfs是hadoop底层存储模块,专门用于 ...
- Ubuntu本地文件上传至HDFS文件系统出现的乱码问题及解决方案
1.问题来源及原因 用shell命令上传到HDFS中之后出现中文乱码,在shell命令窗口查看如图: 在eclipse中的文件HDFS查看工具查看如图: 原因:上传至HDFS文件系统的文本文件(这里是 ...
- hdfs文件上传机制与namenode元数据管理机制
1.hdfs文件上传机制 文件上传过程: 1.客户端想NameNode申请上传文件, 2.NameNode返回此次上传的分配DataNode情况给客户端 3.客户端开始依向dataName上传对应 ...
随机推荐
- 使用Proteus模拟操作HDG12864F-1液晶屏
在Proteus中模拟了89C52操作HDG12864F-1液晶屏,原理图如下: 一.HDG12864F-1官网信息 该液晶屏是Hantronix的产品,官网上搜索出这个型号是系列型号中的一种,各种型 ...
- asp.net core计划任务探索之hangfire+redis+cluster
研究了一整天的quartz.net,发现一直无法解决cluster模式下多个node独立运行的问题,改了很多配置项,仍然是每个node各自为战.本来cluster模式下的各个node应该是负载均衡的, ...
- [hdu5164]ac自动机
中文题目:http://bestcoder.hdu.edu.cn/contests/contest_chineseproblem.php?cid=563&pid=1003 首先贴一下bc的题解 ...
- qt creator源码全方面分析(4-6)
目录 Qt插件基础 Qt插件基础 我们知道Qt Creator源码是基于插件架构的,那么我们先来介绍下插件基础知识. 相关内容如下: How to Create Qt Plugins [ - Defi ...
- JAVA异常以及字节流
异常 JAVA异常可以分为编译时候出现的异常和执行时候出现的异常 JVM默认处理异常的方法是抛出异常 异常处理 //第一种 try{ 可能会出错的代码 }catch{ 发生异常后处置方法 }final ...
- 一句话+两张图搞定JDK1.7HashMap,剩下凑字数
JDK1.7 HashMap一探究竟 HashMap很简单,原理一看散列表,实际数组+链表;Hash找索引.索引若为null,while下一个.Hash对对碰,链表依次查.加载因子.75,剩下无脑扩数 ...
- Mybatis 注入全局参数
在项目中使用mybatis作为dao层,大部分时间都需要使用到mybatis提供的动态sql功能,一般情况下所有的表都是在同一个数据库下的,进行数据操作时都是使用jdbc中默认的schema.但是如果 ...
- jQuery学习笔记——jQuery常规选择器
一.简单选择器在使用 jQuery 选择器时,我们首先必须使用“$()”函数来包装我们的 CSS 规则.而CSS 规则作为参数传递到 jQuery 对象内部后,再返回包含页面中对应元素的 jQuery ...
- equals(), "== ",hashcode() 详细解释
Object 通用方法容易混淆的定义 先搞清楚各自的定义 "==" 用来判断 相等 equals() 用来判断 等价 hashcode() 用来返回散列值 "==&quo ...
- PAT 1010 Radix (25分) radix取值无限制,二分法提高效率
题目 Given a pair of positive integers, for example, 6 and 110, can this equation 6 = 110 be true? The ...