多线程高并发编程(9) -- CopyOnWrite写入时复制
CopyOnWrite写入时复制
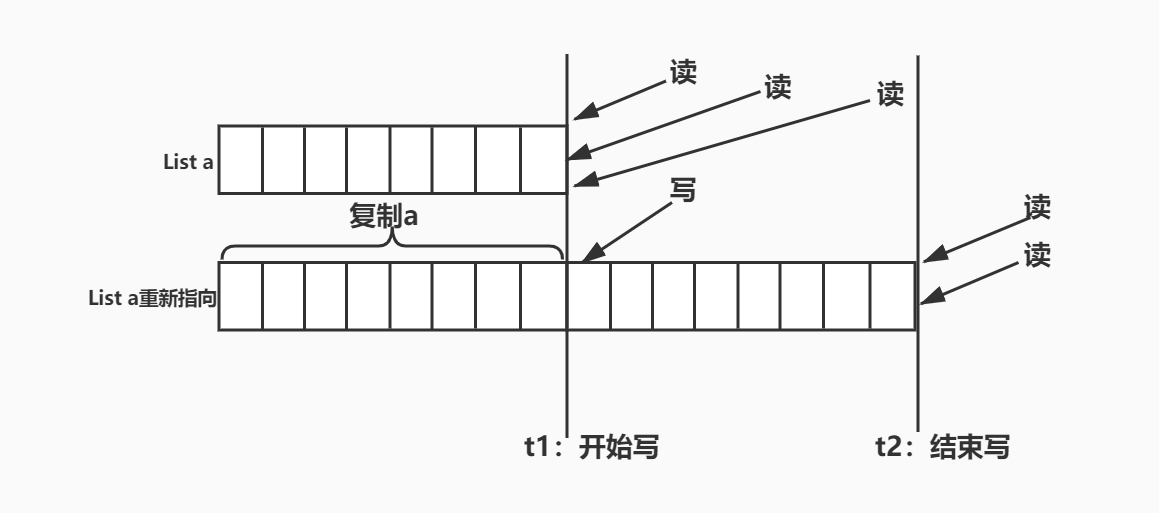
CopyOnWrite,即快照模式,写入时复制就是不同线程访问同一资源的时候,会获取相同的指针指向这个资源,只有在写操作,才会去复制一份新的数据,然后新的数据在被写操作完后立马被其他线程看到最新的数据变化,然后之前获取的指针会指向新的数据,但在写操作未结束时,其他线程仍然能访问最初的资源。此做法主要的优点是如果没有线程进行写操作,就不会进行数据副本的复制,因此多个线程只是读取操作时可以共享同一份资源。
下面以CopyOnWriteArrayList为例:
测试:
public static void main(String[] args) {
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
list.add("a");
list.add("b");
list.add("c");
System.out.println("主线程-0:"+list.toString());
new Thread(()->{
System.out.println("读子线程-0:"+list.toString());
}).start();
new Thread(()->{
list.add("d");
System.out.println("写子线程-0:"+list.toString());
}).start();
new Thread(()->{
System.out.println("读子线程-1:"+list.toString());
}).start();
list.add("e");
new Thread(()->{
System.out.println("读子线程-2:"+list.toString());
}).start();
System.out.println("主线程-1:"+list.toString());
new Thread(()->{
list.add("f");
System.out.println("写子线程-1:"+list.toString());
}).start();
System.out.println("主线程-2:"+list.toString());
new Thread(()->{
System.out.println("读子线程-3:"+list.toString());
}).start();
}
//=======结果========
主线程-0:[a, b, c]
读子线程-0:[a, b, c]
写子线程-0:[a, b, c, d]
读子线程-1:[a, b, c, d, e]//主线程写e立马被读子线程1发现
主线程-1:[a, b, c, d, e]//主线程写e后输出
读子线程-2:[a, b, c, d, e]
主线程-2:[a, b, c, d, e]
写子线程-1:[a, b, c, d, e, f]
读子线程-3:[a, b, c, d, e, f]
CopyOnWriteArrayList.add/set/remove/get源码探究
add:
private transient volatile Object[] array;//volatile确保数组的可见性
public boolean add(E e) {
final ReentrantLock lock = this.lock;//获得可重入排他锁
lock.lock();//加锁
try {
Object[] elements = getArray();//得到之前数组
int len = elements.length;//之前数组长度
Object[] newElements = Arrays.copyOf(elements, len + 1);//重新拷贝一份新数组,长度+1
newElements[len] = e;//元素加入新数组
setArray(newElements);//数组引用重新指向新数组,即进行旧数组的覆盖
return true;
} finally {
lock.unlock();//释放锁
}
}
set:
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
E oldValue = get(elements, index);//获得指定位置的旧元素
if (oldValue != element) {//旧元素不等于新元素
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);//拷贝旧数组
newElements[index] = element;//指定位置的元素更新为新元素
setArray(newElements);//引用重新指向
} else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements);//旧元素和新元素一致
}
return oldValue;//返回指定位置的旧元素
} finally {
lock.unlock();
}
}
remove:
public E remove(int index) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();//旧数组
int len = elements.length;//长度
E oldValue = get(elements, index);//指定位置的旧元素
int numMoved = len - index - 1;//判断是否移除尾部数据
if (numMoved == 0)//移除尾部数据
setArray(Arrays.copyOf(elements, len - 1));//直接截取数组,把尾部去掉
else {
Object[] newElements = new Object[len - 1];//创建新数组,长度-1
System.arraycopy(elements, 0, newElements, 0, index);//复制指定位置前面的数据
System.arraycopy(elements, index + 1, newElements, index,
numMoved);//复制指定位置后面的数据
setArray(newElements);//数组引用重新指向
}
return oldValue;
} finally {
lock.unlock();
}
}
get:从中可以看到,没有加锁,直接返回指定位置的元素
public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}
CopyOnWriteArrayList探讨:
- CopyOnWriteArrayList和Vector的比较:Vector每个方法都加了synchronized,相比CopyOnWriteArrayList只在写操作加锁性能要提升很多;
- CopyOnWriteArrayList适合读多写少的并发场景,比如配置、白名单,黑名单,商品类目的访问和更新场景、物流地址等变化非常少的数据;
- CopyOnWriteArrayList存在内存问题,即每次的写操作都要进行资源的复制、替换,如果资源对象占用的内存过大,可能导致频繁的Yong GC和Full GC,会造成程序的响应时间变长;
- CopyOnWriteArrayList尽量使用批量添加操作addAll方法;
- CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。
CopyOnWriteArraySet
一个Set使用内部CopyOnWriteArrayList其所有操作。
public class CopyOnWriteArraySet<E> extends AbstractSet<E>
implements java.io.Serializable { private final CopyOnWriteArrayList<E> al; public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
public boolean add(E e) {
return al.addIfAbsent(e);
}
}
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
public boolean addIfAbsent(E e) {//如果元素已经存在,返回false,否则进行写操作(CopyOnWrite)
Object[] snapshot = getArray();
return indexOf(e, snapshot, 0, snapshot.length) >= 0 ? false :
addIfAbsent(e, snapshot);
}
}
多线程高并发编程(9) -- CopyOnWrite写入时复制的更多相关文章
- Java 多线程高并发编程 笔记(一)
本篇文章主要是总结Java多线程/高并发编程的知识点,由浅入深,仅作自己的学习笔记,部分侵删. 一 . 基础知识点 1. 进程于线程的概念 2.线程创建的两种方式 注:public void run( ...
- 多线程高并发编程(3) -- ReentrantLock源码分析AQS
背景: AbstractQueuedSynchronizer(AQS) public abstract class AbstractQueuedSynchronizer extends Abstrac ...
- Java 多线程高并发编程 笔记(二)
1. 单例模式(在内存之中永远只有一个对象) 1.1 多线程安全单例模式——不使用同步锁 public class Singleton { private static Singleton sin=n ...
- 多线程高并发编程(12) -- 阻塞算法实现ArrayBlockingQueue源码分析(1)
一.前言 前文探究了非阻塞算法的实现ConcurrentLinkedQueue安全队列,也说明了阻塞算法实现的两种方式,使用一把锁(出队和入队同一把锁ArrayBlockingQueue)和两把锁(出 ...
- 多线程高并发编程(7) -- Future源码分析
一.概念 A Future计算的结果. 提供方法来检查计算是否完成,等待其完成,并检索计算结果. 结果只能在计算完成后使用方法get进行检索,如有必要,阻塞,直到准备就绪. 取消由cancel方法执行 ...
- 多线程高并发编程(10) -- ConcurrentHashMap源码分析
一.背景 前文讲了HashMap的源码分析,从中可以看到下面的问题: HashMap的put/remove方法不是线程安全的,如果在多线程并发环境下,使用synchronized进行加锁,会导致效率低 ...
- 多线程高并发编程(4) -- ReentrantReadWriteLock读写锁源码分析
背景: ReentrantReadWriteLock把锁进行了细化,分为了写锁和读锁,即独占锁和共享锁.独占锁即当前所有线程只有一个可以成功获取到锁对资源进行修改操作,共享锁是可以一起对资源信息进行查 ...
- 多线程高并发编程(5) -- CountDownLatch、CyclicBarrier源码分析
一.CountDownLatch 1.概念 public CountDownLatch(int count) {//初始化 if (count < 0) throw new IllegalArg ...
- 多线程高并发编程(8) -- Fork/Join源码分析
一.概念 Fork/Join就是将一个大任务分解(fork)成许多个独立的小任务,然后多线程并行去处理这些小任务,每个小任务处理完得到结果再进行合并(join)得到最终的结果. 流程:任务继承Recu ...
随机推荐
- 爬虫需要登陆怎么办?这份python登陆代码请收下
模拟登陆思路 通过selenium中的webdriver控制浏览器登录目标网站,然后获取模拟登陆需要的Cookie,再利用此Cookie来达到登录的效果.本次我们使用webdriver来驱动火狐浏览器 ...
- selemiun 问题总结
1.如果打开一个网页定位一个元素时发现不能够定位某一个元素,并且定位的方法没问题,则需要看下该网页是否有frame框架 解决办法: 如果有frame框架则需要先切换到frame框架下: driver. ...
- [git] github 推送以及冲突的解决,以及一些命令
推送以及冲突的解决:(我的觉得先看完) (正常情况就是把修改的文件 git add 然后git commit 然后推送就行啦): 下面是一些命令 1.查看分支状态(查看所有:当前检出分支的前面会有星号 ...
- SringMVC入门程序
Spring MVC是Spring Framework的一部分,是基于Java实现MVC的轻量级Web框架 1.Spring优点 轻量级,简单易学 高效 , 基于请求响应的MVC框架 与Spring兼 ...
- 负载均衡服务之HAProxy基础配置(三)
前文我们聊到了haproxy的代理配置段中比较常用的配置指令的用法以及说明,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/12770930.html:今天我们来 ...
- 4、flink自定义source、sink
一.Source 代码地址:https://gitee.com/nltxwz_xxd/abc_bigdata 1.1.flink内置数据源 1.基于文件 env.readTextFile(" ...
- hash算法解决冲突的方案
1, 开放定址法: 所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入 公式为:fi(key) = (f(key)+di) MOD m ...
- 【Linux常见问题】CentOS 7 root用户密码忘记,找回密码方法
1.开机按esc 2.选择CentOS Linux (3.10.0-693.......) 按 e 键: 3.光标移动到 linux 16 开头的行,找到 ro 改为 rw init=sysr ...
- MySQL5.7中InnoDB不可不知的新特性
讲师介绍 赖铮 Oracle InnoDB团队 Principle Software Developer 曾任达梦.Teradata高级工程师,主要负责研发数据库执行引擎和存储引擎,十年以商数据库内 ...
- PHP的闭包和匿名函数
闭包函数是创建时,封装周围状态的函数,而匿名函数是没有名称的函数,匿名函数可以被赋值给变量,也就是所谓的函数式编程,也可以传递参数,经常作为回调函数.(理论上讲:匿名函数和闭包不算是一个概念,php却 ...