MySQL之唯一索引、外键的变种、SQL语句数据行操作补充
0、唯一索引

unique对num进行唯一限制,表示num是独一无二的,uql是唯一索引名称
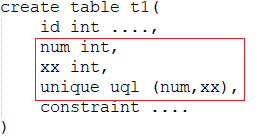
上面为联合索引:num和xx不能完全一样

1、外键的变种
a. 用户表和部门表
用户:
1 alex 1
2 root 1
3 egon 2
4 laoyao 3
部门:
1 服务
2 保安
3 公关
===》 一对多
b. 用户表和博客表
用户表:
1 alex
2 root
3 egon
4 laoyao
博客表:
FK() + 唯一
1 /yuanchenqi/ 4
2 /alex3714/ 1
3 /asdfasdf/ 3
4 /ffffffff/ 2
===> 一对一

程序代码:
create table userinfo1(
id int auto_increment primary key,
name char(10),
gender char(10),
email varchar(64)
)engine=innodb default charset=utf8;
create table admin(
id int not null auto_increment primary key,
username varchar(64) not null,
password VARCHAR(64) not null,
user_id int not null,
unique uq_u1 (user_id),
CONSTRAINT fk_admin_u1 FOREIGN key (user_id) REFERENCES userinfo1(id)
)engine=innodb default charset=utf8;
c.多对多
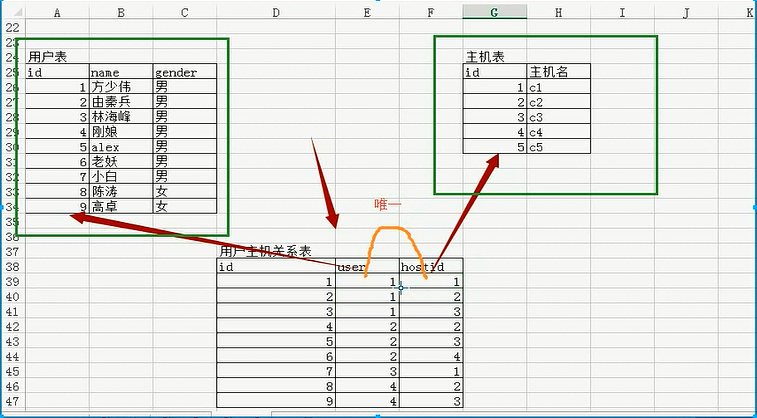
create table userinfo2(
id int auto_increment primary key,
name char(10),
gender char(10),
email varchar(64)
)engine=innodb default charset=utf8; create table host(
id int auto_increment primary key,
hostname char(64)
)engine=innodb default charset=utf8; create table user2host(
id int auto_increment primary key,
userid int not null,
hostid int not null,
unique uq_user_host (userid,hostid),
CONSTRAINT fk_u2h_user FOREIGN key (userid) REFERENCES userinfo2(id),
CONSTRAINT fk_u2h_host FOREIGN key (hostid) REFERENCES host(id)
)engine=innodb default charset=utf8;
3、SQL语句数据行操作补充
3.1 增
insert into tb11(name,age) values('alex',12); #往tb11中插入一条数据
insert into tb11(name,age) values('alex',12),('root',18); #往tb11中插入多条数据
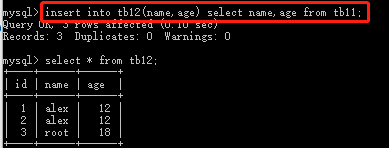
insert into tb12(name,age) select name,age from tb11; #把tb11中的数据复制到tb12中
3.2 删
delete from tb12;
delete from tb12 where id !=2
delete from tb12 where id =2
delete from tb12 where id > 2
delete from tb12 where id >=2
delete from tb12 where id >=2 or name='alex'
3.3 改
update tb12 set name='alex' where id>12 and name='xx'
update tb12 set name='alex',age=19 where id>12 and name='xx'
3.4 查
select * from tb12;
select id,name from tb12;
select id,name from tb12 where id > 10 or name ='xxx';
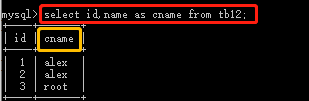
select name as cname,age from tb12; #查数据,并把表头的name改为cname
select id,name as cname from tb12 where id > 10 or name ='xxx';
select name,age,11 from tb12; #多出一列,数据全部为11
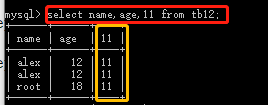
其他:
select * from tb12 where id != 1
select * from tb12 where id in (1,5,12); #取id为1、5、12的数据
select * from tb12 where id not in (1,5,12); #取id不为1、5、12的数据
select * from tb12 where id in (select id from tb11) #先把tb11的id取出来,作为tb12要查的id
select * from tb12 where id between 5 and 12; #取id为5到12的数据(闭区间)
通配符:
select * from tb12 where name like "a%" #查name以a为开头的数据
select * from tb12 where name like "%a%" #查name中带a的数据
select * from tb12 where name like "a_" #查name以a开头,后面只带一位的数据,比如 ab、ag
分页:
select * from tb12 limit 10; #查看前10条
select * from tb12 limit 0,10; #从第0行开始读取,读取10行;
select * from tb12 limit 10,10; #从第10行开始读取,读取10行;
select * from tb12 limit 20,10; #从第20行开始读取,读取10行;
select * from tb12 limit 10 offset 20; #从第20行开始读取,读取10行; #结合Python分页:
page = input('请输入要查看的页码')
page = int(page)
(page-1) * 10
select * from tb12 limit 0,10; #查看第1页数据
select * from tb12 limit 10,10;2 #查看第2页数据
排序:
select * from tb12 order by id desc; #id从大到小排
select * from tb12 order by id asc; #id从小到大排
select * from tb12 order by age desc,id desc; #age从大到小排,id从大到小排(如果age数相同,就按照id从大到小排)
select * from tb12 order by id desc limit 10; #取后10条数据
创建部门与员工表:
create table department5(
id int auto_increment primary key,
title varchar(32)
)engine=innodb default charset=utf8;
insert into department5(title) values('经理'),('销售'),('管理'),('财务');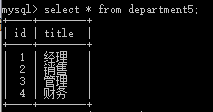
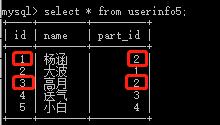
create table userinfo5(
id int auto_increment primary key,
name varchar(32),
part_id int,
CONSTRAINT fk_user_part FOREIGN key (part_id) REFERENCES department5(id)
)engine=innodb default charset=utf8;
insert into userinfo5(name,part_id) values('杨涵',2),('大波',1),('高月',2),('送气',3),('小白',4);
分组:
max:
#按par_id进行分类,如果part_id相同,就取id最大的那个进行分类 count:
此外还有min、sum、avg 如果对于聚合函数结果进行二次筛选时?必须使用having
例如果想筛选出id大于1的part_id:
也可以用where,但后面不能加聚合函数
连表操作:
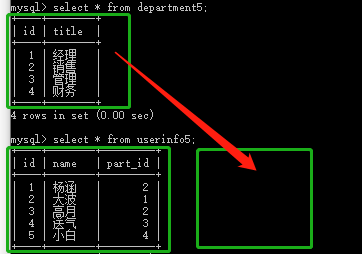
做法:select * from userinfo5,department5 where userinfo5.part_id = department5.id
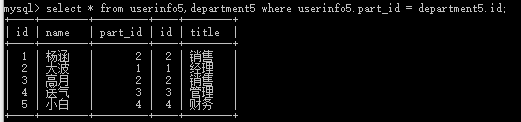
推荐下面写法:

(1)select * from userinfo5 left join department5 on userinfo5.part_id = department5.id; #userinfo5左边全部显示,因为userinfo5中没有对应department5中的刘洋,所以不显示刘洋
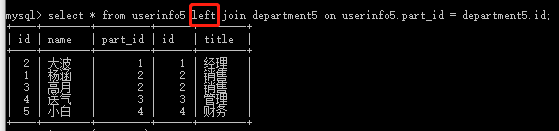
(2) select * from userinfo5 right join department5 on userinfo5.part_id = department5.id; #department5右边全部显示
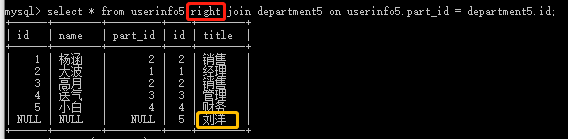
(3)select * from userinfo5 innder join department5 on userinfo5.part_id = department5.id; #将出现null时的一行隐藏
(4)select count(id) from userinfo5; #统计userinfo5中的数据个数

cmd中导出现有数据库数据:
mysqldump -u用户名 -p密码 数据库名称 >导出文件路径 #结构+数据
mysqldump -u用户名 -p密码 -d数据库名称 >导出文件路径 #结构
导出现有数据库数据:
mysqldump -u用户名 -p密码 数据库名称 <文件路径
4、相关知识
1、临时表:把查出来的数据用()括起来,加上as+名称就能生成临时表
select * from (select * from tb where id<10) as B; #这里 (select * from tb where id<10) as B 就是一个临时表,名称为B
2、指定映射:
select id,name,1,sum(x)/count()
3、条件:
case when id>8 then xx else xx end
4、三元运算:
if(isnull(xx),0,1) #如果xx为空取0,否则取1
5、union
join执行的是左右连表,union执行的是上下连表
# 自动去重
select id,name from tb1
union
select num,sname from tb2 # 不去重
select sid,sname from student
UNION ALL
select sid,sname from student
注:group by,having语句中可以存在where,但where要放到group by, having的前面,表示先进行一次筛选,在筛选出的结果中再执行group by,having
作业练习:http://www.cnblogs.com/wupeiqi/articles/5729934.html
参考答案:https://www.cnblogs.com/wupeiqi/p/5748496.html
MySQL之唯一索引、外键的变种、SQL语句数据行操作补充的更多相关文章
- mysql更新(五) 完整性约束 外键的变种 三种关系 数据的增删改
11-数据的增删改 本节重点: 插入数据 INSERT 更新数据 UPDATE 删除数据 DELETE 再来回顾一下之前我们练过的一些操作,相信大家都对插入数据.更新数据.删除数据有了全面的认识. ...
- 2-16 MySQL字段约束-索引-外键
一:字段修饰符 1:null和not null修饰符 我们通过这个例子来看看 mysql> create table worker(id int not null,name varchar(8) ...
- mysql字段约束-索引-外键---3
本节所讲内容: 字段修饰符 清空表记录 索引 外键 视图 一:字段修饰符 (约束) 1:null和not null修饰符 我们通过这个例子来看看 mysql> create table wo ...
- Python9-MySQL索引-外键-day43
1.以ATM引出DBMS2.MySQL -服务端 -客户端3.通信交流 -授权 -SQL语句 -数据库 create database db1 default charset=utf8; drop d ...
- MySQL数据库(3)- 完整性约束、外键的变种、单表查询
一.完整性约束 在创建表时候,约束条件和数据类型的宽度都是可选参数. 作用:用于保证数据的完整性和一致性. 1.not null(不可空)与default 示例一:插入一个空值,如下: mysql&g ...
- python 全栈开发,Day62(外键的变种(三种关系),数据的增删改,单表查询,多表查询)
一.外键的变种(三种关系) 本节重点: 如何找出两张表之间的关系 表的三种关系 一.介绍 因为有foreign key的约束,使得两张表形成了三种了关系: 多对一 多对多 一对一 二.重点理解如果找出 ...
- (原)未能启用约束。一行或多行中包含违反非空、唯一或外键约束的值与DATEADD
SQLServer2014,查询分析器中 这样的脚本是没有问题的:AND TPO.CREATEON <= DATEADD(DAY, 1, '2017/3/3 0:00:00') 但.NET D ...
- MySQL 创建唯一索引忽略对已经重复数据的检查
MySQL 创建唯一索引忽略对已经重复数据的检查 在创建唯一索引的基础上加上关键字"IGNORE "即可.(注意,经测试,在5.7版本已经不再支持该参数) # 重复数据 mysql ...
- mysql(1)—— 详解一条sql语句的执行过程
SQL是一套标准,全称结构化查询语言,是用来完成和数据库之间的通信的编程语言,SQL语言是脚本语言,直接运行在数据库上.同时,SQL语句与数据在数据库上的存储方式无关,只是不同的数据库对于同一条SQL ...
随机推荐
- 【转载】卸载Anaconda教程
文章来源:https://docs.continuum.io/anaconda/install/uninstall/ 卸载Anaconda 要卸载Anaconda,您可以简单地删除该程序.这将留下一些 ...
- spring-cloud-gateway静态路由
为什么引入 API 网关 使用 API 网关后的优点如下: 易于监控.可以在网关收集监控数据并将其推送到外部系统进行分析. 易于认证.可以在网关上进行认证,然后再将请求转发到后端的微服务,而无须在每个 ...
- php基本数据类型解说
一.简介: php语言是弱类型语言,声明变量的时候不需要指定数据类型.但每个数值都是有数据类型的.PHP共有九种数据类型. php基本数据类型共有四种:boolean(布尔型),integer(整型) ...
- TCP 的断包和粘包
以太网中存在一个对于帧的有效数据大小的限制,即 MTU,以太网的 MTU 为 1500 字节. 一.断包 就是说发送端一次发送的消息长度过大,如果超过了 MTU,那么 ip 会对其进行分片. 在网络编 ...
- 加密解密 Python
常见加密方式和Python实现 1. 前言 我们所说的加密方式,都是对二进制编码的格式进行加密的,对应到Python中,则是我们的Bytes. 所以当我们在Python中进行加密操作的时候,要确保我们 ...
- python 开发工具简介
一.python 开发工具简介 1.IDLE IDLE是开发python程序的基本IDE(集成开发环境),具备基本的IDE的功能,是非商业Python开发的不错的选择.当安装好python以后,IDL ...
- PHP序列化及反序列化分析学习小结
PHP反序列化 最近又遇到php反序列化,就顺便来做个总结. 0x01 PHP序列化和反序列化 php序列化:php对象 序列化的最主要的用处就是在传递和保存对象的时候,保证对象的完整性和可传递性.序 ...
- 《Python Enhancement Proposal #8》要点 学习摘录
<Python Enhancement Proposal #8> (8号python增强提案)又叫PEP8,他针对的python代码格式而编订的风格指南. 空白 使用space来表示缩进, ...
- C语言atoi函数
目录 1.包含头文件 2.函数声明 3.功能说明 4.示例 5.其它说明 6.版权声明 C语言提供了一系列函数把字符串转换为整数:atoi.atol.atoll和atoq. 1.包含头文件 #incl ...
- java web知识点复习,重新编写学生选课系统的先关操作。
为了复习之前学习的相关的html,javaweb等知识.自己有重新编写了一遍学生选课系统. 下面主要展示登录界面的代码,以及各个大的主页面的相关jsp. <%@ page language=&q ...