【Spark】通过SparkStreaming实现从socket接受数据,并进行简单的单词计数
步骤
一、创建maven工程并导入jar包
<properties><scala.version>2.11.8</scala.version><spark.version>2.2.0</spark.version></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>${spark.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.11</artifactId><version>2.2.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.5</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.11</artifactId><version>2.2.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency></dependencies><build><sourceDirectory>src/main/scala</sourceDirectory><testSourceDirectory>src/test/scala</testSourceDirectory><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.0</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding><!-- <verbal>true</verbal>--></configuration></plugin><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.0</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals><configuration><args><arg>-dependencyfile</arg><arg>${project.build.directory}/.scala_dependencies</arg></args></configuration></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><filters><filter><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass></mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins></build>
二、安装并启动生产者
在node01安装nc工具
yum -y install nc
使用nc工具向指定端口发送数据
nc -lk 9999
三、开发SparkStreaming代码
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}import org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.streaming.{Seconds, StreamingContext}object WordCountTest {def main(args: Array[String]): Unit = {//获取SparkConfval sparkConf: SparkConf = new SparkConf().setAppName("Streaming_WordCountTest").setMaster("local[4]").set("spark.driver.host", "localhost")//获取SparkContextval sparkContext: SparkContext = new SparkContext(sparkConf)//设置日志级别sparkContext.setLogLevel("WARN")//获取StreamingContext 需要两个参数 SparkContext和duration,后者就是间隔时间val streamContext: StreamingContext = new StreamingContext(sparkContext, Seconds(5))//从socket获取数据val stream: ReceiverInputDStream[String] = streamContext.socketTextStream("node01", 9999)//对数据进行计数操作val result: DStream[(String, Int)] = stream.flatMap(x => x.split(" ")).map((_, 1)).reduceByKey(_ + _)//输出数据result.print()//启动程序streamContext.start()streamContext.awaitTermination()}}
四、查看结果
nc工具发送的数据
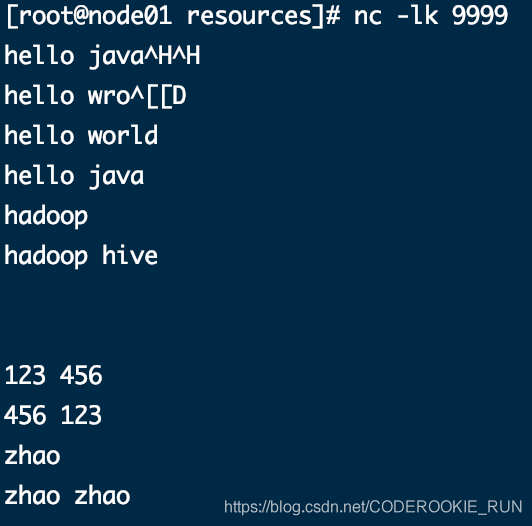
控制台结果-----------------------------------------Time: 1586852050000 ms-------------------------------------------(hive,1)(wro,1)(hadoop,2)(hello,4)(java,1)(ja,1)(world,1)-------------------------------------------Time: 1586852055000 ms--------------------------------------------------------------------------------------Time: 1586852060000 ms-------------------------------------------20/04/14 16:14:23 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.20/04/14 16:14:23 WARN BlockManager: Block input-0-1586852063400 replicated to only 0 peer(s) instead of 1 peers20/04/14 16:14:24 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.20/04/14 16:14:24 WARN BlockManager: Block input-0-1586852064000 replicated to only 0 peer(s) instead of 1 peers-------------------------------------------Time: 1586852065000 ms-------------------------------------------(,2)20/04/14 16:14:29 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.20/04/14 16:14:29 WARN BlockManager: Block input-0-1586852069600 replicated to only 0 peer(s) instead of 1 peers-------------------------------------------Time: 1586852070000 ms-------------------------------------------(456,1)(123,1)20/04/14 16:14:31 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.20/04/14 16:14:31 WARN BlockManager: Block input-0-1586852071200 replicated to only 0 peer(s) instead of 1 peers20/04/14 16:14:34 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.20/04/14 16:14:34 WARN BlockManager: Block input-0-1586852073800 replicated to only 0 peer(s) instead of 1 peers-------------------------------------------Time: 1586852075000 ms-------------------------------------------(zhao,1)(456,1)(123,1)20/04/14 16:14:36 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.20/04/14 16:14:36 WARN BlockManager: Block input-0-1586852076200 replicated to only 0 peer(s) instead of 1 peers-------------------------------------------Time: 1586852080000 ms-------------------------------------------(zhao,2)-------------------------------------------Time: 1586852085000 ms--------------------------------------------------------------------------------------Time: 1586852090000 ms-------------------------------------------
【Spark】通过SparkStreaming实现从socket接受数据,并进行简单的单词计数的更多相关文章
- C# Socket 接受数据不全的处理
由于Socket 一次传输数据有限,因此需要多次接受数据传输. 解决办法一: int numberOfBytesRead = 0; int totalNumberOfBytes = 0 ...
- spark-streaming集成Kafka处理实时数据
在这篇文章里,我们模拟了一个场景,实时分析订单数据,统计实时收益. 场景模拟 我试图覆盖工程上最为常用的一个场景: 1)首先,向Kafka里实时的写入订单数据,JSON格式,包含订单ID-订单类型-订 ...
- Spark Streaming源码解读之流数据不断接收和全生命周期彻底研究和思考
本节的主要内容: 一.数据接受架构和设计模式 二.接受数据的源码解读 Spark Streaming不断持续的接收数据,具有Receiver的Spark 应用程序的考虑. Receiver和Drive ...
- spark or sparkstreaming的内存泄露问题?
关于sparkstreaming的无法正常产生数据---->到崩溃---->到数据读写极为缓慢(或块丢失?)问题 前两阶段请看我的博客:https://www.cnblogs.com/wa ...
- 3 python3 编码解码问题 upd接受数据
1.python3下的中文乱码:send_data.encode("utf-8") from socket import * udp_socket = socket(AF_INET ...
- 【Spark】SparkStreaming与flume进行整合
文章目录 注意事项 SparkStreaming从flume中poll数据 步骤 一.开发flume配置文件 二.启动flume 三.开发sparkStreaming代码 1.创建maven工程,导入 ...
- C#上位机制作之串口接受数据(利用接受事件)
前面设计好了界面,现在就开始写代码了,首先定义一个串口对象.. SerialPort serialport = new SerialPort();//定义串口对象 添加串口扫描函数,扫描出来所有可用串 ...
- dsp28377控制DM9000收发数据——第三版程序,通过外部引脚触发来实现中断接受数据,优化掉帧现象
//-------------------------------------------------------------------------------------------- - //D ...
- PHP+socket游戏数据统计平台发包接包类库
<?php /** * @title: PHP+socket游戏数据统计平台发包接包类库 * @version: 1.0 * @author: perry <perry@1kyou.com ...
随机推荐
- self不明白什么意思,我来帮助你了解self的含义
先看下面这段代码 # 用函数模仿类def dog(name, gender): def jiao(dog1): print('%s汪汪叫' % dog1["name"]) def ...
- [php] 猴子偷桃
<?php /* 10:五只猴子采得一堆桃子,猴子彼此约定隔天早起后再分食. 不过,就在半夜里,一只猴子偷偷起来,把桃子均分成五堆后, 发现还多一个,它吃掉这桃子,并拿走了其中一堆.第二只猴子醒 ...
- C++调用TensorFlow
在使用C++调用TensorFlow接口时出现的问题,网上没有资料,问了老师才知道的. Exception ignored in: <module 'threading' from 'E:\\t ...
- Springboot:属性常量赋值以及yml配置文件语法(四)
方式一: 注解赋值 构建javaBean:com\springboot\vo\Dog 1:@Component:注册bean到spring容器中 2:添加get set toString方法 3:使用 ...
- gloo基本知识
Architechture(架构) Gloo通过Envoy XDS gRPC API来动态更新Envoy配置, 更方便的控制Envoy Proxy, 并保留扩展性..本质是一个Envoy xDS配置翻 ...
- 重大更新!Druid 0.18.0 发布—Join登场,支持Java11
Apache Druid本质就是一个分布式支持实时数据分析的数据存储系统. 能够快速的实现查询与数据分析,高可用,高扩展能力. 距离上一次更新刚过了二十多天,距离0.17版本刚过了三个多月,Druid ...
- Java Web教程——检视阅读
Java Web教程--检视阅读 参考 java web入门--概念理解.名词解释 Java Web 教程--w3school 蓝本 JavaWeb学习总结(一)--JavaWeb开发入门 小猴子mo ...
- 编程语言千千万,为什么学习Python的占一半?
如果让你从数百种的编程语言中选择一个入门语言?你会选择哪一个? 是应用率最高.长期霸占排行榜的常青藤 Java?是易于上手,难以精通的 C?还是在游戏和工具领域仍占主流地位的 C++?亦或是占据 Wi ...
- DEDE中自定义表单HTML 怎么写
用DEDE嵌套网站时,有时我们需要添加自定义字段,而自定义字段的HTML样式如何设置呢? 功能地图(核心/频道模型/内容模型管理/)——普通文章的修改——字段管理——你的自定义字段的修改——最下面自定 ...
- Linux系统管理第一次作业 系统命令
上机作业: 1.请用命令查出ifconfig命令程序的绝对路径 [root@localhost ~]# which ifconfig /usr/sbin/ifconfig 2.请用命令展示以下命令哪 ...