你知道Spring是怎么解析配置类的吗?
彻底读懂Spring(二)你知道Spring是怎么解析配置类的吗?
推荐阅读:
Spring执行流程图如下:
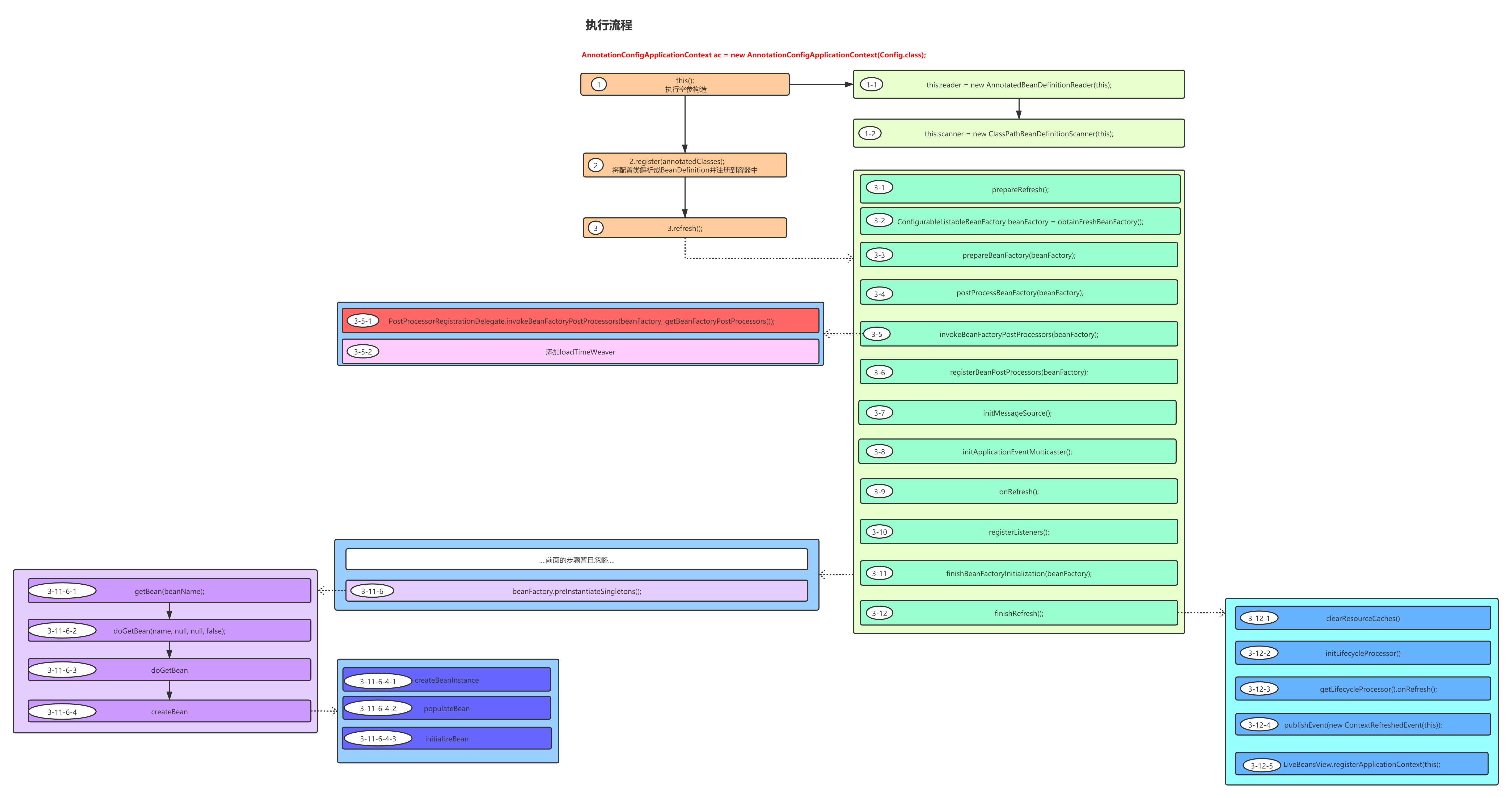
如果图片显示不清楚可以访问如下链接查看高清大图:
这个流程图会随着我们的学习不断的变得越来越详细,也会越来越复杂,希望在这个过程中我们都能朝着精通Spring的目标不断前进!
在上篇文章我们学习了Spring中的第一行代码,我们已经知道了Spring中的第一行代码其实就是创建了一个
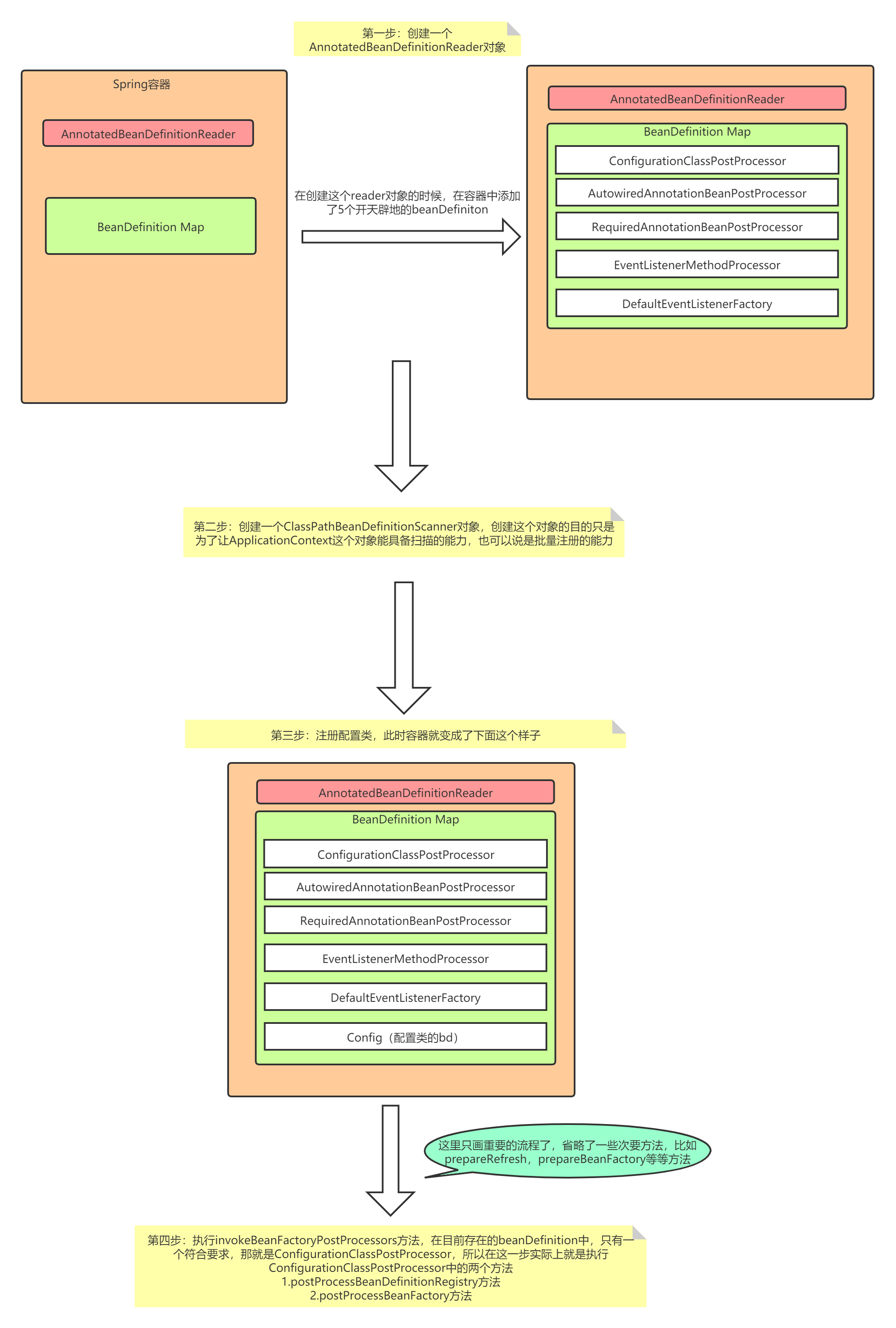
AnnotatedBeanDefinitionReader对象,这个对象的主要作用就是注册bd(BeanDefinition)到容器中。并且在创建这个对象的过程中,Spring还为容器注册了开天辟地的几个bd,包括ConfigurationClassPostProcessor,AutowiredAnnotationBeanPostProcessor等等。那么在本文中,我们就一起来看看Spring中的第二行代码又做了些什么?
Spring中的第二行代码
第二行代码在上面的流程图中已经标注的非常明白了,就是
this.scanner = new ClassPathBeanDefinitionScanner(this);
只是简单的创建了一个ClassPathBeanDefinitionScanner对象。那么这个ClassPathBeanDefinitionScanner有什么作用呢?从名字上来看好像就是这个对象来完成Spring中的扫描的,真的是这样吗?希望同学们能带着这两个问题往下看
ClassPathBeanDefinitionScanner源码分析
这个类名直译过来就是:类路径下的BeanDefinition的扫描器,所以我们就直接关注其扫描相关的方法,就是其中的doScan方法。其代码如下:
// 这个方法会完成对指定包名下的class文件的扫描
// basePackages:指定包名,是一个可变参数
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
// 1.findCandidateComponents这个方法是实际完成扫描的方法,也是接下来我们要分析的方法
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {、
// 上篇文章中我们已经分析过了,完成了@Scope注解的解析
// 参考《彻底读懂Spring(一)读源码,我们可以从第一行读起》
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
// 2.如果你对BeanDefinition有一定了解的话,你肯定会知道这个判断一定会成立的,这意味着 // 所有扫描出来的bd都会执行postProcessBeanDefinition方法进行一些后置处理
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
// 3. 是不是一个AnnotatedBeanDefinition,如果是的话,还需要进行额外的处理
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 4.检查容器中是否已经有这个bd了,如果有就不进行注册了
if (checkCandidate(beanName, candidate)) {
// 下面这段逻辑在上篇文章中都已经分析过了,这里就直接跳过了
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
上面这段代码主要做了四件事
- 通过
findCandidateComponents方法完成扫描 - 判断扫描出来的bd是否是一个
AbstractBeanDefinition,如果是的话执行postProcessBeanDefinition方法 - 判断扫描出来的bd是否是一个
AnnotatedBeanDefinition,如果是的话执行processCommonDefinitionAnnotations方法 - 检查容器中是否已经有这个bd了,如果有就不进行注册了
接下来我们就一步步分析这个方法,搞明白ClassPathBeanDefinitionScanner到底能起到什么作用
1、通过findCandidateComponents方法完成扫描
findCandidateComponents方法源码如下:
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
// 正常情况下都是进入这个判断,对classpath下的class文件进行扫描
return scanCandidateComponents(basePackage);
}
}
- addCandidateComponentsFromIndex
不用过多关注这个方法。正常情况下Spring都是采用扫描classpath下的class文件来完成扫描,但是虽然基于classpath扫描速度非常快,但通过在编译时创建候选静态列表,可以提高大型应用程序的启动性能。在这种模式下,应用程序的所有模块都必须使用这种机制,因为当 ApplicationContext检测到这样的索引时,它将自动使用它而不是扫描类路径。
要生成索引,只需向包含组件扫描指令目标组件的每个模块添加附加依赖项即可:
Maven:org.springframework
spring-context-indexer
5.0.6.RELEASE
true大家有兴趣的话可以参考官网:https://docs.spring.io/spring/docs/5.1.14.BUILD-SNAPSHOT/spring-framework-reference/core.html#beans-scanning-index
这个依赖实在太大了,半天了拉不下来,我这里就不演示了
- scanCandidateComponents(basePackage)
正常情况下我们的应用都是通过这个方法完成扫描的,其代码如下:
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
// 用来存储返回的bd的集合
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// 拼接成这种形式:classpath*:com.dmz.spring
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 获取到所有的class文件封装而成的Resource对象
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
// 遍历得到的所有class文件封装而成的Resource对象
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
// 通过Resource构建一个MetadataReader对象,这个MetadataReader对象包含了对应class文件的解析出来的class的元信息以及注解元信息
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// 并不是所有的class文件文件都要被解析成为bd,只有被添加了注解(@Component,@Controller等)才是Spring中的组件
if (isCandidateComponent(metadataReader)) {
// 解析元信息(class元信息以及注解元信息)得到一个ScannedGenericBeanDefinition
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
// 省略多余的代码
return candidates;
}
在Spring官网阅读(一)容器及实例化一文中,我画过这样一张图
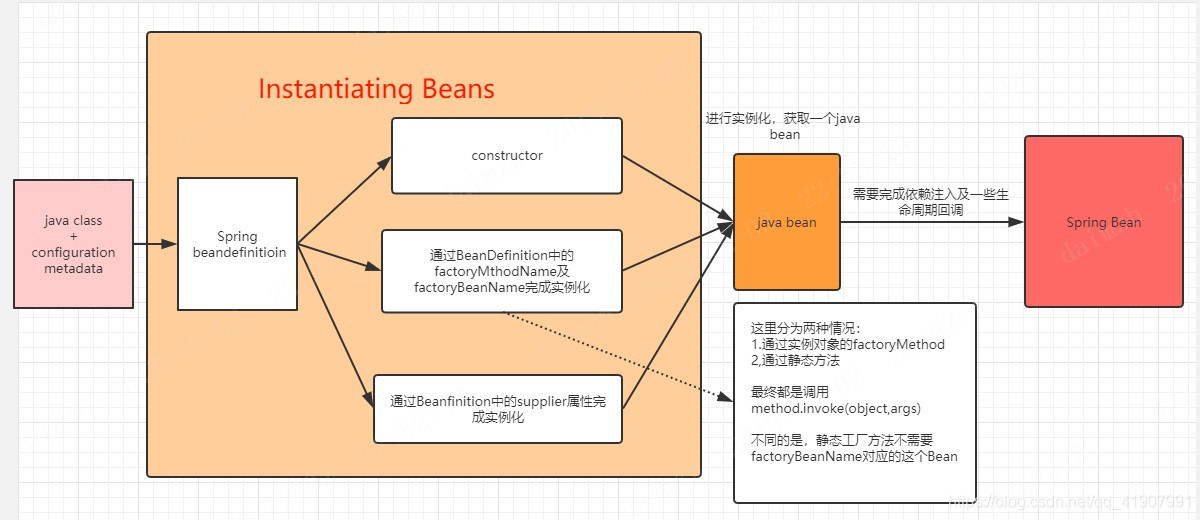
从上图中可以看出,java class + configuration metadata 最终会转换为一个BenaDefinition,结合我们上面的代码分析可以知道,java class + configuration metadata实际上就是一个MetadataReader对象,而转换成一个BenaDefinition则是指通过这个MetadataReader对象创建一个ScannedGenericBeanDefinition。
2、执行postProcessBeanDefinition方法
protected void postProcessBeanDefinition(AbstractBeanDefinition beanDefinition, String beanName) {
// 为bd中的属性设置默认值
beanDefinition.applyDefaults(this.beanDefinitionDefaults);
// 注解模式下这个值必定为null,使用XML配置时,
if (this.autowireCandidatePatterns != null) {
beanDefinition.setAutowireCandidate(PatternMatchUtils.simpleMatch(this.autowireCandidatePatterns, beanName));
}
}
// 设置默认值
public void applyDefaults(BeanDefinitionDefaults defaults) {
setLazyInit(defaults.isLazyInit());
setAutowireMode(defaults.getAutowireMode());
setDependencyCheck(defaults.getDependencyCheck());
setInitMethodName(defaults.getInitMethodName());
setEnforceInitMethod(false);
setDestroyMethodName(defaults.getDestroyMethodName());
setEnforceDestroyMethod(false);
}
可以看出,postProcessBeanDefinition方法最主要的功能就是给扫描出来的bd设置默认值,进一步填充bd中的属性
3、执行processCommonDefinitionAnnotations方法
这句代码将进一步解析class上的注解信息,Spring在创建这个abd的信息时候就已经将当前的class放入其中了,所有这行代码主要做的就是通过class对象获取到上面的注解(包括@Lazy,@Primary,@DependsOn注解等等),然后将得到注解中对应的配置信息并放入到bd中的属性中
4、注册BeanDefinition
跟彻底读懂Spring(一)读源码,我们可以从第一行读起的注册逻辑是一样的
通过上面的分析,我们已经知道了ClassPathBeanDefinitionScanner的作用,毋庸置疑,Spring肯定是通过这个类来完成扫描的,但是问题是,Spring是通过第二步创建的这个对象来完成扫描的吗?我们再来看看这个ClassPathBeanDefinitionScanner的创建过程:
// 第一步
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry) {
this(registry, true);
}
// 第二步
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters) {
this(registry, useDefaultFilters, getOrCreateEnvironment(registry));
}
// 第三步
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment) {
this(registry, useDefaultFilters, environment,
(registry instanceof ResourceLoader ? (ResourceLoader) registry : null));
}
// 第四步
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, @Nullable ResourceLoader resourceLoader) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
this.registry = registry;
if (useDefaultFilters) {
// 注册默认的扫描过滤规则(要被@Component注解修饰)
registerDefaultFilters();
}
setEnvironment(environment);
setResourceLoader(resourceLoader);
}
在这个ClassPathBeanDefinitionScanner的创建过程中我们全程无法干涉,不能对这个ClassPathBeanDefinitionScanner进行任何配置。而我们在配置类上明明是可以对扫描的规则进行配置的,例如:
@ComponentScan(value = "com.spring.study.springfx.aop.service", useDefaultFilters = true,
excludeFilters = @ComponentScan.Filter(type = FilterType.ASSIGNABLE_TYPE, classes = {IndexService.class}))
所以Spring中肯定不是使用在这里创建的这个ClassPathBeanDefinitionScanner对象。
实际上真正完成扫描的时机是在我们流程图中的3-5-1步。完成扫描这个功能的类就是我们在上篇文章中所提到的ConfigurationClassPostProcessor。接下来我们就通过这个类,看看Spring到底是如何完成的扫描,这也是本文重点想要说明的问题
Spring是怎么解析配置类的?
1、解析时机分析
解析前Spring做了什么?
注册配置类
在分析扫描时机之前我们先回顾下之前的代码,整个程序的入口如下:
public AnnotationConfigApplicationContext(Class<?>... annotatedClasses) {
this();
register(annotatedClasses);
refresh();
}
其中在this()空参构造中Spring实例化了两个对象,一个是AnnotatedBeanDefinitionReader,在上篇文章中已经介绍过了,另外一个是ClassPathBeanDefinitionScanner,在前文中也进行了详细的分析。
在完成这两个对象的创建后,Spring紧接着就利用第一步中创建的AnnotatedBeanDefinitionReader去将配置类注册到了容器中。看到这里不知道大家有没有一个疑问,既然Spring是直接通过这种方式来注册配置类,为什么我们还非要在配置类上添加@Configuration注解呢?按照这个代码的话,我不在配置类上添加任何注解,也能将配置类注册到容器中,例如下面这样:
public class Config {
}
public class Main {
public static void main(String[] args) throws Exception {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(Config.class);
System.out.println(ac.getBean("config"));
// 程序输出:com.spring.study.springfx.aop.Config@7b69c6ba
// 意味着Config被注册到了容器中
}
}
大家仔细想想我这个问题,不妨带着这些疑问继续往下看。
调用refresh方法
在将配置类注册到容器中后,Spring紧接着又调用了refresh方法,其源码如下:
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// 这个方法主要做了以下几件事
// 1.记录容器的启动时间,并将容器状态更改为激活
// 2.调用initPropertySources()方法,主要用于web环境下初始化封装相关的web资源,比如将servletContext封装成为ServletContextPropertySource
// 3.校验环境中必要的属性是否存在
// 4.提供了一个扩展点可以提前放入一些事件,当applicationEventMulticaster这个bean被注册到容器中后就直接发布事件
prepareRefresh();
// 实际上获取的就是一个DefaultListableBeanFactory
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// 为bean工厂设置一些属性
prepareBeanFactory(beanFactory);
try {
// 提供给子类复写的方法,允许子类在这一步对beanFactory做一些后置处理
postProcessBeanFactory(beanFactory);
// 执行已经注册在容器中的bean工厂的后置处理器,在这里完成的扫描
invokeBeanFactoryPostProcessors(beanFactory);
// 后面的代码跟扫描无关,我们在之后的文章再介绍
}
// .....
}
}
大部分的代码都写了很详细的注释,对于其中两个比较复杂的方法我们单独分析
- prepareBeanFactory
- invokeBeanFactoryPostProcessors
prepareBeanFactory做了什么?
protected void prepareBeanFactory(ConfigurableListableBeanFactory beanFactory) {
// 设置classLoader,一般就是appClassLoader
beanFactory.setBeanClassLoader(getClassLoader());
// 设置el表达式解析器
beanFactory.setBeanExpressionResolver(new StandardBeanExpressionResolver(beanFactory.getBeanClassLoader()));
// 容器中添加一个属性编辑器注册表,关于属性编辑在《Spring官网阅读(十四)Spring中的BeanWrapper及类型转换》有过详细介绍,这里就不再赘述了
beanFactory.addPropertyEditorRegistrar(new ResourceEditorRegistrar(this, getEnvironment()));
// 添加了一个bean的后置处理器,用于执行xxxAware方法
beanFactory.addBeanPostProcessor(new ApplicationContextAwareProcessor(this));
// 自动注入模型下,如果bean中存在以下类型的依赖,不进行注入
beanFactory.ignoreDependencyInterface(EnvironmentAware.class);
beanFactory.ignoreDependencyInterface(EmbeddedValueResolverAware.class);
beanFactory.ignoreDependencyInterface(ResourceLoaderAware.class);
beanFactory.ignoreDependencyInterface(ApplicationEventPublisherAware.class);
beanFactory.ignoreDependencyInterface(MessageSourceAware.class);
beanFactory.ignoreDependencyInterface(ApplicationContextAware.class);
// 为什么我们能直接将ApplicationContext等一些对象直接注入到bean中呢?就是下面这段代码的作用啦!
// Spring在进行属性注入时会从resolvableDependencies的map中查找是否有对应类型的bean存在,如果有的话就直接注入,下面这段代码就是将对应的bean放入到resolvableDependencies这个map中
beanFactory.registerResolvableDependency(BeanFactory.class, beanFactory);
beanFactory.registerResolvableDependency(ResourceLoader.class, this);
beanFactory.registerResolvableDependency(ApplicationEventPublisher.class, this);
beanFactory.registerResolvableDependency(ApplicationContext.class, this);
// 添加一个后置处理器,用于处理ApplicationListener
beanFactory.addBeanPostProcessor(new ApplicationListenerDetector(this));
// 是否配置了LTW,也就是在类加载时期进行织入,一般都不会配置
if (beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
// 加载时期织入会配置一个临时的类加载器
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
// 配置一些默认的环境相关的bean
if (!beanFactory.containsLocalBean(ENVIRONMENT_BEAN_NAME)) {
beanFactory.registerSingleton(ENVIRONMENT_BEAN_NAME, getEnvironment());
}
if (!beanFactory.containsLocalBean(SYSTEM_PROPERTIES_BEAN_NAME)) {
beanFactory.registerSingleton(SYSTEM_PROPERTIES_BEAN_NAME, getEnvironment().getSystemProperties());
}
if (!beanFactory.containsLocalBean(SYSTEM_ENVIRONMENT_BEAN_NAME)) {
beanFactory.registerSingleton(SYSTEM_ENVIRONMENT_BEAN_NAME, getEnvironment().getSystemEnvironment());
}
}
上面这段代码整体来说还是非常简单的,逻辑也很清晰,就是在为beanFactory做一些配置,我们需要注意的是跟后置处理器相关的内容,可以看到在这一步一共注册了两个后置处理器
- ApplicationContextAwareProcessor,用于执行xxxAware接口中的方法
- ApplicationListenerDetector,保证监听器被添加到容器中
关于ApplicationListenerDetector请参考Spring官网阅读(八)容器的扩展点(三)(BeanPostProcessor)
invokeBeanFactoryPostProcessors做了什么?
这个方法的执行流程在Spring官网阅读(六)容器的扩展点(一)BeanFactoryPostProcessor已经做过非常详细的分析了,其执行流程如下

整的来说,它就是将容器中已经注册的bean工厂的后置处理器按照一定的顺序进行执行。
那么到这一步为止,容器中已经有哪些bean工厂的后置处理器呢?
还记得我们在上篇文章中提到的ConfigurationClassPostProcessor吗?在创建AnnotatedBeanDefinitionReader的过程中它对应的BeanDefinition就被注册到容器中了。接下来我们就来分析ConfigurationClassPostProcessor这个类的源码
ConfigurationClassPostProcessor源码分析
它实现了BeanDefinitionRegistryPostProcessor,所以首先执行它的postProcessBeanDefinitionRegistry方法,其源码如下
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
// 生成一个注册表ID
int registryId = System.identityHashCode(registry);
//.....
// 表明这个工厂已经经过了后置处理器了
this.registriesPostProcessed.add(registryId);
// 从名字来看这个方法是再对配置类的bd进行处理
processConfigBeanDefinitions(registry);
}
processConfigBeanDefinitions方法的代码很长,我们拆分一段段分析,先看第一段
第一段
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
// ========第一段代码========
List<BeanDefinitionHolder> configCandidates = new ArrayList<>();
// 大家可以思考一个问题,当前容器中有哪些BeanDefinition呢?
// 这个地方应该能获取到哪些名字?
String[] candidateNames = registry.getBeanDefinitionNames();
for (String beanName : candidateNames) {
// 根据名称获取到对应BeanDefinition
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
// 省略日志打印
// 检查是否是配置类,在这里会将对应的bd标记为FullConfigurationClass或者LiteConfigurationClass
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
// 是配置类的话,将这个bd添加到configCandidates中
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
}
// 没有配置类,直接返回
if (configCandidates.isEmpty()) {
return;
}
// 根据@Order注解进行排序
configCandidates.sort((bd1, bd2) -> {
int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());
return Integer.compare(i1, i2);
});
// .....
上面这段代码有这么几个问题:
- 当前容器中有哪些BeanDefinition
如果你看过上篇文章的话应该知道,在创建AnnotatedBeanDefinitionReader对象的时候Spring已经往容器中注册了5个BeanDefinition,再加上注册的配置类,那么此时容器中应该存在6个BeanDefinition,我们可以打个断点验证
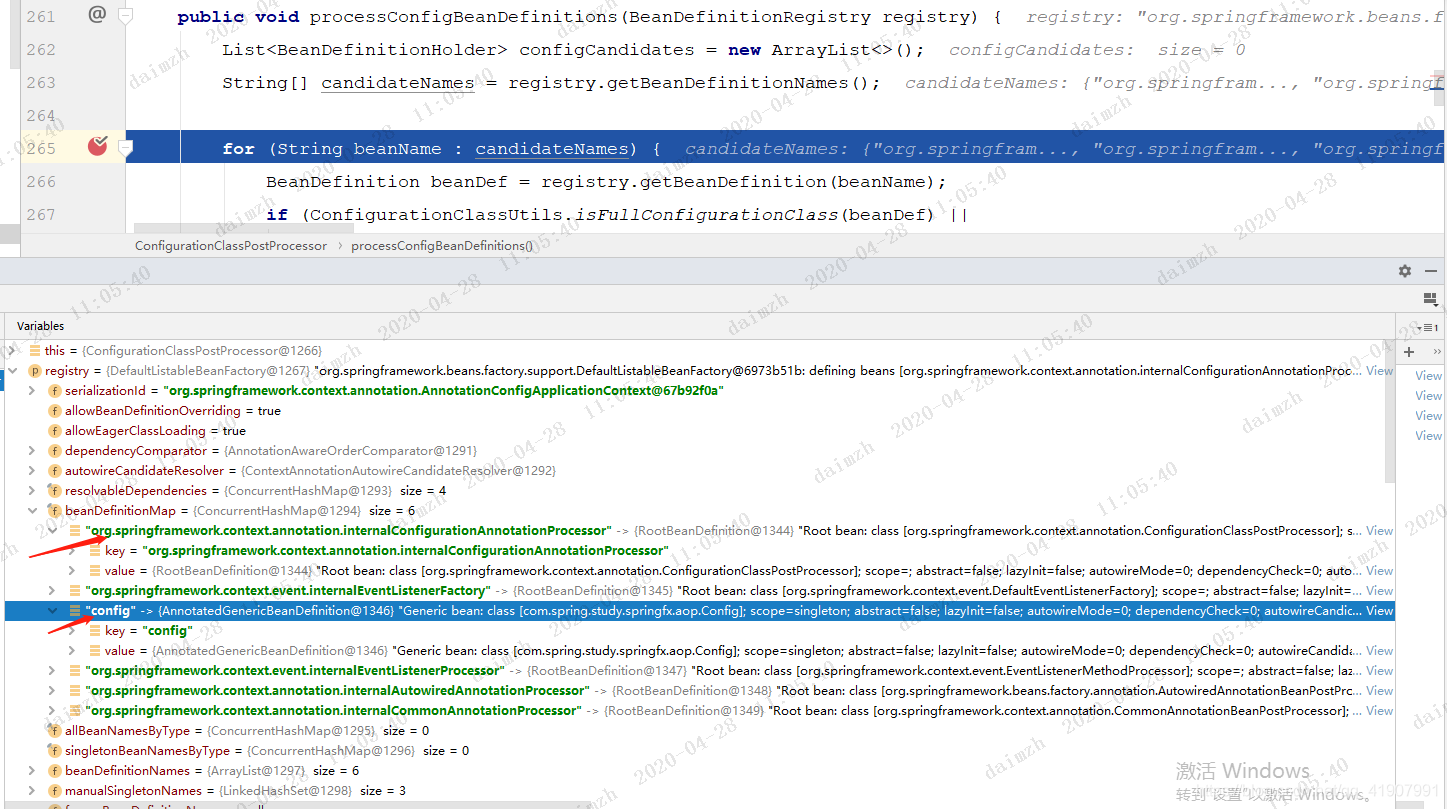
不出所料,确实是6个
- checkConfigurationClassCandidate
代码如下:
public static boolean checkConfigurationClassCandidate(
BeanDefinition beanDef, MetadataReaderFactory metadataReaderFactory) {
String className = beanDef.getBeanClassName();
if (className == null || beanDef.getFactoryMethodName() != null) {
return false;
}
// 下面这一段都是为了获取一个AnnotationMetadata
// AnnotationMetadata包含了对应class上的注解元信息以及class元信息
AnnotationMetadata metadata;
if (beanDef instanceof AnnotatedBeanDefinition &&
className.equals(((AnnotatedBeanDefinition) beanDef).getMetadata().getClassName())) {
// 已经解析过了,比如注册的配置类就属于这种,直接从bd中获取
metadata = ((AnnotatedBeanDefinition) beanDef).getMetadata();
}
else if (beanDef instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) beanDef).hasBeanClass()) {
// 拿到字节码重新解析获取到一个AnnotationMetadata
Class<?> beanClass = ((AbstractBeanDefinition) beanDef).getBeanClass();
metadata = new StandardAnnotationMetadata(beanClass, true);
}
else {
try {
// class属性都没有,就根据className利用ASM字节码技术获取到这个AnnotationMetadata
MetadataReader metadataReader = metadataReaderFactory.getMetadataReader(className);
metadata = metadataReader.getAnnotationMetadata();
}
catch (IOException ex) {
return false;
}
}
// 如果被@Configuration注解标注了,说明是一个FullConfigurationCandidate
if (isFullConfigurationCandidate(metadata)) {
beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_FULL);
}
// 如果被这些注解标注了,@Component,@ComponentScan,@Import,@ImportResource
// 或者方法上有@Bean注解,那么就是一个LiteConfigurationCandidate
// 也就是说你想把这个类当配置类使用,但是没有添加@Configuration注解
else if (isLiteConfigurationCandidate(metadata)) {
beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_LITE);
}
else {
return false;
}
// 解析@Order注解,用于排序
Integer order = getOrder(metadata);
if (order != null) {
beanDef.setAttribute(ORDER_ATTRIBUTE, order);
}
return true;
}
第二段
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
// 第一段
// .....
SingletonBeanRegistry sbr = null;
if (registry instanceof SingletonBeanRegistry) {
sbr = (SingletonBeanRegistry) registry;
// beanName的生成策略,不重要
if (!this.localBeanNameGeneratorSet) {
BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(CONFIGURATION_BEAN_NAME_GENERATOR);
if (generator != null) {
this.componentScanBeanNameGenerator = generator;
this.importBeanNameGenerator = generator;
}
}
}
if (this.environment == null) {
this.environment = new StandardEnvironment();
}
// 核心目的就是创建这个ConfigurationClassParser对象
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
// 第三段
}
这段代码核心目的就是为了创建一个ConfigurationClassParser,这个类主要用于后续的配置类的解析。
第三段
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
// 第一段,第二段
// .....
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
do {
// 在第二段代码中创建了一个ConfigurationClassParser,这里就是使用这个parser来解析配置类
// 我们知道扫描就是通过@ComponentScan,@ComponentScans来完成的,那么不出意外必定是在这里完成的扫描
parser.parse(candidates);
// 校验在解析过程是中是否发生错误,同时会校验@Configuration注解的类中的@Bean方法能否被复写(被final修饰或者访问权限为private都不能被复写),如果不能被复写会抛出异常,因为cglib代理要通过复写父类的方法来完成代理,后文会做详细介绍
parser.validate();
// 已经解析过的配置类
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
// 移除已经解析过的配置类,防止重复加载了配置类中的bd
configClasses.removeAll(alreadyParsed);
// Read the model and create bean definitions based on its content
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
// 将通过解析@Bean,@Import等注解得到相关信息解析成bd被注入到容器中
this.reader.loadBeanDefinitions(configClasses);
alreadyParsed.addAll(configClasses);
candidates.clear();
// 如果大于,说明容器中新增了一些bd,那么需要重新判断新增的bd是否是配置类,如果是配置类,需要再次解析
if (registry.getBeanDefinitionCount() > candidateNames.length) {
String[] newCandidateNames = registry.getBeanDefinitionNames();
Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));
Set<String> alreadyParsedClasses = new HashSet<>();
for (ConfigurationClass configurationClass : alreadyParsed) {
alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());
}
for (String candidateName : newCandidateNames) {
if (!oldCandidateNames.contains(candidateName)) {
BeanDefinition bd = registry.getBeanDefinition(candidateName);
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&
!alreadyParsedClasses.contains(bd.getBeanClassName())) {
candidates.add(new BeanDefinitionHolder(bd, candidateName));
}
}
}
candidateNames = newCandidateNames;
}
}
while (!candidates.isEmpty());
// 注册ImportRegistry到容器中
// 当通过@Import注解导入一个全配置类A(被@Configuration注解修饰的类),A可以实现ImportAware接口
// 通过这个Aware可以感知到是哪个类导入的A
if (sbr != null && !sbr.containsSingleton(IMPORT_REGISTRY_BEAN_NAME)) {
sbr.registerSingleton(IMPORT_REGISTRY_BEAN_NAME, parser.getImportRegistry());
}
if (this.metadataReaderFactory instanceof CachingMetadataReaderFactory) {
((CachingMetadataReaderFactory) this.metadataReaderFactory).clearCache();
}
}
2、解析源码分析
在上面的源码分析中,我们已经能够确定了Spring是通过ConfigurationClassParser的parse方法来完成对配置类的解析的。Spring对类的取名可以说是很讲究了,ConfigurationClassParser直译过来就是配置类解析器。接着我们就来看看它的源码
2.1、parse方法
public void parse(Set<BeanDefinitionHolder> configCandidates) {
this.deferredImportSelectors = new LinkedList<>();
// 遍历所有的配置类,一个个完成解析
for (BeanDefinitionHolder holder : configCandidates) {
BeanDefinition bd = holder.getBeanDefinition();
try {
// 三个判断最终都会进入到同一个方法---->processConfigurationClass方法
if (bd instanceof AnnotatedBeanDefinition) {
parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());
}
else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) {
parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());
}
else {
parse(bd.getBeanClassName(), holder.getBeanName());
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to parse configuration class [" + bd.getBeanClassName() + "]", ex);
}
}
// 对ImportSelector进行延迟处理
processDeferredImportSelectors();
}
2.2、processConfigurationClass方法
protected void processConfigurationClass(ConfigurationClass configClass) throws IOException {
// 解析@Conditional注解,判断是否需要解析
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
// 判断解析器是否已经解析过这个配置类了
ConfigurationClass existingClass = this.configurationClasses.get(configClass);
// 不为null,说明已经解析过了
if (existingClass != null) {
// 如果这个要被解析的配置类是被@Import注解导入的
if (configClass.isImported()) {
// 并且解析过的配置类也是被导入的
if (existingClass.isImported()) {
// 那么这个配置类的导入类集合中新增当前的配置类的导入类,(A通过@Import导入了B,那么A就是B的导入类,B被A导入)
existingClass.mergeImportedBy(configClass);
}
// Otherwise ignore new imported config class; existing non-imported class overrides it.
// 如果已经解析过的配置类不是被导入的,那么直接忽略新增的这个被导入的配置类。也就是说如果一个配置类同时被@Import导入以及正常的
// 添加到容器中,那么正常添加到容器中的配置类会覆盖被导入的类
return;
}
else {
// Explicit bean definition found, probably replacing an import.
// Let's remove the old one and go with the new one.
// 就是说新要被解析的这个配置类不是被导入的,所以这种情况下,直接移除调原有的解析的配置类
// 为什么不是remove(existingClass)呢?可以看看hashCode跟equals方法
// remove(existingClass)跟remove(configClass)是等价的
this.configurationClasses.remove(configClass);
this.knownSuperclasses.values().removeIf(configClass::equals);
}
}
// Recursively process the configuration class and its superclass hierarchy.
// 下面这段代码主要是递归的处理配置类及其父类
// 将配置类封装成一个SourceClass方便进行统一的处理
SourceClass sourceClass = asSourceClass(configClass);
do {
// doxxx方法,真正干活的方法,对配置类进行处理,返回值是当前这个类的父类
sourceClass = doProcessConfigurationClass(configClass, sourceClass);
}
while (sourceClass != null);
this.configurationClasses.put(configClass, configClass);
}
2.3、doProcessConfigurationClass方法
protected final SourceClass doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass)
throws IOException {
// Recursively process any member (nested) classes first
// 递归处理内部类
processMemberClasses(configClass, sourceClass);
// Process any @PropertySource annotations
// 处理@PropertySources跟@PropertySource注解,将对应的属性资源添加容器中(实际上添加到environment中)
for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)) {
if (this.environment instanceof ConfigurableEnvironment) {
processPropertySource(propertySource);
}
else {
logger.warn("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +
"]. Reason: Environment must implement ConfigurableEnvironment");
}
}
// Process any @ComponentScan annotations、
// 处理@ComponentScan,@ComponentScans注解,真正进行扫描的地方就是这里
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
// 核心代码,在这里完成的扫描
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
// 检查扫描出来的bd是否是配置类,如果是配置类递归进行解析
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
// 一般情况下getOriginatingBeanDefinition获取到的都是null
// 什么时候不为null呢?,参考:ScopedProxyUtils.createScopedProxy方法
// 在创建一个代理的bd时不会为null
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
// 判断扫描出来的bd是否是一个配置类,如果是的话继续递归处理
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
// Process any @Import annotations
// 处理@Import注解
processImports(configClass, sourceClass, getImports(sourceClass), true);
// Process any @ImportResource annotations
// 处理@ImportResource注解
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
// Process individual @Bean methods
// 处理@Bean注解
// 获取到被@Bean标注的方法
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
// 添加到configClass中
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
// Process default methods on interfaces
// 处理接口中的default方法
processInterfaces(configClass, sourceClass);
// Process superclass, if any
// 返回父类,进行递归处理
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (superclass != null && !superclass.startsWith("java") &&
!this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
// No superclass -> processing is complete
return null;
}
可以看到,在doProcessConfigurationClass真正完成了对配置类的解析,一共做了下面几件事
- 解析配置类中的内部类,看内部类中是否有配置类,如果有进行递归处理
- 处理配置类上的@PropertySources跟@PropertySource注解
- 处理@ComponentScan,@ComponentScans注解
- 处理@Import注解
- 处理@ImportResource注解
- 处理@Bean注解
- 处理接口中的default方法
- 返回父类,让外部的循环继续处理当前配置类的父类
我们逐一进行分析
2.4、处理配置类中的内部类
这段代码非常简单,限于篇幅原因我这里就不再专门分析了,就是获取到当前配置类中的所有内部类,然后遍历所有的内部类,判断是否是一个配置类,如果是配置类的话就递归进行解析
2.5、处理@PropertySource注解
代码也非常简单,根据注解中的信息加载对应的属性文件然后添加到容器中
2.6、处理@ComponentScan注解
这个段我们就需要看一看了,Spring在这里完成的扫描,我们直接查看其核心方法,
org.springframework.context.annotation.ComponentScanAnnotationParser#parse
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, final String declaringClass) {
// 第一步就创建了一个ClassPathBeanDefinitionScanner对象
// 在这里我们就知道了,Spring在进行扫描时没有使用在最开始的时候创建的那个对象进行扫描
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
// 解析成bd时采用的beanName的生成规则
Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
BeanUtils.instantiateClass(generatorClass));
// 配置这个扫描规则下的ScopedProxyMode的默认值
ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
}
else {
Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
}
// 配置扫描器的匹配规则
scanner.setResourcePattern(componentScan.getString("resourcePattern"));
// 配置扫描器需要扫描的组件
for (AnnotationAttributes filter : componentScan.getAnnotationArray("includeFilters")) {
for (TypeFilter typeFilter : typeFiltersFor(filter)) {
scanner.addIncludeFilter(typeFilter);
}
}
// 配置扫描器不需要扫描的组件
for (AnnotationAttributes filter : componentScan.getAnnotationArray("excludeFilters")) {
for (TypeFilter typeFilter : typeFiltersFor(filter)) {
scanner.addExcludeFilter(typeFilter);
}
}
// 配置默认是否进行懒加载
boolean lazyInit = componentScan.getBoolean("lazyInit");
if (lazyInit) {
scanner.getBeanDefinitionDefaults().setLazyInit(true);
}
// 配置扫描器扫描的包名
Set<String> basePackages = new LinkedHashSet<>();
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
Collections.addAll(basePackages, tokenized);
}
for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
// 排除自身
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
@Override
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
// 在完成对扫描器的配置后,直接调用其doScan方法进行扫描
return scanner.doScan(StringUtils.toStringArray(basePackages));
}
看到了吧,第一步就创建了一个ClassPathBeanDefinitionScanner,紧接着通过解析注解,对这个扫描器进行了各种配置,然后调用doScan方法完成了扫描。
2.7、处理@Import注解
private void processImports(ConfigurationClass configClass, SourceClass currentSourceClass,
Collection<SourceClass> importCandidates, boolean checkForCircularImports) {
// 没有要导入的类,直接返回
if (importCandidates.isEmpty()) {
return;
}
// checkForCircularImports:Spring中写死的为true,需要检查循环导入
// isChainedImportOnStack方法:检查导入栈中是否存在了这个configClass,如果存在了说明
// 出现了A import B,B import A的情况,直接抛出异常
if (checkForCircularImports && isChainedImportOnStack(configClass)) {
this.problemReporter.error(new CircularImportProblem(configClass, this.importStack));
}
else {
// 没有出现循环导入,先将当前的这个配置类加入到导入栈中
this.importStack.push(configClass);
try {
// 遍历所有要导入的类
for (SourceClass candidate : importCandidates) {
// 如果要导入的类是一个ImportSelector
if (candidate.isAssignable(ImportSelector.class)) {
// Candidate class is an ImportSelector -> delegate to it to determine imports
// 反射创建这个ImportSelector
Class<?> candidateClass = candidate.loadClass();
ImportSelector selector = BeanUtils.instantiateClass(candidateClass, ImportSelector.class);
// 执行xxxAware方法
ParserStrategyUtils.invokeAwareMethods(
selector, this.environment, this.resourceLoader, this.registry);
// 如果是一个DeferredImportSelector,添加到deferredImportSelectors集合中去
// 在所有的配置类完成解析后再去处理deferredImportSelectors集合中的ImportSelector
if (this.deferredImportSelectors != null && selector instanceof DeferredImportSelector) {
this.deferredImportSelectors.add(
new DeferredImportSelectorHolder(configClass, (DeferredImportSelector) selector));
}
else {
// 不是一个DeferredImportSelector,那么通过这个ImportSelector获取到要导入的类名
String[] importClassNames = selector.selectImports(currentSourceClass.getMetadata());
// 将其转换成SourceClass
Collection<SourceClass> importSourceClasses = asSourceClasses(importClassNames);
// 递归处理要导入的类,一般情况下这个时候进入的就是另外两个判断了
processImports(configClass, currentSourceClass, importSourceClasses, false);
}
}
else if (candidate.isAssignable(ImportBeanDefinitionRegistrar.class)) {
// Candidate class is an ImportBeanDefinitionRegistrar ->
// delegate to it to register additional bean definitions
// 如果是一个ImportBeanDefinitionRegistrar
// 先通过反射创建这个ImportBeanDefinitionRegistrar
Class<?> candidateClass = candidate.loadClass();
ImportBeanDefinitionRegistrar registrar =
BeanUtils.instantiateClass(candidateClass, ImportBeanDefinitionRegistrar.class);
// 再执行xxxAware方法
ParserStrategyUtils.invokeAwareMethods(
registrar, this.environment, this.resourceLoader, this.registry);
// 最后将其添加到configClass的importBeanDefinitionRegistrars集合中
// 之后会统一调用其ImportBeanDefinitionRegistrar的registerBeanDefinitions方法,将对应的bd注册到容器中
configClass.addImportBeanDefinitionRegistrar(registrar, currentSourceClass.getMetadata());
}
else {
// Candidate class not an ImportSelector or ImportBeanDefinitionRegistrar ->
// process it as an @Configuration class
// 既不是一个ImportSelector也不是一个ImportBeanDefinitionRegistrar,直接导入一个普通类
// 并将这个类作为配置类进行递归处理
this.importStack.registerImport(
currentSourceClass.getMetadata(), candidate.getMetadata().getClassName());
processConfigurationClass(candidate.asConfigClass(configClass));
}
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to process import candidates for configuration class [" +
configClass.getMetadata().getClassName() + "]", ex);
}
finally {
// 在循环前我们将其加入了导入栈中,循环完成后将其弹出,主要是为了处理循环导入
this.importStack.pop();
}
}
}
2.8、处理@ImportResource注解
代码也很简单,在指定的位置加载资源,然后添加到configClass中。一般情况下,我们通过@ImportResource注解导入的就是一个XML配置文件。将这个Resource添加到configClass后,Spring会在后文中解析这个XML配置文件然后将其中的bd注册到容器中,可以参考
org.springframework.context.annotation.ConfigurationClassBeanDefinitionReader#loadBeanDefinitions方法
2.9、处理@Bean注解
将配置类中所有的被@Bean标注的方法添加到configClass的BeanMethod集合中
2.10、处理接口中的default方法
代码也很简单,Java8中接口能定义default方法,这里就是处理接口中的default方法,看其是否有@Bean标注的方法
到此为止,我们分析完了整个解析的过程。可以发现Spring将所有解析到的配置信息都存储在了ConfigurationClass类中,但是到目前为止这些存储的信息都没有进行使用。那么Spring是在哪里使用的这些信息呢?回到我们的第三段代码,其中有一行代码如图所示:
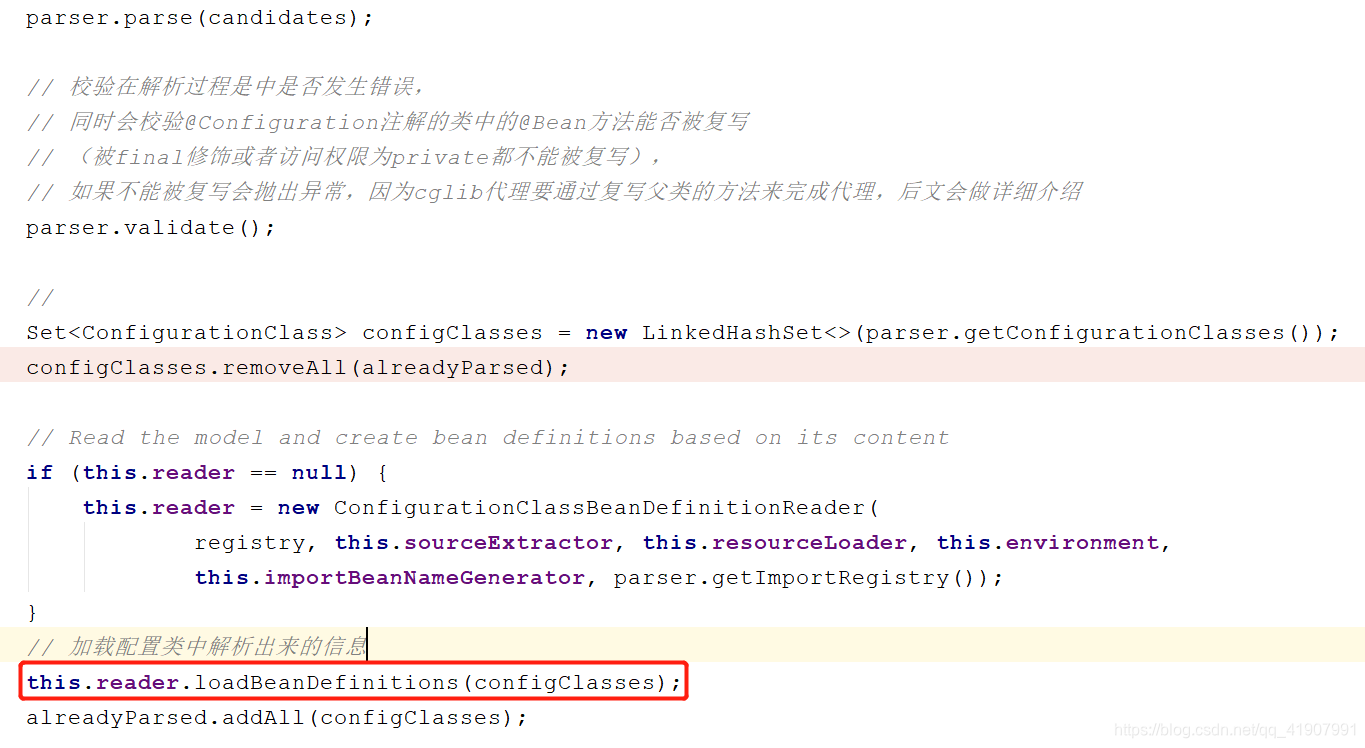
也就是在这里Spring完成了对解析好的配置类的信息处理。
2.11、加载解析完成的配置信息
// configurationModel:被解析完成了配置类集合,其中保存了@Bean注解解析信息,@Import注解解析信息等等
public void loadBeanDefinitions(Set<ConfigurationClass> configurationModel) {
TrackedConditionEvaluator trackedConditionEvaluator = new TrackedConditionEvaluator();
for (ConfigurationClass configClass : configurationModel) {
// 调用这个方法完成的加载
loadBeanDefinitionsForConfigurationClass(configClass, trackedConditionEvaluator);
}
}
private void loadBeanDefinitionsForConfigurationClass(
ConfigurationClass configClass, TrackedConditionEvaluator trackedConditionEvaluator) {
// 判断是否需要跳过,例如A导入了B,A不满足加载的条件需要被跳过,那么B也应该被跳过
if (trackedConditionEvaluator.shouldSkip(configClass)) {
String beanName = configClass.getBeanName();
if (StringUtils.hasLength(beanName) && this.registry.containsBeanDefinition(beanName)) {
this.registry.removeBeanDefinition(beanName);
}
this.importRegistry.removeImportingClass(configClass.getMetadata().getClassName());
return;
}
// 判断配置类是否是被导入进来的,实际的代码就是判断解析出来的configclass中的importedBy集合是否为空
// 那么这个importedBy集合是做什么的呢?
// 例如A通过@Import导入了B,那么解析B得到得configclass中得importedBy集合就包含了A
// 简而言之,importedBy集合就是导入了这个类的其它类(可能同时被多个类导入)
// 在前文中我们也分析过了,被多个类同时导入时会调用mergeImportedBy方法在集合中添加一个元素
if (configClass.isImported()) {
registerBeanDefinitionForImportedConfigurationClass(configClass);
}
// 解析@Bean标注的Method得到对应的BeanDefinition并注册到容器中
for (BeanMethod beanMethod : configClass.getBeanMethods()) {
loadBeanDefinitionsForBeanMethod(beanMethod);
}
// 解析导入的配置文件,并将从中得到的bd注册到容器中
loadBeanDefinitionsFromImportedResources(configClass.getImportedResources());
// 执行configClass中的所有ImportBeanDefinitionRegistrar的registerBeanDefinitions方法
loadBeanDefinitionsFromRegistrars(configClass.getImportBeanDefinitionRegistrars());
}
这段代码阅读起来还是非常简单的,这里我就跟大家一起看下BeanMethod的相关代码,主要是为了让大家对BeanDefinition的理解能够更加深入,其源码如下:
private void loadBeanDefinitionsForBeanMethod(BeanMethod beanMethod) {
ConfigurationClass configClass = beanMethod.getConfigurationClass();
MethodMetadata metadata = beanMethod.getMetadata();
String methodName = metadata.getMethodName();
// 根据@Conditional注解判断是否需要跳过
if (this.conditionEvaluator.shouldSkip(metadata, ConfigurationPhase.REGISTER_BEAN)) {
configClass.skippedBeanMethods.add(methodName);
return;
}
if (configClass.skippedBeanMethods.contains(methodName)) {
return;
}
// 获取@Bean注解中的属性
AnnotationAttributes bean = AnnotationConfigUtils.attributesFor(metadata, Bean.class);
Assert.state(bean != null, "No @Bean annotation attributes");
// 从这里可以看出,如果没有配置beanName,默认会取方法名称作为beanName
List<String> names = new ArrayList<>(Arrays.asList(bean.getStringArray("name")));
String beanName = (!names.isEmpty() ? names.remove(0) : methodName);
// 注册别名
for (String alias : names) {
this.registry.registerAlias(beanName, alias);
}
// isOverriddenByExistingDefinition这个方法判断的是当前注册的bd是否被原有的存在的bd所覆盖了
// 什么是覆盖呢?后文中我们详细分析
if (isOverriddenByExistingDefinition(beanMethod, beanName)) {
// 满足下面这个if的话意味着@Bean创建的bean跟@Bean标注的方法所所在的配置类的名称一样了,这种情况下直接抛出异常
if (beanName.equals(beanMethod.getConfigurationClass().getBeanName())) {
throw new BeanDefinitionStoreException(beanMethod.getConfigurationClass().getResource().getDescription(),
beanName, "Bean name derived from @Bean method '" + beanMethod.getMetadata().getMethodName() +
"' clashes with bean name for containing configuration class; please make those names unique!");
}
return;
}
// 创建一个ConfigurationClassBeanDefinition,从这里可以看出通过@Bean创建的Bean所对应的bd全是ConfigurationClassBeanDefinition
ConfigurationClassBeanDefinition beanDef = new ConfigurationClassBeanDefinition(configClass, metadata);
beanDef.setResource(configClass.getResource());
beanDef.setSource(this.sourceExtractor.extractSource(metadata, configClass.getResource()));
// @Bean是静态的,那么只需要知道静态方法所在类名以及方法名就能执行这个方法了
if (metadata.isStatic()) {
// static @Bean method
beanDef.setBeanClassName(configClass.getMetadata().getClassName());
beanDef.setFactoryMethodName(methodName);
}
else {
//
// instance @Bean method
beanDef.setFactoryBeanName(configClass.getBeanName());
beanDef.setUniqueFactoryMethodName(methodName);
}
// 接下来的代码就是设置一些bd的属性,然后将bd注册到容器中,相关的源码在之前的文章中已经分析过了
// 这里我就不在分析了,参考本文推荐阅读文章的《读源码,我们可以从第一行读起》
//.....
}
上面这个方法的主要目的就是将@Bean标注的方法解析成BeandDefinition然后注册到容器中。关于这个方法我们可以对比下之前分析过的org.springframework.context.annotation.AnnotatedBeanDefinitionReader#doRegisterBean方法。对比我们可以发现,这两个方法最大的不同在于一个是基于Class对象的,而另一个则是基于Method对象的。
正因为如此,所有它们有一个很大的不同点在于BeanDefinition中BeanClasss属性的设置。可以看到,对于@Bean形式创建的Bean其BeanDefinition中是没有设置BeanClasss属性的,但是额外设置了其它的属性
- 静态方法下,设置了BeanClassName以及FactoryMethodName属性,其中的BeanClassName是静态方法所在类的类名,FactoryMethodName是静态方法的方法名
- 实例方法下,设置了FactoryBeanName以及FactoryMethodName属性,其中FactoryBeanName是实例对应的Bean的名称,而FactoryMethodName是实例中对应的方法名
之所以不用设置BeanClasss属性是因为,通过指定的静态方法或者指定的实例中的方法也能唯一确定一个Bean。
除此之外,注册@Bean形式得到的BeanDefinition时,还进行了一个isOverriddenByExistingDefinition(beanMethod, beanName)方法的判断,这个方法的主要作用是判断当前要注册的bean是否被之前已经存在的Bean覆盖了。但是在直接通过AnnotatedBeanDefinitionReader#doRegisterBean方法注册Bean时是没有进行这个判断的,如果存在就直接覆盖了,而不会用之前的bd来覆盖现在要注册的bd。这是为什么呢?据笔者自己的理解,是因为Spring将Bean也是分成了三六九等的,通过@Bean方式得到的bd可以覆盖扫描出来的普通bd(ScannedGenericBeanDefinition),但是不能覆盖配置类,所以当已经存在的bd是一个ScannedGenericBeanDefinition时,那么直接进行覆盖,但是当已经存在的bd是一个配置类时,就不能进行覆盖了,要使用已经存在的bd来覆盖本次要注册的bd。
到此为止,我们就完成了Spring中的整个配置类解析、注册的相关源码分析,不过还没完,我们还得解决一个问题,就是为什么要在配置类上添加@Configuration注解,在之前的源码分析中我们知道,添加@Configuration注解的作用就是讲配置类标志成了一个full configurationClass,这个的目的是什么呢?本来是打算一篇文章写完的,不过实在是太长了,接近6w字,所以还是拆成了两篇,预知后事如何,请看下文:
配置类为什么要添加@Configuration注解呢?
总结
我们结合上篇文章彻底读懂Spring(一)读源码,我们可以从第一行读起整理下目前Spring的执行流程
原图地址: 原图
清晰的知道了执行的流程,我们再来回想下postProcessBeanDefinitionRegistry做了什么。

码字不易,对你有帮助的话记得点个赞,关注一波哦,万分感谢!
你知道Spring是怎么解析配置类的吗?的更多相关文章
- Spring5源码解析6-ConfigurationClassParser 解析配置类
ConfigurationClassParser 在ConfigurationClassPostProcessor#processConfigBeanDefinitions方法中创建了Configur ...
- 【Spring】简述@Configuration配置类注册BeanDefinition到Spring容器的过程
概述 本文以SpringBoot应用为基础,尝试分析基于注解@Configuration的配置类是如何向Spring容器注册BeanDefinition的过程 其中主要分析了 Configuratio ...
- Spring源码解析——核心类介绍
前言: Spring用了这么久,虽然Spring的两大核心:IOC和AOP一直在用,但是始终没有搞懂Spring内部是怎么去实现的,于是决定撸一把Spring源码,前前后后也看了有两边,很多东西看了就 ...
- Spring源码解析-核心类之XmlBeanDefinitionReader
XmlBeanDefinitionReader XML配置文件的读取是 Spring 中重要的功能,因为 Spring 的大部分功能都是以配置作为切入点的,那么我们可以从 XmlBeanDefinit ...
- Spring源码解析-核心类之XmlBeanFactory 、DefaultListableBeanFactory
DefaultListableBeanFactory XmlBeanFactory 继承自 DefaultListableBeanFactory , 而 DefaultListableBeanFact ...
- spring data redis的配置类RedisConfig
package com.tz.config; import org.springframework.context.annotation.Bean; import org.springframewor ...
- spring boot 排除个别配置类的代码
废话不说,直接上代码 @SpringBootApplication(exclude={DataSourceAutoConfiguration.class,HibernateJpaAutoConfigu ...
- 配置类为什么要添加@Configuration注解呢?
配置类为什么要添加@Configuration注解呢? 本系列文章: 读源码,我们可以从第一行读起 你知道Spring是怎么解析配置类的吗? 推荐阅读: Spring官网阅读 | 总结篇 Spring ...
- Spring源码解析之ConfigurationClassPostProcessor(三)
在上一章笔者介绍了ConfigurationClassParser.doProcessConfigurationClass(...)方法,在这个方法里调用了processImports(...)方法处 ...
随机推荐
- MyBatis-Plus使用小结
官网: https://mybatis.plus/ https://gitee.com/baomidou/mybatis-plus https://github.com/baomidou/mybati ...
- Maven版本不合适导致出现的问题如下,换个老版本就好了
2019-09-30 11:56:24,555 [ 597097] ERROR - #org.jetbrains.idea.maven - IntelliJ IDEA 2018.3.5 Build # ...
- ASE课程总结 by 林建平
设想和目标 1. 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? 我们的辅助用户在阅读英文文献时记忆生词,提高用户的生词量,减少用户的阅读障碍.定义非常清晰,要有查 ...
- JS 中的自定义事件和模拟事件
在 JS 中模拟事件指的是模拟 JS 中定义的一些事件,例如点击事件,键盘事件等. 自定义事件指的是创建一个自定义的,JS 中之前没有的事件. 接下来分别说一下创建这两种事件的方法. 创建自定义事件 ...
- C++11<functional>深度剖析
自C++11以来,C++标准每3年修订一次.C++14/17都可以说是更完整的C++11:即将到来的C++20也已经特性完整了. C++11已经有好几年了,它的年龄比我接触C++的时间要长10倍不止吧 ...
- PHP函数:array_chunk
array_chunk() - 将一个数组分割成多个. 说明: array_chunk ( array $array , int $size [, bool $preserve_keys = fa ...
- pytorch Dataset数据集和Dataloader迭代数据集
import torch from torch.utils.data import Dataset,DataLoader class SmsDataset(Dataset): def __init__ ...
- Docker 搭建 ELK 集群步骤
前言 本篇文章主要介绍在两台机器上使用 Docker 搭建 ELK. 正文 环境 CentOS 7.7 系统 Docker version 19.03.8 docker-compose version ...
- htaccess 一般配置
一.Apache服务器 <IfModule mod_rewrite.c> Options +FollowSymlinks -Multiviews RewriteEngine on Rewr ...
- 一,连接Oracle 一
连接Oracle数据库方法: 一,使用sqlplus连接 二,使用第三方软件连接 sqlplus sqlplus 工具简介 (1).概述:sqlplus是在Linux下操作oracle的工具 (2). ...