分类算法之KNN分类
1、介绍
KNN是k nearest neighbor 的简称,即k最邻近,就是找k个最近的实例投票决定新实例的类标。KNN是一种基于实例的学习算法,它不同于贝叶斯、决策树等算法,KNN不需要训练,当有新的实例出现时,直接在训练数据集中找k个最近的实例,把这个新的实例分配给这k个训练实例中实例数最多类。KNN也成为懒惰学习,它不需要训练过程,在类标边界比较整齐的情况下分类的准确率很高。KNN算法需要人为决定K的取值,即找几个最近的实例,k值不同,分类结果的结果也会不同。
2、举例
看如下图的训练数据集的分布,该数据集分为3类(在图中以三种不同的颜色表示),现在出现一个待分类的新实例(图中绿色圆点),假设我们的K=3,即找3个最近的实例,这里的定义的距离为欧氏距离,这样找据该待分类实例最近的三个实例就是以绿点为中心画圆,确定一个最小的半径,使这个圆包含K个点。
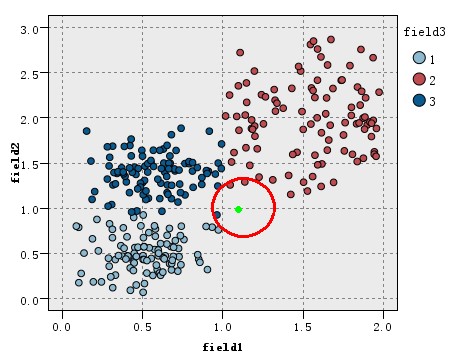
如图所示,可以看到红圈包含的三个点中,类别2中有三个,类别3有一个,而类别1一个也没有,根据少数服从多数的原理投票,这个绿色的新实例应属于2类。
3、K值的选取。
之前说过,K值的选取,将会影响分类的结果,那么K值该取多少合理。我们继续上面提到的分类过程,现在我们把K设置为为7,如下图所示:
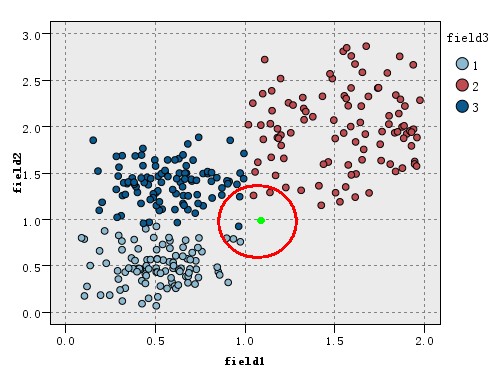
可以看到当k=7时,最近的7个点中1类有三个,2类和3类都有两个,这时绿色的新实例应该分给1类,这与K=5时的分类结果不同。
K值的选取没有一个绝对的标准,但可以想象,K取太大并不能提高正确率,而且求K个最近的邻居是一个O(K*N)复杂度的算法,k太大,算法效率会更低。
虽然说K值的选取,会影响结果,有人会认为这个算法不稳定,其实不然,这种影响并不是很大,因为只有这种影响只是在类别边界上产生影响,而在类中心附近的实例影响很小,看下图,对于这样的一个新实例,k=3,k=5,k=11结果都是一样的。
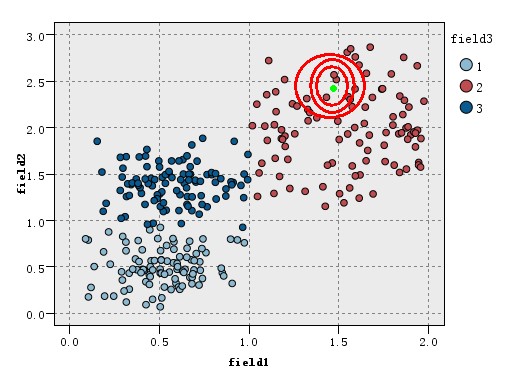
最后还有注意,在数据集不均衡的情况下,可能需要按各类的比例决定投票,这样小类的正确率才不会过低。
参考链接:http://www.cnblogs.com/fengfenggirl/archive/2013/05/27/knn.html
分类算法之KNN分类的更多相关文章
- 【笔记】二分类算法解决多分类问题之OvO与OvR
OvO与OvR 前文书道,逻辑回归只能解决二分类问题,不过,可以对其进行改进,使其同样可以用于多分类问题,其改造方式可以对多种算法(几乎全部二分类算法)进行改造,其有两种,简写为OvO与OvR OvR ...
- 数据挖掘之分类算法---knn算法(有matlab例子)
knn算法(k-Nearest Neighbor algorithm).是一种经典的分类算法.注意,不是聚类算法.所以这种分类算法 必然包括了训练过程. 然而和一般性的分类算法不同,knn算法是一种懒 ...
- kNN算法:K最近邻(kNN,k-NearestNeighbor)分类算法
一.KNN算法概述 邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它 ...
- 数据挖掘之分类算法---knn算法(有matlab样例)
knn算法(k-Nearest Neighbor algorithm).是一种经典的分类算法. 注意,不是聚类算法.所以这样的分类算法必定包含了训练过程. 然而和一般性的分类算法不同,knn算法是一种 ...
- 用Python开始机器学习(2:决策树分类算法)
http://blog.csdn.net/lsldd/article/details/41223147 从这一章开始进入正式的算法学习. 首先我们学习经典而有效的分类算法:决策树分类算法. 1.决策树 ...
- Mahout 分类算法
实验简介 本次课程学习了Mahout 的 Bayes 分类算法. 一.实验环境说明 1. 环境登录 无需密码自动登录,系统用户名 shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu ...
- Spark MLlib架构解析(含分类算法、回归算法、聚类算法和协同过滤)
Spark MLlib架构解析 MLlib的底层基础解析 MLlib的算法库分析 分类算法 回归算法 聚类算法 协同过滤 MLlib的实用程序分析 从架构图可以看出MLlib主要包含三个部分: 底层基 ...
- 机器学习算法之——KNN、Kmeans
一.Kmeans算法 kmeans算法又名k均值算法.其算法思想大致为:先从样本集中随机选取 kk 个样本作为簇中心,并计算所有样本与这 kk 个“簇中心”的距离,对于每一个样本,将其划分到与其距离最 ...
- Spark Mllib里如何对决策树二元分类和决策树多元分类的分类数目numClasses控制(图文详解)
不多说,直接上干货! 决策树二元分类的分类数目numClasses控制 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第13章 使用决策树二元分类算法来预测分类Stumble ...
随机推荐
- [SDOI2016]游戏(树剖+李超树)
趁着我把李超树忘个一干二净的时候来复习一下吧,毕竟马上NOI了. 题解:看着那个dis就很不爽,直接把它转换成深度问题,然后一条直线x->y,假设其lca为z,可以拆分成x->z和z-&g ...
- go 汇编
汇编文件 go tool compile -S main.go>main.S go tool compile 可以看帮助 -N 关闭优化
- xv6 makefile
1. xv6.img的构建 在makefile中 bootblock: bootasm.S bootmain.c $(CC) $(CFLAGS) -fno-pic -O -nostdinc -I. - ...
- CSS3新特性—过渡、转换
过渡 转换 2D转换 2D转换包括四个方面:位移,缩放,旋转,倾斜 位移[让元素移动位置] transform: translate(100px,100px); 备注: 1. 如果只设置一个值,那么代 ...
- 教你如何使用JavaScript入门
JavaScript简介 JavaScript是NetScape公司为Navigator浏览器开发的,是web前端卸载HTML文件中的一种脚本语言,能实现网页内容的交互显示.当用户在客户端显示该网 ...
- [CISCN2019 华北赛区 Day2 Web1]Hack World
知识点:题目已经告知列名和表明为flag,接下来利用ascii和substr函数即可进行bool盲注 eg: id=(ascii(substr((select(flag)from(flag)),1,1 ...
- Codeforces Round #568 (Div. 2)网卡&垫底记
这场和div3差不多嘛(后来发现就是div3),就是网太卡10min交一发就不错了,简直自闭. A 签到. B 记录每一段的字母数,满足条件即:段数相同+字母相同+字母数下>=上. #inclu ...
- Java if、switch语句,break,case,类型转换、常量、赋值比较、标识符(2)
if语句: /* if else 结构 简写格式: 变量 = (条件表达式)?表达式1:表达式2: 三元运算符: 好处:可以简化if else代码. 弊端:因为是一个运算符,所以运算完必须要有一个结果 ...
- Python 中如何自动导入缺失的库?
在写 Python 项目的时候,我们可能经常会遇到导入模块失败的错误:ImportError: No module named 'xxx'或者ModuleNotFoundError: No modul ...
- dozer
1.简介 dozer是用来两个对象之间属性转换的工具,有了这个工具之后,我们将一个对象的所有属性值转给另一个对象时,就不需要再去写重复的set和get方法了. 2.如果两个类之间的属性有些属性意思一样 ...