python selenium模块 css定位
selenium是python的非标准库,使用时需要下载安装
安装命令 pip install selenium
selenium是python的自动化测试模块,可以模拟浏览器的行为
所以在使用之前还要安装浏览器驱动,不同的版本对应不同的驱动文件,这里就不一一赘述了,网上相关的介绍有很多(主要是作者懒)
下载后将驱动文件放到添加过环境变量的路径,以便系统在使用时找到它,这里我把它放在了python的安装目录里
前戏部分就做完了,可以开始了
from selenium import webdriver
import time
# 创建Chrome对象
driver = webdriver.Chrome()
# 打开浏览器预设网址
driver.get('https://www.baidu.com')
# 通过id获取搜索框
input_ele = driver.find_element_by_css_selector('#kw')
# 模拟键盘操作 输入框输入内容
input_ele.send_keys("虞书欣")
# 模拟鼠标点击操作
driver.find_element_by_css_selector('#su').click()
# 延迟2秒,等待页面刷新完成
time.sleep(2)
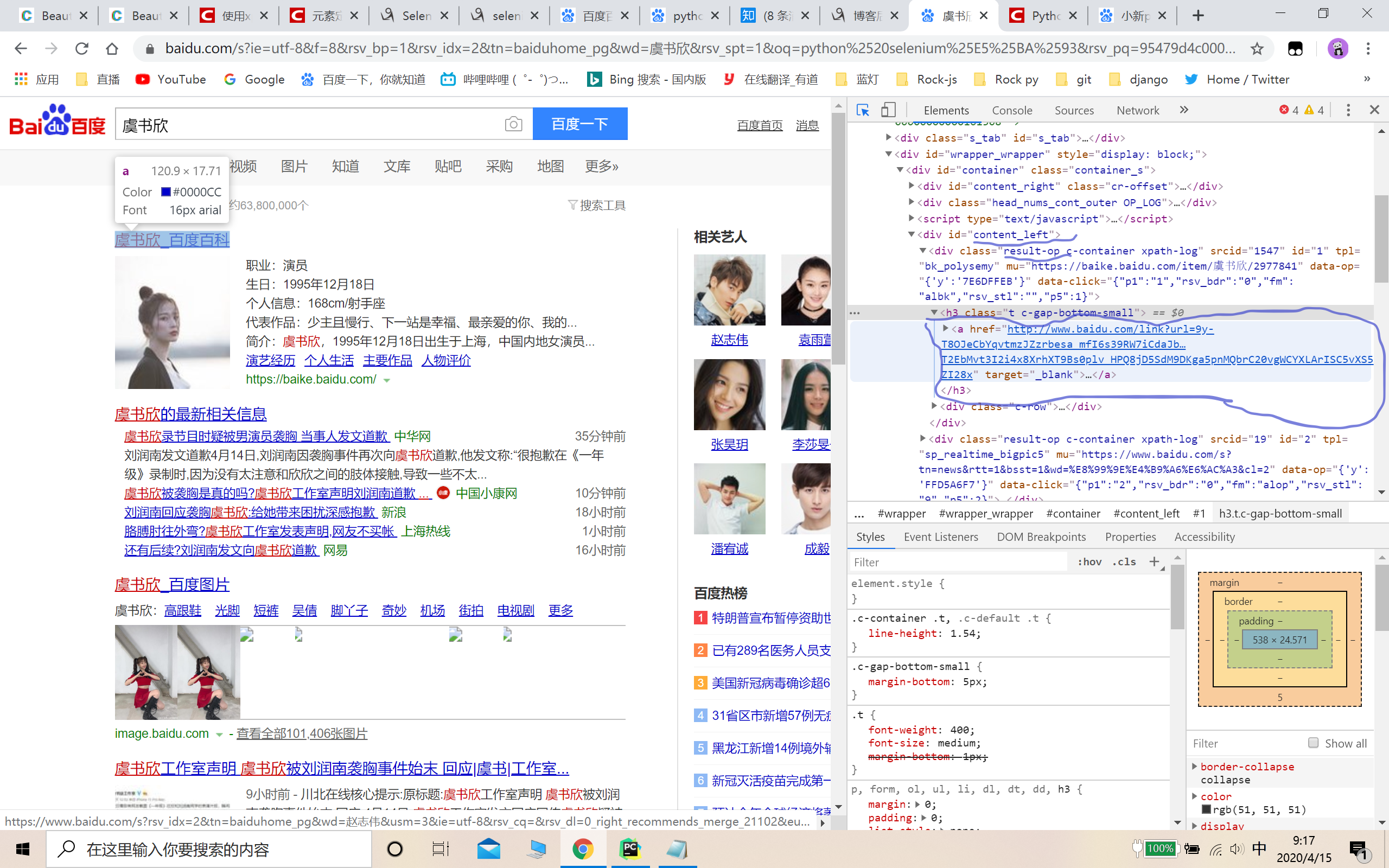
a_ele = driver.find_element_by_css_selector('#content_left div.c-container a') # 解析页面元素 定位到目标链接
'''
中间遇到一个问题
使用id = 1定位时定位不到该节点,
a_ele = driver.find_element_by_css_selector('#content_left div#1 a')
报错:
selenium.common.exceptions.InvalidSelectorException: Message: invalid selector: An invalid or illegal selector was specified
开始想的时页面可能这个元素还没刷新完成,后来我页面延迟5秒后还是报错
然后我使用class定位,成功定位到该节点,然后获取该节点的id,输出为:1
还是没搞懂为什么不能使用id定位到该节点,不知哪位大捞可以帮忙解读解读
原因是id为数字不符合python的命名规则......
'''
结合实例总结一下:
driver.find_element_by_css_selector('#content') 查找id为content的节点
driver.find_element_by_css_selector('.content') 查找class为content的节点
driver.find_element_by_css_selector('div#conten>a') 查找id为content的div的所有子节点为a标签的节点
driver.find_element_by_css_selector('div#conten a') 查找id为content的div的所有子孙节点为a标签的节点
driver.find_element_by_css_selector('#conten p:nth-child(2)') 查找id为content的节点中的其父元素的第二个子元素是p标签的节点,并不是指第二个p标签节点
driver.find_element_by_css_selector('#conten>p:nth-of-type(2)') 查找id为content的节点的第二个p标签节点
driver.find_element_by_css_selector('.content[name=value]') 查找class为content且name属性为value的所有节点
find_element_by_css_selector 返回匹配到的第一个节点
find_elements_by_css_selector 返回匹配到的所有节点,类型是list
python selenium模块 css定位的更多相关文章
- python selenium之CSS定位
ccs的优点:css相对xpath语法比xpath简洁,定位速度比xpath快 css的缺点:css不支持用逻辑运算符来定位,而xpath支持.css定位语法形式多样,相对xpath比较难记. css ...
- python selenium模块 xpath定位
''' 附w3xpath语法地址 https://www.w3school.com.cn/xpath/xpath_syntax.asp 总结: 返回匹配到所有符合条件的第一个节点,对象是 <cl ...
- python+selenium 元素被定位到而且click()也提示执行成功,但是页面就是没有变化和跳转。
python+selenium 元素被定位到而且click()也提示执行成功,但是页面就是没有变化和跳转. 如果多次定位和click(),有时候会跳转. 我遇到很多次就是很郁闷,有人说,操作太快的,页 ...
- python selenium模块调用浏览器的时候出错
python selenium模块使用出错,这个怎么改 因为不同版本更新不同步问题,浏览器都要另外下一个驱动.
- 6 Python+Selenium的元素定位方法(CSS)
[环境] python3.6+selenium3.0.2+Firefox50.0+win7 [定位方法] 1.方法:find_element_by_css_selector('xx') CSS的语法比 ...
- Python selenium根据class定位页面元素
在日常的网页源码中,我们基于元素的id去定位是最万无一失的,id在单个页面中是不会重复的.但是实际工作中,很多前端开发人员并未给每个元素都编写id属性.通常一段html代码如下: <div cl ...
- selenium之css定位小结
前言 大部分人在使用selenium定位元素时,用的是xpath定位,因为xpath基本能解决定位的需求.css定位往往被忽略掉了,其实css定位也有它的价值,css定位更快,语法更简洁.这一篇css ...
- 自动化测试-6.selenium的css定位
前言 大部分人在使用selenium定位元素时,用的是xpath定位,因为xpath基本能解决定位的需求.css定位往往被忽略掉了,其实css定位也有它的价值,css定位更快,语法更简洁.这一篇css ...
- python+selenium二:定位方式
# 八种单数定位方式:elementfrom selenium import webdriverimport time driver = webdriver.Firefox()time.sleep(2 ...
随机推荐
- nginx 自动化定时切割日志
NG在默认情况下,是始终输出到一个日志文件中,日志文件在nginx.conf中 : access_log logs/www.access.log main; 一个文件中不是很方便查找,分析数据, ...
- arcgis10.4.X的oracle数据库要求
受支持的数据库版本:(标准版/标准独立版/企业版) Oracle 11g R2(64 位)11.2.0.4 Oracle 12c R1(64 位)12.1.0.2 受支持的操作系统: 数据库 支持的操 ...
- RabbitMQ 交换机类型
1,扇形交换机 fanout 2, 直连交换机 direct 3, 通配符交换机 topic
- 微信阻止ios下拉回弹,橡皮筋效果
直接阻止touchmove事件就好了(需设置passive: false): document.addEventListener("touchmove", function(evt ...
- Kitty-Cloud环境准备
项目地址 https://github.com/yinjihuan/kitty-cloud 开发工具 开发工具目前对应的都是我本机的一些工具,大家可以根据自己平时的习惯选择对应的工具即可. 工具 说明 ...
- Hadoop调试记录(1)
错误 ERROR: Can't get master address from ZooKeeper; znode data == null 解决 关闭hadoop,发现stop-all.sh后几个进程 ...
- POI2014 FAR-FarmCraft 树形DP+贪心
题目链接 https://www.luogu.org/problem/P3574 题意 翻译其实已经很明确了 分析 这题一眼就是贪心啊,但贪心的方法要思索一下,首先是考虑先走时间多的子树,但不太现实, ...
- Innodb的三大关健特性
今天看<MySql技术内幕InnoDB存储引擎>一书,学习了Mysql的三大关健特性,并记录如下: 插入缓冲 双写(double write) 自适应Hash索引 在记录这些特性之前,先对 ...
- MapReduce( map的使用)
MapReduce Description MapReduce是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Red ...
- H5的新特性
https://blog.csdn.net/weixin_42441117/article/details/80705203 1.h5新语义元素(有利于代码可读性和SEO)2.本地存储 h5提供 ...