【分布式锁】06-Zookeeper实现分布式锁:可重入锁源码分析
前言
前面已经讲解了Redis的客户端Redission是怎么实现分布式锁的,大多都深入到源码级别。
在分布式系统中,常见的分布式锁实现方案还有Zookeeper,接下来会深入研究Zookeeper是如何来实现分布式锁的。
Zookeeper初识
文件系统
Zookeeper维护一个类似文件系统的数据结构
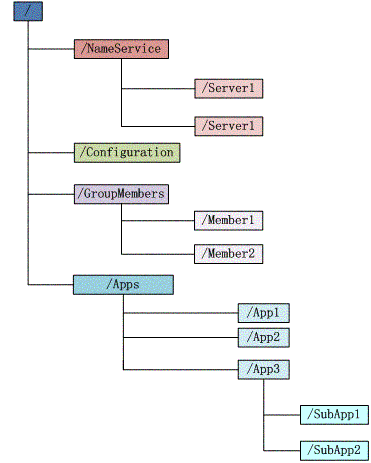 image.png
image.png
每个子目录项如NameService都被称为znoed,和文件系统一样,我们能够自由的增加、删除znode,在znode下增加、删除子znode,唯一不同的在于znode是可以存储数据的。
有4种类型的znode
PERSISTENT--持久化目录节点客户端与zookeeper断开连接后,该节点依旧存在
PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
EPHEMERAL-临时目录节点客户端与zookeeper断开连接后,该节点被删除
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)等,zookeeper会通知客户端。
分布式锁
有了zookeeper的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
对于第一类,我们将zookeeper上的一个znode看作是一把锁,通过create znode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。厕所有言:来也冲冲,去也冲冲,用完删除掉自己创建的distribute_lock 节点就释放出锁。
对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除自己创建的znode节点。
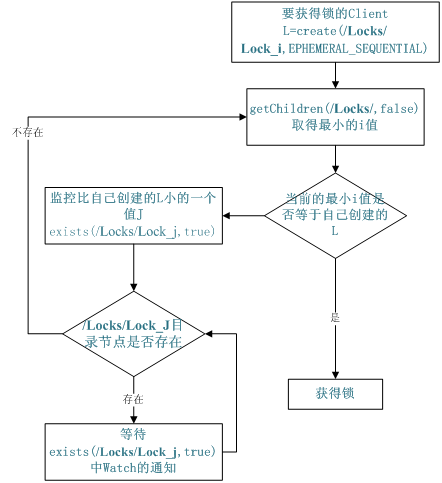 image.png
image.png
注明:以上内容参考 https://www.cnblogs.com/dream-to-pku/p/9513188.html
Curator框架初识
Curator是Netflix公司开源的一套Zookeeper客户端框架。目前已经作为Apache的顶级项目出现,是最流行的Zookeeper客户端之一。
我们看下Apache Curator官网的介绍:
 image.png
image.png
接着看下quick start中关于分布式锁相关的内容
地址为:http://curator.apache.org/getting-started.html
InterProcessMutex lock = new InterProcessMutex(client, lockPath);
if ( lock.acquire(maxWait, waitUnit) )
{
try
{
// do some work inside of the critical section here
}
finally
{
lock.release();
}
}
使用很简单,使用InterProcessMutex类,使用其中的acquire()方法,就可以获取一个分布式锁了。
Curator分布式锁使用示例
启动两个线程t1和t2去争夺锁,拿到锁的线程会占用5秒。运行多次可以观察到,有时是t1先拿到锁而t2等待,有时又会反过来。Curator会用我们提供的lock路径的结点作为全局锁,这个结点的数据类似这种格式:[_c_64e0811f-9475-44ca-aa36-c1db65ae5350-lock-00000000001],每次获得锁时会生成这种串,释放锁时清空数据。
接下来看看加锁的示例:
public class Application {
private static final String ZK_ADDRESS = "192.20.38.58:2181";
private static final String ZK_LOCK_PATH = "/locks/lock_01";
public static void main(String[] args) throws InterruptedException {
CuratorFramework client = CuratorFrameworkFactory.newClient(
ZK_ADDRESS,
new RetryNTimes(10, 5000)
);
client.start();
System.out.println("zk client start successfully!");
Thread t1 = new Thread(() -> {
doWithLock(client);
}, "t1");
Thread t2 = new Thread(() -> {
doWithLock(client);
}, "t2");
t1.start();
t2.start();
}
private static void doWithLock(CuratorFramework client) {
InterProcessMutex lock = new InterProcessMutex(client, ZK_LOCK_PATH);
try {
if (lock.acquire(10 * 1000, TimeUnit.SECONDS)) {
System.out.println(Thread.currentThread().getName() + " hold lock");
Thread.sleep(5000L);
System.out.println(Thread.currentThread().getName() + " release lock");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
运行结果:
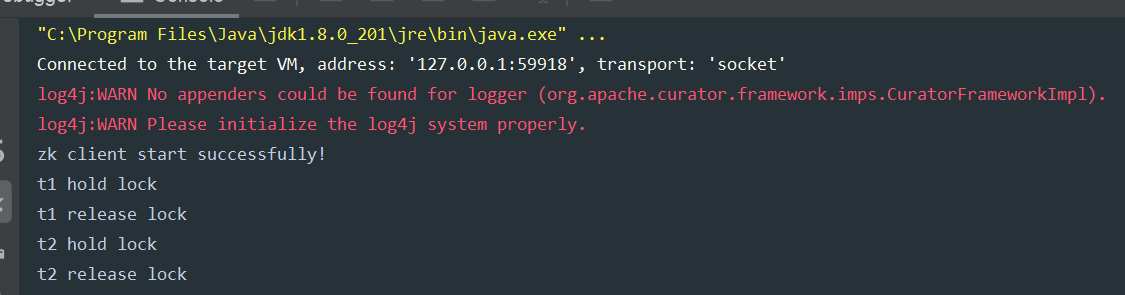 image.png
image.png
Curator 加锁实现原理
直接看Curator加锁的代码:
public class InterProcessMutex implements InterProcessLock, Revocable<InterProcessMutex> {
private final ConcurrentMap<Thread, LockData> threadData = Maps.newConcurrentMap();
private static class LockData
{
final Thread owningThread;
final String lockPath;
final AtomicInteger lockCount = new AtomicInteger(1);
private LockData(Thread owningThread, String lockPath)
{
this.owningThread = owningThread;
this.lockPath = lockPath;
}
}
@Override
public boolean acquire(long time, TimeUnit unit) throws Exception
{
return internalLock(time, unit);
}
private boolean internalLock(long time, TimeUnit unit) throws Exception
{
/*
Note on concurrency: a given lockData instance
can be only acted on by a single thread so locking isn't necessary
*/
Thread currentThread = Thread.currentThread();
LockData lockData = threadData.get(currentThread);
if ( lockData != null )
{
// re-entering
lockData.lockCount.incrementAndGet();
return true;
}
String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
if ( lockPath != null )
{
LockData newLockData = new LockData(currentThread, lockPath);
threadData.put(currentThread, newLockData);
return true;
}
return false;
}
}
直接看internalLock()方法,首先是获取当前线程,然后查看当前线程是否在一个concurrentHashMap中,这里是重入锁的实现,如果当前已经已经获取了锁,那么这个线程获取锁的次数再+1
如果没有获取锁,那么就是用attemptLock()方法去尝试获取锁,如果lockPath不为空,说明获取锁成功,并将当前线程放入到map中。
接下来看看核心的加锁逻辑attemptLock()方法:
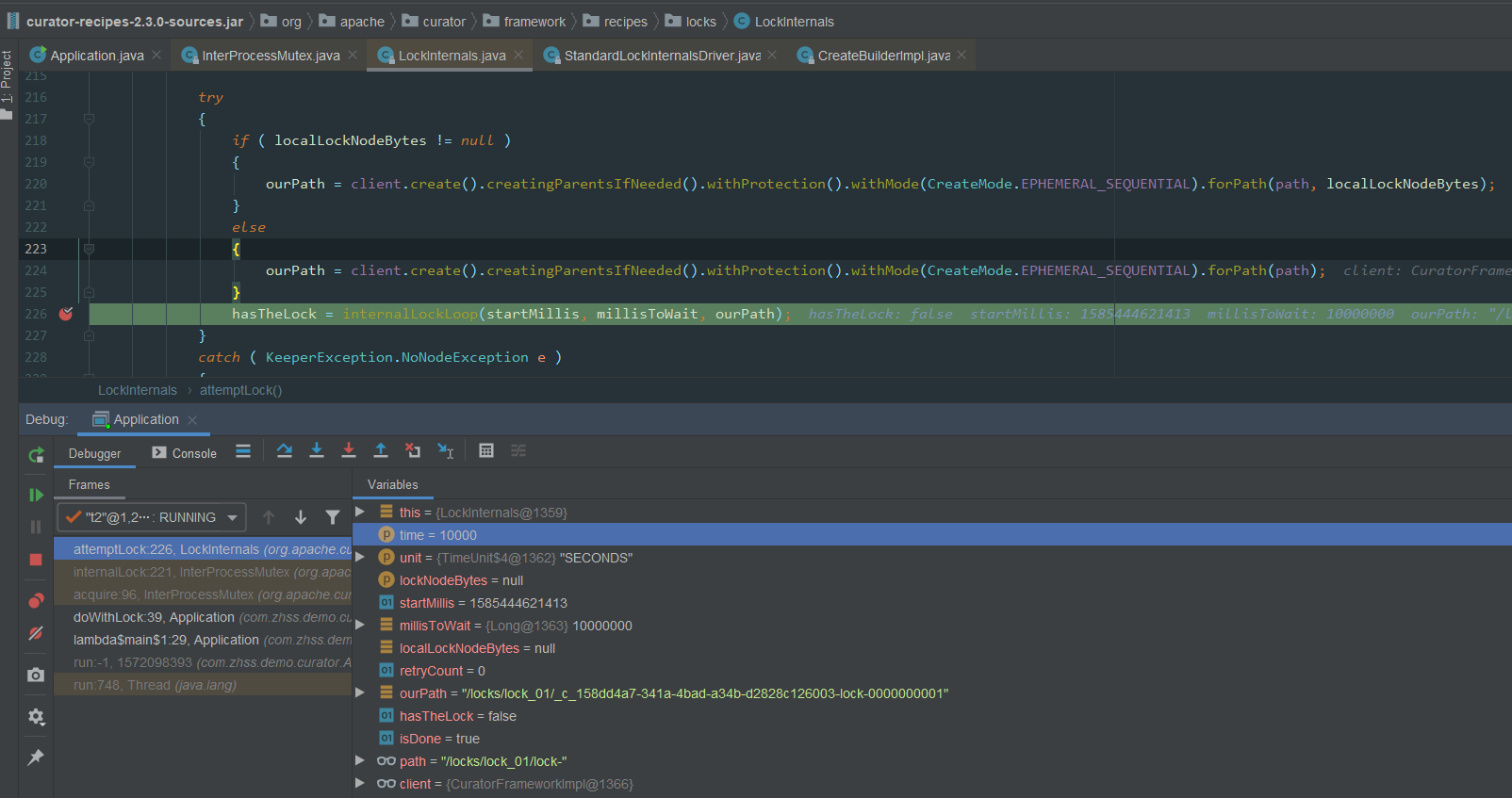
入参:time : 获取锁等待的时间unit:时间单位lockNodeBytes:默认为null
public class LockInternals {
String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception
{
final long startMillis = System.currentTimeMillis();
final Long millisToWait = (unit != null) ? unit.toMillis(time) : null;
final byte[] localLockNodeBytes = (revocable.get() != null) ? new byte[0] : lockNodeBytes;
int retryCount = 0;
String ourPath = null;
boolean hasTheLock = false;
boolean isDone = false;
while ( !isDone )
{
isDone = true;
try
{
if ( localLockNodeBytes != null )
{
ourPath = client.create().creatingParentsIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path, localLockNodeBytes);
}
else
{
ourPath = client.create().creatingParentsIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path);
}
hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);
}
catch ( KeeperException.NoNodeException e )
{
// gets thrown by StandardLockInternalsDriver when it can't find the lock node
// this can happen when the session expires, etc. So, if the retry allows, just try it all again
if ( client.getZookeeperClient().getRetryPolicy().allowRetry(retryCount++, System.currentTimeMillis() - startMillis, RetryLoop.getDefaultRetrySleeper()) )
{
isDone = false;
}
else
{
throw e;
}
}
}
if ( hasTheLock )
{
return ourPath;
}
return null;
}
}
ourPath = client.create().creatingParentsIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path);
使用的临时顺序节点,首先他是临时节点,如果当前这台机器如果自己宕机的话,他创建的这个临时节点就会自动消失,如果有获取锁的客户端宕机了,zk可以保证锁会自动释放的
创建的数据结构类似于:
客户端A获取锁的代码,生成的ourPath=xxxx01
客户端B获取锁的代码,生成的ourPath=xxxx02
查看Zookeeper中/locks/lock_01下所有临时节点数据:
 PS:01/02的图没有截到,这里又跑了一次截图所示 03/04 的顺序节点在ZK中的显示
PS:01/02的图没有截到,这里又跑了一次截图所示 03/04 的顺序节点在ZK中的显示
接着重点看interalLockLoop()的逻辑:
public class LockInternals {
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception
{
boolean haveTheLock = false;
boolean doDelete = false;
try
{
if ( revocable.get() != null )
{
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
}
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock )
{
List<String> children = getSortedChildren();
String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if ( predicateResults.getsTheLock() )
{
haveTheLock = true;
}
else
{
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this)
{
Stat stat = client.checkExists().usingWatcher(watcher).forPath(previousSequencePath);
if ( stat != null )
{
if ( millisToWait != null )
{
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 )
{
doDelete = true; // timed out - delete our node
break;
}
wait(millisToWait);
}
else
{
wait();
}
}
}
// else it may have been deleted (i.e. lock released). Try to acquire again
}
}
}
// 省略部分代码
return haveTheLock;
}
}
重点看while循环中的逻辑
首先是获取锁的逻辑:
- 获取
/locks/lock_01下排好序的znode节点,上面看图已经知道,会有xxx01和xxx02两个节点 - 调用
getsTheLock()方法获取锁,其中maxLeases为1,默认只能一个线程获取锁 - 定位到
StandardLockInternalsDriver.getsTheLock()方法,其中代码核心如下:int ourIndex = children.indexOf(sequenceNodeName);boolean getsTheLock = ourIndex < maxLeases; - 上面
sequenceNodeName参数为xxx01的全路径名,然后查看在排好序的children列表中是否为第一个元素,如果是第一个元素,返回的ourIndex=0,此时则认为获取锁成功 - 如果为有序列表中的第一个元素,那么
predicateResults.getsTheLock()为true,获取锁的标志位havaTheLock为true,直接返回获取锁成功
然后是获取锁失败的逻辑:
获取锁失败的核心代码:
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch(); synchronized(this)
{
Stat stat = client.checkExists().usingWatcher(watcher).forPath(previousSequencePath);
if ( stat != null )
{
if ( millisToWait != null )
{
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 )
{
doDelete = true; // timed out - delete our node
break;
} wait(millisToWait);
}
else
{
wait();
}
}
}
- 针对上一个节点添加监听器
- 如果加锁有过期时间,到了过期时间后直接break退出循环
- 当前线程处于wait()状态,等待上一个线程释放锁
Curator 释放锁实现原理
释放锁其实很简单,直接删除当前临时节点,因为下一个节点监听了上一个节点信息,所以上一个节点删除后,当前节点就会被唤醒重新获取锁。
private void deleteOurPath(String ourPath) throws Exception
{
try
{
client.delete().guaranteed().forPath(ourPath);
}
catch ( KeeperException.NoNodeException e )
{
// ignore - already deleted (possibly expired session, etc.)
}
}
总结
一张图总结:

04_Zookeeper分布式锁实现原理.jpg
原图可查看我的分享:
https://www.processon.com/view/link/5e80508de4b06b85300175d2
【分布式锁】06-Zookeeper实现分布式锁:可重入锁源码分析的更多相关文章
- ZooKeeper 分布式锁 Curator 源码 01:可重入锁
前言 一般工作中常用的分布式锁,就是基于 Redis 和 ZooKeeper,前面已经介绍完了 Redisson 锁相关的源码,下面一起看看基于 ZooKeeper 的锁.也就是 Curator 这个 ...
- Redis分布式锁—Redisson+RLock可重入锁实现篇
前言 平时的工作中,由于生产环境中的项目是需要部署在多台服务器中的,所以经常会面临解决分布式场景下数据一致性的问题,那么就需要引入分布式锁来解决这一问题. 针对分布式锁的实现,目前比较常用的就如下几种 ...
- java高并发系列 - 第12天JUC:ReentrantLock重入锁
java高并发系列 - 第12天JUC:ReentrantLock重入锁 本篇文章开始将juc中常用的一些类,估计会有十来篇. synchronized的局限性 synchronized是java内置 ...
- Java可重入锁如何避免死锁
本文由https://bbs.csdn.net/topics/390939500和https://zhidao.baidu.com/question/1946051090515119908.html启 ...
- java线程的同步控制--重入锁ReentrantLock
我们常用的synchronized关键字是一种最简单的线程同步控制方法,它决定了一个线程是否可以访问临界区资源.同时Object.wait() 和Object.notify()方法起到了线程等待和通知 ...
- 通俗易懂 悲观锁、乐观锁、可重入锁、自旋锁、偏向锁、轻量/重量级锁、读写锁、各种锁及其Java实现!
网上关于Java中锁的话题可以说资料相当丰富,但相关内容总感觉是一大串术语的罗列,让人云里雾里,读完就忘.本文希望能为Java新人做一篇通俗易懂的整合,旨在消除对各种各样锁的术语的恐惧感,对每种锁的底 ...
- 写文章 通俗易懂 悲观锁、乐观锁、可重入锁、自旋锁、偏向锁、轻量/重量级锁、读写锁、各种锁及其Java实现!
网上关于Java中锁的话题可以说资料相当丰富,但相关内容总感觉是一大串术语的罗列,让人云里雾里,读完就忘.本文希望能为Java新人做一篇通俗易懂的整合,旨在消除对各种各样锁的术语的恐惧感,对每种锁的底 ...
- Java 可重入锁的那些事(一)
本文主要包含的内容:可重入锁(ReedtrantLock).公平锁.非公平锁.可重入性.同步队列.CAS等概念的理解 显式锁 上一篇文章提到的synchronized关键字为隐式锁,会自动获取和自动释 ...
- ZooKeeper 分布式锁 Curator 源码 02:可重入锁重复加锁和锁释放
ZooKeeper 分布式锁 Curator 源码 02:可重入锁重复加锁和锁释放 前言 加锁逻辑已经介绍完毕,那当一个线程重复加锁是如何处理的呢? 锁重入 在上一小节中,可以看到加锁的过程,再回头看 ...
- ZooKeeper 分布式锁 Curator 源码 03:可重入锁并发加锁
前言 在了解了加锁和锁重入之后,最需要了解的还是在分布式场景下或者多线程并发加锁是如何处理的? 并发加锁 先来看结果,在多线程对 /locks/lock_01 加锁时,是在后面又创建了新的临时节点. ...
随机推荐
- Leetcode-Day Three
1002. Find Common Characters Given an array A of strings made only from lowercase letters, return a ...
- Angular4——7.表单处理
在Angular中存在两种表单处理方式: 模版驱动式表单 表单的数据模型是通过组件模版中的相关指令来定义的.由于使用这种方式定义表单的数据模型时,我们会受限于HTML的语法,所以,模版驱动方式只适用于 ...
- React Native Build Apk
1 React Native安卓项目打包APK 1.1 产生签名的key 先通过keytool生成key 1 keytool -genkey -v -keystore demo-release-key ...
- Mysql5.7.25安装步骤
安装步骤 在官网下载mysql-5.7.25-winx64.zip压缩包到本地,解压到非中文目录. 列如(D:\Program Files\mysql-5.7.25-winx64). 在环境变量中添加 ...
- Elasticsearch系列---深入全文搜索
概要 本篇介绍怎样在全文字段中搜索到最相关的文档,包含手动控制搜索的精准度,搜索条件权重控制. 手动控制搜索的精准度 搜索的两个重要维度:相关性(Relevance)和分析(Analysis). 相关 ...
- 从头认识js-DOM1
前面说过一个完整的js实现,包括ECMAScript,BOM,DOM三部分,现在就来讲讲DOM的有关知识. DOM(文档对象模型)是针对HTML和XML文档的一个API(应用程序接口).DOM描绘来一 ...
- Enbale IE mode in Edge
1. 打开Edge, 在地址栏输入 edge://flags/ 2. 搜索 Enable IE Integration , 配置为 IE mode 3. 找到Edge的启动程序路径.如 C:\Prog ...
- http协议概览
这里我只是对一些知识进行简单的整理,方便自己理解记忆,还有很多不完善的地方,更多细节,需要查看书籍或者其他文章 http协议的发展过程 HTTP 是基于 TCP/IP 协议的应用层协议.它不涉及数据包 ...
- css实战#用css画一个中国结
大家好!今天跟大家分享一个用 css 画中国结的教程.最终效果如下: 大家如果感兴趣可以参考我的源码:gitHub地址 首先,我们定义好画中国结需要的结构: <div class="k ...
- TCP/IP协议概要--01
学习一下tcp/ip协议,还是很枯燥,哎..... 图片的是从下到上对TCP/IP的协议进行描述的.主要是的描述每一层协议的特点 该层对应的是最底层的数据链路层,即图中的以太网驱动程序那一层. 该层是 ...