kaldi通用底层矩阵运算库——CUDA
cudamatrix/cublas-wrappers.h
该头文件对cuBLAS的接口进行了简单的封装(函数名的简化和部分kaldi函数的封装)。
比如
cublasSgemm_v2封装为cublas_gemm
cublas_copy_kaldi_fd和cublas_copy_kaldi_df封装为cublas_copy
cudamatrix/cu-kernels.{h,cu}
以cuda_add_col_sum_mat函数为例
对Kaldi cuda kernel或cublas进行了简单的封装(针对不同精度浮点型)
|
cudamatrix/cu-kernels.h inline void cuda_add_col_sum_mat(int Gr, int Bl, double* result, const double* mat, const MatrixDim d, const double alpha, const double beta) { cudaD_add_col_sum_mat(Gr, Bl, result, mat, d, alpha, beta); } inline void cuda_add_col_sum_mat(int Gr, int Bl, float* result, const float* mat, const MatrixDim d, const float alpha, const float beta) { cudaF_add_col_sum_mat(Gr, Bl, result, mat, d, alpha, beta); } //... } |
kernel的定义
|
cudamatrix/cu-kernels.cu // Reduce a matrix 'mat' to a column vector 'result' template<EnumTransformReduce TransReduceType, typename Real> __global__ static void _transform_reduce_mat_cols( Real *result, const Real *mat, const MatrixDim d, const TransReduceOp<TransReduceType, Real> op) { __shared__ Real sdata[CU1DBLOCK]; const int tid = threadIdx.x; const int i = blockIdx.x; const int row_start = i * d.stride; Real tdata = op.InitValue(); for (int j = tid; j < d.cols; j += CU1DBLOCK) { tdata = op.Reduce(tdata, op.Transform(mat[row_start + j])); } sdata[tid] = tdata; __syncthreads(); // Tree reduce # pragma unroll for (int shift = CU1DBLOCK / 2; shift > warpSize; shift >>= 1) { if (tid < shift) sdata[tid] = op.Reduce(sdata[tid], sdata[tid + shift]); __syncthreads(); } // Reduce last warp. Threads implicitly synchronized within a warp. if (tid < warpSize) { for (int shift = warpSize; shift > 0; shift >>= 1) sdata[tid] = op.Reduce(sdata[tid], sdata[tid + shift]); } // Output to vector result. if (tid == 0) { result[i] = op.PostReduce(sdata[0], result[i]); } } void cudaD_add_col_sum_mat(int Gr, int Bl, double* result, const double* mat, const MatrixDim d, const double alpha, const double beta) { _transform_reduce_mat_cols<<<Gr, Bl>>>(result, mat, d, TransReduceOp<SUMAB, double>(alpha, beta)); } |
cudamatrix/cu-vector.h
与matrix/kaldi-vector.h类似的,该头文件声明了几个向量类。与之不同的是,但其运算的实现基于CUDA或CBLAS。
class CuVectorBase
Cuda向量抽象类。该类对基础运算与内存优化进行了封装,只提供向量运算。不涉及尺寸缩放和构造函数。
尺寸缩放和构造函数由派生类CuVector和CuSubVector负责。
向量初始化
void SetZero();
向量信息
MatrixIndexT Dim() const { return dim_; }
向量的读取与转换
inline Real* Data() { return data_; }
inline Real operator() (MatrixIndexT i) const
CuSubVector<Real> Range(const MatrixIndexT o, const MatrixIndexT l)
向量的拷贝函数
void CopyFromVec(const CuVectorBase<Real> &v);
向量的运算
void ApplyLog();
void AddVec(const Real alpha, const CuVectorBase<OtherReal> &v, Real beta = 1.0);
//*this += alpha * M [or M^T]
//linear_params_.AddMat(alpha, other->linear_params_);
//linear_params_ += alpha * other->linear_params_
void AddMat ( const Real alpha,
const MatrixBase< Real > & M,
MatrixTransposeType transA = kNoTrans
)
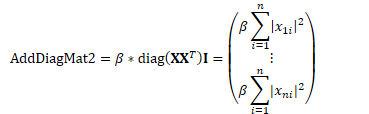
//*this = alpha * diag(M * M^T) + beta * *this
|
diag(M M^T)+beta ** M (1 2 3) (4 5 6) (7 8 9) (1 4 7) (2 5 8) (3 6 9) (1^2+2^2+3^2, *, *) (*, 4^2+5^2+6^2, *) (*, *, 7^2+8^2+9^2) diag=() |
void CuVectorBase<Real>::AddDiagMat2(Real alpha, const CuMatrixBase<Real> &M,
MatrixTransposeType trans, Real beta) {
//*this = alpha * diag(M * M^T) + beta * *this
this->AddDiagMatMat(alpha, M, trans, M, other_trans, beta);
}
//*this = alpha * diag(M * N^T) + beta * *this
void CuVectorBase<Real>::AddDiagMatMat(Real alpha, const CuMatrixBase<Real> &M,
MatrixTransposeType transM,
const CuMatrixBase<Real> &N,
MatrixTransposeType transN, Real beta) {
// v = alpha * diag(M * N^T) + beta * v
static void _add_diag_mat_mat_MNT(const Real alpha, const Real* M,
const MatrixDim dim_M, const Real* N,
const int stride_N, const Real beta,
Real* v)
//data_ = alpha * diag(M.Data() * N.Data()^T) + beta * data_
cuda_add_diag_mat_mat_MNT(dimGrid, dimBlock, alpha, M.Data(), M.Dim(),
N.Data(), N.Stride(), beta, data_);
class CuVector: public CuVectorBase<Real>
该类表示普通Cuda向量,并实现尺寸缩放和一般的构造函数。
多种构造函数
explicit CuVector(const CuVector<Real> &v) : CuVectorBase<Real>() {
Resize(v.Dim(), kUndefined);
this->CopyFromVec(v);
}
template<typename OtherReal>
explicit CuVector(const CuVectorBase<OtherReal> &v) : CuVectorBase<Real>() {
Resize(v.Dim(), kUndefined);
this->CopyFromVec(v);
}
template<typename OtherReal>
explicit CuVector(const VectorBase<OtherReal> &v) : CuVectorBase<Real>() {
Resize(v.Dim(), kUndefined);
this->CopyFromVec(Vector<Real>(v));
}
重载赋值运算符
CuVector<Real> &operator = (const CuVectorBase<Real> &other) {
Resize(other.Dim(), kUndefined);
this->CopyFromVec(other);
return *this;
}
CuVector<Real> &operator = (const CuVector<Real> &other) {
Resize(other.Dim(), kUndefined);
this->CopyFromVec(other);
return *this;
}
CuVector<Real> &operator = (const VectorBase<Real> &other) {
Resize(other.Dim());
this->CopyFromVec(other);
return *this;
}
Utils
void Swap(CuVector<Real> *vec);
void Swap(Vector<Real> *vec);
void Resize(MatrixIndexT length, MatrixResizeType resize_type = kSetZero);
class CuSubVector: public CuVectorBase<Real>
该类表示一个不占有实际数据的泛化向量或向量索引,可以表示高级向量的子向量或矩阵的行。实现多种用于索引的构造函数。
多种构造函数
CuSubVector(const CuVectorBase<Real> &t, const MatrixIndexT origin,
const MatrixIndexT length) : CuVectorBase<Real>() {
KALDI_ASSERT(static_cast<UnsignedMatrixIndexT>(origin)+
static_cast<UnsignedMatrixIndexT>(length) <=
static_cast<UnsignedMatrixIndexT>(t.Dim()));
CuVectorBase<Real>::data_ = const_cast<Real*>(t.Data()+origin);
CuVectorBase<Real>::dim_ = length;
}
/// Copy constructor
/// this constructor needed for Range() to work in base class.
CuSubVector(const CuSubVector &other) : CuVectorBase<Real> () {
CuVectorBase<Real>::data_ = other.data_;
CuVectorBase<Real>::dim_ = other.dim_;
}
CuSubVector(const Real* data, MatrixIndexT length) : CuVectorBase<Real> () {
// Yes, we're evading C's restrictions on const here, and yes, it can be used
// to do wrong stuff; unfortunately the workaround would be very difficult.
CuVectorBase<Real>::data_ = const_cast<Real*>(data);
CuVectorBase<Real>::dim_ = length;
}
cudamatrix/cu-matrix.h
与matrix/kaldi-matrixr.h类似的,该头文件声明了几个矩阵类。与之不同的是,但其运算的实现基于CUDA或CBLAS。当Kaldi基于CUDA环境编译且GPU可用(CuDevice::Instantiate().Enabled() == true)则使用CUDA卡进行计算,否则使用CPU进行计算(CBLAS)。
class CuMatrixBase
Cuda矩阵抽象类。该类对基础运算与内存优化进行了封装,只提供矩阵运算。不涉及尺寸缩放和构造函数。
尺寸缩放和构造函数由派生类CuMatrix和CuSubMatrix负责。
class CuMatrix
该类表示普通Cuda矩阵,并实现尺寸缩放和一般的构造函数。
class CuSubMatrix
该类表示一个不占有实际数据的泛化矩阵或矩阵索引,可以表示其他矩阵的矩阵。实现多种用于索引的构造函数。
继承于CuMatrixBase,用于对矩阵的子矩阵(块矩阵)进行运算。
kaldi通用底层矩阵运算库——CUDA的更多相关文章
- kaldi通用底层矩阵运算库——CBLAS
matrix/cblas-wrappers.h 该头文件对CBLAS与CLAPACK的接口进行了简单的封装(将不同数据类型的多个接口封装为一个). 比如 cblas_scopy和cblas_dcopy ...
- C++矩阵运算库推荐
最近在几个地方都看到有人问C++下用什么矩阵运算库比较好,顺便做了个调查,做一些相关的推荐吧.主要针对稠密矩阵,有时间会再写一个稀疏矩阵的推荐. Armadillo:C++下的Matlab替代品 地址 ...
- C++通用框架和库
C++通用框架和库 来源 https://www.cnblogs.com/skyus/articles/8524408.html 关于 C++ 框架.库和资源的一些汇总列表,内容包括:标准库.Web应 ...
- Python底层socket库
Python底层socket库将Unix关于网络通信的系统调用对象化处理,是底层函数的高级封装,socket()函数返回一个套接字,它的方法实现了各种套接字系统调用.read与write与Python ...
- C++矩阵运算库armadillo配置笔记
前言 最近在用C++实现神经网络模型,优化算法需要用到矩阵操作,一开始我用的是boost的ublas库,但用着用着感觉很不习惯,接口不够友好.于是上网搜索矩阵运算哪家强,大神们都推荐armadillo ...
- uTenux——重新整理底层驱动库
重新整理底层驱动库 1. 整理chip.h 在chip.h文件中的07----13的宏定义设置位如下,这样我们就不用在工程配中定义sam3s4c这个宏了,为我们以后通用少了一件麻烦事. //#if d ...
- .net通用底层搭建
.net通用底层搭建 之前写过几篇,有朋友说看不懂,有朋友说写的有点乱,自己看了下,的确是需要很认真的看才能看懂整套思路. 于是写下了这篇. 1.这个底层,使用的是ado.net,微软企业库 2.实体 ...
- YARN底层基础库
YARN基础库是其他一切模块的基础,它的设计直接决定了YARN的稳定性和扩展性,YARN借用了MRV1的一些底层基础库,比如RPC库等,但因为引入了很多新的软件设计方式,所以它的基础库更多,包括直 ...
- Duanxx的Design abroad: C++矩阵运算库Eigen 概要
一.概要 这两天想起来要做神经网络的作业了,要求用C++完毕神经网络的算法. 摆在面前的第一个问题就是,神经网络算法中大量用到了矩阵运算.可是C++不像matlab那样对矩阵运算有非常好的支持.本来准 ...
随机推荐
- 关于Http
摘自:菜鸟教程 HTTP简介 HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(www)服务器传输超文本到本地浏览器的传送协议. HTTP ...
- vue typescript ui库
https://blog.csdn.net/phj_88/article/details/81302043 vuetifyjs
- 百度地图引用时 报出A Parser-blocking, cross site (i.e. different eTLD+1) script
页面引入百度地图api时 chrome控制台报出警示问题 A Parser-blocking, cross site (i.e. different eTLD+1) script, http://ap ...
- Spring AOP 五大通知类型
1.前置通知 在目标方法执行之前执行执行的通知. 前置通知方法,可以没有参数,也可以额外接收一个JoinPoint,Spring会自动将该对象传入,代表当前的连接点,通过该对象可以获取目标对象 和 目 ...
- ztree 获取子节点所有父节点的name的拼接
ztree 获取子节点所有父节点的name的拼接 //获取子节点,所有父节点的name的拼接字符串function getFilePath(treeObj){if(treeObj==null)retu ...
- 超链接标签绑定JS事件&&不加"javascript:;"导致的杯具
很久以来,在写Html和JS时,经常会给超链接<a>标签,绑定JS事件. 我们经常看到这样的写法,<a href="javascript:;" onclick=& ...
- swift学习 引入三方遇到的问题
问题来源: 1.swift项目pods MJRefresh 为了在swift正常使用 建了一个桥接文件 2.在项目中又使用了 SDWebImage 用于加载网络图片 根据说明加了Podfile一个 ...
- LinkedHashMap源码分析
hashMap源码分析:hashMap源码分析 版本说明:jdk1.7LinkedHashMap继承于HashMap,是一个有序的Map接口的实现.有序指的是元素可以按照一定的顺序排列,比如元素的插入 ...
- mysql5.6.x 字符集修改
1 安装好mysql5.6.x 之后,修改字符集配置为utf8才能支持中文,因为默认为latin1 查看mysql字符集命令: SHOW VARIABLES LIKE 'char%' 2 修改配置文件 ...
- Tomcat热部署--start tomcat后就可自动部署war包
使用tomcat图形化界面,需要现在配置文件中设置用户名和密码: 在maven中配置Tomcat插件: root目录下的内容可以直接访问: 跳过测试: 查看端口占用: