python简单爬虫 用lxml解析页面中的表格
目标:爬取湖南大学2018年在各省的录取分数线,存储在txt文件中
部分表格如图:
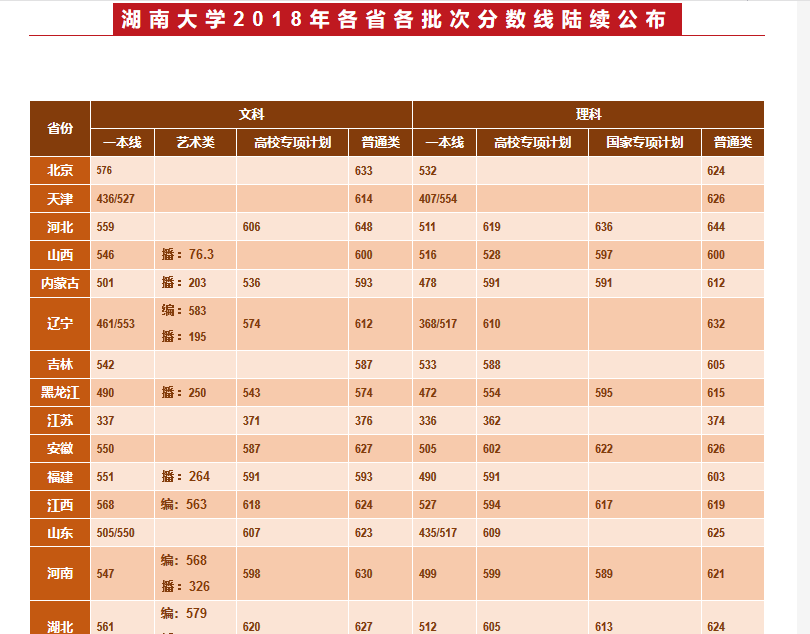
部分html代码:
<table cellspacing="0" cellpadding="0" border="1">
<tbody>
<tr class="firstRow" >
<td rowspan="2" ><p ><strong><span >省份</span></strong></p></td>
<td colspan="4" ><p ><strong><span >文科</span></strong></p></td>
<td colspan="4" ><p ><strong><span >理科</span></strong></p></td>
</tr>
<tr >
<td ><p ><strong><span >一本线</span></strong></p></td>
<td ><p ><strong><span >艺术类</span></strong></p></td>
<td ><p ><strong><span >高校专项计划</span></strong></p></td>
<td ><p ><strong><span >普通类</span></strong></p></td>
<td ><p ><strong><span >一本线</span></strong></p></td>
<td ><p ><strong><span >高校专项计划</span></strong></p></td>
<td ><p ><strong><span >国家专项计划</span></strong></p></td>
<td ><p ><strong><span >普通类</span></strong></p></td>
</tr>
<tr >
<td ><p ><strong><span >北京</span></strong></p></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">576</span></strong></span></p></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">633</span></strong></span></p></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">532</span></strong></span></p></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">624</span></strong></span></p></td>
</tr>
<tr >
<td ><p ><strong><span >天津</span></strong></p></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">436/527</span></strong></span></p></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">614</span></strong></span></p></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">407/554</span></strong></span></p></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><br></td>
<td valign="middle" align="left"><p ><span ><strong><span lang="EN-US">626</span></strong> </span></p></td>
</tr> ...... <tr >
<td ><p ><strong><span >上海</span></strong></p></td>
<td colspan="8" valign="top"><p ><strong><span >本科线</span></strong><strong><span lang="EN-US">/</span></strong><strong><span >自主招生参考线:</span></strong><strong><span lang="EN-US">401/502</span></strong><strong><span >;</span></strong><strong><span lang="EN-US"> </span></strong><strong><span >(专业组)最低投档线:<span >533</span></span></strong></p></td>
</tr>
<tr >
<td ><p ><strong><span >浙江</span></strong></p></td>
<td colspan="8" valign="top"><p ><strong><span >本科线</span></strong><strong><span lang="EN-US">/</span></strong><strong><span >一段线:</span></strong><strong><span lang="EN-US">344/588</span></strong><strong><span >;</span></strong><strong><span lang="EN-US"> </span></strong><strong><span >(专业)最低投档线:639</span></strong></p></td>
</tr>
</tbody>
</table>
代码:
import requests
from lxml import etree # 设置URL地址和请求头
url = 'http://admi.hnu.edu.cn/info/1024/3094.htm'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36',
'Cookie': 'ASP.NET_SessionId=yolmu555asckw145cetno0um'
} # 发送请求并解析HTML对象
response = requests.get(url, headers=headers)
html = etree.HTML(response.content.decode('utf-8')) # 数据解析
table = html.xpath("//table//tr[position()>2]") # XPath定位到表格,因为页面只有一个表格,所以直接//table,
# 如果有多个表格,如取第二个表格,则写为//table[1] 偏移量为1 。我们不取表头信息,所以从tr[3]开始取,返回一个列表 dep = [] for i in table: # 遍历tr列表
p = ''.join(i.xpath(".//td[1]//text()")) # 获取当前tr标签下的第一个td标签,并用text()方法获取文本内容,赋值给p
sl = ''.join(i.xpath(".//td[6]//text()"))
sc = ''.join(i.xpath(".//td[9]//text()"))
ll = ''.join(i.xpath(".//td[2]//text()"))
lc = ''.join(i.xpath(".//td[5]//text()")) print(p, sl, sc, ll, lc)
data = { # 用数据字典,存储需要的信息
'省份': ''.join(p.split()), # .split()方法在此处作用是除去p中多余的空格 '\xa0'
'理科一本线': ''.join(sl.split()),
'理科投档线': ''.join(sc.split()),
'文科一本线': ''.join(ll.split()),
'文科投档线': ''.join(lc.split())
}
print(data)
dep.append(data) #数据存储
with open('2018enro.txt', 'w', encoding='utf-8') as out_file:
out_file.write("湖南大学:"+"2018年各省录取分数线:\n\n")
for i in dep:
out_file.write(str(i)+'\n')
注:原本数据字典是这样写的:
for i in table:
data = { # 用数据字典,存储需要的信息
'省份': ''.join(i.xpath(".//td[1]//text()")),
'理科一本线': ''.join(i.xpath(".//td[6]//text()")),
'理科投档线': ''.join(i.xpath(".//td[9]//text()")),
'文科一本线': ''.join(i.xpath(".//td[2]//text()")),
'文科投档线': ''.join(i.xpath(".//td[5]//text()"))
}
输出结果有很多‘\xa0’,其实就是空格,源网页中就字段里就存在很多空格:


plus:解析表格有更好的方法,比如pandas,一步到位!非常方便。
详情请看我的另一篇文章:
https://www.cnblogs.com/cttcarrotsgarden/p/10769097.html
python简单爬虫 用lxml解析页面中的表格的更多相关文章
- python简单爬虫 用lxml库解析数据
目标:爬取湖南大学2018年本科招生章程 url:http://admi.hnu.edu.cn/info/1026/2993.htm 页面部分图片: 使用工具: Python3.7 火狐浏览器 PyC ...
- python简单爬虫 使用pandas解析表格,不规则表格
url = http://www.hnu.edu.cn/xyxk/xkzy/zylb.htm 部分表格如图: 部分html代码: <table class="MsoNormalTabl ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- python简单爬虫一
简单的说,爬虫的意思就是根据url访问请求,然后对返回的数据进行提取,获取对自己有用的信息.然后我们可以将这些有用的信息保存到数据库或者保存到文件中.如果我们手工一个一个访问提取非常慢,所以我们需要编 ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
- 【转】一张图解析FastAdmin中的表格列表的功能
一张图解析FastAdmin中的表格列表的功能 功能描述请根据图片上的数字索引查看对应功能说明. 1.时间筛选器如果想在搜索栏使用时间区间进行搜索,则可以在JS中修改修改字段属性,如 {field: ...
- jQuery 中使用 DOM 操作节点,对页面中的表格实现增、删、查、改操作
查看本章节 查看作业目录 需求说明: 在 jQuery 中使用 DOM 操作节点,对页面中的表格实现增.删.查.改操作 点击"增加"超链接时,将表格中的第一条数据添加到表格的末尾 ...
随机推荐
- Java基础学习-流程控制语句
在一个程序执行的过程中,各条语句的执行顺序对程序的结果是有直接影响的.也就是说程序的流程对运行结果有直接的影响.所以,我们必须清楚每条语句的执行流程.而且,很多时候我们要通过控制语句的执行顺序来实现我 ...
- JVM即时编译器
为何HotSpot虚拟机要使用解释器与编译器并存的架构? 为何HotSpot虚拟机要实现两个不同的即时编译器? 程序何时使用解释器执行?何时使用编译器执行? 哪些程序代码会被编译为本地代码?如何编译为 ...
- java 有序数组合并
有序数组合并,例如: 数组 A=[100, 89, 88, 67, 65, 34], B=[120, 110, 103, 79, 66, 35, 20] 合并后的结果 result=[120, 110 ...
- 排查OPENSTACK浮动IP被占用记录
在openstack上新建机器时,发现用户无法登陆. 检查该机器的22端口,返回 Connection refused. ping该IP,发现可以ping通. 释放该浮动ip,然后去ping该 ...
- Web 前端技术图谱-菜鸟教程
- vue全局组件-父子组件传值
全局组件注册方式:Vue.component(组件名,{方法}) demo: 子组件:upload.vue <template> <div > <div class=&q ...
- VS code 推荐插件
vs code 中eslint语法检测,保存即可格式化 具体查看:(https://www.jianshu.com/p/23a5d6194a4b) { // vscode默认启用了根据文件类型自动设置 ...
- springboot返回页面
1.使用@Controller注解: @Controller必须配合模板 先导入依赖: <dependency> <groupId>org.springframework.bo ...
- 【差分约束系统】 note
[差分约束系统] note >>>>题目 [题目描述] 最近有一款很火的游戏,叫做八分音符酱,它和马里奥很相似,不过它的跳跃距离是由你的声音大小来控制的.不过我们现在对玩法就行 ...
- jQuery的版本兼容问题
之前在做头像上传的时候,使用的jQuery是1.8.2的版本,然后头像上传做完后,发现项目用的jQuery版本是3.3.1的.由于两个版本的差距太大了.所以兼容很差. 3.3.1不支持剪切头像的某些函 ...