Spark入门到精通--(第十节)环境搭建(ZooKeeper和kafka搭建)
上一节搭建完了Hive,这一节我们来搭建ZooKeeper,主要是后面的kafka需要运行在上面。
ZooKeeper下载和安装
下载ZooKeeper 3.4.5软件包 ,可以在百度网盘进行下载。链接: http://pan.baidu.com/s/1gePE9O3 密码: unmt。
,可以在百度网盘进行下载。链接: http://pan.baidu.com/s/1gePE9O3 密码: unmt。
下载完用Xftp上传到spark1服务器,我是放在/home/software目录下。
[root@spark1 lib]# cd /home/software/
[root@spark1 software]# tar -zxf zookeeper-3.4.5.tar.gz //解压
[root@spark1 software]# mv zookeeper-3.4.5 /usr/lib/zookeeper //重命名并移到/usr/lib目录下
[root@spark1 software]# cd /usr/lib
设置ZooKeeper环境变量。
[root@spark1 lib]# vi ~/.bashrc //配置环境变量 //添加变量,别忘了Path的变量也要修改 export ZOOKEEPER_HOME=/usr/lib/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin //加上ZooKeeper的路径

保存退出,是文件生效。
[root@spark1 lib]# source ~/.bashrc
完成之后我们开始配置ZooKeeper的配置文件。
- 修改zoo_sample.cfg文件,并且重命名为zoo.cfg。
[root@spark1 lib]# cd zookeeper/conf/ [root@spark1 conf]# mv zoo_sample.cfg zoo.cfg [root@spark1 conf]# vi zoo.cfg //修改dataDir
dataDir=/usr/lib/zookeeper/data //添加(最少配置三个节点)
server.0=spark1:2888:3888
server.1=spark2:2888:3888
server.2=spark3:2888:3888
修改完成保存退出。
然后我们去/usr/lib/zookeeper目录下创建data文件夹,设置标示。
[root@spark1 conf]# cd ..
[root@spark1 zookeeper]# mkdir data
[root@spark1 zookeeper]# cd data //创建一个myid文件
[root@spark1 data]# vi myid //添加0
0
修改完成保存退出。
- 将配置文件拷贝到spark2和spark3上,同时myid文件里分别设置1和2.
[root@spark1 data]# cd /usr/lib //拷贝到spark2上
[root@spark1 lib]# scp -r zookeeper root@spark2:/usr/lib/ [root@spark2 lib]# scp ~/.bashrc root@spark2:~/ //拷贝过去别忘了在spark2上执行source ~/.bashrc命令,使生效
完成后同样在spark3上也拷贝一份。(分别将myid文件里设置为1和2)
- 启动ZooKeeper集群
在三台服务器上分别启动,并检查ZooKeeper状态。
[root@spark1 lib]# zookeeper/bin/zkServer.sh start
三台都启动完成后执行查看启动情况。
[root@spark1 lib]# zookeeper/bin/zkServer.sh status JMX enabled by default
Using config: /usr/lib/zookeeper/bin/../conf/zoo.cfg
Mode: leader //关闭 zookeeper/bin/zkServer.sh stop
//重启 zookeeper/bin/zkServer.sh restart
第一台出现Mode:leader,另外2台是Mode:follower,代表OK,ZooKeeper集群完成!
Scala安装
由于之前在第二节已经讲过Scala安装的过程了,现在只要把spark2和spark3都安装上Scala就好了,就不多说了。
kafka安装
下载kafka 2.9.2软件包 ,可以在百度网盘进行下载。链接: http://pan.baidu.com/s/1gePE9O3 密码: unmt。
,可以在百度网盘进行下载。链接: http://pan.baidu.com/s/1gePE9O3 密码: unmt。
下载完用Xftp上传到spark1服务器,我是放在/home/software目录下。
[root@spark1 lib]# cd /home/software/
[root@spark1 software]# tar -zxf kafka_2.9.2-0.8.1.tgz
[root@spark1 software]# mv kafka_2.9.2-0.8.1 /usr/lib/kafka
[root@spark1 software]# cd /usr/lib
- 配置kafka
修改配置文件 server.properties文件。
[root@spark1 lib]# vi kafka/config/server.properties //broker.id是唯一的,默认从0开始
broker.id=0 //修改zookeeper.connect
zookeeper.connect=spark1:2181,spark2:2181,spark3:2181
slf4j安装
下载slf4j 1.7.6软件包 ,放到/home/software目录下。
,放到/home/software目录下。
[root@spark1 software]# unzip slf4j-1.7.6.zip //解压 //我们把slf4j-1.7.6/slf4j-nop-1.7.6.jar拷贝到kafka的lib下
[root@spark1 software]# cp slf4j-1.7.6/slf4j-nop-1.7.6.jar /usr/lib/kafka/libs/
完成后我们在spark1上的kafka安装完成,然后我们继续把kafka拷贝到spark2和spark3上。(分别将kafka/conf/下的server.properties文件里broker.id设置为1和2)
[root@spark1 lib]# scp -r kafka root@spark2:/usr/lib/
之后可能有些人kafka的集群和JVM不匹配,需要在三台服务器上做个配置。
[root@spark1 kafka]# vi bin/kafka-run-class.sh //在配置文件中把-XX:+UseCompressedOops 给去掉
- 完成之后我们分别在三台服务器上启动kafka集群
[root@spark1 lib]# cd kafka/ //要在kafka目录下 //启动
[root@spark1 kafka]# nohup bin/kafka-server-start.sh config/server.properties &
[root@spark1 kafka]# jps
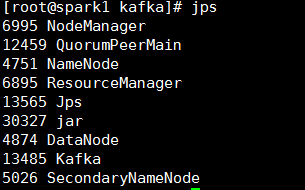
至此kafka配置完成。有问题可以看:http://www.aboutyun.com/thread-12847-1-1.html
kafka测试
//我们创建一个topic
[root@spark1 kafka]# bin/kafka-topics.sh --zookeeper spark1:2181,spark2:2181,spark3:2181 --topic TestTopic --replication-factor 1 --partitions 1 --create //创建producer
[root@spark1 kafka]# bin/kafka-console-producer.sh --broker-list 10.168.21.169:9092,10.162.59.47:9092,10.168.42.26:9092 --topic TestTopic //创建comsumer
[root@spark1 kafka]# bin/kafka-console-consumer.sh --zookeeper 10.168.21.169:2181,10.162.59.47:2181,10.168.42.26:2181 --topic TestTopic --from-beginning


这样我们生产者-消费者的测试hello world没问题。
Spark入门到精通--(第十节)环境搭建(ZooKeeper和kafka搭建)的更多相关文章
- Spark入门到精通--(第九节)环境搭建(Hive搭建)
上一节搭建完了Hadoop集群,这一节我们来搭建Hive集群,主要是后面的Spark SQL要用到Hive的环境. Hive下载安装 下载Hive 0.13的软件包,可以在百度网盘进行下载.链接: h ...
- Spark入门到精通--(第二节)Scala编程详解基础语法
Scala是什么? Scala是以实现scaleable language为初衷设计出来的一门语言.官方中,称它是object-oriented language和functional languag ...
- Spark修炼之道(进阶篇)——Spark入门到精通:第九节 Spark SQL执行流程解析
1.总体执行流程 使用下列代码对SparkSQL流程进行分析.让大家明确LogicalPlan的几种状态,理解SparkSQL总体执行流程 // sc is an existing SparkCont ...
- Spark入门到精通--(第一节)Spark的前世今生
最近由于公司慢慢往spark方面开始转型,本人也开始学习,今后陆续会更新一些spark学习的新的体会,希望能够和大家一起分享和进步. Spark是什么? Apache Spark™ is a fast ...
- Simulink仿真入门到精通(十九) 总结回顾&自我练习
从2019年12月27到2020年2月12日,学习了Simulink仿真及代码生成技术入门到精通,历时17天. 学习的比较粗糙,有一些地方还没理解透彻,全书梳理总结: Simulink的基础模块已基本 ...
- Spark入门到精通--(第七节)环境搭建(服务器搭建)
Spark搭建集群比较繁琐,需要的内容比较多,这里主要从Centos.Hadoop.Hive.ZooKeeper.kafka的服务器环境搭建开始讲.其中Centos的搭建不具体说了,主要讲下集群的配置 ...
- Hibernate从入门到精通(十)多对多单向关联映射
上一篇文章Hibernate从入门到精通(九)一对多双向关联映射中我们讲解了一下关于一对多关联映射的相关内容,这次我们继续多对多单向关联映射. 多对多单向关联映射 在讲解多对多单向关联映射之前,首先看 ...
- [置顶] Hibernate从入门到精通(十)多对多单向关联映射
上一篇文章Hibernate从入门到精通(九)一对多双向关联映射中我们讲解了一下关于一对多关联映射的相关内容,这次我们继续多对多单向关联映射. 多对多单向关联映射 在讲解多对多单向关联映射之前,首先看 ...
- Spark入门到精通--(第八节)环境搭建(Hadoop搭建)
上一节把Centos的集群免密码ssh登陆搭建完成,这一节主要讲一下Hadoop的环境搭建. Hadoop下载安装 下载官网的Hadoop 2.4.1的软件包.http://hadoop.apache ...
随机推荐
- mybatis 查询单个对象,结果集类型一定要明确
简单介绍:用ssm框架已经有很长时间了,但是似乎从来都没有对于查询单个对象,存在问题的,好像也就是那回事,写完sql就查出来了,也从来都没有认真的想过,为什么会这样,为什么要设置结果集类型 代码: / ...
- 1、Filebeat概述
Filebeat是一个轻量级的日志托运工具,用于转发和集中日志数据. Filebeat作为代理安装在服务器上,监控指定的日志文件或目录,收集日志事件,并将它们转发到Elasticsearch或Logs ...
- iOS开发多线程之GCD
Grand Central Dispatch(GCD)是异步执行任务的技术之一.一般将应用程序中记述的线程管理用的代码在系统级中实现.开发者只需要定义想执行的任务并追加到适当的Dispatch Que ...
- VIM编辑常用命令
1.临时使用获取root权限保存文件 :w !sudo tee % 2.多标签编辑文件 :tabnew file 3.切换标签 :tabm N (N为第几个标签,从0开始)
- 10分钟理解JS引擎的执行机制
首先,请牢记2点: (1) JS是单线程语言 (2) JS的Event Loop是JS的执行机制.深入了解JS的执行,就等于深入了解JS里的event loop 1.灵魂三问 (1) JS为什么是单线 ...
- Gradle sync failed: SSL peer shut down incorrectly
http://www.th7.cn/Program/Android/201604/817127.shtml 问题是在更新版本后出现的,被墙隔断的原因 引自大神解决方案 这个问题通常出现在Android ...
- ReSharper反编译C#类库
经常会在使用C#类中的某个函数时想了解其中具体的代码,可是F12转到定义后只能看到函数简单的声明, 看不到方法体中的代码,这挺让人沮丧的.. 如下: F12进入后显示的是元数据, Equals函数只能 ...
- 527D.Clique Problem
题解: 水题 两种做法: 1.我的 我们假设$xi>xj$ 那么拆开绝对值 $$xi-w[i]>x[j]+w[j]$$ 由于$w[i]>0$,所以$x[i]+w[i]>x[j] ...
- ionic2中使用videogular2实现m3u8文件播放
// 安装依赖 npm i videogular2 --save npm i hls.js --save // 在index.html中引入 <script src="assets/h ...
- Andy's First Dictionary---set,stringstream
https://cn.vjudge.net/contest/177260#problem/C stringstream :https://blog.csdn.net/xw20084898/articl ...