Oracle DB管理内存
• 描述SGA 中的内存组件
• 实施自动内存管理
• 手动配置SGA 参数
• 配置自动PGA 内存管理
内存管理:概览
DBA 必须将内存管理视为其工作中至关重要的部分,因为:
• 可用内存空间量有限
• 为某些类型的功能分配更多内存可提高整体性能
• 自动优化的内存分配通常是正确的配置,但特定环境甚至短期情况下可能需要特别注意
由于数据库服务器上的可用内存量有限,因此,对于Oracle DB 实例,必须注意内存的分配情况。如果将过多的内存分配给没有此需求的特定区域使用,则很可能导致其它功能区没有足够的内存,无法以最优方式工作。采用自动确定和维护内存分配的功能,极大地简化了该项任务。但是,要实现系统内存最佳利用,即使是自动优化的内存也需要进行监控,有时可能还需要某种程度的手动配置。
复查Oracle DB 内存结构
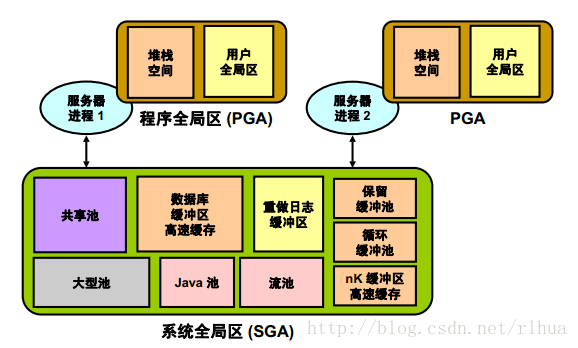
复查Oracle DB 内存结构
Oracle DB 创建并使用内存结构来满足多种用途。例如,内存可以存储正在运行的程序代码、用户间共享的数据以及每个已连接的用户的专用数据区域。
一个实例有两个关联的基本内存结构:
• 系统全局区(SGA) :一组共享的内存结构(称为 SGA 组件),其中包含一个 Oracle DB 实例的数据和控制信息。SGA 在所有服务器和后台进程之间共享。SGA 中存储的数据的示例包括高速缓存的数据块和共享SQL 区域。
• 程序全局区(PGA) :包含服务器进程或后台进程的数据及控制信息的内存区域。PGA 是Oracle DB 在服务器进程或后台进程启动时创建的非共享内存。服务器进程对PGA 的访问是独占的。每个服务器进程和后台进程都具有自己的PGA 。
SGA 是包含实例的数据和控制信息的内存区。SGA 包含以下数据结构:
• 共享池:用于缓存可在用户间共享的各种构造
• 数据库缓冲区高速缓存:用于缓存从数据库中检索到的数据块
• 保留缓冲池:一种经过优化的专用数据库缓冲区高速缓存,用于长时间在内存中保留数据块
• 回收缓冲池:一种经过优化的专用数据库缓冲区高速缓存,用于从内存中快速回收或删除数据块
• nK 缓冲区高速缓存:几种专用数据库缓冲区高速缓存之一,用于存放与默认数据库块大小不同的块大小
• 重做日志缓冲区:用来缓存用于恢复实例的重做信息,直到可以将其写入磁盘中存储的物理重做日志文件
• 大型池:可选区域,用于为某些大型进程(如 Oracle 备份和恢复操作)和I/O 服务器进程分配较大的内存空间
• Java 池:用于存储Java 虚拟机(JVM) 中特定会话的所有 Java 代码和数据.
• 流池:Oracle Streams 使用它来存储捕获和应用所需的信息.
使用Oracle Enterprise Manager 或SQL*Plus 启动实例时,会显示为SGA 分配的内存量。
程序全局区(PGA) 是一个内存区,其中包含每个服务器进程的数据及控制信息。Oracle Server 进程为客户机请求提供服务。每个服务器进程都有在服务器进程启动时创建的自己专用的PGA 。PGA 只能由相应的服务器进程访问,并且只有代表该服务器进程的 Oracle 代码可对其进行读取和写入。PGA 分为两个主要区域:堆栈空间和用户全局区(UGA) 。
使用动态SGA 基础结构,可以在不关闭实例的情况下更改数据库缓冲区高速缓存、共享池、大型池、Java 池和流池的大小。
Oracle DB 使用初始化参数来创建和管理内存结构。管理内存的最简单方法是允许数据库自动管理和优化内存。在大多数平台上,要实现此目的,只需设置目标内存大小初始化参数( MEMORY_TARGET ) 和最大内存大小初始化参数( MEMORY_MAX_TARGET) 。
缓冲区高速缓存
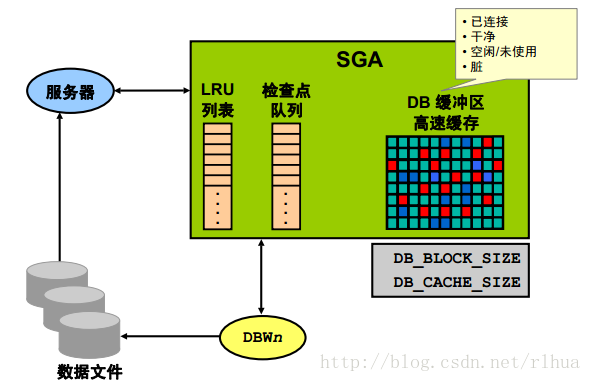
缓冲区高速缓存
通过指定DB_CACHE_SIZE 参数的值,可以配置缓冲区高速缓存。缓冲区高速缓存可存放数据文件中块大小为DB_BLOCK_SIZE 的数据块的副本。缓冲区高速缓存是SGA 的一部分,因此所有用户都可以共享这些块。服务器进程将数据文件中的数据读入缓冲区高速缓存。为了提高性能,服务器进程有时在一个读操作中会读取多个块。然后由DBW n 进程将数据从缓冲区高速缓存写入数据文件。为提高性能,DBW n 在一个写操作中会写入多个块。
在任何给定时间,缓冲区高速缓存都可能会存放一个数据库块的多个副本。虽然该块只存在一个当前副本,但为了满足查询需要,服务器进程可能需要根据过去的映像信息构造读一致性副本。这称为读一致性(CR) 块。
最近最少使用(LRU) 列表可反映缓冲区的使用情况。缓冲区将依据其被引用时间的远近和引用频率进行排序。因此,最经常使用且最常用的缓冲区将列在最近最常使用一端。传入的块先被复制到最近最少使用一端的缓冲区中,然后该缓冲区将被指定到列表中央,作为起点。从这个起点开始,缓冲区根据使用情况在列表中上下移动。
缓冲区高速缓存中的缓冲区可以处于以下四种状态之一:
• 已连接:当前正将该块读入高速缓存或正在写入该块。其它会话正等待访问该块。
• 干净的:该缓冲区目前未连接,如果其当前内容(数据块)将不再被引用,则可以立即执行过期处理。这些内容与磁盘保持同步,或者缓冲区包含块的读一致性快照。
• 空闲/未使用:缓冲区因实例刚启动而处于空白状态。此状态与“干净”状态非常相似,不同之处在于缓冲区未曾使用过。
• 脏:缓冲区不再处于连接状态,但内容(数据块)已更改,因此必须先通过 DBW n 将内容刷新到磁盘,然后才能执行过期处理。
服务器进程使用缓冲区高速缓存中的缓冲区;而DBW n 进程通过将更改的缓冲区写回数据文件,使高速缓存中的缓冲区变为可用状态。
检查点队列中列出将要写出到磁盘的缓冲区。
Oracle DB 支持同一数据库中有多种块大小。标准块大小用于SYSTEM 表空间。标准块大小可以通过设置初始化参数DB_BLOCK_SIZE 来指定。其有效值介于2 KB 到32 KB 之间,默认值为8 KB。非标准块大小的缓冲区的高速缓存大小通过以下参数指定:
• DB_2K_CACHE_SIZE
• DB_4K_CACHE_SIZE
• DB_8K_CACHE_SIZE
• DB_16K_CACHE_SIZE
• DB_32K_CACHE_SIZE
DB_ n K_CACHE_SIZE参数不能用于调整标准块大小的高速缓存的大小。如果DB_BLOCK_SIZE 的值为n K,则设置DB_ n K_CACHE_SIZE是非法的。标准块大小的高
速缓存的大小始终由DB_CACHE_SIZE 的值确定。
由于每个缓冲区高速缓存的大小都有限制,因此,通常并非磁盘上的所有数据都能放在高速缓存中。当高速缓存写满时,后续高速缓存未命中会导致Oracle DB 将高速缓存中已有的灰数据写入磁盘,以便为新数据腾出空间。(如果缓冲区中没有灰数据,则不需要写入磁盘即可将新块读入该缓冲区。)以后若对已写入磁盘的任何数据进行访问,则会导致再次出现高速缓存未命中现象。
数据请求导致高速缓存命中的几率会受到高速缓存大小的影响。高速缓存越大,包含所请求数据的几率也就越大。因此,增加高速缓存大小会提高引起高速缓存命中的数据请求的百分比。
使用多个缓冲池
数据库管理员(DBA) 可以创建多个缓冲池来提高数据库缓冲区高速缓存的性能。你可以根据对象的访问情况将其分配给某个缓冲池。
缓冲池有三种:
• 保留:此池用于保留内存中可能要重用的对象。将这些对象保留在内存中可减少 I/O操作。通过使池的大小大于分配给该池的各个段的总大小,可以将缓冲区保留在此池中。这意味着缓冲区不必执行过期处理。保留池可通过指定DB_KEEP_CACHE_SIZE参数的值来配置。
• 回收:此池用于内存中重用几率很小的块。回收池的大小要小于分配给该池的各个段的总大小。这意味着读入该池的块经常需要在缓冲区内执行过期处理。回收池可通过指定DB_RECYCLE_CACHE_SIZE 参数的值来配置。
• 默认:此池始终存在。它相当于没有保留池和回收池的实例的缓冲区高速缓存,可通过DB_CACHE_SIZE 参数进行配置。
注:保留池或回收池中的内存不是默认缓冲池的子集。
CREATE INDEX cust_idx …
STORAGE (BUFFER _POOL KEEP);
ALTER TABLE oe.customers
STORAGE (BUFFER_POOL RECYCLE);
ALTER INDEX oe.cust_lname_ix
STORAGE (BUFFER _POOL KEEP);
BUFFER_POOL 子句用于定义对象的默认缓冲池。它是STORAGE子句的一部分,对CREATE 和ALTER表、集群和索引语句有效。未明确设置缓冲池的对象中的块将进入默认缓冲池。
语法为:BUFFER_POOL [KEEP | RECYCLE | DEFAULT] 。
使用ALTER语句更改对象的默认缓冲池时,已缓存的块会一直保留在其当前缓冲区中,直到正常缓冲区管理活动将它们清除为止。从磁盘读取的块将被放置在为该段新指定的缓冲池中。
由于多个缓冲池被分配给某一个段,所以有多个段的对象可以将块放置在多个缓冲池中。
例如,按索引组织的表在索引段和溢出段上可以有多个不同的池。
共享池
内容:
• 库高速缓存(共享sql区域):命令文本、已进行语法分析的代码和执行计划
• 数据字典高速缓存:数据字典表中各表、列和权限的定义
• 结果高速缓存:SQL 查询和PL/SQL 函数的结果
• 用户全局区(UGA) :Oracle 共享服务器的会话信息
可以使用SHARED_POOL_SIZE 初始化参数指定共享池的大小。共享池是用于存储多个会话共享的信息的内存区。它包含不同类型的数据,
库高速缓存:库高速缓存包含共享 SQL 区和PL/SQL 区-经过完全语法分析或编译的PL/SQL 块和SQL 语句的表示法。PL/SQL 块包括:
• 过程和函数
• 程序包
• 触发器
• 匿名PL/SQL 块
数据字典高速缓存:数据字典高速缓存将字典对象的定义存放在内存中。
结果高速缓存:结果高速缓存包括 SQL 查询结果高速缓存和PL/SQL 函数结果高速缓存。此高速缓存用于存储SQL 查询或PL/SQL 函数的结果,以加快它们将来的执行速度。
用户全局区:UGA 包含 Oracle 共享服务器的会话信息。使用共享服务器会话时,如果尚未配置大型池,则UGA 位于共享池中。
大型池
• 为以下对象提供大型内存分配:
– 共享服务器和 Oracle XA 接口的会话内存
– I/O 服务器进程
– Oracle DB 备份和还原操作
– 并行查询操作
– 高级排队内存表存储
• 减少潜在的共享池碎片
• 是由AMM 和ASMM 管理的
• 大小是由LARGE_POOL_SIZE参数指定的
大型池
数据库管理员可以配置一个称为大型池的可选内存区,以便为以下对象提供大型内存分配:
• 共享服务器和Oracle XA 接口(在事务处理与多个数据库交互时使用)的会话内存
•I/O 服务器进程
• Recovery Manager (RMAN) I/O 从属进程的缓冲区
• 在语句并行执行中使用的消息缓冲区
• 高级排队内存表存储
通过为上面列项目分配会话内存,减少了共享池中由于频繁分配和取消分配大对象而产生的碎片。将大对象从共享池中分离出来,可增加共享池内存的使用效率,这意味着,它可以将更多内存用于处理新的请求,以及在需要时用于保留现有数据。
大型池可以由AMM 和ASMM 自动管理。还可以用 LARGE_POOL_SIZE参数设置其大小。
Java 池和流池
• Java 池内存用于将JVM 中特定于会话的所有Java 代码和数据存储在服务器内存中。
• Oracle Streams 专门使用流池内存来:
– 存储已缓冲的队列消息
– 为Oracle Streams 进程提供内存
Java 池和流池
Java 池内存用于将JVM 中特定于会话的所有 Java 代码和数据存储在服务器内存中。Java 池内存的使用方式有多种,具体取决于Oracle DB 运行的模式。
Java 池指导统计信息提供有关用于Java 的库高速缓存内存的信息,并且预测如何更改Java 池的大小就可以影响分析速率。将statistics_level 设置为TYPICAL或更高级别时,则在内部打开Java 池指导。关闭指导时,将重置这些统计信息。
流池专门由Oracle Streams 使用。流池存储已缓冲的队列消息,并且为Oracle Streams 捕获进程和应用进程提供内存。
除非专门配置流池,否则其大小以零开始。使用Oracle Streams 时,池大小会根据需要动态地增长。
重做日志缓冲区
• SGA 中的循环缓冲区
• 存放对数据库所做更改的信息
• 包含重做条目,重做条目中具有重做由诸如DML 和DDL 操作所做更改的信息
日志写进程(LGWR) 传送的内容:
– 用户进程提交事务处理时
– 重做日志缓冲区满三分之一时
– DBW n 进程将修改的缓冲区写入磁盘之前
Oracle Server 进程将重做条目从用户的内存空间复制到每个DML 或DDL 语句的重做日志缓冲区。重做条目包含重建或重做DML 和DDL 操作对数据库的更改所必需的信息。它们用于数据库恢复,需要占用缓冲区中的连续空间。
重做日志缓冲区是一个回收缓冲区;服务器进程可以用新条目覆盖重做日志缓冲区中已写入磁盘的条目。LGWR 进程的写速度通常都很快,足以确保缓冲区中始终有存储新条目的空间。LGWR 进程将重做日志缓冲区写入磁盘上的活动联机重做日志文件(或活动组成员)中。LGWR 进程将LGWR 上次写入磁盘以来进入缓冲区的所有重做条目复制到磁盘。
什么导致LGWR 执行写操作?
在以下情况下,LGWR 会从重做日志缓冲区中写出重做数据:
• 用户进程提交事务处理时
• 每隔三秒钟,或者重做日志缓冲区满三分之一时
• DBW n 进程将修改的缓冲区写入磁盘时(如果相应的重做日志数据尚未写入磁盘)
自动内存管理:概览
通过自动内存管理,数据库可以根据工作量自动调整SGA 和PGA 的大小。
ALTER SYSTEM SET MEMORY_TARGET=300M;
通过自动内存管理(AMM),Oracle DB 可以自动管理SGA 内存以及实例PGA 内存的大小。为此,在大多数平台上,只需要设置一个目标内存大小初始化参数( MEMORY_TARGET ) 和一个最大内存大小初始化参数( MEMORY_MAX_TARGET),数据库就会根据处理需求在SGA 与实例 PGA 之间动态交换内存。
通过导航到“Server > Memory Advisors (服务器> 内存指导)”(在“Database Configuration(数据库配置)”区域中),并单击“Enable(启用)”按钮,可启用Oracle Enterprise Manager 中的AMM。
启用自动内存管理后, 数据库将会自动设置内存的最佳分配方式。将不时更改内存分配以适应工作量的变化。 “最大内存大小”指定数据库可以分配的, 并且为了使用自动内存管理而必须设置的内存量。
通过这种内存管理方法,数据库还可以动态调整单个SGA 组件的大小以及单个PGA 的大小。
因为目标内存初始化参数是动态的,因此可以随时更改目标内存大小而不必重新启动数据库。最大内存大小相当于一个上限,以防你无意中将目标内存大小设置得太高。因为某些SGA 组件的大小不容易收缩,或者其大小必须不低于某个下限值,所以数据库还要防止你将目标内存大小设置得太低。
这种间接的内存转移依赖于操作系统(OS) 的共享内存释放机制。将内存释放给 OS 后,其它组件可以通过向OS 请求内存来分配内存。目前,Linux、Solaris 、HPUX、AIX 和Windows 平台上已实施了自动内存管理。
Oracle DB 内存参数
自动内存管理是用两个初始化参数进行配置的:
MEMORY_TARGET:动态控制SGA和PGA时,Oracle总共可以使用的共享内存大小,这个参数是动态的,因此提供给Oracle的内存总量是可以动态增大,也可以动态减小的。它不能超过MEMORY_MAX_TARGET参数设置的大小。默认值是0。
MEMORY_MAX_TARGET:这个参数定义了MEMORY_TARGET最大可以达到而不用重启实例的值,如果没有设置MEMORY_MAX_TARGET值,默认等于MEMORY_TARGET的值。
使用动态内存管理时,SGA_TARGET和PGA_AGGREGATE_TARGET代表它们各自内存区域的最小设置,要让Oracle完全控制内存管理,这两个参数应该设置为0。
Oracle DB 内存大小设置参数
上图展示了内存初始化参数的层次结构。虽然仅需要设置MEMORY_TARGET 来触发自动内存管理,但仍可以为各种高速缓存设置下限值。因此,如果子参数是用户设置的,则这些参数值将是Oracle DB Server 自动优化该组件时的下限值。
• 如果将SGA_TARGET和PGA_AGGREGATE_TARGET设置为非零值,则可将其分别视为SGA 和PGA 大小的下限值。MEMORY_TARGET 可以采用从SGA_TARGET+
PGA_AGGREGATE_TARGET到MEMORY_MAX_SIZE的值。
• 如果设置了SGA_TARGET,则数据库将仅自动优化SGA 的子组件的大小。PGA 的自动优化与是否显式设置PGA 无关。但是,不会自动优化整个 SGA ( SGA_TARGET) 和PGA ( PGA_AGGREGATE_TARGET) ,即不自动增长或收缩。
监视自动内存管理
在EM 主页(“Related Links(相关链接)”部分)中,导航到“Advisor Central > Memory Advisors(指导中心 > 内存指导)”。此时,将显示“Memory Advisors(内存指导)”页。
启用了自动内存管理后,可以在“Memory Advisors(内存指导)”页的“Allocation History(分配历史记录)”部分看到以图形方式显示的内存大小组件历史记录。第一个矩形图的上部为可优化的那部分PGA ,其下部是所有SGA 。
第二个矩形图的上部为共享池大小,其下部对应于缓冲区高速缓存大小。
在此页上,还可以通过单击“Advice (建议)”按钮访问内存目标指导。此指导将提供各种内存总大小可能实现的DB 时间改善。
注:您也可以使用 V$MEMORY_TARGET_ADVISOR 视图查看内存目标指导。
如果要通过命令行监视自动内存管理做出的决定:
• V$MEMORY_DYNAMIC_COMPONENTS包含所有内存组件的当前状态
• V$MEMORY_RESIZE_OPS 包含最近完成的800 个内存大小调整请求的循环历史记录缓冲区
• V$MEMORY_TARGET_ADVICE提供针对MEMORY_TARGET 初始化参数的优化建议
动态性能视图V$MEMORY_DYNAMIC_COMPONENTS显示所有动态优化的内存组件的当前大小,其中包括SGA 和实例PGA 的总大小。V$MEMORY_TARGET_ADVICE视图提供针对MEMORY_TARGET 初始化参数的优化建议。
查看V$MEMORY_TARGET_ADVICE视图时,MEMORY_SIZE_FACTOR 为1 的行显示当前的内存大小(由MEMORY_TARGET 初始化参数设置)以及完成当前工作量所需的DB 时间量。在之前以及之后的行中,将显示使用一组替代MEMORY_TARGET 大小的结果。如果将MEMORY_TARGET 参数更改为替代大小中的任何一个,那么数据库将显示大小因子(当前大小的乘数)以及完成当前工作量的估计DB 时间。请注意,如果内存总大小小于当前MEMORY_TARGET 大小,则估计的DB 时间会增加。
sys@TEST0924> desc V$MEMORY_TARGET_ADVICE
Name Null? Type
----------------------------------------------------- -------- ------------------------------------
MEMORY_SIZE NUMBER
MEMORY_SIZE_FACTOR NUMBER
ESTD_DB_TIME NUMBER
ESTD_DB_TIME_FACTOR NUMBER
VERSION NUMBER
sys@TEST0924> select * from V$MEMORY_TARGET_ADVICE;
MEMORY_SIZE MEMORY_SIZE_FACTOR ESTD_DB_TIME ESTD_DB_TIME_FACTOR VERSION
----------- ------------------ ------------ ------------------- ----------
2400 .75 326 1 0
3200 1 326 1 0
4000 1.25 326 1 0
4800 1.5 326 1 0
5600 1.75 326 1 0
6400 2 326 1 0
6 rows selected.
sys@TEST0924> show parameter memory
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
hi_shared_memory_address integer 0
memory_max_target big integer 3200M
memory_target big integer 3200M
shared_memory_address integer 0
有效使用内存:准则
• 使SGA 适合物理内存。
• 优化以实现高缓冲区高速缓存命中率,但要注意以下几点:
– 即使有效且必需的全表扫描也会降低命中率。
– 可能存在因不必要地重复读取同一块而出现命中率虚升的情况。
• 使用内存指导。
如果可能,最好使SGA 适合物理内存,以便提供最快的访问速度。即使操作系统可能提供额外的虚拟内存,该内存也经常会因其性质而换出到磁盘。在某些平台上,可以使用LOCK_SGA 初始化参数将SGA 锁定到物理内存中。此参数不能与 AMM 或ASMM 一起使用。
执行SQL 语句时,将请求数据块进行读、写或读写操作。这被认为是一个逻辑I/O。请求某个块时,会先查看它是否已在内存中。如果不在内存中,则从磁盘中读取块,这称为物理I/O。在内存中发现块的次数与逻辑I/O 的总次数之比,称为缓冲区高速缓存命中率。
通常,命中率越高越好,因为这意味着在内存中找到了更多的块,而不必进行磁盘I/O 操作。
缓冲区高速缓存命中率高于99% 的情况不罕见,但这并不总表示系统优化好了。如果某个查询的执行频率超过了必要的次数,而且它不断地反复请求相同的块,则命中率就会提高。如果这是个低效或不必要的查询,则会虚升命中率。这是因为它首先不应以这种方式执行或不应如此频繁地执行。
此外,考虑到大型全表扫描(完全读取整个表)会降低此命中率,因为可能要从磁盘中读取整个表;此类扫描可能不会利用某些已在缓冲区高速缓存中的块。所以,如果应用程序中有一些必要的大型全表扫描,则即使是优化良好的数据库,其数据库缓冲区高速缓存命中率也可能始终很低。
使用Oracle Enterprise Manager 内存指导。这些指导可以帮助您基于特定数据库中的活动调整SGA 的大小。
库高速缓存的内存优化准则
• 为开发人员制定格式使用约定,以便SQL 语句符合高速缓存的要求。
• 使用绑定变量。
• 消除不必要的重复SQL。
• 考虑使用CURSOR_SHARING。
• 尽可能使用PL/SQL。
• 缓存序列号。
• 连接库高速缓存中的对象。
库高速缓存是共享池的一部分,它是Oracle DB 用于存储所有SQL 、Java 代码、PL/SQL 过程和程序包以及控制结构(如锁定和库高速缓存句柄)的地方。这些代码进入此中央位置的目的是为了能够让所有用户共享。共享的好处在于,所有用户都能利用SQL 代为执行的工作。因此,对于每条语句,不论它执行多少次,也不管有多少用户执行它,对语句进行语法分析和确定数据访问路径(也称为“解释计划”)之类的任务都只执行一次。
如果库高速缓存过小,则没有空间容纳所有要执行的语句,因此对于某些语句,也就无法利用此工作共享的优势。如果库高速缓存过大,又会给系统带来管理其内容的负担。
因为库高速缓存中最终可能会填满一些看似不同、实际却是同一语句副本的语句。导致此问题的一个常见原因是每条语句的格式稍有不同。如果字符串不完全比较就没有匹配项。另一个原因是使用了文字而不是绑定变量。当两条语句之间的唯一差别是文字值时,如果用绑定变量替换这些文字,则大多数情况下,这些语句的每次执行和整个系统都将受益。
可以设置CURSOR_SHARING 初始化参数,指示系统在语句的其它部分都匹配时自动用绑定变量替换文字。通常,在适当时使用绑定变量更正应用程序之前,应将此设置作为临时手段。与所有这些准则一样,使用此变量也可能有其它负面影响,这一点应该调查清楚。
避免从应用程序中的几个不同位置发出同一SQL 语句,而是使用PL/SQL 将一条或多条语句放置在一个存储过程中。以后只需调用该存储过程。这样可保证该SQL 语句是共享的,因为它只位于一个地方。同样,该SQL 语句也已经过语法分析并有了解释计划,因为它位于一个已编译的存储过程中。
序列号可以缓存。因此,如果某些序列的活动频繁,请为其设置一个合适的高速缓存大小,然后利用它。
可以使用DBMS_SHARED_POOL 程序包来连接库高速缓存中的对象。这样可减少重新加载和重新编译对象的几率。
自动共享内存管理:概览
• 自动根据工作量变化调整
• 最大程度地提高内存利用率
• 有助于消除内存不足的错误
如果AMM 不能正常工作,因为需要一个固定的PGA ,考虑使用可简化 SGA 内存管理的自动共享内存管理(ASMM) 。可以使用 SGA_TARGET初始化参数指定实例的可用SGA 内存总量,然后,Oracle DB 会自动在各个SGA 组件间分配该内存,从而确保内存的高效利用。
例如,对于白天运行大型联机事务处理(OLTP) 作业(要求大型缓冲区高速缓存)和夜晚运行并行批处理作业(要求大型池的内存空间比较大)的系统,就必须同时配置缓冲区高速缓存和大型池,以便适应峰值需求。
有了ASMM 功能,当 OLTP 作业运行时,缓冲区高速缓存会获取大部分内存来保证良好的I/O 性能。以后启动数据分析和报告批处理作业时,内存又会自动迁移到大型池,供并行查询操作使用,而不会产生内存溢出错误。
如果使用的是服务器参数文件(SPFILE) ,则Oracle DB 会在每次关闭实例时记住自动优化的组件的大小。因此,系统不需要在每次启动实例时都重新了解工作量的特性。它可以利用从以前的实例中获取的信息,从上次关闭时中断的位置开始继续评估工作量。
ASMM 的工作原理
• ASMM 以MMON 在后台捕获的工作量信息为基础。
• MMON 使用内存指导。
• 将内存移到MMAN 最迫切需要的地方。
• 如果使用SPFILE(推荐):
– 在关闭时保存组件大小
– 保存的值用于引导程序组件大小
– 无需再确定最佳值
自动共享内存管理功能使用SGA 内存中介,此内存中介由可管理性监视器( MMON) 和内存管理器( MMAN) 这两个后台进程实施。统计信息和内存指导数据由MMON 定期在内存中捕获。MMAN 根据MMON 决策来协调内存组件的大小。SGA 内存中介会不断跟踪组件的大小和待处理的大小调整操作。
SGA 内存中介会观察系统和工作量,以便确定理想的内存分配方案。SGA 内存中介每隔几分钟就执行一次这种检查,使内存始终用在需要的地方。如果没有自动共享内存管理功能,必须分别预计各组件在峰值时的内存需求,然后对其内存大小进行调整。
在工作量信息基础上,自动共享内存管理功能会:
• 定期在后台捕获统计信息
• 使用内存指导
• 进行假设分析,确定最佳内存分配方案
• 将内存移到最迫切需要的地方
• 如果使用了SPFILE,则在关闭时保存组件大小(这些大小可以在最后一次关闭前重新起用)
启用自动共享内存管理功能
要从手动共享内存管理模式下启用ASMM,执行以下操作:
1. 获取SGA_TARGET的值:
SELECT ((SELECT SUM(value) FROM V$SGA) - (SELECT CURRENT_SIZE
FROM V$SGA_DYNAMIC_FREE_MEMORY)) "SGA_TARGET" FROM DUAL;
sys@TEST0924> SELECT ((SELECT SUM(value) FROM V$SGA) - (SELECT CURRENT_SIZE
2 FROM V$SGA_DYNAMIC_FREE_MEMORY)) "SGA_TARGET" FROM DUAL;
SGA_TARGET
----------
2501591040
sys@TEST0924> select 2501591040/1024/1024 from dual;
2501591040/1024/1024
--------------------
2385.70313
2. 使用该值设置SGA_TARGET。
3. 将自动设置大小的SGA 组件的值设置为0。
要从自动内存管理模式切换到ASMM,请执行以下操作:
1. 将初始化参数MEMORY_TARGET 设置为0。
2. 将自动设置大小的SGA 组件的值设置为0。
启用ASMM 的具体过程取决于是从手动共享内存管理模式更改为 ASMM,还是从自动内存管理模式更改为ASMM。要从手动共享内存管理模式更改为 ASMM,请执行以下操作:
1. 运行以下查询获取SGA_TARGET的值:
SELECT ((SELECT SUM(value) FROM V$SGA) - (SELECT CURRENT_SIZE FROM
V$SGA_DYNAMIC_FREE_MEMORY)) “SGA_TARGET” FROM DUAL;
2. 设置SGA_TARGET的值:
ALTER SYSTEM SET SGA_TARGET= value [SCOPE={SPFILE|MEMORY|BOTH}]
其中value是在步骤1 中计算的值,或者是介于所有SGA 组件的总大小与
SGA_MAX_SIZE之间的某个值。
3. 将自动设置大小的SGA 组件的值设置为0。为此,需要编辑文本初始化参数文件,或者发出ALTER SYSTEM语句。如果需要,重新启动实例。
sys@TEST0924> desc v$sgainfo;
Name Null? Type
----------------------------------------------------- -------- ------------------------------------
NAME VARCHAR2(32)
BYTES NUMBER
RESIZEABLE VARCHAR2(3)
sys@TEST0924> select * from v$sgainfo;
NAME BYTES RES
-------------------------------- ---------- ---
Fixed SGA Size 2232960 No
Redo Buffers 16326656 No
Buffer Cache Size 1795162112 Yes
Shared Pool Size 637534208 Yes
Large Pool Size 16777216 Yes
Java Pool Size 16777216 Yes
Streams Pool Size 16777216 Yes
Shared IO Pool Size 0 Yes
Granule Size 16777216 No
Maximum SGA Size 3340451840 No
Startup overhead in Shared Pool 117967168 No
Free SGA Memory Available 838860800
12 rows selected.
要从自动内存管理模式更改为ASMM,请执行以下操作:
1. 将初始化参数MEMORY_TARGET 设置为0。
ALTER SYSTEM SET MEMORY_TARGET = 0;
数据库将根据当前的SGA 内存分配设置SGA_TARGET。
2. 将自动设置大小的SGA 组件的值设置为0。完成后,重新启动实例。
禁用ASMM
• 将SGA_TARGET设置为0 可禁用自动优化功能。
• 自动优化的参数设置为其当前大小。
• SGA 大小总体上不受影响。
通过将SGA_TARGET设置为0,可以动态选择禁用自动共享内存管理。在此情况下,所有自动优化的参数的值都将设置为其对应组件的当前大小;即使用户早先为自动优化的参数指定了其它非零值,也是如此。
例如,SGA_TARGET的值为8 GB,SHARED_POOL_SIZE 的值为1 GB。
如果系统将共享池组件的大小内部调整为2 GB,则将SGA_TARGET设置为0 会导致SHARED_POOL_SIZE 被设置为2 GB,从而覆盖用户定义的原有值。
程序全局区(PGA)
默认情况下,启用自动PGA 内存管理。
程序全局区(PGA) 是包含某服务器进程的数据及控制信息的内存区。这是 Oracle Server 在服务器进程启动时创建的非共享内存,只有该服务器进程才能访问。由关联到某个Oracle 实例的所有服务器进程分配的PGA 总内存,也称为该实例分配的聚集 PGA 内存。使用共享服务器时,部分PGA 可位于 SGA 中。
PGA 内存通常包含以下各项:
专用SQL 区
专用SQL 区包含绑定信息和运行时内存结构等数据。这些信息是每个会话的SQL 语句调用所特有的;在其它方面,绑定变量有不同的值,游标的状态也不同。发出SQL 语句的每个会话都有一个专用SQL 区。提交同一SQL 语句的每个用户也都有其自己的专用SQL 区,该专用SQL 区使用一个共享SQL 区。这样,许多专用SQL 区可与同一个共享SQL 区关联。专用SQL 区的位置取决于为会话建立的连接类型。如果会话是通过专用服务器连接的,则专用SQL 区位于该服务器进程的PGA 中。不过,如果会话是通过共享服务器连接的,则部分专用SQL 区将保留在SGA 中。
游标和SQL 区
Oracle Pro*C 程序或Oracle 调用接口(OCI) 程序的应用程序开发人员可以显式打开特定专用SQL 区的游标或句柄,并在该程序的整个执行过程中将它们用作命名资源。数据库为某些SQL 语句隐式发出的递归游标也使用共享SQL 区。
工作区
对于复杂查询(例如,决策支持查询),会将大部分PGA 供内存密集型运算符分配的工作区专用,例如:
• 基于排序的运算符(如ORDER BY 、GROUP BY 和ROLLUP )和窗口函数
• 散列联接
• 位图合并
• 位图创建
• 批量加载操作使用的写缓冲区
排序运算符使用工作区(排序区),对一组行执行内存中排序。与此类似,散列联接运算符使用工作区(散列区),根据其左侧输入内容生成散列表。
工作区的大小是可以控制和优化的。通常,较大的工作区可以显著改进特定运算符的性能不过代价是消耗较多的内存。
会话内存
会话内存是用于存放会话的变量(登录信息)以及与会话相关的其它信息的内存。对于共享服务器,会话内存是共享的,而不是专用的。
自动PGA 内存管理
默认情况下,Oracle DB 会自动对供实例PGA 专用的内存总量进行全局管理。可以通过设
置初始化参数PGA_AGGREGATE_TARGET来控制此内存量。随后,Oracle DB 会努力确保
分配给所有数据库服务器进程和后台进程的PGA 内存总量始终不超过此目标值。
使用V$PARAMETER 视图
SGA_TARGET = 8G
DB_CACHE_SIZE = 0
JAVA_POOL_SIZE = 0
LARGE_POOL_SIZE = 0
SHARED_POOL_SIZE = 0
STREAMS_POOL_SIZE = 0
SELECT name, value, isdefault FROM v$parameter WHERE name LIKE '%size';
如果为SGA_TARGET指定非零值,且未指定自动优化的SGA 参数的值,则V$PARAMETER 视图中自动优化的SGA 参数的值为 0,ISDEFAULT 列的值为TRUE。
如果已为任何自动优化的SGA 参数指定了值,则查询 V$PARAMETER 时显示的值是你为该参数指定的值。
sys@TEST0924> SELECT name, value, isdefault FROM v$parameter WHERE name LIKE '%size';
NAME VALUE ISDEFAULT
------------------------------ -------------------------------------------------- ---------
sga_max_size 3355443200 TRUE
shared_pool_size 0 FALSE
large_pool_size 0 TRUE
java_pool_size 0 TRUE
streams_pool_size 0 TRUE
shared_pool_reserved_size 31876710 TRUE
db_keep_cache_size 50331648 FALSE
db_recycle_cache_size 0 TRUE
db_flash_cache_size 0 TRUE
db_recovery_file_dest_size 9565110272 FALSE
---------------------
作者:Riveore
来源:CSDN
原文:https://blog.csdn.net/rlhua/article/details/12493791
版权声明:本文为博主原创文章,转载请附上博文链接!
Oracle DB管理内存的更多相关文章
- Oracle DB 管理数据库的空间
• 描述4 KB 扇区磁盘的概念及使用 • 使用可移动表空间 • 描述可移动表空间的概念 数据库存储 数据库存储 数据库包括物理结构和逻辑结构.由于物理结构和逻辑结构是分开的,因此管理数据的物 理存储 ...
- Oracle 自己主动内存管理 SGA、PGA 具体解释
ASMM自己主动共享内存管理: 自己主动依据工作量变化调整 最大程度地提高内存利用率 有助于消除内存不足的错误 SYS@PROD>show parameter sga NAME ...
- Oracle DB 存储增强
• 设置Automatic Storage Management (ASM) 快速镜像 再同步 • 使用ASM 首选镜像读取 • 了解可伸缩性和性能增强 • 设置ASM 磁盘组属性 • 使用SYSA ...
- Oracle DB 备份和恢复的概念
• 确定Oracle DB 中可能发生的故障类型 • 说明优化实例恢复的方法 • 说明检查点.重做日志文件和归档日志文件的重要性 • 配置快速恢复区 • 配置ARCHIVELOG模式 部分工作内容 ...
- OCP读书笔记(13) - 管理内存
SGA 1. 什么是LRULRU表示Least Recently Used,也就是指最近最少使用的buffer header链表LRU链表串联起来的buffer header都指向可用数据块 2. 什 ...
- ORACLE DB体系结构
. 实例:一组oracle后台进程.线程以及一个共享内存区. 连接:用户进程和实例之间的通信 会话:用户通过用户进程与实例建立的特定连接 参数文件:包含控制文件的位置和名称 分为pfile和spfil ...
- Oracle DB 数据库维护
• 管理优化程序统计信息 • 管理自动工作量资料档案库(AWR) • 使用自动数据库诊断监视器(ADDM) • 说明和使用指导框架 • 设置预警阈值 • 使用服务器生成的预警 • 使用自动任务 数 ...
- Oracle DB 移动数据
描述移动数据的方式 • 创建和使用目录对象 • 使用SQL*Loader 加载非Oracle DB(或用户文件)中的数据 • 使用外部表并通过与平台无关的文件移动数据 • 说明Oracle 数据泵的 ...
- Oracle DB 使用调度程序自动执行任务
• 使用调度程序来简化管理任务 • 创建作业.程序和调度 • 监视作业执行 • 使用基于时间或基于事件的调度来执行调度程序作业 • 描述窗口.窗口组.作业类和使用者组的用途 • 使用电子邮件通知 • ...
随机推荐
- GIL
GIL(Global Interpreter Look):全局解释器锁,为了避免线程竞争资源造成数据错乱. 其实每个py程序都必须有解释器参加,解释器就是一堆代码,就等于多线程要竞争同一个解释器的代码 ...
- JavaScript笔记1———js的一些常识
一.什么是js? js是一种运行于解释器中的解释型脚本语言. 二.js的组成部分? 1.ECMAScript-----这是js的核心 2.DOM-----让js可以对网页进行操作(例:对页面元素的增. ...
- java网络编程学习之NIO模型
网上对NIO的解释有很多,但自己一直没有理解,根据自己的理解画出下面这个图,有什么不对的地方,欢迎留言指出. 理解是,客户端先与通过通道Channel与连接(注册到服务器端),然后再传送数据,服务器端 ...
- DB2数据库常用的函数
1.value函数 语法value(表达式1,表达式2)value函数是用返回一个非空的值,当其第一个参数非空,直接返回该参数的值,如果第一个参数为空,则返回第一个参数的值. eg:表示如果T1.ID ...
- vue 路由守卫
router.beforeEach((to, from, next) => { const nextRoute = [ 'login']; var token = window.localSto ...
- 使用CA签发的服务器证书搭建Tomcat双向SSL认证服务
第一部分,先说证书的申请. 这步是要到正规的CA公司申请正式的设备证书必须走的步骤. 1.先生成证书的密钥对 打开命令行,切换到某个自己新建的目录下,执行如下命令 keytool -genkey -k ...
- setInterval中this
今天使用react做钟表,自然用到了setInterval,但是出现this指向不明的问题. <html> <head> <meta charset="UTF- ...
- 大量的rcuob进程
环境: OS:Centos 7 问题,今天采购了一台dell R430机器,启动发现大量的如下进程[root@localhost opt]# toptop - 02:07:57 up 6:39, 2 ...
- centos7安装supervisor
安装supervisor cd /root/tools/ wget http://pnxcvm0bq.bkt.clouddn.com/get-pip.py python get-pip.py pip ...
- AutoCAD2015有时候会显示乱七八糟的线
问题描述:AutoCAD2015以上版本有时候打开一张图,会出现乱七八糟的线 解决方案: 这是由于硬件加速平滑线显示引起的,可以如下修改