Storm环境搭建(分布式集群)
作为流计算的开篇,笔者首先给出storm的安装和部署,storm的第二篇,笔者将详细的介绍storm的工作原理。下边直接上干货,跟笔者的步伐一块儿安装storm。
原文链接:Storm环境搭建(分布式集群)
Step1:新建用户
在所有主机上新建hadoop用户,密码是Hadoop123
useradd hadoop
passwd hadoop
输入密码Hadoop123
Step2:设置免密登录
设置所有主机之间ssh免密码登录。设置主节点到从节点的免密码登录即可。
Step3:软件包下载
(1)mkdir -p /mnt/data/software
(2)将所需要的软件包放在/mnt/data/software目录下
如需要以下三个安装包,请长按文末二维码关注“大数据技术宅”,后台输入“storm安装包”获取。
jdk-8u121-linux-i586.tar.gzapache-storm-1.0.5.tar.gzzookeeper-3.4.10.tar.gz
Step4:安装JDK
(1)卸载openjdk
rpm -qa | grep jdkrpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64rpm -e --nodepscopy-jdk-configs-1.2-1.el7.noarchrpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
(2)安装jdk1.8
cd /mnt/data/softwaretar -zxvf jdk-8u121-linux-i586.tar.gz
配置java环境变量
vim /etc/profile
在文件中写入以下内容
JAVA_HOME=/mnt/data/software/jdk1.8.0_121JRE_HOME=/mnt/data/software/jdk1.8.0_121/jreCLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/libPATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/binexport JAVA_HOME JRE_HOME CLASS_PATH PATH
使环境变量生效:source/etc/profile
Step5:安装zookeeper
(1)关闭三台机器上的防火墙(CentOS 7)
firewall-cmd --state 查看防火墙状态systemctl stop firewalld.service 关闭防火墙systemctl disable firewalld.service 禁止开机启动
(2)安装
cd /mnt/data/softwaretar -zxvf zookeeper-3.4.10.tar.gzmv zookeeper-3.4.10cd zookeeper/conf
将conf目录中的zoo_sample.cfg文件复制为zoo.cfg并利用vi命令进行修改
dataDir=/mnt/data/software/zookeeper/dataserver.1=ip:2888:3888 ip为服务器的ipserver.2=ip:2888:3888 ip为服务器的ipserver.3=ip:2888:3888 ip为服务器的ip
这里的dataDir需要自己创建 mkdir命令创建,并在目录下创建一个文件:myid分别在myid上按照配置文件的server.<id>中id的数值,在不同机器上的该文件中填写相应过的值1|2|3
如[root@safe01data]# vim myid
1
保存即可
(3)添加zookeeper环境变量
vim /etc/profileZOOKEEPER_HOME=/mnt/data/software/zookeeperPATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/binexport JAVA_HOME CLASSPATH ZOOKEEPER_HOME PATH
引用环境变量:source/etc/profile
(4)测试安装
三台机器执行zkServer.shstart进行启动zookeeper
查看状态zkServer.shstatus
[root@safe01 data]# zkServer.sh status
JMX enabled by defaultUsing config: /mnt/data/software/zookeeper/bin/../conf/zoo.cfgMode: follower
两个follower一个leader就是正确的
Step6:安装Storm
(1)安装
cd /mnt/data/softwaretar -zxvf apache-storm-1.0.5.tar.gzmv apache-storm-1.0.5 stormcd ./storm/conf
编辑storm.yaml
storm.zookeeper.servers:- "172.16.2.27"- "172.16.2.42"- "172.16.2.72"#nimbusnimbus.host: "172.16.2.27"ui.port: 8081supervisor.slots.ports:-6700-6701-6702-6703storm.local.dir:"/mnt/data/software/storm/data"
创建数据文件目录:mkdir /mnt/data/software/storm/data
将storm分发到其他主机上:
scp -r /mnt/data/software/storm/ hadoop@172.16.2.42:/mnt/data/softwarescp -r /mnt/data/software/storm/ hadoop@172.16.2.72:/mnt/data/software
在所有主机上添加storm的环境变量:
STORM_HOME=/mnt/data/software/stormPATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$STORM_HOME/bin:$KAFKA_HOME/bin:$PATHexport JAVA_HOME CLASSPATH ZOOKEEPER_HOME STORM_HOME KAFKA_HOME PATH
(2)启动
在主机centos上开启nimbus进程
storm nimbus &
在另外两台机子上开启supervisor 进程
storm supervisor &
开启完按Ctrl+c
在centos主机上开启
storm ui &
storm logviewer &
这样就可以通过web查看storm部署情况了
访问http://172.16.2.27:8080/,如图:
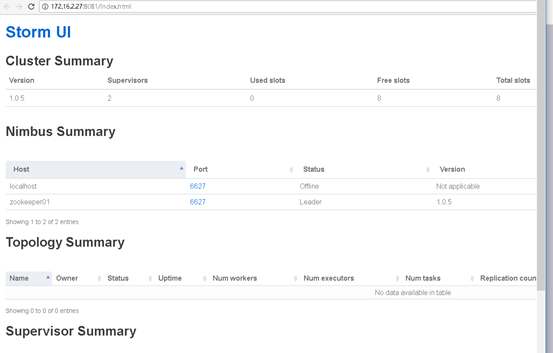
下篇。。。
Storm环境搭建(分布式集群)的更多相关文章
- Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境
Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境 一.环境说明 个人理解:zookeeper可以独立搭建集群,hbase本身不能独立搭建集群需要和hadoo ...
- Windows及Linux环境搭建Redis集群
一.Windows环境搭建Redis集群 参考资料:Windows 环境搭建Redis集群 二.Linux环境搭建Redis集群 参考资料:Redis Cluster的搭建与部署,实现redis的分布 ...
- 环境搭建-Hadoop集群搭建
环境搭建-Hadoop集群搭建 写在前面,前面我们快速搭建好了centos的集群环境,接下来,我们就来开始hadoop的集群的搭建工作 实验环境 Hadoop版本:CDH 5.7.0 这里,我想说一下 ...
- 环境搭建-CentOS集群搭建
环境搭建-CentOS集群搭建 写在前面 最近有许多小伙伴问我,大数据的hadoop分布式集群该如何去搭建.所以,想着,就写一篇博客,帮助到更多刚入门大数据的人.本博客会一步一步带你实现一个Hadoo ...
- Redis.之.环境搭建(集群)
Redis.之.环境搭建(集群) 现有环境: /u01/app/ |- redis # 单机版 |- redis-3.2.12 # redis源件 所需软件:redis-3.0.0.gem -- ...
- Windows 环境搭建Redis集群(win 64位)
转: http://blog.csdn.net/zsg88/article/details/73715947 参考:https://www.cnblogs.com/tommy-huang/p/6240 ...
- CentOS 7 环境搭建kafka集群
Kafka是一个MQ服务,流行的MQ服务器有三个,分别是ActiveMQ,RabbbitMQ和Kafka 目录说明:/home/fuqinqin/packages : 安装包存放目录/home/fuq ...
- 利用vmware搭建分布式集群
背景: 我们需要至少3台服务器来实现分布式,鉴于没那么多钱买真机器,从学习和开发的角度看,只有虚拟机一条路了. 软件选择: 虚拟机使用VMware软件,因为主流而且资料比较多,学习成 ...
- Windows 环境搭建Redis集群
环境以及引用资料 1.windows server 2008 r2 enterprise (木有办法,公司的服务器全是如此,就这种环境搭建吧) 2.redis官方资料下载: https://redi ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
随机推荐
- Golang的模块管理Module
Golang 1.11版本终于支持了官方的模块依赖管理功能,1.11以前想要实现依赖管理只能够通过借助第三方库来实现,1.11以前的版本Golang项目必须依赖以GOPATH,从当前版本开始Golan ...
- java拦截处理System.exit(0)
在使用TestNG做单元测试时,需要测试的代码中出现System.exit(0),导致单元测试还未结束程序就停止了.解决方法如下: public class TestMain { public sta ...
- today-Extension widget 扩展开发
设置UI部分的展开和收起
- Chrome_高亮显示当前改变的区域
- centos7搭建本地 Remix
由于最近要弄加入某联盟链,是基于ETH 所以要弄一个开发环境 一.准备 安装 nodejs,npm,git 二.安装 git clone https://github.com/ethereum/rem ...
- 欢迎访问我的独立博客 tracefact.net (2019.1.30)
欢迎访问我的独立博客 tracefact.net 长期以来,我都同时维护着两个博客,博客园和 tracefact.net,感觉有点分散精力,所以博客园以后不再每篇文章都同步更新了. 我会挑个别比较好的 ...
- TechEmpower最新一轮的性能测试出炉,ASP.NET Core依旧表现不俗
TechEmpower在10月30发布最新一轮(Round 17)针对“Web Framework Benchmarks”的性能测试报告,ASP.NET Core依旧表现不俗,在一些指标上甚至是碾压其 ...
- 【RL-TCPnet网络教程】第26章 RL-TCPnet之DHCP应用
第26章 RL-TCPnet之DHCP应用 本章节为大家讲解RL-TCPnet的DHCP应用,学习本章节前,务必要优先学习第25章的DHCP基础知识.有了这些基础知识之后,再搞本章节会有事半功 ...
- 【安富莱二代示波器教程】第16章 附件A---电阻屏触摸校准
第16章 附件A---电阻屏触摸校准 二代示波器的触摸校准比较简单,随时随地都可以做触摸校准,按下K1按键即可校准.有时候我们做触摸校准界面,需要在特定的界面才可以进入触摸校准状态,非常繁琐 ...
- [Swift]LeetCode109. 有序链表转换二叉搜索树 | Convert Sorted List to Binary Search Tree
Given a singly linked list where elements are sorted in ascending order, convert it to a height bala ...