大数据Hadoop——初识Hadoop
Hadoop简介
官方网站: http://hadoop.apache.org/
中文网站: http://hadoop.apache.org/docs/r1.0.4/cn/
Hadoop设计来源
根据Google的三大论文 GFS(Google File System):
Google的分布式文件系统 http://www.cnblogs.com/999-/p/7120490.html
MapReduce: Google的MapReduce开源分布式并行计算框架 http://www.cnblogs.com/999-/p/7120503.html
BigTable: 一个大型的分布式数据库 http://www.cnblogs.com/999-/p/7120499.html
创始人


Hadoop之父Doug Cutting,Hadoop这个名字不是一个缩写,而是一个虚构的名字。该项目的创建者,Doug Cutting解释Hadoop的得名 :“这个名字是我孩子给一个棕黄色的大象玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义
Hadoop可以做什么
1.HDFS用于存储大数据

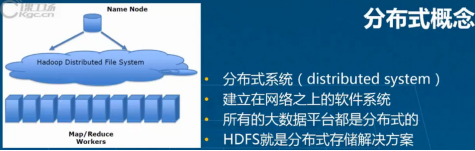
2.分布式概念
3.MapReduce用于处理数据

Map分配数据到各个节点,Reduce拉取处理后数据
4.HBase用于存储数据,快速高效查询处理

5.Zookeeper用于协调各个组件

6.Hadoop生态圈
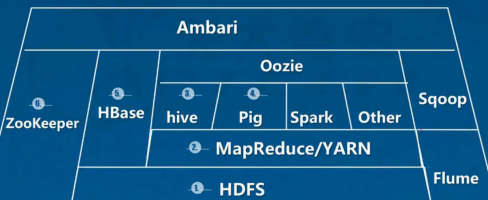
相关组件介绍
HDFS(Hadoop Distributed File System): 分布式文件存储系统(HDFS)。源自于Google的GFS论文。HDFS 是一种数据分布式保存机制,数据被保存在计算机集群上。数据写入一次,读取多次。是Hadoop体系中数据存储管理的基础。
MapReduce: 它是一个分布式、并行处理的计算框架。MapReduce 把任务分为 map(映射)阶段和 reduce(化简)。开发人员使用存储在HDFS 中数据(可实现快速存储),编写 Hadoop 的 MapReduce 任务。由于 MapReduce工作原理的特性, Hadoop 能以并行的方式访问数据,从而实现快速访问数据。
Yarn(Yet Another Resource Negotiator): 是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
Hbase: 源自Google的Bigtable论文,是一个分布式的列式存储 NoSQL 数据库,用于快速读/写大量数据。HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。HBase 使用 Zookeeper 进行管理,确保所有组件都正常运行。
ZooKeeper: 用于 Hadoop 的分布式协调服务。Hadoop 的许多组件依赖于 Zookeeper,它运行在计算机集群上面,用于管理 Hadoop 操作。解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Sqoop(SQL-to-Hadoop): 数据同步工具。Sqoop是一个Hadoop和关系型数据库之间的数据转移工具。可将关系型数据库中的数据导入到Hadoop的HDFS中,也可将HDFS中的数据导进到关系型数据库中主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
Hive: Hive定义了一种类似SQL的查询语言(HQL),用于运行存储在 Hadoop 上的查询语句,Hive 让不熟悉 MapReduce 开发人员也能编写数据查询语句,然后这些语句被翻译为 Hadoop 上面的 MapReduce 任务。
Flume: Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。
Pig :Pig是一个基于Hadoop的大数据分析平台,它提供了一个叫PigLatin的高级语言来表达大数据分析程序,将脚本转换为MapReduce任务在Hadoop上执行。通常用于进行离线分析。
Kafka: Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理, 也是为了通过集群来提供实时的消费。
Mahout: 数据挖掘算法库。Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或Cassandra)集成等数据挖掘支持架构。
Ambari 是一个对Hadoop集群进行监控和管理的基于Web的系统。
Hadoop优点

适合大数据的处理 --GB,TB,PB级别的数据量 --百万规模以上的文件数量
高容错性 --数据自动保存多个副本 --副本丢失后,自动恢复
流式文件访问 --一次性写入、多次并行读取 --保证数据的一致性
可构建在廉价机器上 --通过多副本提高可靠性 --提供了容错和恢复机制
适合批处理 --移动计算而非移动数据 --数据位置暴露给计算框架
Hadoop缺点
不适合低延迟数据访问场景 --比如毫秒级 --低延迟与高吞吐率
小文件存取 --占用NameNode大量内存 --寻道时间超过读取时间
不适合并发写入、文件随时修改 --一个文件只能有一个写入者 --仅支持append
应用场景
1.海量数据的可靠性存储
2.数据归档
01. 数据存档(data archiving)是将不再经常使用的数据移到一个单独的存储设备来进行长期保存的过程。
02. 数据存档由旧的数据组成,但它是以后参考所必需且很重要的数据,其数据必 须遵从规则来保存。
03. 数据存档具有索引和搜索功能,这样文件可以很容易地找到.
大数据Hadoop——初识Hadoop的更多相关文章
- 大数据测试之初识Hadoop
大数据测试之初识Hadoop POPTEST老李认为测试开发工程师是面向测试的开发,也就是说,写代码就是为完成测试任务服务的,写自动化测试(性能自动化,功能自动化,安全自动化,接口自动化等等)的cas ...
- 【大数据】初识Hadoop
因为项目日志体量较大,每天有4-7T的日志量,传统的sqlserver已经不能满足,所以现在需要使用到大数据的相关工具进行记录和使用. 虽然公共项目提供了组件和解决方案,但是对于一些名词.概念还是有必 ...
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- 一篇了解大数据架构及Hadoop生态圈
一篇了解大数据架构及Hadoop生态圈 阅读建议,有一定基础的阅读顺序为1,2,3,4节,没有基础的阅读顺序为2,3,4,1节. 第一节 集群规划 大数据集群规划(以CDH集群为例),参考链接: ht ...
- [Hadoop大数据]——Hive初识
Hive出现的背景 Hadoop提供了大数据的通用解决方案,比如存储提供了Hdfs,计算提供了MapReduce思想.但是想要写出MapReduce算法还是比较繁琐的,对于开发者来说,需要了解底层的h ...
- 初识大数据(二. Hadoop是什么)
hadoop是一个由Apache基金会所发布的用于大规模集群上的分布式系统并行编程基础框架.目前已经是大数据领域最流行的开发架构.并且已经从HDFS.MapReduce.Hbase三大核心组件成长为一 ...
- 从Hadoop Summit 2016看大数据行业与Hadoop的发展
前言: 好吧我承认已经有四年多没有更新博客了.... 在这四年中发生了很多事情,换了工作,换了工作的方向.在工作的第一年的时候接触机器学习,从那之后的一年非常狂热的学习机器学习的相关技术,也写了一些自 ...
- ASP.NET + SqlSever 大数据解决方案 PK HADOOP
半个月前看到博客园有人说.NET不行那篇文章,我只想说你们有时间去抱怨不如多写些实在的东西. 1.SQLSERVER优点和缺点? 优点:支持索引.事务.安全性以及容错性高 缺点:数据量达到100万以 ...
- 大数据时代之hadoop(四):hadoop 分布式文件系统(HDFS)
分布式文件系统即是网络中多台计算机组合在一起提供一个统一存储及管理的系统. Hadoop提供了一个文件系统接口和多个分布式文件系统实现,其中比较重要的就是HDFS(Hadoop Distributed ...
随机推荐
- Repeater 实现 OnSelectedIndexChanged
在Repeater中使用DropDownList的方法 在Repeater中使用DropDownList的方法 以下代码并不完整,只记录了关键的方法 aspx代码中 假设这是一个用户管理的系统的模 ...
- 使用PL/SQL能查询oracle中数据,在for update 语句中一直卡住
原因:在oracle中,执行了update或者insert语句后,都会要求commit,如果不commit却强制关闭连接,oracle就会将这条提交的记录锁住.下次就不能执行增删操作. 解决:1.查询 ...
- php通过pecl方式安装扩展
安装pecl cd /usr/local/php/bin/ wget http://pear.php.net/go-pear.phar -O go-pear.php php go-pear.php # ...
- Vue学习5:条件渲染
上代码: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF- ...
- .Net Collection Distinct 去重
由于业务场景的需要,海量的数据需要进行处理.组装,难免会出现冗余的重复数据.如何处理重复的数据就是一个问题. 简单的集合中,去重就可以用linq distinct来完成.对于复杂的集合直接使用dist ...
- java基础语法-char数据类型
1.java中的char描述了UTF-16中的一个代码单元,因此对于基本的多语言层面可以随意的用char表示 ;//int值只能在0到65535即0000到FFFF 对于其他16个代码级别(两个代码单 ...
- 04-python3.5-模拟三级菜单-省-县-区域--01
#!/usr/bin/env python # -*- coding:utf-8 -*- #Author:XZ data = { '北京':{ "昌平":{ "沙河&qu ...
- getparameter的使用
在做项目的过程中,会遇到跳转的页面,直接打开到里面的子项,这个时候,看了UI给我设计了四个页面,如果做四个页面,肯定是可以实现的.但是这个不符合前端的设计.就在想通过点击传值进去,肯定是能够获取到的. ...
- python反反爬,爬取猫眼评分
python反反爬,爬取猫眼评分.解决网站爬取时,内容类似:$#x12E0;样式,且每次字体文件变化.下载FontCreator . 用FontCreator打开base.woff.查看对应字体关系 ...
- 【转】LNK1123: 转换到 COFF 期间失败: 文件无效或损坏
用VS2010编译C++项目时出现这样的错误: LNK1123: 转换到 COFF 期间失败: 文件无效或损坏 方案一:(这个方法比较好,在用qt运行时出现问题也能解决) 复制 C:\Windows\ ...