周末班:Python基础之函数进阶
迭代器和生成器
迭代和可迭代
什么是迭代(iteration)?
如果给定一个list或tuple,我们要想访问其中的某个元素,我们可以通过下标来,如果我们想要访问所有的元素,那我们可以用for循环来遍历这个list或者tuple,而这种遍历我们就叫做迭代。
可迭代(iterable)?
其实你已经知道,不是所有的数据类型都是可迭代的。那么可迭代的数据类型都有什么特点呢?
print(dir([1,2]))
print(dir((2,3)))
print(dir({1:2}))
print(dir({1,2}))
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'count', 'index']
['__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values']
['__and__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__iand__', '__init__', '__ior__', '__isub__', '__iter__', '__ixor__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__or__', '__rand__', '__reduce__', '__reduce_ex__', '__repr__', '__ror__', '__rsub__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__xor__', 'add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersection', 'intersection_update', 'isdisjoint', 'issubset', 'issuperset', 'pop', 'remove', 'symmetric_difference', 'symmetric_difference_update', 'union', 'update']
结果
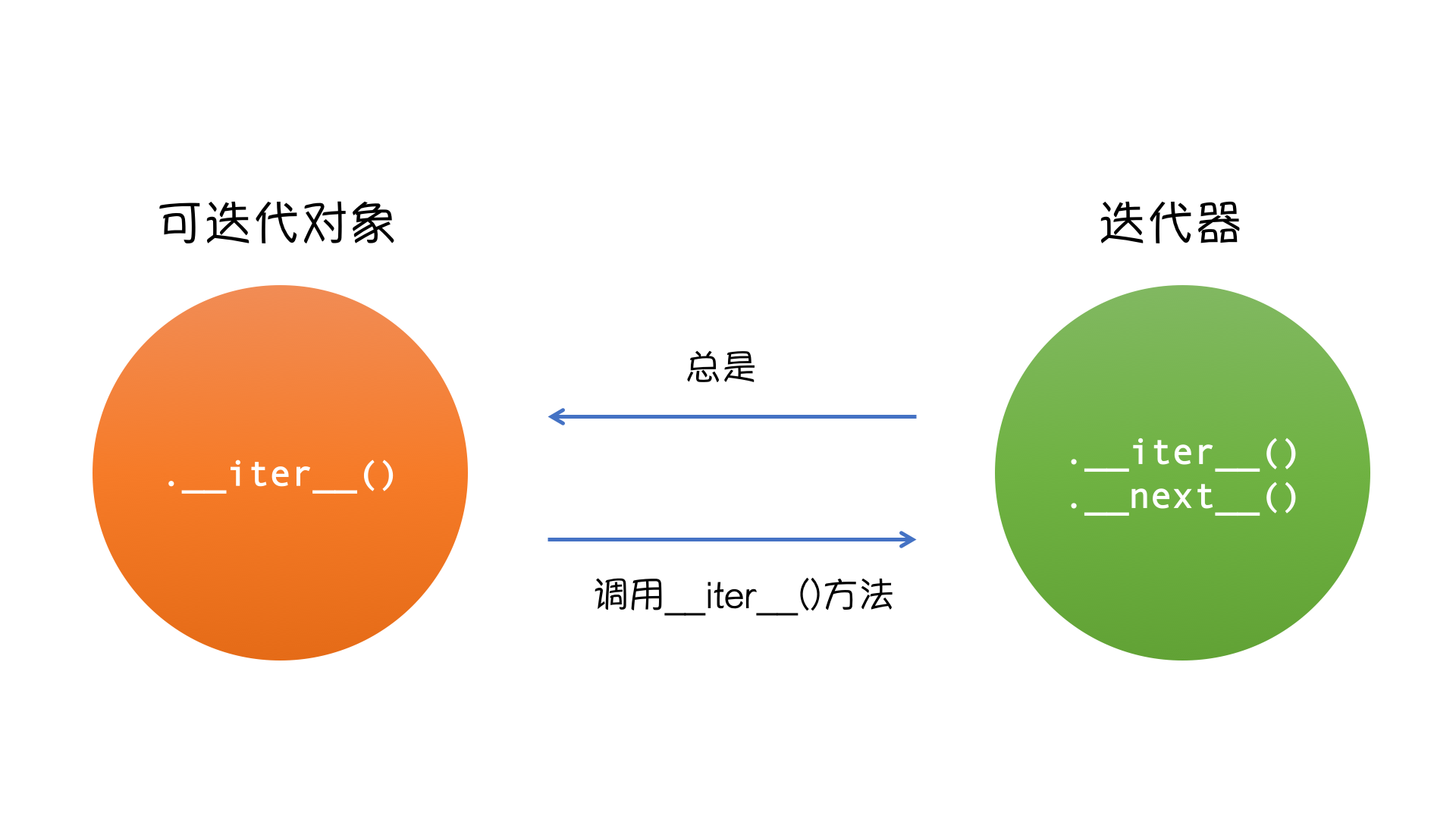
总结一下我们现在所知道的:可以被for循环的都是可迭代的,要想可迭代,内部必须有一个__iter__方法。迭代器协议
from collections import Iterable l = [1,2,3,4]
t = (1,2,3,4)
d = {1:2,3:4}
s = {1,2,3,4} print(isinstance(l,Iterable))
print('__iter__' in dir([l]))
print(isinstance(t,Iterable))
print('__iter__' in dir([t]))
print(isinstance(d,Iterable))
print('__iter__' in dir([d]))
print(isinstance(s,Iterable))
print('__iter__' in dir([s]))
判断是否可迭代
接着分析,__iter__方法做了什么事情呢?
print([1,2].__iter__()) 结果
<list_iterator object at 0x1024784a8>
执行了list([1,2])的__iter__方法,我们好像得到了一个list_iterator,现在我们又得到了一个新名词——iterator。

iterator,这里给我们标出来了,是一个计算机中的专属名词,叫做迭代器。
迭代器
我们调用可迭代对象的__iter__方法之后,得到了一个新东西--迭代器。
那迭代器是什么呢?请继续往后阅读吧。
迭代器协议
既什么叫“可迭代”之后,又一个历史新难题,什么叫“迭代器”?
虽然我们不知道什么叫迭代器,但是我们现在已经有一个迭代器了,这个迭代器是一个列表的迭代器。
我们来看看这个列表的迭代器比起列表来说实现了哪些新方法,这样就能揭开迭代器的神秘面纱了吧?
'''
dir([1,2].__iter__())是列表迭代器中实现的所有方法,dir([1,2])是列表中实现的所有方法,都是以列表的形式返回给我们的,为了看的更清楚,我们分别把他们转换成集合,
然后取差集。
'''
#print(dir([1,2].__iter__()))
#print(dir([1,2]))
print(set(dir([1,2].__iter__()))-set(dir([1,2]))) 结果:
{'__length_hint__', '__next__', '__setstate__'}
我们看到在列表迭代器中多了三个方法,那么这三个方法都分别做了什么事呢?
iter_l = [1,2,3,4,5,6].__iter__()
#获取迭代器中元素的长度
print(iter_l.__length_hint__())
#根据索引值指定从哪里开始迭代
print('*',iter_l.__setstate__(4))
#一个一个的取值
print('**',iter_l.__next__())
print('***',iter_l.__next__())
这三个方法中,能让我们一个一个取值的神奇方法是谁?
没错!就是__next__
在for循环中,就是在内部调用了__next__方法才能取到一个一个的值。
那接下来我们就用迭代器的next方法来写一个不依赖for的遍历。
l = [1,2,3,4]
l_iter = l.__iter__()
item = l_iter.__next__()
print(item)
item = l_iter.__next__()
print(item)
item = l_iter.__next__()
print(item)
item = l_iter.__next__()
print(item)
item = l_iter.__next__()
print(item)
这是一段会报错的代码,如果我们一直取next取到迭代器里已经没有元素了,就会抛出一个异常StopIteration,告诉我们,列表中已经没有有效的元素了。
这个时候,我们就要使用异常处理机制来把这个异常处理掉。
l = [1,2,3,4]
l_iter = l.__iter__()
while True:
try:
item = l_iter.__next__()
print(item)
except StopIteration:
break
那现在我们就使用while循环实现了原本for循环做的事情,我们是从谁那儿获取一个一个的值呀?是不是就是l_iter?好了,这个l_iter就是一个迭代器。
迭代器遵循 迭代器协议 :必须拥有__iter__方法和__next__方法。
还账:next和iter方法
如此一来,关于迭代器和生成器的方法我们就还清了两个,最后我们来看看 range()是个啥。首先,它肯定是一个可迭代的对象,但是它是否是一个迭代器?我们来测试一下
print('__next__' in dir(range(12))) #查看'__next__'是不是在range()方法执行之后内部是否有__next__
print('__iter__' in dir(range(12))) #查看'__next__'是不是在range()方法执行之后内部是否有__next__
from collections import Iterator
print(isinstance(range(100000000),Iterator)) #验证range执行之后得到的结果不是一个迭代器
range函数的返回值是一个可迭代对象
为什么要有for循环
基于上面讲的列表这一大堆遍历方式,聪明的你立马看除了端倪,于是你不知死活大声喊道,你这不逗我玩呢么,有了下标的访问方式,我可以这样遍历一个列表啊
l=[1,2,3] index=0
while index < len(l):
print(l[index])
index+=1 #要毛线for循环,要毛线可迭代,要毛线迭代器
没错,序列类型字符串,列表,元组都有下标,你用上述的方式访问,perfect!但是你可曾想过非序列类型像字典,集合,文件对象的感受,所以嘛,年轻人,for循环就是基于迭代器协议提供了一个统一的可以遍历所有对象的方法,即在遍历之前,先调用对象的__iter__方法将其转换成一个迭代器,然后使用迭代器协议去实现循环访问,这样所有的对象就都可以通过for循环来遍历了,而且你看到的效果也确实如此,这就是无所不能的for循环,觉悟吧,年轻人
生成器
初识生成器
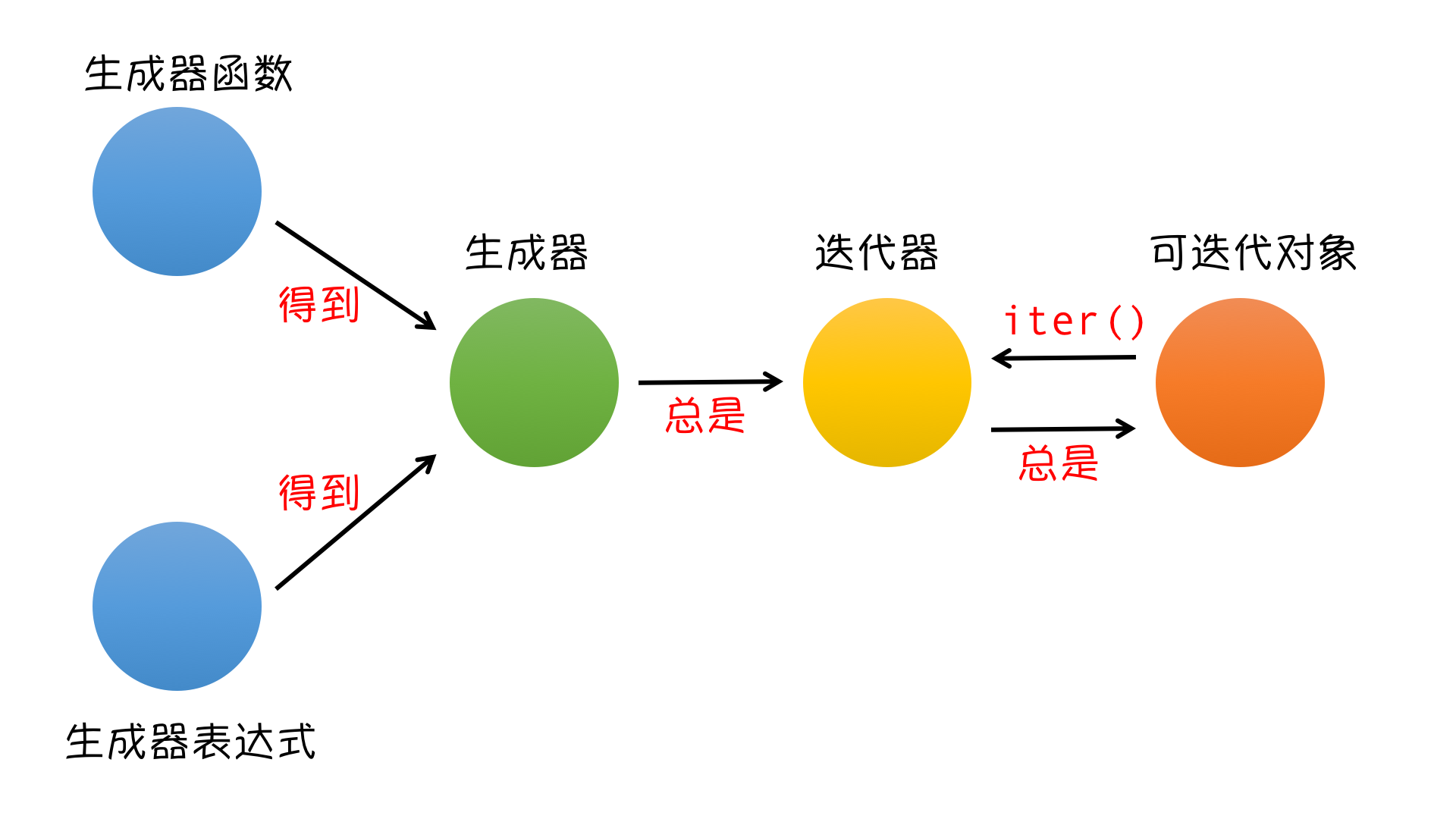
我们知道的迭代器有两种:一种是调用方法直接返回的,一种是可迭代对象通过执行 iter方法得到的,迭代器有的好处是可以节省内存。
如果在某些情况下,我们也需要节省内存,就只能自己写。我们自己写的这个能实现迭代器功能的东西就叫生成器。
Python 中提供的 生成器:
1.生成器函数:常规函数定义,但是,使用yield语句而不是return语句返回结果。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次从它离开的地方继续执行
2.生成器表达式:类似于列表推导,但是,生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
生成器Generator:
本质:迭代器 ( 所以自带了 __iter__方法和 __next__方法,不需要我们去实现)
特点:惰性运算,开发者自定义
生成器函数
一个包含yield关键字的函数就是一个生成器函数。
yield和return一样可以从函数中返回值,但是yield又不同于return,return的执行意味着程序的结束,只能返回一次,yield可以返回多次。
调用生成器函数不会得到返回的具体的值,而是得到一个生成器对象。
每一次从这个可迭代对象获取值,就能推动函数的执行,获取新的返回值。直到函数执行结束(yield像是拥有能够让函数暂停的魔力)。
def my_range():
print('我是一个生成器函数')
n = 0
while 1:
yield n
n += 1
生成器有什么好处呢?就是不会一下子在内存中生成太多数据
接下来,我们在这个函数的基础上来写一个我们自己的range函数,实现开始和结束
def my_range2(start, stop):
n = start
while n < stop:
yield n
n += 1
再进一步,实现步长:
def my_range3(start, stop, step):
n = start
while n < stop:
yield n
n += step
生成器本质上就是个迭代器,我们根据自己的想法创造的迭代器,它当然也支持for循环:
for i in my_range3(1, 10, 2):
print(i)
更多应用
import time def tail(filename):
f = open(filename)
f.seek(0, 2) #从文件末尾算起
while True:
line = f.readline() # 读取文件中新的文本行
if not line:
time.sleep(0.1)
continue
yield line tail_g = tail('tmp')
for line in tail_g:
print(line)
生成器监听文件输入的例子
send
yield可以返回值,也可以接收值。
通过生成器的send方法可以给yield传值。
def eat(name):
print('%s要开始吃了!' % name)
while 1:
food = yield
print('{}在吃{}'.format(name, food)) a = eat('alex')
a.__next__() # 初始化,让函数暂停在yield处
a.send('包子') # send两个作用:1.给yield传值 2.继续执行函数
a.send('饺子')
yield可以同时返回值和接收值。
def averager():
total = 0.0
count = 0
average = None
while True:
term = yield average
total += term
count += 1
average = total/count g_avg = averager()
next(g_avg)
print(g_avg.send(10))
print(g_avg.send(30))
print(g_avg.send(5))
计算移动平均值(1)
def init(func): #在调用被装饰生成器函数的时候首先用next激活生成器
def inner(*args,**kwargs):
g = func(*args,**kwargs)
next(g)
return g
return inner @init
def averager():
total = 0.0
count = 0
average = None
while True:
term = yield average
total += term
count += 1
average = total/count g_avg = averager()
# next(g_avg) 在装饰器中执行了next方法
print(g_avg.send(10))
print(g_avg.send(30))
print(g_avg.send(5))
计算移动平均值(2)_预激协程的装饰器
yield from
在一个生成器中引用另外一个生成器。
def gen1():
for c in 'AB':
yield c
for i in range(3):
yield i print(list(gen1())) def gen2():
yield from 'AB'
yield from range(3) print(list(gen2()))
yield from
列表推导式和生成器表达式
#老男孩由于峰哥的强势加盟很快走上了上市之路,alex思来想去决定下几个鸡蛋来报答峰哥
egg_list=['鸡蛋%s' %i for i in range(10)] #列表解析
#峰哥瞅着alex下的一筐鸡蛋,捂住了鼻子,说了句:哥,你还是给我只母鸡吧,我自己回家下
laomuji=('鸡蛋%s' %i for i in range(10))#生成器表达式
print(laomuji)
print(next(laomuji)) #next本质就是调用__next__
print(laomuji.__next__())
print(next(laomuji))
峰哥与alex的故事
总结:
1.把列表解析的[]换成()得到的就是生成器表达式
2.列表解析与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存
3.Python不但使用迭代器协议,让for循环变得更加通用。大部分内置函数,也是使用迭代器协议访问对象的。例如, sum函数是Python的内置函数,该函数使用迭代器协议访问对象,而生成器实现了迭代器协议,所以,我们可以直接这样计算一系列值的和:
sum(x ** 2 for x in range(4))
而不用多此一举的先构造一个列表:
sum([x ** 2 for x in range(4)])
更多精彩请见——迭代器生成器专题:https://www.cnblogs.com/liwenzhou/p/9762052.html
生成器相关的面试题
def demo():
for i in range(4):
yield i g=demo() g1=(i for i in g)
g2=(i for i in g1) print(list(g1))
print(list(g2))
面试题1
def add(a, b):
return a + b def func():
for i in range(4):
yield i g = func()
for n in [1, 10]:
g = (add(n, i) for i in g) print(list(g))
面试题2
内置函数
abs/round/sum
>>> abs(1)
1
>>> abs(-1) # 求绝对值
1
>>> round(1.234,2)
1.23
>>> round(1.269,2) # 四舍五入
1.27
>>> sum([1,2,3,4])
10
>>> sum((1,3,5,7)) # 接收数字组成的元组/列表
16
callable/chr/dir
>>> def func():pass
>>> callable(func) # 判断一个变量是否可以调用 函数可以被调用
True
>>> a = 123 # 数字类型a不能被调用
>>> callable(a)
False
>>> chr(97) # 将一个数字转换成一个字母
'a'
>>> chr(65)
'A'
>>> dir(123) # 查看数字类型中含有哪些方法
['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes']
>>> dir('abc')
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
eval/exec
>>> eval('1+2-3*4/5') # 执行字符串数据类型的代码并且将值返回
0.6000000000000001
>>> exec('print(123)') # 执行字符串数据类型的代码但没有返回值
123
enumerate
>>> enumerate(['apple','banana'],1) # 会给列表中的每一个元素拼接一个序号
<enumerate object at 0x113753fc0>
>>> list(enumerate(['apple','banana'],1))
[(1, 'apple'), (2, 'banana')]
max/min
>>> max(1,2,3,) # 求最小值
3
>>> min(2,1,3) # 求最大值
1
sorted
将给定的可迭代对象进行排序,并生成一个有序的可迭代对象。
>>> sorted([1, 4, 5, 12, 45, 67]) # 排序,并生成一个新的有序列表
[1, 4, 5, 12, 45, 67]
还接受一个key参数和reverse参数。
>>> sorted([1, 4, 5, 12, 45, 67], reverse=True)
[67, 45, 12, 5, 4, 1]
list1 = [
{'name': 'Zoe', 'age': 30},
{'name': 'Bob', 'age': 18},
{'name': 'Tom', 'age': 22},
{'name': 'Jack', 'age': 40},
] ret = sorted(list1, key=lambda x: x['age'])
print(ret) # [{'name': 'Bob', 'age': 18}, {'name': 'Tom', 'age': 22}, {'name': 'Zoe', 'age': 30}, {'name': 'Jack', 'age': 40}]
zip
zip函数接收一个或多个可迭代对象作为参数,最后返回一个迭代器:
>>> x = ["a", "b", "c"]
>>> y = [1, 2, 3]
>>> a = list(zip(x, y)) # 合包
>>> a
[('a', 1), ('b', 2), ('c', 3)]
>>> b =list(zip(*a)) # 解包
>>> b
[('a', 'b', 'c'), (1, 2, 3)]
zip(x, y) 会生成一个可返回元组 (m, n) 的迭代器,其中m来自x,n来自y。 一旦其中某个序列迭代结束,迭代就宣告结束。 因此迭代长度跟参数中最短的那个序列长度一致。
>>> x = [1, 3, 5, 7, 9]
>>> y = [2, 4, 6, 8]
>>> for m, n in zip(x, y):
... print(m, n)
...
1 2
3 4
5 6
7 8
如果上面不是你想要的效果,那么你还可以使用 itertools.zip_longest() 函数来代替这个例子中的zip。
>>> from itertools import zip_longest
>>> x = [1, 3, 5, 7, 9]
>>> y = [2, 4, 6, 8]
>>> for m, n in zip_longest(x, y):
... print(m, n)
...
1 2
3 4
5 6
7 8
9 None
zip其他常见应用:
>>> keys = ["name", "age", "salary"]
>>> values = ["Andy", 18, 50]
>>> d = dict(zip(keys, values))
>>> d
{'name': 'Andy', 'age': 18, 'salary': 50}
map
map()接收两个参数func(函数)和seq(序列,例如list)。如下图:
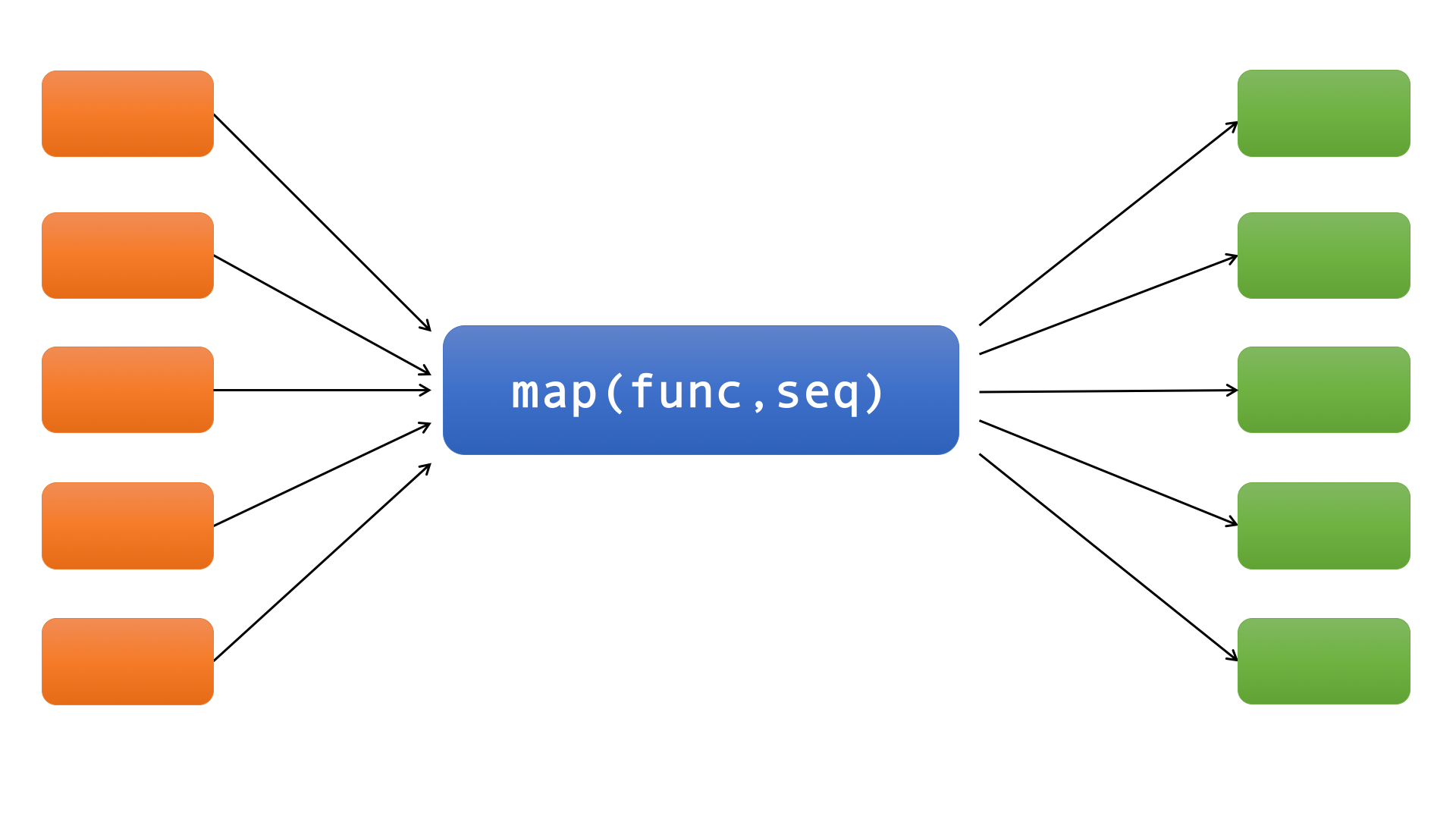
map()将函数func应用于序列seq中的所有元素。在Python3之前,map()返回一个列表,列表中的每个元素都是将列表或元组“seq”中的相应元素传入函数func返回的结果。Python 3中map()返回一个迭代器。
因为map()需要一个函数作为参数,所以可以搭配lambda表达式很方便的实现各种需求。
例子1:将一个列表里面的每个数字都加100:
>>> l = [11, 22, 33, 44, 55]
>>> list(map(lambda x:x+100, l))
[111, 122, 133, 144, 155]
例子2:
使用map就相当于使用了一个for循环,我们完全可以自己定义一个my_map函数:
def my_map(func, seq):
result = []
for i in seq:
result.append(func(i))
return result
测试一下我们自己的my_map函数:
>>> def my_map(func, seq):
... result = []
... for i in seq:
... result.append(func(i))
... return result
...
>>> l = [11, 22, 33, 44, 55]
>>> list(my_map(lambda x:x+100, l))
[111, 122, 133, 144, 155]
我们自定义的my_map函数的效果和内置的map函数一样。
当然在Python3中,map函数返回的是一个迭代器,所以我们也需要让我们的my_map函数返回一个迭代器:
def my_map(func, seq):
for i in seq:
yield func(i)
测试一下:
>>> def my_map(func, seq):
... for i in seq:
... yield func(i)
...
>>> l = [11, 22, 33, 44, 55]
>>> list(my_map(lambda x:x+100, l))
[111, 122, 133, 144, 155]
与我们自己定义的my_map函数相比,由于map是内置的因此它始终可用,并且始终以相同的方式工作。它也具有一些性能优势,通常会比手动编写的for循环更快。当然内置的map还有一些高级用法:
例如,可以给map函数传入多个序列参数,它将并行的序列作为不同参数传入函数:
拿pow(arg1, arg2)函数举例,
>>> pow(2, 10)
1024
>>> pow(3, 11)
177147
>>> pow(4, 12)
16777216
>>> list(map(pow, [2, 3, 4], [10, 11, 12]))
[1024, 177147, 16777216]
filter
filter函数和map函数一样也是接收两个参数func(函数)和seq(序列,如list),如下图:
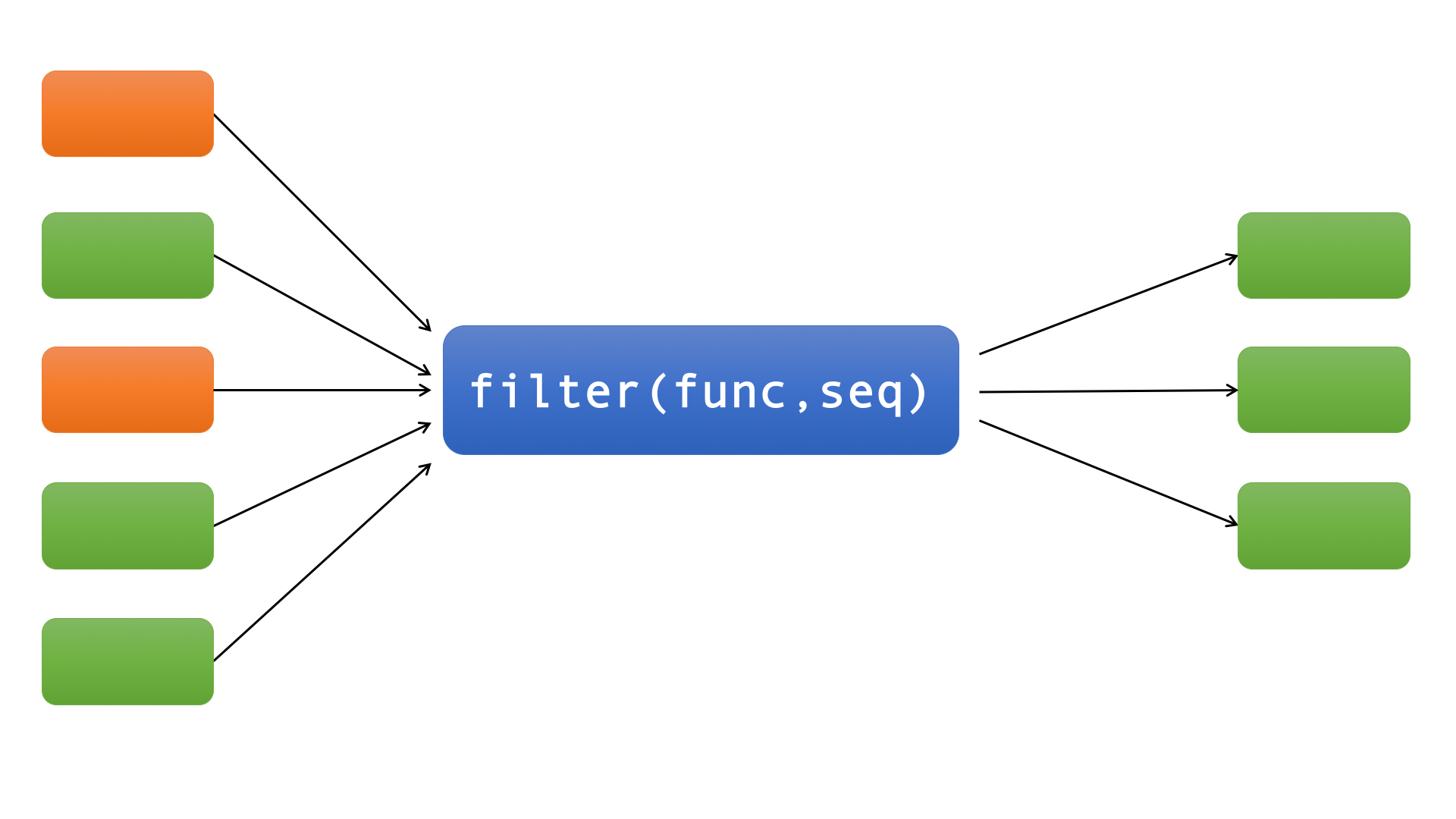
filter函数类似实现了一个过滤功能,它过滤序列中的所有元素,返回那些传入func后返回True的元素。也就是说filter函数的第一个参数func必须返回一个布尔值,即True或者False。
下面这个例子,是使用filter从一个列表中过滤出大于33的数:
>>> l = [30, 11, 77, 8, 25, 65, 4]
>>> list(filter(lambda x: x>33, l))
[77, 65]
利用filter()还可以用来判断两个列表的交集:
>>> x = [1, 2, 3, 5, 6]
>>> y = [2, 3, 4, 6, 7]
>>> list(filter(lambda a: a in y, x))
[2, 3, 6]
补充:reduce
reduce
注意:Python3中reduce移到了functools模块中,你可以用过from functools import reduce来使用它。
reduce同样是接收两个参数:func(函数)和seq(序列,如list),如下图:
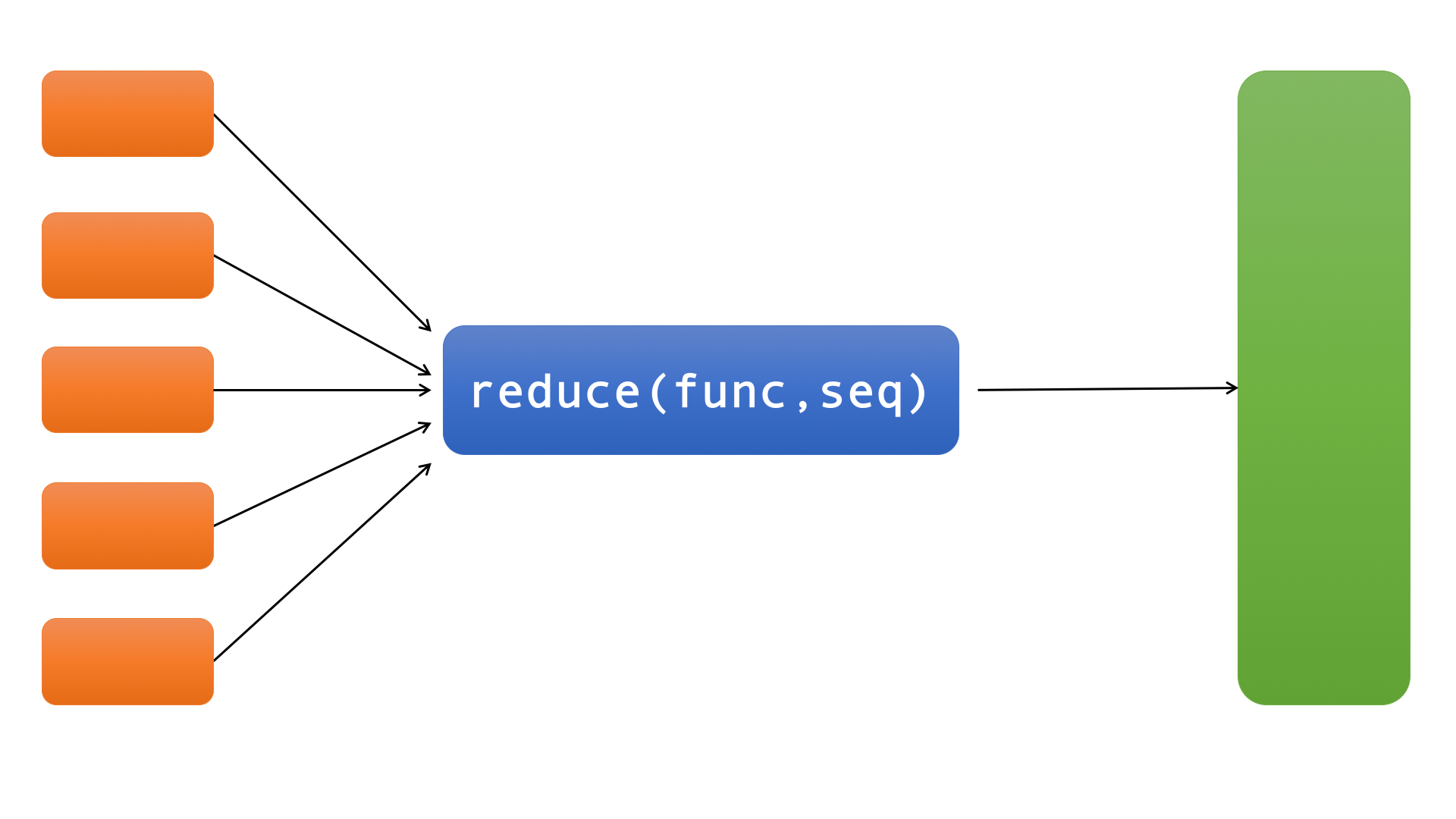
reduce最后返回的不是一个迭代器,它返回一个值。
reduce首先将序列中的前两个元素,传入func中,再将得到的结果和第三个元素一起传入func,…,这样一直计算到最后,得到一个值,把它作为reduce的结果返回。
原理类似于下图:

看一下运行结果:
>>> from functools import reduce
>>> reduce(lambda x,y:x+y, [1, 2, 3, 4])
10
再来练习一下,使用reduce求1~100的和:
>>> from functools import reduce
>>> reduce(lambda x,y:x+y, range(1, 101))
5050
lambda
lambda是匿名函数,也就是没有名字的函数。lambda的语法非常简单:
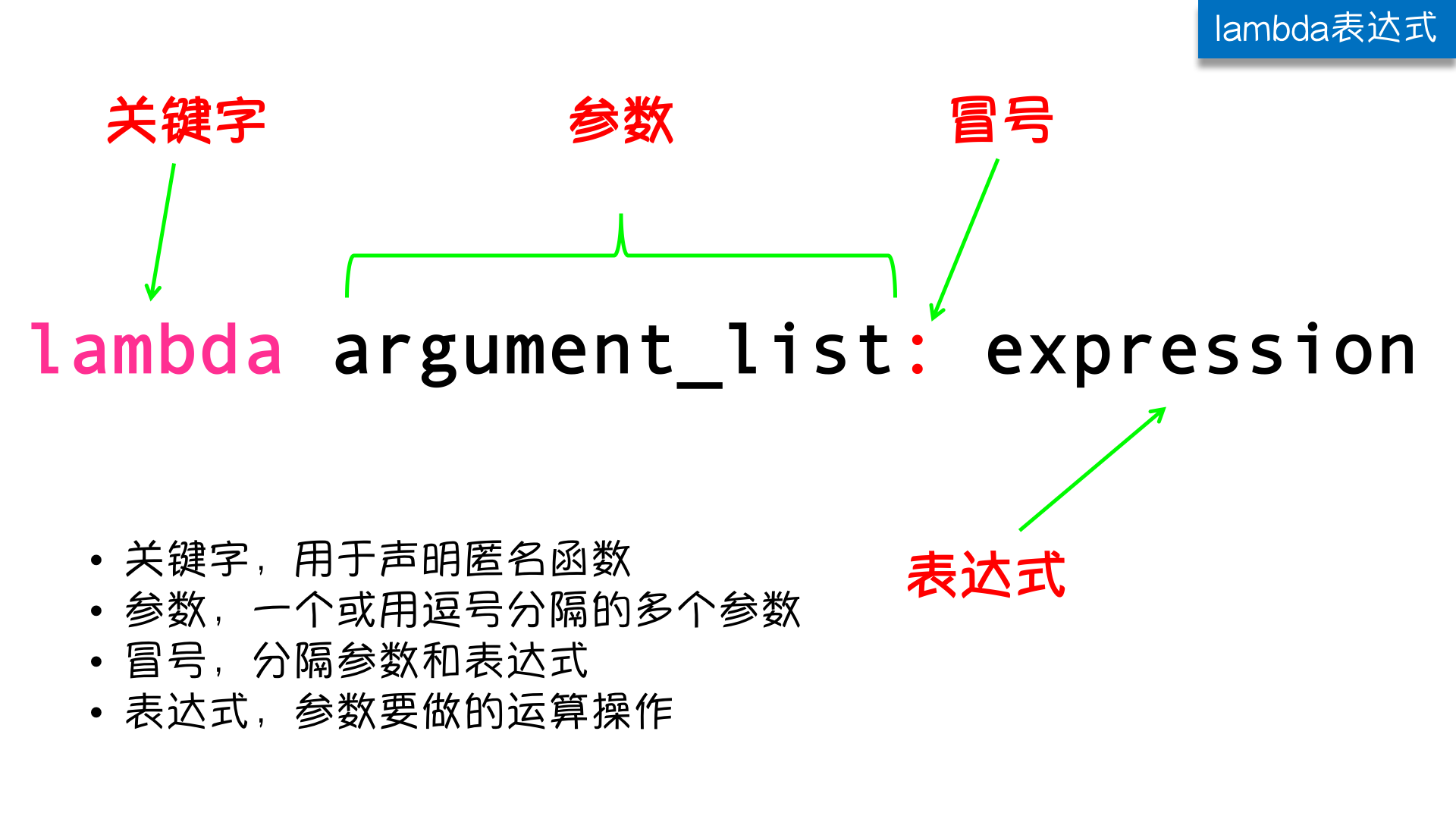
直白一点说:为了解决那些功能很简单的需求而设计的一句话函数
注意:
使用lambda表达式并不能提高代码的运行效率,它只能让你的代码看起来简洁一些。
#这段代码
def func(x, y):
return x + y#换成匿名函数
lambda x, y:x+y
lambda表达式和定义一个普通函数的对比:
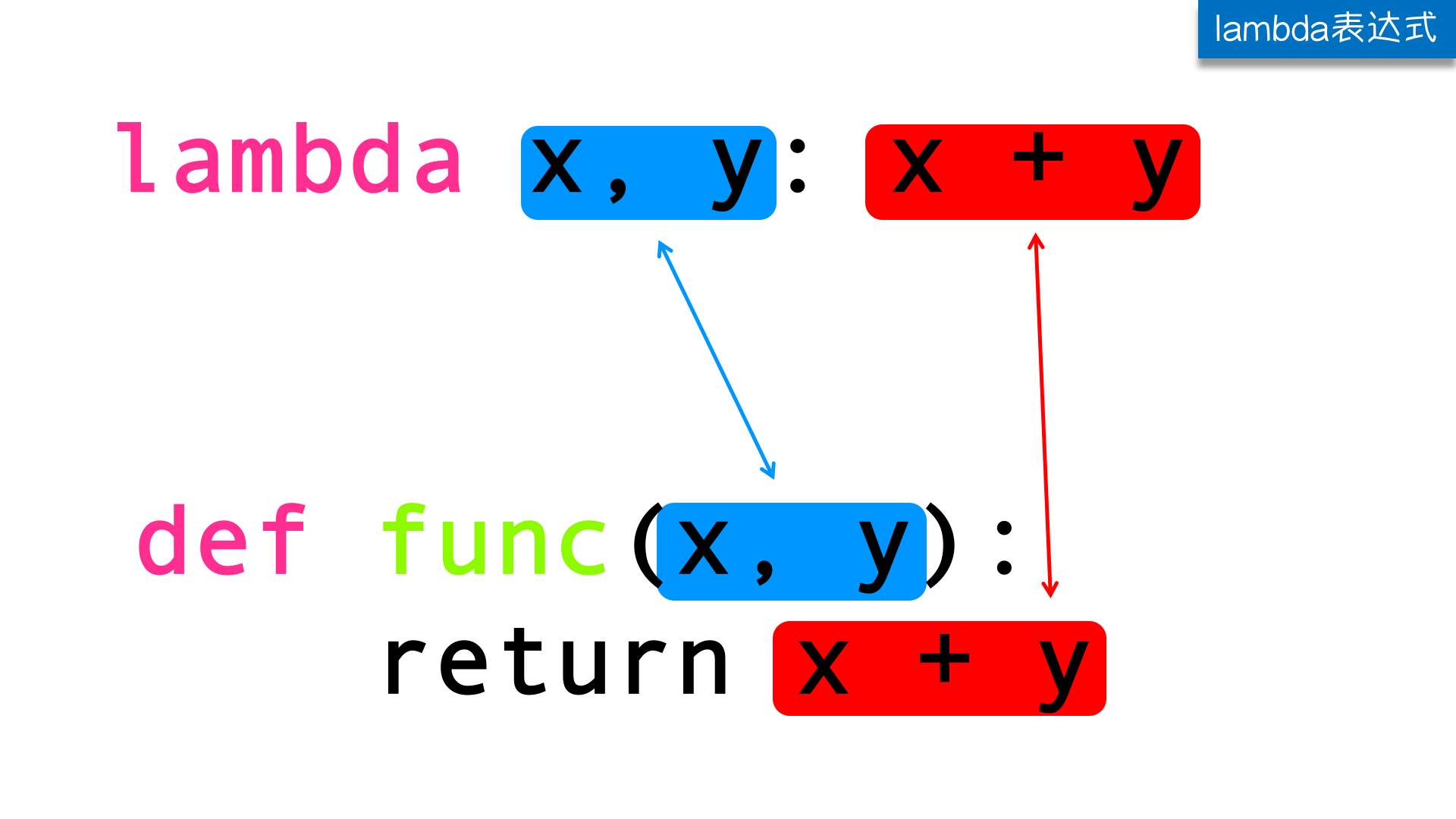
我们可以将匿名函数赋值给一个变量然后像调用正常函数一样调用它。
匿名函数的调用和正常的调用也没有什么分别。 就是 函数名(参数) 就可以了~~~
练一练:
请把以下函数变成匿名函数
def func(x, y):
return x + y
上面是匿名函数的函数用法。除此之外,匿名函数也不是浪得虚名,它真的可以匿名。在和其他功能函数合作的时候
l=[3,2,100,999,213,1111,31121,333]
print(max(l)) dic={'k1':10,'k2':100,'k3':30} print(max(dic))
print(dic[max(dic,key=lambda k:dic[k])])
res = map(lambda x:x**2,[1,5,7,4,8])
for i in res:
print(i) 输出
1
25
49
16
64
res = filter(lambda x:x>10,[5,8,11,9,15])
for i in res:
print(i) 输出
11
15
面试题练一练
1.现有两个元组(('a'),('b')),(('c'),('d')),请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}]
#答案一
test = lambda t1,t2 :[{i:j} for i,j in zip(t1,t2)]
print(test(t1,t2))
#答案二
print(list(map(lambda t:{t[0]:t[1]},zip(t1,t2))))
#还可以这样写
print([{i:j} for i,j in zip(t1,t2)])
练习1-coding
1.下面程序的输出结果是:
d = lambda p:p*2
t = lambda p:p*3
x = 2
x = d(x)
x = t(x)
x = d(x)
print x
练习2
三元运算
三元运算(三目运算)在Python中也叫条件表达式。三元运算的语法非常简单,主要是基于True/False的判断。如下图:

使用它就可以用简单的一行快速判断,而不再需要使用复杂的多行if语句。 大多数时候情况下使用三元运算能够让你的代码更清晰。
三元运算配合lambda表达式和reduce,求列表里面值最大的元素:
>>> from functools import reduce
>>> l = [30, 11, 77, 8, 25, 65, 4]
>>> reduce(lambda x,y: x if x > y else y, l)
77
再来一个,三元运算配合lambda表达式和map的例子:
将一个列表里面的奇数加100:
>>> l = [30, 11, 77, 8, 25, 65, 4]
>>> list(map(lambda x: x+100 if x%2 else x, l))
[30, 111, 177, 8, 125, 165, 4]
递归
递归是一种解决问题的思路。
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
def story():
s = """
从前有个山,山里有座庙,庙里有个老和尚在讲故事,
讲的什么呢?
"""
print(s)
story() story()
初识递归
递归的定义—— 在一个函数里再调用这个函数本身
现在我们已经大概知道刚刚讲的story函数做了什么,就是 在一个函数里再调用这个函数本身 ,这种魔性的使用函数的方式就叫做 递归 。
刚刚我们就已经写了一个最简单的递归函数。
递归的最大深度——1000
正如你们刚刚看到的,递归函数如果不受到外力的阻止会一直执行下去。
但是我们之前已经说过关于函数调用的问题,每一次函数调用都会产生一个属于它自己的名称空间,如果一直调用下去,就会造成名称空间占用太多内存的问题。
Python为了杜绝此类现象,强制的将递归层数控制在了1000 (你写代码测试可能只测出997或998)。
我们可以通过下面的代码来查看此限制:
import sys
print(sys.getrecursionlimit())
1000是Python为了我们程序的内存优化所设定的一个默认值,我们当然还可以通过一些手段去修改它:
import sys
print(sys.setrecursionlimit(100000))
修改递归最大深度
我们可以通过这种方式来修改递归的最大深度,刚刚我们将Python允许的递归深度设置为了10w,至于实际可以达到的深度就取决于计算机的性能了。
不过我们还是非常不推荐修改这个默认的递归深度,因为如果用1000层递归都没有解决的问题要么是不适合使用递归来解决要么就是你代码写的太烂了~~~
江湖上流传这这样一句话叫做:人理解循环,神理解递归。
注意Python解释器不支持尾递归优化。
再谈递归
这里我们又要举个例子来说明递归能做的事情。
首先我们需要记住构成递归需具备的条件:
1. 子问题须与原始问题为同样的事,且更为简单(问题相同,但规模在变小);
2. 不能无限制地调用本身,须有个出口,化简为非递归状况处理。
总结一下:
递归是用来解决那些问题可以简化为很多相同的规模小很多的子问题的场景。
就是把大问题分成小问题,小问题本质上合大问题是一样的问题。
比如:list1 = [1, [2, [3, [4, [5, [6, [7, [8, [9]]]]]]]]],把里面的每一个数字都打印出来。
def tell(x):
for i in x:
if not isinstance(i, list):
print(i)
else:
tell(i) tell(list1)
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
再比如斐波那契数列,这种典型的可以使用递归解决的问题,都可以清晰的分为回溯和递推两个阶段。
递归函数与二分查找算法
周末班:Python基础之函数进阶的更多相关文章
- Python全栈开发之路 【第五篇】:Python基础之函数进阶(装饰器、生成器&迭代器)
本节内容 一.名称空间 又名name space,就是存放名字的地方.举例说明,若变量x=1,1存放于内存中,那名字x存放在哪里呢?名称空间正是存放名字x与1绑定关系的地方. 名称空间共3种,分别如下 ...
- python基础之函数进阶之函数作为返回值/装饰器
因为装饰器需要用到返回函数的知识,所以在这里将返回函数和装饰器合并讲解. 什么是返回函数? 我们知道,一个函数中return可以返回一个或者多个值,但其实,return不仅可以返回值,还可以返回函数. ...
- python基础之函数进阶
假如有一个函数,实现返回两个数中的较大值: def my_max(x,y): m = x if x>y else y return mbigger = my_max(10,20)print(bi ...
- 十三. Python基础(13)--生成器进阶
十三. Python基础(13)--生成器进阶 1 ● send()方法 generator.send(value) Resumes the execution, and "sends&qu ...
- python基础篇之进阶
python基础篇之进阶 参考博客:http://www.cnblogs.com/wupeiqi/articles/5115190.html python种类 1. cpython 使用c解释器生产 ...
- python基础——匿名函数
python基础——匿名函数 当我们在传入函数时,有些时候,不需要显式地定义函数,直接传入匿名函数更方便. 在Python中,对匿名函数提供了有限支持.还是以map()函数为例,计算f(x)=x2时 ...
- python基础——返回函数
python基础——返回函数 函数作为返回值 高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回. 我们来实现一个可变参数的求和.通常情况下,求和的函数是这样定义的: def calc_ ...
- python基础——sorted()函数
python基础——sorted()函数 排序算法 排序也是在程序中经常用到的算法.无论使用冒泡排序还是快速排序,排序的核心是比较两个元素的大小.如果是数字,我们可以直接比较,但如果是字符串或者两个d ...
- python基础——filter函数
python基础——filter函数 Python内建的filter()函数用于过滤序列. 和map()类似,filter()也接收一个函数和一个序列.和map()不同的是,filter()把传入的函 ...
随机推荐
- 今天俺要说一说装饰着模式(Decorator)
前言:装饰者模式,又叫做装饰器模式.顾名思义,就是给对象包裹一层,包装.让它变成你喜欢的对象.这种模式在我们开发中经常会用到,它是一种处理问题的技巧,即不让程序死板,也可以扩展程序. (一)何时能用到 ...
- 使用ML.NET + Azure DevOps + Azure Container Instances打造机器学习生产化
介绍 Azure DevOps,以前称为Visual Studio Team Services(VSTS),可帮助个人和组织更快地规划,协作和发布产品.其中一项值得注意的服务是Azure Pipeli ...
- Python进阶:迭代器与迭代器切片
2018-12-31 更新声明:切片系列文章本是分三篇写成,现已合并成一篇.合并后,修正了一些严重的错误(如自定义序列切片的部分),还对行文结构与章节衔接做了大量改动.原系列的单篇就不删除了,毕竟也是 ...
- leetcode — word-ladder-ii
import java.util.*; /** * Source : https://oj.leetcode.com/problems/word-ladder-ii/ * * * Given two ...
- 设计模式总结篇系列:适配器模式(Adapter)
网上看到不少关于适配器模式的讲解,其中对于适配器模式解释的过于专业,一时不是特别理解适配器模式到底是用来干嘛的,具体的适用场景在哪,其最精髓的地方到底在哪. 本文结合自己的理解,阐述下对适配器模式的看 ...
- 设计模式总结篇系列:单例模式(SingleTon)
在Java设计模式中,单例模式相对来说算是比较简单的一种构建模式.适用的场景在于:对于定义的一个类,在整个应用程序执行期间只有唯一的一个实例对象.如Android中常见的Application对象. ...
- 适配器模式 adapter 结构型 设计模式(九)
现实世界中的适配器模型 先来看下来几个图片,截图自淘宝 上图为港版的插头与港版的插座 上图为插座适配器卖家的描述图 上图为适配后的结果 现实世界中适配器模式 角色分类 这就是适配器模式在电 ...
- 一篇文章彻底搞懂es6 Promise
前言 Promise,用于解决回调地狱带来的问题,将异步操作以同步的操作编程表达出来,避免了层层嵌套的回调函数. 既然是用来解决回调地狱的问题,那首先来看下什么是回调地狱 var sayhello = ...
- H5 和 CSS3 新特性
博客地址:https://ainyi.com/52 H5 新特性 语义化标签:header.footer.section.nav.aside.article 增强型表单:input 的多个 type ...
- Linux几个常用的目录结构
记录几个个人觉得需要了解的目录结构含义: /lost+found: 这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件. /media: linux系统会自动识别一些设备,例如U盘.光驱 ...