【原创】大叔问题定位分享(3)Kafka集群broker进程逐个报错退出
kafka0.8.1
一 问题现象
生产环境kafka服务器134、135、136分别在10月11号、10月13号挂掉:
134日志
[2014-10-13 16:45:41,902] FATAL [KafkaApi-134] Halting due to unrecoverable I/O error while handling produce request: (kafka.server.KafkaApis)
135日志
[2014-10-11 11:02:35,754] FATAL [KafkaApi-135] Halting due to unrecoverable I/O error while handling produce request: (kafka.server.KafkaApis)
136日志
[2014-10-13 19:10:35,106] FATAL [KafkaApi-136] Halting due to unrecoverable I/O error while handling produce request: (kafka.server.KafkaApis)
报java.io.FileNotFoundException(No such file or directory),具体错误日志如下:
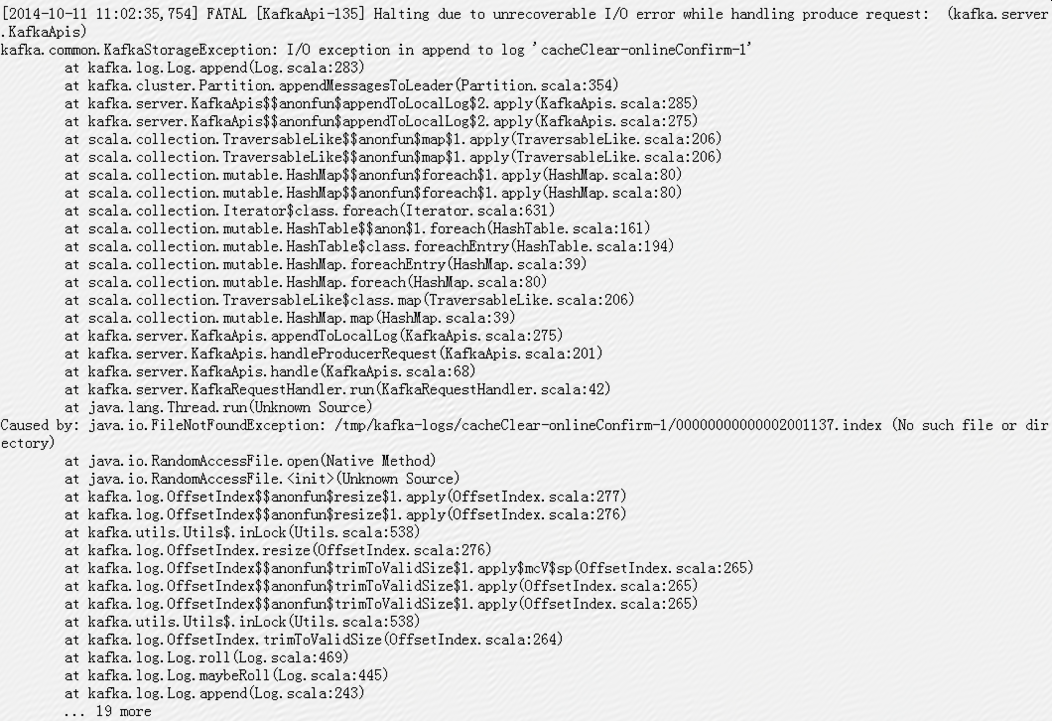
其中cacheClear-onlineConfirm-1是在线确认环境使用的一个分区;
二 问题分析
Kafka broker在作为leader收到message之后会调用kafka.log.Log.append将message加到本地log
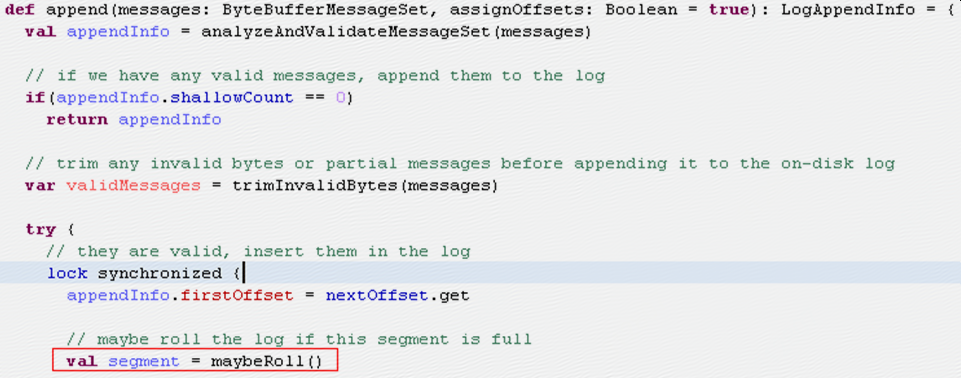
其中会先调用maybeRoll来检查是否需要做roll,
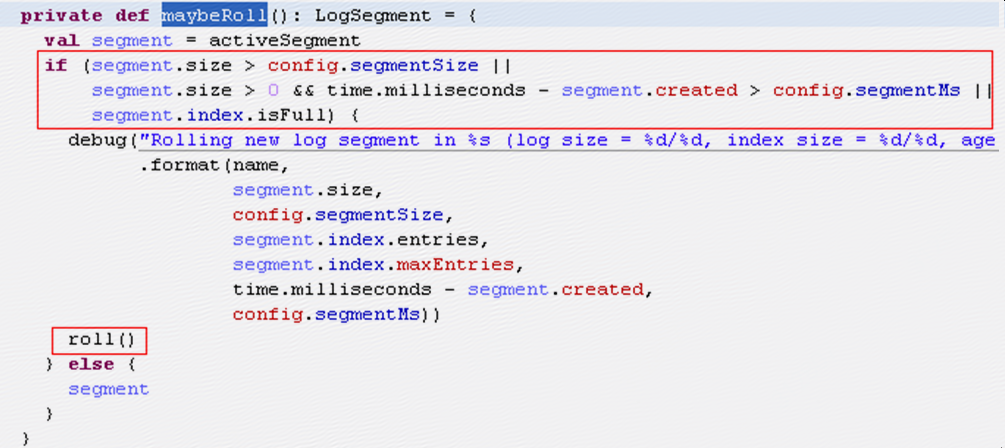
roll中会新建一个segment,同时将老的segment的index文件做一下trim,

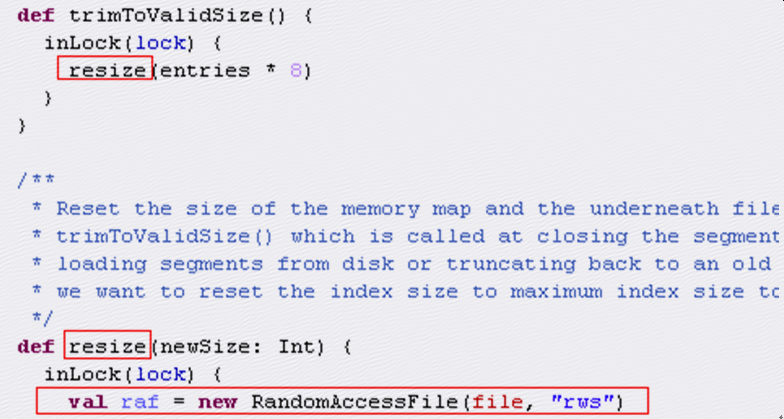
trimToValidSize中会调用resize,resize中会使用RandomAccessFile来打开index文件,报错的就是这一行:
1.1 为什么需要对index做trim
index文件初始化过程为:

LogSegment构造函数:

OffsetIndex构造函数:

可见index文件初始化时文件大小是固定的,按照配置中的maxIndexSize来定义,所以最后一个segment的index文件大小是一样的,并且初始时比log文件要大很多,如下图红框所示:

但是这样的index文件会有很多浪费,所以在roll时会根据index文件中的实际的entry数量做一下对文件大小做trim,这样只需要必要的文件大小来存储信息,如上图蓝框所示;
1.2 什么时候RandomAccessFile会报java.io.FileNotFoundException
目录/home/test存在,但是/home/test/1.txt不存在,/home/test/1/1.txt也不存在,使用RandomAccessFile来分别读取/home/test/1.txt和/home/test/1/1.txt,发现读取/home/test/1.txt时程序不会报错,但是读取/home/test/1/1.txt时程序报错:
1) 读取/home/test/1.txt

2) 读取/home/test/1/1.txt

所以报错

是因为cacheClear-onlineConfirm-1目录不存在,而不是因为00000000000002001137.index索引文件不存在;
1.3 目录什么时间被删除
在kafka服务器进程退出之前,日志中有很多error:
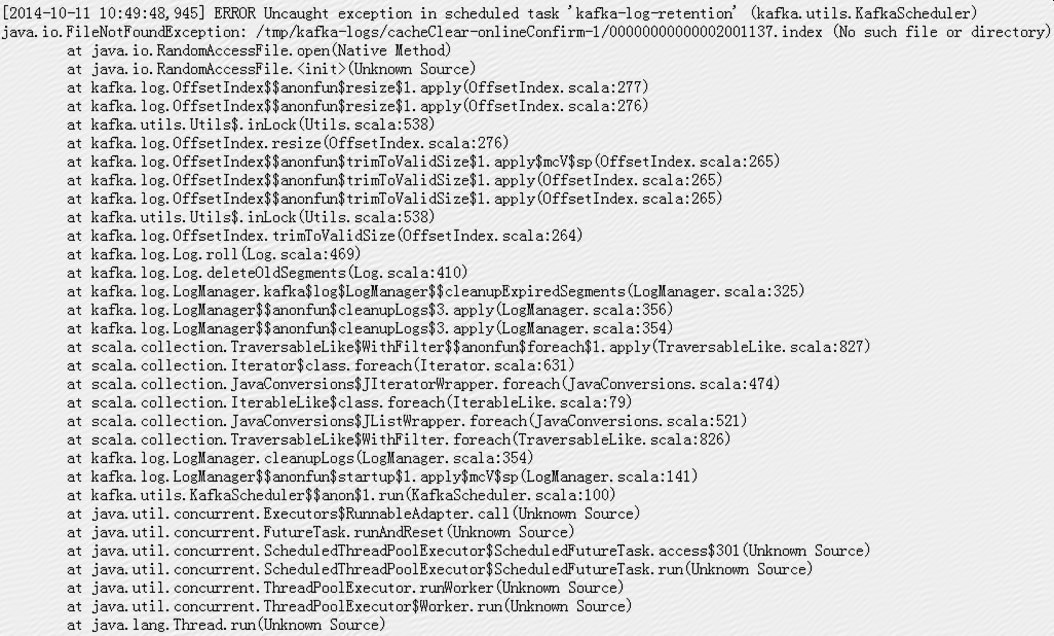
Kafka服务器有一个后台线程会做retention检查,检查间隔默认是5分钟

在134-136上分别检查error发现:
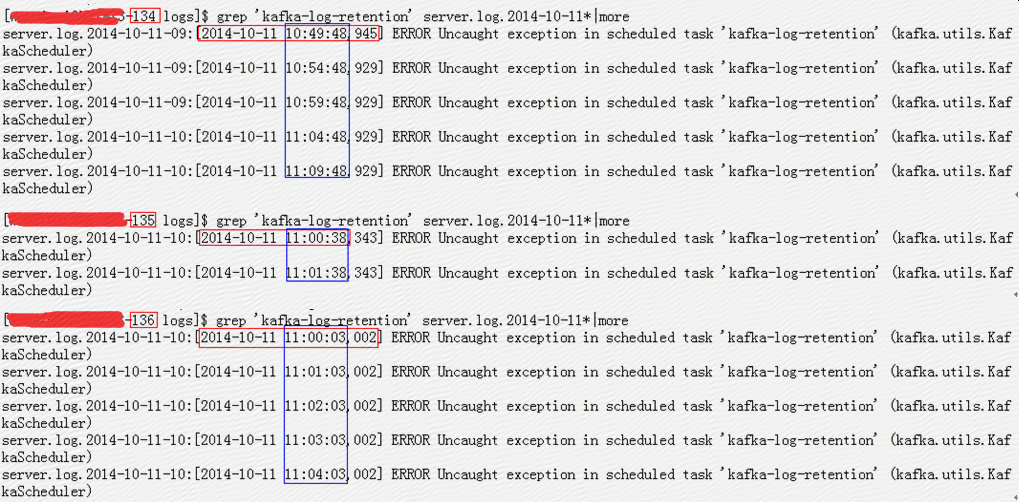
可见134从10:49:48开始报error,135从11:00:38开始报error,136从11:00:03开始报error,并且他们的检查间隔不同,134是5分钟,135和136都是1分钟,可见134上的分区目录是在10:49:48之前被删除,135是在11:00:38之前被删除,136是在11:00:03之前被删除;
1.4 为什么kafka进程退出时间不同
Kafka每个partition都有一个leader,只有leader会对message做append,所以只有leader才有可能执行上边的代码并退出进程,
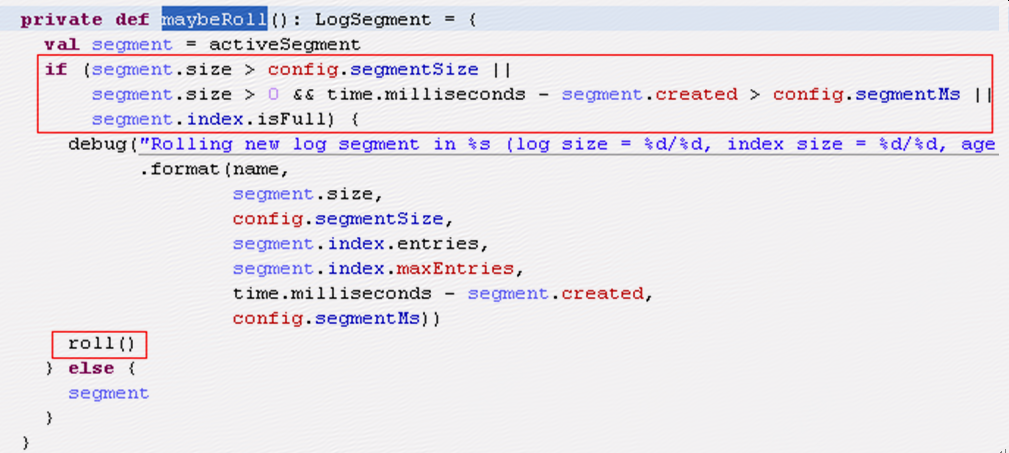
Leader在接受message时会判断是否需要roll,当segment大小超出限制或者segment存在时间超出限制时会做roll,当leader执行roll时会报错退出;
所以刚开始是135作为leader,然后在11号11:02:35时执行roll然后退出:
[2014-10-11 11:02:35,754] FATAL [KafkaApi-135] Halting due to unrecoverable I/O error while handling produce request: (kafka.server.KafkaApis)
然后134接任leader,然后在13号16:45:41执行roll报错退出:
[2014-10-13 16:45:41,902] FATAL [KafkaApi-134] Halting due to unrecoverable I/O error while handling produce request: (kafka.server.KafkaApis)
最后只剩下136接任leader,然后在13号19:10:35执行roll报错退出:
[2014-10-13 16:45:41,902] FATAL [KafkaApi-134] Halting due to unrecoverable I/O error while handling produce request: (kafka.server.KafkaApis)
Ps:
从135上的server.log可以看到8月20号时135作为leader对ISR进行操作:

从134的controller.log中可以看出,当135挂了之后,134作为controller接管原本135作为leader的partition:
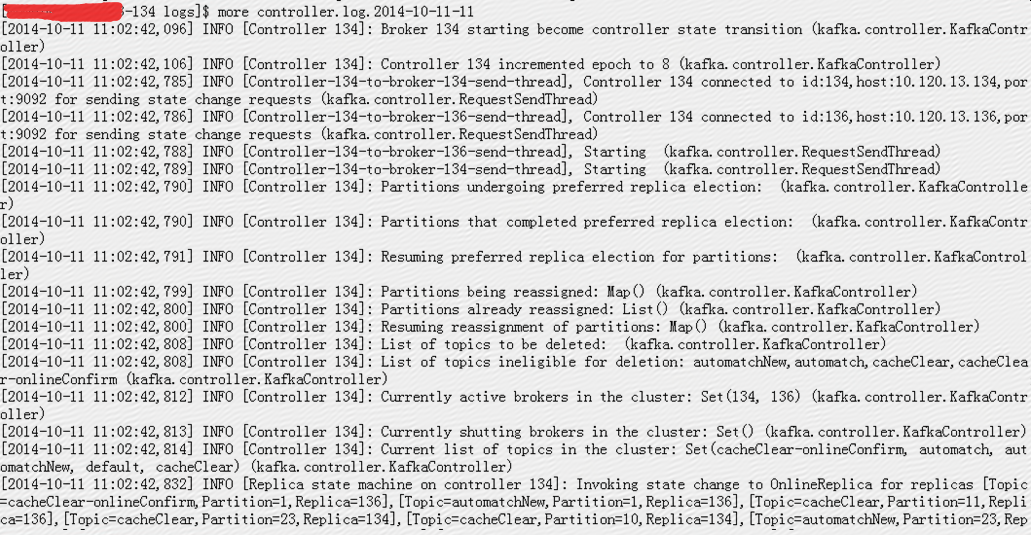
而134挂了之后,136作为controller接管原本134作为leader的partition:

三 问题定位
Partition目录被删除有几种可能,一种是操作系统删除,一种是人为删除,一种是kafka自己删除;
1 操作系统删除
/tmp 目录是临时目录,操作系统会负责删除过期文件

检查cron日志发现当天134-136执行tmpwatch的时间是在凌晨3点多,并且只执行了一次,
Oct 11 03:28:02 hz1-13-134 run-parts(/etc/cron.daily)[24593]: starting tmpwatch
Oct 11 03:28:02 hz1-13-134 run-parts(/etc/cron.daily)[24829]: finished tmpwatch
Ps:
tmpwatch recursively removes files which haven't been accessed for a given time. Normally, it's used to clean up directories which are used for temporary holding space such as /tmp.
It does not follow symbolic links in the directories it's cleaning (even if a symbolic link is given as its argument), will not switch filesystems, skipslost+found directories owned by the root user, and only removes empty directories, regular files, and symbolic links.
By default, tmpwatch dates files by their atime (access time), not their mtime (modification time).
2 人为删除

Kafka日志目录属于root,并且只有root才有write权限,所以如果是人为删除,只能是root自己删除,这点不太可能;
Ps:人为删除partition目录可以很容易重现服务器的错误;
3 kafka自己删除
查看kafka代码发现确实有删除分区方法,位于kafka.cluster.Partition中:
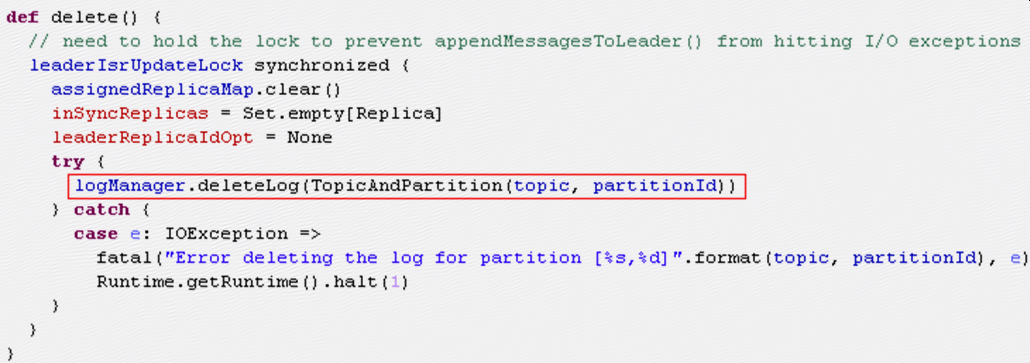
LogManager的deleteLog方法如下:

Log的delete方法如下:

方法中会迭代删除所有segment,然后清空segments变量,最后删除分区目录;
这里有两点需要考虑:
- 发生问题是因为kafka认为partition存在但其实partition已经由于某种原因被删除了,所以才会报错,如果是调用以上deleteLog方法删除partition,说明kafka肯定知道分区被删除(segments变量被清空,roll的时候取segments.lastEntry()肯定取不到),这样不会出问题;
- 要执行roll,需要当前broker作为partition的leader,但是以上deleteLog方法是被ReplicaManager.stopReplica调用,如果stopReplica被调用,说明当前broker已经不再作为partition的replica,更不可能作为leader;
以上两点可以反证出不是kafka自己删除partition目录;
四 问题原因
1 背景
1.1 Kafka的retention检查会调用kafka.log.Log.deleteOldSegment方法:
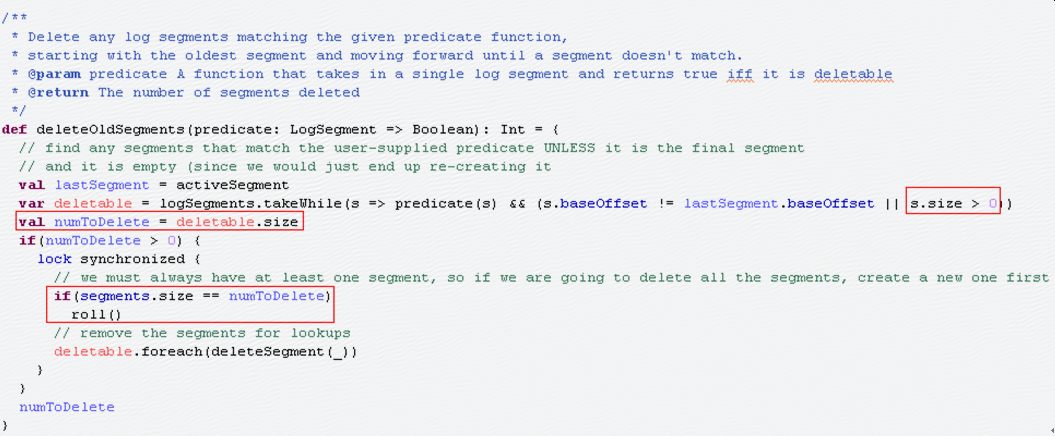
可以发现:如果没有新的message,最后一个segment会一直为空,这时这个segment不会被删除,也不会被roll,这个segment会一直原封不动的保留下去;
1) retention检查时如果segment为空,不会执行roll,这时即使partition目录为空,也不会报错,所以不能直接根据报错的时间推断出目录被删除的时间;
2) segment长时间为空有可能会满足tmpwatch的删除条件,即超过10天没有访问,如果segment文件被删除之后,分区目录会变成一个空目录,也会被删除;
1.2 kafka在接受消息时会调用kafka.log.Log.append方法,append方法会调用maybeRoll方法:
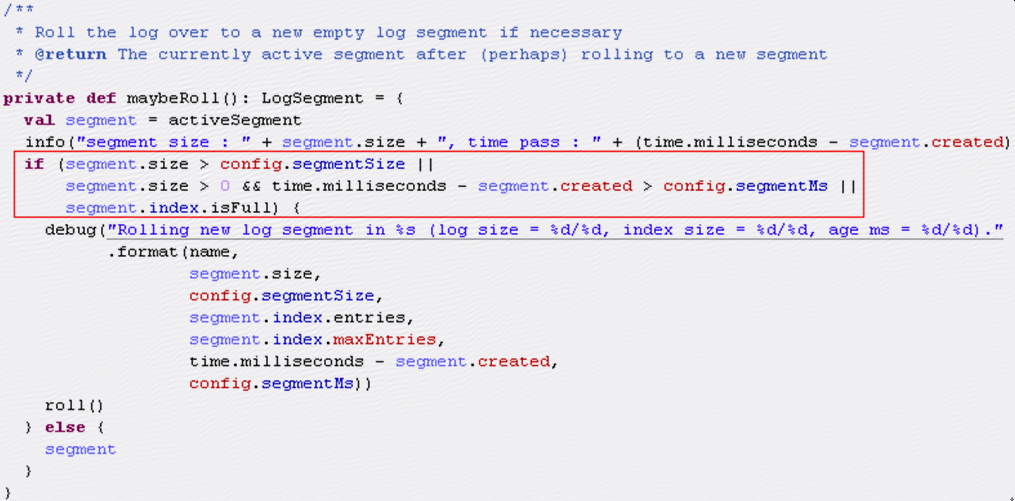
可以发现:当segment为空时,即segment.size=0,即使segment创建时间超过限制,在接收第一条消息的时候也不会进行roll,但是接受完第一条消息之后,segment.size>0,这时如果接收第二条消息就会进行roll;
2 模拟重现问题发生过程
1) kafka服务器配置retention检查间隔为1分钟,启动kafka服务器;
log.retention.check.interval.ms=60000
2) 10:00:00,创建测试topic:
kafka-topics.sh --zookeeper $zk_server:2187 --create --topic test --partitions 1 --config retention.ms=300000 --config segment.ms=600000
3) 马上手工将分区目录test-0删除;
4) 10:05:00之前至少进行4次retention检查,由于内存中的segment变量的最后修改时间还没有超过retention.ms(以下截图红框处),所以不会执行roll,不会报错;

5) 10:05:00之后,在进行retention检查时,segment最后修改时间超过retention.ms,但是由于segment为空(以下截图红框处),所以不会执行roll,不会报错;

6) 10:10:00之后,segment的创建时间超过segment.ms(以下截图红框处);

7) 在10:10:01,发送第一条消息到kafka
kafka-console-producer.sh --broker-list $kafka_server:9081 –topic test
8) kafka服务器中,由于此时segment.size=0,所以maybeRoll中下图红框中条件不满足,

所以不会进行roll,不会报错;
9) 10:10:01开始,kafka服务器每次retention检查时,下图红框两个条件都为true,
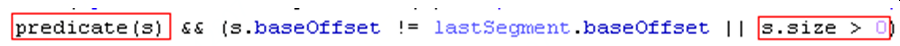
满足roll条件,进行roll,然后报错:
ERROR Uncaught exception in scheduled task 'kafka-log-retention' (kafka.utils.KafkaScheduler)
java.io.FileNotFoundException: /home/wuweiwei/kafkalogs/1/test-0/00000000000000000000.index (No such file or directory)
10) 在发送第二条消息到kafka之前,服务器每隔1分钟进行一次检查都会报以上错误,由于进行检查的是后台线程,所以kafka进程不会退出;
11) 10:20:00,发送第二条消息到kafka
kafka-console-producer.sh --broker-list $kafka_server:9081 –topic test
12) kafka服务器中,由于之前已经收到第一条消息,此时segment.size>0,所以maybeRoll中下图红框两个条件都为true,

满足roll条件,进行roll,然后报错:
FATAL [KafkaApi-101] Halting due to unrecoverable I/O error while handling produce request: (kafka.server.KafkaApis)
kafka.common.KafkaStorageException: I/O exception in append to log 'test1-0'
Caused by: java.io.FileNotFoundException: /home/test/kafkalogs/1/test-0/00000000000000000000.index (No such file or directory)
由于这个报错是在kafka进程中,所以kafka进程退出;
3 实际问题发生过程
3.1 135服务器
1)2014-10-01 03:44之前,kafka对分区cacheClear-onlineConfirm-1执行retention检查,删除了旧的segment并且新建了一个空的segment;
2)2014-10-01 03:44到2014-10-11 03:44没有新的message到达分区cacheClear-onlineConfirm-1,所以这个分区一直只有一个空的segment;
3)2014-10-11 03:44 anacron执行,调用tmpwatch来清理/tmp目录,分区cacheClear-onlineConfirm-1完整路径是/tmp/kafka-logs/ cacheClear-onlineConfirm-1,tmpwatch发现分区目录最后访问时间是10天前,进行删除;
4)2014-10-11 03:44到11:00:03之间kafka一直在进行retention检查,但是由于内存中的segment变量是空segment,所以没有执行roll,不会报错;
5)2014-10-11 10:59:38到11:00:38之间,第一条message到达分区cacheClear-onlineConfirm-1;
6)2014-10-11 11:00:38,kafka做retention检查,此时segment不为空,进入roll,然后开始报错(ERROR);
7)2014-10-11 11:02:35,第二条message到达分区cacheClear-onlineConfirm-1,这时kafka在append前进行roll,报错(FATAL),kafka进程退出;
3.2 134服务器
1)135服务器挂了之后,134服务器作为leader接管分区cacheClear-onlineConfirm-1;
2)2014-10-13 16:45:41,134服务器接收到第一条message,执行roll,报错(FATAL),进程退出;
3.3 136服务器
1)134服务器挂了之后,136服务器作为leader接管分区cacheClear-onlineConfirm-1;
2)2014-10-13 19:10:35,136服务器接收到第一条message,执行roll,报错(FATAL),进程退出;
五 问题总结
1)使用默认的kafka日志目录/tmp/kafka-logs是一个隐患,可以先将/tmp/kafka-logs加到/etc/cron.daily/tmpwatch的目录排除列表里;
2)另外可以梳理一下kafka的日志,尤其是ERROR和FATAL,做好日志监控及时发现问题;
【原创】大叔问题定位分享(3)Kafka集群broker进程逐个报错退出的更多相关文章
- 【原创】大叔问题定位分享(2)spark任务一定几率报错java.lang.NoSuchFieldError: HIVE_MOVE_FILES_THREAD_COUNT
最近用yarn cluster方式提交spark任务时,有时会报错,报错几率是40%,报错如下: 18/03/15 21:50:36 116 ERROR ApplicationMaster91: Us ...
- 【原创】大叔问题定位分享(24)hbase standalone方式启动报错
hbase 2.0.2 hbase standalone方式启动报错: 2019-01-17 15:49:08,730 ERROR [Thread-24] master.HMaster: Failed ...
- 【原创】大叔问题定位分享(10)提交spark任务偶尔报错 org.apache.spark.SparkException: A master URL must be set in your configuration
spark 2.1.1 一 问题重现 问题代码示例 object MethodPositionTest { val sparkConf = new SparkConf().setAppName(&qu ...
- windows下配置redis集群,启动节点报错:createing server TCP listening socket *:7000:listen:Unknown error
windows下配置redis集群,启动节点报错:createing server TCP listening socket *:7000:listen:Unknown error 学习了:https ...
- 【原创】大叔问题定位分享(4)Kafka集群broker节点从zookeeper上消失
kafka_2.8.0-0.8.1 一 现象 生产环境一组kafka集群经常发生问题,现象是kafka在zookeeper上的broker节点消失,此时kafka进程和端口都在,然后每个broker都 ...
- kafka集群broker频繁挂掉问题解决方案
现象:kafka集群频繁挂掉 排查日志:查看日志文件[kafkaServer.out],发现错误日志:ERROR Shutdown broker because all log dirs in /tm ...
- 【原创】大叔问题定位分享(9)oozie提交spark任务报 java.lang.NoClassDefFoundError: org/apache/kafka/clients/producer/KafkaProducer
oozie中支持很多的action类型,比如spark.hive,对应的标签为: <spark xmlns="uri:oozie:spark-action:0.1"> ...
- HDFS集群启动start-dfs.sh报错
[root@master sbin]# start-dfs.sh Starting namenodes on [master] master: Error: JAVA_HOME is not set ...
- Kafka 集群在马蜂窝大数据平台的优化与应用扩展
马蜂窝技术原创文章,更多干货请订阅公众号:mfwtech Kafka 是当下热门的消息队列中间件,它可以实时地处理海量数据,具备高吞吐.低延时等特性及可靠的消息异步传递机制,可以很好地解决不同系统间数 ...
随机推荐
- JAVA获取计算机CPU、硬盘、主板、网络等信息
通过使用第三方开源jar包sigar.jar我们可以获得本地的信息 1.下载sigar.jar sigar官方主页 sigar-1.6.4.zip 2.按照主页上的说明解压包后将相应的文件copy到j ...
- 电脑装windows和ubuntu,如何卸载ubuntu系统
电脑装windows和ubuntu,如何卸载ubuntu系统 2018年01月17日 16:28:29 职业炮灰 阅读数:684 版权声明:本文为博主原创文章,未经博主允许不得转载. https ...
- CSS3选择器p:nth-child和p:nth-of-type之间的差异
稍微自己理解了一下,感觉就是:nth-of-type似乎有种族歧视,界限划分很清晰.在同一个国家(父级)中的时候,nth-of-type指认自己人排名,nth-child全都算在内排名,阿T的要求真的 ...
- 「CF1154F」Shovels Shop【背包DP】
题目链接 [洛谷传送门] 题解 非常简单的背包. \(f[i]\)表示购买\(i\)个物品所需要最少的花费. 不考虑免费的限制条件,那么一定是选择前\(k\)个双鞋子. 那么加入免费的条件,那么还是要 ...
- <数据结构基础学习>(三)Part 1 栈
一.栈 Stack 栈也是一种线性的数据结构 相比数组,栈相对应的操作是数组的子集. 只能从一端添加元素,也只能从一端取出元素.这一端成为栈顶. 1,2,3依次入栈得到的顺序为 3,2,1,栈顶为3, ...
- Yii2.0 安装使用报错:yii\web\Request::cookieValidationKey must be configured with a secret key.
下载了Yii2.0的basic版,配置好apache之后,浏览器访问,出现如下错误: Invalid Configuration – yii\base\InvalidConfigException y ...
- create-react-app中添加less支持
前言 使用 create-react-app 脚手架创建项目后,默认是不支持 less 的.所以我们需要手动添加. 第一步 暴露webpack配置文件 使用 create-react-app 创建的项 ...
- 我眼中的支持向量机(SVM)
看吴恩达支持向量机的学习视频,看了好几遍,才有一点的理解,梳理一下相关知识. (1)优化目标: 支持向量机也是属于监督学习算法,先从优化目标开始. 优化目标是从Logistics regressi ...
- ZOJ Monthly, January 2018
A 易知最优的方法是一次只拿一颗,石头数谁多谁赢,一样多后手赢 #include <map> #include <set> #include <ctime> #in ...
- SQL Server数据库的备份和还
转:http://blog.csdn.net/zwj7612356/article/details/8188025 在sql server数据库中,备份和还原都只能在服务器上进行,备份的数据文件在服务 ...