Redis的持久化之RDB
1.什么是Redis的持久化
Redis是一种高级key-value数据库,是一个高性能的(key/value)分布式内存数据库,基于内存运行并支持持久化的NoSQL数据库,所以Redis的所有数据都是保存在内存中,为了Redis提供了一种机制可以把数据保存到磁盘上(可永久保存的存储设备中),以便数据恢复和永久保存,而这种机制就是持久化。
redis提供两种方式进行持久化,一种是RDB持久化,另外一种是AOF(append only file)持久化
2.RDB
2.1什么是RDB
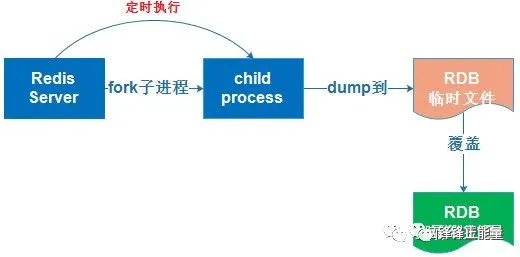
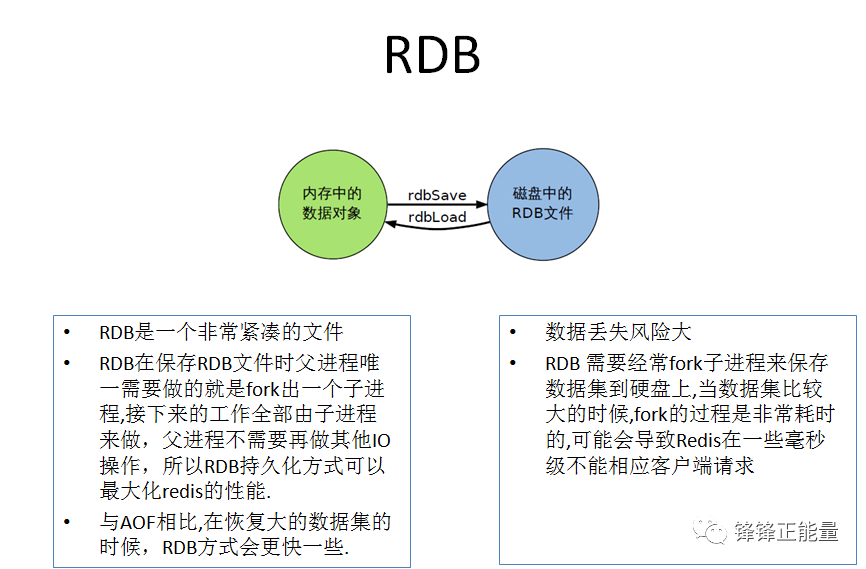
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。(在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里)
2.2RDB持久化的原理
RDB持久化的原理:是Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能,如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
备注:Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
2.3RDB2触发机制的方式
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,那么就应该有一种触发机制,是实现这个过程。对于RDB来说,提供了三种机制:save、bgsave、自动化
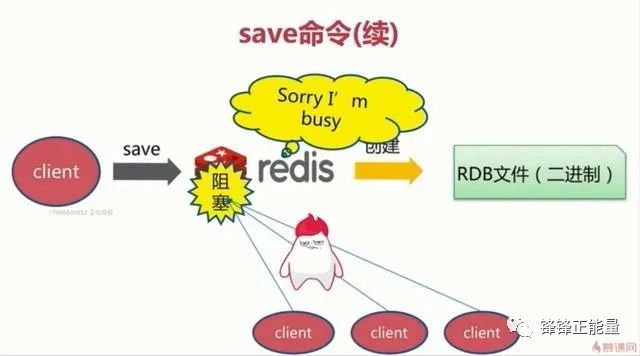
2.3.1save触发方式
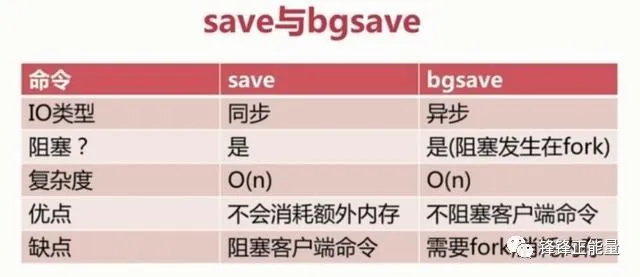
save触发方式会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止(save时只管保存,其它不管,全部阻塞)具体流程如下
2.3.2bgsave触发方式
使用bgsave触发方式时Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求,可以通过lastsave命令获取最后一次成功执行快照的时间
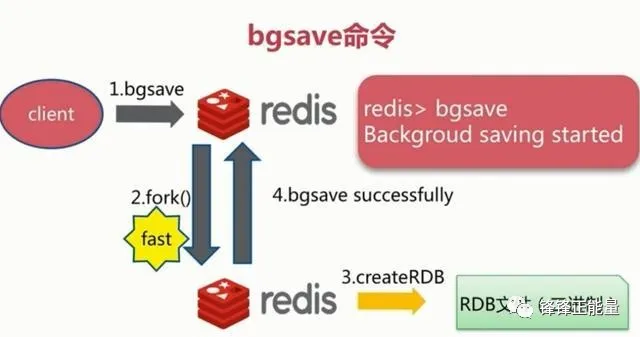
具体执行过程:是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。在实际开发中基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
*save与bgsave对比:
2.3.3自动触发
自动触发是由我们的配置redis.conf文件来完成的在redis.conf配置文件中,里面有如下配置
①save:这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。
比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。如果不需要持久化,
那么你可以注释掉所有的 save 行来停用保存功能默认如下配置:
#表示900 秒内如果至少有 1 个 key 的值变化,则保存save 900
1#表示300 秒内如果至少有 10 个 key 的值变化,则保存save 300
10#表示60 秒内如果至少有 10000 个 key 的值变化,则保存save 60 10000 ②stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败,
Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,
否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了 ③rdbcompression ;默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。 ④rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,
但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。 ⑤dbfilename :设置快照的文件名,默认是 dump.rdb ⑥dir:设置快照文件的存放路径,设置快照文件的存放路径,
这个配置项一定是个目录,而不能是文件名
2.4RDB 的优势和劣势
2.4.1RDB的优势
(1)RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
(2)生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
(3)RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
(4)适合大规模的数据恢复
(5)对数据完整性和一致性要求不高
2.4.2RDB的劣势
(1)在一定间隔时间做一次备份,所以如果redis意外down掉的话,就
会丢失最后一次快照后的所有修改
(2)Fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑
2.5如何恢复与停止
恢复:
备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可
CONFIG GET dir获取目录
停止
动态所有停止RDB保存规则的方法:redis-cli config set save ""
2.6RDB总结
Redis的持久化之RDB的更多相关文章
- Redis:持久化之RDB和AOF
Redis:持久化之RDB和AOF RDB(Redis DataBase) 在指定的时间间隔内将内存中的数据集快照写入硬盘 也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里. R ...
- redis的持久化之RDB的配置和原理
Redis优秀的性能是由于其将所有的数据都存储在内存中,同样memcached也是这样做的,内存中的数据会在服务器重启后就没有了,也就是不能保证持久化.但是为什么Redis能够脱颖而出呢,很大程度上是 ...
- redis的持久化方式RDB和AOF的区别
1.前言 最近在项目中使用到Redis做缓存,方便多个业务进程之间共享数据.由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能, ...
- Redis的持久化之RDB方式
RDB方式 Redis是默认支持的 优势:只有一个文件,时间间隔的数据,可以归档为一个文件,方便压缩转移(就一个文件) 劣势:如果宕机,数据损失比较大,因为它是没一个时间段进行持久化操作的.也就是积攒 ...
- 11、Redis的持久化(RDB、AOF)
写在前面的话:读书破万卷,编码如有神 --------------------------------------------------------------------------------- ...
- NoSql数据库Redis系列(3)——Redis数据持久化(RDB)
大家都知道 Redis 是一个内存数据库,所谓内存数据库,就是将数据库中的内容保存在内存中,这与传统的MySQL,Oracle等关系型数据库直接将内容保存到硬盘中相比,内存数据库的读写效率比传统数据库 ...
- 分布式缓存Redis的持久化方式RDB和AOF
一.前言 Redis支持两种方式的持久化,RDB和AOF.RDB会根据指定的规则“定时”将内存中的数据存储到硬盘上,AOF会在每次执行命令后将命令本身记录下来.两种持久化方式可以单独使用其中一种,但更 ...
- 详细分析Redis的持久化操作——RDB与AOF
一.前言 由于疫情的原因,学校还没有开学,这也就让我有了很多的时间.趁着时间比较多,我终于可以开始学习那些之前一直想学的技术了.最近这几天开始学习Redis,买了本<Redis实战>, ...
- redis的持久化(RDB与AOF)
1.为什么redis要实现持久化? 避免因宕机.断电等场景导致进程退出后数据丢失,如果redis的数据都只存放于内存,那么进程退出后数据就丢失了.持久化机制可以持久化内存数据到硬盘,重启redis后基 ...
随机推荐
- 电脑添加多个SSH key
创建新得ssh key ssh-keygen -t rsa -C "excem@excemple" -f ~/.ssh/id_rsa.gitlab 编辑config vim ~/. ...
- DP没入门就入土
写在前面 记录最近刷的DP题 以及 打死都不可能想到状态设计DP系列 汇总 洛谷 P6082 [JSOI2015]salesman 树形\(\texttt{DP}\) + 优先队列 比较容易看出来这是 ...
- 快来!我从源码中学习到了一招Dubbo的骚操作!
荒腔走板 大家好,我是 why,欢迎来到我连续周更优质原创文章的第 55 篇. 老规矩,先来一个简短的荒腔走板,给冰冷的技术文注入一丝色彩. 魔幻的 2020 年的上半年过去了,很多人都在朋友圈和上半 ...
- Linux多任务编程之四:exit()函数及其基础实验(转)
来源:CSDN 作者:王文松 转自Linux公社 exit()和_exit()函数 函数说明 创建进程使用fork()函数,执行进程使用exec函数族,终止进程则使用exit()和_exit() ...
- Scala 基础(十六):泛型、类型约束-上界(Upper Bounds)/下界(lower bounds)、视图界定(View bounds)、上下文界定(Context bounds)、协变、逆变和不变
1 泛型 1)如果我们要求函数的参数可以接受任意类型.可以使用泛型,这个类型可以代表任意的数据类型. 2)例如 List,在创建 List 时,可以传入整型.字符串.浮点数等等任意类型.那是因为 Li ...
- java 面向对象(七):类结构 方法(四)递归方法
1.定义:递归方法:一个方法体内调用它自身.2.如何理解递归方法?> 方法递归包含了一种隐式的循环,它会重复执行某段代码,但这种重复执行无须循环控制.> 递归一定要向已知方向递归,否则这种 ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- ASP.NET Core策略授权和 ABP 授权
目录 ASP.NET Core 中的策略授权 策略 定义一个 Controller 设定权限 定义策略 存储用户信息 标记访问权限 认证:Token 凭据 颁发登录凭据 自定义授权 IAuthoriz ...
- 大话深度学习:B站Up主麦叔教你零代码实现图像分类神经网络
之前,我在B站发布了“大话神经网络,10行代码不调包,听不懂你打我!”的视频后,因为简单易懂受到了很多小伙伴的喜欢! 但也有小伙伴直呼不够过瘾,因为大话神经网络只有4个神经元. 也有小伙伴问不写代码, ...
- Kubernetes容器化工具Kind实践部署Kubernetes v1.18.x 版本, 发布WordPress和MySQL
Kind 介绍 Kind是Kubernetes In Docker的缩写,顾名思义是使用Docker容器作为Node并将Kubernetes部署至其中的一个工具.官方文档中也把Kind作为一种本地集群 ...