Deep Learning with Differential Privacy
原文链接:Deep Learning with Differential Privacy
abstract:新的机器学习算法,差分隐私框架下隐私成本的改良分析,使用非凸目标训练深度神经网络。
数学中最优化问题的一般表述是求取$ x * \in \chi $ 使得 $ f(x * ) = min\{ f(x):x \in \chi \} $,其中x是n维向量, $ \chi $ 是x的可行域,f是$ \chi $ 上的实值函数。凸优化问题是指$ \chi $ 是闭合的凸集且f是$ \chi $ 上的凸函数的最优化问题,这两个条件任一不满足则该问题即为非凸的最优化问题。
Part1 introduction:
我们训练模型使用非凸目标、多个层次、上万个参数
相比来说:以往的工作对参数较少的凸模型和隐私损失较大的复杂神经网络都取得了较好的结果
contribution:
1.跟踪隐私丢失细节,我们可以从渐进和经验两方面获得对整体隐私损失的更严格的估计。
2.提出独立训练样本计算梯度的高效算法,任务分成小堆,输入层使用差分隐私策略投影。
3.机器学习框架TensorFlow建立DP模型,MNIST/CIFAR测试数据集(机器学习公认测试集),在软件复杂度、训练效率和模型质量方面,深度神经网络的隐私保护可以以适当的成本实现。
规范化技术避免对训练样本过拟合。
一个特定的敌手很可能是提取部分训练数据,逆模型攻击(恢复图像)只需要黑盒访问模型
假设敌手对训练机制有完全了解且完全访问模型参数。
Part2 Background
2.1差分:
相邻数据集的定义 例如,在我们的实验中,每个训练数据集是一组图像-标签对;如果这两个集合在单个项中不同,也就是说,如果一个图像-标签对存在于一个集合中,而另一个集合中不存在,我们就说它们是相邻的。
Dierential隐私有几个特性:可组合性、组隐私和对辅助信息的健壮性。
组隐私意味着如果数据集包含相关的输入,比如由同一个人提供的输入,隐私保证的完美减低。
对辅助信息的鲁棒性是指隐私保证不受对手可用的任何辅助信息的影响。
preliminary:设计一个差分隐私额外噪声机制的基本流程:
1.通过限定敏感度函数的顺序组合逼近函数性。
2.选择额外噪声的参数。
3.执行隐私分析的结果机制。
2.2深度学习:
深度神经网络,在许多机器学习任务中非常有效,定义从输入到输出的参数化函数为许多基础模块的组合,比如仿射转换和简单的非线性函数,后者常用的例子是S型和改正线型单元。通过改变这些模块的参数,我们可以训练一个参数化函数,这个函数的目的是适应任何给定的有限输入输出例子。
我们定义了一个损失函数,表征与训练数据不匹配的惩罚。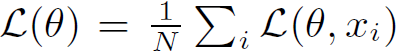
训练包含寻找到θ,产生可接受的最小损失。
the minimization is often done by the mini-batch stochastic gradient descent(SGD) algorithm.
在这个算法中,每一步生成一组随机数,并计算梯度。然后θ根据梯度方向更新,直到损失函数达到局部最小。
我们的工作基于TensorFlow,一个谷歌发布的开源数据流引擎。TensorFlow允许程序员从基本运算符定义大型计算图,并在异构的分布式系统中分布它们的执行。TensorFlow自动创建梯度的计算图形;它还使批处理计算变得容易。
3.Our Approach
本节描述了我们对神经网络进行差分私有训练的方法的主要组成部分:差分私有随机梯度下降(SGD)算法,矩阵计算和超参数调整。
3.1 Differentially Private SGD Algorithm
人们试图保护训练数据,通过仅仅对最终参数工作,视整个过程为黑盒子,但是没有对这些参数对训练数据依赖性有用准确的定义
对参数加入过度保守的噪声,这些噪声根据最差情况选择,会破坏学习模型的实用性。因此,我们选择更加精细的方法,旨在控制训练过程中训练数据的影响,特别是在SGD的计算中。
算法实现:剪切每个梯度的L2范数,计算平均值,添加噪声以保护隐私。然后对此平均噪声梯度逆梯度操作一步。最后,除了提出模型,我们计算根据隐私计算的隐私损失。

标准裁剪:
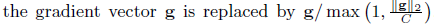
出于非隐私原因,对于深层网络,此形式的梯度裁剪是SGD的一种流行成分,尽管在这种情况下,通常取平均值后就足以裁剪。
每层与时间相关参数:
算法的伪代码将所有参数放在损失函数$ \mathcal{L} (\cdot)$的输出$ \theta $,
对于多层次神经网络我们分别考虑每个层次,允许设置不同的阈值和噪声范围
削减和噪声参数随着训练步骤t不同
分组Lots:
像普通的SGD算法一样,本算法通过计算一组例子的梯度并取平均估算L的梯度。这个平均值提供了一个无偏差的估算值,它的变化随着数据量的增加迅速减少。我们称这个组合为lot,与通常的计算组合batch区别开。
为了限制内存消耗,我们设置batch的容量远小于lot,batch是算法的参量。我们对batch进行计算,然后将batch放在一个lot中为了添加噪声。
隐私计算:
差分隐私的可组合性允许我们执行可累加过程:先计算每种到达训练数据的方式的隐私,然后将这些隐私累加作为训练过程。
训练的每一步骤要求多个层次的梯度,然后计算器累加对应于它们的所有成本。
Moments accountant:
对于特定噪声分布下的隐私损失以及隐私损失的构成进行了大量的研究
产生最佳整体限制的结果是强组合理论
强组合理论可能是不准确的,无法将特殊噪声分布纳入考虑
这允许我们证明该算法1是差分隐私的,如果选择合适的噪声范围和削减阈值。
3.2 The Moments Accountant: Details
时刻计算追踪隐私损失随机变量,它概括了追踪(ε,δ)的传统方法和使用强组合理论
直接从它组合可能导致结果是松的。我们转而计算隐私损失随机变量时刻的log,这是线性组合的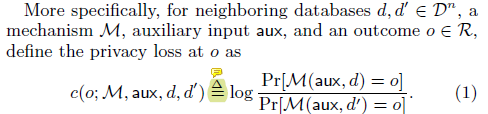
一个普遍的设计方法是更新状态,通过有序的运用差分隐私机制
前一个机制的输出作为下一个的附加输入。


当机制本身根据前一个机制的(公共)输出选择时,保持不变
3.3 Hyperparameter Tuning
我们可以调节的超参数,从而平衡隐私、准确性和性能。
我们发现对于神经网络模型结构的准确性对训练参数更敏感,比如batch的容量、噪声水平
凸目标函数的差分隐私优化是使用小到1的批处理大小来最佳实现的,非凸学习本身固有的稳定性较差,这受益于聚集成较大的Batch。
当模型收敛到局部最优时,非私有训练中的学习率通常会向下调整。
我们永远不需要把学习率降低到一个很小的值,因为从本质上讲,差分隐私训练永远不会达到一个需要被判断的领域。
Part4.implementation
我们需要在使用梯度去更新参数前对它们进行清洗
我们需要根据清洗是如何完成的来跟踪隐私成本
因此,我们的实现主要由两个组件组成:sanitizer和privacy_accountant,前者对梯度进行预处理以保护隐私,后者在训练过程中跟踪隐私开销。
在许多情况下,神经网络模型可以通过将输入投影在主方向(PCA)上或通过卷积层进行输入来从输入处理中受益。 我们实施差分私有PCA,并应用预训练的卷积层(从公共数据中学到)。
Sanitizer:
执行两个操作:通过裁剪每个示例的梯度范数来限制每个示例的灵敏度;在更新网络参数之前,将噪声添加到一批的梯度中。
我们当前的实现支持损失函数L的bacthed计算,其中每个xi都单独连接到L,允许我们处理大多数隐藏层,但不能处理卷积层。
一旦我们能够访问每个示例的梯度,就很容易使用TensorFlow操作符来剪辑它的范数和添加噪声。
Privacy accountant:
我们实施的主要组成部分是PrivacyAccountant,它在训练过程中跟踪隐私开销。
第一种方法恢复了一般的高级组合定理,后两种方法对隐私损失进行了更准确的计算。
根据Theorem2.2在训练期间的任何时候,都可以使用(epslion,delta)隐私更可解释的概念查询隐私损失.
我们通过提前确定迭代次数和隐私参数,避免他们的攻击和负面结果。隐私计算的更一般实现必须正确区分作为隐私距离或隐私过滤器的两种操作模式
Differentially private PCA:Principal component analysis(PCA) is a useful method for capturing the main features of the input data.
捕获输入数据的主要特征的有用方法
We take a random sample of the training examples, treat them as vectors, and normalize each vector to unit l2 norm to form the matrix A, where each vector is a row in the matrix. We then add Gaussian noise to the covariance matrix ATA and compute the principal directions of the noisy covariance matrix.
Then for each input example we apply the projection to these principal directions before feeding it into the neural network.
我们从训练样本中随机抽取一个样本,将它们视为向量,然后将每个向量归一化为2范数以形成矩阵A,其中每个向量都是矩阵中的一行。 然后,我们将高斯噪声添加到协方差矩阵ATA并计算有噪协方差矩阵的主要方向。
然后,对于每个输入示例,我们将投影应用于这些主要方向,然后再将其提供给神经网络。
由于运行PCA,我们产生了隐私成本。然而,我们发现它对于提高模型质量和减少训练时间都是有用的,正如我们在MNIST数据上的实验所表明的那样。
Convolutional layers:
卷积层对深度神经网络很有用。然而,一个有效的per-example梯度计算卷积层TensorFlow框架内仍然是一个挑战,它激励创建一个单独的工作。例如,最近的一些研究表明,即使是随机的卷积也满足。
另外,我们遵循Jarrett等人的观点探索在公共数据上学习卷积层的想法。 这样的卷积层可以基于用于图像模型的GoogLeNet或AlexNet功能,或者基于语言模型中的预训练word2vec或GloVe嵌入
Part5 Experiment Results
Part6 Related Work
现有的文献可以沿着几个轴进行广泛的分类:模型的类别、学习算法和隐私保证。
Privacy guarantees
隐私保护学习的早期研究是在安全函数评估的框架下进行的(SFE)和安全多方计算(MPC),其中输入在两个或更多方之间分割,重点是使在某些已达成共识的功能的联合计算过程中泄漏的信息最小化。 相反,我们假设数据集中保存,并且我们担心功能输出(模型)的泄漏。
另一种方法是k-匿名性和紧密相关的概念[53],它试图通过归纳和抑制某些识别属性来对基础数据提供一定程度的保护。该方法具有很强的理论和经验限制[4,9],这使其几乎不适用于高维,多样化输入数据集的去匿名化。与其保持输入原始状态不变,我们不破坏基础原始记录,而扰乱派生数据。
差分隐私理论为我们的工作提供了分析框架,已被应用于大量的机器学习任务,这些任务在训练机制或目标模型上都与我们的不同。
moments accountant与R'enyi差异隐私概念密切相关[42],后者提出了(定标)α(λ)作为量化隐私保证的一种手段。在并发且独立的工作中,Bun和Steinke [10]通过α(λ)的线性上限定义了放宽的差分隐私(概括了Dwork和Rothblum [20]的工作),这些工作证明了moments accountant是一种用于复杂隐私保护算法的理论和实证分析的有用技术。
Learning algorithm
隐私学习的一个共同目标是一类可应用多种技术的凸优化问题。
在并行工作中,Wu等人通过凸经验风险最小化在MNIST上实现了83%的准确率。
多层神经网络的训练是非凸的,通常通过SGD的应用来解决,其理论保证很少被理解。
对于CIFAR神经网络,我们分别对主成分分析投影矩阵[23]进行私有训练,用于降低输入的维数。
Model class
第一个端到端的差分隐私系统评估在Netflix Prize数据集[39],一个版本的协同过滤的问题。
尽管该问题与我们的高维输入有很多相似之处,但非凸目标函数的使用由McSherry和Mironov所采用的方法明显不同。 他们确定了学习任务的核心,即有效的足够的统计数据,可以通过高斯机制以差分隐私的方式进行计算。 在我们的方法中,没有足够的统计数据。
在最近的工作中,Shokri和Shmatikov [50]设计和评估了用于深度神经网络的分布式训练的系统。 紧密保持数据的参与者将经过sanitized处理的更新传达给central authority。 sanitization依赖于基于敏感性估计的加性噪声机制,可以将其改进为硬性敏感性保证。 他们计算每个参数的隐私损失(不适用于整个模型)。 按着我们的标准,MNIST数据集上每个参与者的总隐私损失超过数千。
Phan等人[45]探讨了另一种最新的差分隐私深度学习方法。这项工作的重点是学习自动编码器。隐私是基于干扰这些自动编码器的目标函数。
Deep Learning with Differential Privacy的更多相关文章
- Deep Learning and the Triumph of Empiricism
Deep Learning and the Triumph of Empiricism By Zachary Chase Lipton, July 2015 Deep learning is now ...
- Does Deep Learning Come from the Devil?
Does Deep Learning Come from the Devil? Deep learning has revolutionized computer vision and natural ...
- (转) Awesome - Most Cited Deep Learning Papers
转自:https://github.com/terryum/awesome-deep-learning-papers Awesome - Most Cited Deep Learning Papers ...
- (转)WHY DEEP LEARNING IS SUDDENLY CHANGING YOUR LIFE
Main Menu Fortune.com E-mail Tweet Facebook Linkedin Share icons By Roger Parloff Illustration ...
- Applied Deep Learning Resources
Applied Deep Learning Resources A collection of research articles, blog posts, slides and code snipp ...
- Understanding Convolution in Deep Learning
Understanding Convolution in Deep Learning Convolution is probably the most important concept in dee ...
- The Brain vs Deep Learning Part I: Computational Complexity — Or Why the Singularity Is Nowhere Near
The Brain vs Deep Learning Part I: Computational Complexity — Or Why the Singularity Is Nowhere Near ...
- Open Data for Deep Learning
Open Data for Deep Learning Here you’ll find an organized list of interesting, high-quality datasets ...
- Privacy-Preserving Deep Learning via Additively Homomorphic Encryption
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Full version of a paper at the 8-th International Conference on Appli ...
随机推荐
- 二、多线程及服务器编程总结------linux多线程服务端编程
- flink1.10版本StreamGraph生成过程分析
1.StreamGraph本质 本质就是按照用程序代码的执行顺序构建出来的用于向执行环境传输的流式图,并且可以支持可视化展示给用户的一种数据结构. 2.StreamGraph.StreamNode和S ...
- python程序基础
高级程序设计语言包括Python.C/C++.Java等 低级程序设计语言包括汇编语言和机器语言 Python是一种解释型语言,但为了提高运行效率,Python程序在 执行一次之后会自动生成扩展名 ...
- 听法国设计师大卫·维森特讲述他与CorelDRAW的渊源
在这次采访中,我们采访了法国插画家兼平面设计师大卫·维森特(David Vicente),他的特殊风格与Old-School美学,尤其是疯狂摇滚派有着密切的联系.在他精心制作的插图中,充满了细节和强烈 ...
- MathType中怎么编辑韩文字符
用MathType编辑公式,所涉及到符号与字母一般都是英文字母与数字,或者使用希腊字母,当然还有很多使用中文的情况.但是不仅如此,我们在使用MathType时,除了这些字符之外,还可以输入韩文或者日文 ...
- 「CSP-S 2019」Emiya 家今天的饭
description loj 3211 solution 看到题目中要求每种主要食材至多在一半的菜中被使用,容易想到补集转换. 即\(ans=\)总方案数-存在某一种食材在一半以上的菜中被使用的方案 ...
- python应用(1):安装与使用
程序员的基本工作是写程序,而写程序要用到编程语言,编程语言可以分为编译型语言跟解释型语言. 编译型语言,就是在执行代码之前,先把源代码编译(加链接)成另一种形式的代码,比如目标代码,或字节码,这种代码 ...
- 802.11抓包软件对比之Microsoft Network Monitor
从事WiFi嵌入式软件开发的同学,802.11协议层抓包分析是一个需要熟练掌握的一个技能,需要通过分析WiFi底层802.11协议层的数据包来定位问题.同时从学习802.11协议的角度而言,最有效的学 ...
- 可变长形参,增强for语句
`package 可变长形参; public class VarArgumen { public static int max(int...varArgs) {//就有可变长形参的求最大值方法 //可 ...
- python安装第三方库aiohtpp,sanio失败,pip install multidict 失败问题
1.python的第三库安装地址:http://www.lfd.uci.edu/~gohlke/pythonlibs 2. 3.pip安装.whl文件指定该文件的位置