python——sklearn完整例子整理示范(有监督,逻辑回归范例)(原创)
sklearn使用方法,包括从制作数据集,拆分数据集,调用模型,保存加载模型,分析结果,可视化结果
1 import pandas as pd
2 import numpy as np
3 from sklearn.model_selection import train_test_split #训练测试集拆分
4 from sklearn.linear_model import LogisticRegression #逻辑回归模型
5 import matplotlib.pyplot as plt #画图函数
6
7 from sklearn.externals import joblib #保存加载模型函数joblib
8
9 #以下为sklearn评测指标的一些函数
10 from sklearn.metrics import precision_score
11 from sklearn.metrics import classification_report
12 from sklearn.metrics import confusion_matrix
13
14 #1. 若有文件,建议用read_csv加载,用sep代表按照该符号分割,若文件无列标签名,则header设置为None,自定义标签名names
15
16 #file = "XXX_file"
17 #df = pd.read_csv(file, sep='###',header = None, names = ['flag','uuid','features'],engine = 'python')
18 #df.head()
19
20
21 #2. 准备好特征集合x 和 标签集合y
22
23 #x = df['features'] #x存储特征
24 #y = df['flag'] #y存储标签
25 x = np.random.rand(100,3)
26 print("x:\n",x)
27 print(x.shape)
28 y = np.array([1 if i.sum()>1.2 else 0 for i in x]) #若三个维度之和大于1.2,则y分类为1,否则为0
29 print("y:\n",y)
30 print(y.shape) #注意y的形式必须是(n,),即numpy中的一维格式
31 #当同时有 if 和 else 时,列表生成式构造为 [最终表达式 - 条件分支判断 - 范围选择]
32
33
34 #3. 拆分训练集和测试集(7:3)
35 x_train, x_test, y_train, y_test = train_test_split(x,y, random_state=666, train_size = 0.7)
36
37
38 #4. 生成模型,并喂入数据
39 clf = LogisticRegression()
40 clf.fit(x_train, y_train)
41
42
43 #5. 保存模型(用joblib,不用pickle)
44 joblib.dump(clf,"lr.model") #from sklearn.externals import joblib
45 #加载模型是: clf = joblib.load("lr.model")
46
47
48 #6. 预测结果,并评测
49 y_pred = clf.predict(x_test) #预测出来的值计做y_pred
50 y_true = y_test #真实值计做y_true,和sklearn参数一模一样
51
52 target_names = ['class 0', 'class 1']
53 print(classification_report(y_true, y_pred, target_names=target_names)) #可以参考sklearn官网API
54 print(confusion_matrix(y_true, y_pred)) #混淆矩阵(记住!sklearn定义的混淆矩阵m行n列含义是:该样本真实值是m,预测值是n)
55 print("precision_score:", precision_score(y_test,y_pred)) #打印精确率(记住!默认是positive,即标注为1的精确率)
56
57
58 #7. 附加:结果可视化,利用plt(用seaborn也可以)
59 """
60 #神秘代码,主要是保证plt字体显示正确
61 plt.rcParams['font.sans-serif'] = ['SimHei']
62 plt.rcParams['font.family']='sans-serif'
63 plt.rcParams['axes.unicode_minus'] = False
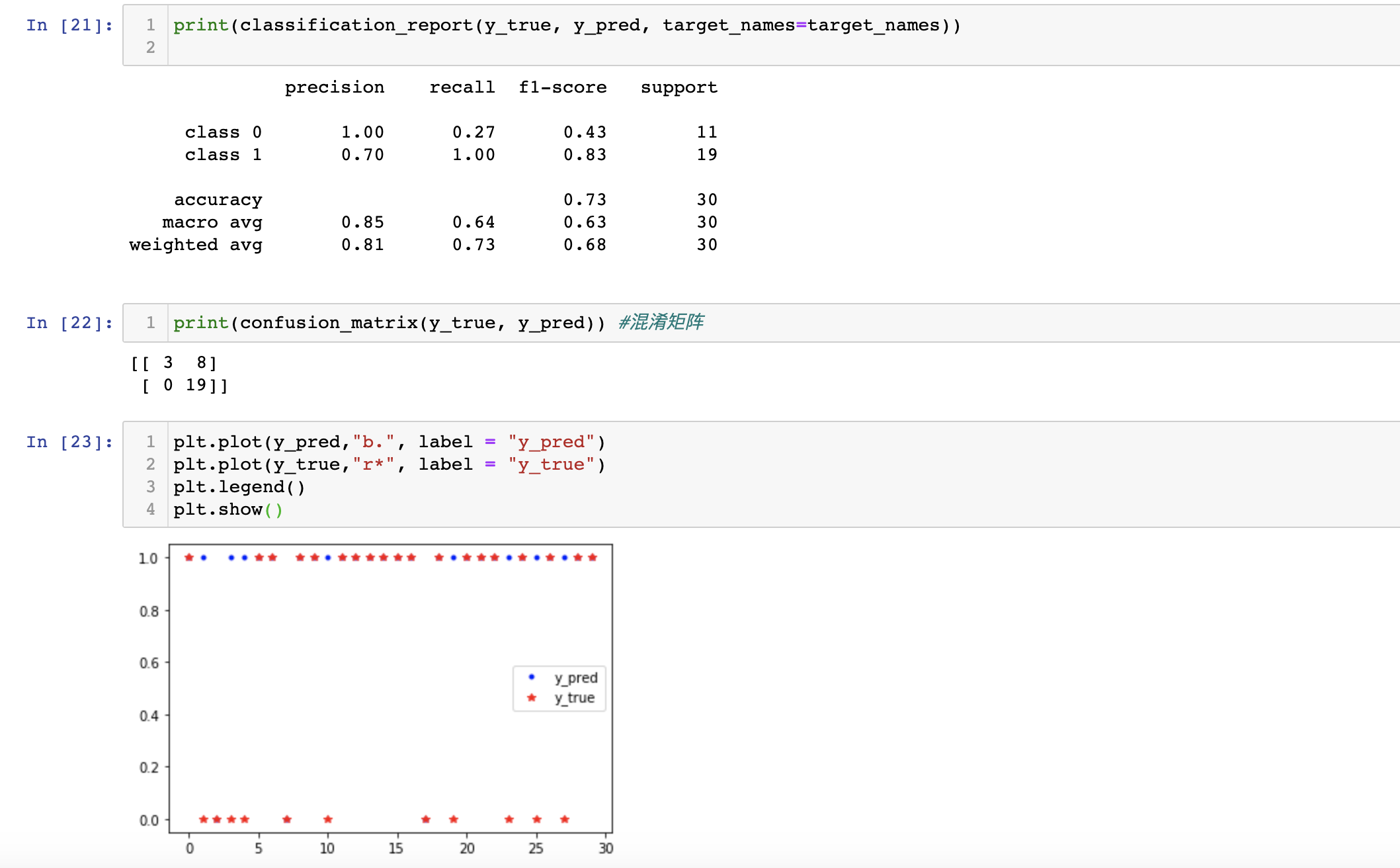
64 """
65 plt.plot(y_pred,"b.", label = "y_pred") #blue,点号
66 plt.plot(y_true,"r*", label = "y_true") #red,星号
67 plt.legend()
68 plt.show() #画的比较简略,可以进一步美化
python——sklearn完整例子整理示范(有监督,逻辑回归范例)(原创)的更多相关文章
- python基础全部知识点整理,超级全(20万字+)
目录 Python编程语言简介 https://www.cnblogs.com/hany-postq473111315/p/12256134.html Python环境搭建及中文编码 https:// ...
- Python —— sklearn.feature_selection模块
Python —— sklearn.feature_selection模块 sklearn.feature_selection模块的作用是feature selection,而不是feature ex ...
- Python Sklearn.metrics 简介及应用示例
Python Sklearn.metrics 简介及应用示例 利用Python进行各种机器学习算法的实现时,经常会用到sklearn(scikit-learn)这个模块/库. 无论利用机器学习算法进行 ...
- python+sklearn+kaggle机器学习
python+sklearn+kaggle机器学习 系列教程 0.kaggle 1. 初级线性回归模型机器学习过程 a. 提取数据 b.数据预处理 c.训练模型 d.根据数据预测 e.验证 今天是10 ...
- C#调用存储过程简单完整例子
CREATE PROC P_TEST@Name VARCHAR(20),@Rowcount INT OUTPUTASBEGIN SELECT * FROM T_Customer WHERE NAME= ...
- python多线程简单例子
python多线程简单例子 作者:vpoet mail:vpoet_sir@163.com import thread def childthread(threadid): print "I ...
- 使用Connector/C++(VS2015)连接MySQL的完整例子
完整示例代码1 /* Copyright 2008, 2010, Oracle and/or its affiliates. All rights reserved. This program is ...
- python 三方面库整理
测试开发 Web UI测试自动化 splinter - web UI测试工具,基于selnium封装. selenium - web UI自动化测试. –推荐 mechanize- Python中有状 ...
- Python NLP完整项目实战教程(1)
一.前言 打算写一个系列的关于自然语言处理技术的文章<Python NLP完整项目实战>,本文算是系列文章的起始篇,为了能够有效集合实际应用场景,避免为了学习而学习,考虑结合一个具体的项目 ...
随机推荐
- 微软发布.net 6,net5 RC2
2020-11-13 更新 .net 6 SDK https://dotnetcli.azureedge.net/dotnet/Sdk/6.0.100-alpha.1.20562.2/dotnet-s ...
- python xmind转Excel(puppet洛洛原创)
需求:将xmind文件转为Excel文件,并添加UI界面操作以降低操作难度. 这个需求一句话就讲清楚了,但实际上还需要做很多工作: 1,了解Xmind文件结构 2,提取Xmind文件分支内容(重点) ...
- Scanner对象
Scanner对象 通过Scanner类来获取用户的输入. 使用需导入 java.util.Scanner 包. 基本语法: Scanner s = new Scanner(System.in); n ...
- InnoDB事务的二阶段提交
问题: 什么是二阶段提交 为什么需要二阶段提交 二阶段提交流程 什么是二阶段提交? ### 假设原来id 为10 的记录age 为5 begin; update student set age = 1 ...
- 从头学起Verilog(三):Verilog逻辑设计
引言 经过了组合逻辑和时序逻辑的复习,终于到了Verilog部分.这里主要介绍Verilog一些基础内容,包括结构化模型.TestBench编写和仿真.真值表模型. 这部分内容不多,也都十分基础,大家 ...
- Linux踩坑之云服务器 ssh 连接不上
前奏:今天没事处理一下之前远程不了Linux桌面的问题时,找到一个解决方法(开始入坑): systemctl set-default graphical.tar ...
- Python_爬虫_案例汇总:
1.豆瓣采集 1 #coding:utf-8 2 #采集豆瓣书信息和图片,写进数据库 3 4 from urllib import request 5 # from bs4 import Beauti ...
- Appium常用操作之「Toast提示信息获取」
坚持原创输出,点击蓝字关注我吧 作者:清菡 博客:Oschina.云+社区.知乎等各大平台都有. 目录 一.什么是 Toast 二.获取 Toast 提示信息的前提 1.针对这种元素,有的时候我们需要 ...
- Xshell不能连接Kali系统SSH的解决
修改sshd_config文件 vim /etc/ssh/sshd_config 将#PasswordAuthentication yes的注释去掉 将#PermitRootLogin prohibi ...
- cmd编译java代码为什么总是说找不到main方法;请园子里大神指点迷津!!!
编写源代码如下: cmd,编译路径:E: cd Notepad cd src javac Character.java jvav Character 运行结果: 实在是找不到问题点,请评论区给予指导啊 ...