Database | 浅谈Query Optimization (2)
为什么选择左深连接树
对于n个表的连接,数量为卡特兰数,近似\(4^n\),因此为了减少枚举空间,早期的优化器仅考虑左深连接树,将数量减少为\(n!\)
但为什么是左深连接树,而不是其他样式呢?
如果join算法为index join或者hash join,当两张表进行连接的时候,需要为左表建立哈希映射或者搜索索引,连接时直接寻找对应的元素:
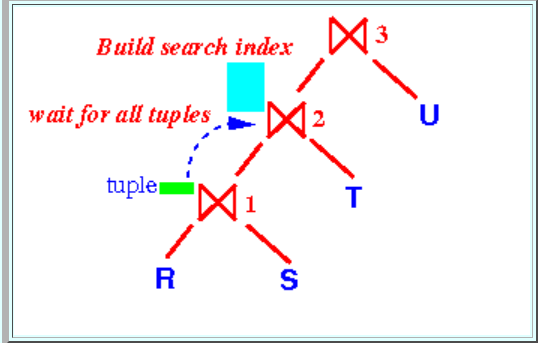
join ⋈2 必须等到⋈1 的全部元组输出之后才能生成它的映射表/索引。即只有⋈1 结束后,⋈2才能开始输出元组。而此时⋈3必须等待,直到⋈2完成。
对于多个表的连接,当⋈i正在执行时,⋈i+1处于半活跃的状态,它累积⋈i的输出到缓冲区并建立映射,而后面的⋈i+2到⋈n均处于空闲状态。
当执行连接⋈1时,需要为⋈1中的表分配内存,然后将输出的元组同样储存在内存中。而如前所述,只有⋈1结束时⋈2才能开始,因此⋈1结束时可以直接释放掉之前占用的内存空间。
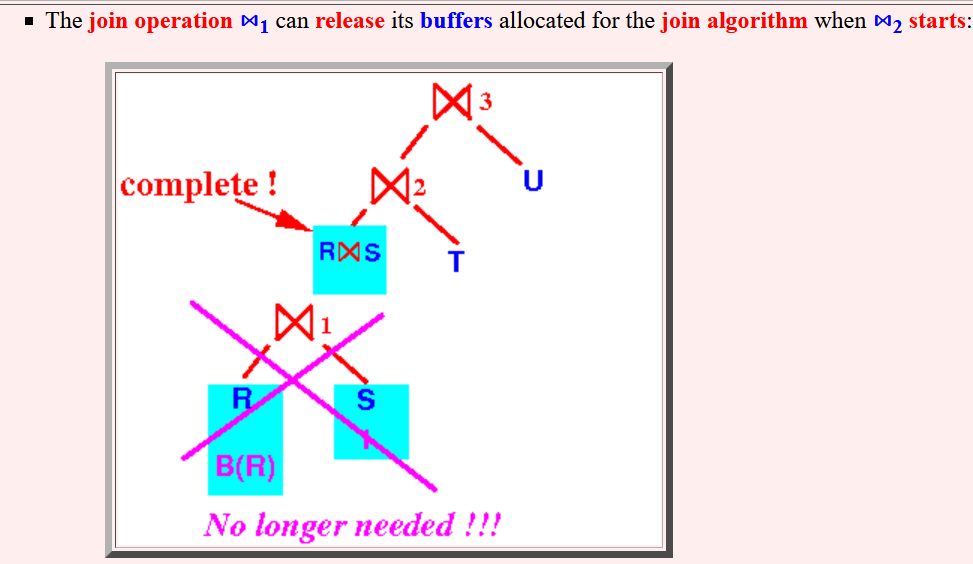
而对于其他形式的树,例如右深连接树,因为左侧的操作数都是一个关系,所有的join连接符都可以为左表建立映射表/索引,会占用大量的内存空间。
因此对于Hash Join,采用左深连接树可以减少执行计划对内存的需求。
当join算法为nested-loop join时,如果采用右深连接树,结果会更糟糕:
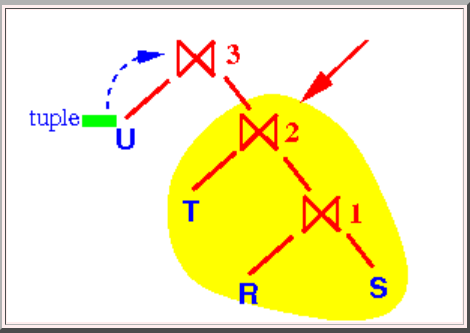
如图,执行⋈3时会导致多次访问⋈3的第二个操作数,使得该子查询多次执行,会多次访问表T、R、S增加读取磁盘的次数。
寻找最佳连接顺序
最佳的连接顺序即是中间结果中产生最少元组数量的连接顺序
因为不同的连接顺序都会访问每个表一次,而表连接的中间结果往往需要写入磁盘中暂时储存,因此中间结果元组数量越少,读取磁盘次数越少。
因此我们定义 cost for join 即是指连接后产生的中间结果的个数。
而不去连接怎么知道中间结果的个数呢?那就需要用到上一篇博客中提到的谓词的选择性和数据直方图,估算连接后产生的元组个数。
对于三个关系的连接,需要维护如下的数据图:
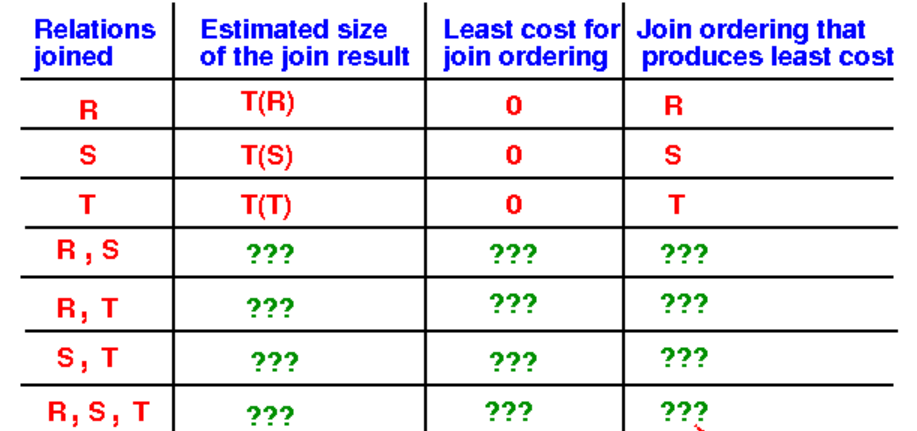
首先是相互连接关系的列表,然后是连接后的元组总数和连接的cost,以及这几个关系的最佳连接顺序。
然后对给定的n个表,将其分解成n个n-1的表的连接,再逐层分解,先求得两个关系的最佳连接方式。最优解即是这些子问题的组合。
算法的伪代码如下:
j = set of join nodes
for (i in 1...|j|): //一开始寻找单个join的最佳方案,再向上延伸
for s in {all length i subsets of j} //寻找s的最优连接
bestPlan = {}
//i-1的最优解都已经储存在optjoin中
//只需要考虑再加一个表的情况
for ss in {all length i-1 subsets of s}
subplan = optjoin(ss)
//optjoin 可以理解为一个哈希表,储存对应ss的最优连接
plan = best way to join (s-ss) to subplan
if (cost(plan) < cost(bestPlan))
bestPlan = plan
optjoin(s) = bestPlan
return optjoin(j)
具体而言,假设现在是R、S、T、U四个关系相连接,我们已经得出两个关系的最优解如下图所示:
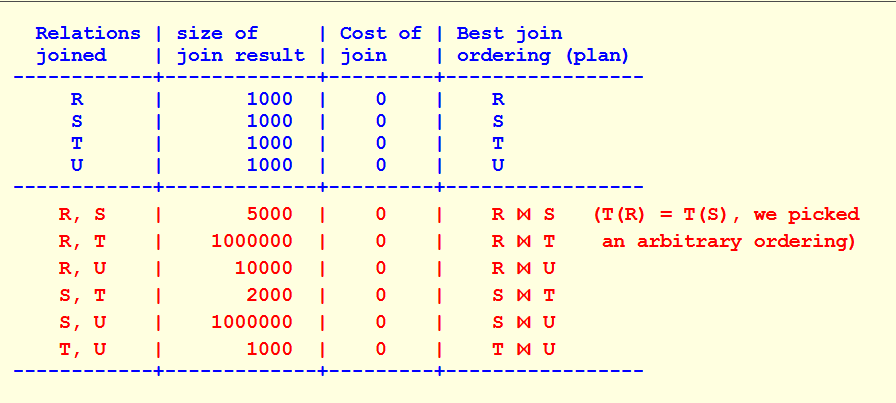
那么假设现在有
i=3, s=R,S,T
//那么对于ss
ss=R,S or R,T or S,T
计算出三种s的cost,找出bestplan,则
optjoin(R,S,T) = bestplan
我们先不考虑谓词选择性,直接将生成的元组个数作为cost,那么
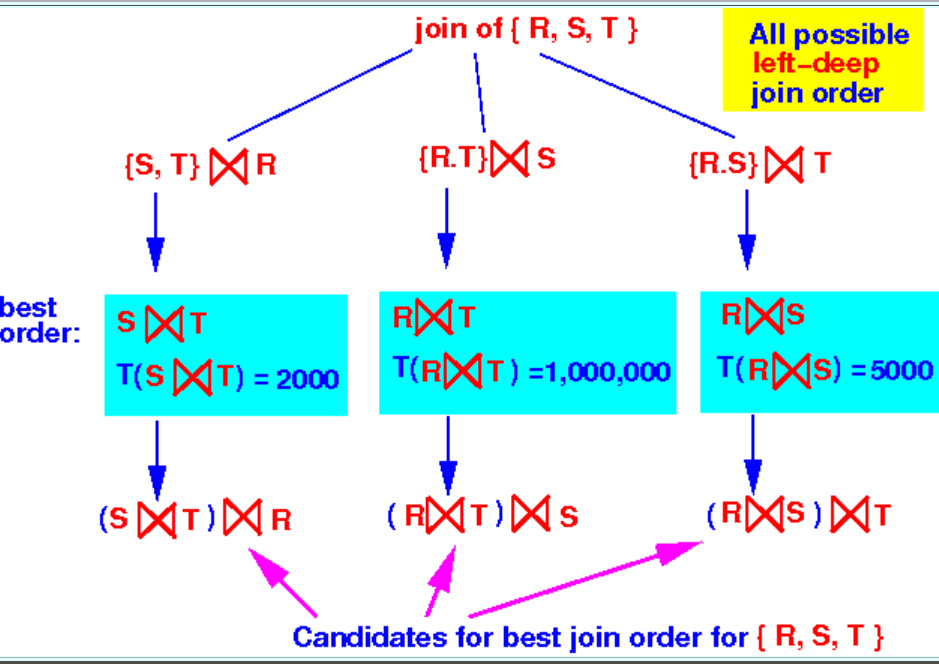
因为 T(S ⋈ T) = 2000, 因此 {S, T} ⋈ R 即为 s=R, S, T 的最优顺序。
将length(s)=3的四种情况依次计算,再求得四个关系相连接的最优顺序。
动态规划算法的缺点
- 缺乏扩展性:当需要加入新的join方法时,需要修改大量代码。如果增加新的operator,比如aggregation,那么修改就更加困难。
- 对Join顺序优化的问题非常适合,但是却不容易适用其他的优化方法,比如对GroupBy或者Union的优化。
动态规划的主要意义还是寻找次优的连接顺序,并且其搜索空间依然很大,需要\(O(n*2^{n-1})\),当表的数量为两位数时依然需要较长时间来响应。
参考
Database | 浅谈Query Optimization (2)的更多相关文章
- Database | 浅谈Query Optimization (1)
综述 由于SQL是声明式语言(declarative),用户只告诉了DBMS想要获取什么,但没有指出如何计算.因此,DBMS需要将SQL语句转换成可执行的查询计划(Query Plan).但是对同样的 ...
- 手撸ORM浅谈ORM框架之Query篇
快速传送 手撸ORM浅谈ORM框架之基础篇 手撸ORM浅谈ORM框架之Add篇 手撸ORM浅谈ORM框架之Update篇 手撸ORM浅谈ORM框架之Delete篇 手撸ORM浅谈ORM框架之Query ...
- CMU Database Systems - Query Optimization
查询优化应该是数据库领域最难的topic 当前查询优化,主要有两种思路, Rules-based,基于先验知识,用if-else把优化逻辑写死 Cost-based,试图去评估各个查询计划的cost, ...
- 浅谈php生成静态页面
一.引 言 在速度上,静态页面要比动态页面的比方php快很多,这是毫无疑问的,但是由于静态页面的灵活性较差,如果不借助数据库或其他的设备保存相关信息的话,整体的管理上比较繁琐,比方修改编辑.比方阅读权 ...
- 浅谈一下SSI+Oracle框架的整合搭建
浅谈一下SSI+Oracle框架的整合搭建 最近换了一家公司,公司几乎所有的项目都采用的是Struts2+Spring+Ibatis+Oracle的架构,上一个东家一般用的就是JSF+Spring,所 ...
- MYSQL优化浅谈,工具及优化点介绍,mysqldumpslow,pt-query-digest,explain等
MYSQL优化浅谈 msyql是开发常用的关系型数据库,快速.稳定.开源等优点就不说了. 个人认为,项目上线,标志着一个项目真正的开始.从运维,到反馈,到再分析,再版本迭代,再优化… 这是一个漫长且考 ...
- 【转】.NET(C#):浅谈程序集清单资源和RESX资源 关于单元测试的思考--Asp.Net Core单元测试最佳实践 封装自己的dapper lambda扩展-设计篇 编写自己的dapper lambda扩展-使用篇 正确理解CAP定理 Quartz.NET的使用(附源码) 整理自己的.net工具库 GC的前世与今生 Visual Studio Package 插件开发之自动生
[转].NET(C#):浅谈程序集清单资源和RESX资源 目录 程序集清单资源 RESX资源文件 使用ResourceReader和ResourceSet解析二进制资源文件 使用ResourceM ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- 手撸ORM浅谈ORM框架之基础篇
好奇害死猫 一直觉得ORM框架好用.功能强大集众多优点于一身,当然ORM并非完美无缺,任何事物优缺点并存!我曾一度认为以为使用了ORM框架根本不需要关注Sql语句如何执行的,更不用关心优化的问题!!! ...
随机推荐
- nvm install node error
nvm install node error ➜ mini-program-all git:(master) nvm install 10.15.3 Downloading and installin ...
- 灰度发布 & A/B 测试
灰度发布 & A/B 测试 http://www.woshipm.com/pmd/573429.html 8 https://testerhome.com/topics/15746 scree ...
- js & disabled right click & disabled right menu
js & disabled right click (() => { const log = console.log; log(`disabled copy`); document.bo ...
- WebAssembly JavaScript APIs
WebAssembly JavaScript APIs https://developer.mozilla.org/en-US/docs/WebAssembly/Using_the_JavaScrip ...
- 法兰西金融专访SPC空投重磅来袭
最近,法兰西金融日报联合德意志财经等知名金融媒体就SPC这一话题进行了专访. 法兰西金融日报记者德维尔斯问到,之前2020年的BGV项目等市场反响异常火爆,2021年已经来到,NGK目前有何新的大动作 ...
- ViewPager 高度自适应
public class ContentViewPager extends ViewPager { public ContentViewPager(Context context) { super(c ...
- CentOS7系统重置root密码
https://blog.csdn.net/qq_42969074/article/details/88080821
- 微信小程序弹出层
1.消息提示 wx.showToast wx.showToast({ title: '成功', icon: 'success', duration: 2000 })2.模态弹窗 wx.show ...
- 【产品设计】linux产品设计总结笔记
Linux 预研产品设计 产品的目的: 1.综合集团内部重复性开发的工作,将多种操作系统统一到科东统一负责 2.明确技术在哪些设备上是可行的,再去拓展.一开始不做平台化产品 3.软件规划需要结合硬 ...
- 剑指 Offer 44. 数字序列中某一位的数字 + 找规律 + 数位
剑指 Offer 44. 数字序列中某一位的数字 Offer_44 题目描述 题解分析 java代码 package com.walegarrett.offer; /** * @Author Wale ...