吴恩达《深度学习》-第一门课 (Neural Networks and Deep Learning)-第二周:(Basics of Neural Network programming)-课程笔记
第二周:神经网络的编程基础 (Basics of Neural Network programming)
2.1、二分类(Binary Classification)
二分类问题的目标就是习得一个分类器,它以图片的特征向量(RGB值的矩阵,最后延展成一维矩阵x,如下)作为输入,然后预测输出结果为 1 还是 0:
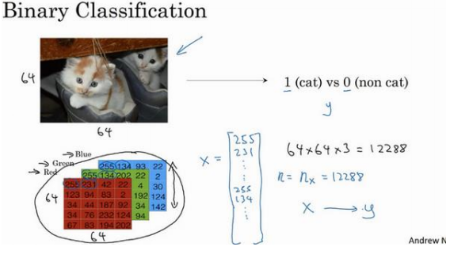
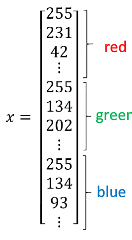
主要需要注意的是一些符号定义:
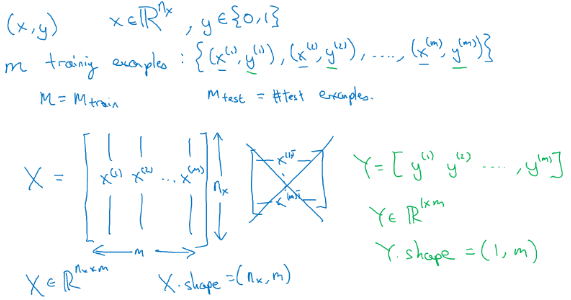
:表示一个维数据,为输入数据,维度为(, 1);
:表示输出结果,取值为(0,1);
( () , () ):表示第组数据,可能是训练数据,也可能是测试数据,此处默认为训练数 据;
= [ (1) , (2) , . . . , () ]:表示所有的训练数据集的输入值,放在一个 × 的矩阵中, 其中表示样本数目,输入神经网络时数据形状为 $ nx∗m:([x(1),x(2)⋯ x(m)]) $ 而非 \(m * nx:\left(\begin{matrix} x_{(1)}^T \\ x_{(2)}^T \\ \vdots\\ x_{(m)}^T \\ \end{matrix}\right)\)
= [ (1) , (2) , . . . , () ]:对应表示所有训练数据集的输出值,维度为1 × 。
python实现的时候:.shape 等于(, ),Y.shape 等于(1, )
2.2、 逻辑回归(Logistic Regression)
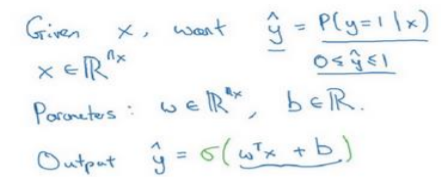
让\(\hat{y}\)表示实际值等于 1 的机率的话, \(\hat{y}\)应该在 0 到 1 之间。因为\(w^Tx +b\)可能比 1 要大得多,或者甚至为一个负值。因此在逻辑回归中,输出应该是\(\hat{y}\)等于由上面得到的线性函数式子\(w^Tx +b\)作为自变量的 sigmoid 函数中,将线性函数转换为非线性函数。
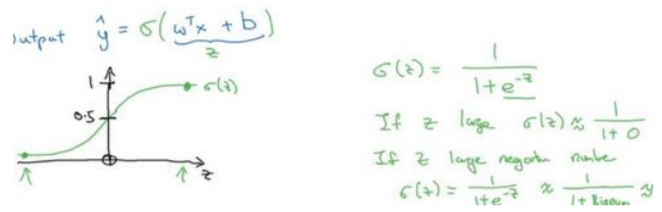
介绍一种符号惯例,可以让参数和参数分开 :
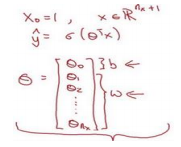
定义一个额外的特征称之为\(x_0\),并且使它等于 1,那么现在就是一 个+1 维的变量
这样\(\theta_0\)就充当了,这是一个实数,而剩下的\(\theta_1\) 直到\(\theta_{nx}\) 充当了\(w\)
2.3 逻辑回归的代价函数(Logistic Regression Cost Function)
训练代价函数来得到参数和参数b:
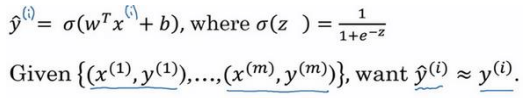
损失函数又叫做误差函数,Loss function:\(L(\hat{y},y)\).
逻辑回归中用到的损失函数是: \(L(\hat{y},y)=-(ylog(\hat{y}+(1-y)log(1-\hat{y}))\)
使用该Loss function 的理由:
当 = 1时损失函数\( = −log(\hat{y})\),如果想要损失函数尽可能得小,那么 \(\hat{y}\) 就要尽可能大, 因为 sigmoid 函数取值[0,1],所以 \(\hat{y}\) 会无限接近于 1。
当 = 0时损失函数 = −log(1 − \(\hat{y}\) ),如果想要损失函数尽可能得小,那么\(\hat{y}\) 就要尽可能小,因为 sigmoid 函数取值[0,1],所以\(\hat{y}\) 会无限接近于 0。
有很多的函数效果和现在这个类似,就是如果等于 1,我们就尽可能让 \(\hat{y}\) 变大,如果等于 0,我们就尽可能让 \(\hat{y}\) 变小。
损失函数是在单个训练样本中定义,它衡量的是算法在单个训练样本中表现。
衡量算法在全部训练样本上的表现,需要定义一个算法的代价函数(Cost function):对个样本的损失函数求和然后除以:
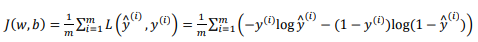
在训练逻辑回归模型时候,需要找到合适的和,来让代价函数 的总代价降到最低。
逻辑回归可以看做是一个非常小的神经网络。
2.4 梯度下降法(Gradient Descent)
梯度下降法(仅有一个参数)
-
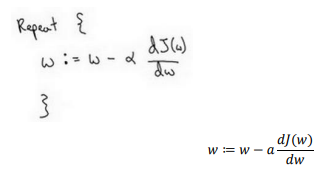
- =表示更新参数.
表示学习率(learning rate),用来控制步长(step).
\(\frac{()}{}\)就 是函数()对 求导(derivative) 对于导数更加形象化的理解就是斜率(slope).
逻辑回归的代价函数(成本函数)(, )是含有两个参数的:
在代码中使用 表示 \(\frac{\partial J(w,b)}{\partial w}\), 使用 \(db\) 表示\(\frac{\partial J(w,b)}{\partial b}\)
2.5 导数(Derivatives)
超简单导数讲解,没什么笔记。
2.6 更多的导数例子(More Derivative Examples)
一些基础函数的导数讲解。
2.7 计算图(Computation Graph)
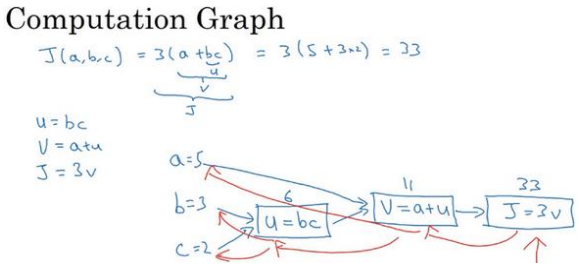
神经网络的计算,都是按照前向或反向传播过程组织的:
首先我们计算出一个新的网络的输出(前向过程),紧接着进行一个反向传输操作。后者我们用来计算出对应的梯度或导数。
计算图解释了为什么我们用这种方式组织这些计算过程,计算图组织计算的形式是用蓝色箭头从左到右的计算。
2.8 使用计算图求导数(Derivatives with a Computation Graph)

主要使用的是求导中的链式法则:
这是一个计算流程图,就是正向或者说从左到右的计算来计算成本函数,然后反向从右到左计算导数。
2.9 逻辑回归中的梯度下降(Logistic Regression Gradient Descent)

和的修正量,\(a\)为学习率:
微积分得到:
现在进行最后一步反向推导:

\(dw_1\)表示\(\frac{\partial L}{\partial w_1}\),\(dw_2\)表示\(\frac{\partial L}{\partial w_2}\),\(db=dz\)。
然后: 更新\(_1 = _1 − _1\), 更新\(_2 = _2 − _2\), 更新\( = − \)。

2.10 m 个样本的梯度下降(Gradient Descent on m Examples)
损失函数(, )的定义:
现在带有求和的全局代价函数,实际上是 1 到项各个损失的平均。 它表明全局代价函数对1的微分,对1的微分也同样是各项损失对1微分的平均。

代码流程:
初始化:J=0;dw1=0;dw2=0;db=0;
for i = 1 to m
z(i) = wx(i)+b;
a(i) = sigmoid(z(i));
J += -[y(i)log(a(i))+(1-y(i))log(1-a(i));
dz(i) = a(i)-y(i);
dw1 += x1(i)dz(i);
dw2 += x2(i)dz(i);
db += dz(i); J/= m;
dw1/= m;
dw2/= m;
db/= m;
J/= m;
dw1/= m;
dw2/= m;
db/= m;
w=w-alpha*dw
b=b-alpha*db
这种计算中有两个缺点:
需要编写两个 for 循环。 第一个 for 循环是一个小循环遍历个训练样本,第二个 for 循环是一个遍历所有特征的 for 循环。这个例子中只有 2 个特征,所以等于 2 并且 等于 2。 但如果有更多特征, 需要一 个 for 循环遍历所有个特征。
向量化技术:可以允 许代码摆脱这些显式的 for 循环。
2.11 向量化(Vectorization)

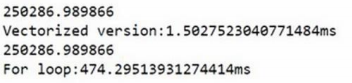
矩阵向量的加减,主要突出:采用numpy库函数进行向量的运算速度比使用for循环快超级多!
import numpy as np #导入 numpy 库
a = np.random.rand(1000000)
b = np.random.rand(1000000) #通过 round 随机得到两个一百万维度的数组
c = np.dot(a,b)#向量相加
for i in range(1000000):#采用for循环
c += a[i]*b[i]
运行时间对比:
2.12 向量化的更多例子(More Examples of Vectorization)
矩阵乘法$ u=Av $:
向量化方式就可以用 = . (, ),消除了两层循环使得代码运行速度更快。
主要就是用numpy进行矩阵的运算。
2.13 向量化逻辑回归(Vectorizing Logistic Regression)
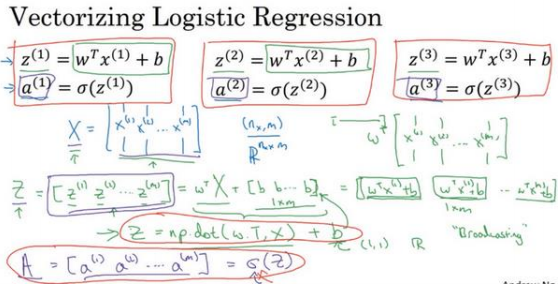
用numpy库的计算表示logistic regression。
2.14 向量化 logistic 回归的梯度输出(Vectorizing Logistic Regression's Gradient)
2.13中虽然去掉了一个for循环:针对w、d等参数的,但仍有一个遍历训练集的循环:
但计算 仍然需要一个循环遍历训练集,所以就用一个np.sum函数来快速替代就好了。
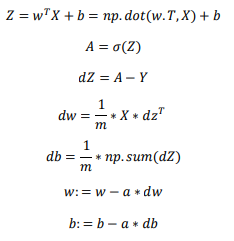
2.15 Python 中的广播(Broadcasting in Python)
broadcasting可以这样理解:如果你有一个mn的矩阵,让它加减乘除一个1n的矩阵,它会被复制m次,成为一个mn的矩阵,然后再逐元素地进行加减乘除操作。同样地对m1的矩阵成立:

2.16 关于 python _ numpy 向量的说明(A note on python or numpy vectors)
Python 语言巨大的灵活性也是缺点,由于广播巨大的灵活性,有时候可能会产生很细微或者看起来很奇怪的 bug。例如,将一个列向量添加到一个行向量中,会以为它报出维度不匹配或类型错误之类的错误,但是实际上会得到一个行向量和列向量的求和。
是如果对 Python 不熟悉的话,就可能会非常生硬、非常艰难地去寻找 bug。
置 = . . (5)此时 的 shape(形 状)是一个(5, )的结构。这在 Python 中被称作一个一维数组。相反,如果你设置 为(5,1),那么这就将置于 5 行 1 列向量中。
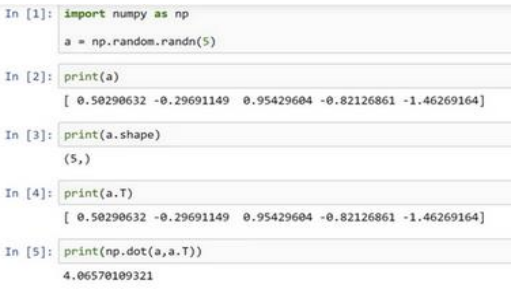

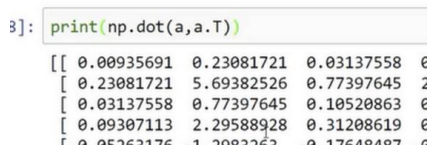
要去简化你的代码,而且不要使用一维数组。总是使用 × 1 维矩阵(基本上是列向量),或者 1 × 维矩阵(基本上是行向量)
2.17 Jupyter/iPython Notebooks 快速入门(Quick tour of Jupyter/iPython Notebooks)
jupyter介绍,没什么好说的。
2.18 (选修)logistic 损失函数的解释(Explanation of logistic regression cost function)
约定 \(\hat{} = ( = 1|)\) ,即算法的输出\(\hat{}\)是 给定训练样本 条件下 等于 1 的概率。 换句话说,如果 = 1,在给定训练样本 条件下y = \(\hat{}\); 反过来说,如果 = 0,在给定训练样本条件下 ( = 1 − \(\hat{}\)), 因此,如果 \(\hat{}\) 代表 = 1 的概率,那么1 − \(\hat{}\)就是 = 0的概率。 接下来,我们就来分析这两个条件概率公式。
可以将这两个公式合并成一个公式。需要指出的是我们讨论的是二分类问题的损失函 数,因此,的取值只能是 0 或者 1:
第一种情况:\(y=1 \quad (|) = \hat{y}\)
第二种情况:$y=0\quad p(y|x)=1\times(1-\hat{y})^{1-y} $
由于 log 函数是严格单调递增的函数,最大化 ((|)) 等价于最大化 (|) 通过对数 函数化简为:
吴恩达《深度学习》-第一门课 (Neural Networks and Deep Learning)-第二周:(Basics of Neural Network programming)-课程笔记的更多相关文章
- 吴恩达深度学习第2课第2周编程作业 的坑(Optimization Methods)
我python2.7, 做吴恩达深度学习第2课第2周编程作业 Optimization Methods 时有2个坑: 第一坑 需将辅助文件 opt_utils.py 的 nitialize_param ...
- 吴恩达深度学习第4课第3周编程作业 + PIL + Python3 + Anaconda环境 + Ubuntu + 导入PIL报错的解决
问题描述: 做吴恩达深度学习第4课第3周编程作业时导入PIL包报错. 我的环境: 已经安装了Tensorflow GPU 版本 Python3 Anaconda 解决办法: 安装pillow模块,而不 ...
- 吴恩达深度学习第1课第4周-任意层人工神经网络(Artificial Neural Network,即ANN)(向量化)手写推导过程(我觉得已经很详细了)
学习了吴恩达老师深度学习工程师第一门课,受益匪浅,尤其是吴老师所用的符号系统,准确且易区分. 遵循吴老师的符号系统,我对任意层神经网络模型进行了详细的推导,形成笔记. 有人说推导任意层MLP很容易,我 ...
- cousera 吴恩达 深度学习 第一课 第二周 作业 过拟合的表现
上图是课上的编程作业运行10000次迭代后,输出每一百次迭代 训练准确度和测试准确度的走势图,可以看到在600代左右测试准确度为最大的,74%左右, 然后掉到70%左右,再掉到68%左右,然后升到70 ...
- 吴恩达深度学习第2课第3周编程作业 的坑(Tensorflow+Tutorial)
可能因为Andrew Ng用的是python3,而我是python2.7的缘故,我发现了坑.如下: 在辅助文件tf_utils.py中的random_mini_batches(X, Y, mini_b ...
- 吴恩达深度学习第1课第3周编程作业记录(2分类1隐层nn)
2分类1隐层nn, 作业默认设置: 1个输出单元, sigmoid激活函数. (因为二分类); 4个隐层单元, tanh激活函数. (除作为输出单元且为二分类任务外, 几乎不选用 sigmoid 做激 ...
- 【Deeplearning.ai 】吴恩达深度学习笔记及课后作业目录
吴恩达深度学习课程的课堂笔记以及课后作业 代码下载:https://github.com/douzujun/Deep-Learning-Coursera 吴恩达推荐笔记:https://mp.weix ...
- 吴恩达深度学习 反向传播(Back Propagation)公式推导技巧
由于之前看的深度学习的知识都比较零散,补一下吴老师的课程希望能对这块有一个比较完整的认识.课程分为5个部分(粗体部分为已经看过的): 神经网络和深度学习 改善深层神经网络:超参数调试.正则化以及优化 ...
- 深度学习 吴恩达深度学习课程2第三周 tensorflow实践 参数初始化的影响
博主 撸的 该节 代码 地址 :https://github.com/LemonTree1994/machine-learning/blob/master/%E5%90%B4%E6%81%A9%E8 ...
随机推荐
- 基于Prometheus和Grafana打造业务监控看板
前言 业务监控对许许多多的场景都是十分有意义,业务监控看板可以让我们比较直观的看到当前业务的实时情况,然后运营人员可以根据这些情况及时对业务进行调整操作,避免业务出现大问题. 老黄曾经遇到过一次比较尴 ...
- 如何在 asp.net core 的中间件中返回具体的页面
前言 在 asp.net core 中,存在着中间件这一概念,在中间件中,我们可以比过滤器更早的介入到 http 请求管道,从而实现对每一次的 http 请求.响应做切面处理,从而实现一些特殊的功能 ...
- idea Maven项目 包下载不下来或者已经下载了就是飘红
0.先在settings.xml加上阿里的镜像在刷新试试 <mirror> <id>aliyunmaven</id> <mirrorOf>*</m ...
- RPC 框架通俗解释 转自知乎(洪春涛)
本地过程调用 RPC就是要像调用本地的函数一样去调远程函数.在研究RPC前,我们先看看本地调用是怎么调的.假设我们要调用函数Multiply来计算lvalue * rvalue的结果: 那么在第8行时 ...
- VyOS软路由系统基本设置
1. VyOS简介 VyOS是一个开源的网络操作系统,可以安装在物理硬件上,也可以安装在你自己的虚拟机上,或者是一个云平台上.它基于GNU/Linux,并加入了多个应用程序,如:Quagga, ISC ...
- 匹配对象方法:group() 与 groups()
当在处理正则表达式的时候,除了正则表达式对象之外,还有另一个对象类型:匹配对象,即是成功调用match()或者search()所返回的对象. 匹配对象有两个主要方法:group() 和 groups( ...
- 使用grub2引导进入Linux或Window系统
很多人在一通烂搞之后把自己的grub搞崩了(比如我当时手贱删除了boot分区)虽然后来又装了grub,但是进入grub后还是没有引导,只有一个孤零零的命令行界面 这时候应该怎么办呢?首先当然是想进入系 ...
- 构建docker私有仓库+k8s-pod应用
环境版本系统:centos7.4docker-compose version 1.26.2docker-py version: 4.3.0CPython version: 2.7.5docker-ve ...
- Labview学习之路(八)如何让控件显示在修饰符的前面
在Labview2017版本中,前面板选择修饰控件,会出现部分修饰控件会掩盖其他控件,情况如下: 我们右键点击和属性中都没有相关属性的改变,为什么是这样我也不清除: 上网查了一下,看到其他版本会有显示 ...
- unity 真机调试
[Unity3D]Android和ios真机调试测Profiler http://blog.csdn.net/swj524152416/article/details/53466413 Unity5. ...