4 IDEA环境应用
第4章 IDEA环境应用
spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包的依赖。
4.1 在IDEA中编写WordCount程序
1)创建一个Maven项目WordCount并导入依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<finalName>WordCount</finalName>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<archive>
<manifest>
<mainClass>WordCount(修改)</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2)编写代码
package com.atguigu
import org.apache.spark.{SparkConf, SparkContext}
object WordCount{
def main(args: Array[String]): Unit = {
//创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("WC")
//创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//使用sc创建RDD并执行相应的transformation和action
sc.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_, 1).sortBy(_._2, false).saveAsTextFile(args(1))
sc.stop()
}
}
3)打包到集群测试
bin/spark-submit \ --class WordCount \ --master spark://hadoop102:7077 \ WordCount.jar \ /word.txt \ /out
4.2 本地调试
本地Spark程序调试需要使用local提交模式,即将本机当做运行环境,Master和Worker都为本机。运行时直接加断点调试即可。如下:
创建SparkConf的时候设置额外属性,表明本地执行:
val conf = new SparkConf().setAppName("WC").setMaster("local[*]")
如果本机操作系统是windows,如果在程序中使用了hadoop相关的东西,比如写入文件到HDFS,则会遇到如下异常:
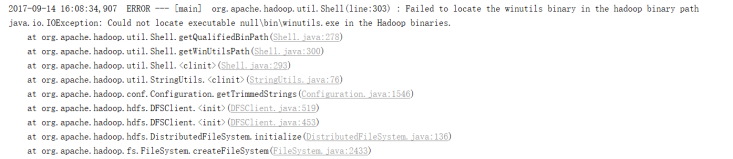
出现这个问题的原因,并不是程序的错误,而是用到了hadoop相关的服务,解决办法是将附加里面的hadoop-common-bin-2.7.3-x64.zip解压到任意目录。

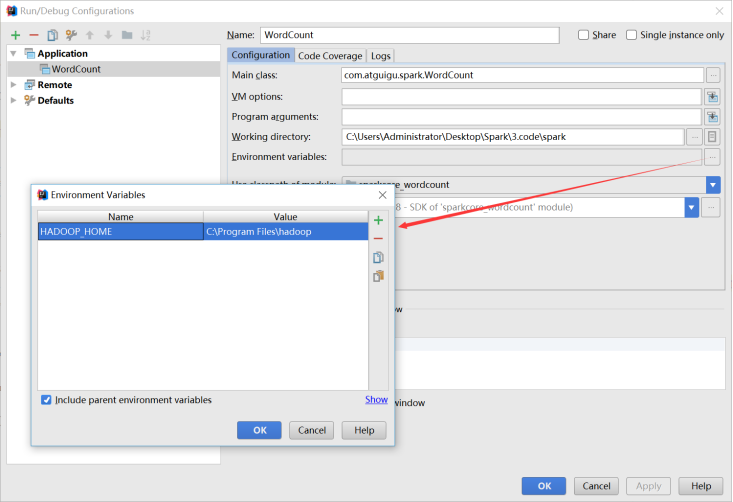
在IDEA中配置Run Configuration,添加HADOOP_HOME变量
4.3 远程调试
通过IDEA进行远程调试,主要是将IDEA作为Driver来提交应用程序,配置过程如下:
修改sparkConf,添加最终需要运行的Jar包、Driver程序的地址,并设置Master的提交地址:
val conf = new SparkConf().setAppName("WC")
.setMaster("spark://hadoop102:7077")
.setJars(List("E:\\SparkIDEA\\spark_test\\target\\WordCount.jar"))
然后加入断点,直接调试即可:
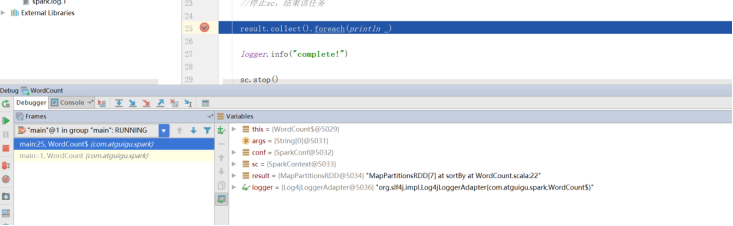
本地直接运行
package com.briup.core
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//1 获取配置SparkConf
// spark-submit master name 在命令行里设置
// 右键运行 master name 代码配置
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dzy_wordCount")
//2 SparkContext
val sc= new SparkContext(conf)
//3 RDD
val lines = sc.textFile("file:///opt/software/spark/README.md")
//4 执行操作 flatten
// Mapper ----> shuffle ---->Reducer
val rdd1 = lines.flatMap(_.split(" "))
.groupBy(x => x)
.mapValues(x => x.size)
//* 序列化执行结果
rdd1.foreach(println)
rdd1.saveAsTextFile("file:///home/dengzhiyong/Documents/IDEA_workspace/IdeaProjects/ECJTU_Spack_Ecosphere/Spark/src/main/scala/com/briup/core/result")
//5 关闭sc
sc.stop()
}
}
4 IDEA环境应用的更多相关文章
- 配置android sdk 环境
1:下载adnroid sdk安装包 官方下载地址无法打开,没有vpn,使用下面这个地址下载,地址:http://www.android-studio.org/
- Angular2入门系列教程1-使用Angular-cli搭建Angular2开发环境
一直在学Angular2,百忙之中抽点时间来写个简单的教程. 2016年是前端飞速发展的一年,前端越来越形成了(web component)组件化的编程模式:以前Jquery通吃一切的田园时代一去不复 ...
- 构建一个基本的前端自动化开发环境 —— 基于 Gulp 的前端集成解决方案(四)
通过前面几节的准备工作,对于 npm / node / gulp 应该已经有了基本的认识,本节主要介绍如何构建一个基本的前端自动化开发环境. 下面将逐步构建一个可以自动编译 sass 文件.压缩 ja ...
- win10 环境 gitbash 显示中文乱码问题处理
gitbash 是 windows 环境下非常好用的命令行终端,可以模拟一下linux下的命令如ls / mkdir 等等,如果使用过程中遇到中文显示不完整或乱码的情况,多半是因为编码问题导致的,修改 ...
- Javascript 的执行环境(execution context)和作用域(scope)及垃圾回收
执行环境有全局执行环境和函数执行环境之分,每次进入一个新执行环境,都会创建一个搜索变量和函数的作用域链.函数的局部环境不仅有权访问函数作用于中的变量,而且可以访问其外部环境,直到全局环境.全局执行环境 ...
- 总结:Mac前端开发环境的搭建(配置)
新年新气象,在2016年的第一天,我入手了人生中第一台自己的电脑(大一时好友赠送的电脑在一次无意中烧坏了主板,此后便不断借用别人的或者网站的).macbook air,身上已无分文...接下来半年的房 ...
- Android Studio 多个编译环境配置 多渠道打包 APK输出配置
看完这篇你学到什么: 熟悉gradle的构建配置 熟悉代码构建环境的目录结构,你知道的不仅仅是只有src/main 开发.生成环境等等环境可以任意切换打包 多渠道打包 APK输出文件配置 需求 一般我 ...
- [APUE]UNIX进程的环境(下)
一.共享库 共享库使得可执行文件中不再需要包含常用的库函数,而只需在所有进程都可存取的存储区中保存这种库例程的一个副本.程序第一次执行的时候或第一次调用某个库函数的时候,用动态链接方法将程序与共享库函 ...
- Jexus 5.8.2 正式发布为Asp.Net Core进入生产环境提供平台支持
Jexus 是一款运行于 Linux 平台,以支持 ASP.NET.PHP 为特色的集高安全性和高性能为一体的 WEB 服务器和反向代理服务器.最新版 5.8.2 已经发布,有如下更新: 1,现在大 ...
- .NET Core系列 : 1、.NET Core 环境搭建和命令行CLI入门
2016年6月27日.NET Core & ASP.NET Core 1.0在Redhat峰会上正式发布,社区里涌现了很多文章,我也计划写个系列文章,原因是.NET Core的入门门槛相当高, ...
随机推荐
- Asp.net Core 3.1基于AspectCore实现AOP,实现事务、缓存拦截器
最近想给我的框架加一种功能,就是比如给一个方法加一个事务的特性Attribute,那这个方法就会启用事务处理.给一个方法加一个缓存特性,那这个方法就会进行缓存. 这个也是网上说的面向切面编程AOP. ...
- NACOS安装和配置
安装包nacos-server-1.1.4.tar.gz 环境 JDK1.8 上传及解压 [root@centos7- ~ ]# mkdir -p /cslc/nacos #通过SFTP将安装包上传至 ...
- Dom运用2
1.登录系统 <!--输入框创建--> 账号:<input class="ipt" type="text"><br> 密码: ...
- vue“欺骗”ueditor,实现图片上传
一.环境介绍 @vue/cli 4.3.1 webpack 4.43.0 ueditor1.4.3.3 jsp版 二.springboot集成ueditor,实现分布式图片上传 参考我的另一篇博客,& ...
- python绝技:运用python成为顶级黑客|中文pdf完整版[42MB|网盘地址附提取码自行提取|
Python 是一门常用的编程语言,它不仅上手容易,而且还拥有丰富的支持库.对经常需要针对自己所 处的特定场景编写专用工具的黑客.计算机犯罪调查人员.渗透测试师和安全工程师来说,Python 的这些 ...
- Upload 上传 el-upload 上传配置请求头为Content-Type: "multipart/form-data"
api接口处添加属性 (标红处) // 校验台账 export const checkEquiment = (data) => { return axios({ url: '/job/equip ...
- HTML 基础- 4个实例
HTML 基础- 4个实例 不要担心本章中您还没有学过的例子,高佣联盟 www.cgewang.com 您将在下面的章节中学到它们. HTML 标题 HTML 标题(Heading)是通过<h1 ...
- Calibre LVS BOX 详细用法
https://www.cnblogs.com/yeungchie/ LVS BOX的使用对于后端的团队协作起到非常便利的作用. 通过在lvs rules file添加BOX的相关语句可以达到这个目的 ...
- Lambda表达式运行原理
目录 一.创建测试样例 二.利用Java命令编译分析 三.文末 JDK8引入了Lambda表达式以后,对我们写代码提供了很大的便利,那么Lambda表达式是如何运用简单表示来达到运行效果的呢?今天,我 ...
- linux的用户扩充权限管理acl和用户使用系统资源的限制
用户扩充权限管理 acl 1.扩充权限的方式 文件扩充权限 ACL 磁盘配额 2.文件扩充权限 1.安全位 安全位 ---set位 SUID SGID set仅可以加给 u.g, 如: ...