Group by 优化
一个标准的 Group by 语句包含排序、分组、聚合函数,比如 select a,count(*) from t group by a ; 这个语句默认使用 a 进行排序。如果 a 列没有索引,那么就会创建临时表来统计 a和 count(*),然后再通过 sort_buffer 按 a 进行排序。
标准的执行流程
结构:
create table t1(id int primary key, a int, b int, index(a));
delimiter ;;
create procedure idata()
begin
declare i int; set i=1;
while(i<=1000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
函数就是向 t1 中插入1000条语句,从(1,1,1) 到(1000,1000,1000)。
执行 select id%10 as m, count(*) as c from t1 group by m;
解析:

Using index,表示这个语句使用了覆盖索引,选择了索引 a,不需要回表;
Using temporary,表示使用了临时表;
Using filesort,表示需要排序。
过程:
1、创建内存临时表,表里有两个字段 m 和 c,主键是 m;
2、扫描表 t1 的索引 a,依次取出叶子节点上的 id 值,计算 id%10 的结果,记为 x;
1)如果临时表中没有主键为 x 的行,就插入一个记录 (x,1);
2)如果表中有主键为 x 的行,就将 x 这一行的 c 值加 1;
第2 步如果发现内存临时表存储的总字段长度到达参数 tmp_table_size 设置的大小,那么就会将内存临时表升级为磁盘临时表,然后重新开始遍历计算。
3、遍历完成后,再根据字段 m 做排序,得到结果集返回给客户端。
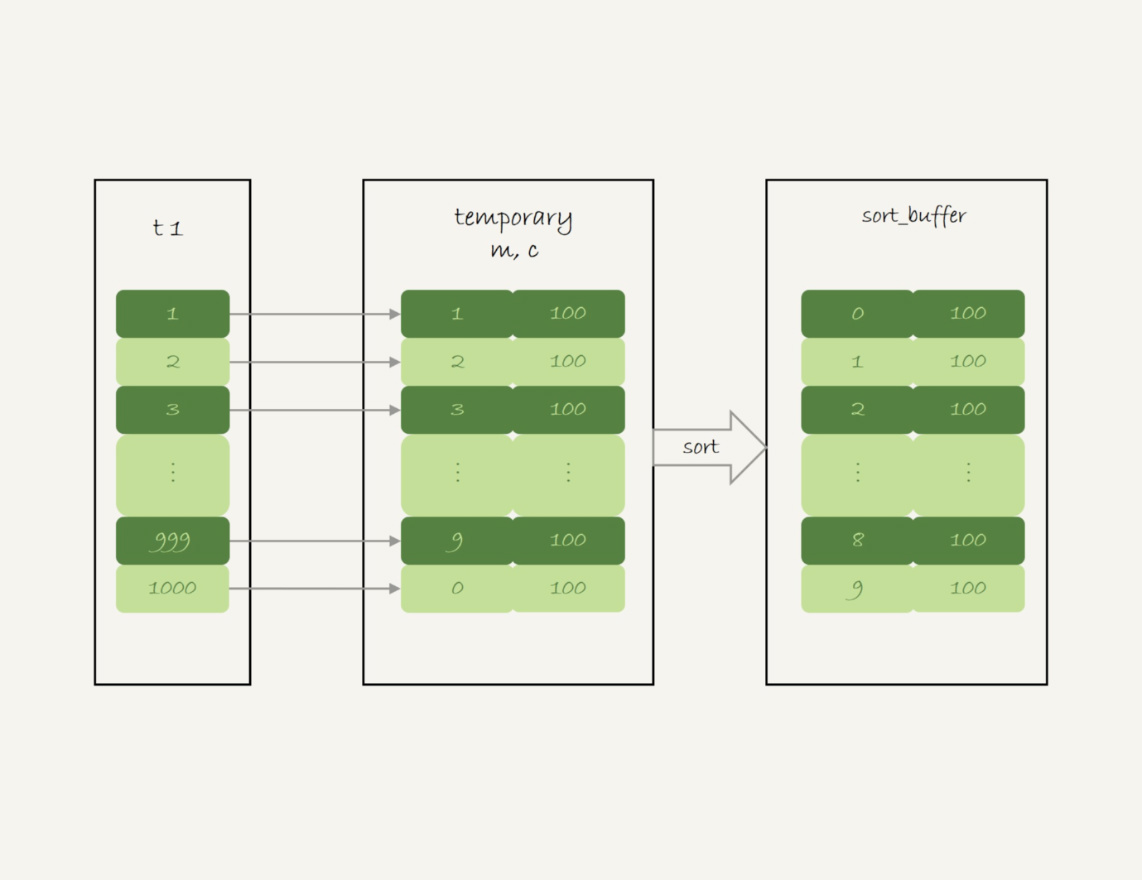
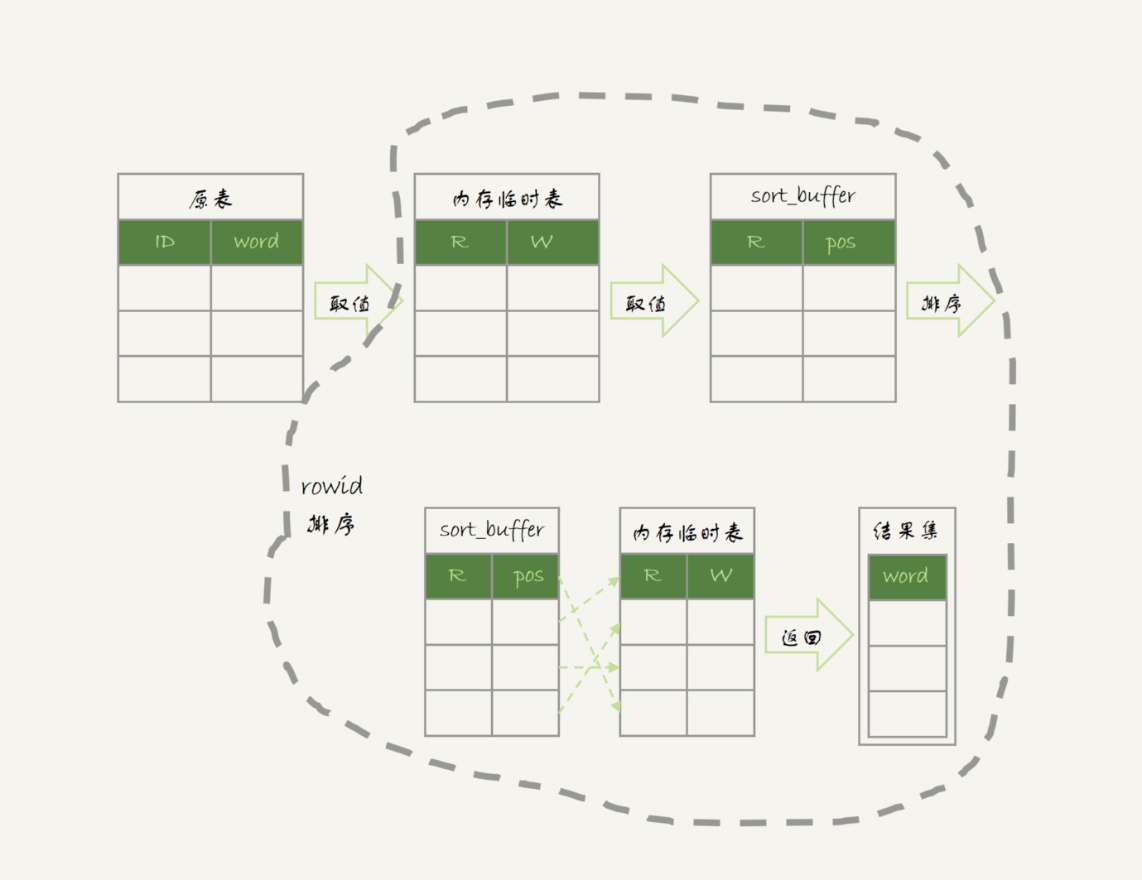
最后的排序就是下图虚线框中的操作,如果 sort_buffer 设置的大小不够大,那么就会使用临时表来辅助排序。
优化
未优化(也就是分组列没有索引)的 group by 的总过程可以概括为:因为数据是无序的,所以需要创建临时表,然后一个一个判断属于哪个分组,最后再根据分组列进行排序。所以,优化可以有两个思路:
去掉排序
在明确返回的数据不需要排序的情况下,可以禁止排序,也就是将上面的语句改成 select a,count(*) from t group by a order by null。
顺序排列
如果记录都按照排序字段排序,那么数据就变成了下面的结构:

这样在实际获取要返回的字段或计算聚合函数时,只需要按顺序依次访问,等到列值变成下一个就知道当前组访问结束,将之前统计的数据直接返回。这样就避免了创建临时表,同时排序也不需要使用 sort_buffer 进行额外排序。这样就极大地提高了执行的效率。
实现
1、如果分组字段适合创建索引就直接为分组字段创建索引。
MySQL 5.7 版本支持了 generated column 机制,用来实现列数据的关联更新。你可以用下面的方法创建一个列 z,然后在 z 列上创建一个索引(如果是 MySQL 5.6 及之前的版本,你也可以创建普通列和索引,来解决这个问题)
alter table t1 add column z int generated always as(id % 100), add index(z);
然后解析:

这时没有用到临时表和额外排序,所以性能提升。
2、如果分组字段不适合(使用率很低),那么可以使用 SQL_BIG_RESULT 来尝试优化。
在 group by 语句中加入 SQL_BIG_RESULT 这个提示(hint),就可以告诉优化器:这个语句涉及的数据量很大,请直接用磁盘临时表。MySQL 的优化器一看,磁盘临时表是 B+ 树存储,存储效率不如数组来得高。所以,既然使用SQL_BIG_RESULT来说明数据量很大,那从磁盘空间考虑,还是直接用数组来存吧。所以在使用 SQL_BIG_RESULT 后优化器会使用数组结构的磁盘临时表。
但是如果在未达到磁盘临时表的使用条件是不会使用磁盘临时表的,也就是在 sort_buffer 空间能够存储要返回和排序的总字段长度时,就使用数组结构的 sort_buffer ,如果总字段超过 sort_buffer 大小,那么就再加上数组结构的磁盘临时表来帮助排序。
那么在 sort_buffer 空间足够的情况下, sort_buffer 内部就会对数据进行排序,这样也就起到了索引的作用,
还是以上面的例子来看,使用 SQL_BIG_RESULT
alter table t1 add column z int generated always as(id % 100), add index(z);
具体过程如下:
1、初始化 sort_buffer,确定放入一个整型字段,记为 m;
2、扫描表 t1 的索引 a,依次取出里面的 id 值, 将 id%10 的值存入 sort_buffer 中;
3、扫描完成后,对 sort_buffer 的字段 m 做排序(如果 sort_buffer 内存不够用,就会利用磁盘临时文件辅助排序);
4、排序完成后,就得到了一个有序数组。
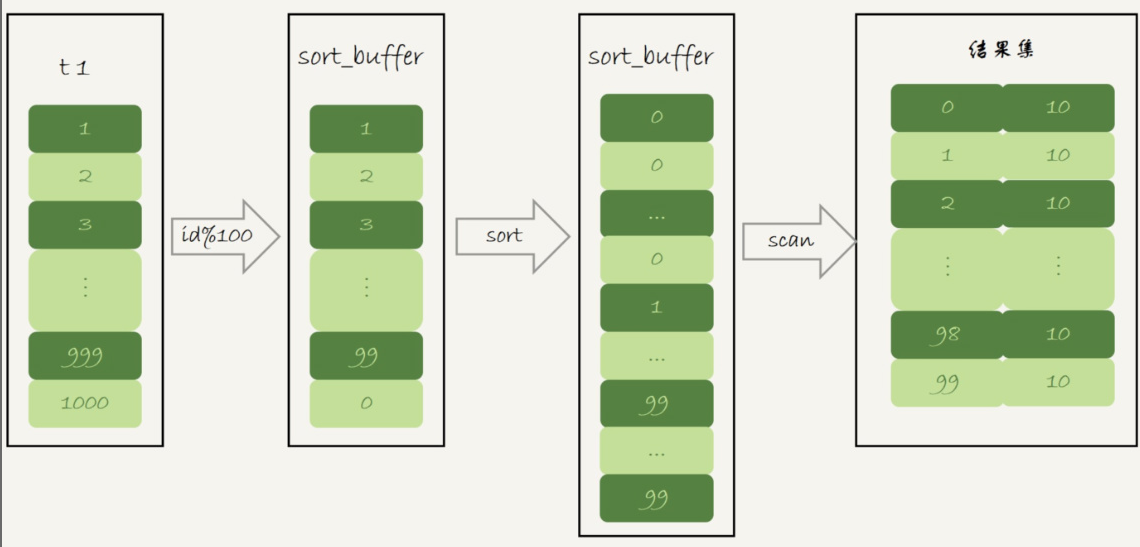
解析:

可以看到此时就没有使用临时表了,而是直接使用 sort_buffer 进行排序,这样就省去了使用临时表带来的性能消耗。
总结
1、如果对 group by 语句的结果没有排序要求,要在语句后面加 order by null;那么一般情况就不需要使用临时表了(上面两个优化都是在要求排序的前提下提出的优化方式)
2、尽量让 group by 过程用上表的索引,确认方法是 explain 结果里没有 Using temporary 和 Using filesort;
3、如果 group by 需要统计的数据量不大,尽量只使用内存临时表;也可以通过适当调大 tmp_table_size 参数,来避免用到磁盘临时表;
4、如果数据量实在太大,使用 SQL_BIG_RESULT 这个提示,来告诉优化器直接使用排序算法得到 group by 的结果。
Group by 优化的更多相关文章
- Mysql查询优化汇总 order by优化例子,group by优化例子,limit优化例子,优化建议
Mysql查询优化汇总 order by优化例子,group by优化例子,limit优化例子,优化建议 索引 索引是一种存储引擎快速查询记录的一种数据结构. 注意 MYSQL一次查询只能使用一个索引 ...
- Hive:表1inner join表2结果group by优化
问题背景 最近遇到一个比较棘手的事情:hive sql优化: lib表(id,h,soj,noj,sp,np) --一个字典表 mitem表(md,mt,soj,noj,sp,np)- ...
- 6.4 group by 优化
1.小总结 group by 实质是先排序后进行分组,遵照索引建的最佳左前缀. 当无法使用索引列,增大max_length_for_sort_data参数的设置 + 增大sort_buffer_siz ...
- MySQL高级 之 order by、group by 优化
参考: https://blog.csdn.net/wuseyukui/article/details/72627667 order by示例 示例数据: Case 1 Case 2 Case 3 ...
- mysql group by优化
mysql> explain select actor.first_name,actor.last_name,count(*) from sakila.film_actor inner join ...
- distinct用group by优化
当数据量非常大,在同一个query中计算多个不相关列的distinct时,往往很容易出现数据倾斜现象,导致运行半天都不能得到结果. 比如以下的SQL语句(a, b, c没有相关性): select d ...
- Mysql group by,order by,dinstict优化
1.order by优化 2.group by优化 3.Dinstinct 优化 1.order by优化 实现方式: 1. 根据索引字段排序,利用索引取出的数据已经是排好序的,直接返回给客户端: 2 ...
- ORDER BY,GROUP BY 和DI STI NCT 优化
读<MySQL性能调优与架构设计>笔记之ORDER BY,GROUP BY 和DI STI NCT 优化 2015年01月18日 18:51:31 lihuayong 阅读数:2593 标 ...
- [MySQL Reference Manual] 8 优化
8.优化 8.优化 8.1 优化概述 8.2 优化SQL语句 8.2.1 优化SELECT语句 8.2.1.1 SELECT语句的速度 8.2.1.2 WHERE子句优化 8.2.1.3 Range优 ...
随机推荐
- .net core 和 WPF 开发升讯威在线客服与营销系统:系统总体架构
本系列文章详细介绍使用 .net core 和 WPF 开发 升讯威在线客服与营销系统 的过程.本产品已经成熟稳定并投入商用. 在线演示环境:https://kf.shengxunwei.com 注意 ...
- 在.NET Core 中收集数据的几种方式
APM是一种应用性能监控工具,可以帮助理解系统行为, 用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题, 通过汇聚业务系统各处理环节的实时数据,分析业务系统各事务处理的交易路径和处理 ...
- Jenkins 持续集成实现 Android 自动化打包
打 debug 包流程: git pull 分支最新代码 Android Studio:Build - Generate Signed APK 从 IDE 里可以看到,实际上该操作是执行了 assem ...
- 使用@Cacheable注解时,Redis连不上,直接调用方法内部的解决方案
最近redis 域名一致解析错误,导致业务多了很多异常.那么如何在这种情况下直接访问数据库,而不是报错呢 1. 解决方案 其实很简单,在配置 redis 时,只需要多一项配置,继承 CachingCo ...
- 【探索之路】机器人篇(4)-根据3D文件来优化自己的机器人模型
此章节不是必须做的!!!! 因为我已经用solidworks画了机器人的3D模型,那我就直接导入已经画好的三维模型. 如果大家没有画也是可以直接使用上一章节我们已经构建的机器人模型.我这里只是一个对显 ...
- FPT: Feature Pyramid Transfomer
导言: 本文介绍了一个在空间和尺度上全活跃特征交互(fully active feature interaction across both space and scales)的特征金字塔transf ...
- 初始MQTT
初识 MQTT 物联网 (IoT) 设备必须连接互联网.通过连接到互联网,设备就能相互协作,以及与后端服务协同工作.互联网的基础网络协议是 TCP/IP.MQTT(消息队列遥测传输) 是基于 TC ...
- k8s之HTTP请求负载分发
一.导读 对于基于HTTP的服务来说,不同的URL地址经常对应不同的后端服务或者虚拟服务器,通常的做法是在应用前添加一个反向代理服务器Nginx,进行请求的负载转发,在Spring Cloud这个微服 ...
- VoltDB成功入选CNCF Landscape云原生数据库全景图
近日,VoltDB正式入选 CNCF Landscape(可能是目前其中唯一的关系型分布式内存数据库).此次VoltDB 进入 CNCF Landscape,意味着 VoltDB 正式成为了 CNCF ...
- [ABP教程]第七章 作者:数据库集成
Web开发教程7 作者:数据库集成 关于此教程 在这个教程系列中,你将要构建一个基于ABP框架的应用程序 Acme.BookStore.这个应用程序被用于甘丽图书页面机器作者.它将用以下开发技术: E ...