在.NET中使用Apache Kafka(一)
曾经在你的应用程序中使用过异步处理吗?在处理不需要立即执行的任务时,异步代码似乎是不可避免的。Apache Kafka是最常用和最健壮的开源事件流平台之一。许多公司和开发者利用它的强大功能来创建高性能的异步操作,用于微服务的数据集成,以及用于应用程序健康指标的监控工具。这篇文章解释了在.NET应用程序中使用Kafka的细节,还展示了如何在Windows操作系统上安装及使用。
它是如何工作的
当今世界,数据正在以指数形式增长。为了容纳不断增长的数据,Kafka这样的工具应运而生,提供了健壮而令人印象深刻的架构。
但是Kafka是如何在幕后工作的呢?
Kafka在生产者和消费者之间交换信息。生产者和消费者是这一线性过程的两个主要角色。
Kafka也可以在一个或多个服务器的集群中工作。这些服务器被称为Kafka代理,通过代理你可以受益于多种特性,例如数据复制、容错和高可用。
这些代理由另一个叫做Zookeeper的工具管理。总之,它是一种旨在保持分布式系统中同步和组织配置数据的服务。
Kafka Topics
Kafka只是一个代理,所有的行为都发生在这。生产者向世界发送消息,而消费者读取特定的数据块。如何区分数据的一个特定部分与其他部分?消费者如何知道要使用哪些数据?要理解这一点,你需要一个新的内容:topic。
Kafka topics是传递消息的载体。由生产者产生的Kafka记录被组织并存储到topic中。
假设你正在处理一个用于记载植物目录的API项目。你要确保公司中的每个人都能够访问每一个新注册的植物。所以你选了Kafka。
在系统中注册的每一个新植物都将通过Kafka进行广播。topic的名称是tree_catalog。
在这种情况下,topic像堆栈一样工作。它将信息保存在到达时的相同位置,并保证数据不会丢失。
到达的每个数据记录被存储在一个slot中,并用一个称为offset的唯一位置号注册。
例如,当一个消费者消费了存储在offset是0的消息时,它提交消息,声明一切正常,然后移动到下一个offset,依此类推。这个过程通常是线性的。然而,由于许多消费者可以同时将记录“插入”到同一个topic中,所以确定哪些数据位置已经被占用的责任留给了消费者。这意味着消费者可以决定使用消息的顺序,甚至决定是否从头开始重新开始处理(offset为0)。
分区
分布式系统的一个关键特性是数据复制。它允许一个更安全的体系结构,数据可以被复制到其他地方,以防不好的事情发生。Kafka通过分区处理复制。Kafka topics被配置为分散在几个分区(可配置的)。每个分区通过唯一的offset保存数据记录。
为了实现冗余,Kafka在分区(一个或多个)创建副本,并在集群中传播数据。
这个过程遵循leader-follower模型,其中一个leader副本总是处理给定分区的请求,而follower复制该分区。每次制作人将消息推送到某个主题时,它都会直接传递给该主题的领导者。
消费组
在Kafka中,消费来自topic的消息最合适的方式是通过消费组。
顾名思义,这些组由一个或多个消费者组成,目的是获取来自特定主题的所有消息。
为此,组必须始终具有唯一的id(由属性group.id设置)。无论何时消费者想要加入那个组,它都将通过组id来完成。
每次你添加或删除一个组的消费者,Kafka会重新平衡它们之间的负载,这样就不会过载。
设置
现在,你已经了解了Kafka的通用工作原理,是时候开始环境设置了。为了简化,这个例子将使用Docker来保存Kafka和Zookeeper映像,而不是将它们安装到你的机器上。这样可以节省一些空间和复杂性。
对于Windows用户,Docker提供了一种安装和管理Docker容器的简单方式:Docker桌面。进入它的下载页面并下载安装程序。运行它,并在不更改默认设置选项的情况下继续到最后。
![]()
确保在此过程完成后重新启动计算机。重启后,Docker可能会要求你安装其他依赖项,所以请确保接受每一个依赖项。在Docker上安装一个有效的Kafka本地环境最快的路径之一是通过Docker Compose。通过这种方式,可以通过一个YAML文件建立应用程序服务,并快速地让它们运行。
创建一个名为docker-compose的新文件,并将以下的内容保存到其中:
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_CREATE_TOPICS: "simpletalk_topic:1:1"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
注意,代码从Docker Hub的wurstmeister帐户中导入了两个服务镜像(kafka和zookeeper)。这是在Docker上使用Kafka最稳定的镜像之一。端口也使用它们的推荐值进行设置,因此请注意不要更改它们。
其中最重要的设置之一属于KAFKA_CREATE_TOPICS。在这里,你必须定义要创建的topic名称。还有其他方法可以创建主题,以后你将看到。
通过命令行导航到docker-compose.yml所在的文件夹。然后执行如下命令启动镜像:
docker-compose up
![]()
这段代码将加载所有依赖项并启动镜像。在此过程中,可能会看到大量的日志。
如果没有错误日志显示,说明启动成功。
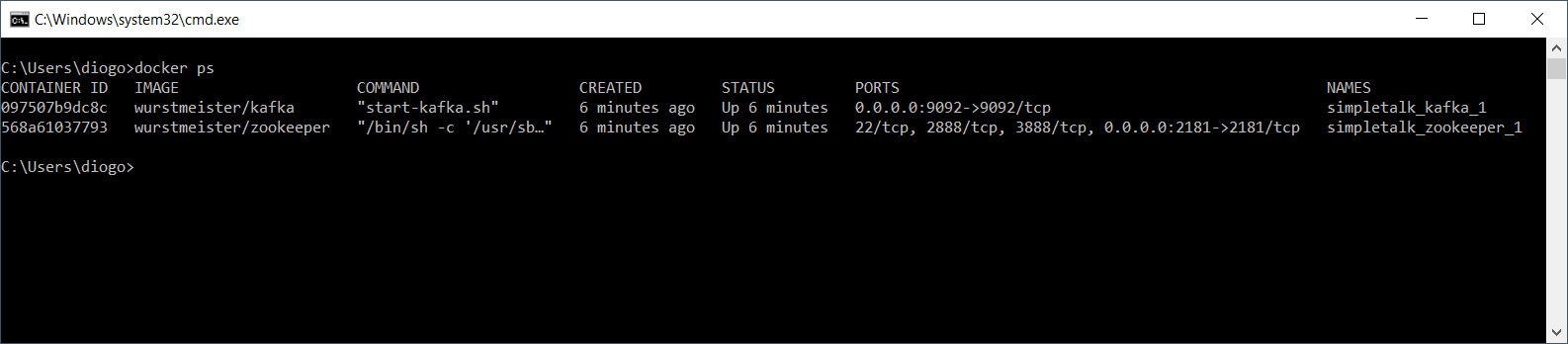
为了检查Docker镜像是否启动,在另一个cmd窗口中运行以下命令:
docker ps
![]()
显示如下:
亲自动手
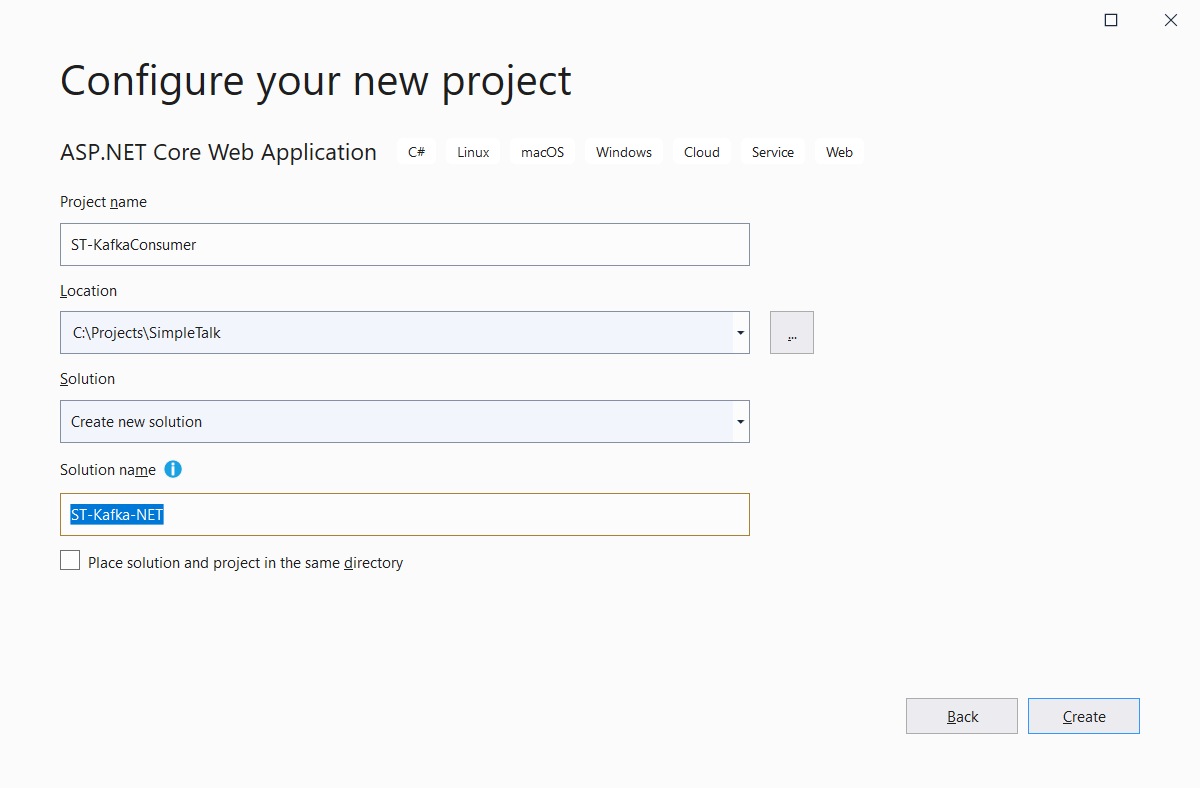
你的Kafka环境已经可以使用了。下一步是在Visual Studio中进行项目创建。进入项目创建窗口。搜索ASP.NET Core Web Application模板,单击Next。
解决方案新建一个名称消费者项目和生产者项目将在同一个解决方案中共存。
下一个窗口选择API模板。取消勾选“配置为HTTPS”选项。
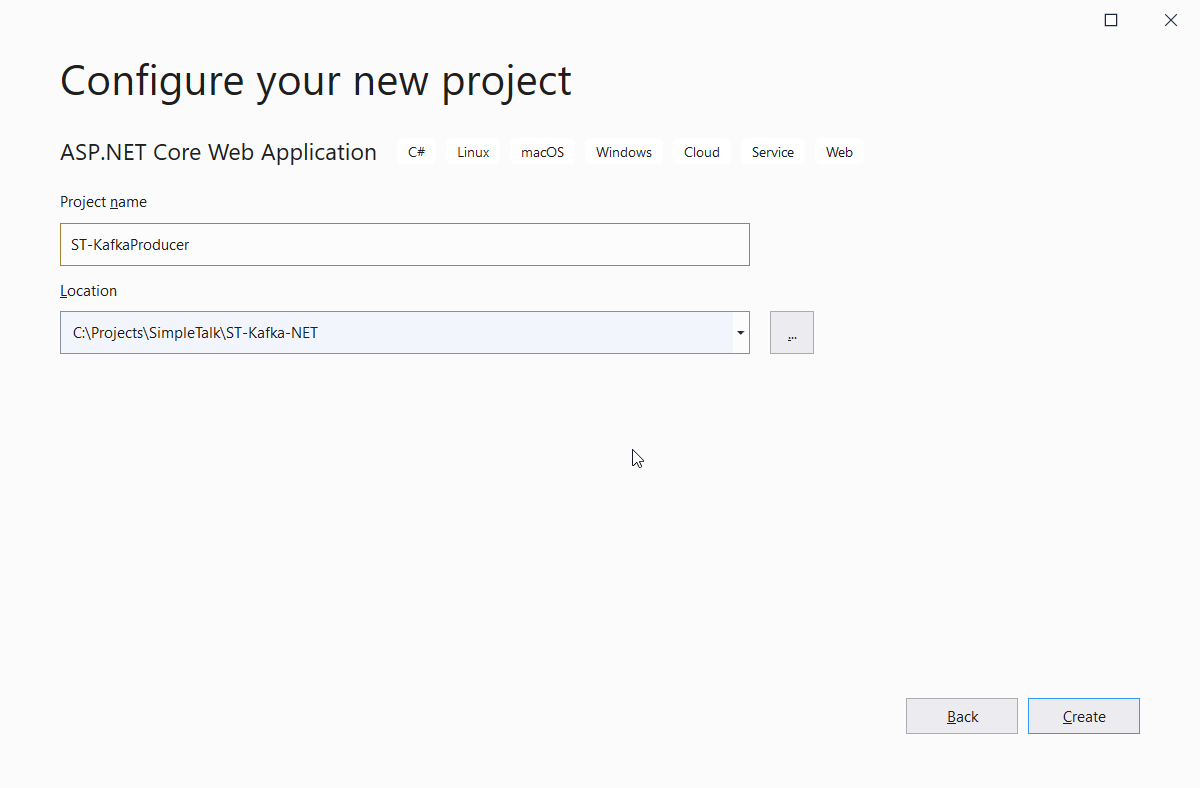
创建项目后,右键单击解决方案,选择添加新项目,然后,选择ASP.NET Core Web Application项目类型。
![]()
继续并像前面一样选择API模板。
![]()
现在,在ST-Kafka-NET解决方案中有两个项目。
NuGet包
为了让C#代码理解如何产生和消费消息,你需要一个Kafka的客户端。现在最常用的客户端是Confluent’s Kafka .NET Client。
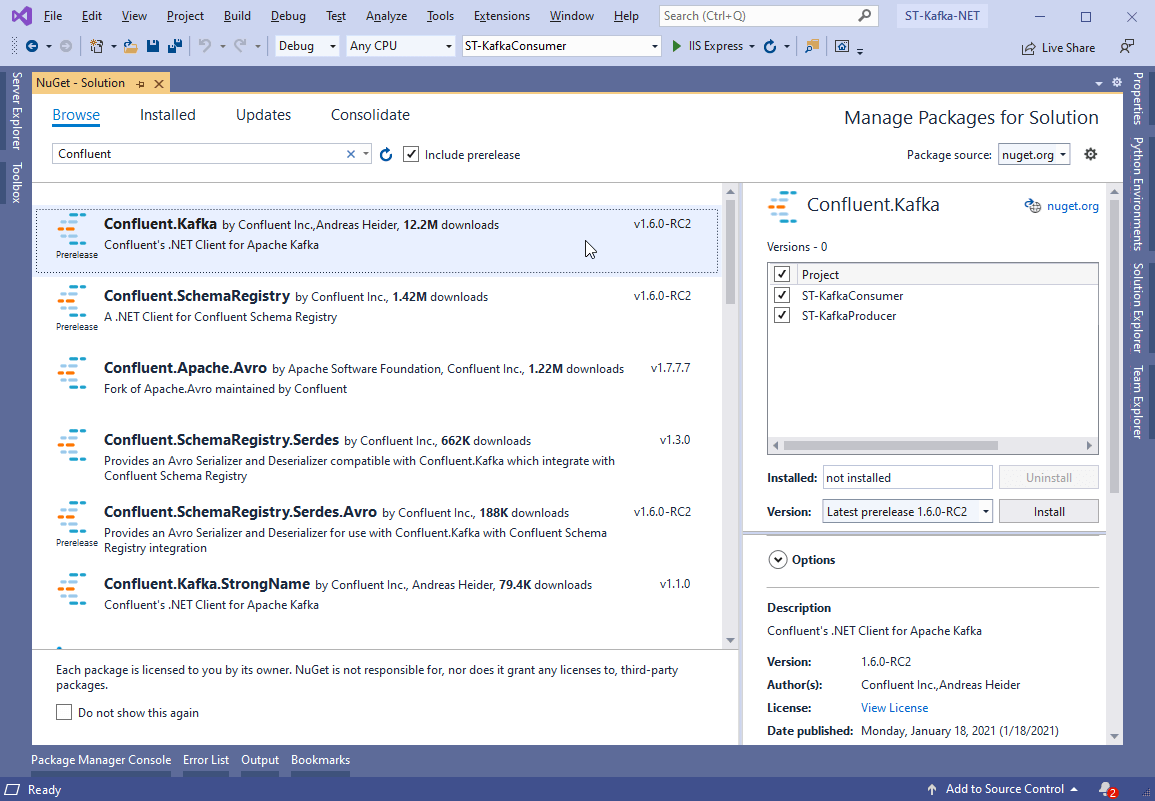
![]()
选择并单击Install。或者,你可以通过命令行添加它们:
PM> Install-Package Confluent.Kafka
设置消费者
现在来实现消费者项目。虽然它是一个类似rest的应用程序,但消费者不是必需的。任何类型的.net项目都可以监听topic消息。
该项目已经包含一个Controllers文件夹。你需要创建一个名为Handlers的新类,并向其添加一个KafkaConsumerHandler.cs的文件。内容如下:
using Confluent.Kafka;
using Microsoft.Extensions.Hosting;
using System;
using System.Threading;
using System.Threading.Tasks;
namespace ST_KafkaConsumer.Handlers
{
public class KafkaConsumerHandler : IHostedService
{
private readonly string topic = "simpletalk_topic";
public Task StartAsync(CancellationToken cancellationToken)
{
var conf = new ConsumerConfig
{
GroupId = "st_consumer_group",
BootstrapServers = "localhost:9092",
AutoOffsetReset = AutoOffsetReset.Earliest
};
using (var builder = new ConsumerBuilder<Ignore,
string>(conf).Build())
{
builder.Subscribe(topic);
var cancelToken = new CancellationTokenSource();
try
{
while (true)
{
var consumer = builder.Consume(cancelToken.Token);
Console.WriteLine($"Message: {consumer.Message.Value} received from {consumer.TopicPartitionOffset}");
}
}
catch (Exception)
{
builder.Close();
}
}
return Task.CompletedTask;
}
public Task StopAsync(CancellationToken cancellationToken)
{
return Task.CompletedTask;
}
}
}
这个处理程序必须在一个单独的线程中运行,因为它将永远在while循环中监视传入消息。因此,需要在这个类中使用异步任务。
请注意topic名称和消费者配置。它们与docker-compose.yml中的设置完全匹配。一定要反复检查你的输入,否则可能会导致一些莫名其妙的错误。
消费者组id可以是任何你想要的。通常,它们都有直观的名称,以帮助进行维护和故障排除。
每当新消息被发布到simpletalk_topic时,该消费者将使用它并将其记录到控制台。当然,在现实应用程序中,你会更好地利用这些数据。
你还需要将这个托管服务类添加到Startup中,因此,打开它,并在ConfigureServices方法中添加以下代码行:
services.AddSingleton<IHostedService, KafkaConsumerHandler>();
![]()
并确保引入了以下命名空间:
using ST_KafkaConsumer.Handlers;
设置生产者
至于生产者,这里的处理方式会有所不同。由于不需要无限循环来监听到达的消息,生产者可以简单地从任何地方发布消息,甚至是从控制器。在实际的应用程序中,最好将这类代码与MVC层分开,但本例坚持使用控制器,以保持简单。
在Controllers文件夹中创建一个名为KafkaProducerController.cs的文件,并向其添加一下内容:
using System;
using Confluent.Kafka;
using Microsoft.AspNetCore.Mvc;
namespace Kafka.Producer.API.Controllers
{
[Route("api/kafka")]
[ApiController]
public class KafkaProducerController : ControllerBase
{
private readonly ProducerConfig config = new ProducerConfig
{ BootstrapServers = "localhost:9092" };
private readonly string topic = "simpletalk_topic";
[HttpPost]
public IActionResult Post([FromQuery] string message)
{
return Created(string.Empty, SendToKafka(topic, message));
}
private Object SendToKafka(string topic, string message)
{
using (var producer =
new ProducerBuilder<Null, string>(config).Build())
{
try
{
return producer.ProduceAsync(topic, new Message<Null, string> { Value = message })
.GetAwaiter()
.GetResult();
}
catch (Exception e)
{
Console.WriteLine($"Oops, something went wrong: {e}");
}
}
return null;
}
}
}
![]()
生产者代码比消费者代码简单得多。ProducerBuilder类负责根据提供的配置选项、Kafka服务器和topic名称创建一个功能齐全的Kafka生产者。
重要的是要记住整个过程是异步的。但是,你可以使用Confluent的API来检索awaiter对象,然后从API方法返回结果。
测试
要测试这个示例,你需要分别运行生产者和使用者应用程序。在工具栏中,找到Startup Projects组合框并选择ST-KafkaConsumer选项:
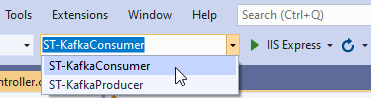
![]()
点击按钮IIS Express来运行消费者应用程序。这将启动一个新的浏览器窗口,我们将忽略并最小化它,因为消费者API不是重点。
打开一个新的cmd窗口,跳转到producer文件夹。运行命令dotnet run来启动它。
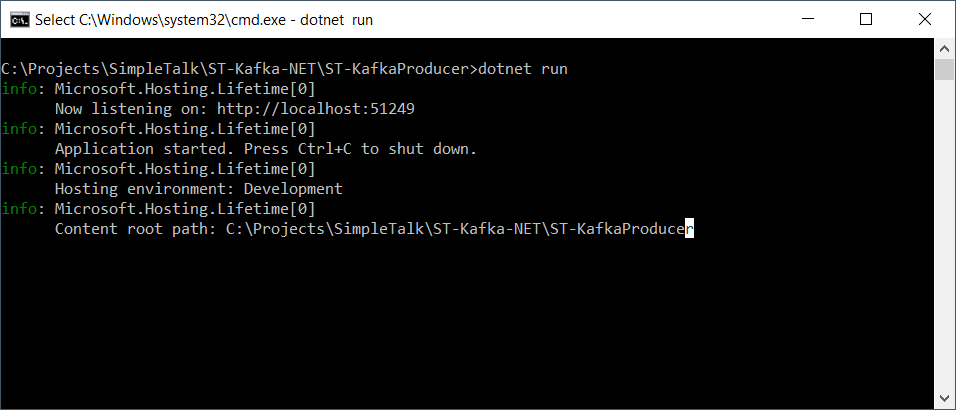
![]()
请注意它所运行的URL和端口。
现在是时候通过producer API发送一些消息了。为此,你可以使用任何API测试工具,例如Postman。
为了让下面的命令正常工作,必须确保Docker镜像正常工作。因此,请确保再次执行docker ps来检查。有时,重新启动计算机会停止这些进程。
如果命令没有任何日志信息,那么再运行一次docker-compose。
要测试发布-订阅消息,打开另一个cmd窗口并发出以下命令:
curl -H "Content-Length: 0" -X POST "http://localhost:51249/api/kafka?message=Hello,kafka!"
![]()
这个请求发送到生产者API并向Kafka发布一个新消息。
要检查消费者是否收到了它,你可以找到输出窗口并选择ST-KafkaConsumer – ASP.NET Core Web Server,如图所示:
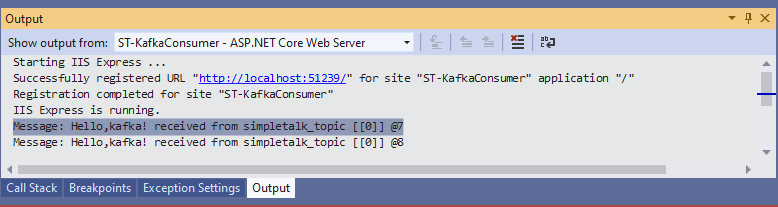
cmd窗口也可以显示JSON结果。但是,它没有格式化。要解决这个问题,如果你安装了Python,你可以运行以下命令:
curl -H "Content-Length: 0" -X POST "http://localhost:51249/api/kafka?message=Hello,kafka!" | python -m json.tool
![]()
输出如下:
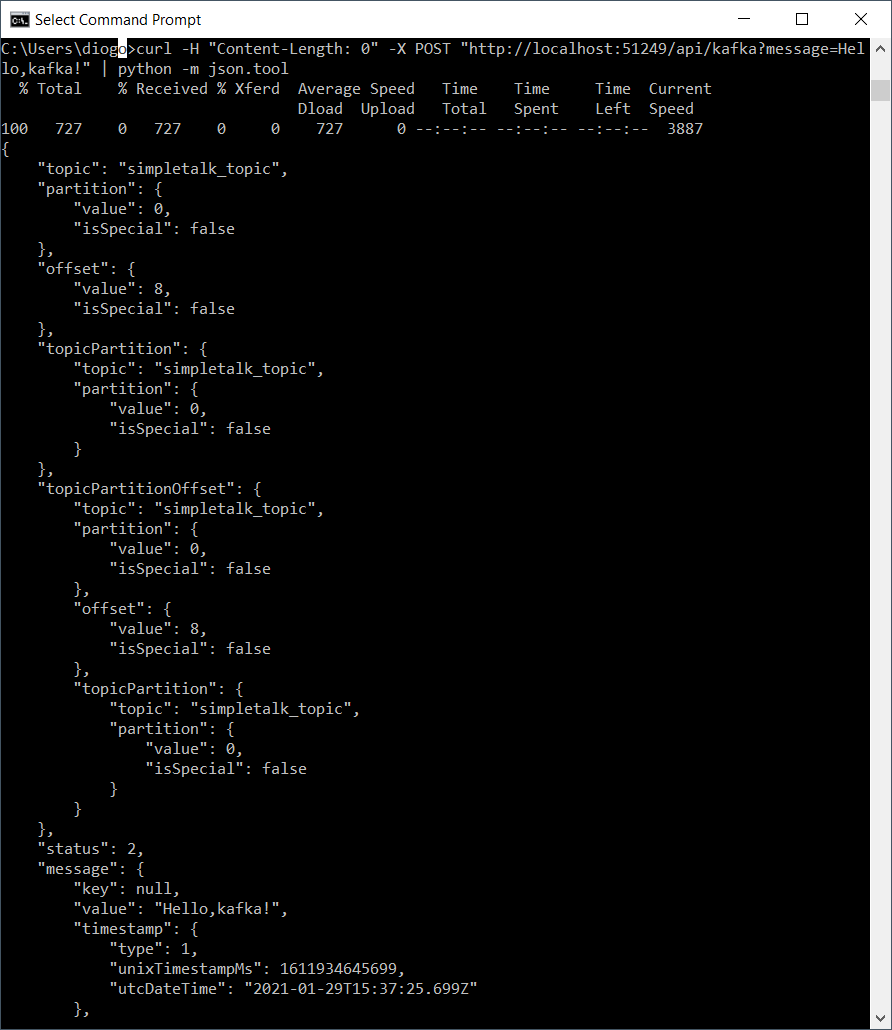
这是目前可以获得的关于topic message对象的所有信息。第二个测试将显示当消费者项目关闭并发布消息时发生了什么。
停止Visual Studio中的consumer项目,但这一次有一个不同的消息:
curl -H "Content-Length: 0" -X POST "http://localhost:51249/api/kafka?message=Is%20anybody%20there?" | python -m json.tool
![]()
接着启动消费者项目,观察日志记录,内容如下:
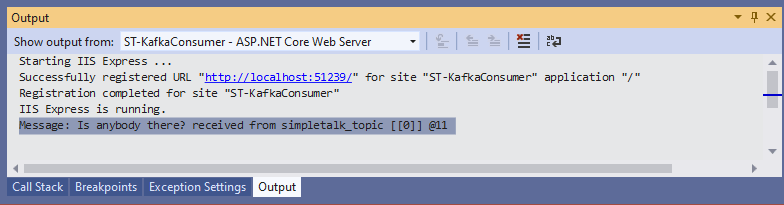
总结
Kafka是一个灵活和健壮的工具,它允许在许多类型的项目中进行强大的实现,这是它被广泛采用的第一个原因。
这篇文章只是对它的世界的一个简要介绍,但是还有更多的东西可以看到。在下一篇文章中,我将探讨Kafka的功能。
原文链接:https://www.red-gate.com/simple-talk/dotnet/net-development/using-apache-kafka-with-net/

在.NET中使用Apache Kafka(一)的更多相关文章
- CDH下集成spark2.2.0与kafka(四十一):在spark+kafka流处理程序中抛出错误java.lang.NoSuchMethodError: org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/util/Collection;)V
错误信息 19/01/15 19:36:40 WARN consumer.ConsumerConfig: The configuration max.poll.records = 1 was supp ...
- 1.1 Introduction中 Apache Kafka™ is a distributed streaming platform. What exactly does that mean?(官网剖析)(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Apache Kafka™ is a distributed streaming p ...
- Kafka工具教程 - Apache Kafka中的2个重要工具
1.目标 - 卡夫卡工具 在我们上一期的Kafka教程中,我们讨论了Kafka Workflow.今天,我们将讨论Kafka Tool.首先,我们将看到卡夫卡的意义.此外,我们将了解两个Kafka工具 ...
- Windows OS上安装运行Apache Kafka教程
Windows OS上安装运行Apache Kafka教程 下面是分步指南,教你如何在Windows OS上安装运行Apache Zookeeper和Apache Kafka. 简介 本文讲述了如何在 ...
- 【转】apache kafka监控系列-KafkaOffsetMonitor
apache kafka监控系列-KafkaOffsetMonitor 时间 2014-05-27 18:15:01 CSDN博客 原文 http://blog.csdn.net/lizhitao ...
- Apache Kafka - Quick Start on Windows
在这篇文章中,我将要介绍如何搭建和使用Apache Kafka在windows环境.在开始之前,简要介绍一下Kafka,然后再进行实践. Apache Kafka Kafka是分布式的发布-订阅消息的 ...
- 【转】apache kafka技术分享系列(目录索引)
转自: http://blog.csdn.net/lizhitao/article/details/39499283 估计大神会不定期更新,所以还是访问这个链接看最新的目录list比较好 apa ...
- org.apache.kafka.common.network.Selector
org.apache.kafka.common.client.Selector实现了Selectable接口,用于提供符合Kafka网络通讯特点的异步的.非阻塞的.面向多个连接的网络I/O. 这些网络 ...
- Apache Kafka:下一代分布式消息系统
[http://www.infoq.com/cn/articles/apache-kafka/]分布式发布-订阅消息系统. Kafka是一种快速.可扩展的.设计内在就是分布式的,分区的和可复制的提交日 ...
随机推荐
- Spark Dataset DataFrame空值null,NaN判断和处理
Spark Dataset DataFrame空值null,NaN判断和处理 import org.apache.spark.sql.SparkSession import org.apache.sp ...
- 深信服上网行为管理配置跨三层MAC识别
1.在认证高级选项里点击新增 如果PC的IP和MAC存在于多个三层交换机,则需新增多个. 点击上图"查看服务器信息"测试能否从交换机获取PC的IP和MAC,有返回结果则能正常获取, ...
- 一文弄懂-BIO,NIO,AIO
目录 一文弄懂-BIO,NIO,AIO 1. BIO: 同步阻塞IO模型 2. NIO: 同步非阻塞IO模型(多路复用) 3.Epoll函数详解 4.Redis线程模型 5. AIO: 异步非阻塞IO ...
- o2,o3优化
#pragma GCC optimize(2)//O2优化 #pragma GCC optimize(3,"Ofast","inline")//O3优化
- POJ_2112 二分图多重匹配
题意: //题意就是给你k个挤奶池和c头牛,每个挤奶池最多可以来m头牛,而且每头牛距离这k这挤奶池//有一定的距离,题目上给出k+c的矩阵,每一行代表某一个物品距离其他物品的位置//这里要注意给出的某 ...
- Codeforces Round #177 (Div. 2) B. Polo the Penguin and Matrix (贪心,数学)
题意:给你一个\(n\)x\(m\)的矩阵,可以对矩阵的所有元素进行\(\pm d\),问能否使得所有元素相等. 题解:我们可以直接记录一个\(n*m\)的数组存入所有数,所以\((a_1+xd)=( ...
- 梨子带你刷burp练兵场(burp Academy) - 服务器篇 - Sql注入 - SQL injection UNION attack, determining the number of columns returned by the query
目录 SQL injection UNION attack, determining the number of columns returned by the query SQL injection ...
- Kubernets二进制安装(16)之安装部署traefik(ingress)
K8S的DNS实现了服务在集群"内"被自动发现,如何使得服务在Kuberneters集群"外"被使用和访问呢,有二种方法 1)使用NodePort型的Servi ...
- Ubuntu Live CD联网修复
此模式下可以联网修复ubuntu系统下绝大多数问题.进入LIVE CD模式,打开终端执行以下命令: #此处/dev/sda1为ubuntu根分区,工作中根据实际分区情况更改 sudo mount /d ...
- keepalived.conf说明
keepalived.conf说明 发表于 2017-06-04 | 分类于 运维相关 , Keepalived | | 阅读次数 348 | 字数统计 1,889 | 阅读时长预计 8 本文主要介绍 ...