五分钟带你深入了解Redis
相信phper都知道Redis是什么,既然如此,为表仪式感,首先我还是得说说什么是Redis。
Redis是什么
redis是一个高性能的key-value数据库,它是完全开源免费的,而且redis是一个NOSQL类型数据库,是为了解决高并发、高扩展,大数据存储等一系列的问题而产生的数据库解决方案,是一个非关系型的数据库。但是,它也是不能替代关系型数据库,只能作为特定环境下的扩充。redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。
Redis的特点:
1.速度快
- Redis的所有数据都是存放在内存中的,所以把数据放在内存中是Redis速度快的最主要原因。
- Redis是用C语言实现的,一般来说C语言实现的程序“距离”操作系统更近,执行速度相对会更快。
- Redis使用了单线程架构,预防了多线程可能产生的竞争问题。
2.redis提供了丰富的数据结构
它主要提供了5种数据结构:string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。
3.丰富的功能
除了5种数据结构,Redis还提供了许多额外的功能:
- 提供了键过期功能,可以用来实现缓存。
- 提供了发布订阅功能,可以用来实现消息系统。
- 支持Lua脚本功能,可以利用Lua创造出新的Redis命令。
- 提供了简单的事务功能,能在一定程度上保证事务特性。
- 提供了流水线(Pipeline)功能,这样客户端能将一批命令一次性传到Redis,减少了网络的开销。
4.简单稳定
Redis的简单主要表现在三个方面。
- Redis的源码很少。
- Redis使用单线程模型,这样不仅使得Redis服务端处理模型变得简单,而且也使得客户端开发变得简单。
- Redis不需要依赖于操作系统中的类库(例如Memcache需要依赖libevent这样的系统类库),Redis自己实现了事件处理的相关功能。
Redis虽然很简单,但是不代表它不稳定。维护的上千个Redis为例,没有出现过因为Redis自身bug而宕掉的情况。
5.客户端语言多
Redis提供了简单的TCP通信协议,很多编程语言可以很方便地接入到Redis,并且由于Redis受到社区和各大公司的广泛认可,所以支持Redis的客户端语言也非常多,几乎涵盖了主流的编程语言,例如Java、PHP、Python、C、C++、Nodejs等。
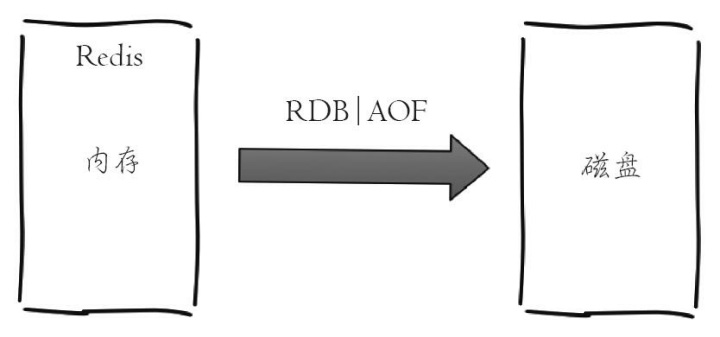
6.持久化
通常看,将数据放在内存中是不安全的,一旦发生断电或者机器故障,重要的数据可能就会丢失,因此Redis提供了两种持久化方式:RDB和AOF,即可以用两种策略将内存的数据保存到硬盘中(如图所示)这样就保证了数据的可持久性。
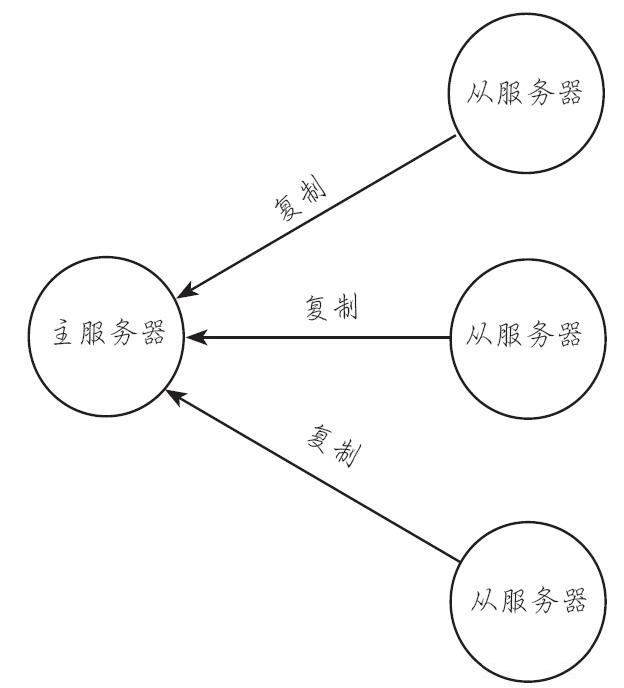
7.主从复制
Redis提供了复制功能,实现了多个相同数据的Redis副本(如图所示),复制功能是分布式Redis的基础。
Redis的工作流程
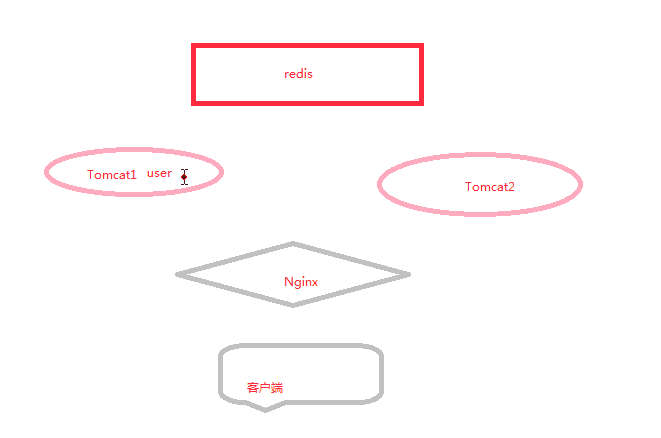
从图上可以看出,当一个客户端访问服务器的时候,客户端请求会先到达Nginx,由Nginx负责对数据进行分发,上传到多个服务器,当用户访问到tomcat1的时候,会进行登陆验证并将session放入session管理中,使用Redis管理session的好处就是当第二次客户端登陆后再进行操作,这时很可能到达tomcat2服务器,这时候tomcat2会从Redis中寻找session,从而避免了session只在一个服务器中造成第二次读取session发现为空的问题。
在shiro中,shiro也提供了一个分布式session的管理功能,但使用Redis更能集中管理。
Redis数据类型及使用场景
前面也提到了Redis支持五种数据类型,下面详细介绍一下这5种数据类型级使用场景
1、string
简单介绍一下,Strings数据类型是最常用、简单的key-value类型,普通的key/ value 存储都可以归为此类。value不仅可以是字符串,也可以是数字。因为是二进制安全的,所以你完全可以把一个图片文件的内容作为string来存储。Redis的string可以完全实现目前memcached的功能,并且效率更高。除了提供与 Memcached 一样的get、set、incr、decr 等操作外,Redis还额外提供了下面一些操作:
- 获取字符串长度
- 往字符串append内容
- 设置和获取字符串的某一段内容
- 设置及获取字符串的某一位(bit)
- 批量设置一系列字符串的内容
常用命令:
set,get,decr,incr,mget 等。
应用场景:
- 应用 Memcached和CKV的所有场景。字符串和数字直接存取。结构化数据需要先序列化,再set到value;相应的,get到value后需要反序列化。
- 可以利用redis的INCR、INCRBY、DECR、DECRBY等指令来实现原子计数的效果。即可以用来实现业务上的统计计数需求。也可用于实现idmaker,即生成全局唯一的id。
- 存放session key,实现一个分布式session系统。Redis的key可以方便地设置过期时间,用于实现session key的自动过期。验证skey时先根据uid路由到对应的redis,如取不到skey,则表示skey已过期,需要重新登录;如取到skey且校验通过则升级此skey的过期时间即可。
- Set nx或SetNx,仅当key不存在时才Set。可以用来选举Master或实现分布式锁:所有Client不断尝试使用SetNx master myName抢注Master,成功的那位不断使用Expire刷新它的过期时间。如果Master挂掉了key就会失效,剩下的节点又会发生新一轮抢夺。
- 借助redis2.6开始支持的lua脚本,可以实现更安全的2种分布式锁:一种适用于各进程竞争但总是单个进程获取锁并处理的场景。除非原处理进程挂掉因而锁过期才会被其它进程获取到锁。无须主动解锁。通过get、expire/pexpire、setnx ex| px的lua脚本实现;一种适用于各进程竞争获取锁并处理的场景。通过set nx ex| px获取锁,用完需要通过先get判断再del释放锁,否则在锁过期之前不能获取到锁。
- GetSet, 设置新值,返回旧值。比如实现一个计数器,可以用GetSet获取计数并重置为0。
- GetBit/SetBit/BitOp/BitCount, BitMap的玩法,比如统计今天的独立访问用户数时,每个注册用户都有一个offset,他今天进来的话就把他那个位设为1,用BitCount就可以得出今天的总人数。
- Append/SetRange/GetRange/StrLen,对文本进行扩展、替换、截取和求长度,对特定数据格式非常有用。
实现方式:
String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr,decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
2、List
简单介绍一下,List是一个双向链表,支持双向的Pop/Push,江湖规矩一般从左端Push,右端Pop——LPush/RPop,而且还有Blocking的版本BLPop/BRPop,客户端可以阻塞在那直到有消息到来。还有RPopLPush/ BRPopLPush,弹出来返回给client的同时,把自己又推入另一个list,LLen获取列表的长度。还有按值进行的操作:LRem(按值删除元素)、LInsert(插在某个值的元素的前后),复杂度是O(N),N是List长度,因为List的值不唯一,所以要遍历全部元素,而Set只要O(log(N))。
按下标进行的操作:下标从0开始,队列从左到右算,下标为负数时则从右到左。LSet ,按下标设置元素值。LIndex,按下标返回元素。LRange,不同于POP直接弹走元素,只是返回列表内一段下标的元素,是分页的最爱。LTrim,限制List的大小,比如只保留最新的20条消息。复杂度也是O(N),其中LSet的N是List长度,LIndex的N是下标的值,LRange的N是start的值+列出元素的个数,因为是链表而不是数组,所以按下标访问其实要遍历链表,除非下标正好是队头和队尾。LTrim的N是移除元素的个数。
常用命令:
lpush,rpush,lpop,rpop,lrange等。
应用场景:
- 各种列表,比如twitter的关注列表、粉丝列表等,最新消息排行、每篇文章的评论等也可以用Redis的list结构来实现。
- 消息队列,可以利用Lists的PUSH操作,将任务存在Lists中,然后工作线程再用POP操作将任务取出执行。这里的消息队列并没有ack机制,如果消费者把任务给Pop走了又没处理完就死机了怎么办?解决方法之一是加多一个sorted set,分发的时候同时发到list与sorted set,以分发时间为score,用户把任务做完了之后要用ZREM消掉sorted set里的job,并且定时从sorted set中取出超时没有完成的任务,重新放回list。另一个做法是为每个worker多加一个的list,弹出任务时改用RPopLPush,将job同时放到worker自己的list中,完成时用LREM消掉。如果集群管理(如zookeeper)发现worker已经挂掉,就将worker的list内容重新放回主list。
- 利用LRANGE可以很方便的实现list内容分页的功能。
- 取最新N个数据的操作:LPUSH用来插入一个内容ID,作为关键字存储在列表头部。LTRIM用来限制列表中的项目数最多为5000。如果用户需要的检索的数据量超越这个缓存容量,这时才需要把请求发送到数据库。
实现方式:
Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
3、Set
简单介绍一下,set是一种无序的集合,集合中的元素没有先后顺序,不重复。将重复的元素放入Set会自动去重。
常用命令:
sadd,spop,smembers,sunion等。
应用场景:
- 某些需要去重的列表,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
- 可以存储一些集合性的数据,比如在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis还为集合提供了求交集、并集、差集等操作,可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。又比如QQ有一个社交功能叫做“好友标签”,大家可以给你的好友贴标签,比如“大美女”、“土豪”、“欧巴”等等,这里也可以把每一个用户的标签都存储在一个集合之中。
- 想要知道某些特定的注册用户或IP地址,他们到底有多少访问了某个页面,可以这样实现:SADD page:day1:。想知道特定用户的数量,使用SCARD page:day1:。 需要测试某个特定用户是否访问了这个页面?SISMEMBER page:day1:。
实现方式:
set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
4、zest
简单介绍一下,有序集合,相比set,元素放入集合时还要提供该元素的分数,可根据分数自动排序。
常用命令:
zadd,zrange,zrem,zcard等
使用场景:
- 存放一个有序的并且不重复的集合列表,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
- 可以做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
- 排行榜相关:ZADD leaderboard。 得到前100名高分用户很简单:ZREVRANGE leaderboard 0 99。用户的全球排名也相似,只需要执行:ZRANK leaderboard。
- 新闻按照用户投票和时间排序,ZADD时的score = points / time^alpha, 这样用户的投票会相应的把新闻挖出来,但时间会按照一定的指数将新闻埋下去。
- 过期项目处理:使用unix时间作为关键字,用来保持列表能够按时间排序。对current_time和time_to_live进行检索,完成查找过期项目的艰巨任务。另一项后台任务使用ZRANGE...WITHSCORES进行查询,删除过期的条目。
实现方式:
Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
5、Hash
简单介绍一下,Hash存的是字符串和字符串值之间的映射。Hash将对象的各个属性存入Map里,可以只读取/更新对象的某些属性。这样有些属性超长就让它一边呆着不动,另外不同的模块可以只更新自己关心的属性而不会互相并发导致覆盖冲突。
常用命令:
hget,hset,hgetall 等。
应用场景:
- 存放结构化数据,比如用户信息。在Memcached或CKV中,对于用户信息比如用户的昵称、年龄、性别、积分等,我们需要先序列化后存储为一个字符串的值,这时候在需要修改其中某一项时,通常需要将所有值取出反序列化后,修改某一项的值,再序列化存储回去。这样不仅增大了开销,也不适用于一些可能并发操作的场合(比如两个并发的操作都需要修改积分)。而Redis的Hash结构可以使你像在数据库中Update一个属性一样只修改某一项属性值
- Key是用户ID, value是一个Map,这个Map的key是成员的属性名,value是属性值,这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。3. 不过这里需要注意,Redis提供了接口(hgetall)
- 可以直接取到全部的属性数据,但是如果内部Map的成员很多,那么涉及到遍历整个内部Map的操作,由于Redis单线程模型的缘故,这个遍历操作可能会比较耗时,而对其它客户端的请求完全不响应,这点需要格外注意。
- 可用来建索引。比如User对象,除了id有时还要按name来查询,可以建一个Key为user:name:id的Hash,在插入User对象时(set user:101{"id":101,"name":"calvin"}), 顺便往这个hash插入一条(hset user:name:id calvin 101),这时calvin作为hash里的一个key,值为101。按name查询的时候,用hgetuser:name:id calvin 就能从名为calvin的key里取出id。假如需要使用多种索引来查找某条数据时可以使用,一个hash key搞定,避免使用多个string key存放索引值。
- HINCRBY同样可用于实现idmaker。相对string类型的idmaker每一个类型需要一个key,hash类型的用一个key即可。
实现方式:
Redis Hash对应Value内部实际就是一个HashMap,这里会有2种不同实现,这个Hash的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,对应的value redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
今日就分享到这啦,如果任何问题或者建议,欢迎留言交流。
五分钟带你深入了解Redis的更多相关文章
- Python专题——五分钟带你了解map、reduce和filter
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是Python专题第6篇文章,给大家介绍的是Python当中三个非常神奇的方法:map.reduce和filter. 不知道大家看到ma ...
- 五分钟带你走入MP
一.MyBatis-Plus简介 1.1MyBatis-Plus是什么? MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化 ...
- Python——五分钟带你弄懂迭代器与生成器,夯实代码能力
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是周一Python专题,给大家带来的是Python当中生成器和迭代器的使用. 我当初第一次学到迭代器和生成器的时候,并没有太在意,只是觉 ...
- 五分钟带你读懂 TCP全连接队列(图文并茂)
爱生活,爱编码,微信搜一搜[架构技术专栏]关注这个喜欢分享的地方. 本文 架构技术专栏 已收录,有各种视频.资料以及技术文章. 一.问题 今天有个小伙伴跑过来告诉我有个奇怪的问题需要协助下,问题确实也 ...
- 五分钟带你读懂 堆 —— heap(内含JavaScript代码实现!!)
一.概念 说起堆,我们就想起了土堆,把土堆起来,当我们要用土的时候,首先用到最上面的土.类似地,堆其实是一种优先队列,按照某种优先级将数字"堆"起来,每次取得时候从堆顶取. 堆 ...
- 五分钟带你入门TensorFlow
TensorFlow是Google开源的一款人工智能学习系统.为什么叫这个名字呢?Tensor的意思是张量,代表N维数组:Flow的意思是流,代表基于数据流图的计算.把N维数字从流图的一端流动到另一端 ...
- OpenCV开发笔记(五十五):红胖子8分钟带你深入了解Haar、LBP特征以及级联分类器识别过程(图文并茂+浅显易懂+程序源码)
若该文为原创文章,未经允许不得转载原博主博客地址:https://blog.csdn.net/qq21497936原博主博客导航:https://blog.csdn.net/qq21497936/ar ...
- OpenCV开发笔记(五十六):红胖子8分钟带你深入了解多种图形拟合逼近轮廓(图文并茂+浅显易懂+程序源码)
若该文为原创文章,未经允许不得转载原博主博客地址:https://blog.csdn.net/qq21497936原博主博客导航:https://blog.csdn.net/qq21497936/ar ...
- OpenCV开发笔记(六十五):红胖子8分钟带你深入了解ORB特征点(图文并茂+浅显易懂+程序源码)
若该文为原创文章,未经允许不得转载原博主博客地址:https://blog.csdn.net/qq21497936原博主博客导航:https://blog.csdn.net/qq21497936/ar ...
随机推荐
- 微服务配置中心 Apollo 源码解析——Admin 发送发布消息
内容参考:https://www.toutiao.com/a6643383570985386509/ 摘要: 原创出处http://www.iocoder.cn/Apollo/admin-server ...
- windows 64位上安装mysql 5.7版本
下载的mysql不是安装exe的软件,而是在windows上编译好的二进制mysql软件 下载安装之后配置环境变量:将目录D:\Program Files\mysql-5.7.18-winx64\my ...
- C++核心内容和机制
备注:不局限与C++版本 一. 基础知识 数据类型和POD/Trivial 数据类型: 类型转换: NULL和nullptr: 操作符重载: 全局静态变量和成员静态变量的申明和初始化: 左值和右值 ...
- 微信小程序上传Word文档、PDF、图片等文件
<view class="main" style="border:none"> <view class="title"&g ...
- 谈谈 Promise 以及实现 Fetch 的思路
Promise 是异步编程的一种解决方案. Promise /** * 属性 */ Promise.length Promise.prototype /** * 方法 */ Promise.all(i ...
- akka-typed(8) - CQRS读写分离模式
前面介绍了事件源(EventSource)和集群(cluster),现在到了讨论CQRS的时候了.CQRS即读写分离模式,由独立的写方程序和读方程序组成,具体原理在以前的博客里介绍过了.akka-ty ...
- Elastic认证考试,请先看这一篇
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/wojiushiwo987/article ...
- ASP.NET MVC 中解决Session,Cookie等依赖的方式
原文:https://blog.csdn.net/mzl87/article/details/90580869 本文将分别介绍在MVC中使用Filter和Model Binding两种方式来说明如何解 ...
- socket 建立网络连接,client && server
client代码: package socket; import java.io.IOException; import java.net.Socket; /** * 客户端_聊天室 * * @aut ...
- 112买卖股票的最佳时机II
from typing import List# 这道题和上一题很类似,但有一些不同,每天都可以买入,或者卖出# 那么利润最大化,就是i + 1 天的价格比i天的价格高的时候买入# 然后在i + 1天 ...