[已完结]CMU数据库(15-445)实验2-B+树索引实现(下)
4. Index_Iterator实现
这里就是需要实现迭代器的一些操作,比如begin、end、isend等等
下面是对于IndexIterator的构造函数
template <typename KeyType, typename ValueType, typename KeyComparator>
IndexIterator<KeyType, ValueType, KeyComparator>::
IndexIterator(BPlusTreeLeafPage<KeyType, ValueType, KeyComparator> *leaf,
int index_, BufferPoolManager *buff_pool_manager):
leaf_(leaf), index_(index_), buff_pool_manager_(buff_pool_manager) {}
1. 首先我们来看begin函数的实现
- 利用key值找到叶子结点
- 然后获取当前key值的index就是begin的位置
INDEX_TEMPLATE_ARGUMENTS
INDEXITERATOR_TYPE BPLUSTREE_TYPE::Begin(const KeyType &key) {
auto leaf = reinterpret_cast<BPlusTreeLeafPage<KeyType, ValueType,KeyComparator> *>(FindLeafPage(key, false));
int index = 0;
if (leaf != nullptr) {
index = leaf->KeyIndex(key, comparator_);
}
return IndexIterator<KeyType, ValueType, KeyComparator>(leaf, index, buffer_pool_manager_);
}
2. end函数的实现
- 找到最开始的结点
- 然后一直向后遍历直到
nextPageId=-1结束 - 这里注意需要重载
!=和==
end函数
INDEX_TEMPLATE_ARGUMENTS
INDEXITERATOR_TYPE BPLUSTREE_TYPE::end() {
KeyType key{};
auto leaf= reinterpret_cast<BPlusTreeLeafPage<KeyType, ValueType,KeyComparator> *>( FindLeafPage(key, true));
page_id_t new_page;
while(leaf->GetNextPageId()!=INVALID_PAGE_ID){
new_page=leaf->GetNextPageId();
leaf=reinterpret_cast<BPlusTreeLeafPage<KeyType, ValueType,KeyComparator> *>(buffer_pool_manager_->FetchPage(new_page));
}
buffer_pool_manager_->UnpinPage(new_page,false);
return IndexIterator<KeyType, ValueType, KeyComparator>(leaf, leaf->GetSize(), buffer_pool_manager_);
}
==和 !=函数
bool operator==(const IndexIterator &itr) const {
return this->index_==itr.index_&&this->leaf_==itr.leaf_;
}
bool operator!=(const IndexIterator &itr) const {
return !this->operator==(itr);
}
3. 重载++和*(解引用符号)
- 重载++
简单的index++然后设置nextPageId即可
template <typename KeyType, typename ValueType, typename KeyComparator>
IndexIterator<KeyType, ValueType, KeyComparator> &IndexIterator<KeyType, ValueType, KeyComparator>::
operator++() {
//
// std::cout<<"++"<<std::endl;
++index_;
if (index_ == leaf_->GetSize() && leaf_->GetNextPageId() != INVALID_PAGE_ID) {
// first unpin leaf_, then get the next leaf
page_id_t next_page_id = leaf_->GetNextPageId();
auto *page = buff_pool_manager_->FetchPage(next_page_id);
if (page == nullptr) {
throw Exception("all page are pinned while IndexIterator(operator++)");
}
// first acquire next page, then release previous page
page->RLatch();
buff_pool_manager_->FetchPage(leaf_->GetPageId())->RUnlatch();
buff_pool_manager_->UnpinPage(leaf_->GetPageId(), false);
buff_pool_manager_->UnpinPage(leaf_->GetPageId(), false);
auto next_leaf =reinterpret_cast<BPlusTreeLeafPage<KeyType, ValueType,KeyComparator> *>(page->GetData());
assert(next_leaf->IsLeafPage());
index_ = 0;
leaf_ = next_leaf;
}
return *this;
};
- 重载*
return array[index]即可
template <typename KeyType, typename ValueType, typename KeyComparator>
const MappingType &IndexIterator<KeyType, ValueType, KeyComparator>::
operator*() {
if (isEnd()) {
throw "IndexIterator: out of range";
}
return leaf_->GetItem(index_);
}
5. 并发机制的实现
0. 首先复习一下读写机制
- 读操作是可以多个进程之间共享latch的而写操作则必须互斥
- 加入
MaxReader数就是为了防止等待的️写进程饥饿
首先来看如果没有机制多线程会发生什么问题
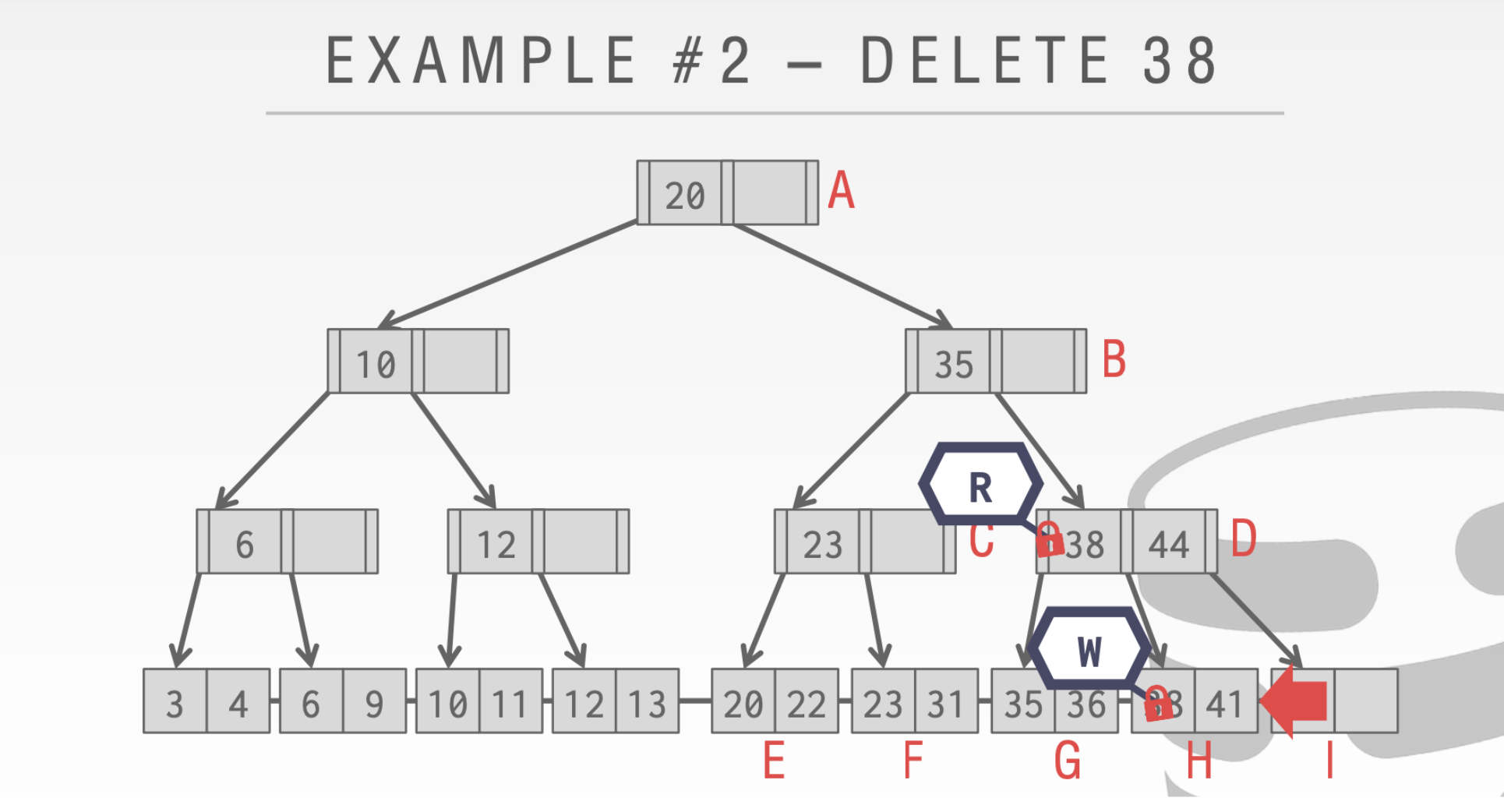
- 线程T1想要删除44。
- 线程T2 想要查找41
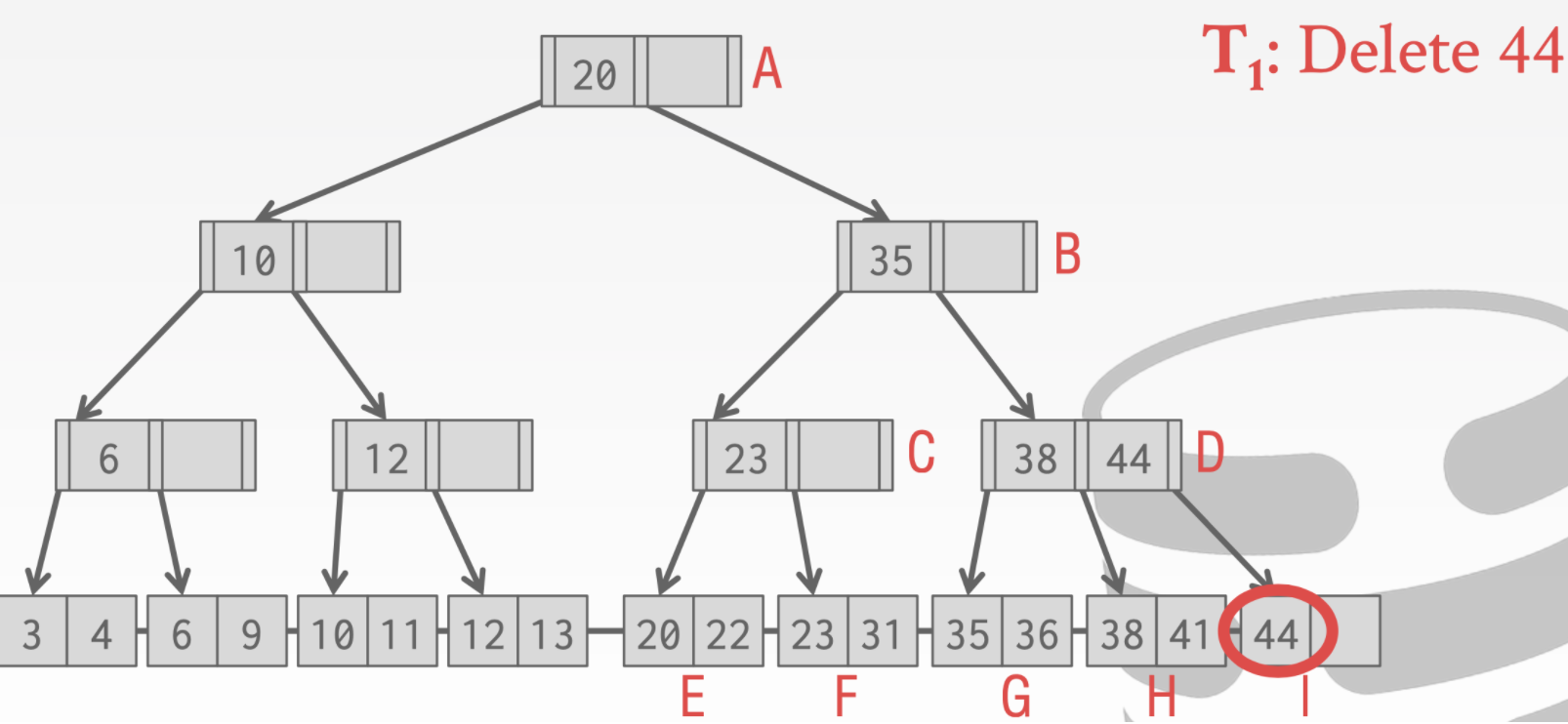
- 假设T2在执行到D位置的时候又切换到线程T1
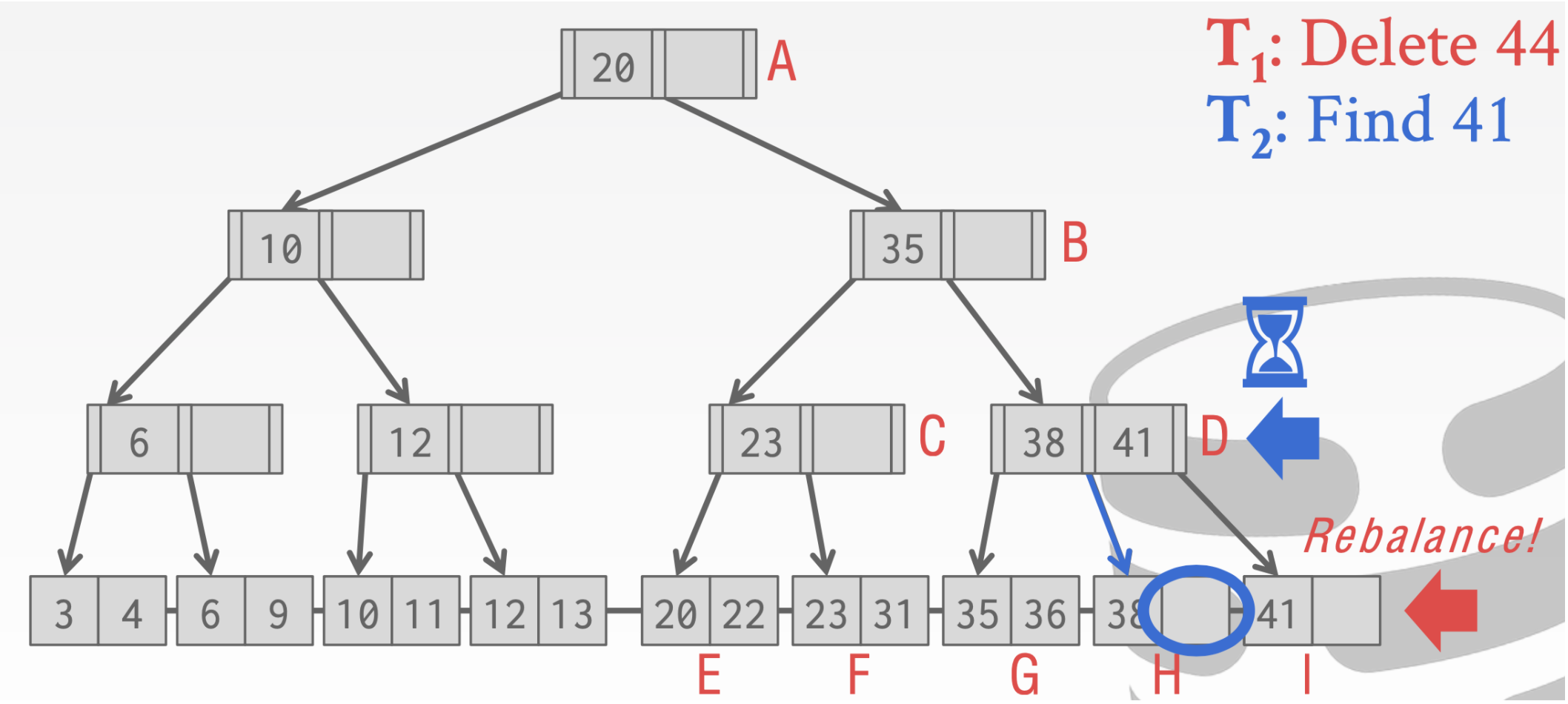
- 这个时候T1进行重新分配,会把41借到I结点上
- T1执行完成切换回T2这时候T2再去原来的执行寻找41就会找不到
就会出现下面的情况。
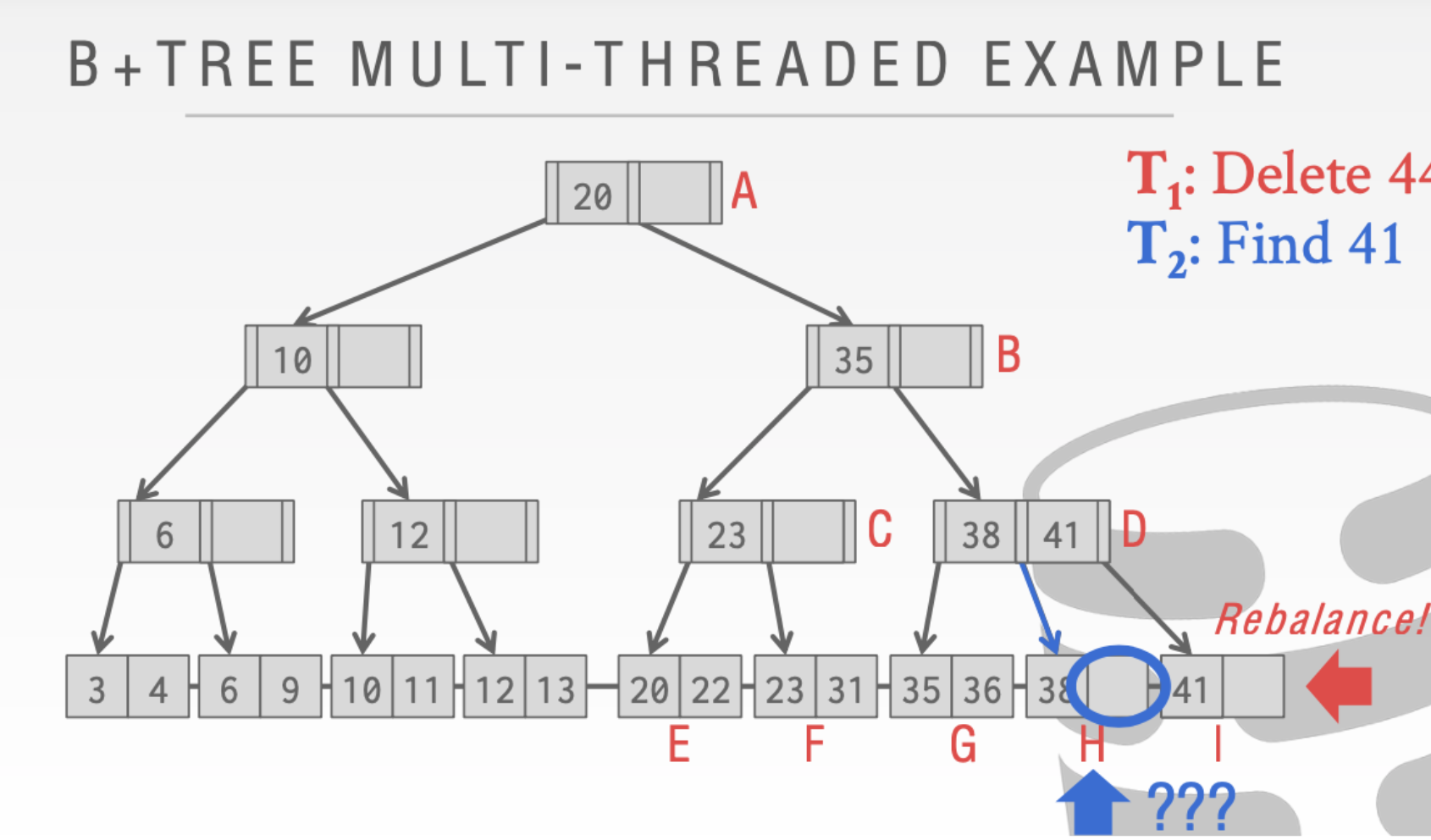
由此我们需要读写的存在
- 对于find操作
由于我们是只读操作,所以我们到下一个结点的时候就可以释放上一个结点的Latch
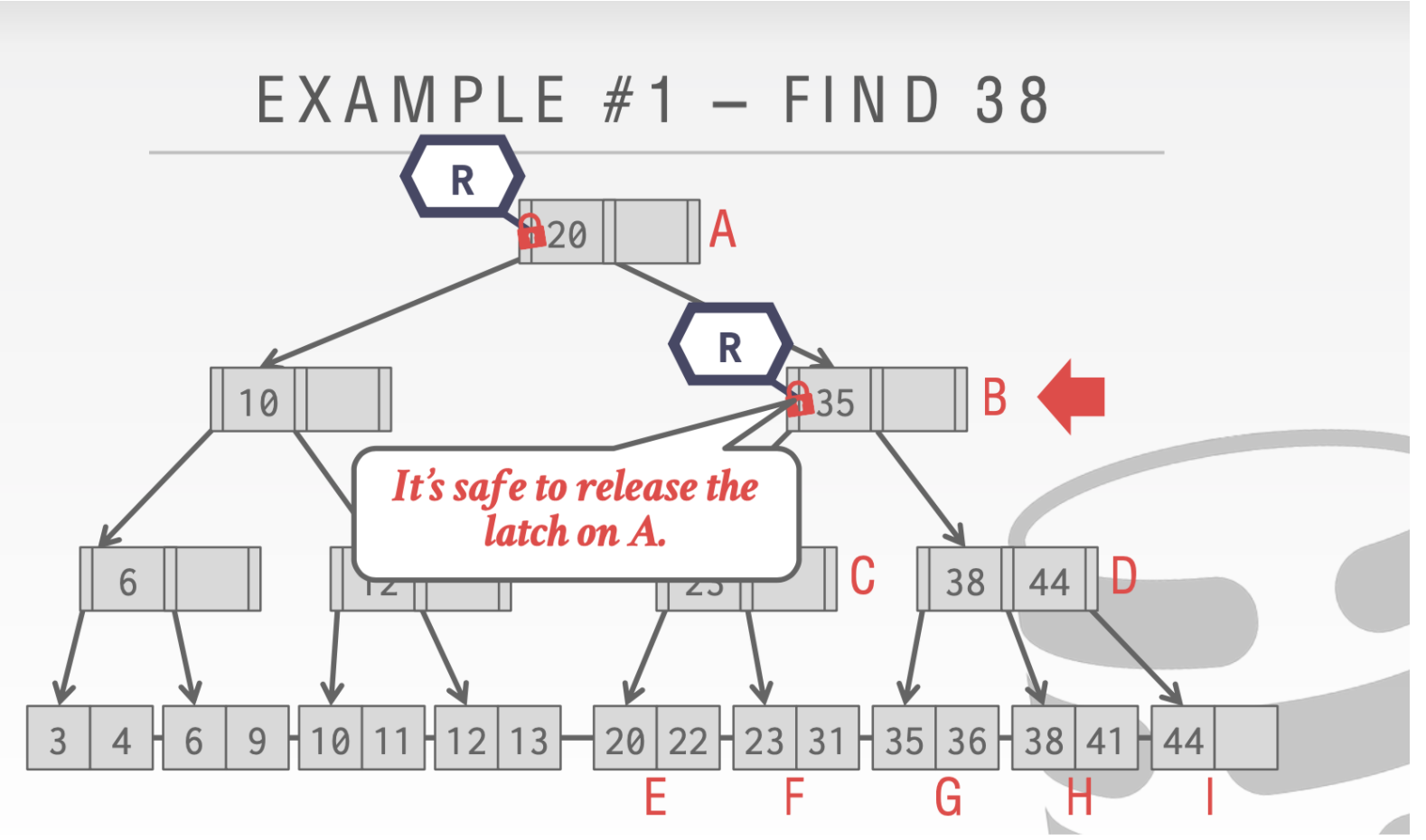
剩下的操作都是一样的
- 对于
delete则不一样
因为我们需要写操作
这里我们不能释放结点A的Latch。因为我们的删除操作可能会合并根节点。
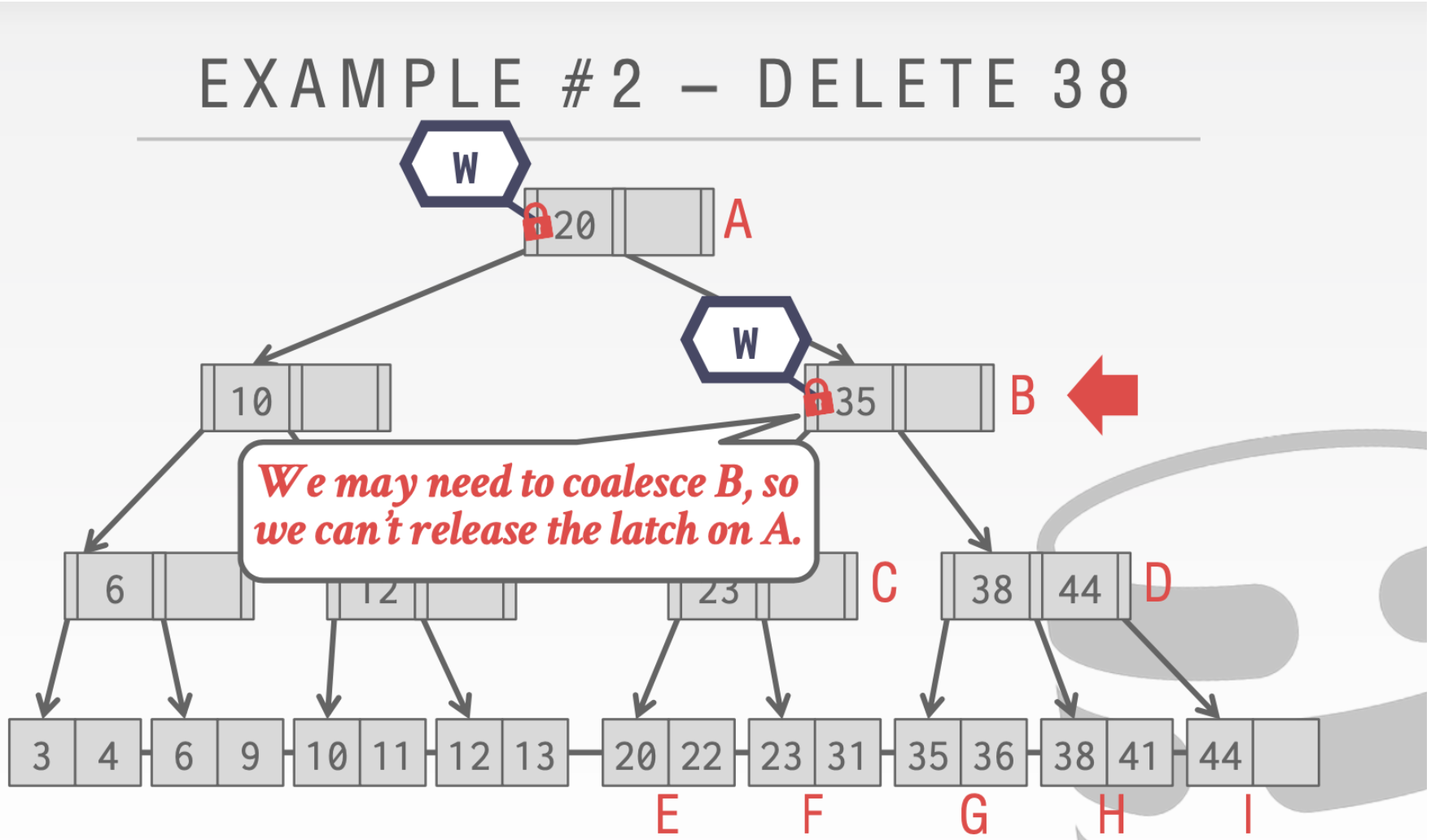
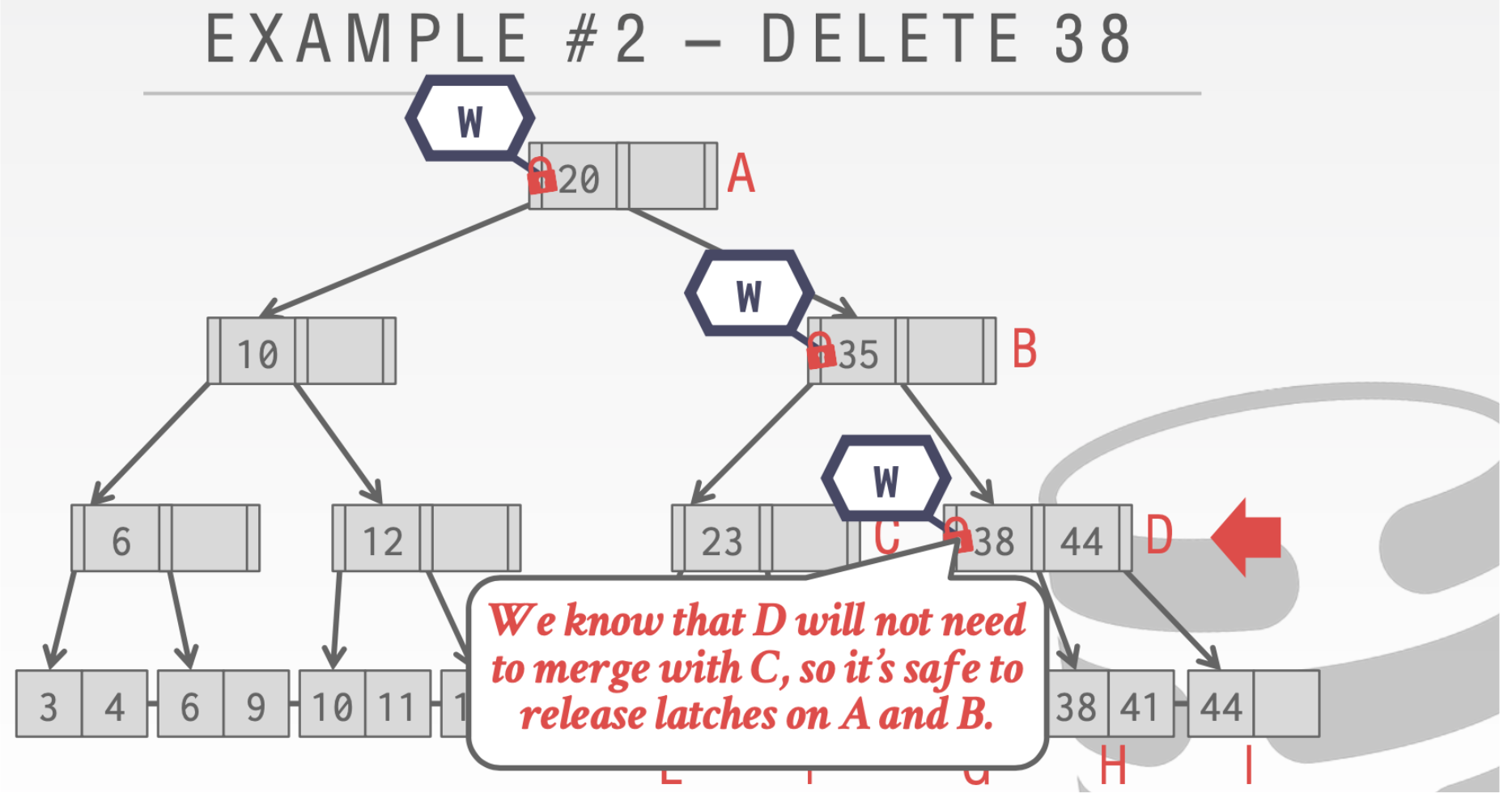
到D的时候。我们会发现D中的38删除之后不需要进行合并,所以对于A和B的写Write是可以安全释放了
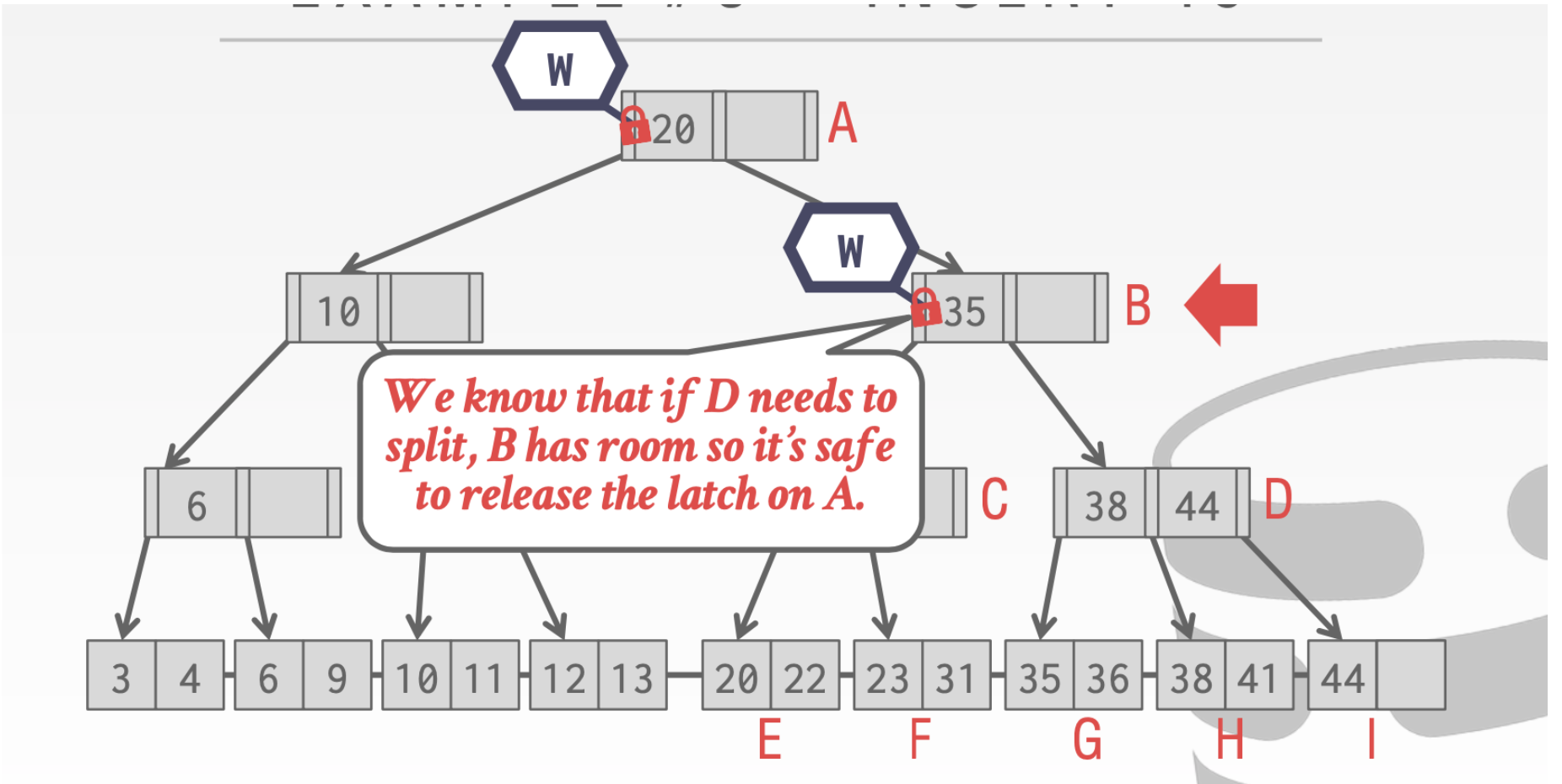
- 对于
Insert操作
这里我们就可以安全的释放掉A的锁。因为B中还有空位,我们插入是不会对A造成影响的
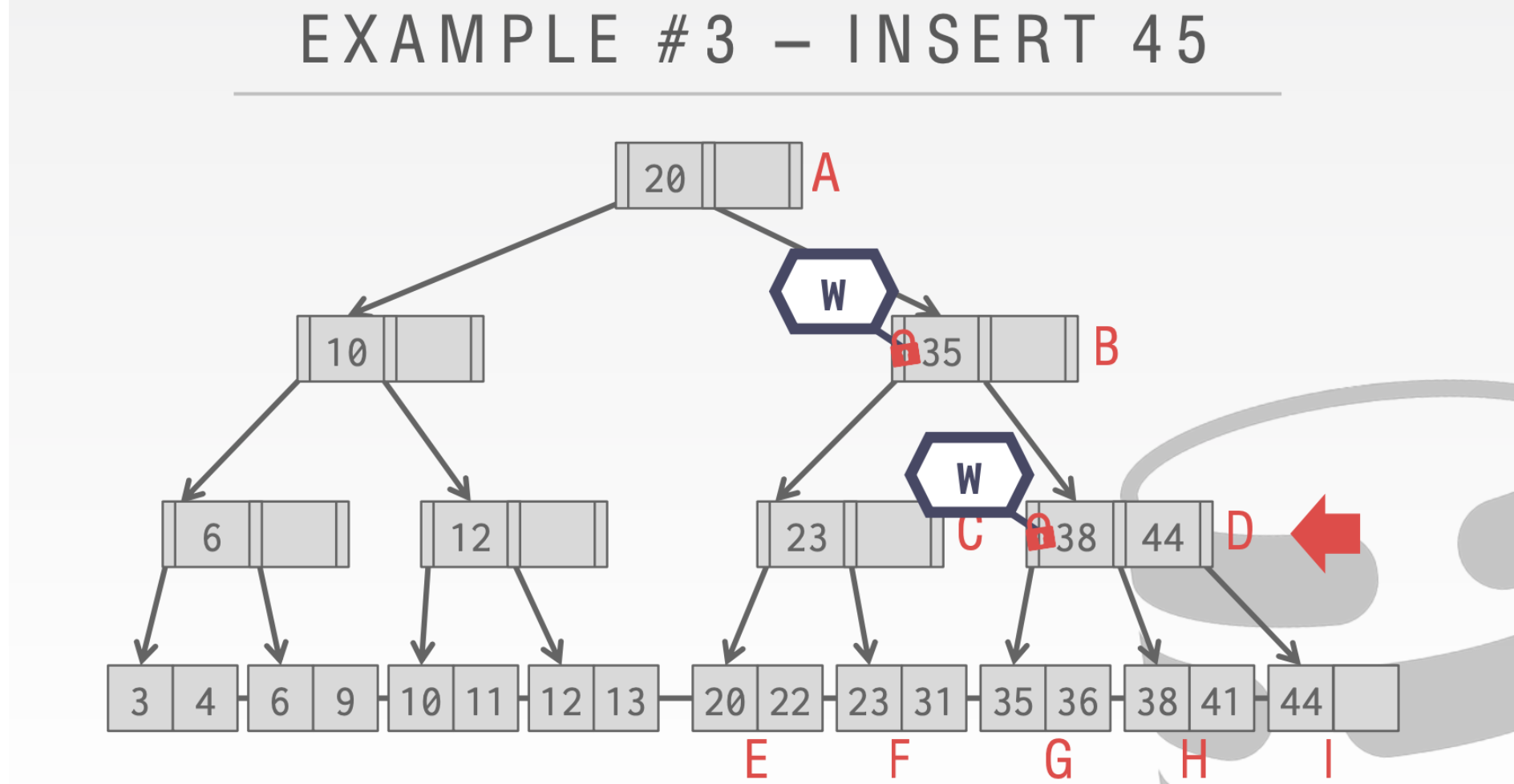
当我们执行到D这里发现D中已经满了。所以此时我们不会释放B的锁,因为我们会对B进行写操作
上面的算法虽然是正确的但是有瓶颈问题。由于只有一个线程可以获得写Latch。而插入和删除的时候都需要对头结点加写Latch。所以多线程在有许多个插入或者删除操作的时候,性能就会大打折扣
这里要引入乐观
乐观的假设大部分操作是不需要进行合并和分裂的。因此在我们向下的时候都是读Latch而不是写Latch。只有在叶子结点才是write Latch
- 从上到下都是读Latch。而且逐步释放
- 到叶子结点需要修改的时候才为写Latch。这个删除是安全的所以直接结束
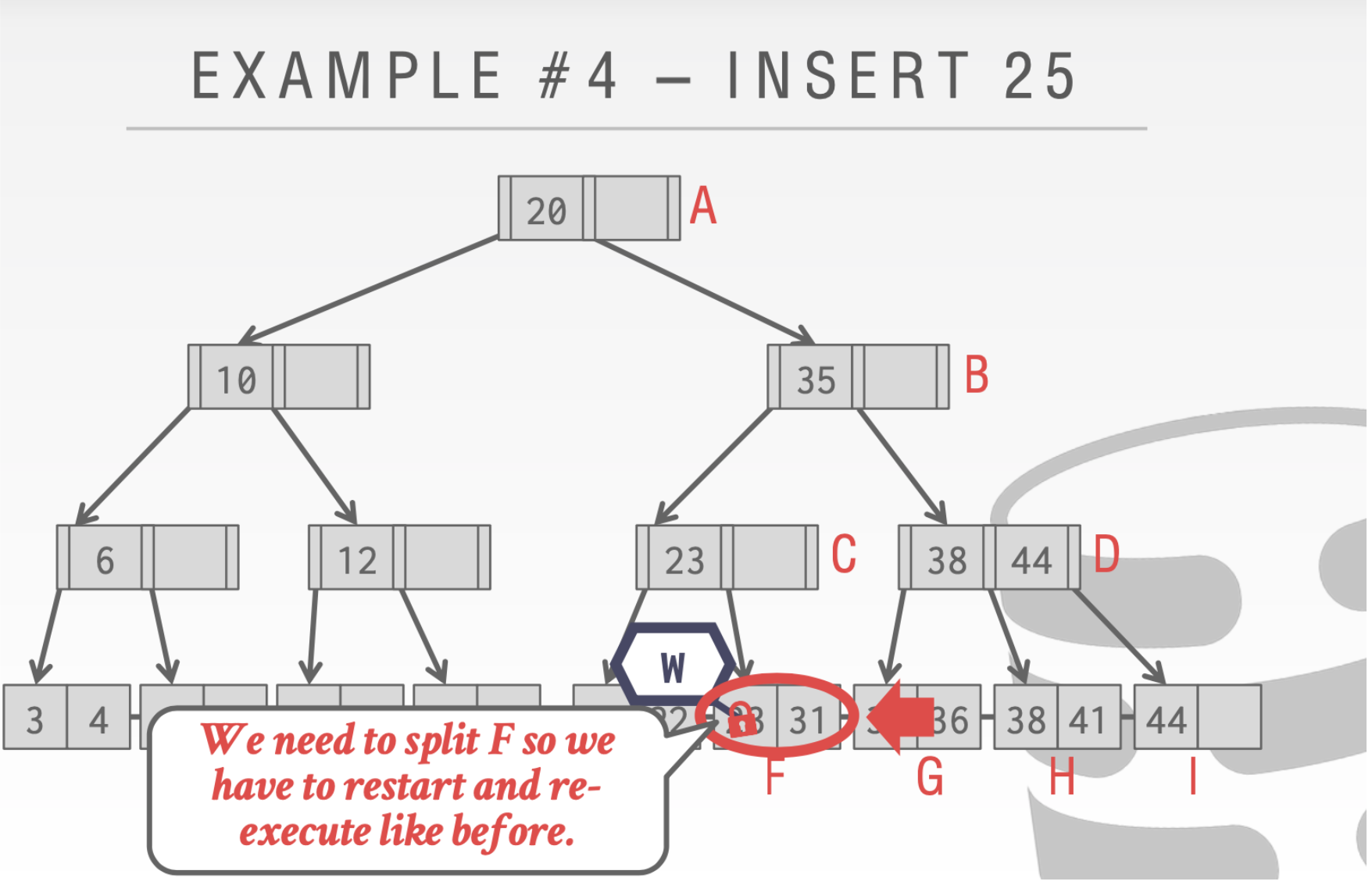
- 当我们到最后一步发现不安全的时候。则需要像上面我们没有引入乐观的时候一样。重新执行一遍
B-Link Tree简介
延迟更新父结点
这里用一个来标记这里需要被更新但是还没有执行
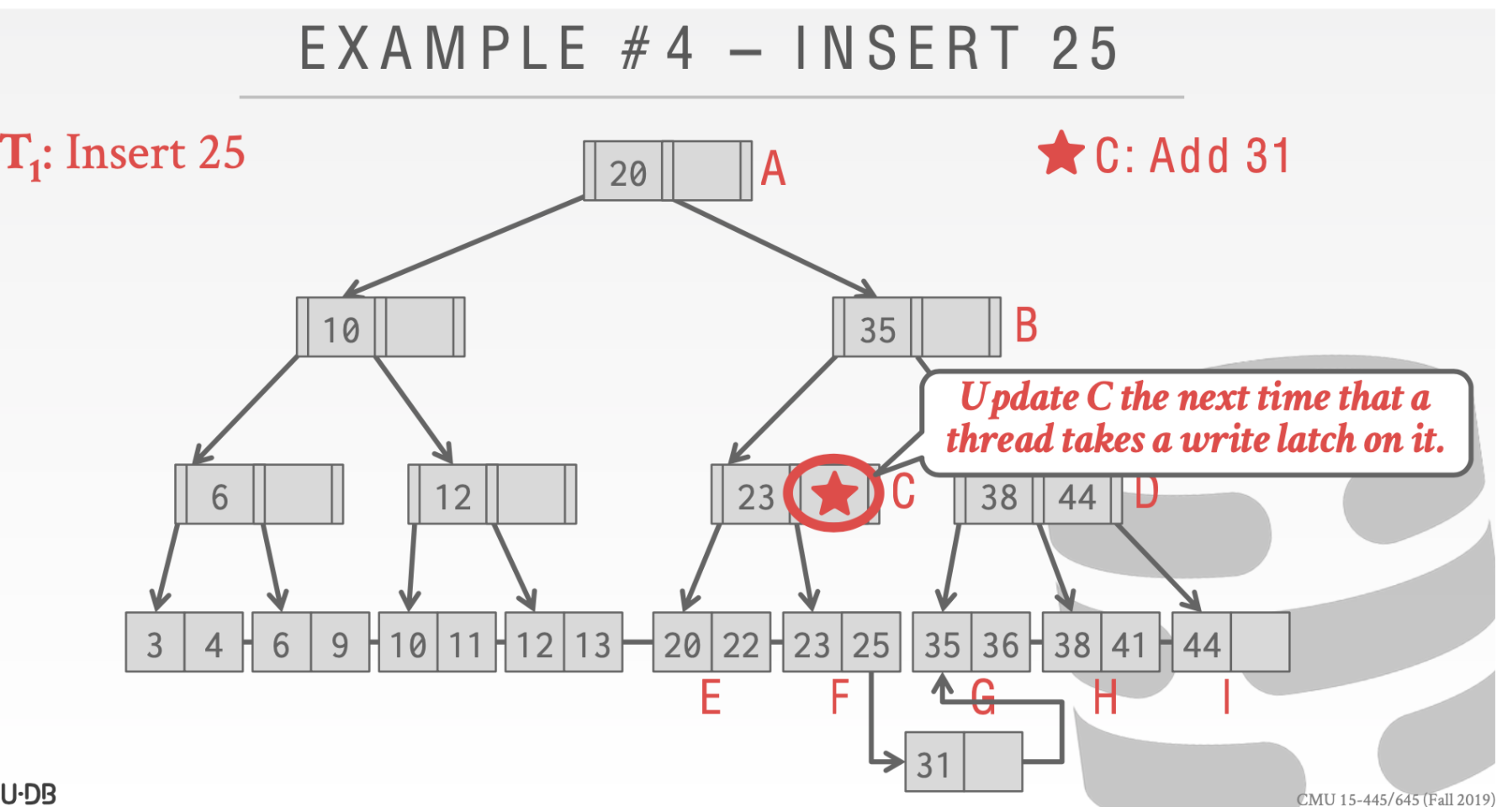
这个时候我们执行其他操作也是正确的比如查找31
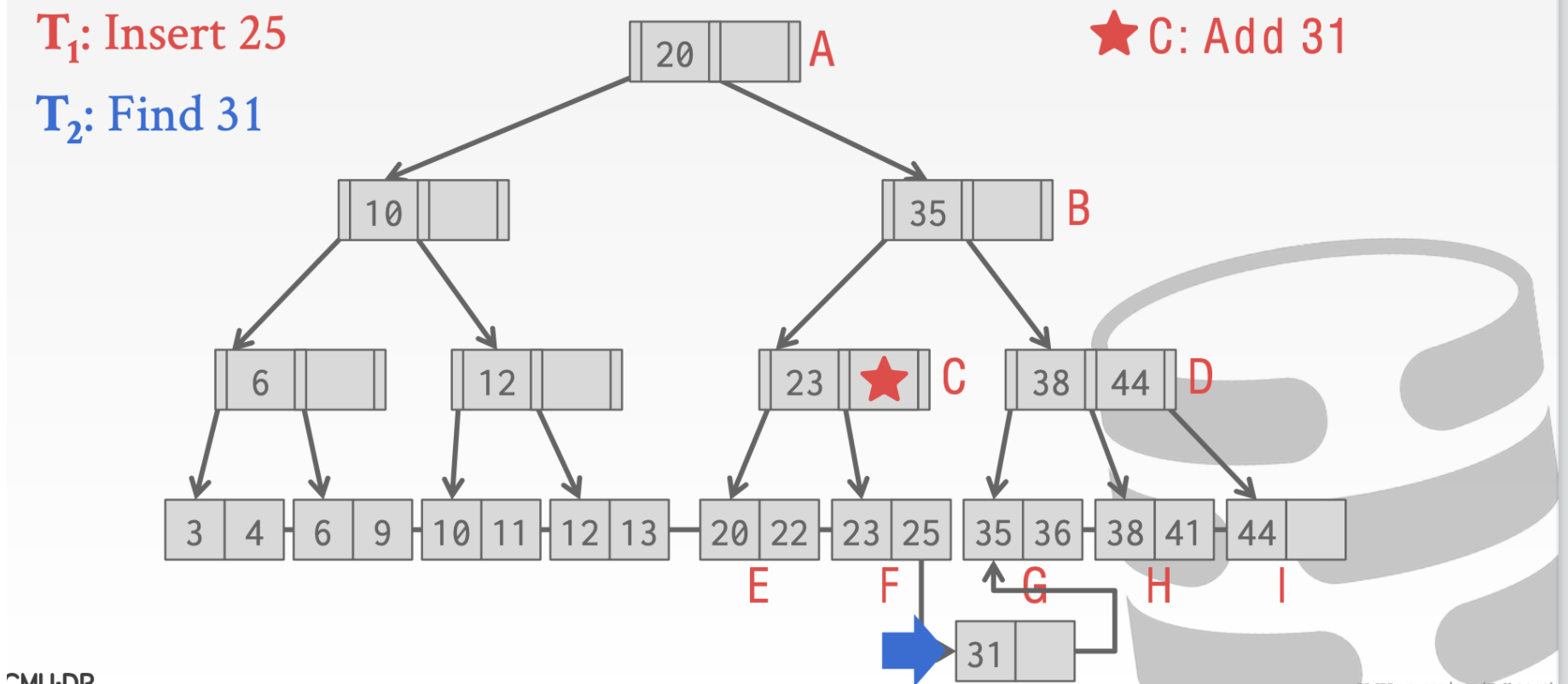
这里我们执行insert 33
当执行到结点C的时候。因为这个时候有另一个线程持有了write Latch。所以这个时候操作要执行。随后在插入33
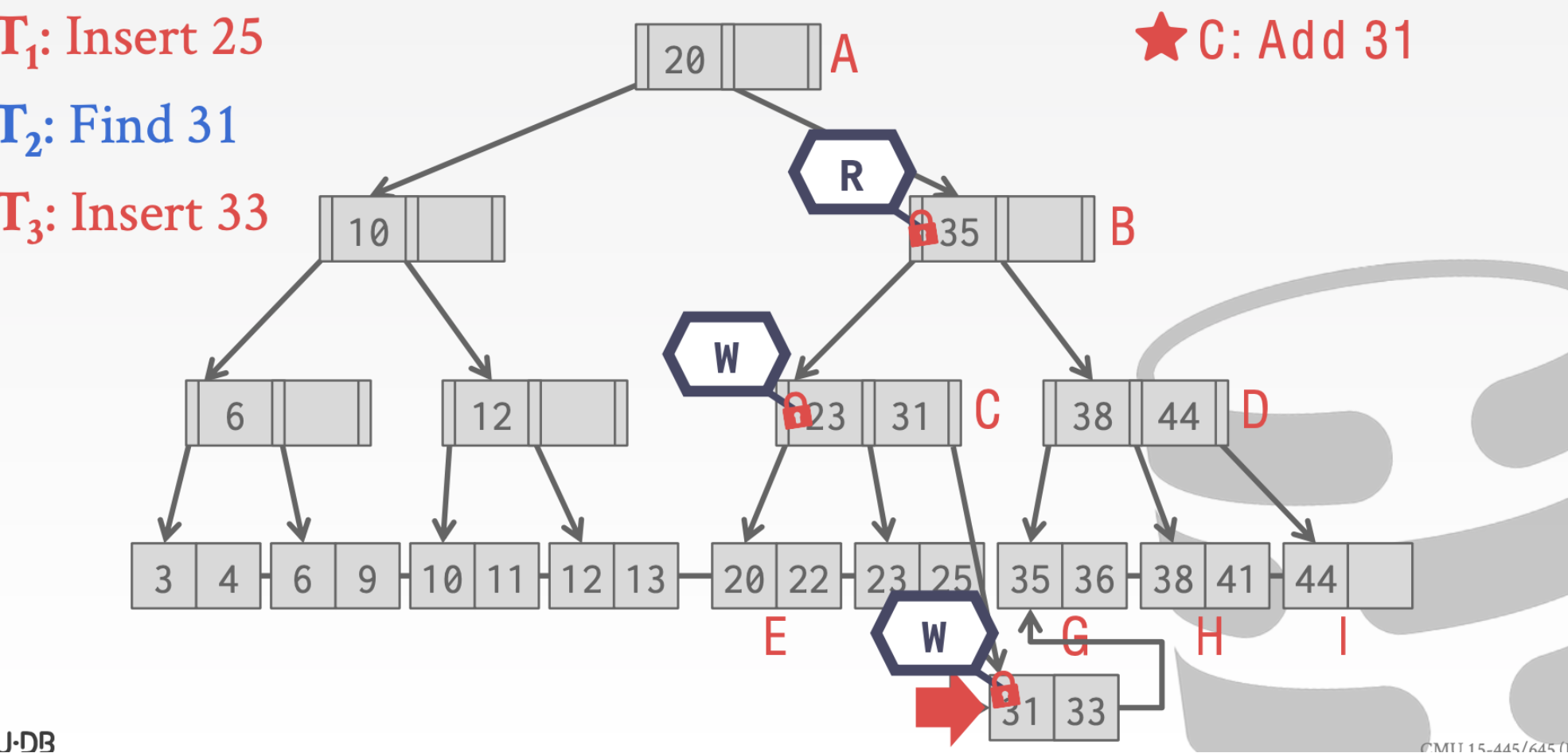
最后一点补充关于扫描操作的
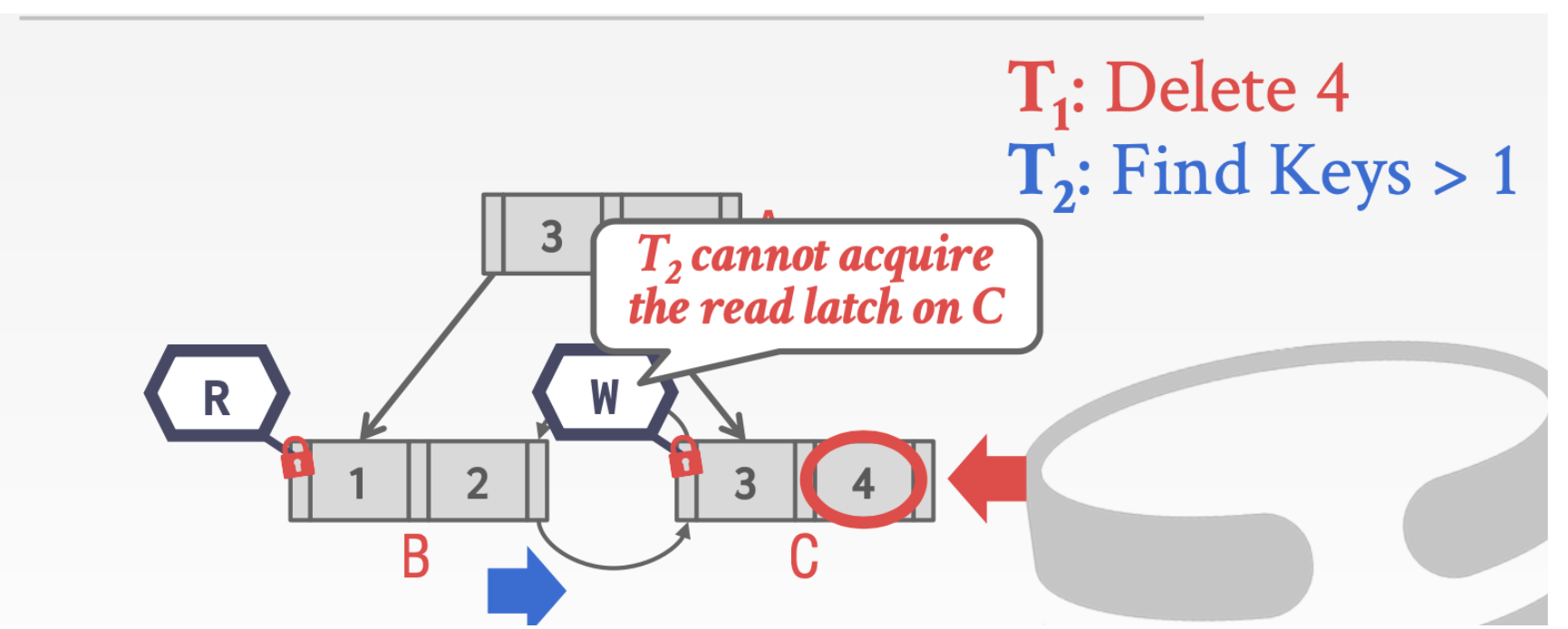
- 线程1在C结点上持有write Latch
- 线程2已经扫描完了结点B想要获得结点C的read Latch
这时候会发生问题,因为线程2无法拿到read Latch
这里有几种解决方法
- 可以等到T1的写操作完成
- 可以重新执行T2
- 可以直接让线程T2停止抢得这个Latch。
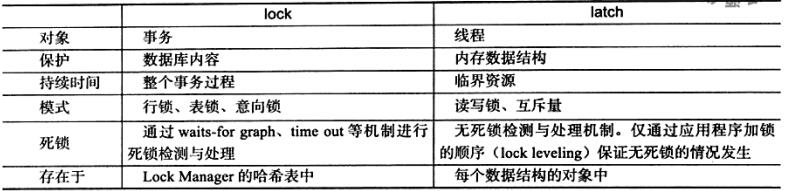
注意这里的Latch和Lock并不一样
1. 辅助函数UnlockUnpinPages的实现
- 如果是读操作则释放read锁
- 否则释放write锁
INDEX_TEMPLATE_ARGUMENTS
void BPLUSTREE_TYPE::
UnlockUnpinPages(Operation op, Transaction *transaction) {
if (transaction == nullptr) {
return;
}
for (auto page:*transaction->GetPageSet()) {
if (op == Operation::READ) {
page->RUnlatch();
buffer_pool_manager_->UnpinPage(page->GetPageId(), false);
} else {
page->WUnlatch();
buffer_pool_manager_->UnpinPage(page->GetPageId(), true);
}
}
transaction->GetPageSet()->clear();
for (const auto &page_id: *transaction->GetDeletedPageSet()) {
buffer_pool_manager_->DeletePage(page_id);
}
transaction->GetDeletedPageSet()->clear();
// if root is locked, unlock it
node_mutex_.unlock();
}
四个自带的解锁和上锁操作
/** Acquire the page write latch. */
inline void WLatch() { rwlatch_.WLock(); }
/** Release the page write latch. */
inline void WUnlatch() { rwlatch_.WUnlock(); }
/** Acquire the page read latch. */
inline void RLatch() { rwlatch_.RLock(); }
/** Release the page read latch. */
inline void RUnlatch() { rwlatch_.RUnlock(); }
这里的rwlatch是自己实现的读写锁类下面来探究一下这个类
由于c++ 并发编程我现在还不太会。。。所以就简单看一下啦后面学完并发编程再补充
WLock函数- 首先获取一个锁
- 用一个记号
writer_entered表示是否有写操作 - 如果之前已经有了现在的操作就需要等(这个线程处于阻塞状态)
- 当前如果有其他线程执行读操作。则仍需要阻塞(别人读的时候你不能写)
void WLock() {
std::unique_lock<mutex_t> latch(mutex_);
while (writer_entered_) {
reader_.wait(latch);
}
writer_entered_ = true;
while (reader_count_ > 0) {
writer_.wait(latch);
}
}
WunLock函数- 写标记置为false
- 然后通知所有的线程
void WUnlock() {
std::lock_guard<mutex_t> guard(mutex_);
writer_entered_ = false;
reader_.notify_all();
}
RLock函数- 如果当前有人在写或者已经有最多的人读了则阻塞
- 否则只需要让读的计数++
因为是允许多个线程一起读这样并不会出错
void RLock() {
std::unique_lock<mutex_t> latch(mutex_);
while (writer_entered_ || reader_count_ == MAX_READERS) {
reader_.wait(latch);
}
reader_count_++;
}
RUnLatch函数- 计数--
- 如果当前有人在写并且无人读的话需要通知所有其他线程
- 如果在计数--之前达到了最大读数,释放这个锁之后需要通知其他线程,现在又可以读了。
void RUnlock() {
std::lock_guard<mutex_t> guard(mutex_);
reader_count_--;
if (writer_entered_) {
if (reader_count_ == 0) {
writer_.notify_one();
}
} else {
if (reader_count_ == MAX_READERS - 1) {
reader_.notify_one();
}
}
}
6. Summary
好了终于磕磕绊绊的写完了Lab2.关于数据库的Lab2应该会停一段时间。这段时间要补一补深度学习(毕竟要毕业)然后赶工一下老师给的活。同时学一下c++并发编程和看一下侯捷老师的课程。
最后附上GitHub的
https://github.com/JayL-zxl/CMU15-445Lab
[已完结]CMU数据库(15-445)实验2-B+树索引实现(下)的更多相关文章
- CMU数据库(15-445)实验2-B+树索引实现(下+课上笔记)
4. Index_Iterator实现 这里就是需要实现迭代器的一些操作,比如begin.end.isend等等 下面是对于IndexIterator的构造函数 template <typena ...
- CMU数据库(15-445)实验2-b+树索引实现(上)
Lab2 在做实验2之前请确保实验1结果的正确性.不然你的实验2将无法正常进行 环境搭建地址如下 https://www.cnblogs.com/JayL-zxl/p/14307260.html 实验 ...
- Lenovo k860i 移植Android 4.4 cm11进度记录【上篇已完结】
2014.5.16 为了验证一下下载的CM11的源码有没有问题,决定编译一下cm官方支持的机器,手上正好有台nexus7 2012,就拿它为例测试一下在mac os x平台的整个编译过程. 1. 最开 ...
- [Android]如何导入已有的外部数据库
转自:http://www.cnblogs.com/xiaowenji/archive/2011/01/03/1925014.html 我们平时见到的android数据库操作一般都是在程序开始时创建一 ...
- CMU数据库(15-445)Lab0-环境搭建
0.写在前面 从这篇文章开始.开一个新坑,记录以下自己做cmu数据库实验的过程,同时会分析一下除了要求我们实现的代码之外的实验自带的一些代码.争取能够对实现一个数据库比较了解.也希望能写进简历.让自己 ...
- CMU数据库(15-445)Lab3- QUERY EXECUTION
Lab3 - QUERY EXECUTION 实验三是添加对在数据库系统中执行查询的支持.您将实现负责获取查询计划节点并执行它们的executor.您将创建执行下列操作的executor Access ...
- 《Entity Framework 6 Recipes》翻译系列 (4) -----第二章 实体数据建模基础之从已存在的数据库创建模型
不知道对EF感兴趣的并不多,还是我翻译有问题(如果是,恳请你指正),通过前几篇的反馈,阅读这个系列的人不多.不要这事到最后成了吃不讨好的事就麻烦了,废话就到这里,直奔主题. 2-2 从已存在的数据库创 ...
- 使用EF对已存在的数据库进行模块化数据迁移
注:本文面向的是已经对EF的迁移功能有所了解,知道如何在控制台下进行相关命令输入的读者 问题 最近公司项目架构使用ABP进行整改,顺带想用EF的自动迁移代替了以前的手工脚本. 为什么要替代? 请看下图 ...
- 如何把已有SQLSERVER数据库更名而且附加到数据库中?
如何把已有SQLSERVER数据库更名而且附加到数据库中? 例如:已有数据库:zrmaa,希望更名为jjsh 特别提醒:数据库名中不能加入下划线,因为数据库日志文件有下划线. 把数据库文件mdf和数据 ...
随机推荐
- MySQL数据归档小工具推荐--mysql_archiver
一.主要概述 MySQL数据库归档历史数据主要可以分为三种方式:一.创建编写SP.设置Event:二.通过dump导入导出:三.通过pt-archiver工具进行归档.第一种方式往往受限于同实例要求, ...
- 制作3D小汽车游戏(下)
书接上回,这一节我们分模块说一说怎么写一个这样的游戏 1. 初始化场景.相机和渲染器 这几乎是绘制three必须做的事情,我们有两套场景和相机,一个是主场景和相机,另一个是小地图的场景和相机(用来俯视 ...
- H3C S5120V2-SI 交换机配置
连接终端线 可以看到开机信息 ......................................................................Done. System is ...
- Ubuntu Server 16.04.1 LTS 64位 搭建LNMP环境
安装配置 Nginx 为了确保获得最新的 Nginx,先使用sudo apt-get update命令更新源列表.安装 Nginx,输入命令:sudo apt-get install nginx. 启 ...
- 将后端返回的数据在jsp中拼接成table列表
//先下载jquery js文件 放入项目中 jsp文件内容 <%@ page language="java" pageEncoding="UTF-8"% ...
- RTC_Configuration
Void RTC_Configuration(void)// 实时时钟的初始化配置 { RCC_APB1PeriphClockCmd(RCC_APB1Periph_PWR | RCC_APB1Peri ...
- springboot容器启动顺序之@Configuration ContextRefreshedEvent事件初始化 ApplicationRunner
笔者最近遇到一个问题 我们根据自己业务需要 需要首次启动springboot项目时 把数据库数据同步至本地缓存(比如ehcache)但有一个要求 在缓存未载入成功 不允许有流量打入 一开始我们使用 ...
- SpringBoot整合Shiro权限框架实战
什么是ACL和RBAC ACL Access Control list:访问控制列表 优点:简单易用,开发便捷 缺点:用户和权限直接挂钩,导致在授予时的复杂性,比较分散,不便于管理 例子:常见的文件系 ...
- Java并发包源码学习系列:CLH同步队列及同步资源获取与释放
目录 本篇学习目标 CLH队列的结构 资源获取 入队Node addWaiter(Node mode) 不断尝试Node enq(final Node node) boolean acquireQue ...
- 【Flutter】功能型组件之异步UI更新
前言 很多时候会依赖一些异步数据来动态更新UI,比如在打开一个页面时我们需要先从互联网上获取数据,在获取数据的过程中我们显示一个加载框,等获取到数据时我们再渲染页面:又比如想展示Stream(比如文件 ...