Solr的原理及使用
1.Solr的简介
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
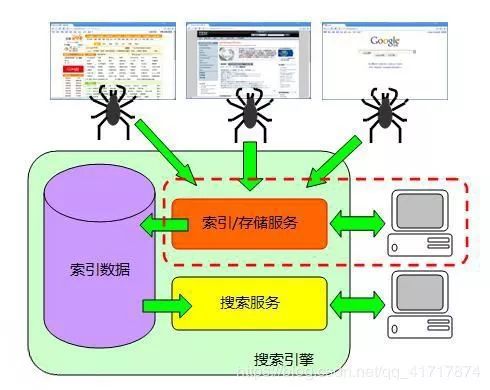
2.工作原理
solr是基于Lucence开发的企业级搜索引擎技术,而lucence的原理是倒排索引。那么什么是倒排索引呢?接下来我们就介绍一下lucence倒排索引原理。
假设有两篇文章1和2:
文章1的内容为:老超在卡子门工作,我也是。
文章2的内容为:小超在鼓楼工作。
由于lucence是基于关键词索引查询的,那我们首先要取得这两篇文章的关键词。如果我们把文章看成一个字符串,我们需要取得字符串中的所有单词,即分词。分词时,忽略”在“、”的“之类的没有意义的介词,以及标点符号可以过滤。
我们使用Ik Analyzer实现中文分词,分词之后结果为:
文章1:
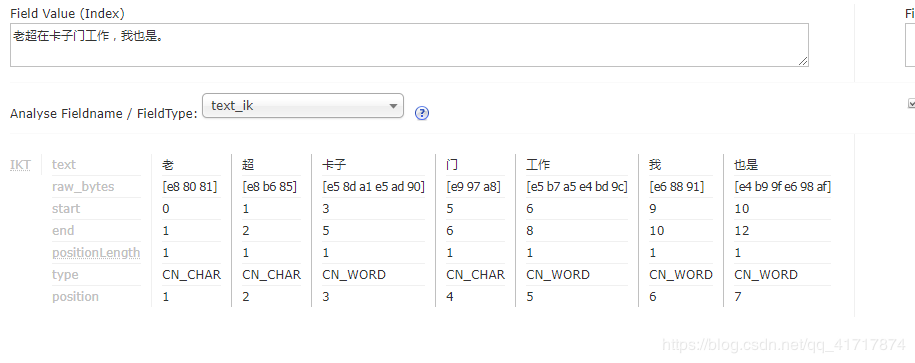
文章2:

接下来,有了关键词后,我们就可以建立倒排索引了。上面的对应关系是:“文章号”对“文章中所有关键词”。倒排索引把这个关系倒过来,变成: “关键词”对“拥有该关键词的所有文章号”。

通常仅知道关键词在哪些文章中出现还不够,我们还需要知道关键词在文章中出现次数和出现的位置,通常有两种位置:
a.字符位置,即记录该词是文章中第几个字符(优点是关键词亮显时定位快);
b.关键词位置,即记录该词是文章中第几个关键词(优点是节约索引空间、词组(phase)查询快),lucene中记录的就是这种位置。
加上出现频率和出现位置信息后,我们的索引结构变为:

实现时,lucene将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件 (positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
3.使用SolrJ管理索引库
使用SolrJ可以实现索引库的增删改查操作。
3.1 添加文档
第一步:把solrJ的jar包添加到工程中。
第二步:创建一个SolrServer,使用HttpSolrServer创建对象。
第三步:创建一个文档对象SolrInputDocument对象。
第四步:向文档中添加域。必须有id域,域的名称必须在schema.xml中定义。
第五步:把文档添加到索引库中。
第六步:提交。
public voidtestSolrJAdd() throws SolrServerException, IOException {
// 创建一个SolrServer对象。创建一个HttpSolrServer对象
// 需要指定solr服务的url
SolrServer solrServer = newHttpSolrServer( "http://101.132.69.111:8080/solr/collection1");
// 创建一个文档对象SolrInputDocument
SolrInputDocument document= newSolrInputDocument();
// 向文档中添加域,必须有id域,域的名称必须在schema.xml中定义
document.addField( "id", "123");
document.addField( "item_title", "红米手机");
document.addField( "item_price", 1000);
// 把文档对象写入索引库
solrServer.add( document);
// 提交
solrServer.commit();
}
3.2 删除文档
3.2.1 根据id删除
第一步:创建一个SolrServer对象。
第二步:调用SolrServer对象的根据id删除的方法。
第三步:提交。
publicvoiddeleteDocumentById()throwsException {
SolrServer solrServer = newHttpSolrServer( "http://101.132.69.111:8080/solr/collection1");
solrServer.deleteById( "123");
// 提交
solrServer.commit();
}
3.2.2 根据查询删除
publicvoiddeleteDocumentByQuery()throwsException {
SolrServer solrServer = newHttpSolrServer( "http://101.132.69.111:8080/solr/collection1");
//这边会根据分词去删
solrServer.deleteByQuery( "item_title:红米手机");
solrServer.commit();
}
3.3 查询索引库
第一步:创建一个SolrServer对象
第二步:创建一个SolrQuery对象。
第三步:向SolrQuery中添加查询条件、过滤条件。
第四步:执行查询。得到一个Response对象。
第五步:取查询结果。
第六步:遍历结果并打印。
3.3.1 简单查询
publicvoidqueryDocument() throws Exception {
// 第一步:创建一个SolrServer对象
SolrServer solrServer = newHttpSolrServer( "http://101.132.69.111:8080/solr/collection1");
// 第二步:创建一个SolrQuery对象。
SolrQuery query = newSolrQuery();
// 第三步:向SolrQuery中添加查询条件、过滤条件。。。
query.setQuery( "*:*");
// 第四步:执行查询。得到一个Response对象。
QueryResponse response = solrServer.query(query);
// 第五步:取查询结果。
SolrDocumentList solrDocumentList = response.getResults();
System. out.println( "查询结果的总记录数:"+ solrDocumentList.getNumFound());
// 第六步:遍历结果并打印。
for(SolrDocument solrDocument : solrDocumentList) {
System. out.println(solrDocument. get( "id"));
System. out.println(solrDocument. get( "item_title"));
System. out.println(solrDocument. get( "item_price"));
}
}
3.3.2 带高亮显示
public voidsearchDocumet() throws Exception {
// 创建一个SolrServer对象
SolrServer solrServer = newHttpSolrServer( "http://101.132.69.111:8080/solr/collection1");
// 创建一个SolrQuery对象
SolrQuery query = newSolrQuery();
// 设置查询条件、过滤条件、分页条件、排序条件、高亮
// query.set("q", "*:*");
query.setQuery( "手机");
// 分页条件
query.setStart( 0);
query.setRows( 30);
// 设置默认搜索域
query. set( "df", "item_keywords");
// 设置高亮
query.setHighlight( true);
// 高亮显示的域
query.addHighlightField( "item_title");
query.setHighlightSimplePre( "<div>");
query.setHighlightSimplePost( "</div>");
// 执行查询,得到一个Response对象
QueryResponse response = solrServer.query(query);
// 取查询结果
SolrDocumentList solrDocumentList = response.getResults();
// 取查询结果总记录数
System.out.println( "查询结果总记录数:"+ solrDocumentList.getNumFound());
for(SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument. get( "id"));
// 取高亮显示
Map< String, Map< String, List< String>>> highlighting = response.getHighlighting();
List< String> list = highlighting. get(solrDocument. get( "id")). get( "item_title");
StringitemTitle = "";
if(list != null&& list.size() > 0) {
itemTitle = list. get( 0);
} else{
36itemTitle = ( String) solrDocument. get( "item_title");
}
System.out.println(itemTitle);
System.out.println(solrDocument. get( "item_sell_point"));
System.out.println(solrDocument. get( "item_price"));
System.out.println(solrDocument. get( "item_image"));
System.out.println(solrDocument. get( "item_category_name"));
}
4.Solr服务器中的后台数据处理
这个其实是通过图形界面操作,只需手动填写查询条件,不需要进行代码处理。但是实际项目开发中,还是需要进行代码编写的。
solr的基础语法
1.q 查询的关键字,此参数最为重要,例如,q= id: 1,默认为q=*:*,
2.fq (filter query)过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果
3.sort 排序方式,例如 iddesc 表示按照 “ id” 降序
4.start 返回结果的第几条记录开始,一般分页用,默认 0开始
5.rows 指定返回结果最多有多少条记录,默认值为 10,配合start实现分页
6.fl 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如fl= id,title,sort
7.df 默认的查询字段,一般默认指定
8.wt (writer type)指定输出格式,有 xml, json, php等
9.indent 返回的结果是否缩进,默认关闭0
10.hl 高亮
10.1.hl.fl 设定高亮显示的字段
10.2.hl.requireFieldMatch 如果置为 true,除非用hl.fl指定了该字段,查询结果才会被高亮。它的默认值是 false。
10.3.hl.usePhraseHighlighter 如果一个查询中含有短语(引号框起来的)那么会保证一定要完全匹配短语的才会被高亮。
10.4.hl.highlightMultiTerm如果使用通配符和模糊搜索,那么会确保与通配符匹配的term会高亮。默认为 false,同时hl.usePhraseHighlighter要为 true。
10.5.hl.fragsize 返回的最大字符数。默认是 100.如果为 0,那么该字段不会被fragmented且整个字段的值会被返回。
Solr的原理及使用的更多相关文章
- solr全文检索原理及solr5.5.0 Windows部署
文章原理链接:http://blog.csdn.net/xiaoyu411502/article/details/44803859 自己稍微总结:全文检索主要有两个过程:创建索引,搜索索引 创建索引: ...
- solr replication原理探究
原文出自:http://sbp810050504.blog.51cto.com/2799422/1423199 无论是垂直搜索,还是通用搜索引擎,对外提供搜索服务其压力都比较大,经常有垂直电商在做活动 ...
- Solr缓存原理分析及配置优化
一.缓存原理 缓存,带来急速性能体验! Solr提供了一系列的内置缓存来优化查询性能.Solr的缓存原理主要涉及以下4个方面: 1.缓存大小及缓存置换法 从缓存大小的角度来看,不能将缓存设置的太大,否 ...
- Solr的原理及在项目中的使用实例.
前面已经讲过 如果安装及配置Solr服务器了, 那么现在我们就来正式在代码中使用Solr.1,这里Solr主要是怎么使用的呢? 当我们在前台页面搜索商品名称关键词时, 我们这时是在Solr库中去查找 ...
- Solr入门之(3)常用概念说明(持续补充):
由于solr底层使用lucene,所以很多概念与lucene相同,下面是几个常用的概念: * Document:一个要进行索引的单元,相当于数据库的一行纪录,任何想要被索引的数据,都必须转化为Docu ...
- Lucene/Solr开发经验
1.开篇语2.概述3.渊源4.初识Solr5.Solr的安装6.Solr分词顺序7.Solr中文应用的一个实例8.Solr的检索运算符 [开篇语]按照惯例应该写一篇技术文章了,这次结合Lucene/S ...
- 六、Solr高亮与Field权重
Solr高亮 原理 做搜索时,高亮是很常见的需求,那么Solr肯定也为高亮提供了支持.先解释下Solr高亮的原理,在我们设置了需要高亮显示的Field之后,查询得到的返回结果会多出来下面的内容: &q ...
- 一、Solr综述
什么是Solr搜索 我们经常会用到搜索功能,所以也比较熟悉,这里就简单的介绍一下搜索的原理. 当然只是介绍solr的原理,并不是搜索引擎的原理,那会更复杂. 流程图 这是一个非常简单的流程图: Use ...
- solr 从零学习开始
2010-10 目 录 1 1.1 1.2 1.2.1 1.2.2 1.2.3 1.2.4 1.2.5 1.2.6 1.2.7 1.3 1.3.1 1.3.2 1.4 1.4.1 1.4.2 1.4. ...
随机推荐
- Django学习路15_创建一个订单信息,并查询2020年\9月的信息都有哪些
在 app5.models.py 中添加一个 Order 表 class Order(models.Model): o_num = models.CharField(max_length= 16 ,u ...
- PHP array_fill() 函数
------------恢复内容开始------------ 实例 用给定的键值填充数组: <?php$a1=array_fill(3,4,"blue");print_r($ ...
- 小甲鱼零基础汇编语言学习笔记第五章之[BX]和loop指令
这一章主要介绍什么是[BX]以及loop(循环)指令怎么使用,loop和[BX]又怎么样相结合,段前缀又是什么鬼,以及如何使用段前缀. 1.[BX]的概念 [BX]和[0]类似 ...
- 2020牛客暑期多校训练营 第二场 C Cover the Tree 构造 贪心
LINK:Cover the Tree 最受挫的是这道题,以为很简单 当时什么都想不清楚. 先胡了一个树的直径乱搞的贪心 一直过不去.后来意识到这类似于最经典长链剖分优化贪心的做法 然后那个是求最大值 ...
- C++中unordered_map几种按键查询比较
unorder_map有3种常见按键查值方法. 使用头文件<unordered_map>和<iostream>,以及命名空间std. 第一种是按键访问.如果键存在,则返回键对应 ...
- 强烈推荐的 IntelliJ IDEA 插件,别说我没告诉你
为什么你的 Intellij IDEA 没别人的好用?还不是因为你缺少这几个插件啊! 善用 Intellij IDEA 插件可以提高我们的开发效率,今天和大家一起分享一下实际工作中常用的几款能提升幸福 ...
- 十分钟搭建自己的私有NuGet服务器-BaGet
目录 前言 开始 搭建BaGet 上传程序包 在vs中使用 其他 最后 前言 NuGet是用于微软.NET(包括 .NET Core)开发平台的软件包管理器.NuGet能够令你在项目中添加.移除和更新 ...
- 9、Bridge 桥梁模式 将类的功能层次结构与实现层结构分离 结构型设计模式
1.何为桥接模式 桥接模式是一种将类的功能层次和实现层次分离的技术,所谓类的功能层次指的是类要实现什么功能,要定义多少个函数还进行处理,在功能之中我们会用到继承来定义新的方法同时也能使用父类的方法,这 ...
- PYTHON实战完整教程1-配置VSCode开发环境
一.安装 为降低学习门槛,保证学习目标的聚焦,我们在windows(使用WinServer2019虚拟机)上搭建开发环境.(系列教程最后结束时,也会部署到linux上) 打开Python官网 http ...
- Cayley-Hamilton 定理简要证明
证明思路来源于 DZYO 发的博客 Cayley-Hamilton 定理: 设 \(\textbf A\) 是 n阶矩阵,\(f(\lambda)=\det(\lambda\textbf I-\tex ...