卡耐基梅隆大学(CMU)元学习和元强化学习课程 | Elements of Meta-Learning

Goals for the lecture:
Introduction & overview of the key methods and developments.
[Good starting point for you to start reading and understanding papers!]
原文链接:

@
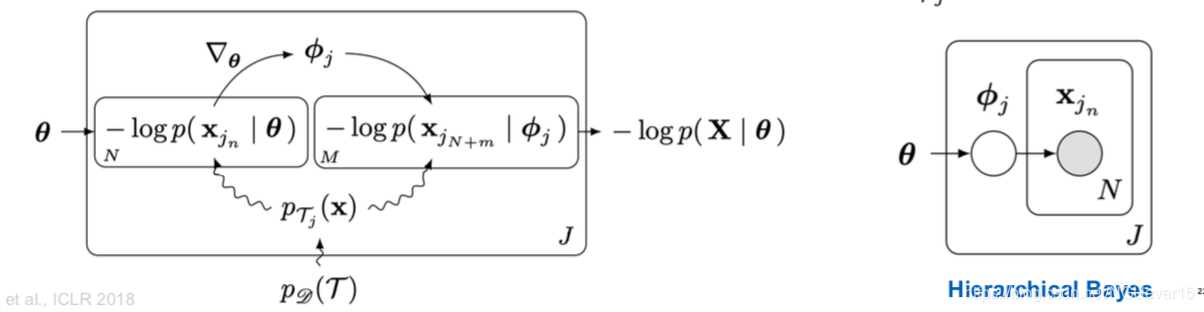
Probabilistic Graphical Models | Elements of Meta-Learning
01 Intro to Meta-Learning

Motivation and some examples
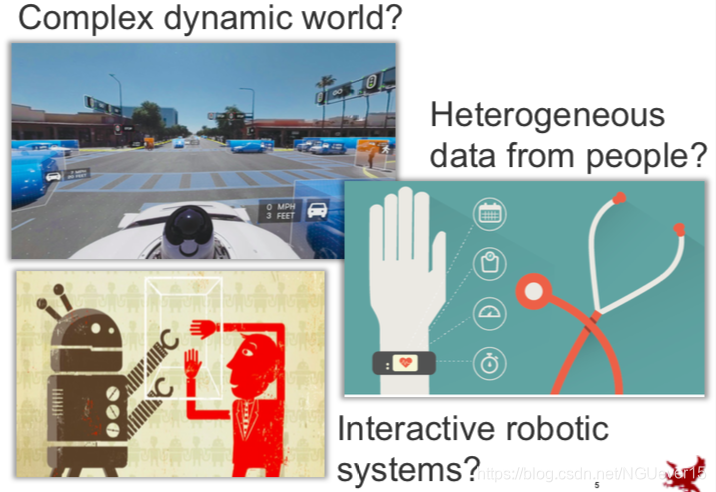
When is standard machine learning not enough?
Standard ML finally works for well-defined, stationary tasks.

But how about the complex dynamic world, heterogeneous data from people and the interactive robotic systems?
General formulation and probabilistic view
What is meta-learning?
Standard learning: Given a distribution over examples (single task), learn a function that minimizes the loss:
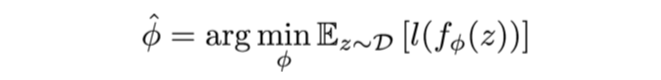
Learning-to-learn: Given a distribution over tasks, output an adaptation rule that can be used at test time to generalize from a task description
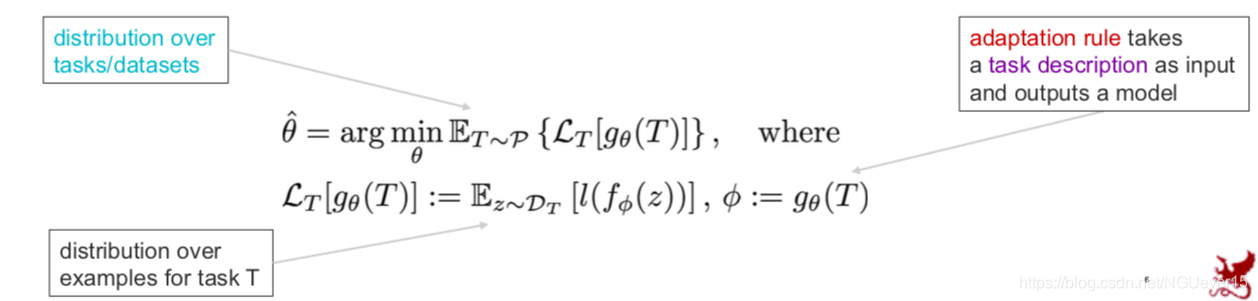
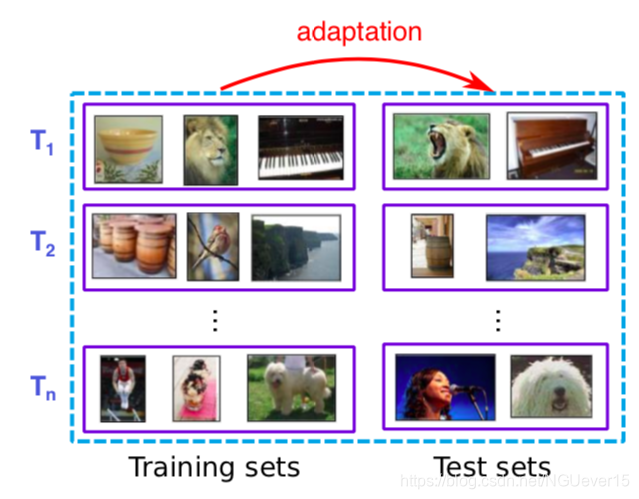
A Toy Example: Few-shot Image Classification

Other (practical) Examples of Few-shot Learning
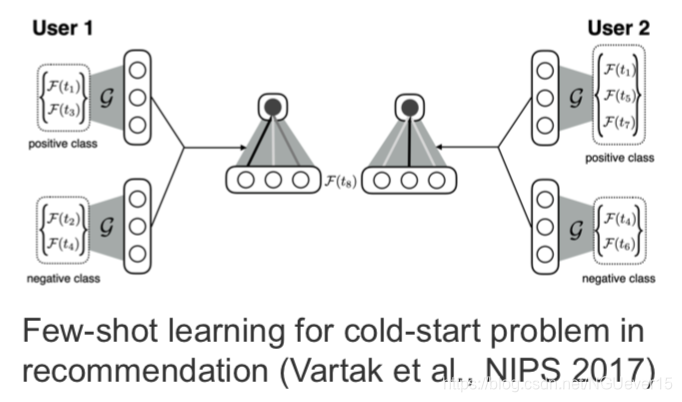
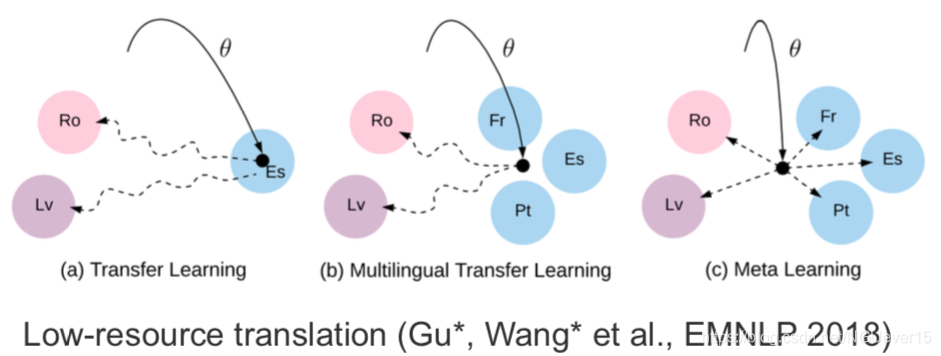
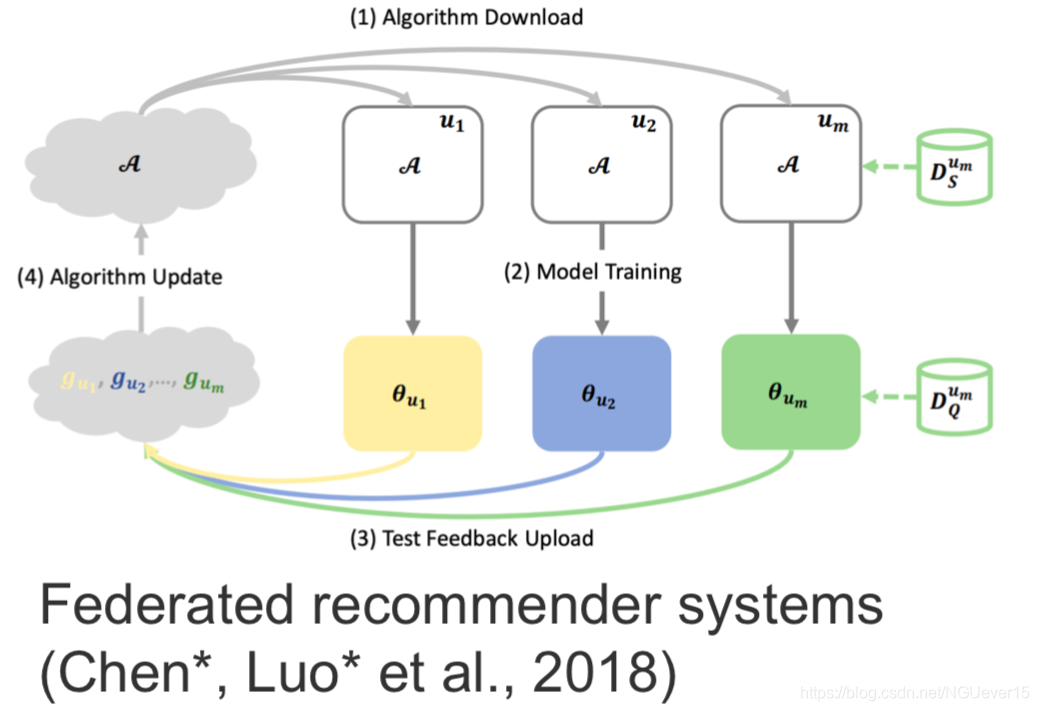

Gradient-based and other types of meta-learning
Model-agnostic Meta-learning (MAML) 与模型无关的元学习
- Start with a common model initialization \(\theta\)
- Given a new task \(T_i\) , adapt the model using a gradient step:
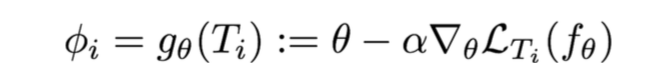
- Meta-training is learning a shared initialization for all tasks:
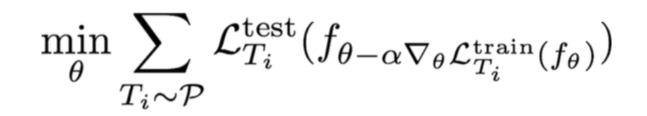
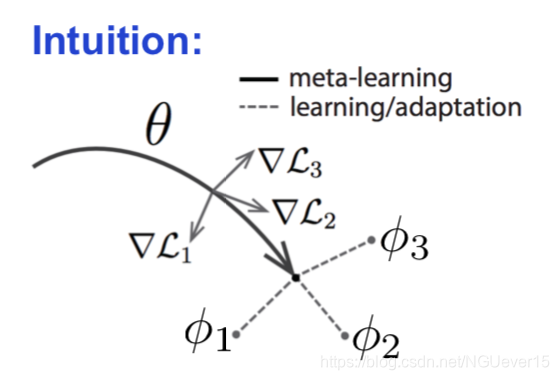
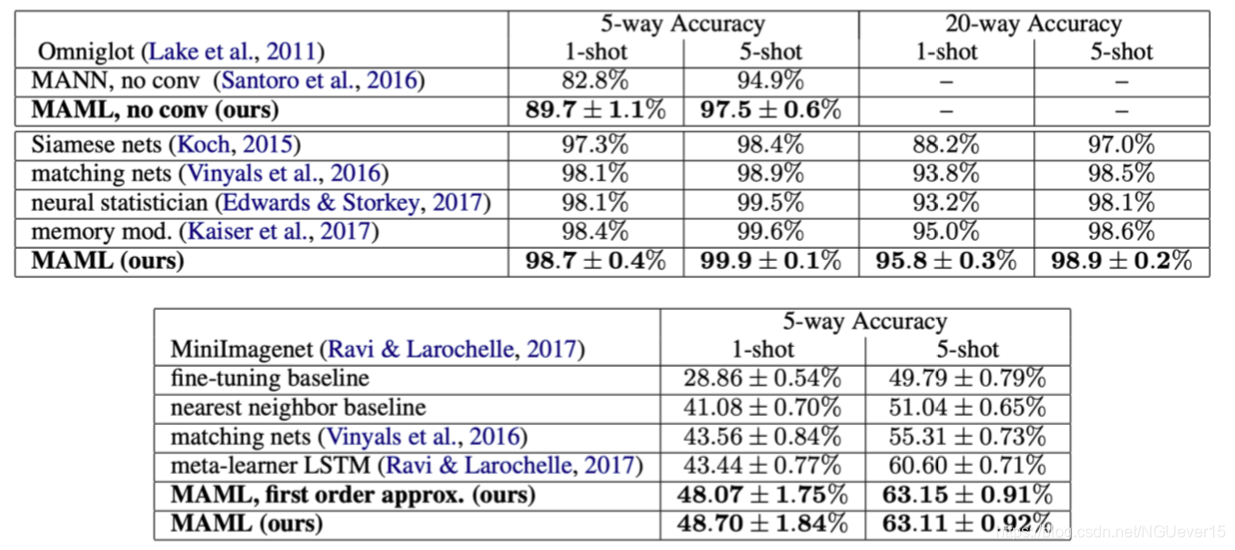
Does MAML Work?
MAML from a Probabilistic Standpoint
Training points: 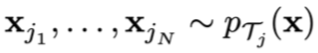
testing points: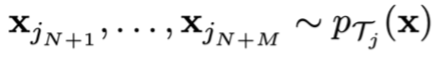
MAML with log-likelihood loss对数似然损失:
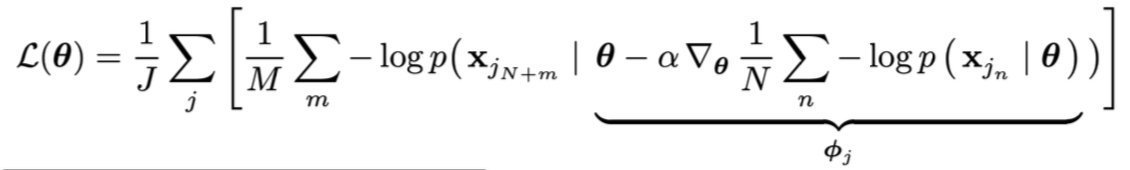
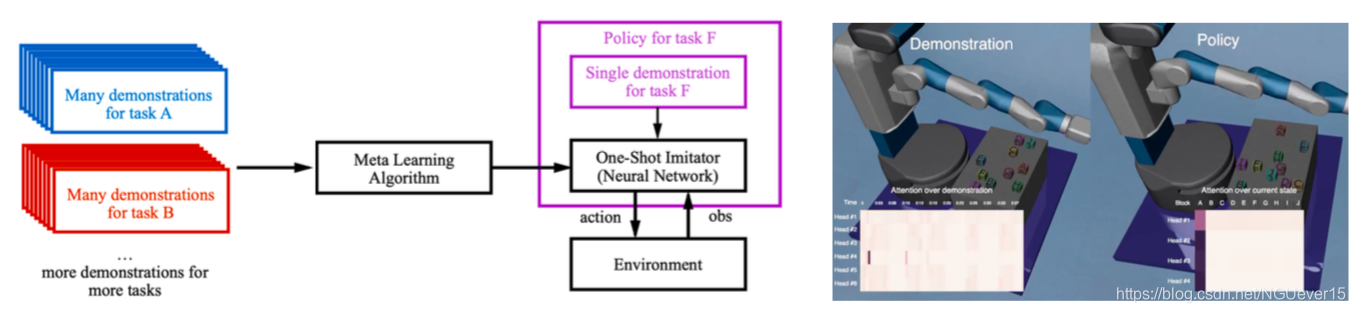
One More Example: One-shot Imitation Learning 模仿学习
Prototype-based Meta-learning
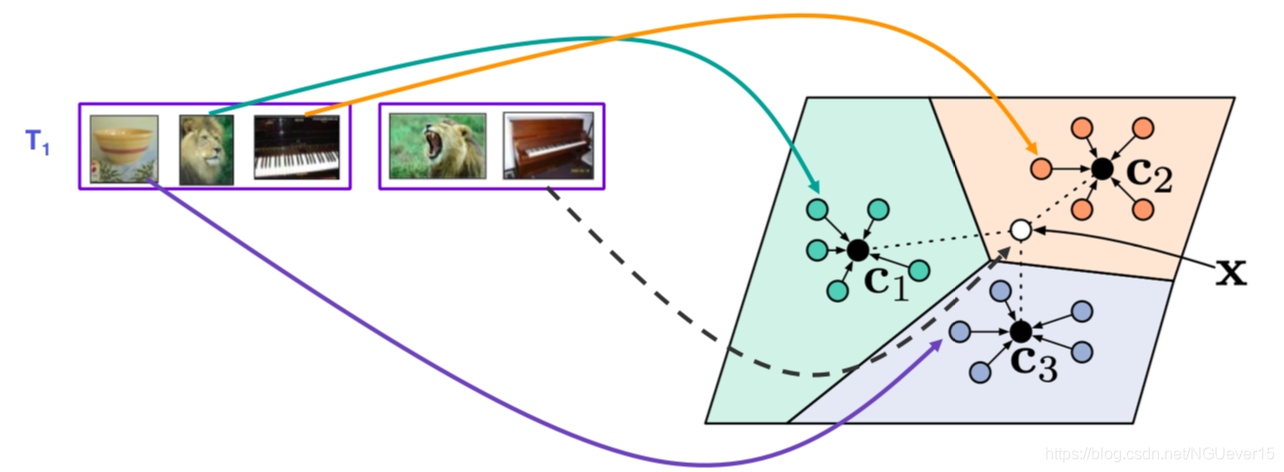
Prototypes:
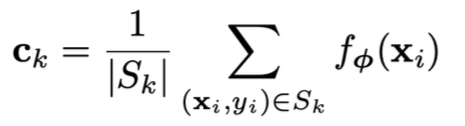
Predictive distribution:
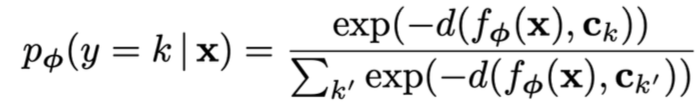
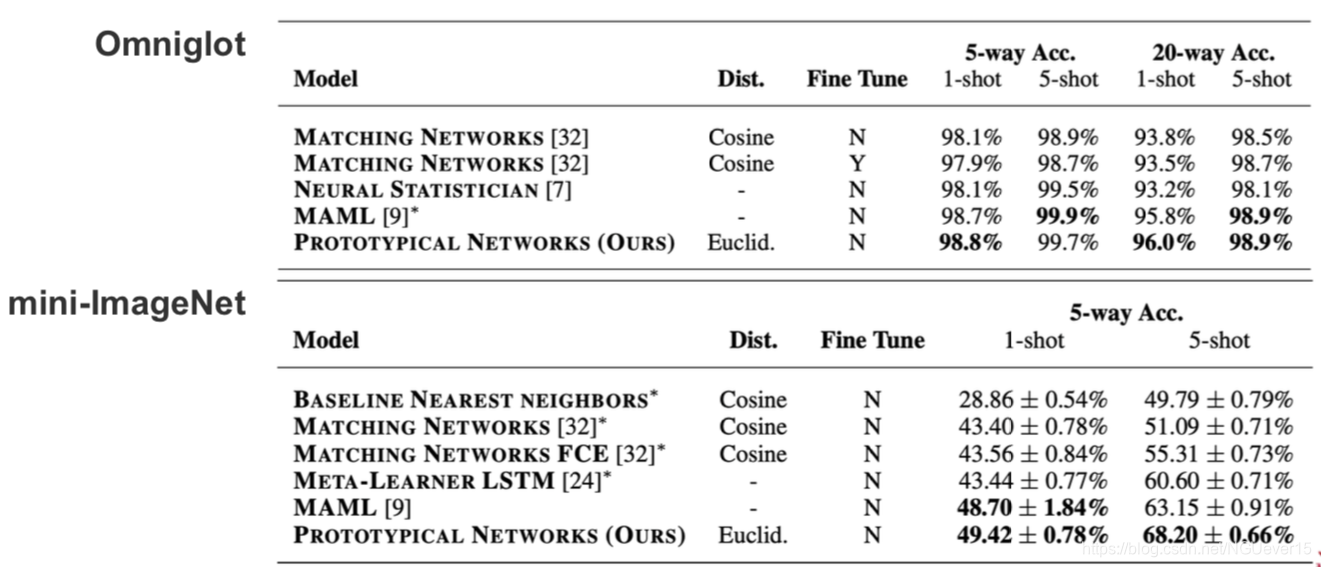
Does Prototype-based Meta-learning Work?
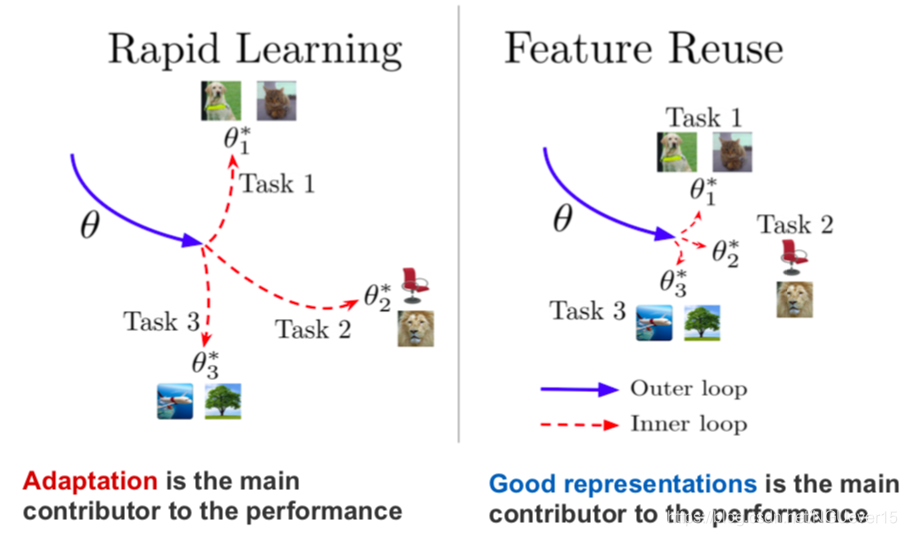
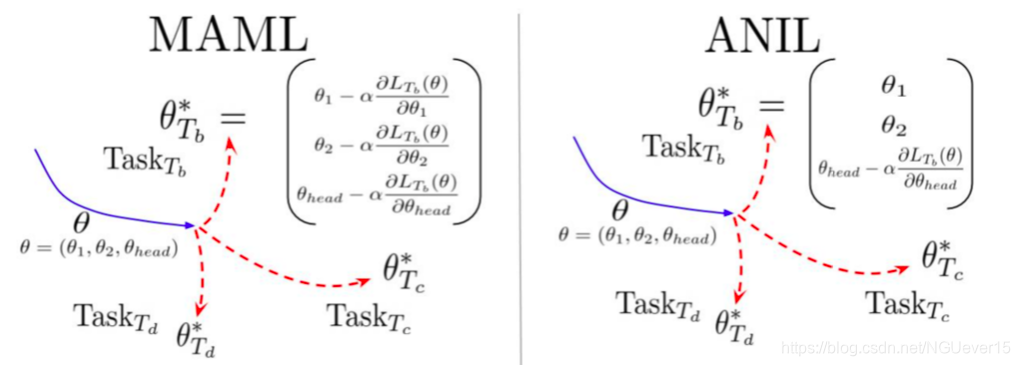
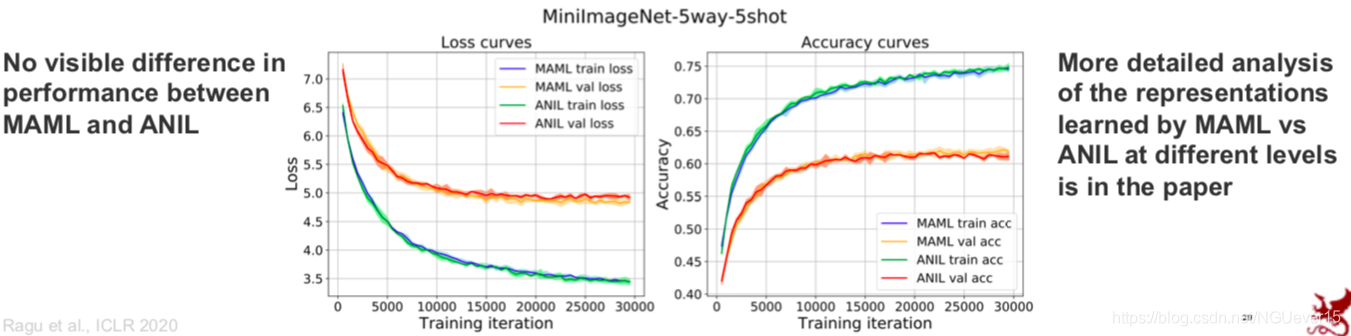
Rapid Learning or Feature Reuse 特征重用

Neural processes and relation of meta-learning to GPs
Drawing parallels between meta-learning and GPs
In few-shot learning:
- Learn to identify functions that generated the data from just a few examples.
- The function class and the adaptation rule encapsulate our prior knowledge.
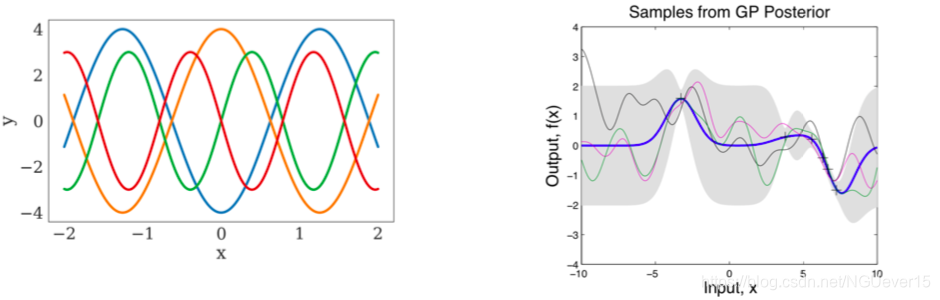
Recall Gaussian Processes (GPs): 高斯过程
- Given a few (x, y) pairs, we can compute the predictive mean and variance.
- Our prior knowledge is encapsulated in the kernel function.
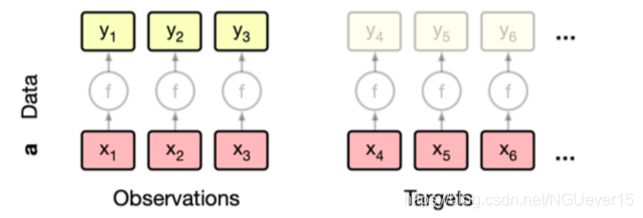
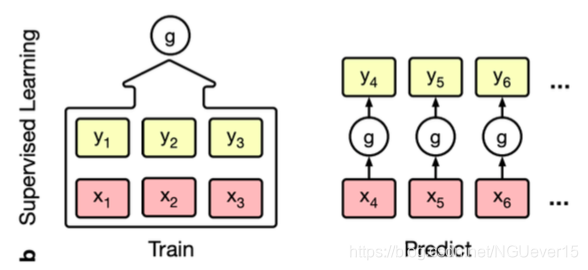
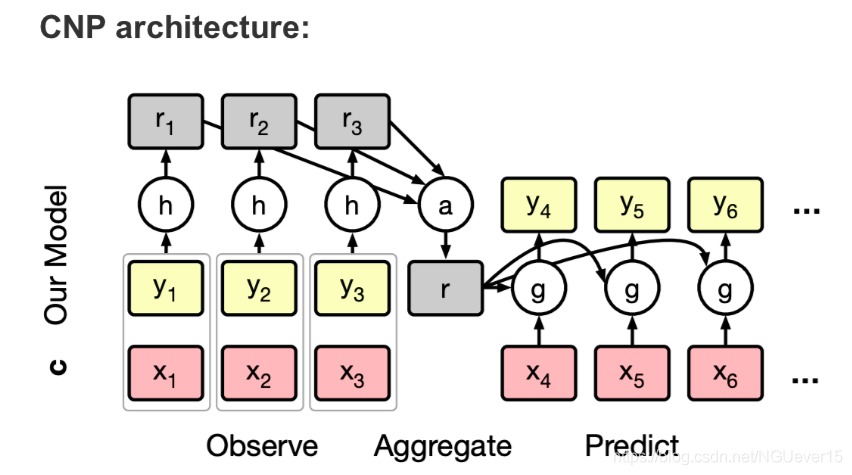
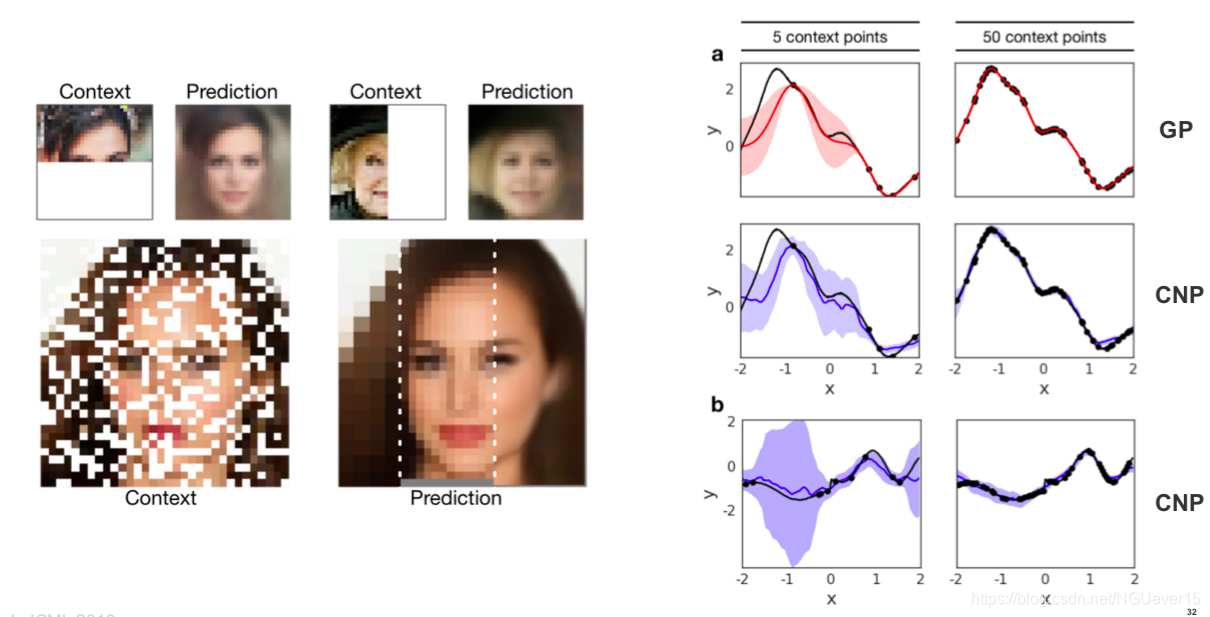
Conditional Neural Processes 条件神经过程
On software packages for meta-learning
A lot of research code releases (code is fragile and sometimes broken)
A few notable libraries that implement a few specific methods:
- Torchmeta (https://github.com/tristandeleu/pytorch-meta)
- Learn2learn (https://github.com/learnables/learn2learn)
- Higher (https://github.com/facebookresearch/higher)

Takeaways
- Many real-world scenarios require building adaptive systems and cannot be solved using “learn-once” standard ML approach.
- Learning-to-learn (or meta-learning) attempts extend ML to rich multitask scenarios—instead of learning a function, learn a learning algorithm.
- Two families of widely popular methods:
- Gradient-based meta-learning (MAML and such)
- Prototype-based meta-learning (Protonets, Neural Processes, ...)
- Many hybrids, extensions, improvements (CAIVA, MetaSGD, ...)
- Is it about adaptation or learning good representations? Still unclear and depends on the task; having good representations might be enough.
- Meta-learning can be used as a mechanism for causal discovery.因果发现 (See Bengio et al., 2019.)
02 Elements of Meta-RL
What is meta-RL and why does it make sense?
Recall the definition of learning-to-learn
Standard learning: Given a distribution over examples (single task), learn a function that minimizes the loss:
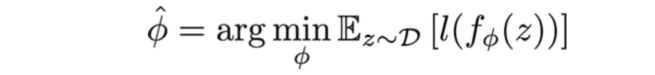
Learning-to-learn: Given a distribution over tasks, output an adaptation rule that can be used at test time to generalize from a task description
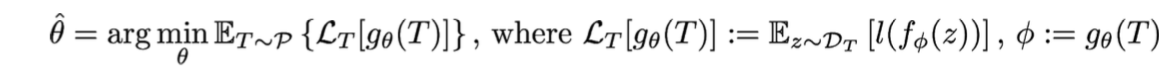
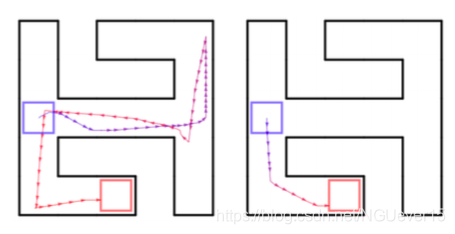
Meta reinforcement learning (RL): Given a distribution over environments, train a policy update rule that can solve new environments given only limited or no initial experience.
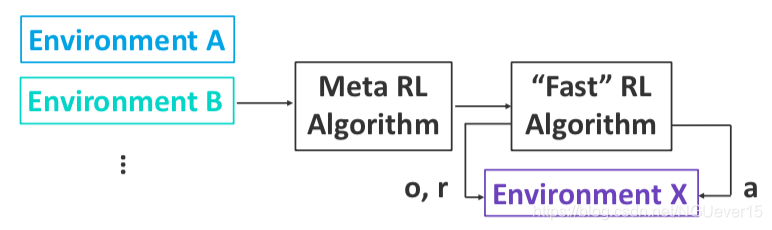
Meta-learning for RL
On-policy and off-policy meta-RL
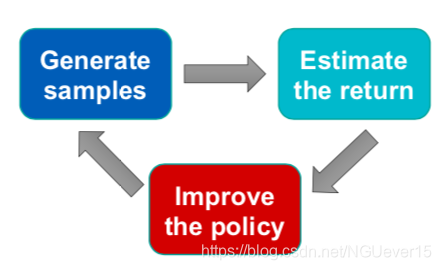
On-policy RL: Quick Recap 符合策略的RL:快速回顾
REINFORCE algorithm:
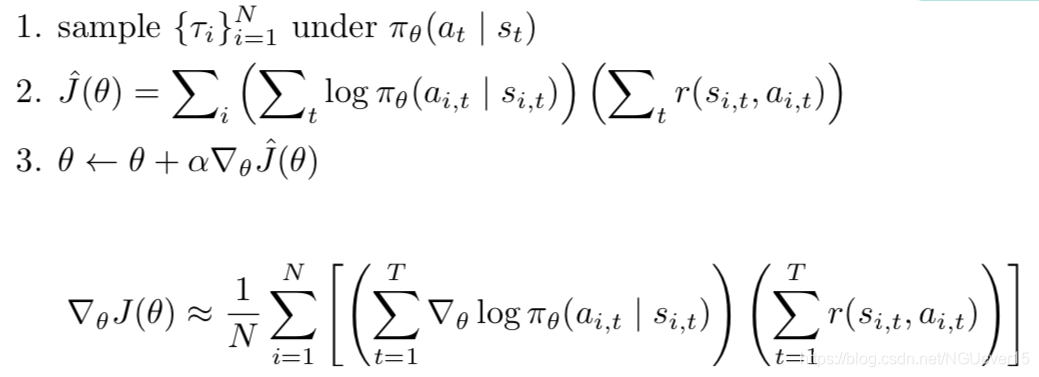
On-policy Meta-RL: MAML (again!)
- Start with a common policy initialization \(\theta\)
- Given a new task \(T_i\) , collect data using initial policy, then adapt using a gradient step:
- Meta-training is learning a shared initialization for all tasks:
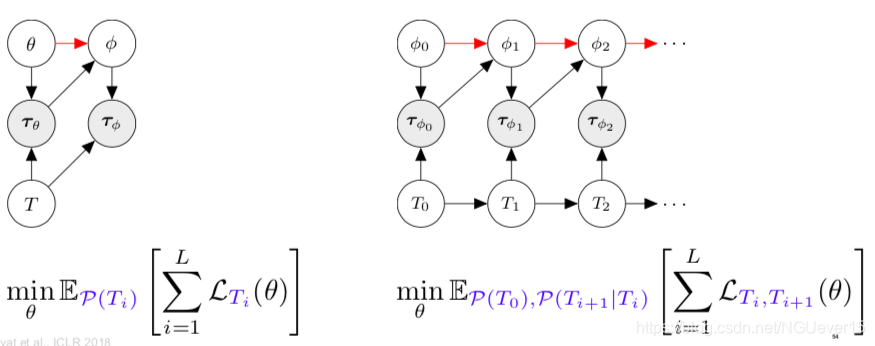
Adaptation as Inference 适应推理
Treat policy parameters, tasks, and all trajectories as random variables随机变量
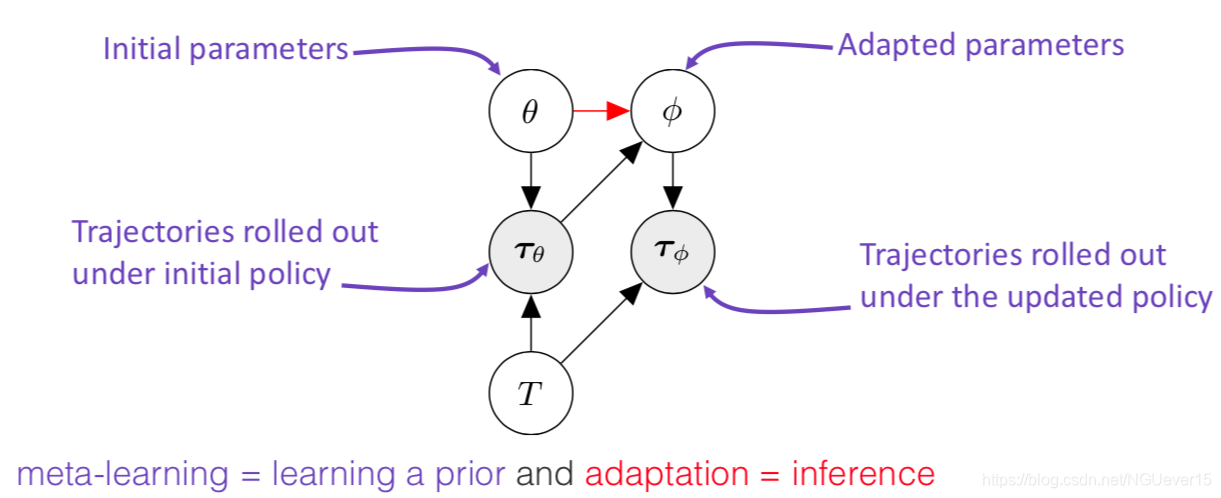
meta-learning = learning a prior and adaptation = inference
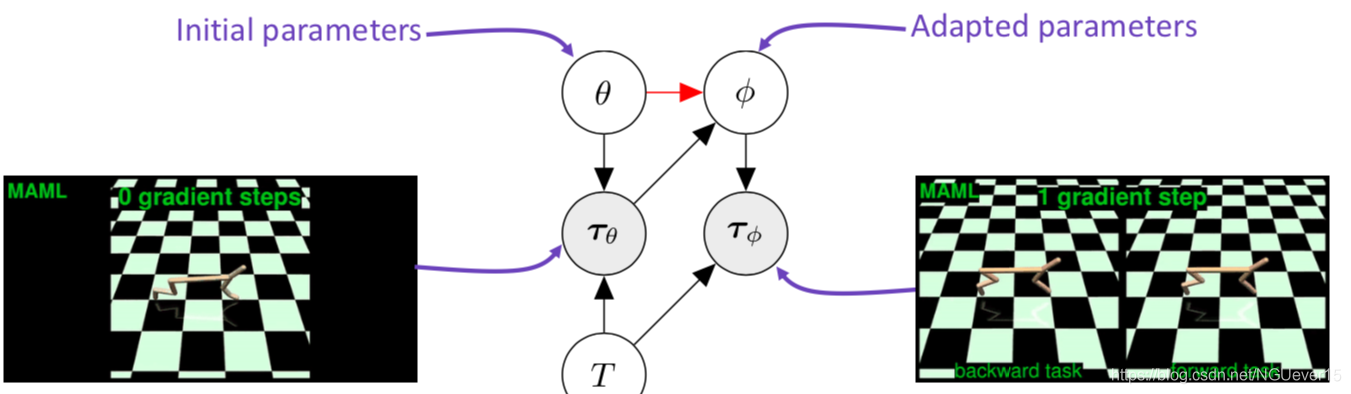
Off-policy meta-RL: PEARL
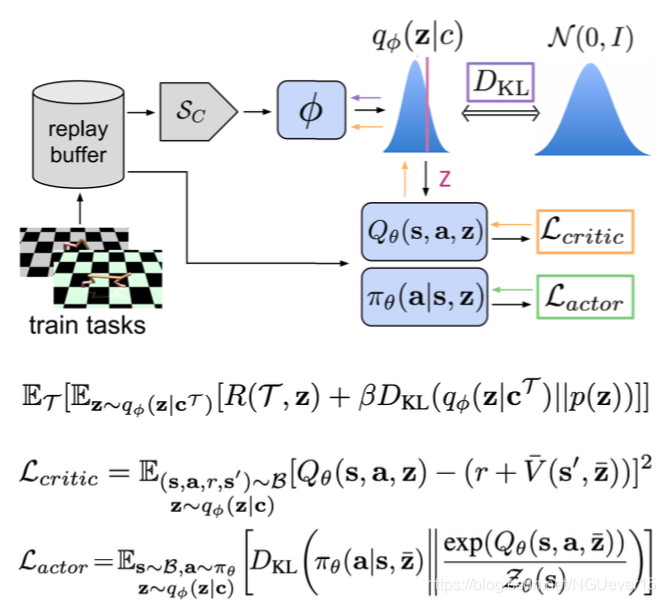
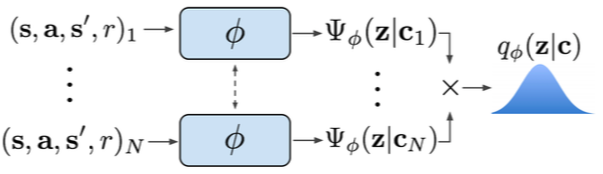
Key points:
- Infer latent representations z of each task from the trajectory data.
- The inference networkq is decoupled from the policy, which enables off-policy learning.
- All objectives involve the inference and policy networks.
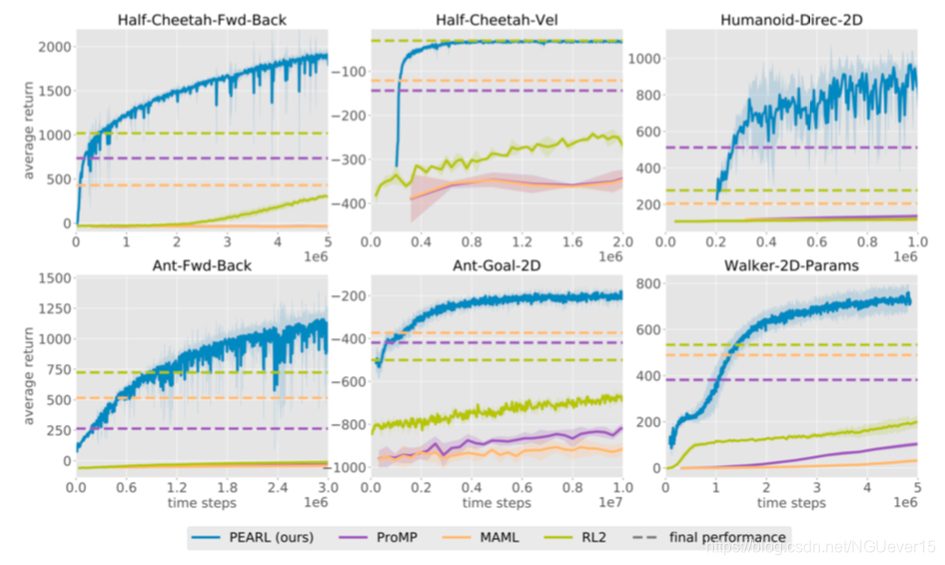
Adaptation in nonstationary environments 不稳定环境
Classical few-shot learning setup:
- The tasks are i.i.d. samples from some underlying distribution.
- Given a new task, we get to interact with it before adapting.
- What if we are in a nonstationary environment (i.e. changing over time)? Can we still use meta-learning?
Example: adaptation to a learning opponent
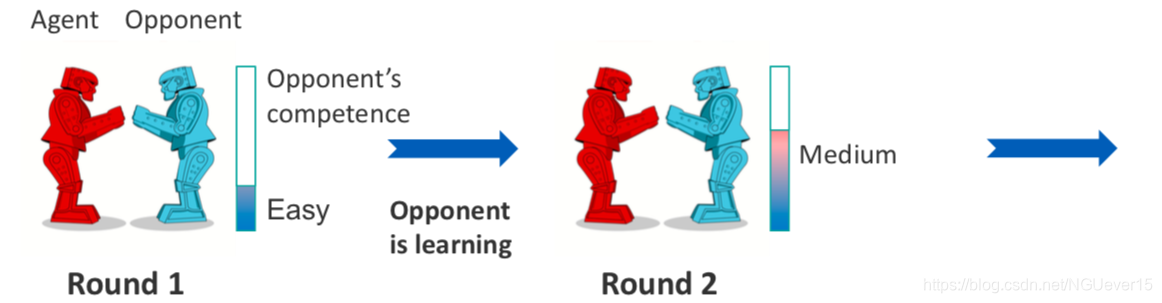 Each new round is a new task. Nonstationary environment is a sequence of tasks.
Each new round is a new task. Nonstationary environment is a sequence of tasks.
Continuous adaptation setup:
- The tasks are sequentially dependent.
- meta-learn to exploit dependencies
Continuous adaptation
Treat policy parameters, tasks, and all trajectories as random variables
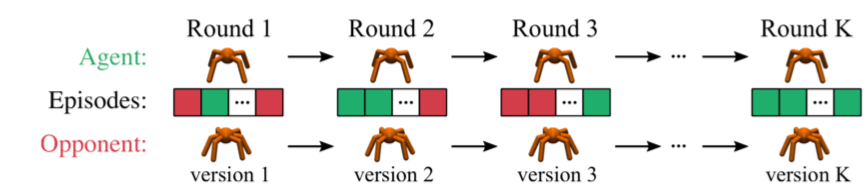
RoboSumo: a multiagent competitive env
an agent competes vs. an opponent, the opponent’s behavior changes over time
Takeaways
- Learning-to-learn (or meta-learning) setup is particularly suitable for multi-task reinforcement learning
- Both on-policy and off-policy RL can be “upgraded” to meta-RL:
- On-policy meta-RL is directly enabled by MAML
- Decoupling task inference and policy learning enables off-policy methods
- Is it about fast adaptation or learning good multitask representations? (See discussion in Meta-Q-Learning: https://arxiv.org/abs/1910.00125)
- Probabilistic view of meta-learning allows to use meta-learning ideas beyond distributions of i.i.d. tasks, e.g., continuous adaptation.
- Very active area of research.
卡耐基梅隆大学(CMU)元学习和元强化学习课程 | Elements of Meta-Learning的更多相关文章
- 李飞飞确认将离职!谷歌云AI总帅换人,卡耐基·梅隆老教授接棒
https://mp.weixin.qq.com/s/i1uwZALu1BcOq0jAMvPdBw 看点:李飞飞正式回归斯坦福,新任谷歌云AI总帅还是个教授,不过这次是全职. 智东西9月11日凌晨消息 ...
- 知乎:在卡内基梅隆大学 (Carnegie Mellon University) 就读是怎样一番体验?
转自:http://www.zhihu.com/question/24295398 知乎 Yu Zhang 知乎搜索 首页 话题 发现 消息 调查类问题名校就读体验修改 在卡内基梅隆大学 (Car ...
- 卡内基梅隆大学软件工程研究所先后制定用于评价软件系统成熟度的模型CMM和CMMI
SEI(美国卡内基梅隆大学软件工程研究所(Software Engineering Institute, SEI))开发的CMM模型有: 用于软件的(SW-CMM;SW代表'software即软件') ...
- 洛谷P3389 高斯消元 / 高斯消元+线性基学习笔记
高斯消元 其实开始只是想搞下线性基,,,后来发现线性基和高斯消元的关系挺密切就一块儿在这儿写了好了QwQ 先港高斯消元趴? 这个算法并不难理解啊?就会矩阵运算就过去了鸭,,, 算了都专门为此写个题解还 ...
- 【敬业福bug】支付宝五福卡敬业福太难求 被炒至200元
016年央视春晚官方独家互动合作伙伴--支付宝,正式上线春晚红包玩法集福卡活动. 用户新加入10个支付宝好友,就可以获成3张福卡.剩下2张须要支付宝好友之间相互赠送.交换,终于集齐5张福卡就有机会平分 ...
- 【转载】 准人工智能分享Deep Mind报告 ——AI“元强化学习”
原文地址: https://www.sohu.com/a/231895305_200424 ------------------------------------------------------ ...
- (@WhiteTaken)设计模式学习——享元模式
继续学习享元模式... 乍一看到享元的名字,一头雾水,学习了以后才觉得,这个名字确实比较适合这个模式. 享元,即共享对象的意思. 举个例子,如果制作一个五子棋的游戏,如果每次落子都实例化一个对象的话, ...
- 大学启示录I 浅谈大学生的学习与就业
教育触感 最近看了一些书,有了一些思考,以下纯属博主脑子被抽YY的一些无关大雅的思考,如有雷同,纯属巧合.. 现实总是令人遗憾的,我们当中太多人已经习惯于沿着那一成不变的"典型成功道路&qu ...
- python学习(十)元类
python 可以通过`type`函数创建类,也可通过type判断数据类型 import socket from io import StringIO import sys class TypeCla ...
随机推荐
- Hadoop安装 与 HDFS体系结构
- MarkDown排版、多样的文本框
<战争与和平>一八一二年,俄.法两国再度交战,安德烈·保尔康斯基在战役中身受重伤,而俄军节节败退,眼见莫斯科将陷于敌人之手了.罗斯托夫将原本用来搬运家产的马车,改去运送伤兵,娜达莎方能于伤 ...
- Spring AOP实现注解式的Mybatis多数据源切换
一.为什么要使用多数据源切换? 多数据源切换是为了满足什么业务场景?正常情况下,一个微服务或者说一个WEB项目,在使用Mybatis作为数据库链接和操作框架的情况下通常只需要构建一个系统库,在该系统库 ...
- git clone下载速度慢的解决方案
由于自己碰到git clone速度慢的问题,查询后发现有一个很好用的方法 首先获得你git clone的原格式,例如: git clone https://github.com/graykode/nl ...
- 测试工具-慢sql日志分析工具pt-query-digest
pt-query-digest分析来自慢速日志文件,常规日志文件和二进制日志文件的MySQL查询.它还可以分析来自tcpdump的查询和MySQL协议数据. 开启慢日志 set global slow ...
- 学习笔记——ESP8266项目的例子编译时发生cannot find -lstdc++问题的解决
在尝试对进行ESP8266项目的例子进行编译时发生cannot find -lstdc++问题 第一想法是安装libstdc++,结果安装时又发生了下面的情况: 再次查找原因,最后发现当前安装的交叉编 ...
- 基于FFmpeg的Dxva2硬解码及Direct3D显示(二)
解析视频源 目录 解析视频源 获取视频流 解析视频流 说明:这篇博文分为"获取视频流"和"解析视频流"两个部分,使用的是FFmpeg4.1的版本,与网上流传的低 ...
- C++调用Go方法的字符串传递问题及解决方案
摘要:C++调用Go方法时,字符串参数的内存管理需要由Go侧进行深度值拷贝. 现象 在一个APP技术项目中,子进程按请求加载Go的ServiceModule,将需要拉起的ServiceModule信息 ...
- linux下制作软件包安装服务器
linux下的软件包在有网络的情况下比较好安装,在ubuntu下,更新sourcelist,然后使用apt-get就可以很方便的安装包,在centos下面,更新yum列表,然后使用yum也可以进行方便 ...
- 编译一个Centos6.4下可用的内核rpm升级包-3.8.13内核rpm包
在Centos6.4下进行内核升级,采用内核源码的升级方式比较简单,但是需要升级的机器多的情况下进行内核升级就比较麻烦,并且编译内核的速度依赖于机器的性能,一般需要20分钟,而通过rpm内核包的方式进 ...