怎样将大批量文件进行循环分组(reduce)?
背景
当有时候一个文件夹下有几万个几十万个文件时,我们的桌面终端打开这个文件夹可能会卡。或者将文件进行批量上传时,如果是在文件夹下全选,那么基本上浏览器就卡死了,当然也不能这样子操作滴~
题主最近就遇到这样一个问题,批量上传文件,有几万个,担心全选会搞崩浏览器或者cmd终端,于是打算将数据分组,分批次上传,减少风险压力。可能有的同学会说,那简单嘛,直接ctrl C+V完事儿,但是人这个眼睛呐,越集中注意力看一个字,就越不觉得它像个字,所以难免会出错的,而且拖动也会很卡。
作为一个搞电脑的工程师(程序猿),能用电脑解决的,怎么能浪费体力呢[滑稽]
参考步骤
其实要实现这么一个东西,很简单的,二话不多说,直接一个for循环搞定 欧耶!但是呀,那个速度呀,难以忍受,如果分组这个文件还需要去做一些额外的操作,那岂不是更慢,说到这,想到以前读书学习大数据的时候,分词计算map-reduce那每次一跑就是一个小时过去了,所以,光写出来不得行,还得优化。而且分组的时候有一些注意点要注意。
题主的大致步骤如下:
- 打开文件夹,遍历文件;
- 启用线程池,多线程跑批任务,加快速度;
- 计数文件夹中文件个数,达到指定数量,建立下一个文件夹;
- 使用新的文件夹继续移动或复制文件,操作过程中进行重命名;重复3,4步骤
- 操作完毕,等待线程池任务处理完毕,销毁。
代码实现
说了那么多,还是直接上代码吧:)
import java.io.File;
import java.util.Arrays;
import java.util.Objects;
import java.util.concurrent.*;
public class TestReduceFile {
/**
* 文件计数
*/
private static volatile int currentFileNum = 0;
private static final String initFilePathName = "/Users/anhaoo/test/reduceFile/reduce";
private static volatile String currentFilePathName;
public static void main(String[] args) {
groupFile("/User/anhaoo/test/big_pdf");
}
/**
* 将文件分组:分成一个文件夹多少个文件这种
* @param oldFilePath
*/
private static void groupFile(String oldFilePath) {
File file = new File(oldFilePath);
File[] fileList = file.listFiles();
// 线程池批处理:链表阻塞队列
ExecutorService executor = Executors.newFixedThreadPool(80);
if (Objects.nonNull(fileList) && fileList.length > 0) {
// System.out.println(fileList.length);
Arrays.stream(fileList).forEach(item -> {
// 线程池提交任务处理
if (!item.isDirectory()) {
executor.execute(() -> groupFileSub(item));
}
});
}
// shutdown 等待任务全部执行完毕 销毁
executor.shutdown();
}
/**
* 分组文件,每满n个文件生成下一个文件夹,然后将后续遍历的文件移动到下一个文件夹中
* @param oldFile
*/
private static synchronized void groupFileSub(File oldFile) {
// 判断是否需要新生成文件夹,一个文件夹下放700个
if (currentFileNum % 700 == 0) {
// reduce0,reduce1,reduce2......
String newFileFolder = initFilePathName.concat(String.valueOf(currentFileNum/700));
// 将新的文件夹名赋值给共享变量
currentFilePathName = newFileFolder;
}
File aimFilePath = new File(currentFilePathName);
if (!aimFilePath.exists()) {
aimFilePath.mkdirs();
}
try {
// 移动文件时顺便重命名文件
String oldFileName = oldFile.getName();
String[] fileNameArr = oldFileName.split("_");
// 加下面这个if的原因 是因为mac电脑下有一个隐藏的.DS_Store文件,它按我的规则重命名时会影响我的操作
// 所以判断一下,不然我这里会抛越界异常:)
if (fileNameArr.length < 3) {
return;
}
String uuid = fileNameArr[2];
String newFileName = "/pdfFile_".concat(uuid);
File aimFile = new File(aimFilePath + File.separator + newFileName);
currentFileNum++;
oldFile.renameTo(aimFile);
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码就如上了,效果如图所示:
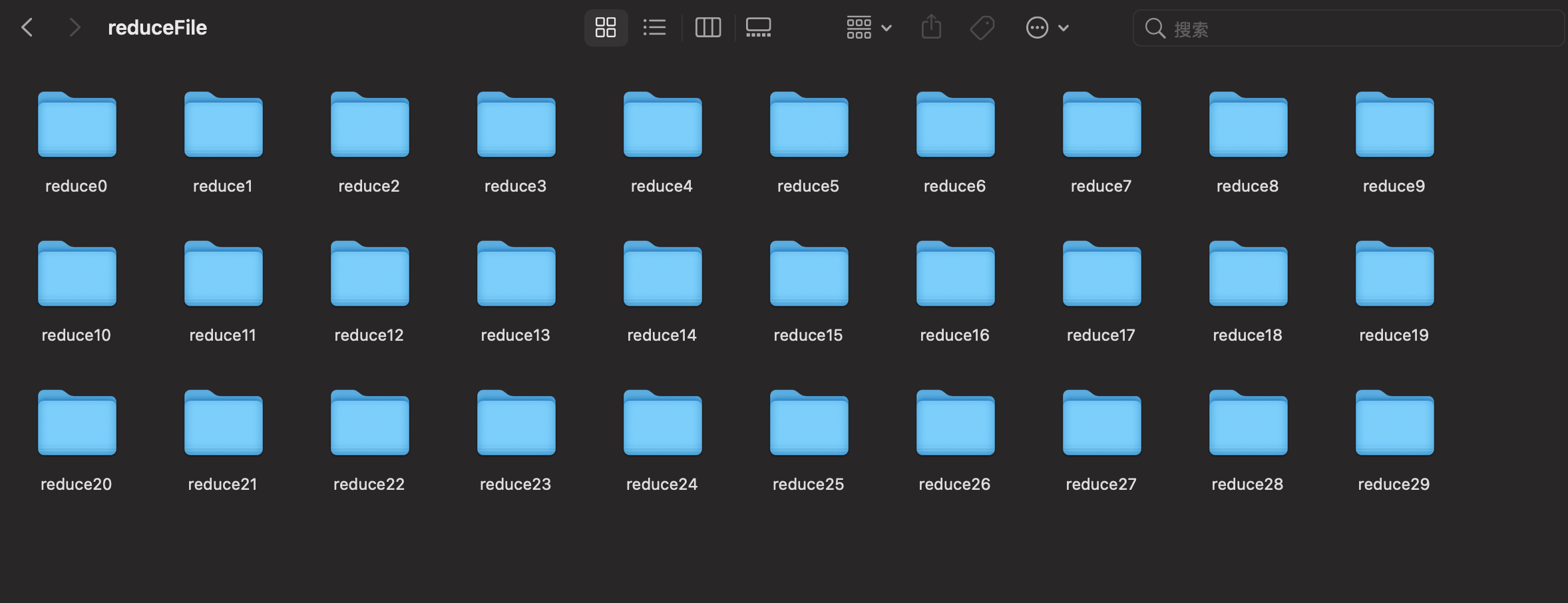
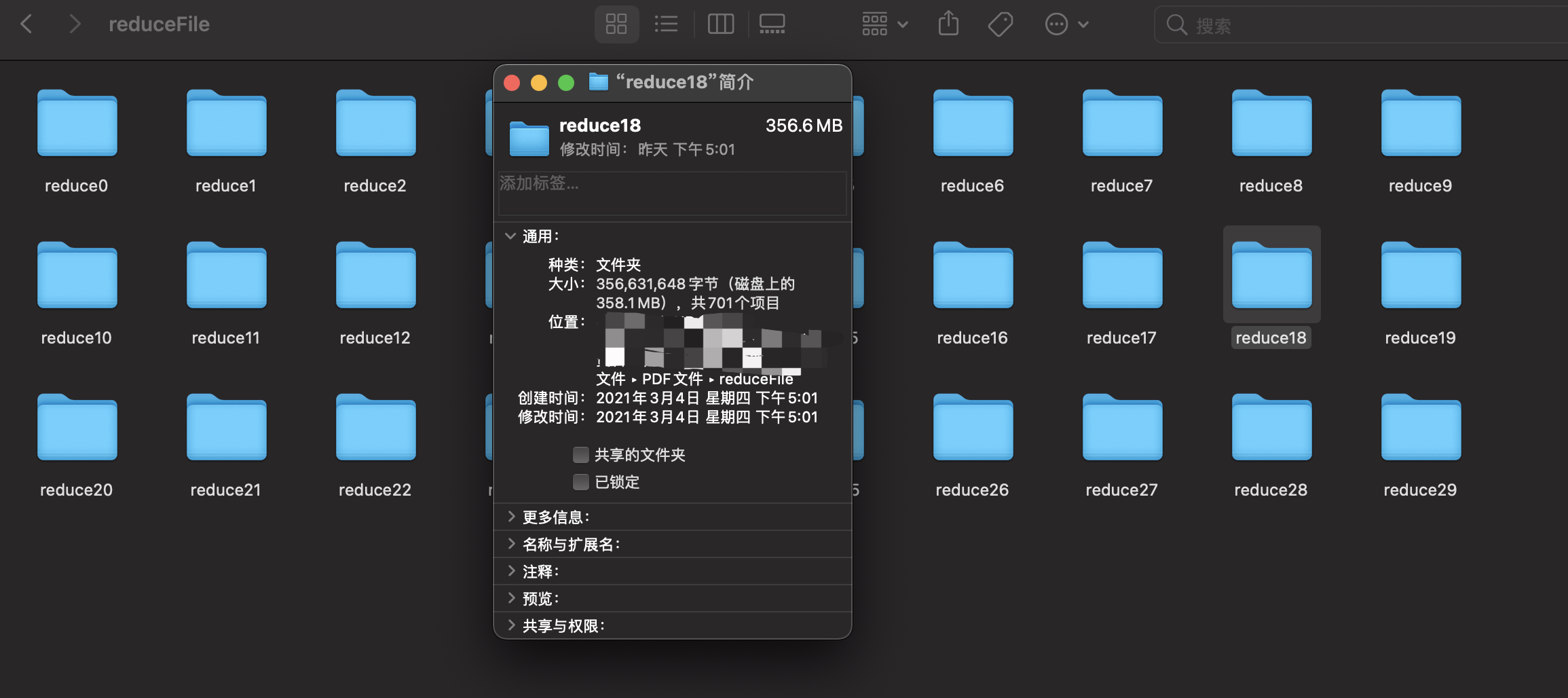
701 是因为有一个隐藏文件了哈!
注意事项
有几个点需要注意一下:上面程序中使用了volatile和synchronized,以及线程池等工具,
- 使用线程池,是为了多个线程一起处理,加快效率;
- 使用volatile修饰了两个变量,因为currentFileNum会实时变化,currentFilePathName文件夹也会在执行过程中发生变化
可能有的同学会有疑惑,既然使用了volatile关键保证了多线程变量的可见性,那为什么还要使用synchronize开持锁同步呢?哈哈哈,刚开始我也是这么认为的,没有使用锁,直接跑,但是每次跑完后每个文件夹的数量不仅不相等而且数量还不一致,不止700个多,后来仔细一想,volatile虽然保持了变量的可见性,但是当多个线程拿到这个变量是将变量副本拷贝到自己的栈内存中,只能保证在获取变量的时候是最新的,但是CPU指令的执行是哪个线程抢到了就去执行,所以可能刚好那个时候其他线程又将变量修改了,因为计数变量currentFileNum在不停地自增,导致线程不安全,不符合我们的预期效果,这个也再一次证明了一个结论:
volatile只是保证了可见性,但是线程变量的安全它无法保证;
所以在这个方法上加了一个锁,保证线程的安全性;
上述就是本文想分享的东西了,如果有更好的方法或者文章中有不足之处欢迎大家指出,共同进步才是我们的宗旨!
怎样将大批量文件进行循环分组(reduce)?的更多相关文章
- Python第五天 文件访问 for循环访问文件 while循环访问文件 字符串的startswith函数和split函数 linecache模块
Python第五天 文件访问 for循环访问文件 while循环访问文件 字符串的startswith函数和split函数 linecache模块 目录 Pycharm使用技巧( ...
- Linux rm删除大批量文件
在使用rm删除大批量文件时,有可能会遭遇"参数列太长"(Argument list too long)的问题.如下所示 [oracle@DB-Server bdump]$ rm - ...
- Linux rm删除大批量文件遇到 Argument list too long
在使用rm删除大批量文件时,有可能会遭遇“参数列太长”(Argument list too long)的问题.如下所示 [oracle@DB-Server bdump]$ rm -v epps_q ...
- VBS文件无限循环解决办法
VBS文件无限循环解决办法,也就相当于编程中的停止运行指令. 那么如何关掉VBS文件呢?当然关机后会自动关掉,还有另外一种方法就是,在"任务管理器"中找到进程"WScri ...
- 读取JSON文件并 排序,分组,
读取.json文件 public string GetFileJson(string filepath) { string json = string.Empty; using (FileStream ...
- php使用PHPexcel类读取excel文件(循环读取每个单元格的数据)
error_reporting(E_ALL); date_default_timezone_set('Asia/ShangHai'); include_once('Classes/PHPExcel/I ...
- JavaScript的map循环、forEach循环、filter循环、reduce循环、reduceRight循环
1.map循环 let arr=[1,2,3,4]; arr.map(function(value,key,arr){ //值,索引,数组(默认为选定数组) return item; //如果没有re ...
- python 文件单行循环读取的坑(一个程序中,文件默认只能按行循环读取一次,即使写到另一个循环里,它也只读取一次)
本来写了一个程序,想获取a文件中有,但是b文件中没有的行: 想到的方法是:1.一行一行提取a文件中数据,然后用a文件中的每一行与b文件中的每一行比较, 2.如果找到相同行就继续查找a中的下一行,如果找 ...
- AIX7.1删除大批量文件(百万级、千万级)
假设/data/test目录下含有数百万上千万的文件需要删除,可以选择的方式如下: 1.如果文件名不包含空白符.引号等特殊字符,则可以使用如下命令: find /data/test -type f | ...
随机推荐
- CodeForces - 1201B Zero Array
You are given an array a1,a2,-,ana1,a2,-,an. In one operation you can choose two elements aiai and a ...
- Qt内部的d指针和q指针手把手教你实现
Qt内部的d指针和q指针 在讲Qt的D指针之前让我们来简单的解释一下D指针出现的目的,目的是什么呢?保证模块间的二进制兼容. 什么是二进制兼容呢,简单说就是如果自己的程序使用了第三方模块,二进制兼容可 ...
- 14. 从0学ARM-exynos4412-看门狗裸机程序编写
看门狗 一.概念 看门狗的简称是WDT(Watch Dog Timer),exynos4412scp中的看门狗定时器(WDT)是一种定时装置. 1. 工作原理 由(一般需要客户编写)软件读写定时器相关 ...
- nginx+lua实现灰度发布/waf防火墙
nginx+lua 实现灰度发布 waf防火墙 课程链接:[课程]Nginx 与 Lua 实现灰度发布与 WAF 防火墙(完)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili 参考博客 Nginx ...
- hdu5303贪心
http://acm.hdu.edu.cn/showproblem.php?pid=5303 说一下题目大意.. 有一个长为L的环..你家在原点位置0,那么剩下L-1个点上种有一些树, 给你树的位置和 ...
- JWT实现登录认证实例
JWT全称JSON Web Token,是一个紧凑的,自包含的,安全的信息交换协议.JWT有很多方面的应用,例如权限认证,信息交换等.本文将简单介绍JWT登录权限认证的一个实例操作. JWT组成 JW ...
- 可迭代对象&迭代器&生成器
在python中,可迭代对象&迭代器&生成器的关系如下图: 即:生成器是一种特殊的迭代器,迭代器是一种特殊的可迭代对象. 可迭代对象 如上图,这里x是一个列表(可迭代对象),其实正如第 ...
- 『数据结构与算法』二叉查找树(BST)
微信搜索:码农StayUp 主页地址:https://gozhuyinglong.github.io 源码分享:https://github.com/gozhuyinglong/blog-demos ...
- how to fetch html content in js
how to fetch html content in js same origin CORS fetch('https://cdn.xgqfrms.xyz/') .then(function (r ...
- 微信公众号 bug
微信公众号 bug web bug refs xgqfrms 2012-2020 www.cnblogs.com 发布文章使用:只允许注册用户才可以访问!