python之路模块与包
一、import加载的模块分为四个通用类别:
1 使用python编写的代码(.py文件)
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包
4 使用C编写并链接到python解释器的内置模块
import
示例文件:自定义模块my_moudle.py,文件名my_moudle.py,模块名my_moudle
#my_moudle.py
print('from the my_moudle.py') money=1000 def read1():
print('my_moudle->read1->money',money) def read2():
print('my_moudle->read2 calling read1')
read1() def change():
global money
money=0
#demo.py
import my_moudle #只在第一次导入时才执行my_moudle.py内代码,此处的显式效果是只打印一次'from the my_moudle.py',当然其他的顶级代码也都被执行了,只不过没有显示效果.
import my_moudle
import my_moudle
import my_moudle '''
执行结果:
from the my_moudle.py
'''
二、一个py文件就可以作为一个模块
模块的导入:直接导入文件的名字,不需要带着后缀
模块中的函数调用:模块名.函数名()
money = 10000
my_moudle.read1()
print(my_moudle.money)
模块导入的时候做了三件事:
(1) 首先 开辟了一个新的命名空间 my_moudle
(2)执行my_moudle内的代码
(3) 将my_moudle里面的名字都和my_moudle绑定在一起
模块在一个程序中只会被导入一次,不会被重复导入
为了节约资源 如何实现的?
导入一个模块之后,会将模块存储在内存中
当再次导入的时候,就到内存中去查看是否导入过这个模块,如果导入了就不继续导入
三、导入的模块有自己的命名空间:
def read1():
print('*'*20) my_moudle.read1()
my_moudle.read2()
print(mm) my_moudle = 10000
print(my_moudle) mm.read1()
当你给一个模块起了别名的时候,就产生了一个命名空间,这个命名空间只和别名相关:
from my_moudle import read1
read1()
#from ... import ... 这种形式是导入啥就能用啥 不导入的一律不能用
#这个被import的名字就属于全局
def read1():
print('*'*20) read1()
四、from 模块 import *
首先会把模块当中所有不是‘_’开头的内容导入进来
还可以通过__all__来控制可以导入的内容
但是 以上两条只和 * 有关
#在与glance同级的test.py中
import glance
glance.cmd.manage.main() '''
执行结果:
AttributeError: module 'glance' has no attribute 'cmd' '''
解决方法:
1 #glance/__init__.py
2 from . import cmd
3
4 #glance/cmd/__init__.py
5 from . import manage
执行:
1 #在于glance同级的test.py中
2 import glance
3 glance.cmd.manage.main()
import glance之后直接调用模块中的方法:
glance/ ├── __init__.py from .api import *
from .cmd import *
from .db import *
├── api │ ├── __init__.py __all__ = ['policy','versions'] │ ├── policy.py │ └── versions.py ├── cmd __all__ = ['manage'] │ ├── __init__.py │ └── manage.py └── db __all__ = ['models'] ├── __init__.py └── models.py import glance
policy.get()
五、 绝对导入和相对导入
绝对导入:以glance作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
例如:我们在glance/api/version.py中想要导入glance/cmd/manage.py
在glance/api/version.py #绝对导入
from glance.cmd import manage
manage.main() #相对导入
from ..cmd import manage
manage.main()
测试结果:注意一定要在于glance同级的文件中测试
1 from glance.api import versions
特别需要注意的是:可以用import导入内置或者第三方模块(已经在sys.path中),但是要绝对避免使用import来导入自定义包的子模块(没有在sys.path中),应该使用from... import ...的绝对或者相对导入,且包的相对导入只能用from的形式。
在于glance同级下的一个test.py文件中导入version.py,如下
from glance.api import versions '''
执行结果:
ImportError: No module named 'policy'
''' '''
分析:
此时我们导入versions在versions.py中执行
import policy需要找从sys.path也就是从当前目录找policy.py,
这必然是找不到的
'''
glance/ ├── __init__.py from glance import api
from glance import cmd
from glance import db ├── api │ ├── __init__.py from glance.api import policy
from glance.api import versions │ ├── policy.py │ └── versions.py ├── cmd from glance.cmd import manage │ ├── __init__.py │ └── manage.py └── db from glance.db import models ├── __init__.py └── models.py
glance/ ├── __init__.py from . import api #.表示当前目录
from . import cmd
from . import db ├── api │ ├── __init__.py from . import policy
from . import versions │ ├── policy.py │ └── versions.py ├── cmd from . import manage │ ├── __init__.py │ └── manage.py from ..api import policy
#..表示上一级目录,想再manage中使用policy中的方法就需要回到上一级glance目录往下找api包,从api导入policy └── db from . import models ├── __init__.py └── models.py
附加:
软件开发规范:
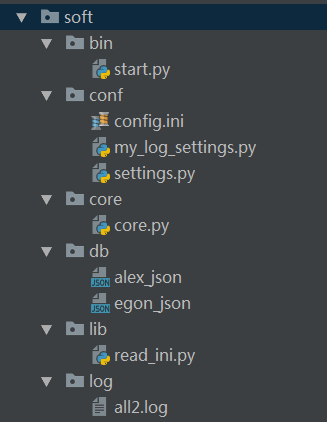
#=============>bin目录:存放执行脚本
#start.py
import sys,os BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR) from core import core
from conf import my_log_settings if __name__ == '__main__':
my_log_settings.load_my_logging_cfg()
core.run() #=============>conf目录:存放配置文件
#config.ini
[DEFAULT]
user_timeout = 1000 [egon]
password = 123
money = 10000000 [alex]
password = alex3714
money=10000000000 [yuanhao]
password = ysb123
money=10 #settings.py
import os
config_path=r'%s\%s' %(os.path.dirname(os.path.abspath(__file__)),'config.ini')
user_timeout=10
user_db_path=r'%s\%s' %(os.path.dirname(os.path.dirname(os.path.abspath(__file__))),\
'db') #my_log_settings.py
"""
logging配置
""" import os
import logging.config # 定义三种日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' # 定义日志输出格式 结束 logfile_dir = r'%s\log' %os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # log文件的目录 logfile_name = 'all2.log' # log文件名 # 如果不存在定义的日志目录就创建一个
if not os.path.isdir(logfile_dir):
os.mkdir(logfile_dir) # log文件的全路径
logfile_path = os.path.join(logfile_dir, logfile_name) # log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {},
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
},
},
} def load_my_logging_cfg():
logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置
logger = logging.getLogger(__name__) # 生成一个log实例
logger.info('It works!') # 记录该文件的运行状态 if __name__ == '__main__':
load_my_logging_cfg() #=============>core目录:存放核心逻辑
#core.py
import logging
import time
from conf import settings
from lib import read_ini config=read_ini.read(settings.config_path)
logger=logging.getLogger(__name__) current_user={'user':None,'login_time':None,'timeout':int(settings.user_timeout)}
def auth(func):
def wrapper(*args,**kwargs):
if current_user['user']:
interval=time.time()-current_user['login_time']
if interval < current_user['timeout']:
return func(*args,**kwargs)
name = input('name>>: ')
password = input('password>>: ')
if config.has_section(name):
if password == config.get(name,'password'):
logger.info('登录成功')
current_user['user']=name
current_user['login_time']=time.time()
return func(*args,**kwargs)
else:
logger.error('用户名不存在') return wrapper @auth
def buy():
print('buy...') @auth
def run(): print('''
购物
查看余额
转账
''')
while True:
choice = input('>>: ').strip()
if not choice:continue
if choice == '':
buy() if __name__ == '__main__':
run() #=============>db目录:存放数据库文件
#alex_json
#egon_json #=============>lib目录:存放自定义的模块与包
#read_ini.py
import configparser
def read(config_file):
config=configparser.ConfigParser()
config.read(config_file)
return config #=============>log目录:存放日志
#all2.log
[2017-07-29 00:31:40,272][MainThread:11692][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
[2017-07-29 00:31:41,789][MainThread:11692][task_id:core.core][core.py:25][ERROR][用户名不存在]
[2017-07-29 00:31:46,394][MainThread:12348][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
[2017-07-29 00:31:47,629][MainThread:12348][task_id:core.core][core.py:25][ERROR][用户名不存在]
[2017-07-29 00:31:57,912][MainThread:10528][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
[2017-07-29 00:32:03,340][MainThread:12744][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
[2017-07-29 00:32:05,065][MainThread:12916][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
[2017-07-29 00:32:08,181][MainThread:12916][task_id:core.core][core.py:25][ERROR][用户名不存在]
[2017-07-29 00:32:13,638][MainThread:7220][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
[2017-07-29 00:32:23,005][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功]
[2017-07-29 00:32:40,941][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功]
[2017-07-29 00:32:47,222][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功]
[2017-07-29 00:32:51,949][MainThread:7220][task_id:core.core][core.py:25][ERROR][用户名不存在]
[2017-07-29 00:33:00,213][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功]
[2017-07-29 00:33:50,118][MainThread:8500][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
[2017-07-29 00:33:55,845][MainThread:8500][task_id:core.core][core.py:20][INFO][登录成功]
[2017-07-29 00:34:06,837][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在]
[2017-07-29 00:34:09,405][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在]
[2017-07-29 00:34:10,645][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在]
软件开发示范
python之路模块与包的更多相关文章
- python之路--模块和包
一 . 模块 ⾸先,我们先看⼀个老⽣常谈的问题. 什么是模块. 模块就是⼀个包含了python定义和声明的⽂件, ⽂件名就是模块的名字加上.py后缀. 换句话说我们⽬前写的所有的py⽂件都可以看成是⼀ ...
- python之路——模块和包
阅读目录 一 模块 3.1 import 3.2 from ... import... 3.3 把模块当做脚本执行 3.4 模块搜索路径 3.5 编译python文件 二 包 2.2 import 2 ...
- 二十五. Python基础(25)--模块和包
二十五. Python基础(25)--模块和包 ● 知识框架 ● 模块的属性__name__ # my_module.py def fun1(): print("Hello& ...
- Python之路-Python中的模块与包
一.模块简介 在实际开发中我们不可能不用到系统的标准模块,或第三方模块. 如果想实现与时间有关的功能,就需要调用系统的time模块.如果想实现与文件和文件夹有关的操作,就需要要用到os模块. 每一个 ...
- Python中的模块与包
标准库的安装路径 在import模块的时候,python是通过系统路径找到这些模块的,我们可以将这些路径打印出来: >>> pprint.pprint(sys.path) ['', ...
- 【循序渐进学Python】10.模块和包
1.导入模块 任何Python程序都可以作为模块导入,只要Python解释器能找到我们定义的模块所在位置即可,一般来讲,在一个模块被导入时,Python解释器会按照下面的步骤进行搜索: 在当前所在目录 ...
- Python类、模块、包的区别
类 类的概念在许多语言中出现,很容易理解.它将数据和操作进行封装,以便将来的复用. 模块 模块,在Python可理解为对应于一个文件.在创建了一个脚本文件后,定义了某些函数和变量.你在其他需要这些功能 ...
- Python进阶之模块与包
模块 .note-content {font-family: "Helvetica Neue",Arial,"Hiragino Sans GB","S ...
- 【Python实战】模块和包导入详解(import)
1.模块(module) 1.1 模块定义 通常模块为一个.py文件,其他可作为module的文件类型还有".pyo".".pyc".".pyd&qu ...
随机推荐
- SpringMVC注解@RequestMapping之produces属性导致的406错误
废话不多说,各位,直接看图说话,敢吗?这个问题网上解决的办法写的狠是粗糙,甚至说这次我干掉它完全是靠巧合,但是也不否认网上针对406错误给出的解决方式,可能是多种情况下出现的406吧?我这次的流程就是 ...
- xargs - 地下管道
xargs - 地下管道 xargs 促使我去思!考,管道 | 的具象含义是什么. $ cat sample.txt Things to do today: Low:Go grocery shoppi ...
- 免费的Lucene 原理与代码分析完整版下载
Lucene是一个基于Java的高效的全文检索库.那么什么是全文检索,为什么需要全文检索?目前人们生活中出现的数据总的来说分为两类:结构化数据和非结构化数据.很容易理解,结构化数据是有固定格式和结构的 ...
- 《CS:APP》二进制炸弹实验(phase_1-3)
<深入理解计算机系统>第三章的bomb lab,拆弹实验:给出一个linux的可执行文件bomb,执行后文件要求分别进行6次输入,每一次输入错误都会导致炸弹爆炸,程序终止.需要通过反汇编来 ...
- Oracle异常汇总
持续更新中,可参见https://hnuhell.gitbooks.io/oracle_errmg/content/或https://hnuhell.github.io/Oracle_ERRMG/上的 ...
- node.js后台快速搭建在阿里云(一)(express篇)
前期准备 阿里云服务器 node.js pm2 express nginx linux(推荐教程:鸟哥的私房菜) 简介 嗯……我只是个前端而已 前段时间写过一个.net mvc的远程发布,关于.net ...
- 分布式memcached-虚拟节点
1.通过memcached服务器下的不同端口来达到模拟多台服务器的效果 2.假设现在有三台memcached服务器,本地分别使用11211,11212,11213三个端口来模拟 ①打开端口 ②连接端口 ...
- Java double和 float丢失精度问题
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt357 由于对float或double 的使用不当,可能会出现精度丢失的问题. ...
- spring boot认识
Spring Boot的好处: 1.配置简化 2.配合各种starter使用,基本上可以做到自动化配置 3.上手速度快 4.提供运行时的应用监控 运用IDEA创建spring boot项目请查看: h ...
- if判断与比较操作符gt、lt、eq等的使用
在整数中比较使用如下 //-eq 等于(equal) if [ "$a" -eq "$b" ] //-ne不等于(no equal) if [ "$ ...