[笔记]LibSVM源码剖析(java版)
之前学习了SVM的原理(见http://www.cnblogs.com/bentuwuying/p/6444249.html),以及SMO算法的理论基础(见http://www.cnblogs.com/bentuwuying/p/6444516.html)。最近又学习了SVM的实现:LibSVM(版本为3.22),在这里总结一下。
1. LibSVM整体框架
Training: parse_command_line
从命令行读入需要设置的参数,并初始化各参数
read_problem
读入训练数据
svm_check_parameter
检查参数和训练数据是否符合规定的格式
do_cross_validation
svm_cross_validation
对训练数据进行均匀划分,使得同一个类别的数据均匀分布在各个fold中
最终得到的数组中,相同fold的数据的索引放在连续内存空间数组中
Cross Validation(k fold)
svm_train(使用k-1个fold的数据做训练)
svm_predict(使用剩下的1个fold的数据做预测)
得到每个样本在Cross Validation中的预测类别
得出Cross Validation的准确率
svm_train
classification
svm_group_classes
对训练数据按类别进行分组重排,相同类别的数据的索引放在连续内存空间数组中
得到类别总数:nr_class,每个类别的标识:label,每个类别的样本数:count,每个类别在重排数组中的起始位置:start,重排后的索引数组:perm(每个元素的值代表其在原始数组中的索引)
train k*(k-1)/2 models
新建1个训练数据子集sub_prob,并使用两个类别的训练数据进行填充
svm_train_one //根据svm_type的不同,使用不同的方式进行单次模型训练
solve_c_svc //针对C-SVC这一类型进行模型训练
新建1个Solver类对象s
s.Solve //使用SMO算法求解对偶问题(二次优化问题)
初始化拉格朗日乘子状态向量(是否在边界上)
初始化需要参与迭代优化计算的拉格朗日乘子集合
初始化梯度G,以及为了重建梯度时候节省计算开销而维护的中间变量G_bar
迭代优化
do_shrinking(每间隔若干次迭代进行一次shrinking)
找出m(a)和M(a)
reconstruct_gradient(如果满足停止条件,进行梯度重建)
因为有时候shrinking策略太过aggressive,所以当对shrinking之后的部分变量的优化问题迭代优化到第一次满足停止条件时,便可以对梯度进行重建
接下来的shrinking过程便可以建立在更精确的梯度值上
be_shrunk
判断该alpha是否被shrinking(不再参与后续迭代优化)
swap_index
交换两个变量的位置,从而使得参与迭代优化的变量(即没有被shrinking的变量)始终保持在变量数组的最前面的连续位置上
select_working_set(选择工作集)
对工作集的alpha进行更新
更新梯度G,拉格朗日乘子状态向量,及中间变量G_bar
计算b
填充alpha数组和SolutionInfo对象si并返回
返回alpha数组和SolutionInfo对象si
输出decision_function对象(包含alpha数组和b)
修改nonzero数组,将alpha大于0的对应位置改为true
填充svm_model对象model(包含nr_class,label数组,b数组,probA&probB数组,nSV数组,l,SV二维数组,sv_indices数组,sv_coef二维数组)并返回 //sv_coef二维数组内元素的放置方式很特别
svm_save_model
保存模型到制定文件中 Prediction: svm_predict
svm_predict_values
Kernel.k_function //计算预测样本与Support Vectors的Kernel值
用k(k-1)/2个分类器对预测样本进行预测,得出k(k-1)/2个预测类别
使用投票策略,选择预测数最多的那个类别作为最终的预测类别
返回预测类别
2. 各参数文件
public class svm_node implements java.io.Serializable
{
public int index;
public double value;
}
用于存储单个向量中的单个特征。index是该特征的索引,value是该特征的值。这样设计的好处是,可以节省存储空间,提高计算速度。
public class svm_problem implements java.io.Serializable
{
public int l;
public double[] y;
public svm_node[][] x;
}
用于存储本次运算的所有样本(数据集),及其所属类别。
public class svm_parameter implements Cloneable,java.io.Serializable
{
/* svm_type */
public static final int C_SVC = 0;
public static final int NU_SVC = 1;
public static final int ONE_CLASS = 2;
public static final int EPSILON_SVR = 3;
public static final int NU_SVR = 4; /* kernel_type */
public static final int LINEAR = 0;
public static final int POLY = 1;
public static final int RBF = 2;
public static final int SIGMOID = 3;
public static final int PRECOMPUTED = 4; public int svm_type;
public int kernel_type;
public int degree; // for poly
public double gamma; // for poly/rbf/sigmoid
public double coef0; // for poly/sigmoid // these are for training only
public double cache_size; // in MB
public double eps; // stopping criteria
public double C; // for C_SVC, EPSILON_SVR and NU_SVR
public int nr_weight; // for C_SVC
public int[] weight_label; // for C_SVC
public double[] weight; // for C_SVC
public double nu; // for NU_SVC, ONE_CLASS, and NU_SVR
public double p; // for EPSILON_SVR
public int shrinking; // use the shrinking heuristics
public int probability; // do probability estimates public Object clone()
{
try
{
return super.clone();
} catch (CloneNotSupportedException e)
{
return null;
}
} }
用于存储模型训练所需设置的参数。
public class svm_model implements java.io.Serializable
{
public svm_parameter param; // parameter
public int nr_class; // number of classes, = 2 in regression/one class svm
public int l; // total #SV
public svm_node[][] SV; // SVs (SV[l])
public double[][] sv_coef; // coefficients for SVs in decision functions (sv_coef[k-1][l])
public double[] rho; // constants in decision functions (rho[k*(k-1)/2])
public double[] probA; // pariwise probability information
public double[] probB;
public int[] sv_indices; // sv_indices[0,...,nSV-1] are values in [1,...,num_traning_data] to indicate SVs in the training set // for classification only public int[] label; // label of each class (label[k])
public int[] nSV; // number of SVs for each class (nSV[k])
// nSV[0] + nSV[1] + ... + nSV[k-1] = l
};
用于存储训练得到的模型,当然原来的训练参数也必须保留。
3. Cache类
Cache类主要负责运算所涉及的内存的管理,包括申请和释放等。
private final int l;
private long size;
private final class head_t
{
head_t prev, next; // a cicular list
float[] data;
int len; // data[0,len) is cached in this entry
}
private final head_t[] head;
private head_t lru_head;
类成员变量。包括:
l:样本总数。
size:指定的全部内存总量。
head_t:单块申请到的内存用class head_t来记录所申请内存,并记录长度。而且通过双向的指针,形成链表,增加寻址的速度。记录所有申请到的内存,一方面便于释放内存,另外方便在内存不够时适当释放一部分已经申请到的内存。
head:类似于变量指针,该指针用来记录程序所申请的内存。
lru_head:双向链表的头。
Cache(int l_, long size_)
{
l = l_;
size = size_;
head = new head_t[l];
for(int i=0;i<l;i++) head[i] = new head_t();
size /= 4;
size -= l * (16/4); // sizeof(head_t) == 16
size = Math.max(size, 2* (long) l); // cache must be large enough for two columns
lru_head = new head_t();
lru_head.next = lru_head.prev = lru_head;
}
构造函数。该函数根据样本数L,申请L 个head_t 的空间。Lru_head 因为尚没有head_t 中申请到内存,故双向链表指向自己。至于size 的处理,先将原来的byte 数目转化为float 的数目,然后扣除L 个head_t 的内存数目。
private void lru_delete(head_t h)
{
// delete from current location
h.prev.next = h.next;
h.next.prev = h.prev;
}
从双向链表中删除某个元素的链接,不删除、不释放该元素所涉及的内存。一般是删除当前所指向的元素。
private void lru_insert(head_t h)
{
// insert to last position
h.next = lru_head;
h.prev = lru_head.prev;
h.prev.next = h;
h.next.prev = h;
}
在链表后面插入一个新的节点。
// request data [0,len)
// return some position p where [p,len) need to be filled
// (p >= len if nothing needs to be filled)
// java: simulate pointer using single-element array
int get_data(int index, float[][] data, int len)
{
head_t h = head[index];
if(h.len > 0) lru_delete(h);
int more = len - h.len; if(more > 0)
{
// free old space
while(size < more)
{
head_t old = lru_head.next;
lru_delete(old);
size += old.len;
old.data = null;
old.len = 0;
} // allocate new space
float[] new_data = new float[len];
if(h.data != null) System.arraycopy(h.data,0,new_data,0,h.len);
h.data = new_data;
size -= more;
do {int tmp=h.len; h.len=len; len=tmp;} while(false);
} lru_insert(h);
data[0] = h.data;
return len;
}
该函数保证head_t[index]中至少有len 个float 的内存,并且将可以使用的内存块的指针放在 data 指针中。返回值为申请到的内存。函数首先将head_t[index]从链表中断开,如果head_t[index]原来没有分配内存,则跳过断开这步。计算当前head_t[index]已经申请到的内存,如果不够,释放部分内存,等内存足够后,重新分配内存。重新使head_t[index]进入双向链表。返回值不为申请到的内存的长度,为head_t[index]原来的数据长度h.len。
调用该函数后,程序会计算 的值,并将其填入 data 所指向的内存区域,如果下次index 不变,正常情况下,不用重新计算该区域的值。若index 不变,则get_data()返回值len 与本次传入的len 一致,从get_Q( )中可以看到,程序不会重新计算。从而提高运算速度。
的值,并将其填入 data 所指向的内存区域,如果下次index 不变,正常情况下,不用重新计算该区域的值。若index 不变,则get_data()返回值len 与本次传入的len 一致,从get_Q( )中可以看到,程序不会重新计算。从而提高运算速度。
void swap_index(int i, int j)
{
if(i==j) return; if(head[i].len > 0) lru_delete(head[i]);
if(head[j].len > 0) lru_delete(head[j]);
do {float[] tmp=head[i].data; head[i].data=head[j].data; head[j].data=tmp;} while(false);
do {int tmp=head[i].len; head[i].len=head[j].len; head[j].len=tmp;} while(false);
if(head[i].len > 0) lru_insert(head[i]);
if(head[j].len > 0) lru_insert(head[j]); if(i>j) do {int tmp=i; i=j; j=tmp;} while(false);
for(head_t h = lru_head.next; h!=lru_head; h=h.next)
{
if(h.len > i)
{
if(h.len > j)
do {float tmp=h.data[i]; h.data[i]=h.data[j]; h.data[j]=tmp;} while(false);
else
{
// give up
lru_delete(h);
size += h.len;
h.data = null;
h.len = 0;
}
}
}
}
交换head_t[i] 和head_t[j]的内容,先从双向链表中断开,交换后重新进入双向链表中。然后对于每个head_t[index]中的值,交换其第 i 位和第 j 位的值。这两步是为了在Kernel 矩阵中在两个维度上都进行一次交换。
4. Kernel类
Kernel类是用来进行计算Kernel evaluation矩阵的。
//
// Kernel evaluation
//
// the static method k_function is for doing single kernel evaluation
// the constructor of Kernel prepares to calculate the l*l kernel matrix
// the member function get_Q is for getting one column from the Q Matrix
//
abstract class QMatrix {
abstract float[] get_Q(int column, int len);
abstract double[] get_QD();
abstract void swap_index(int i, int j);
};
Kernel的父类,抽象类。
abstract class Kernel extends QMatrix {
private svm_node[][] x;
private final double[] x_square;
// svm_parameter
private final int kernel_type;
private final int degree;
private final double gamma;
private final double coef0;
abstract float[] get_Q(int column, int len);
abstract double[] get_QD();
Kernel类的成员变量。
Kernel(int l, svm_node[][] x_, svm_parameter param)
{
this.kernel_type = param.kernel_type;
this.degree = param.degree;
this.gamma = param.gamma;
this.coef0 = param.coef0; x = (svm_node[][])x_.clone(); if(kernel_type == svm_parameter.RBF)
{
x_square = new double[l];
for(int i=0;i<l;i++)
x_square[i] = dot(x[i],x[i]);
}
else x_square = null;
}
构造函数。初始化类中的部分常量、指定核函数、克隆样本数据(每次数据传入时通过克隆函数来实现,完全重新分配内存)。如果使用RBF 核函数,则计算x_sqare[i]。
double kernel_function(int i, int j)
{
switch(kernel_type)
{
case svm_parameter.LINEAR:
return dot(x[i],x[j]);
case svm_parameter.POLY:
return powi(gamma*dot(x[i],x[j])+coef0,degree);
case svm_parameter.RBF:
return Math.exp(-gamma*(x_square[i]+x_square[j]-2*dot(x[i],x[j])));
case svm_parameter.SIGMOID:
return Math.tanh(gamma*dot(x[i],x[j])+coef0);
case svm_parameter.PRECOMPUTED:
return x[i][(int)(x[j][0].value)].value;
default:
return 0; // java
}
}
对Kernel类的对象中包含的任意2个样本求kernel evaluation。
static double k_function(svm_node[] x, svm_node[] y,
svm_parameter param)
{
switch(param.kernel_type)
{
case svm_parameter.LINEAR:
return dot(x,y);
case svm_parameter.POLY:
return powi(param.gamma*dot(x,y)+param.coef0,param.degree);
case svm_parameter.RBF:
{
double sum = 0;
int xlen = x.length;
int ylen = y.length;
int i = 0;
int j = 0;
while(i < xlen && j < ylen)
{
if(x[i].index == y[j].index)
{
double d = x[i++].value - y[j++].value;
sum += d*d;
}
else if(x[i].index > y[j].index)
{
sum += y[j].value * y[j].value;
++j;
}
else
{
sum += x[i].value * x[i].value;
++i;
}
} while(i < xlen)
{
sum += x[i].value * x[i].value;
++i;
} while(j < ylen)
{
sum += y[j].value * y[j].value;
++j;
} return Math.exp(-param.gamma*sum);
}
case svm_parameter.SIGMOID:
return Math.tanh(param.gamma*dot(x,y)+param.coef0);
case svm_parameter.PRECOMPUTED:
return x[(int)(y[0].value)].value;
default:
return 0; // java
}
}
静态方法,对参数传入的任意2个样本求kernel evaluation。主要应用在predict过程中。
//
// Q matrices for various formulations
//
class SVC_Q extends Kernel
{
private final byte[] y;
private final Cache cache;
private final double[] QD; SVC_Q(svm_problem prob, svm_parameter param, byte[] y_)
{
super(prob.l, prob.x, param);
y = (byte[])y_.clone();
cache = new Cache(prob.l,(long)(param.cache_size*(1<<20)));
QD = new double[prob.l];
for(int i=0;i<prob.l;i++)
QD[i] = kernel_function(i,i);
} float[] get_Q(int i, int len)
{
float[][] data = new float[1][];
int start, j;
if((start = cache.get_data(i,data,len)) < len)
{
for(j=start;j<len;j++)
data[0][j] = (float)(y[i]*y[j]*kernel_function(i,j));
}
return data[0];
} double[] get_QD()
{
return QD;
} void swap_index(int i, int j)
{
cache.swap_index(i,j);
super.swap_index(i,j);
do {byte tmp=y[i]; y[i]=y[j]; y[j]=tmp;} while(false);
do {double tmp=QD[i]; QD[i]=QD[j]; QD[j]=tmp;} while(false);
}
}
Kernel类的子类,用于对C-SVC进行定制的Kernel类。其中构造函数中会调用父类Kernel类的构造函数,并且初始化自身独有的成员变量。
在get_Q函数中,调用了Cache类的get_data函数。想要得到第 i 个变量与其它 len 个变量的Kernel函数值。但是如果取出的缓存中没有全部的值,只有部分的值的话,就需要重新计算一下剩下的那部分的Kernel值,这部分新计算的值会保存到缓存中去。只要不删除掉,以后可以继续使用,不用再重复计算了。
5. Solver类
LibSVM中的Solver类主要是SVM中SMO算法求解拉格朗日乘子的实现。SMO算法的原理可以参考之前的一篇博客:http://www.cnblogs.com/bentuwuying/p/6444516.html。
// An SMO algorithm in Fan et al., JMLR 6(2005), p. 1889--1918
// Solves:
//
// min 0.5(\alpha^T Q \alpha) + p^T \alpha
//
// y^T \alpha = \delta
// y_i = +1 or -1
// 0 <= alpha_i <= Cp for y_i = 1
// 0 <= alpha_i <= Cn for y_i = -1
//
// Given:
//
// Q, p, y, Cp, Cn, and an initial feasible point \alpha
// l is the size of vectors and matrices
// eps is the stopping tolerance
//
// solution will be put in \alpha, objective value will be put in obj
//
class Solver {
5.1 Solver类的成员变量
int active_size;
byte[] y;
double[] G; // gradient of objective function
static final byte LOWER_BOUND = 0;
static final byte UPPER_BOUND = 1;
static final byte FREE = 2;
byte[] alpha_status; // LOWER_BOUND, UPPER_BOUND, FREE
double[] alpha;
QMatrix Q;
double[] QD;
double eps;
double Cp,Cn;
double[] p;
int[] active_set;
double[] G_bar; // gradient, if we treat free variables as 0
int l;
boolean unshrink; // XXX static final double INF = java.lang.Double.POSITIVE_INFINITY;
Solver类的成员变量。包括:
active_size:计算时实际参加运算的样本数目,经过shrinking处理后,该数目会小于全部样本总数。
y:样本所属类别,+1/-1。
G:梯度, 。
。
alpha_status:拉格朗日乘子的状态,分别是 ,代表内部点(非SV,LOWER_BOUND),错分点(BSV,UPPER_BOUND),和支持向量(SV,FREE)。
,代表内部点(非SV,LOWER_BOUND),错分点(BSV,UPPER_BOUND),和支持向量(SV,FREE)。
alpha:拉格朗日乘子。
Q:核函数矩阵。
QD:核函数矩阵中的对角线部分。
eps:误差极限。
Cp,Cn:正负样本各自的惩罚系数。
p:目标函数中的系数。
active_set:计算时实际参加运算的样本索引。
G_bar:在重建梯度时的中间变量,可以降低重建的计算开销。
l:样本数目。
5.2 Solver类的简单辅助成员函数
double get_C(int i)
{
return (y[i] > 0)? Cp : Cn;
}
double get_c(int i):返回对应样本的C值(惩罚系数)。这里对正负样本设置了不同的惩罚系数Cp,Cn。
void update_alpha_status(int i)
{
if(alpha[i] >= get_C(i))
alpha_status[i] = UPPER_BOUND;
else if(alpha[i] <= 0)
alpha_status[i] = LOWER_BOUND;
else alpha_status[i] = FREE;
}
void update_alpha_status(int i):更新拉格朗日乘子的状态。
boolean is_upper_bound(int i) { return alpha_status[i] == UPPER_BOUND; }
boolean is_lower_bound(int i) { return alpha_status[i] == LOWER_BOUND; }
boolean is_free(int i) { return alpha_status[i] == FREE; }
boolean is_upper_bound(int i),boolean is_lower_bound(int i),boolean is_free(int i):返回拉格朗日是否在界上。
// java: information about solution except alpha,
// because we cannot return multiple values otherwise...
static class SolutionInfo {
double obj;
double rho;
double upper_bound_p;
double upper_bound_n;
double r; // for Solver_NU
}
static class Solutioninfo:SMO算法求得的解(除了alpha)。
void swap_index(int i, int j)
{
Q.swap_index(i,j);
do {byte tmp=y[i]; y[i]=y[j]; y[j]=tmp;} while(false);
do {double tmp=G[i]; G[i]=G[j]; G[j]=tmp;} while(false);
do {byte tmp=alpha_status[i]; alpha_status[i]=alpha_status[j]; alpha_status[j]=tmp;} while(false);
do {double tmp=alpha[i]; alpha[i]=alpha[j]; alpha[j]=tmp;} while(false);
do {double tmp=p[i]; p[i]=p[j]; p[j]=tmp;} while(false);
do {int tmp=active_set[i]; active_set[i]=active_set[j]; active_set[j]=tmp;} while(false);
do {double tmp=G_bar[i]; G_bar[i]=G_bar[j]; G_bar[j]=tmp;} while(false);
}
void swap_index(int i, int j):完全交换样本 i 和样本 j 的内容,包括申请的内存的地址。
5.3 Solving the Quadratic Problems
我们可以用一个通用的表达式来表示SMO算法要解决的二次优化问题:

对于这个二次优化问题,最困难的地方在于Q是一个很大的稠密矩阵,难以存储,所以需要采用分解的方式解决,SMO算法就是采用每次选取拉格朗日乘子中的2个来更新,直到收敛到最优解。


5.4 Stopping Criteria
假设存在向量 是(11)式的解,则必然存在实数
是(11)式的解,则必然存在实数 和两个非负向量
和两个非负向量 使得下式成立:
使得下式成立:

其中, 是目标函数的梯度。
是目标函数的梯度。
上面的条件可以被重写为:

进一步,存在b使得
其中,

则目标函数存在最优解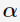 的条件是:
的条件是:

而实际实现过程中,优化迭代的停止条件为:

其中,epsilon是误差极限,tolerance。
5.5 Working Set Selection

// return 1 if already optimal, return 0 otherwise
int select_working_set(int[] working_set)
{
// return i,j such that
// i: maximizes -y_i * grad(f)_i, i in I_up(\alpha)
// j: mimimizes the decrease of obj value
// (if quadratic coefficeint <= 0, replace it with tau)
// -y_j*grad(f)_j < -y_i*grad(f)_i, j in I_low(\alpha) double Gmax = -INF;
double Gmax2 = -INF;
int Gmax_idx = -1;
int Gmin_idx = -1;
double obj_diff_min = INF; for(int t=0;t<active_size;t++)
if(y[t]==+1)
{
if(!is_upper_bound(t))
if(-G[t] >= Gmax)
{
Gmax = -G[t];
Gmax_idx = t;
}
}
else
{
if(!is_lower_bound(t))
if(G[t] >= Gmax)
{
Gmax = G[t];
Gmax_idx = t;
}
} int i = Gmax_idx;
float[] Q_i = null;
if(i != -1) // null Q_i not accessed: Gmax=-INF if i=-1
Q_i = Q.get_Q(i,active_size); for(int j=0;j<active_size;j++)
{
if(y[j]==+1)
{
if (!is_lower_bound(j))
{
double grad_diff=Gmax+G[j];
if (G[j] >= Gmax2)
Gmax2 = G[j];
if (grad_diff > 0)
{
double obj_diff;
double quad_coef = QD[i]+QD[j]-2.0*y[i]*Q_i[j];
if (quad_coef > 0)
obj_diff = -(grad_diff*grad_diff)/quad_coef;
else
obj_diff = -(grad_diff*grad_diff)/1e-12; if (obj_diff <= obj_diff_min)
{
Gmin_idx=j;
obj_diff_min = obj_diff;
}
}
}
}
else
{
if (!is_upper_bound(j))
{
double grad_diff= Gmax-G[j];
if (-G[j] >= Gmax2)
Gmax2 = -G[j];
if (grad_diff > 0)
{
double obj_diff;
double quad_coef = QD[i]+QD[j]+2.0*y[i]*Q_i[j];
if (quad_coef > 0)
obj_diff = -(grad_diff*grad_diff)/quad_coef;
else
obj_diff = -(grad_diff*grad_diff)/1e-12; if (obj_diff <= obj_diff_min)
{
Gmin_idx=j;
obj_diff_min = obj_diff;
}
}
}
}
} if(Gmax+Gmax2 < eps || Gmin_idx == -1)
return 1; working_set[0] = Gmax_idx;
working_set[1] = Gmin_idx;
return 0;
}
其中,第1个 for 循环是在确定工作集的第1个变量 i 。在确定了 i 之后,第2个 for 循环即是为了确定第2个变量 j 的选取。当两者都确定了之后,通过看停止条件来确定是否当前变量已经处在最优解上了,如果是则返回1,如果不是对working_set数组赋值并返回0。
5.6 Maintaining the Gradient
我们可以看到,在每次迭代中,主要操作是找到 ((12)式目标函数中会用到),以及
((12)式目标函数中会用到),以及 (在working set selection和stopping condition中会用到)。这两个主要操作可以合起来一起看待,因为:
(在working set selection和stopping condition中会用到)。这两个主要操作可以合起来一起看待,因为:


在第k次迭代中,我们已经得到了 ,于是便可以得到,用来计算(12)式的目标函数。当第k次迭代的目标函数得到解决后,我们又可以得到 k+1 次的
,于是便可以得到,用来计算(12)式的目标函数。当第k次迭代的目标函数得到解决后,我们又可以得到 k+1 次的 。所以,LibSVM在整个迭代优化过程中都一直维护着梯度数组。
。所以,LibSVM在整个迭代优化过程中都一直维护着梯度数组。
5.7 The Calculation of b
令
(1)当存在 ,有
,有 。为了数值的稳定性,做一个平均处理,
。为了数值的稳定性,做一个平均处理,

(2)当 ,有
,有

则取中值。
double calculate_rho()
{
double r;
int nr_free = 0;
double ub = INF, lb = -INF, sum_free = 0;
for(int i=0;i<active_size;i++)
{
double yG = y[i]*G[i]; if(is_lower_bound(i))
{
if(y[i] > 0)
ub = Math.min(ub,yG);
else
lb = Math.max(lb,yG);
}
else if(is_upper_bound(i))
{
if(y[i] < 0)
ub = Math.min(ub,yG);
else
lb = Math.max(lb,yG);
}
else
{
++nr_free;
sum_free += yG;
}
} if(nr_free>0)
r = sum_free/nr_free;
else
r = (ub+lb)/2; return r;
}
5.8 Shrinking
对于(11)式目标函数的最优解中会包含一些边界值 ,这些值在迭代优化的过程中可能就已经成为了边界值了,之后便不再变化。为了节省训练时间,使用shrinking方法去除这些个边界值,从而可以进一步解决一个更小的子优化问题。下面的这2个定理显示,在迭代的最后,只有一小部分变量还在改变。
,这些值在迭代优化的过程中可能就已经成为了边界值了,之后便不再变化。为了节省训练时间,使用shrinking方法去除这些个边界值,从而可以进一步解决一个更小的子优化问题。下面的这2个定理显示,在迭代的最后,只有一小部分变量还在改变。


使用A来表示 k 轮迭代中没有被shrinking的元素集合,从而(11)式目标函数便可以缩减为一个子优化问题:

其中, 是被shrinking的集合。在LibSVM中,通过元素的重排使得始终有
是被shrinking的集合。在LibSVM中,通过元素的重排使得始终有 。
。
当(28)式解决了之后,我们会发现可能会有部分的元素被错误地shrinking了。如果有这种情况发生,那么需要对(11)式原优化问题进行重新求解最优值,而重新求解的起始点即是 ,其中
,其中 是(28)式子问题的最优解,
是(28)式子问题的最优解, 是被shrinking的变量。
是被shrinking的变量。
shrinking的步骤如下:


private boolean be_shrunk(int i, double Gmax1, double Gmax2)
{
if(is_upper_bound(i))
{
if(y[i]==+1)
return(-G[i] > Gmax1);
else
return(-G[i] > Gmax2);
}
else if(is_lower_bound(i))
{
if(y[i]==+1)
return(G[i] > Gmax2);
else
return(G[i] > Gmax1);
}
else
return(false);
}
通过上述shrinking条件来判断第 i 个变量是否被shrinking。
void do_shrinking()
{
int i;
double Gmax1 = -INF; // max { -y_i * grad(f)_i | i in I_up(\alpha) }
double Gmax2 = -INF; // max { y_i * grad(f)_i | i in I_low(\alpha) } // find maximal violating pair first
for(i=0;i<active_size;i++)
{
if(y[i]==+1)
{
if(!is_upper_bound(i))
{
if(-G[i] >= Gmax1)
Gmax1 = -G[i];
}
if(!is_lower_bound(i))
{
if(G[i] >= Gmax2)
Gmax2 = G[i];
}
}
else
{
if(!is_upper_bound(i))
{
if(-G[i] >= Gmax2)
Gmax2 = -G[i];
}
if(!is_lower_bound(i))
{
if(G[i] >= Gmax1)
Gmax1 = G[i];
}
}
} if(unshrink == false && Gmax1 + Gmax2 <= eps*10)
{
unshrink = true;
reconstruct_gradient();
active_size = l;
} for(i=0;i<active_size;i++)
if (be_shrunk(i, Gmax1, Gmax2))
{
active_size--;
while (active_size > i)
{
if (!be_shrunk(active_size, Gmax1, Gmax2))
{
swap_index(i,active_size);
break;
}
active_size--;
}
}
}
第1个 for 循环是为了找到 这2个变量。
这2个变量。
因为有时候shrinking策略太过aggressive,所以当对shrinking之后的部分变量的优化问题迭代优化到第一次满足条件 时,便可以对梯度进行重建。于是,接下来的shrinking过程便可以建立在更精确的梯度值上。
时,便可以对梯度进行重建。于是,接下来的shrinking过程便可以建立在更精确的梯度值上。
最后的 for 循环是为了交换两个变量的位置,从而使得参与迭代优化的变量(即没有被shrinking的变量)始终保持在变量数组的最前面的连续位置上。进一步,为了减少交换操作的次数,从而优化计算开销,可以使用以下的trick:从左向右遍历找出需要被shrinking的变量位置 t1,从右向左遍历找出需要参与迭代优化计算的变量位置 t2,交换 t1 和 t2 的位置,然后继续遍历,直到两个遍历的指针相遇。
5.9 Reconstructing the Gradient
一旦(31)式和(32)式满足了,便需要重建梯度向量。因为在优化(28)子问题的时候, 一直都在内存中的,所以在重建梯度时,我们只需要计算
一直都在内存中的,所以在重建梯度时,我们只需要计算 即可。为了减少计算的开销,在迭代计算时,我们可以维护着另一个向量:
即可。为了减少计算的开销,在迭代计算时,我们可以维护着另一个向量:

而对于任意不在 A 集合中的变量 i 而言,有:

而对于上式的计算,包含了两层循环。是先对 i 循环还是先对 j 进行循环,意味着截然不同的Kernel evaluation次数。具体证明如下:

所以,我们具体选择method 1 还是method 2,是要看情况讨论的:

void reconstruct_gradient()
{
// reconstruct inactive elements of G from G_bar and free variables if(active_size == l) return; int i,j;
int nr_free = 0; for(j=active_size;j<l;j++)
G[j] = G_bar[j] + p[j]; for(j=0;j<active_size;j++)
if(is_free(j))
nr_free++; if(2*nr_free < active_size)
svm.info("\nWARNING: using -h 0 may be faster\n"); if (nr_free*l > 2*active_size*(l-active_size))
{
for(i=active_size;i<l;i++)
{
float[] Q_i = Q.get_Q(i,active_size);
for(j=0;j<active_size;j++)
if(is_free(j))
G[i] += alpha[j] * Q_i[j];
}
}
else
{
for(i=0;i<active_size;i++)
if(is_free(i))
{
float[] Q_i = Q.get_Q(i,l);
double alpha_i = alpha[i];
for(j=active_size;j<l;j++)
G[j] += alpha_i * Q_i[j];
}
}
}
5.10 迭代优化整体框架


void Solve(int l, QMatrix Q, double[] p_, byte[] y_,
double[] alpha_, double Cp, double Cn, double eps, SolutionInfo si, int shrinking)
Solver类中最重要的迭代优化函数 Solve 的接口格式。由于这个函数行数太多,下面分段进行剖析。
this.l = l;
this.Q = Q;
QD = Q.get_QD();
p = (double[])p_.clone();
y = (byte[])y_.clone();
alpha = (double[])alpha_.clone();
this.Cp = Cp;
this.Cn = Cn;
this.eps = eps;
this.unshrink = false;
对Solver类的一些成员变量进行初始化。
// initialize alpha_status
{
alpha_status = new byte[l];
for(int i=0;i<l;i++)
update_alpha_status(i);
}
初始化拉格朗日乘子状态向量值。
// initialize active set (for shrinking)
{
active_set = new int[l];
for(int i=0;i<l;i++)
active_set[i] = i;
active_size = l;
}
初始化需要参与迭代优化计算的拉格朗日乘子集合。
// initialize gradient
{
G = new double[l];
G_bar = new double[l];
int i;
for(i=0;i<l;i++)
{
G[i] = p[i];
G_bar[i] = 0;
}
for(i=0;i<l;i++)
if(!is_lower_bound(i))
{
float[] Q_i = Q.get_Q(i,l);
double alpha_i = alpha[i];
int j;
for(j=0;j<l;j++)
G[j] += alpha_i*Q_i[j];
if(is_upper_bound(i))
for(j=0;j<l;j++)
G_bar[j] += get_C(i) * Q_i[j];
}
}
初始化梯度G,以及为了重建梯度时候节省计算开销而维护的中间变量G_bar。
// optimization step
int iter = 0;
int max_iter = Math.max(10000000, l>Integer.MAX_VALUE/100 ? Integer.MAX_VALUE : 100*l);
int counter = Math.min(l,1000)+1;
int[] working_set = new int[2];
while(iter < max_iter)
{
// show progress and do shrinking
if(--counter == 0)
{
counter = Math.min(l,1000);
if(shrinking!=0) do_shrinking();
svm.info(".");
}
if(select_working_set(working_set)!=0)
{
// reconstruct the whole gradient
reconstruct_gradient();
// reset active set size and check
active_size = l;
svm.info("*");
if(select_working_set(working_set)!=0)
break;
else
counter = 1; // do shrinking next iteration
}
int i = working_set[0];
int j = working_set[1];
++iter;
// update alpha[i] and alpha[j], handle bounds carefully
float[] Q_i = Q.get_Q(i,active_size);
float[] Q_j = Q.get_Q(j,active_size);
double C_i = get_C(i);
double C_j = get_C(j);
double old_alpha_i = alpha[i];
double old_alpha_j = alpha[j];
if(y[i]!=y[j])
{
double quad_coef = QD[i]+QD[j]+2*Q_i[j];
if (quad_coef <= 0)
quad_coef = 1e-12;
double delta = (-G[i]-G[j])/quad_coef;
double diff = alpha[i] - alpha[j];
alpha[i] += delta;
alpha[j] += delta;
if(diff > 0)
{
if(alpha[j] < 0)
{
alpha[j] = 0;
alpha[i] = diff;
}
}
else
{
if(alpha[i] < 0)
{
alpha[i] = 0;
alpha[j] = -diff;
}
}
if(diff > C_i - C_j)
{
if(alpha[i] > C_i)
{
alpha[i] = C_i;
alpha[j] = C_i - diff;
}
}
else
{
if(alpha[j] > C_j)
{
alpha[j] = C_j;
alpha[i] = C_j + diff;
}
}
}
else
{
double quad_coef = QD[i]+QD[j]-2*Q_i[j];
if (quad_coef <= 0)
quad_coef = 1e-12;
double delta = (G[i]-G[j])/quad_coef;
double sum = alpha[i] + alpha[j];
alpha[i] -= delta;
alpha[j] += delta;
if(sum > C_i)
{
if(alpha[i] > C_i)
{
alpha[i] = C_i;
alpha[j] = sum - C_i;
}
}
else
{
if(alpha[j] < 0)
{
alpha[j] = 0;
alpha[i] = sum;
}
}
if(sum > C_j)
{
if(alpha[j] > C_j)
{
alpha[j] = C_j;
alpha[i] = sum - C_j;
}
}
else
{
if(alpha[i] < 0)
{
alpha[i] = 0;
alpha[j] = sum;
}
}
}
// update G
double delta_alpha_i = alpha[i] - old_alpha_i;
double delta_alpha_j = alpha[j] - old_alpha_j;
for(int k=0;k<active_size;k++)
{
G[k] += Q_i[k]*delta_alpha_i + Q_j[k]*delta_alpha_j;
}
// update alpha_status and G_bar
{
boolean ui = is_upper_bound(i);
boolean uj = is_upper_bound(j);
update_alpha_status(i);
update_alpha_status(j);
int k;
if(ui != is_upper_bound(i))
{
Q_i = Q.get_Q(i,l);
if(ui)
for(k=0;k<l;k++)
G_bar[k] -= C_i * Q_i[k];
else
for(k=0;k<l;k++)
G_bar[k] += C_i * Q_i[k];
}
if(uj != is_upper_bound(j))
{
Q_j = Q.get_Q(j,l);
if(uj)
for(k=0;k<l;k++)
G_bar[k] -= C_j * Q_j[k];
else
for(k=0;k<l;k++)
G_bar[k] += C_j * Q_j[k];
}
}
}
迭代优化最重要的循环部分。每间隔若干次迭代进行一次shrinking,使得部分变量不用参与迭代计算。选择工作集合(包含2个拉格朗日乘子),对工作集合进行更新计算操作。具体的更新原理可见paper:《Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines》。更新完工作集合后,再更新梯度G,拉格朗日乘子的状态向量,以及维护的中间变量G_bar。
// calculate rho
si.rho = calculate_rho();
// calculate objective value
{
double v = 0;
int i;
for(i=0;i<l;i++)
v += alpha[i] * (G[i] + p[i]);
si.obj = v/2;
}
// put back the solution
{
for(int i=0;i<l;i++)
alpha_[active_set[i]] = alpha[i];
}
si.upper_bound_p = Cp;
si.upper_bound_n = Cn;
svm.info("\noptimization finished, #iter = "+iter+"\n");
收尾工作。
6. Multi-class classification
LibSVM使用了“one-against-one”的方法实现了多分类。如果有 k 类样本,则需要建立 k(k-1)/2个分类器。
在预测时,用k(k-1)/2个分类器对预测样本进行预测,得出k(k-1)/2个预测类别,使用投票策略,选择预测数最多的那个类别作为最终的预测类别。
7. 参考文献
1. LIBSVM: A Library for Support Vector Machines
2. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines
3. Working Set Selection Using Second Order Information
版权声明:
本文由笨兔勿应所有,发布于http://www.cnblogs.com/bentuwuying。如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。
[笔记]LibSVM源码剖析(java版)的更多相关文章
- LibSVM源码剖析(java版)
之前学习了SVM的原理(见http://www.cnblogs.com/bentuwuying/p/6444249.html),以及SMO算法的理论基础(见http://www.cnblogs.com ...
- Java ArrayList源码剖析
转自: Java ArrayList源码剖析 总体介绍 ArrayList实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入null元素,底层通过数组实现.除该类未实现同步外 ...
- Java HashSet和HashMap源码剖析
转自: Java HashSet和HashMap源码剖析 总体介绍 之所以把HashSet和HashMap放在一起讲解,是因为二者在Java里有着相同的实现,前者仅仅是对后者做了一层包装,也就是说Ha ...
- [转]【安卓笔记】AsyncTask源码剖析
[转][安卓笔记]AsyncTask源码剖析 http://blog.csdn.net/chdjj/article/details/39122547 前言: 初学AsyncTask时,就想研究下它的实 ...
- 我的书籍《深入解析Java编译器:源码剖析与实例详解》就要出版了
一个十足的技术迷,2013年毕业,做过ERP.游戏.计算广告,在大公司呆过,但终究不满足仅对技术的应用,在2018年末离开了公司,全职写了一本书<深入解析Java编译器:源码剖析与实例详解> ...
- STL源码剖析读书笔记之vector
STL源码剖析读书笔记之vector 1.vector概述 vector是一种序列式容器,我的理解是vector就像数组.但是数组有一个很大的问题就是当我们分配 一个一定大小的数组的时候,起初也许我们 ...
- 转:【Java集合源码剖析】LinkedHashmap源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/37867985 前言:有网友建议分析下LinkedHashMap的源码,于是花了一晚上时 ...
- 转:【Java集合源码剖析】TreeMap源码剖析
前言 本文不打算延续前几篇的风格(对所有的源码加入注释),因为要理解透TreeMap的所有源码,对博主来说,确实需要耗费大量的时间和经历,目前看来不大可能有这么多时间的投入,故这里意在通过于阅读源码对 ...
- 转:【Java集合源码剖析】Hashtable源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/36191279 Hashtable简介 Hashtable同样是基于哈希表实现的,同样每个元 ...
随机推荐
- 开箱即用 - Grunt合并和压缩 js,css 文件
js,css 文件合并与压缩 Grunt 是前端自动化构建工具,类似webpack. 它究竟有多强悍,请看它的 介绍. 这里只演示如何用它的皮毛功能:文件合并与压缩. 首先说下js,css 合并与压缩 ...
- github使用介绍
github是个比较火的分布式版本管理工具,适合多人协同工作,感觉比svn好.下面简单介绍一下github使用以及把本地代码和github同步的方法. 首先注册账号 https://github.co ...
- page cache 与free
我们经常用free查看服务器的内存使用情况,而free中的输出却有些让人困惑,如下: 先看看各个数字的意义以及如何计算得到: free命令输出的第二行(Mem):这行分别显示了物理内存的总量(tota ...
- 将 ext_net 连接到 router - 每天5分钟玩转 OpenStack(145)
上一节完我们创建了外部网络 ext_net,接下来需要将其连接到 Neutron 的虚拟路由器,这样 instance 才能访问外网. 点击菜单 Project -> Network -> ...
- 应用程序初次运行数据库配置小程序(Java版)
应用程序初始化数据库配置小程序 之前写过一个Java版的信息管理系统,但部署系统的时候还需要手动的去配置数据库和导入一些初始化的数据才能让系统运行起来,所以我在想是不是可以写一个小程序在系统初次运行的 ...
- 【java设计模式】之 抽象工厂(Abstract Factory)模式
1. 女娲的失误 上一节学习了工厂模式,女娲运用了该模式成功创建了三个人种,可是问题来了,她发现没有性别--这失误也忒大了点吧--竟然没有性别,那岂不是--无奈,只好抹掉重来了,于是所有人都被消灭掉了 ...
- WinForm 控件(上)
窗体的事件 每一个窗体都有一个事件,这个窗体加载完成之后执行哪一段代码 位置:1)右键属性→事件→load 双击进入 2)双击窗体任意一个位置进入 删除事件:先将事件页面里面的挂好的事件删除,再删后台 ...
- oracle_角色
一. 每个Oracle用户都有一个名字和口令,并拥有一些由其创建的表.视图和其他资源. Oracle角色(role)就是一组权限(privilege) (或者是每个用户根据其状态和条件所需的访问类型) ...
- BZOJ 3479: [Usaco2014 Mar]Watering the Fields(最小生成树)
这个= =最近刷的都是水题啊QAQ 排除掉不可能的边然后就最小生成树就行了= = CODE: #include<cstdio>#include<iostream>#includ ...
- 如何通过Visual Studio来管理我们的数据库项目
某日的一个早晨,产品早上来告诉我说要把之前变更的一个功能更改回原来的设计内容,作为程序员大家都最讨厌需求来回反复变更,但是没有办法,苦逼的程序员最终还是继续要改,毕竟是给老板打工的,但是发现我们之前的 ...