Kafka的基本概念与安装指南(单机+集群同步)
最近在搞spark streaming,很自然的前端对接的就是kafka。不过在kafka的使用中还是遇到一些问题,比如mirrormaker莫名其妙的丢失数据[原因稍后再说],消费数据offset错乱[之后介绍spark streaming的时候再解释]
总之,还是遇到了不少的问题。本篇就从下面几个方面介绍一下kafka:
- 基本介绍
- 安装与helloworld
- producer
- consumer
- mirror maker跨集群同步
- 控制台
基本介绍
Kafka是一款分布式的消息队列框架,它由三个重要的部分组成:
- Producer 消息的生产者,负责生产消息
- Broker 消息的存储,负责消息的持久化与高可用
- Consumer 消息的消费者,负责消费消息
大致的结构如下:
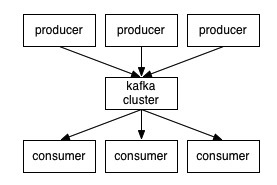
消息则是通过topic进行标识,每个topic可以有多个partition分区组成。每一个parition内部消息是按照顺序写入的,所有的partition加起来才是全部的数据,也就是说kafka并不能保证全局有序,只能保证在某一个partition内部是有序的。
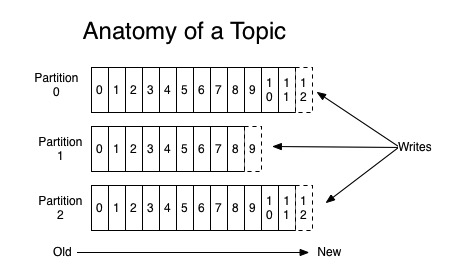
消费者消费数据的时候是根据一个叫做offset的游标来记录消费的位置,可以通俗的把它理解成递增的id。
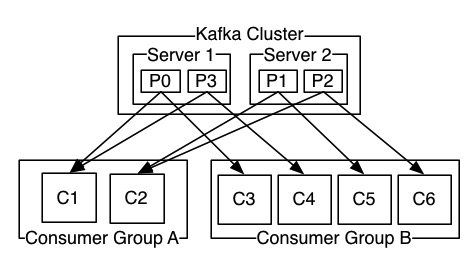
消费者可以由多个组成一个消费者组,同一个消费者组内的数据不会重复消费。不过消费者的数量跟partition的数量是有关系的,如果只有一个partition,那么即便是由10个消费者,同一时间也只能由一个消费者进行消费。
另外,broker是负责消息的持久化,前面提到过消息是通过partition组织在一起的,物理上则是通过一个log文件来记录。如果有一条消息写入,就会追加到log文件的末尾,当大小超过一定的阈值后,就新建一个log文件。如果log文件的修改时间超过一定的阈值,kafka还会清理掉该文件。
原理的东西就简单说这么多,下面来看看安装与体验吧!
安装与hello world
按照官方文档的步骤,是最快的入门方式:
下载安装包
去官方下载地址下载安装包,并参照对应的版本的文档即可,下载后执行下面的命令:
> tar -xzf kafka_2.11-0.9.0.0.tgz
> cd kafka_2.11-0.9.0.0
启动zookeeper
如果方便的话,最好自己额外安装zookeeper,或者与其他的组建公用一个zk,否则单独为了kafka运行一个zk还是挺浪费资源的。
> bin/zookeeper-server-start.sh config/zookeeper.properties
最好不要随意修改zk的地址,2181是默认的端口号,如果修改,后面启动kafka会很麻烦,修改的地方会很多。
启动kafka-broker
bin/kafka-server-start.sh config/server.properties
创建主题并查看
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
bin/kafka-topics.sh --list --zookeeper localhost:2181
启动producer
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
启动consumer
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
至此,单机版的kafka就搭建完成了!如果要创建kafka的集群,可以直接
producer例子
import kafka.producer.KeyedMessage;
import kafka.javaapi.producer.Producer;
import kafka.producer.ProducerConfig;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class KafkaProducer {
private static final String TOPIC = "test"; //kafka创建的topic
private static final String CONTENT = "This is a single message"; //要发送的内容
private static final String BROKER_LIST = "xxxx:9092"; //broker的地址和端口
private static final String SERIALIZER_CLASS = "kafka.serializer.StringEncoder"; // 序列化类
public static void main(String[] args) {
Properties props = new Properties();
props.put("serializer.class", SERIALIZER_CLASS);
props.put("metadata.broker.list", BROKER_LIST);
ProducerConfig config = new ProducerConfig(props);
Producer<String, String> producer = new Producer<String, String>(config);
//Send one message.
KeyedMessage<String, String> message =
new KeyedMessage<String, String>(TOPIC, CONTENT);
producer.send(message);
//Send multiple messages.
List<KeyedMessage<String,String>> messages =
new ArrayList<KeyedMessage<String, String>>();
for (int i = 0; i < 100; i++) {
messages.add(new KeyedMessage<String, String>
(TOPIC, i+"Multiple message at a time. " + i));
}
producer.send(messages);
producer.close();
}
}
执行后,如果有一个consumer启动,就可以看到消息输出。
consumer例子
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
public class KafkaConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("zookeeper.connect", "xxxx:2181");
props.put("group.id", "t1");
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put("xxx-topic", 1);
ConsumerConnector consumer = Consumer.createJavaConsumerConnector(new ConsumerConfig(props));
Map<String, List<KafkaStream<byte[], byte[]>>> msgStreams = consumer.createMessageStreams(topicCountMap);
List<KafkaStream<byte[], byte[]>> msgStreamList = msgStreams.get("test");
for(KafkaStream stream : msgStreamList){
ConsumerIterator<byte[], byte[]> iterator = stream.iterator();
while(iterator.hasNext()) {
String message = new String(iterator.next().message());
if(message.contains("xxxx")){
System.out.println(message);
}
}
}
}
}
跨集群同步——mirror maker
如果公司有云环境,可能还涉及到多个集群环境数据的同步。那么官方提供了一个mirrormaker的工具,它其实就是封装了一个consumer和一个producer,把一个集群的数据,直接消费到另一个集群。
代码可以参考github:
https://github.com/apache/kafka/blob/trunk/core/src/main/scala/kafka/tools/MirrorMaker.scala
文档可以参考:
https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=27846330
我这里介绍一下它的用法,首先启动的脚本,官方已经封装到kafka解压后的bin目录下。
主要用到了kafka-run-class.sh,kafka-mirror-maker.sh脚本其实就是对它的一层封装:
exec $(dirname $0)/kafka-run-class.sh kafka.tools.MirrorMaker $@
然后需要创建两个配置文件,分别是consumer的配置文件和producer的配置文件:
consumer.properties
zookeeper.connect=xxxx:2181
group.id=test-mirror
zookeeper.connect是想要消费的集群的zk地址,group.id是消费者组的id,一定别跟其他的mirrormaker搞到一起哈![这就是我开篇遇到的问题原因]。
producer.properties
zk.connect=localhost:2181
bootstrap.servers=localhost:9092
zk.connect是消息即将存储的zk地址, bootstrap.servers是消息即将存储的broker地址。(我试过没有bootstrap.servers的话,会报错)
然后执行下面的命令,启动脚本即可:
./kafka-run-class.sh kafka.tools.MirrorMaker --consumerrties --producer.config producer.properties --whitelist test --num.streams 2
num.streams控制了消费者的个数,必须要设置的。
这样就开启了mirrormaker服务,可以看到第一个集群的所有消息,都同步到了第二个集群。
控制台主要功能介绍
控制台可以安装kafka-manager进行监控与管理,安装的教程可以参考:
http://blog.csdn.net/lsshlsw/article/details/47300145
集群概况
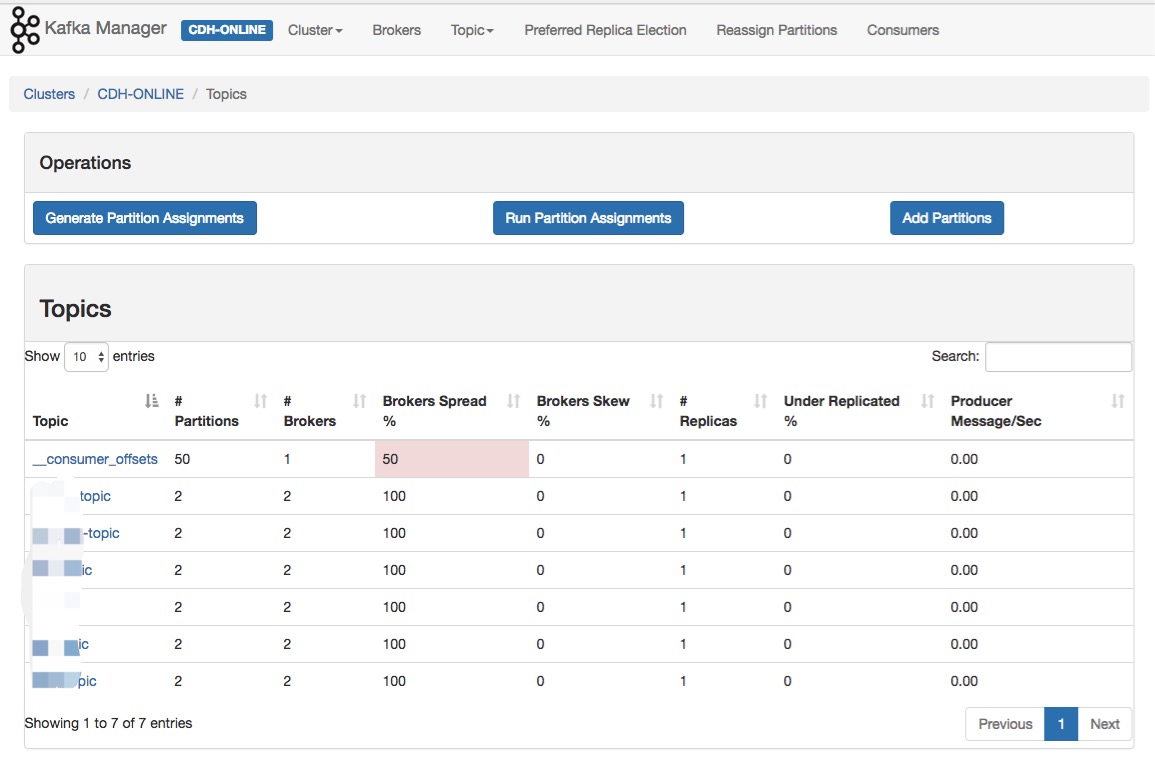
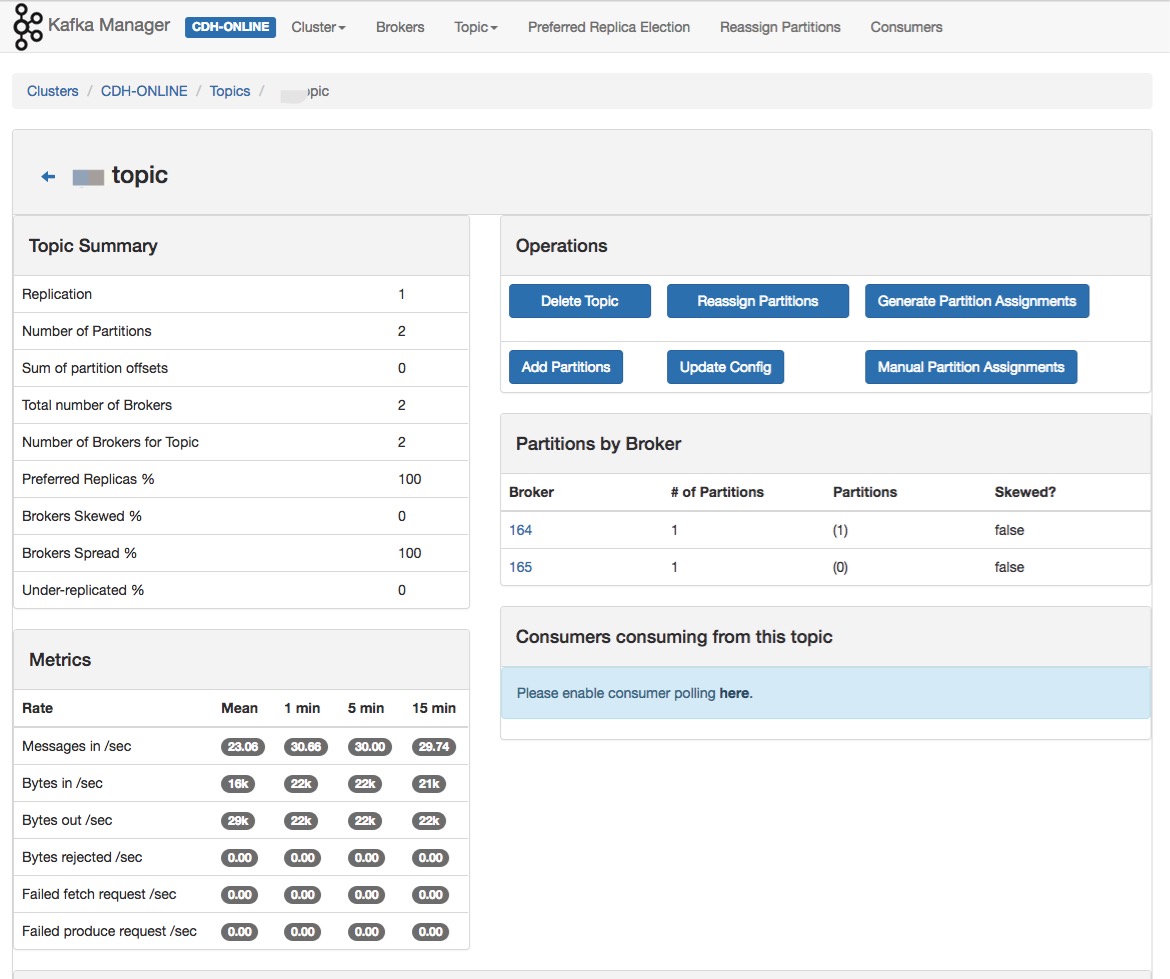
主题
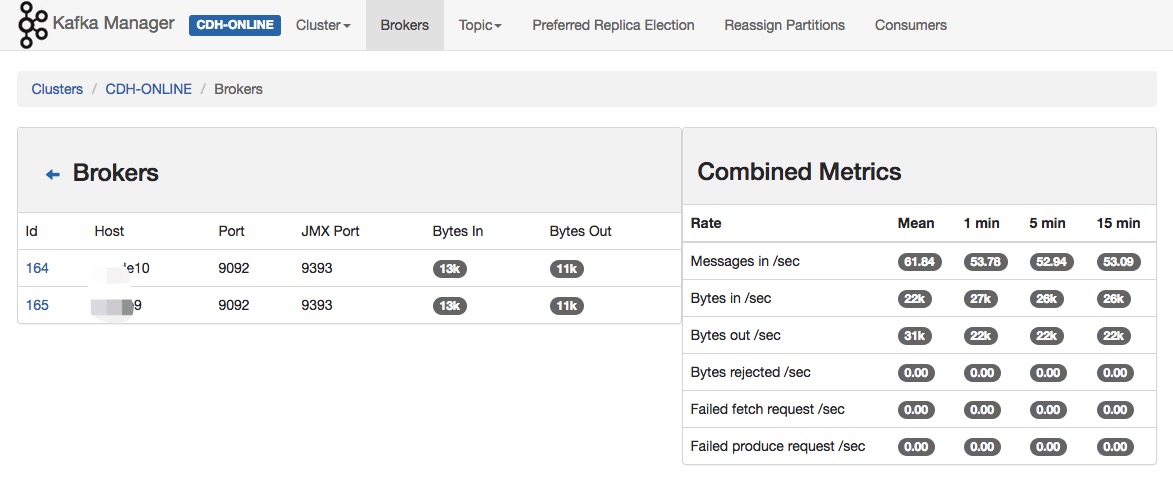
broker
消费者
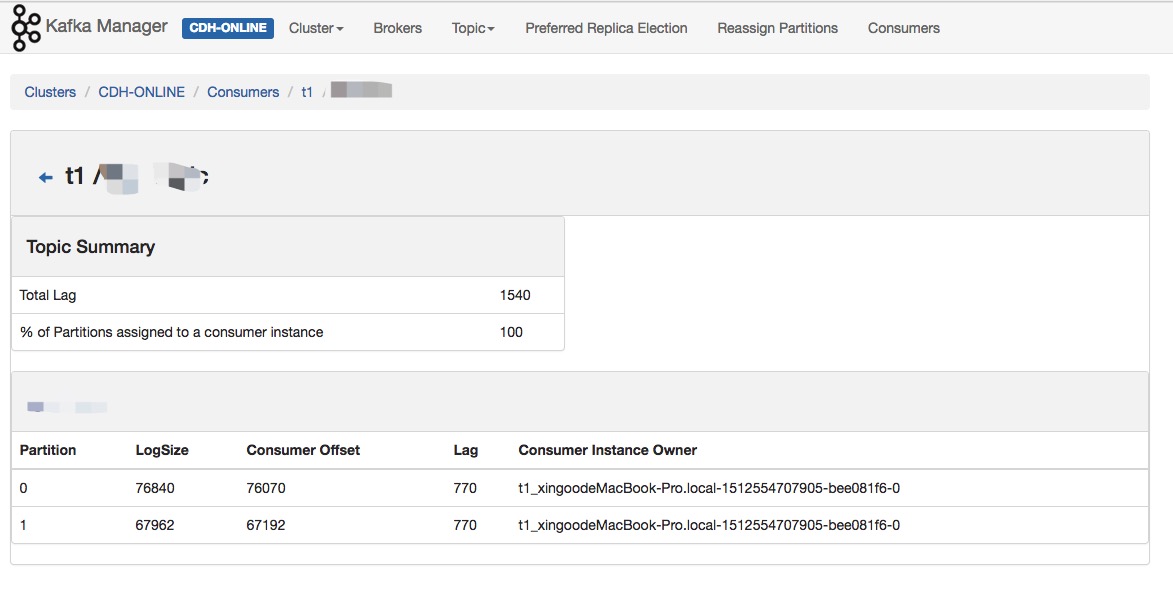
参考
Kafka的基本概念与安装指南(单机+集群同步)的更多相关文章
- 阿里云构建Kafka单机集群环境
简介 在一台ECS阿里云服务器上构建Kafa单个集群环境需要如下的几个步骤: 服务器环境 JDK的安装 ZooKeeper的安装 Kafka的安装 1. 服务器环境 CPU: 1核 内存: 2048 ...
- Redis基本概念、基本使用与单机集群部署
1. Redis基础 1.1 Redis概述 Redis是一个开源.先进的key-value存储,并用于构建高性能.可扩展的应用程序的完美解决方案. Redis从它的许多竞争继承了三个主要特点: ...
- 顶级Apache Kafka术语和概念
1.卡夫卡术语 基本上,Kafka架构 包含很少的关键术语,如主题,制作人,消费者, 经纪人等等.要详细了解Apache Kafka,我们必须首先理解这些关键术语.因此,在本文“Kafka术语”中, ...
- 玩转nodeJS系列:使用原生API实现简单灵活高效的路由功能(支持nodeJs单机集群),nodeJS本就应该这样轻快
前言: 使用nodeJS原生API实现快速灵活路由,方便与其他库/框架进行整合: 1.原生API,简洁高效的轻度封装,加速路由解析,nodeJS本就应该这样轻快 2.不包含任何第三方库/框架,可以灵活 ...
- zookeeper单机集群搭建
1. 下载zookeeper 参考官方文档下载一节:https://zookeeper.apache.org/doc/current/zookeeperStarted.html#sc_Download ...
- Kafka 跨集群同步方案(转)
来自:http://tangzhaohui.net/524 Kafka 跨集群同步方案——Kafka内置的MirrorMaker工具 该方案解决Kafka跨集群同步.创建Kafka集群镜像等相关问题, ...
- Kafka跨集群同步工具——MirrorMaker
MirrorMaker是为解决Kafka跨集群同步.创建镜像集群而存在的.下图展示了其工作原理.该工具消费源集群消息然后将数据又一次推送到目标集群. watermark/2/text/aHR0cDov ...
- RabbitMQ入门教程(十四):RabbitMQ单机集群搭建
原文:RabbitMQ入门教程(十四):RabbitMQ单机集群搭建 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://b ...
- Presto单机/集群模式安装笔记
Presto单机/集群模式安装笔记 一.安装环境 二.安装步骤 三.集群模式安装: 3.1 集群模式修改配置部分 3.1.1 coordinator 节点配置. Node172配置 3.1.2 nod ...
随机推荐
- 在.NET Core类库中使用EF Core迁移数据库到SQL Server
前言 如果大家刚使用EntityFramework Core作为ORM框架的话,想必都会遇到数据库迁移的一些问题. 起初我是在ASP.NET Core的Web项目中进行的,但后来发现放在此处并不是很合 ...
- QT之TCP通信
QT中可以通过TCP协议让服务器和客户端之间行通信.所以下面我就围绕服务器和客户端来写. 这是我么写服务器和客户端的具体流程: A.服务器: 1.创建QTcpServer对象 2.启动 ...
- 项目实战8—tomcat企业级Web应用服务器配置与会话保持
tomcat企业级Web应用服务器配置与实战 环境背景:公司业务经过长期发展,有了很大突破,已经实现盈利,现公司要求加强技术架构应用功能和安全性以及开始向企业应用.移动APP等领域延伸,此时原来开发w ...
- Springboot读取配置文件及自定义配置文件
1.创建maven工程,在pom文件中添加依赖 <parent> <groupId>org.springframework.boot</groupId> <a ...
- Zepto中的Swipe事件失效
需要阻止浏览器默认滑动的事件 document.addEventListener('touchmove', function (event) { event.preventDefault(); }, ...
- 前端开发者常用的9个JavaScript图表库
当前,数据可视化已经成为数据科学领域非常重要的一部分.不同网络系统中产生的数据,都需要经过适当的可视化处理,以便更好的呈现给用户读取和分析. 对任何一个组织来说,如果能够充分的获取数据.可视化数据和分 ...
- PHP递归解决兔子问题,面试必备
接到面试通知辗转反侧,一直在默念明天改如何介绍自己的项目经验等.早早的起床,洗漱,把自己的总结的问题自问自答了一些.匆匆吃了早饭,挤进让人面目狰狞的地铁,此时什么都不顾,只盼着赶紧下地铁.终于提前半小 ...
- 关于Oracle处理DDL和DML语句的事务管理
SQL主要程序设计语言 数据定义语言DDL(Data Definition Language) 如 create.alter.drop, 数据操作语言DML(Data Munipulation Lan ...
- C++ Primer高速入门之三:几种常见的控制语句
语句总是顺序运行的:第一条语句运行完了接着是第二条,第三条等等.这是最简单的情况,为了更好的控制语句的运行.程序设计语言提供了多种控制结构支持更为复杂的语句运行.我们就来看看C++ 提供的控制方式. ...
- zookeeper web ui-->node-zk-browser安装
眼下公司正在使用zookeeper做配置管理和其它工作,在网上找几个zookeeper管理工具,都不尽人意,要么功能不够强大,要么不能友好的浏览zk树形结构.我的想法是zk管理工具,应该有一个树形结构 ...