Lucene的配置及创建索引全文检索
Lucene
是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
优点
概念
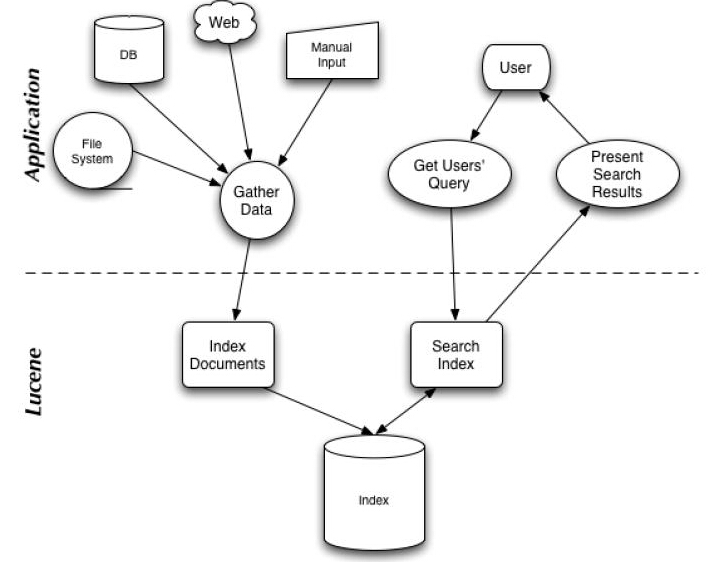
Lucene配置

public static void createindex() throws Exception {
//创建文件目录 创建在项目目录下的index中
Directory dir=FSDirectory.open(FileSystems.getDefault().getPath(System.getProperty("user.dir")+"/index"));
//分词处理 是一个抽象类 一种单字分词,标准的
Analyzer analyzer=new IKAnalyzer();
//创建IndexWriterConfig对象
IndexWriterConfig config=new IndexWriterConfig(analyzer);
//创建IndexWriter对象
IndexWriter iWriter=new IndexWriter(dir, config);
//清除之前的索引
iWriter.deleteAll();
//创建文档对象
Document doc=new Document();
//向文档中添加文本内容字段,及字段类型
doc.add(new Field("fieldname","坚持到底gl博主的博文,转载请注释出处", TextField.TYPE_STORED));
//将文档添加到indexWriter中,写入索引文件中
iWriter.addDocument(doc);
//关闭写入
iWriter.close();
}
这样运行可以看到你的索引index中的内容文件已经创建出来了
索引已经创建,接下来查询一下试试索引 ,传入需要查询的词
public static void search(String string) throws Exception {
Directory dir=FSDirectory.open(FileSystems.getDefault().getPath(System.getProperty("user.dir")+"/search"));
//打开索引目录的
DirectoryReader dReader=DirectoryReader.open(dir);
IndexSearcher searcher=new IndexSearcher(dReader);
//第一个参数 field值 ,第二个参数用户需要检索的字符串
Term t=new Term("fieldname",string);
//将用户需要索引的字符串封装成lucene能识别的内容
Query query=new TermQuery(t);
//查询,最大的返回值10
TopDocs top=searcher.search(query, 10);
//命中数,那个字段命中,命中的字段有几个
System.out.println("命中数:"+top.totalHits);
//查询返回的doc数组
ScoreDoc[] sDocs= top.scoreDocs;
for (ScoreDoc scoreDoc : sDocs) {
//输出命中字段内容
System.out.println(searcher.doc(scoreDoc.doc).get(field));
}
}
就这样一个全文检索的测试就出来了,多去思考总结,扩展出去
再给添加一个代码有益于理解
public static void main(String[] args) throws Exception {
String chString="坚持到底的文章,转载请注释出处";
Analyzer analyzer=new IKAnalyzer();
TokenStream stream=analyzer.tokenStream("word", chString);
stream.reset();
CharTermAttribute cta=stream.addAttribute(CharTermAttribute.class);
while (stream.incrementToken()) {
System.out.println(cta.toString());
}
stream.close();
}
显示如下:

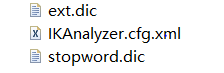
还可以添加这几个文件,有一点需要注意的是,注意你的编码格式
第一个:ext.dic 扩展词典,分词中那个需要组在一起的,如:分词处理可能将“坚持到底”四个字分为“坚持”和“到底”,可以在这个文件中直接添加坚持到底,就可以显示出坚持到底的这个索引
第三个:stopword.dic 扩展停止词典,分词中不想出现的,不希望他被分开出现或单独的,可以往里面写,检索的时候就不会有
第二个:是指定上面两个扩展词典的
这些就是最基本掌握的内容,还有很多分词算法等类型,需要去扩展
Lucene的配置及创建索引全文检索的更多相关文章
- Lucene学习之一:使用lucene为数据库表创建索引,并按关键字查询
最近项目中要用到模糊查询,开始研究lucene,期间走了好多弯路,总算实现了一个简单的demo. 使用的lucene jar包是3.6版本. 一:建立数据库表,并加上测试数据.数据库表:UserInf ...
- Lucene学习笔记:一,全文检索的基本原理
一.总论 根据http://lucene.apache.org/java/docs/index.html定义: Lucene是一个高效的,基于Java的全文检索库. 所以在了解Lucene之前要费一番 ...
- 用Lucene对文档进行索引搜索
问题 现在给出很多份文档,现在对某个搜索词感兴趣,想找到相关的文档. 简单搜索 一种简单粗暴的做法是: 1.读取每个文档:2.找到其中含有搜索词的文档:3.对找到的文档中搜索词出现的次数统计:4.根据 ...
- Elasticsearch-索引新数据(创建索引、添加数据)
ES-索引新数据 0.通过mapping映射新建索引 CURL -XPOST 'localhost:9200/test/index?pretty' -d '{ "mappings" ...
- Apache Lucene(全文检索引擎)—创建索引
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- lucene创建索引
创建索引. 1.lucene下载. 下载地址:http://archive.apache.org/dist/lucene/java/. lucene不同版本之间有不小的差别,这里下载的是lucene ...
- lucene简介 创建索引和搜索初步
lucene简介 创建索引和搜索初步 一.什么是Lucene? Lucene最初是由Doug Cutting开发的,2000年3月,发布第一个版本,是一个全文检索引擎的架构,提供了完整的查询引擎和索引 ...
- lucene全文搜索之二:创建索引器(创建IKAnalyzer分词器和索引目录管理)基于lucene5.5.3
前言: lucene全文搜索之一中讲解了lucene开发搜索服务的基本结构,本章将会讲解如何创建索引器.管理索引目录和中文分词器的使用. 包括标准分词器,IKAnalyzer分词器以及两种索引目录的创 ...
- Lucene 4.7 --创建索引
Lucene的最新版本和以前的语法或者类名,类规定都相差甚远 0.准备工作: 1). Lucene官方API http://lucene.apache.org/core/4_7_0/index.htm ...
随机推荐
- 关于EasyUI中DataGrid控件的一些使用方法总结
一,DataGrid 控件的工作流程 1,通过JavaScript将一个空白的div美化成一个空白的Datagrid模板 2,Datagrid模板通过制定的Url发送请求,获取数据 ...
- Python:使用Kivy将python程序打包为apk文件
1.概述 Kivy是一套Python下的跨平台开源应用开发框架,官网,我们可以用 它来将Python程序打包为安卓的apk安装文件.以下是在windows环境中使用. 安装和配置的过程中会下载很多东西 ...
- 5.spark弹性分布式数据集
弹性分布式数据集 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- JavaBean+servlet+jsp——>对数据进行增删改查
1.开始页面(查询数据) <%@page import="com.zdsofe.work.Student"%> <%@page import="java ...
- 走进STM32世界之Hex程序烧写
多数51单片机(STC系列单片机)的初学者都知道,在51单片机初上电时,可以通过PC机上位机软件将程序引导至bootloader,从而将新程序的hex文件下载至单片机中,完成程序的升级或是更新.在32 ...
- C#设计模式(1)-单例模式
单例(Singleton)模式介绍 单例模式:也可以叫单件模式,官方定义:保证一个类仅有一个实例,并提供一个访问它的全局访问点. 单例模式的特点: 单例类只能有一个实例. 单例类必须自己创建自己的唯一 ...
- 48. leetcode 105题 由树的前序序列和中序序列构建树结构
leetcode 105题,由树的前序序列和中序序列构建树结构.详细解答参考<剑指offer>page56. 先序遍历结果的第一个节点为根节点,在中序遍历结果中找到根节点的位置.然后就可以 ...
- 28.leetcode 13. Roman to Integer
思路:罗马计数转阿拉伯数字.罗马数字构造规则:http://www.cnblogs.com/glorywu/p/5256968.html.从右至左,用max记录当前最大数的符号,若当前索引处的数字比m ...
- Hadoop 新生报道(二) hadoop2.6.0 集群系统版本安装和启动配置
本次基于Hadoop2.6版本进行分布式配置,Linux系统是基于CentOS6.5 64位的版本.在此设置一个主节点和两个从节点. 准备3台虚拟机,分别为: 主机名 IP地址 master 192. ...
- [dubbo实战] dubbo+zookeeper伪集群搭建
zookeeper作为注册中心,服务器和客户端都要访问,如果有大量的并发,肯定会有等待.所以可以通过zookeeper集群解决. 一.为什么需要zookeeper呢? 大部分分布式应用需要一个主控.协 ...