Deep Q-Network 学习笔记(一)—— Q-Learning 学习与实现过程中碰到的一些坑
这方面的资料比较零散,学起来各种碰壁,碰到各种问题,这里就做下学习记录。
参考资料:
非常感谢莫烦老师的教程
http://mnemstudio.org/path-finding-q-learning-tutorial.htm
http://www.cnblogs.com/dragonir/p/6224313.html
这篇文章也是用非常简单的说明将 Q-Learning 的过程给讲解清楚了
http://www.cnblogs.com/jinxulin/tag/%E5%A2%9E%E5%BC%BA%E5%AD%A6%E4%B9%A0/
还有感谢这位园友,将增强学习的原理讲解的非常清晰
这里还是先以上面教程中的例子来实现 Q-Learning。
目录:
Deep Q-Network 学习笔记(一)—— Q-Learning
Deep Q-Network 学习笔记(二)—— Q-Learning与神经网络结合使用
一、思路

图 1.1
这里,先自己对那个例子的理解总结一下。
要解决的问题是:如上图 1.1 中有 5 个房间,分别被标记成 0-4,房间外可以看成是一个大的房间,被标记成 5,现在智能程序 Agent 被随机丢在 0-4 号 5 个房间中的任意 1 个,目标是让它寻找到离开房间的路(即:到达 5 号房间)。
图片描述如下:
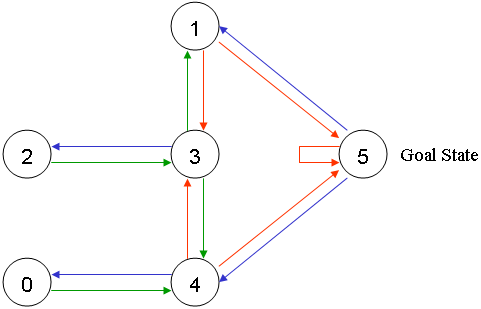
图 1.2
给可以直接移动到 5 号房间的动作奖励 100 分,即:图1.2中,4 到 5 、 1 到 5 和 5 到 5 的红线。
在其它几个可移动的房间中移动的动作奖励 0 分。
如下图:
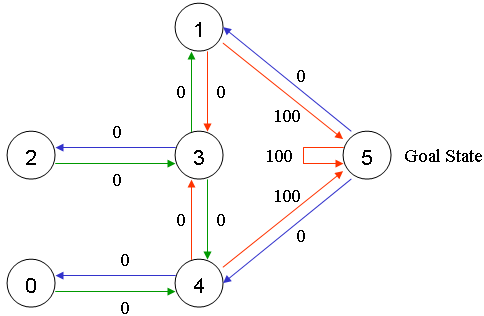
图 1.3
假设 Agent 当前的位置是在 2 号房间,这里就将 Agent 所在的位置做为“状态”,也就是 Agent 当前的状态是 ,当前 Agent 只能移动到 3 号房间,当它移动到 3 号房间的时候,状态就变为了 3,此时得到的奖励是 0 分。
而 Agent 根据箭头的移动则是一个“行为”。
根据状态与行为得到的奖励可以组成以下矩阵。

图 1.4
同时,可以使用一个 Q 矩阵,来表示 Agent 学习到的知识,在图 1.4 中,“-1”表示不可移动的位置,比如从 2 号房间移动到 1 号房间,由于根本就没有门,所以没办法过去。
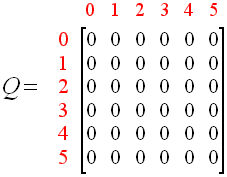
图 1.5
该 Q 矩阵就表示 Agent 在各种状态下,做了某种行为后自己给打的分,也就是将经验数据化,由于 Agent 还没有行动过,所以这里全是 0。
在 Q-Learning 算法中,计算经验得分的公式如下:
Q(state, action) = Q(state, action) + α(R(state, action) + Gamma * Max[Q(next state, all actions)] - Q(state, action))
当 α 的值是 1 时,公式如下:
Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
state: 表示 Agent 当前状态。
action: 表示 Agent 在当前状态下要做的行为。
next state: 表示 Agent 在 state 状态下执行了 action 行为后达到的新的状态。
Q(state, action): 表示 Agent 在 state 状态下执行了 action 行为后学习到的经验,也就是经验分数。
R(state, action): 表示 Agent 在 state 状态下做 action 动作后得到的即时奖励分数。
Max[Q(next state, all actions)]: 表示 Agent 在 next state 状态下,自我的经验中,最有价值的行为的经验分数。
Gamma: ,γ,表示折损率,也就是未来的经验对当前状态执行 action 的重要程度。
二、算法流程
Agent 通过经验去学习。Agent将会从一个状态到另一个状态这样去探索,直到它到达目标状态。我们称每一次这样的探索为一个场景(episode)。
每个场景就是 Agent 从起始状态到达目标状态的过程。每次 Agent 到达了目标状态,程序就会进入到下一个场景中。
1. 初始化 Q 矩阵,并将初始值设置成 0。
2. 设置好参数 γ 和得分矩阵 R。
3. 循环遍历场景(episode):
(1)随机初始化一个状态 s。
(2)如果未达到目标状态,则循环执行以下几步:
① 在当前状态 s 下,随机选择一个行为 a。
② 执行行为 a 得到下一个状态 s`。
③ 使用 Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)] 公式计算 Q(state, action) 。
④ 将当前状态 s 更新为 s`。
设当前状态 s 是 1, γ =0.8和得分矩阵 R,并初始化 Q 矩阵:
由于在 1 号房间可以走到 3 号房间和 5 号房间,现在随机选一个,选到了 5 号房间。
现在根据公式来计算,Agent 从 1 号房间走到 5 号房间时得到的经验分数 Q(1, 5) :
1.当 Agent 从 1 号房间移动到 5 号房间时,得到了奖励分数 100(即:R(1, 5) = 100)。
2.当 Agent 移动到 5 号房间后,它可以执行的动作有 3 个:移动到 1 号房间(0 分)、移动到 4 号房间(0 分)和移动到 5 号房间(0 分)。注意,这里计算的是经验分数,也就是 Q 矩阵,不是 R 矩阵!
所以,Q(1, 5) = 100 + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * Max{0, 0, 0} = 100
在次迭代进入下一个episode:
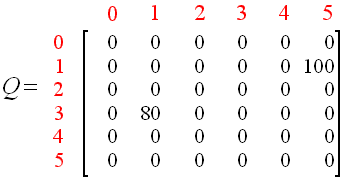
随机选择一个初始状态,这里设 s = 3,由于 3 号房间可以走到 1 号房间、 2 号房间和 4 号房间,现在随机选一个,选到了 1 号房间。
步骤同上得:Q(3, 1) = 0 + 0.8 * Max[Q(1, 3), Q(1, 5)] = 0 + 0.8 * Max{0, 100} = 0 + 0.8 * 100 = 80
即:
三、程序实现
先引入 numpy:
import numpy as np
初始化:
# 动作数。
ACTIONS = 6 # 探索次数。
episode = 100 # 目标状态,即:移动到 5 号房间。
target_state = 5 # γ,折损率,取值是 0 到 1 之间。
gamma = 0.8 # 经验矩阵。
q = np.zeros((6, 6)) def create_r():
r = np.array([[-1, -1, -1, -1, 0, -1],
[-1, -1, -1, 0, -1, 100.0],
[-1, -1, -1, 0, -1, -1],
[-1, 0, 0, -1, 0, -1],
[0, -1, -1, 1, -1, 100],
[-1, 0, -1, -1, 0, 100],
])
return r
执行代码:
特别注意红色字体部分,当程序随机到不可移动的位置的时候,直接给于死亡扣分,因为这不是一个正常的操作,比如 从 4 号房间移动到 1 号房间,但这两个房间根本没有门可以直接到。
至于为什么不使用公式来更新,是因为,如果 Q(4, 5)和Q(1, 5)=100分,
当随机到(4, 1)时,Q(4, 1)的经验值不但没有减少,反而当成了一个可移动的房间计算,得到 79 分,即:Q(4, 1) = 79,
当随机到(2, 1)的次数要比(4, 5)多时,就会出现Q(4, 1)的分数要比Q(4, 5)高的情况,这个时候,MaxQ 选择到的就一直是错误的选择。
if __name__ == '__main__':
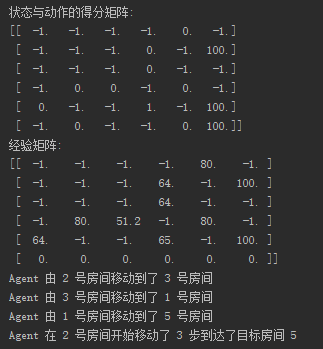
r = create_r() print("状态与动作的得分矩阵:")
print(r) # 搜索次数。
for index in range(episode): # Agent 的初始位置的状态。
start_room = np.random.randint(0, 5) # 当前状态。
current_state = start_room while current_state != target_state:
# 当前状态中的随机选取下一个可执行的动作。
current_action = np.random.randint(0, ACTIONS) # 执行该动作后的得分。
current_action_point = r[current_state][current_action] if current_action_point <:
q[current_state][current_action] = current_action_point
else:
# 得到下一个状态。
next_state = current_action # 获得下一个状态中,在自我经验中,也就是 Q 矩阵的最有价值的动作的经验得分。
next_state_max_q = q[next_state].max() # 当前动作的经验总得分 = 当前动作得分 + γ X 执行该动作后的下一个状态的最大的经验得分
# 即:积累经验 = 动作执行后的即时奖励 + 下一状态根据现有学习经验中最有价值的选择 X 折扣率
q[current_state][current_action] = current_action_point + gamma * next_state_max_q current_state = next_state print("经验矩阵:")
print(q) start_room = np.random.randint(0, 5)
current_state = start_room step = 0 while current_state != target_state:
next_state = np.argmax(q[current_state]) print("Agent 由", current_state, "号房间移动到了", next_state, "号房间") current_state = next_state step += 1 print("Agent 在", start_room, "号房间开始移动了", step, "步到达了目标房间 5")
下面是运行结果图:
完整代码:
import numpy as np # 动作数。
ACTIONS = 6 # 探索次数。
episode = 100 # 目标状态,即:移动到 5 号房间。
target_state = 5 # γ,折损率,取值是 0 到 1 之间。
gamma = 0.8 # 经验矩阵。
q = np.zeros((6, 6)) def create_r():
r = np.array([[-1, -1, -1, -1, 0, -1],
[-1, -1, -1, 0, -1, 100.0],
[-1, -1, -1, 0, -1, -1],
[-1, 0, 0, -1, 0, -1],
[0, -1, -1, 1, -1, 100],
[-1, 0, -1, -1, 0, 100],
])
return r def get_next_action():
# # 获得当前可执行的动作集合。
# actions = np.where(r[current_state] >= 0)[0]
#
# # 获得可执行的动作数。
# action_count = actions.shape[0]
#
# # 随机选取一个可执行的动作。
# next_action = np.random.randint(0, action_count)
#
# # 执行动作,获得下一个状态。
# next_state = actions[next_action]
next_action = np.random.randint(0, ACTIONS) return next_action if __name__ == '__main__':
r = create_r() print("状态与动作的得分矩阵:")
print(r) # 搜索次数。
for index in range(episode): # Agent 的初始位置的状态。
start_room = np.random.randint(0, 5) # 当前状态。
current_state = start_room while current_state != target_state:
# 当前状态中的随机选取下一个可执行的动作。
current_action = get_next_action() # 执行该动作后的得分。
current_action_point = r[current_state][current_action] if current_action_point < 0:
q[current_state][current_action] = current_action_point
else:
# 得到下一个状态。
next_state = current_action # 获得下一个状态中,在自我经验中,也就是 Q 矩阵的最有价值的动作的经验得分。
next_state_max_q = q[next_state].max() # 当前动作的经验总得分 = 当前动作得分 + γ X 执行该动作后的下一个状态的最大的经验得分
# 即:积累经验 = 动作执行后的即时奖励 + 下一状态根据现有学习经验中最有价值的选择 X 折扣率
q[current_state][current_action] = current_action_point + gamma * next_state_max_q current_state = next_state print("经验矩阵:")
print(q) start_room = np.random.randint(0, 5)
current_state = start_room step = 0 while current_state != target_state:
next_state = np.argmax(q[current_state]) print("Agent 由", current_state, "号房间移动到了", next_state, "号房间") current_state = next_state step += 1 print("Agent 在", start_room, "号房间开始移动了", step, "步到达了目标房间 5")
Deep Q-Network 学习笔记(一)—— Q-Learning 学习与实现过程中碰到的一些坑的更多相关文章
- Linux学习笔记(1)Linux虚拟机安装过程中的知识点及常用管理工具
1. VMware的相关知识 (1)建议的VMware的配置: CPU 主频1GHz以上 内存 1GB以上 硬盘 分区空闲空间8GB以上 (2)VMware创建快照 快照的作用是保存虚拟机的现有状态, ...
- (转载)林轩田机器学习基石课程学习笔记1 — The Learning Problem
(转载)林轩田机器学习基石课程学习笔记1 - The Learning Problem When Can Machine Learn? Why Can Machine Learn? How Can M ...
- 【神经网络与深度学习】学习笔记:AlexNet&Imagenet学习笔记
学习笔记:AlexNet&Imagenet学习笔记 ImageNet(http://www.image-net.org)是李菲菲组的图像库,和WordNet 可以结合使用 (毕业于Caltec ...
- [原创]java WEB学习笔记75:Struts2 学习之路-- 总结 和 目录
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- [原创]java WEB学习笔记66:Struts2 学习之路--Struts的CRUD操作( 查看 / 删除/ 添加) 使用 paramsPrepareParamsStack 重构代码 ,PrepareInterceptor拦截器,paramsPrepareParamsStack 拦截器栈
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- C#数字图像处理算法学习笔记(一)--C#图像处理的3中方法
C#数字图像处理算法学习笔记(一)--C#图像处理的3中方法 Bitmap类:此类封装了GDI+中的一个位图,次位图有图形图像及其属性的像素数据组成.因此此类是用于处理像素数据定义的图形的对象.该类的 ...
- MVC学习笔记(三)—用EF向数据库中添加数据
1.在EFDemo文件夹中添加Controllers文件夹(用的是上一篇MVC学习笔记(二)—用EF创建数据库中的项目) 2.在Controllers文件夹下添加一个空的控制器(StudentsCon ...
- Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第七章:在Direct3D中绘制(二)
原文:Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第七章:在Direct3D中绘制(二) 代码工程地址: https:/ ...
- Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第六章:在Direct3D中绘制
原文:Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第六章:在Direct3D中绘制 代码工程地址: https://gi ...
随机推荐
- python练习_12
题目:敏感词文本文件 filtered_words.txt,里面的内容 和 0011题一样,当用户输入敏感词语,则用 星号 * 替换,例如当用户输入「北京是个好城市」,则变成「**是个好城市」.(11 ...
- jQuery修炼心得-DOM节点的删除
要移除页面上节点是开发者常见的操作,jQuery提供了几种不同的方法用来处理这个问题. 1.empty empty 顾名思义,清空方法,但是与删除又有点不一样,因为它只移除了 指定元素中的所有子节点. ...
- phpcms笔记
一.建立虚拟站点 1.先更改www目录下的站点名称,再找到apache, 打开"Apache2\conf\extra"下的"httpd-vhosts.conf" ...
- python之基础中的基础(三)
1.类,类就像是负责特定项目的主管,交给主管干这件事情,主管可以让手下的人分别去完成自己该干的活,最后综合起来把结果交给主管传递出去,即完成任务. class Dog(): ""& ...
- hdu1150 Machine Schedule 经典二分匹配题目
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1150 很经典的二分题目 就是求最小点覆盖集 二分图最小点覆盖集=最大匹配数 代码: #include& ...
- Welcome to my Blog
Only English? Oh my god!!! why open live write can't write by Chinese?
- 张高兴的 Windows 10 IoT 开发笔记:使用 ADS1115 读取模拟信号
考虑到 Raspberry Pi 读取模拟信号是很烦人的事情,更何况是在没人玩的 Windows 10 IoT 下,所以准备正儿八经的写点东西. 需求:使用 Raspberry Pi 读取输出模拟信号 ...
- 分布式Java应用与实践 (一)
一) 分布式Java应用 1.1 基于消息方式实现系统间的通信 数据传输 TCP/IP 可靠的网络传输协议,首先给通信双方建立链接之后再进行数据传输,保证链接及数据传输的可靠,因此会牺牲一些性能 UD ...
- (高级篇 Netty多协议开发和应用)第十章-Http协议开发应用(基于Netty的HttpServer和HttpClient的简单实现)
1.HttpServer package nettyHttpTest; import io.netty.bootstrap.ServerBootstrap; import io.netty.chann ...
- struts2.1.6教程三、在Action获取Scope对象
引言:在前面的Action操作中,关键就是Action中的exectue方法,但是此方法并没有request.session.application等对象作为参数,自然就不能利用这些对象来操作.下面我 ...