spark新闻项目环境搭建
前面安装好三节点的centos 6.5 和配置好静态ip,这里就不多说了
创建kfk用户,然后重启
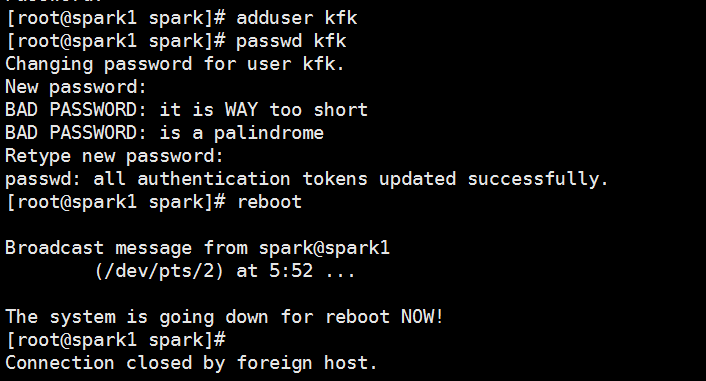
Last login: Fri Jan :: from 192.168.86.1
[spark@spark1 ~]$ su
Password:
[root@spark1 spark]# adduser kfk
[root@spark1 spark]# passwd kfk
Changing password for user kfk.
New password:
BAD PASSWORD: it is WAY too short
BAD PASSWORD: is a palindrome
Retype new password:
passwd: all authentication tokens updated successfully.
[root@spark1 spark]# reboot Broadcast message from spark@spark1
(/dev/pts/) at : ... The system is going down for reboot NOW!
设置主机名


接下来是主机名与ip地址的映射

配置完了重启

重启后可以看到我们的主机名改变了
接下来在windows下的映射
找到这个路径下的hosts文件,用记事本编辑

在后面加上

通过软件
实现远程连接,当然也可以用Xshell
进来之后需要设置一下,当然这个软件需要破解的,不能直接使用,怎么破解的这里就不多说了,百度上有教程,下载一个注册机按照教程来就好了


下面设置root用户切换不需要密码
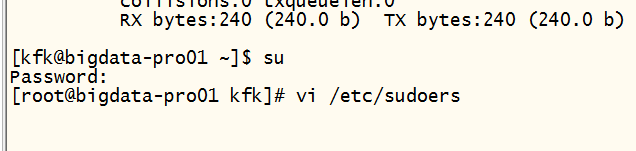
加这么一句话
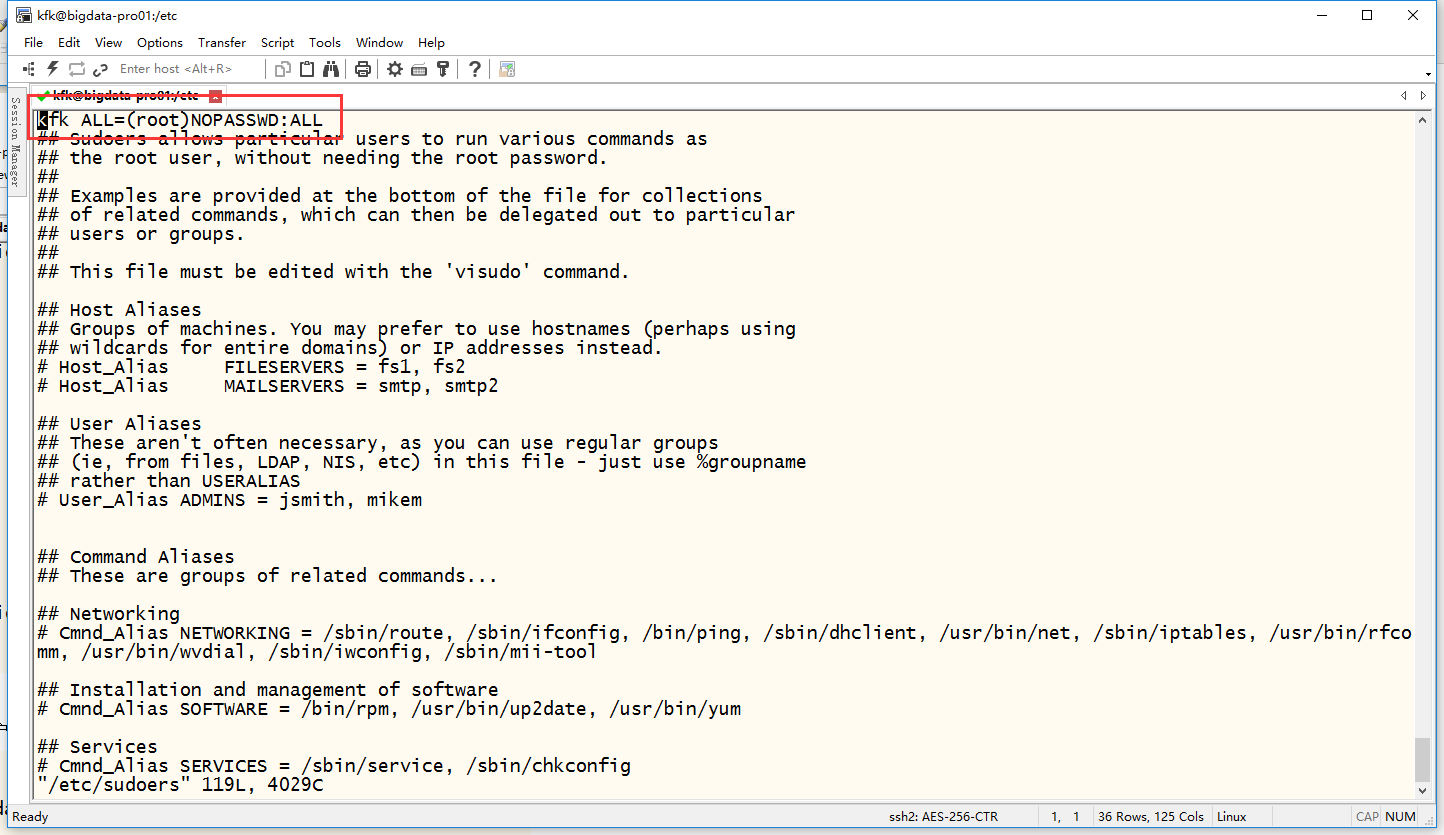
在编辑sudoers文件的时候大家会遇到不能编辑的问题,那是因为sudoers文件的权限是不够的原因,那就先通过chmod 777 sudoers修改权限,等编辑完了之后就chmod 440 sudoers把权限改回来
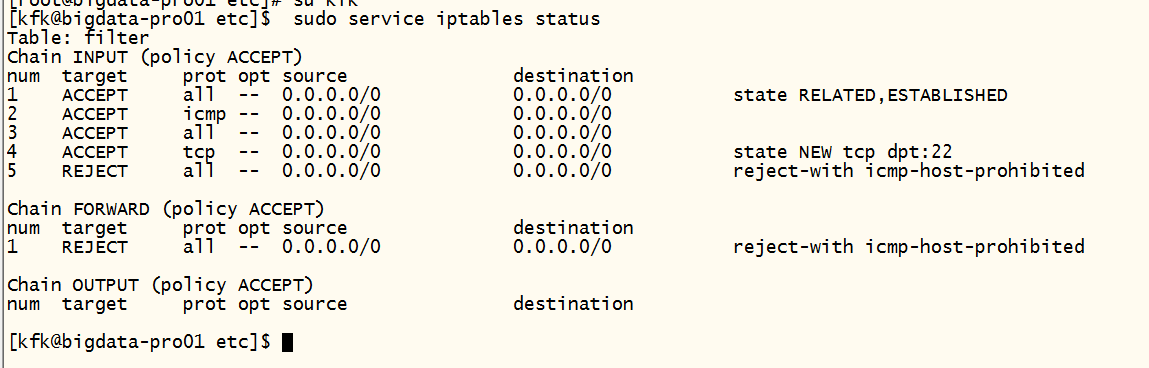
查看到防火墙是开启的,我们现行把防火墙关了

虽然这样能关闭了防火墙。但是我们这里还是要配置一下

把这里修改了

改成这样的,然后保存退出

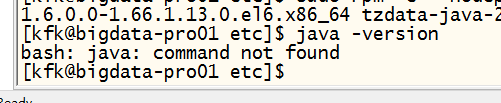
下一步就是卸载自带的jdk

具体步骤就是先查看jdk信息然后把这几个都卸载了
[kfk@bigdata-pro01 etc]$ sudo rpm -qa|grep java
java-1.7.-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
java-1.6.-openjdk-1.6.0.0-1.66.1.13..el6.x86_64
tzdata-java-2013g-.el6.noarch
[kfk@bigdata-pro01 etc]$ sudo rpm -e --nodeps java-1.7.-openjdk-1.7.0.45-2.4.3.3.el6.x86_64 java-1.6.-openjdk-1.6.0.0-1.66.1.13..el6.x86_64 tzdata-java-2013g-.el6.noarch
创建目录
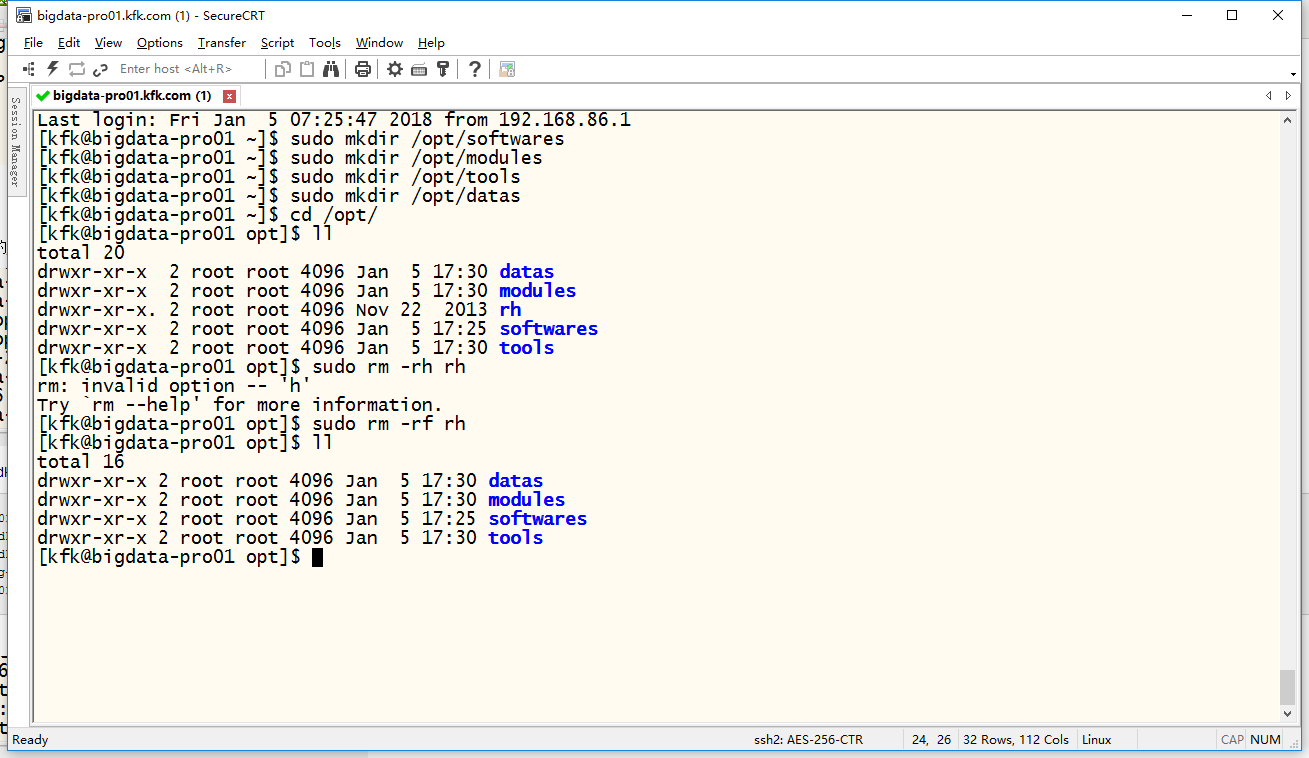
[kfk@bigdata-pro01 ~]$ sudo mkdir /opt/softwares
[kfk@bigdata-pro01 ~]$ sudo mkdir /opt/modules
[kfk@bigdata-pro01 ~]$ sudo mkdir /opt/tools
[kfk@bigdata-pro01 ~]$ sudo mkdir /opt/datas
[kfk@bigdata-pro01 ~]$ cd /opt/
[kfk@bigdata-pro01 opt]$ ll
total
drwxr-xr-x root root Jan : datas
drwxr-xr-x root root Jan : modules
drwxr-xr-x. root root Nov rh
drwxr-xr-x root root Jan : softwares
drwxr-xr-x root root Jan : tools
[kfk@bigdata-pro01 opt]$ sudo rm -rh rh
rm: invalid option -- 'h'
Try `rm --help' for more information.
[kfk@bigdata-pro01 opt]$ sudo rm -rf rh
[kfk@bigdata-pro01 opt]$ ll
total
drwxr-xr-x root root Jan : datas
drwxr-xr-x root root Jan : modules
drwxr-xr-x root root Jan : softwares
drwxr-xr-x root root Jan : tools
[kfk@bigdata-pro01 opt]$
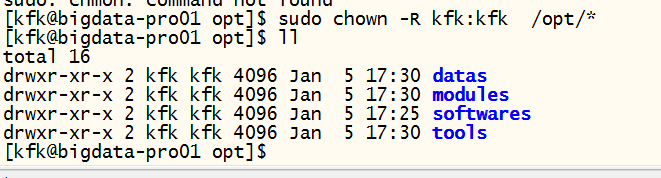
把目录改成kfk用户下的目录
安装jdk1.7版本
上传安装包(这里我切换回远程连接xshell工具)

改成可执行的权限
解压

配置jdk环境变量

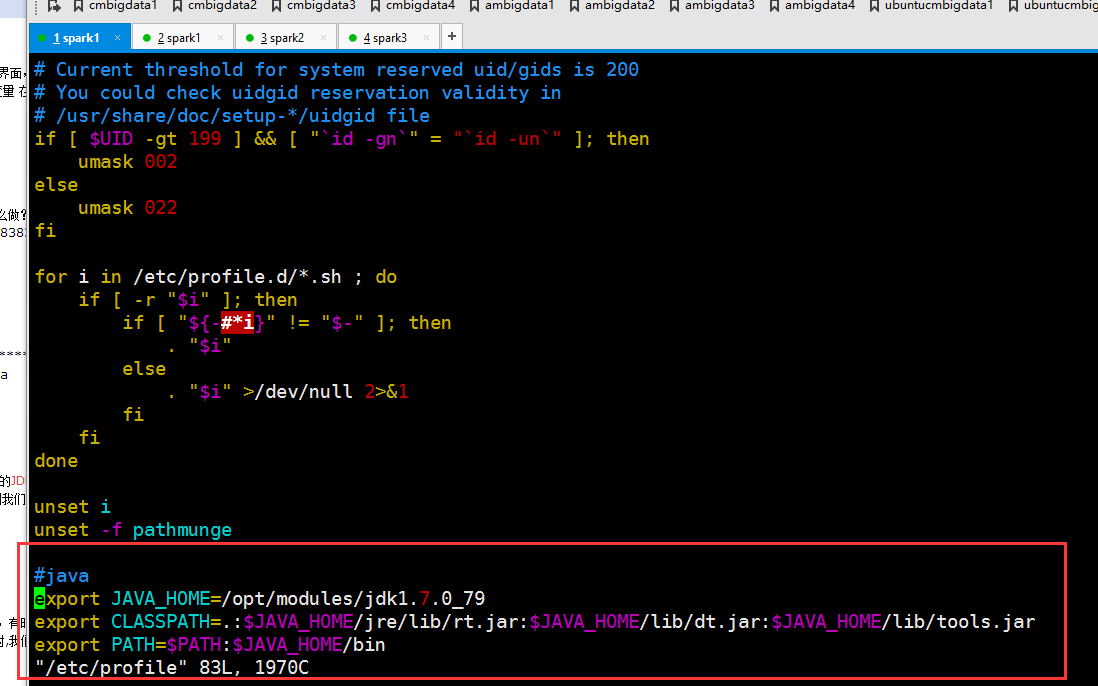
#java
export JAVA_HOME=/opt/modules/jdk1..0_79
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
使环境变量生效

到这里为止,从复上面的操作,我同时配置另外两台机子主机名分别是bigdata-pro02.kfk.com bigdata-pro03.kfk.com
需要注意的是主机名映射的地方配置(三个节点都这样配置),在windows的hosts文件映射也是一样的,这里就不做赘述

hadoop 分布式集群部署
先上传hadoop安装包
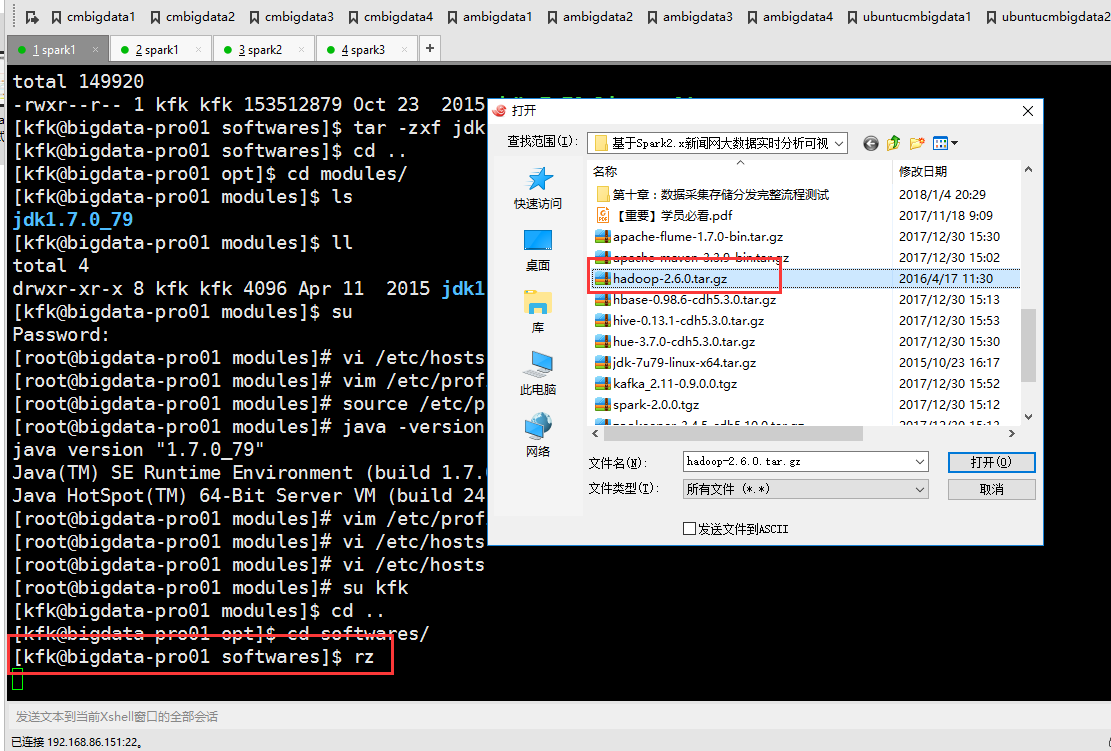
解压

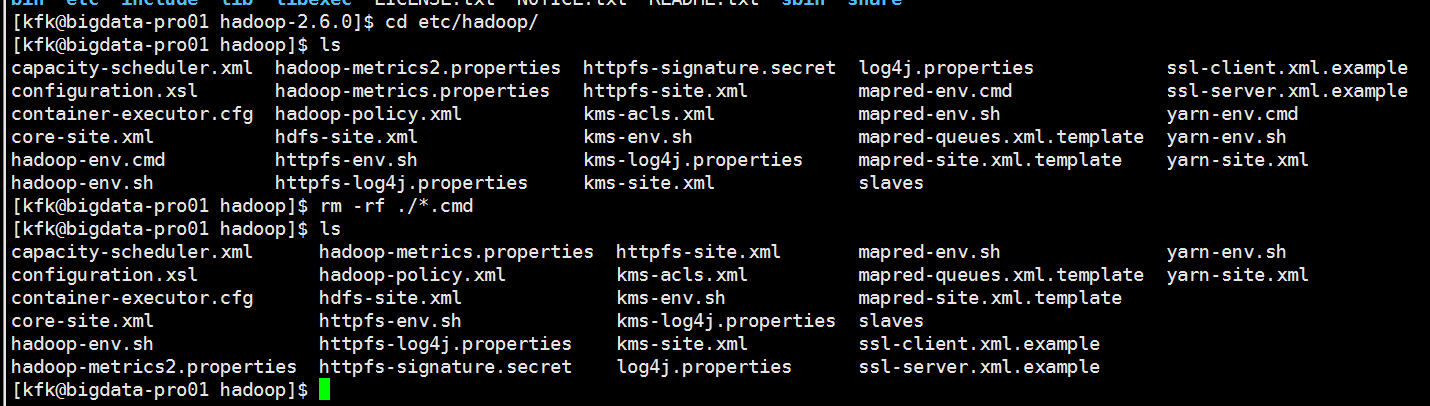
把一些没有用的文件删除掉

把.cmd结尾的文件删除掉,因为这个是windows的才用到的文件
接下来我们配置文件,我们这里使用notepad++来远程连接配置文件
首先要下载一个插件,把这个插件放到对应notepad++的plugins目录下
你会发现多了这么一项


连接成功!

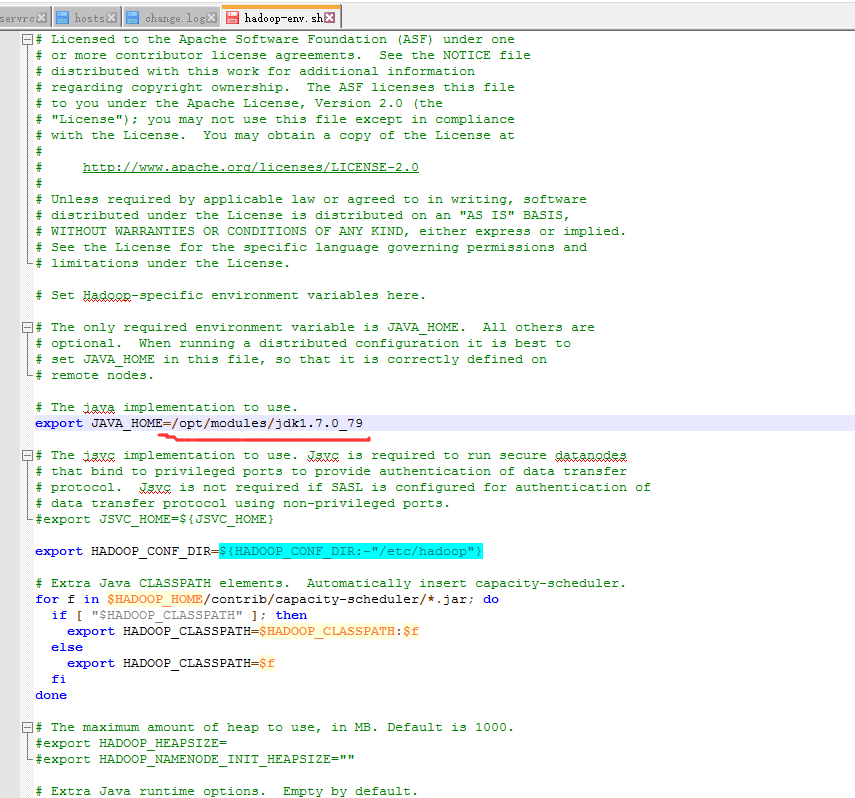
首先我们需要配置的是这个文件

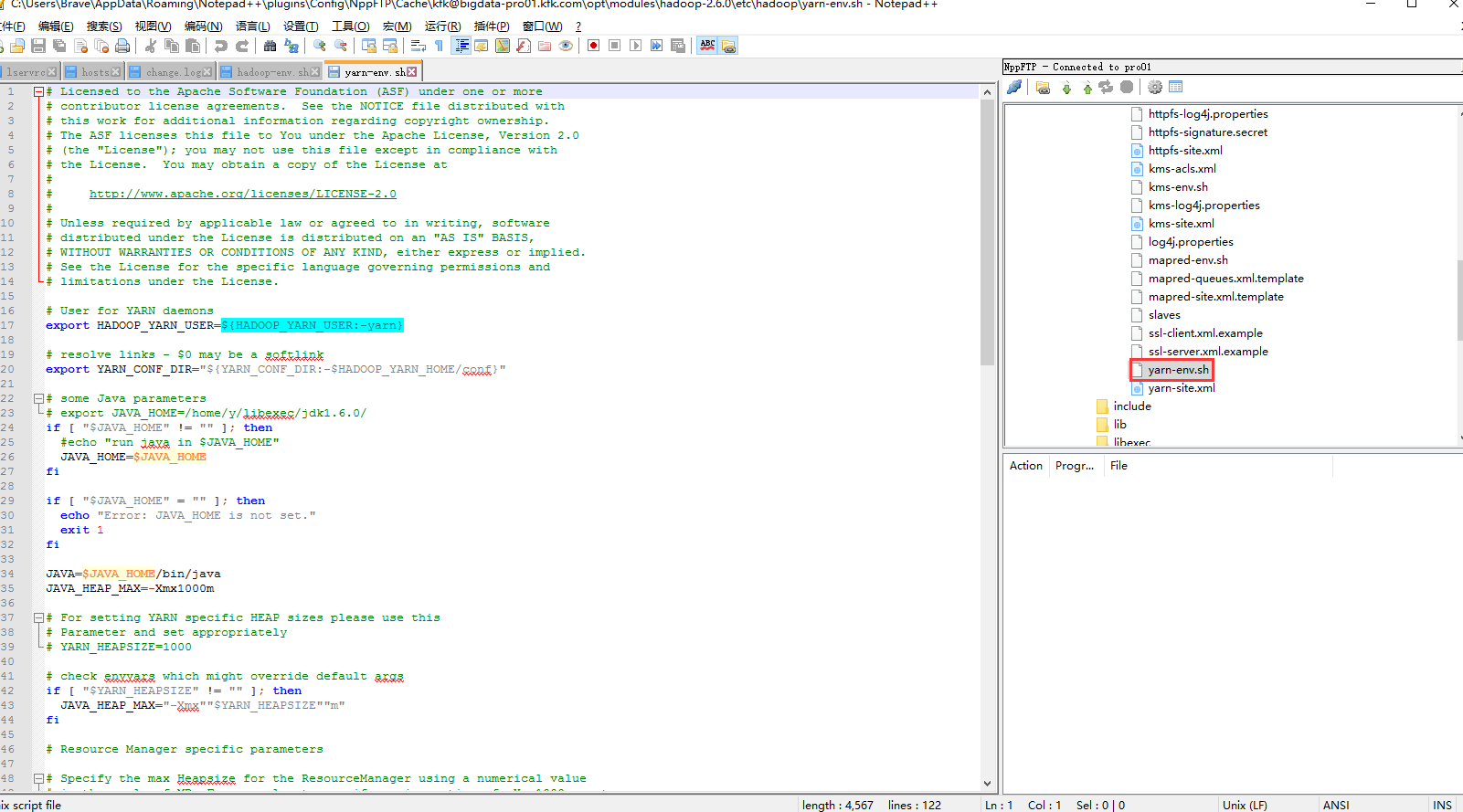
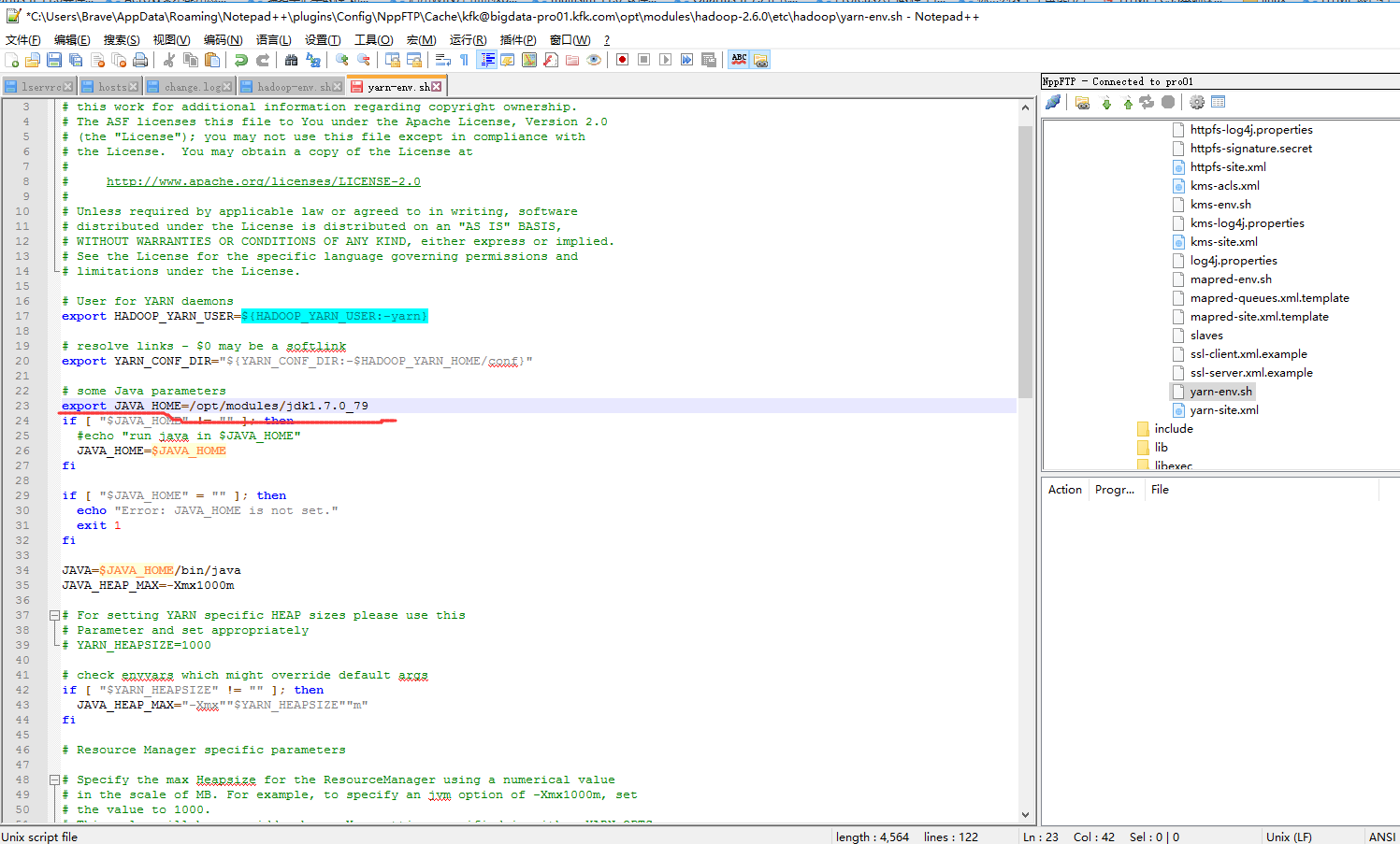
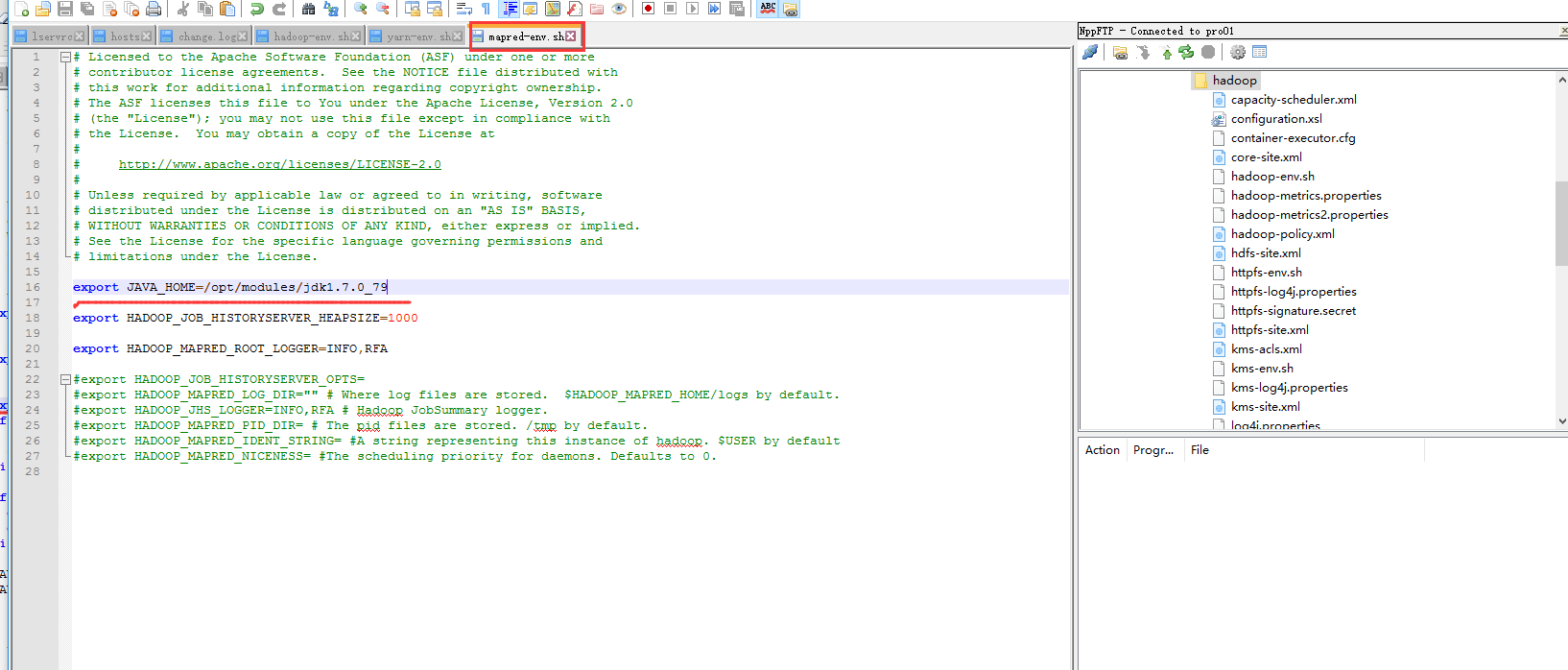


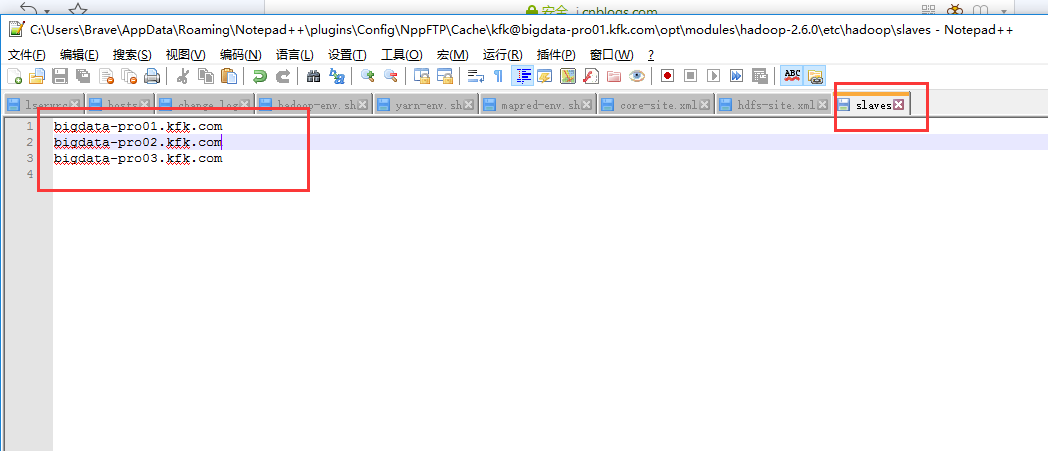
配置完之后先格式化一下


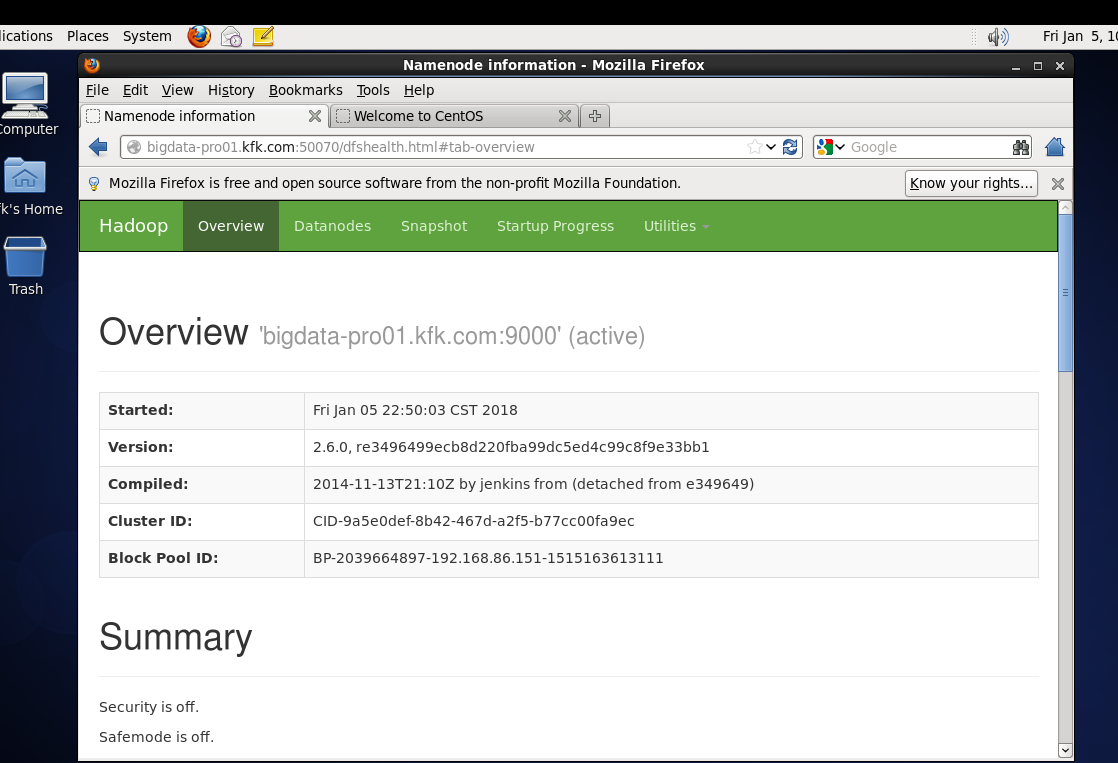
分别启动一下这个节点的namenode datanode

在浏览器上跑一下打开测试页面,我这里是在linux里面的火狐浏览器跑的,因为在windows下的浏览器打不开,我估计是我这边网络的原因

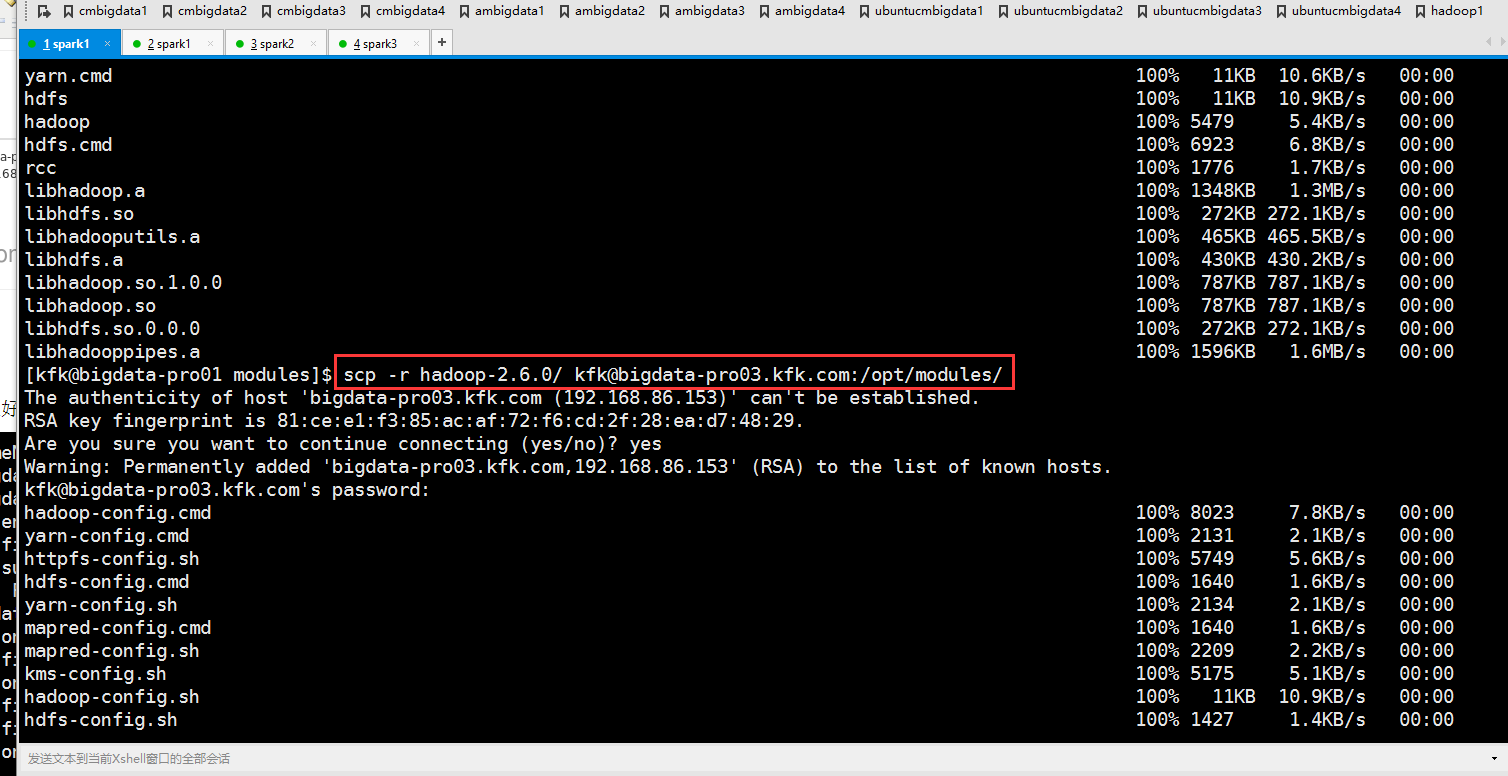
现在把安装好的hadoop分发到另外两个节点上

在hdfs上创建目录

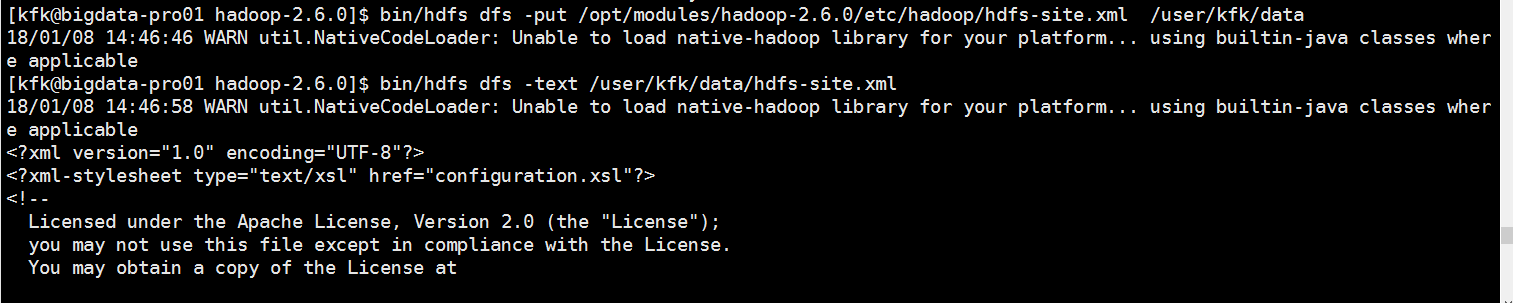
上传一个文件到hdfs上面去

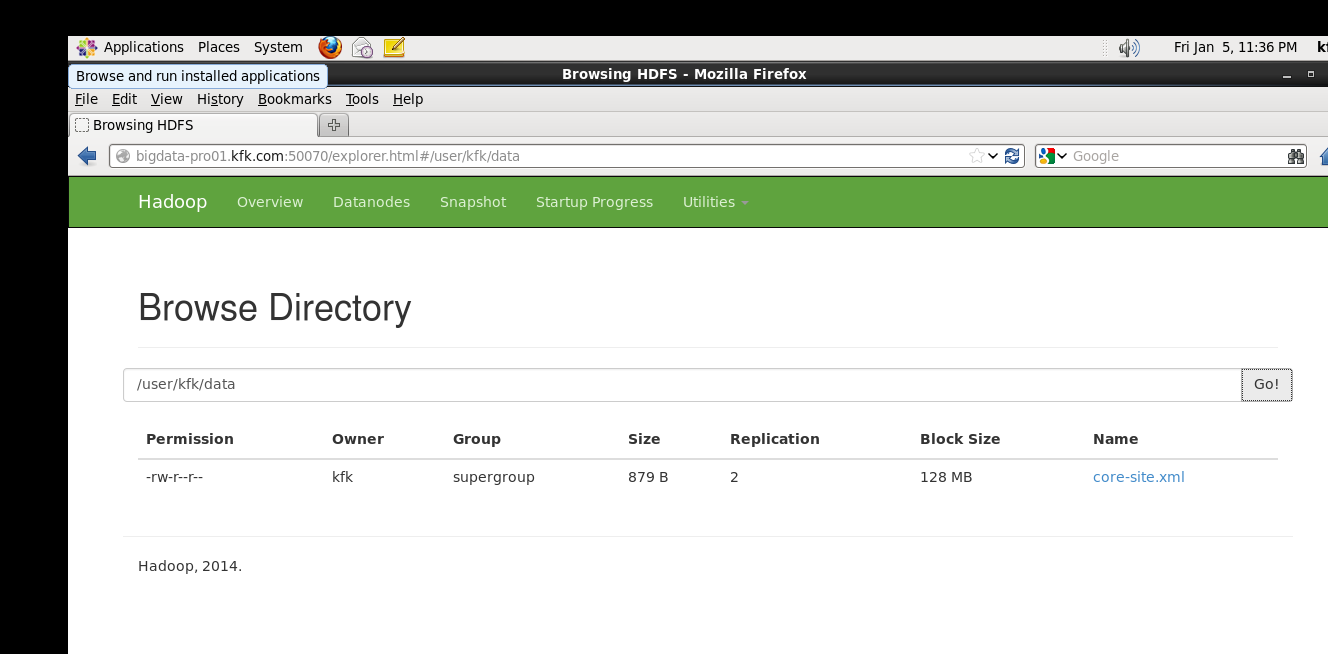
可以看到能上传
下面继续配置

这里吧文件名改了
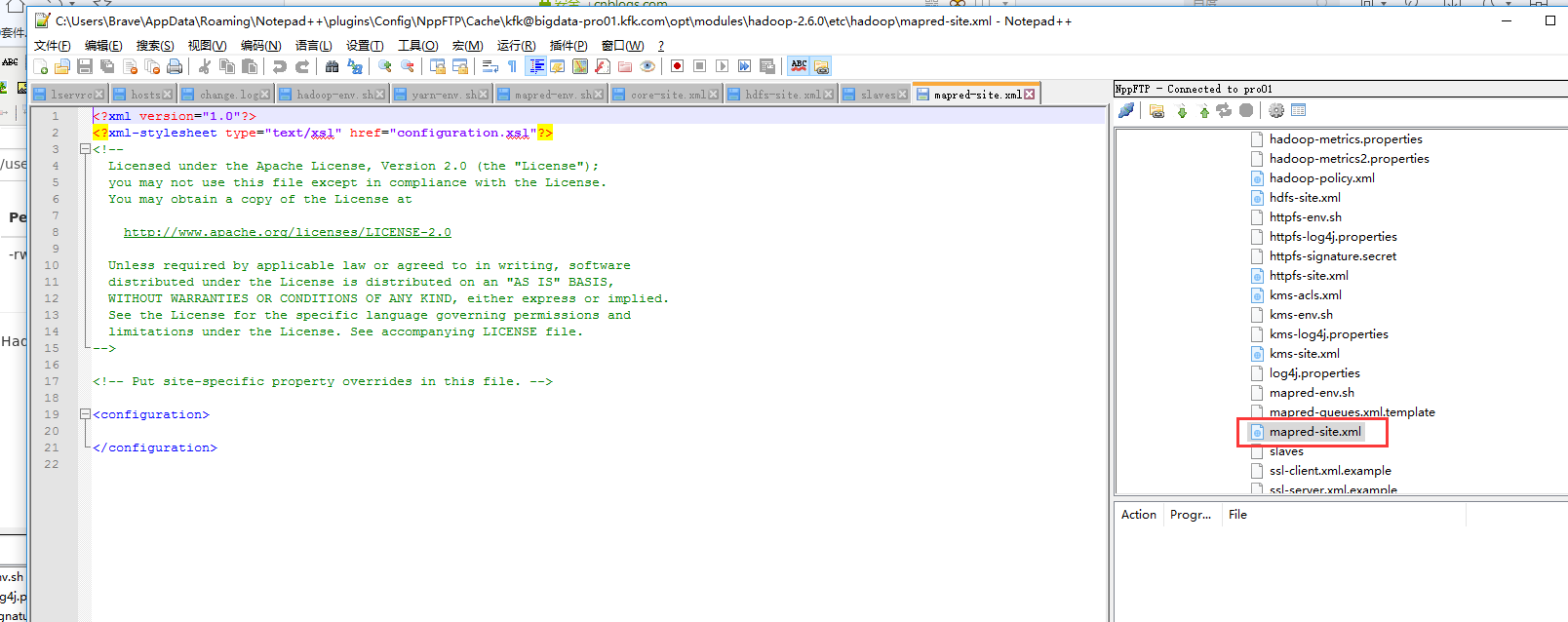
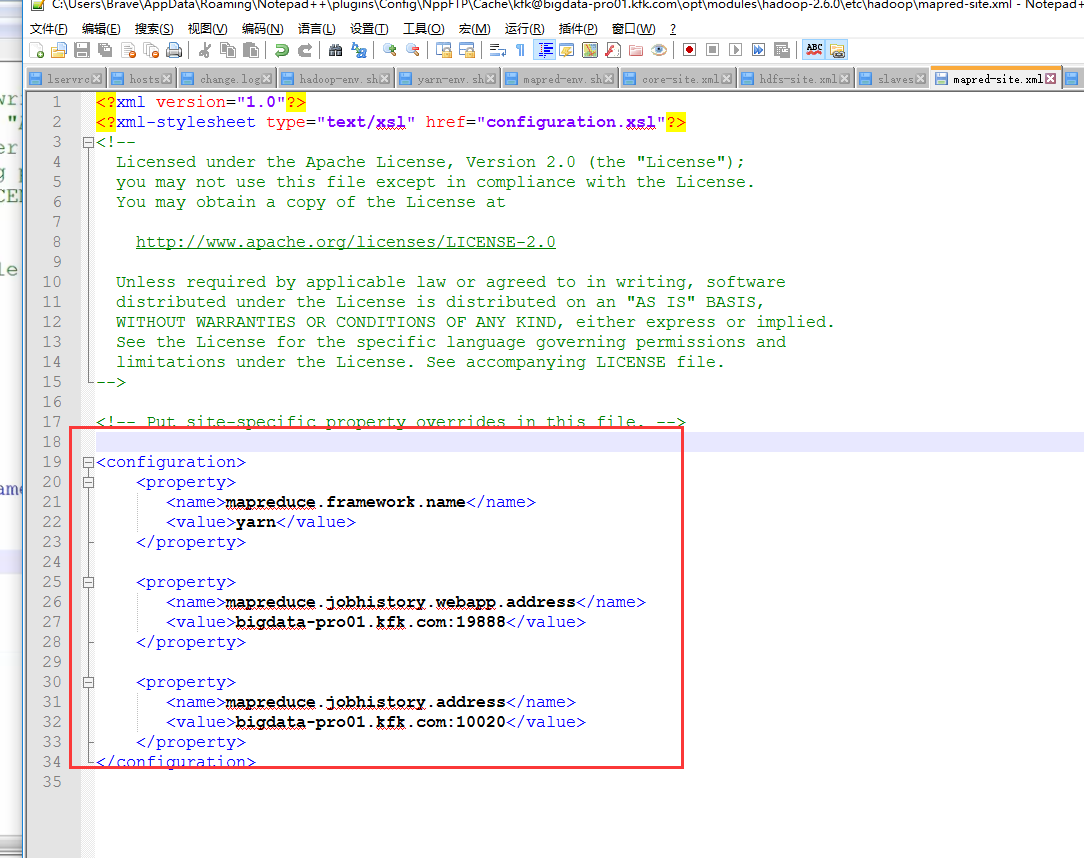
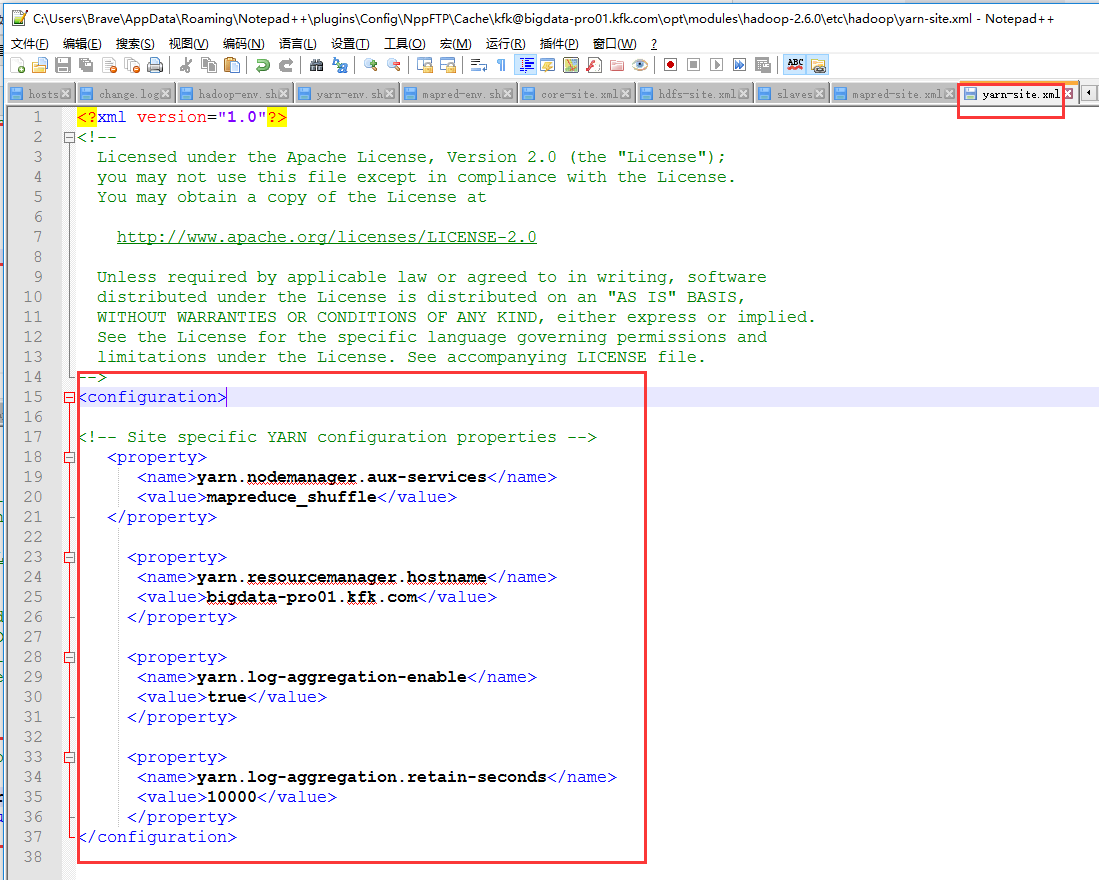
把配置好的文件分发到另外两个节点

下面我们来做一个数据文件
自己随意敲一些单词进去
把这个数据文件上传到hdfs上去


分别启动resourcemanager nodemanager
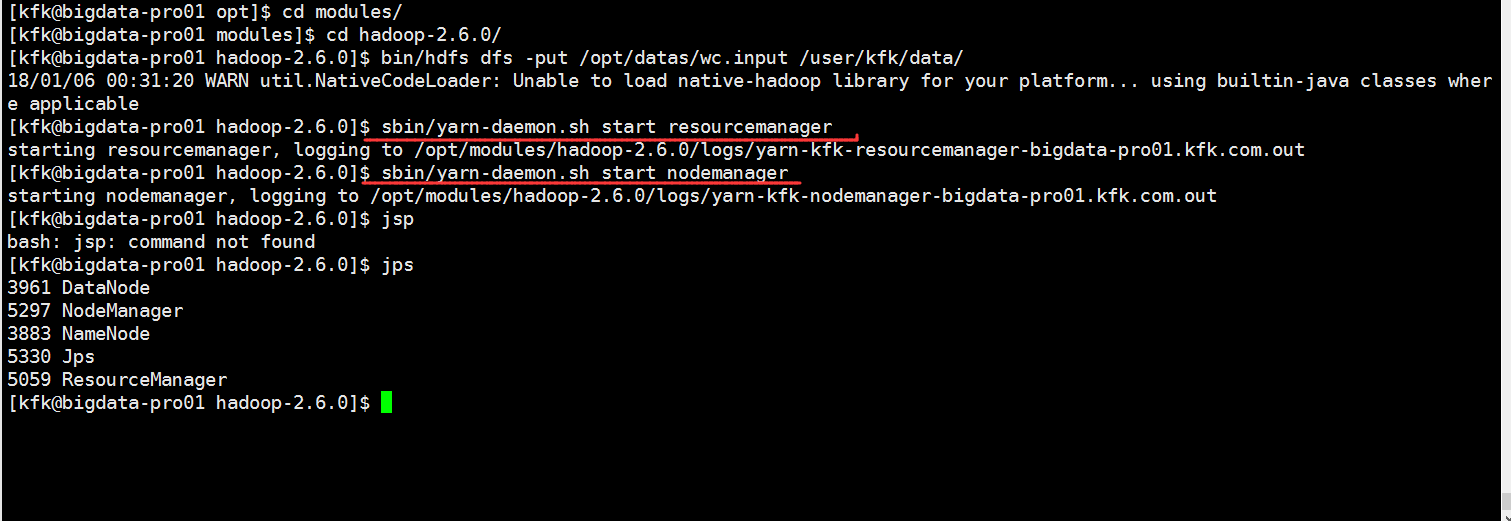


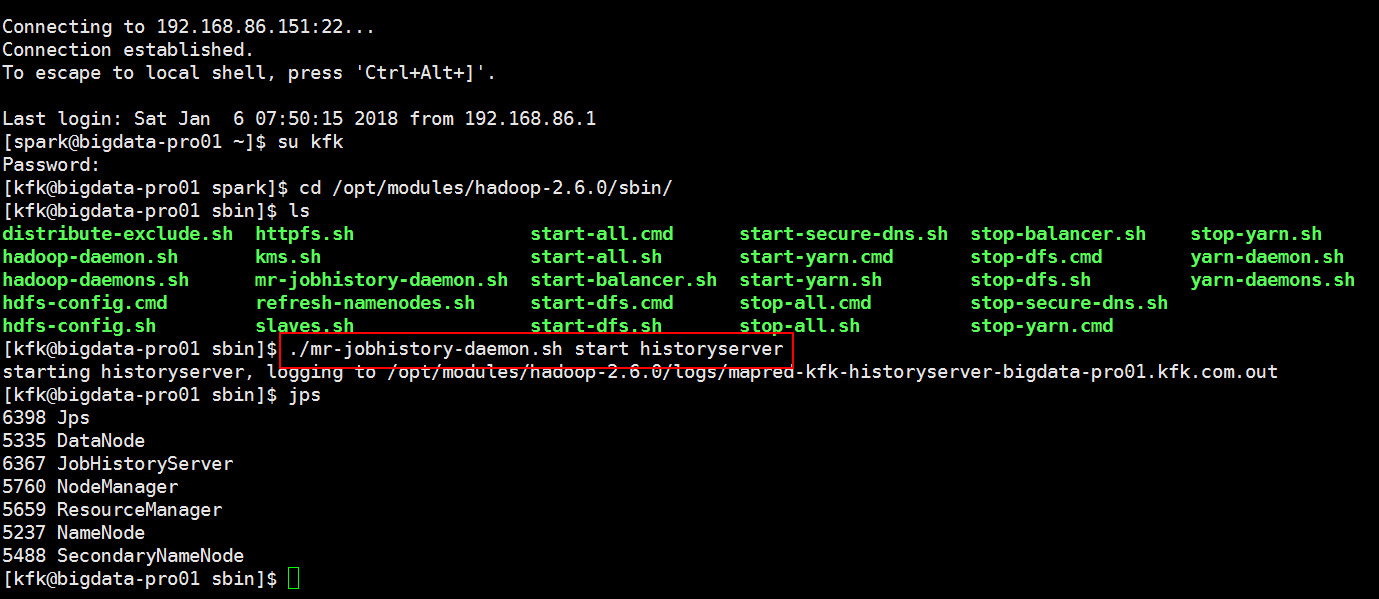
这个时候可以发现多了一个tmp目录,但是不能访问

修改一下配置文件

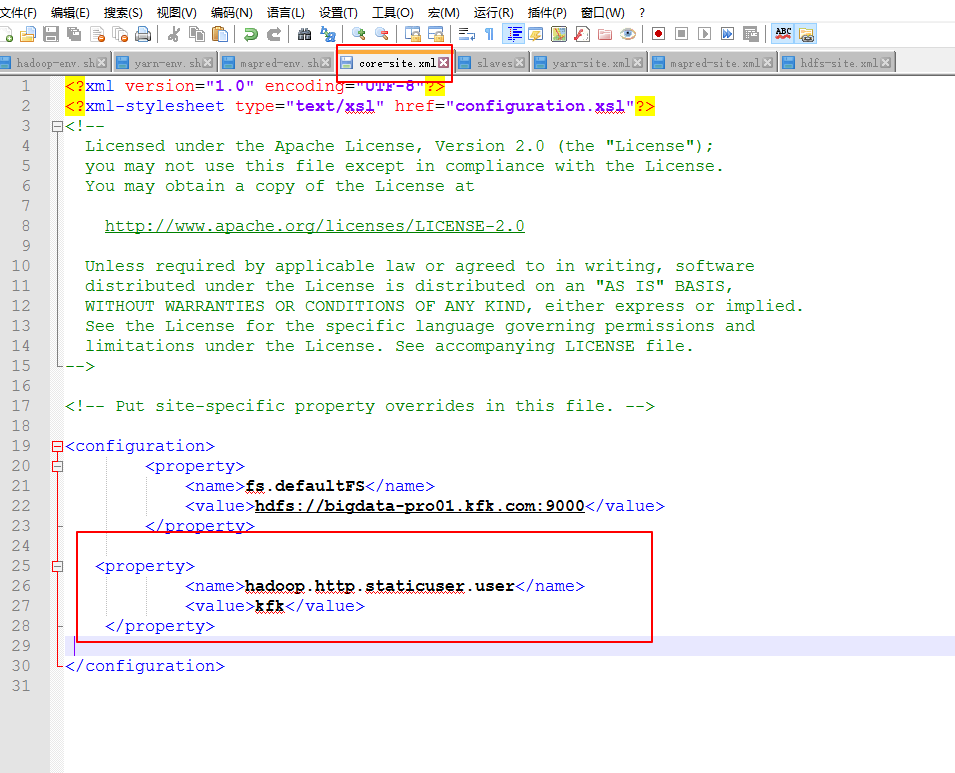
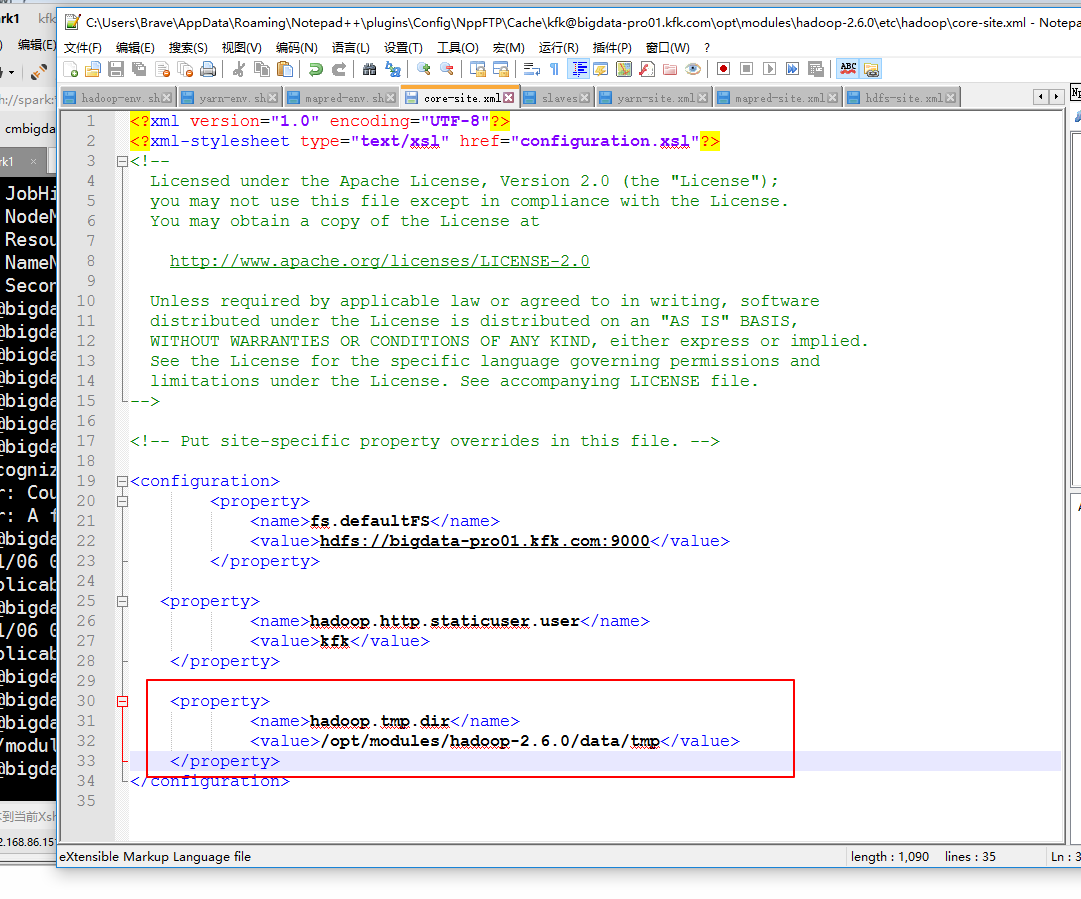
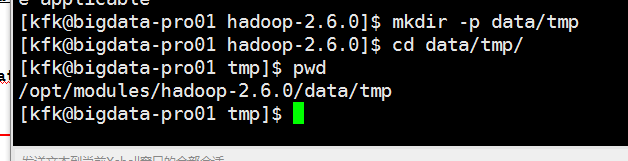
因为在第一个节点对配置文件修改比较多,现在打算把他分发到另外两个节点上,所以先把另外两个节点的hadoop安装文件删除掉
删除


分发


先把启动的服务停掉

再次格式化namenode


分别启动各个进程



因为刚刚重新格式化了namenode,所以hdfs上的目录和文件就没有了

现在我们重新创建一下






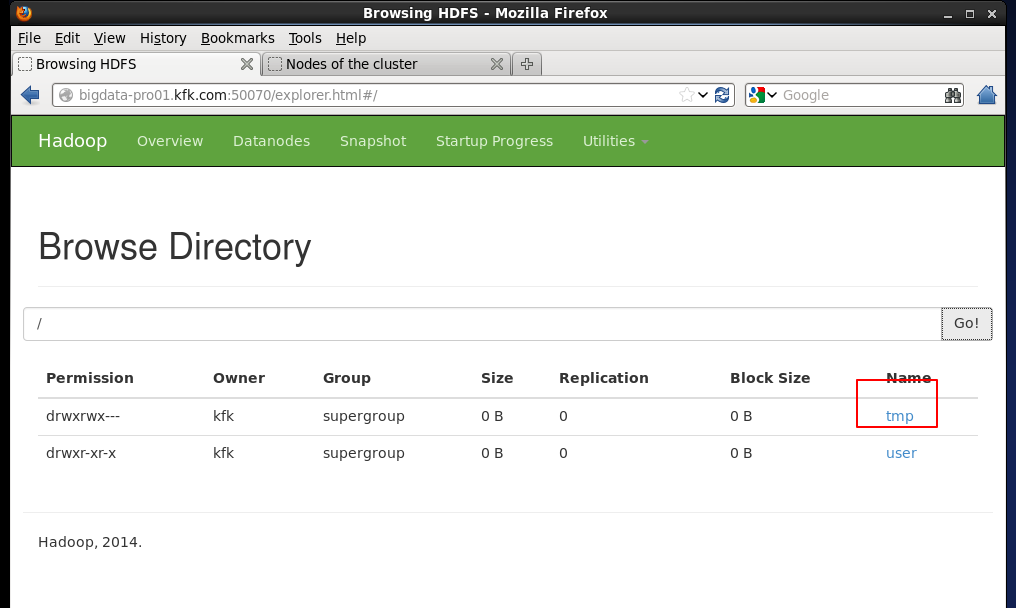


在hdfs上创建一个输出路径

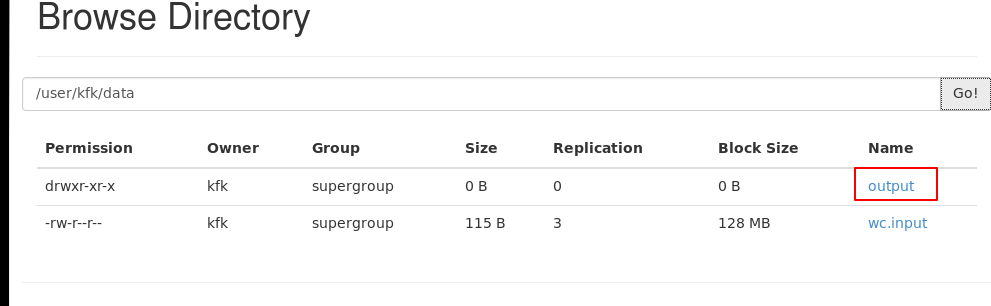
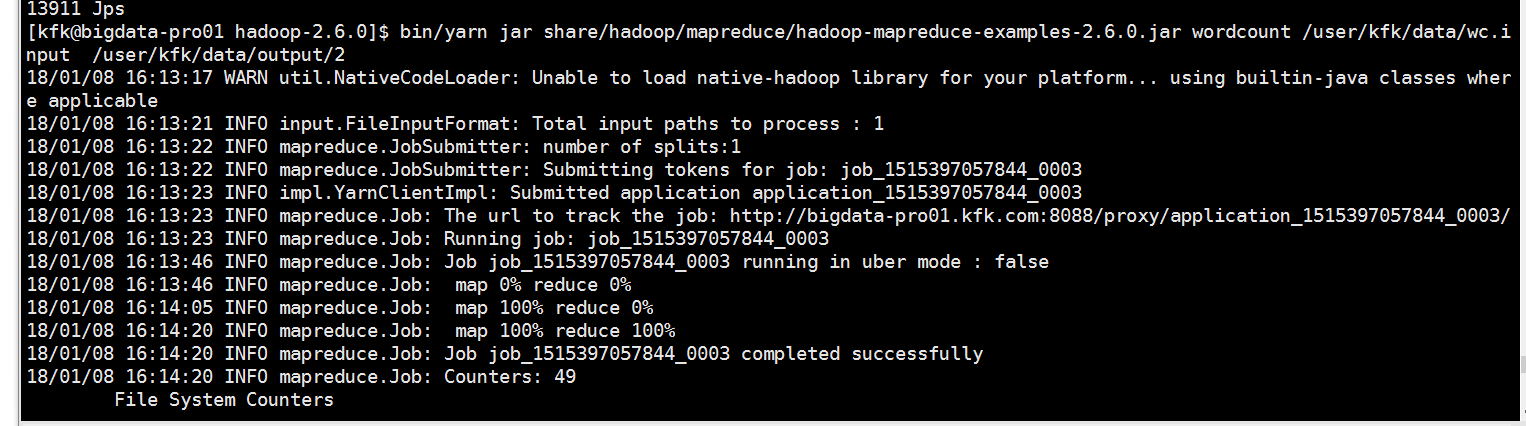
下面我们来运行一下mapreduce
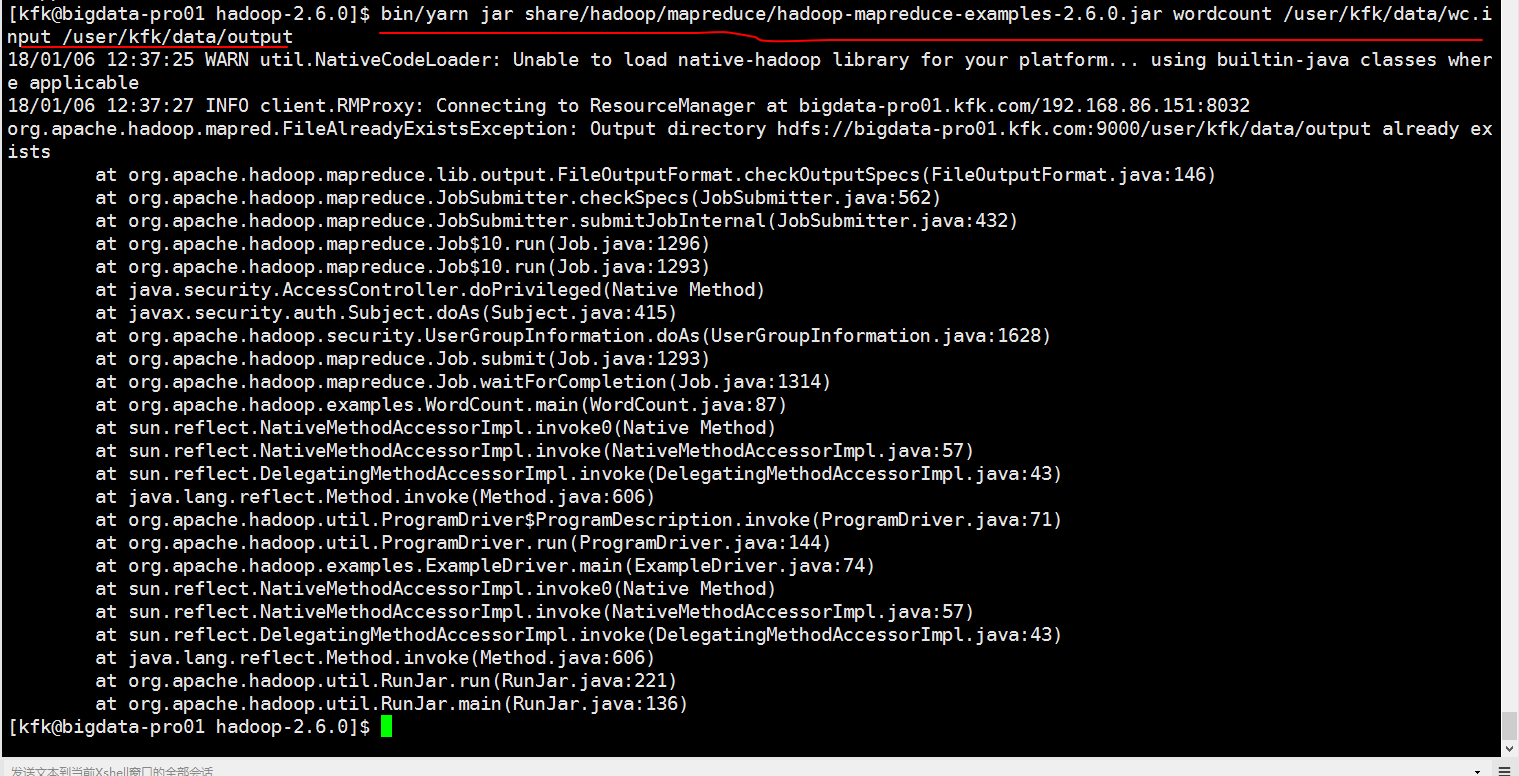
可以看到报错了,因为输出目录已经存在了。我们可以给一个不存在的输出目录给他
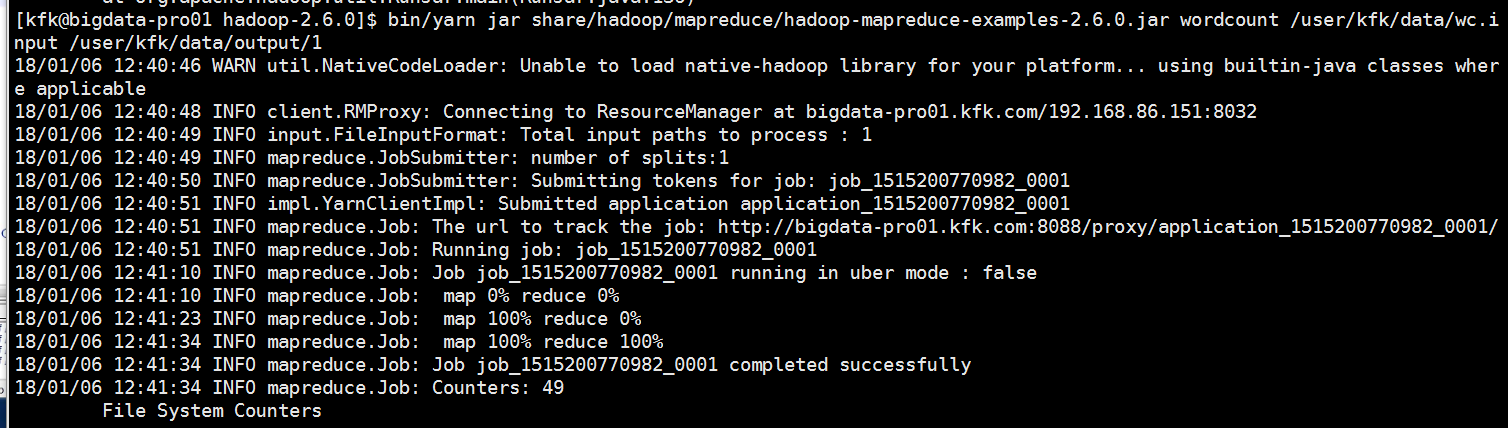
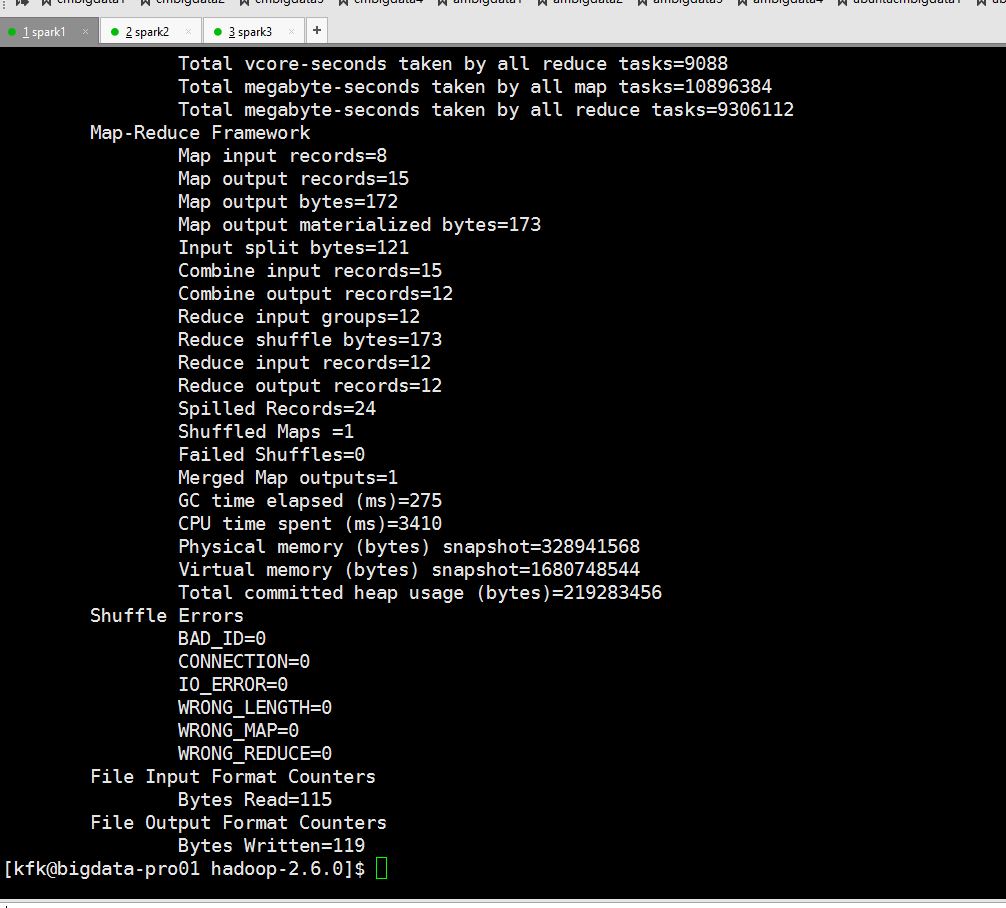
可以看到运行成功了!
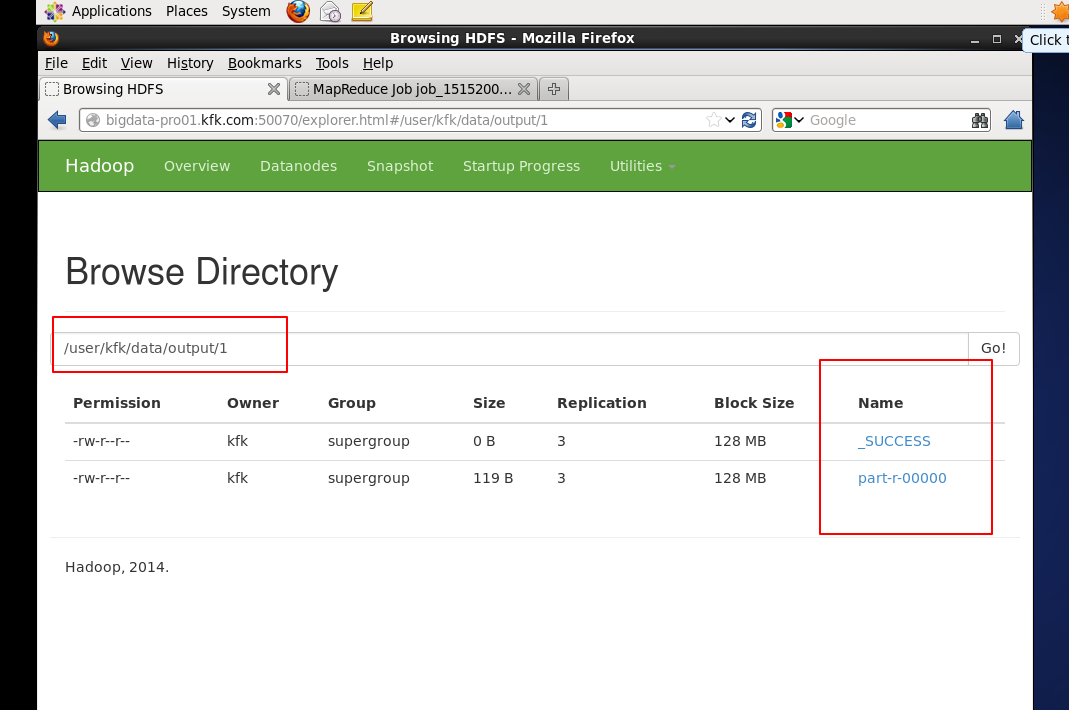
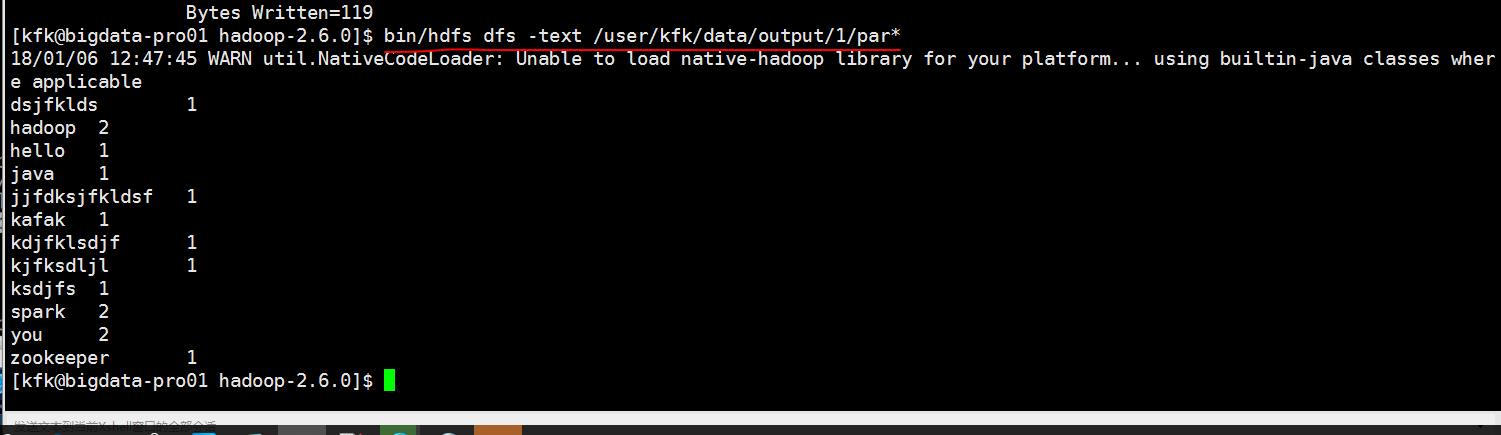
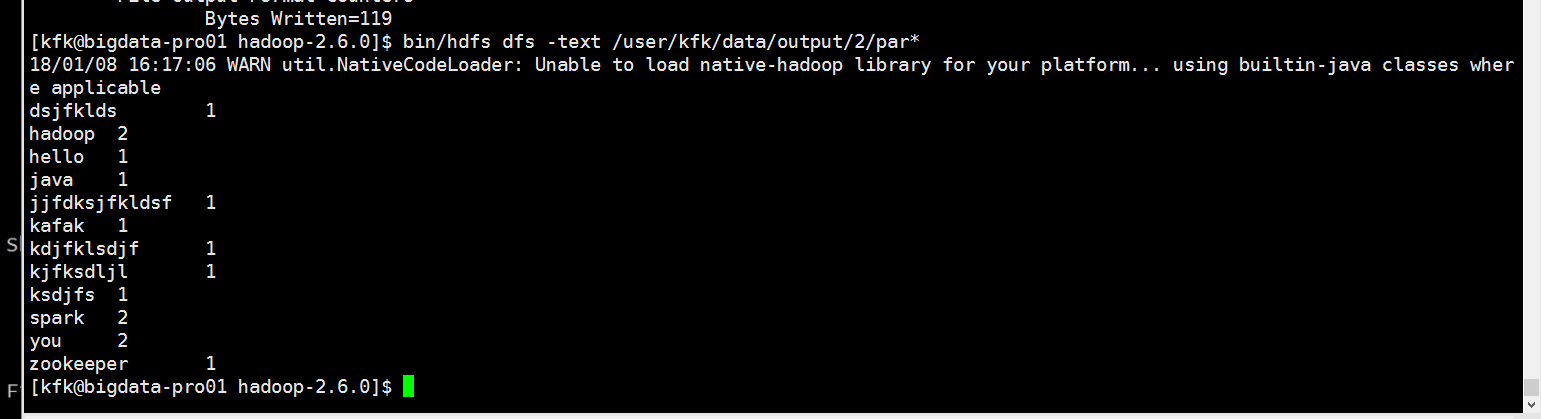
我们查看一下结果
zookeeper分布式集群的部署
先把安装包上传

上传完成后我们修改一下他的权限

解压


我们可以看看zookeeper的目录结构

把没有用的东西干掉

下面来配置zookeeper
把这个文件的名字改一下
修改后


创建一个目录zkData

修改配置文件

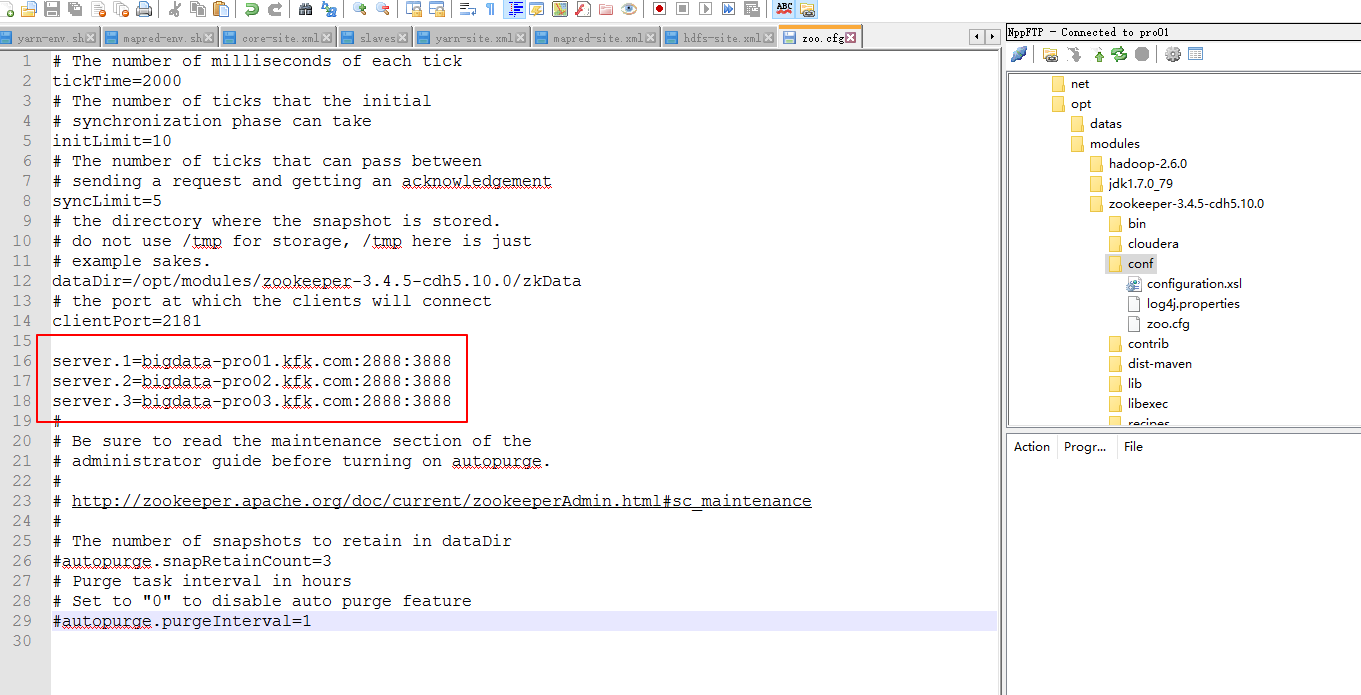


现在我们对zookeeper的配置就完成了,接下来就是分发给另外两台机器。


分发完了之后分别进入 第二个节点和第三个节点的/opt/modules/zookeeper-3.4.5-cdh5.10.0/zkData下分别把myid改成2和3 !!!!
下面我们来启动zookeeper服务
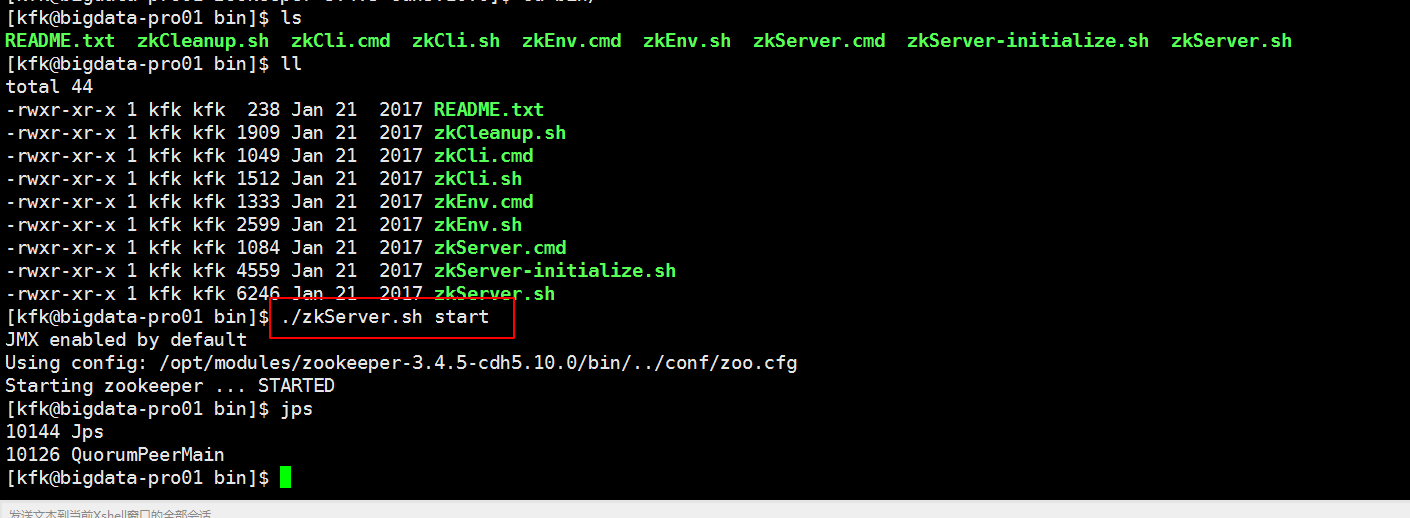
启动完之后我们就可以通过客户端来连接我们的服务了
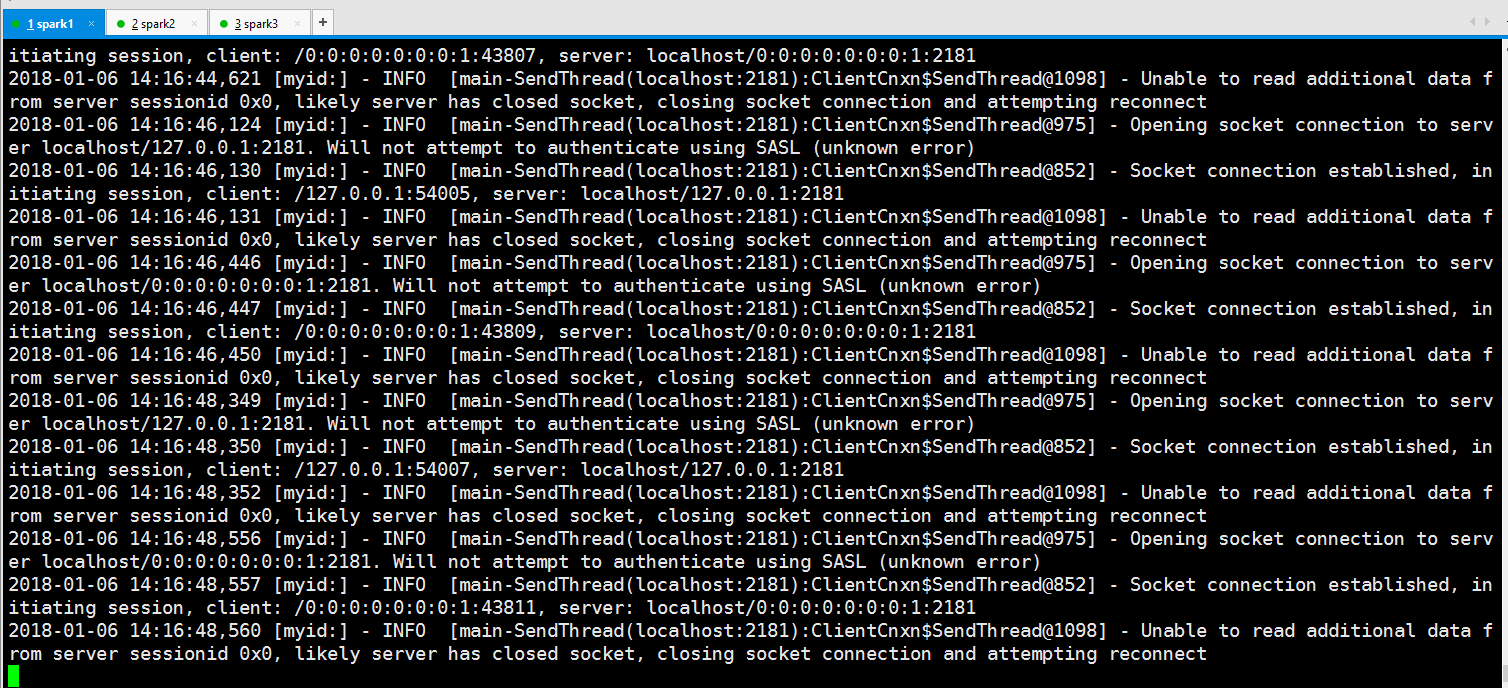
从结果看没连接上
显然这里是要把3台机器的zookeeper启动了才行,当然这个是必须的,但是结果我的还是不行
查看状态

查看zookeeper.out日志

经过一段时间的折腾,和从天而降的一个高速相助,我发现我的防火墙没有关闭
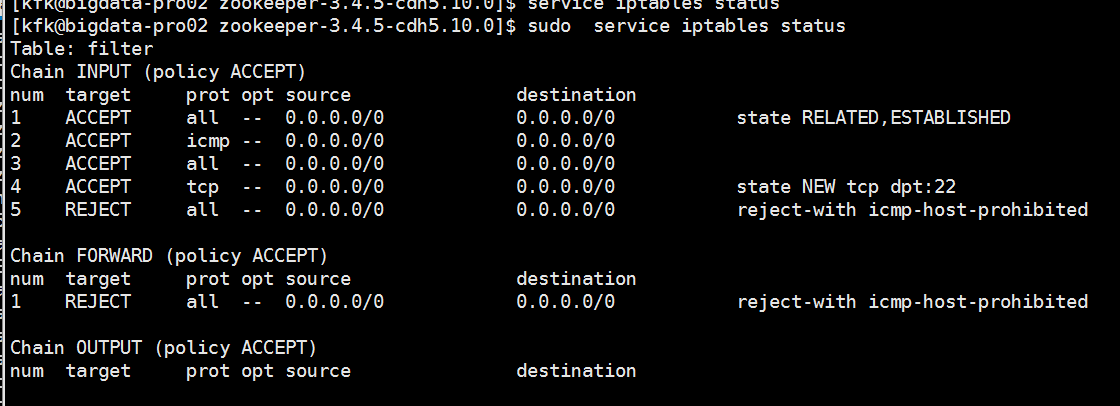
啊啊 啊啊啊啊啊啊啊!!!!!!!!!!!,真他妈的日了狗了,居然犯这样的错误
好,废话不多,马上关闭防火墙


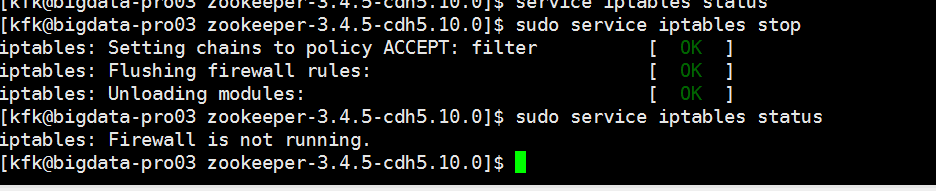
居然成功了
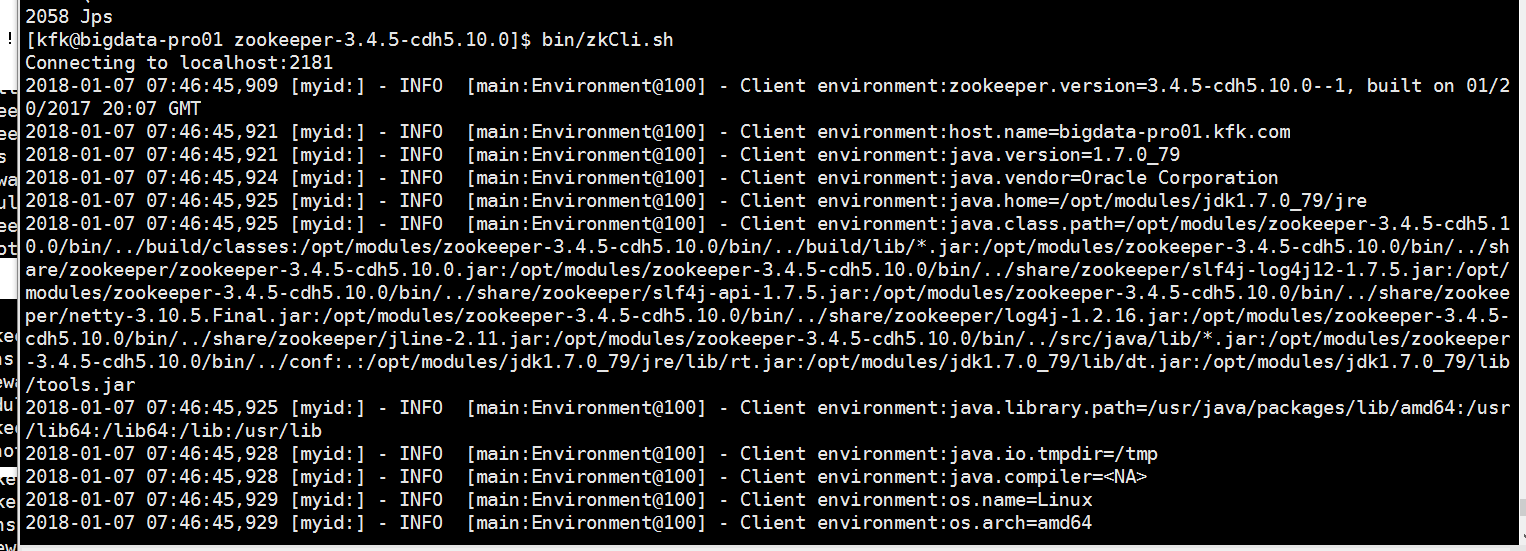
成功了,感谢党!!!!
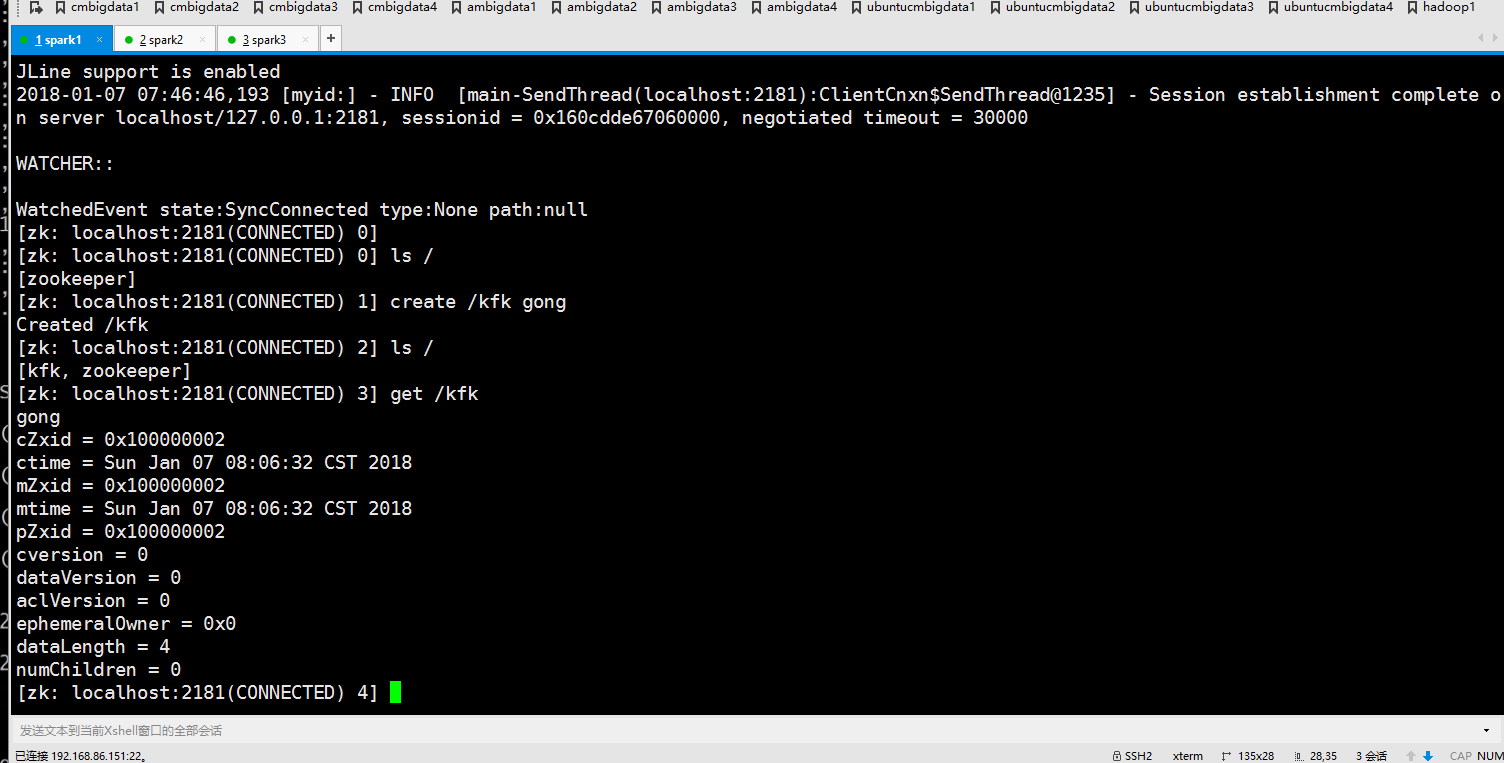
现在查看谁是“老大”



可以看出来第三台机器是老大!!
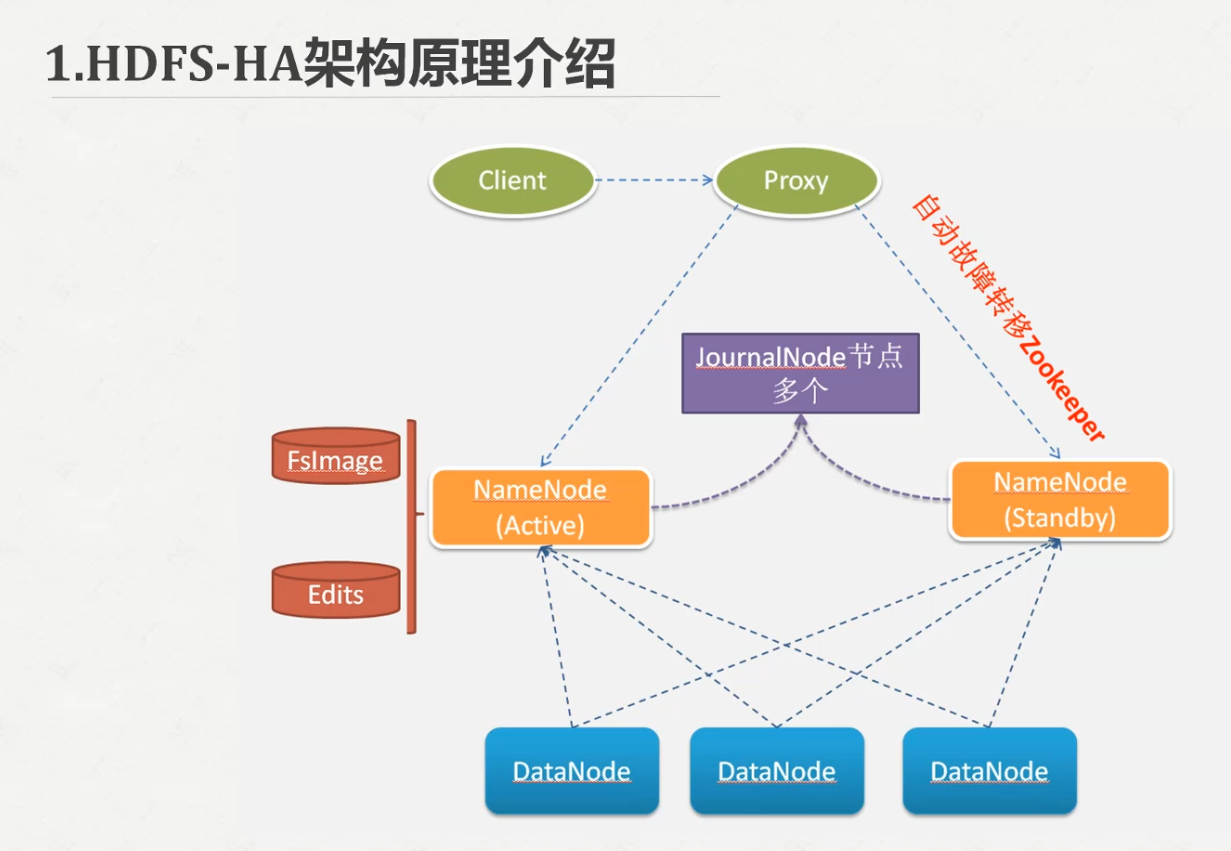
Hadoop HA的搭建

先把原来的配置文件和临时目录备份一下
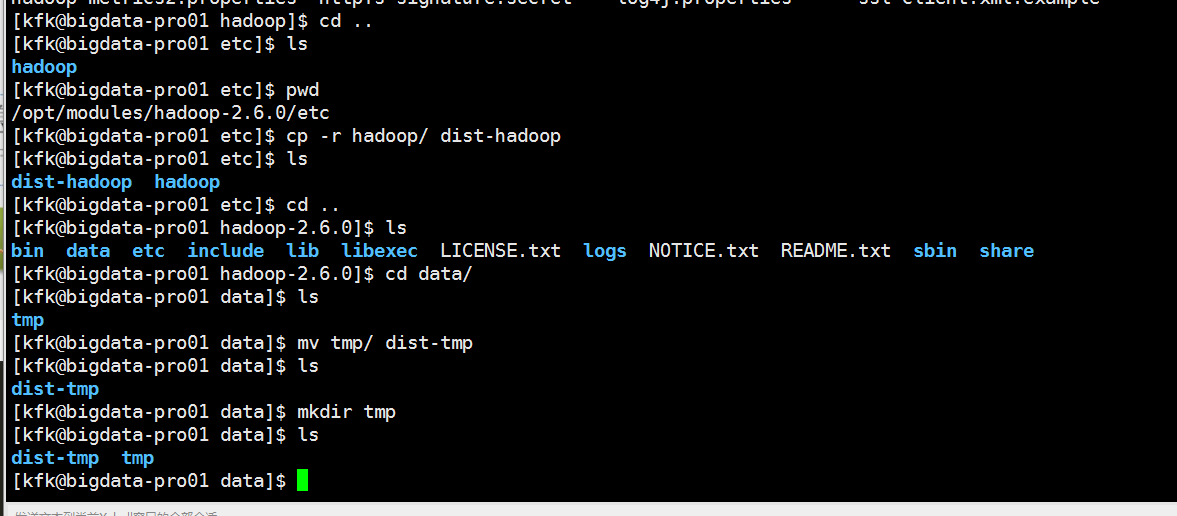
进到这里来

添加以下内容


创建目录
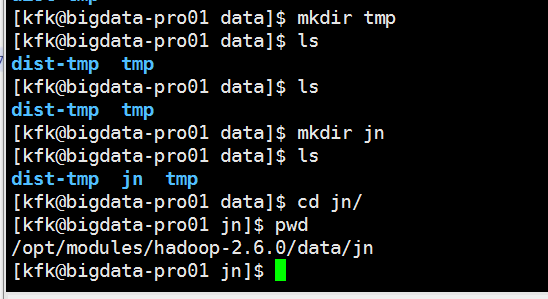



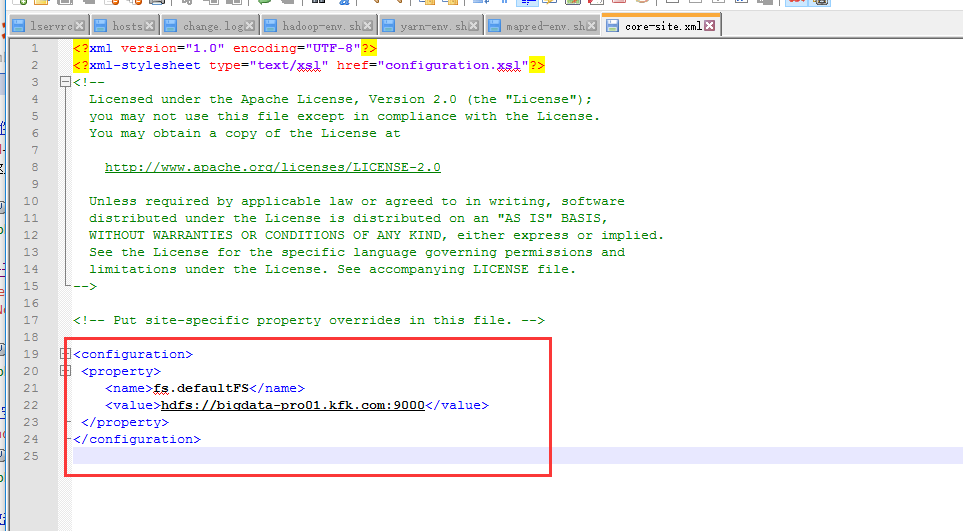
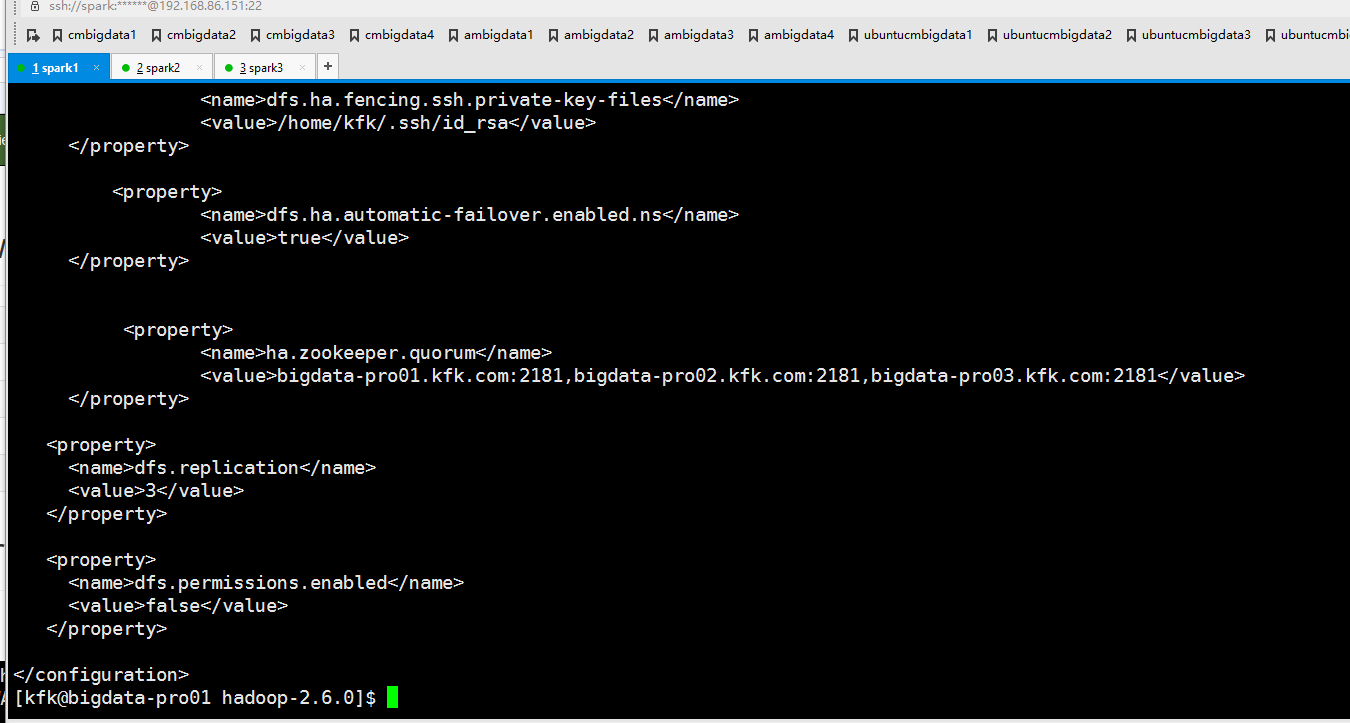
修改core-site.xml

在第二个节点上


在第三个节点上也是一样的操作
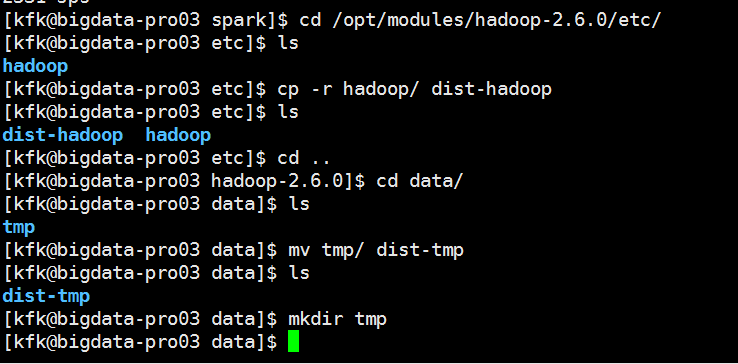

把第一节点的配置文件分别分发到其他两个节点
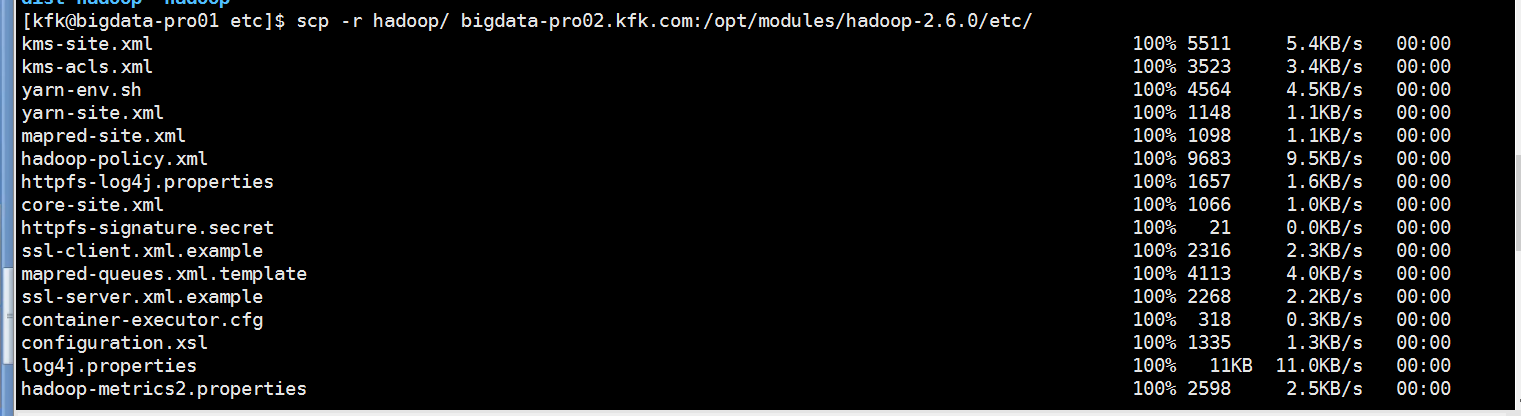
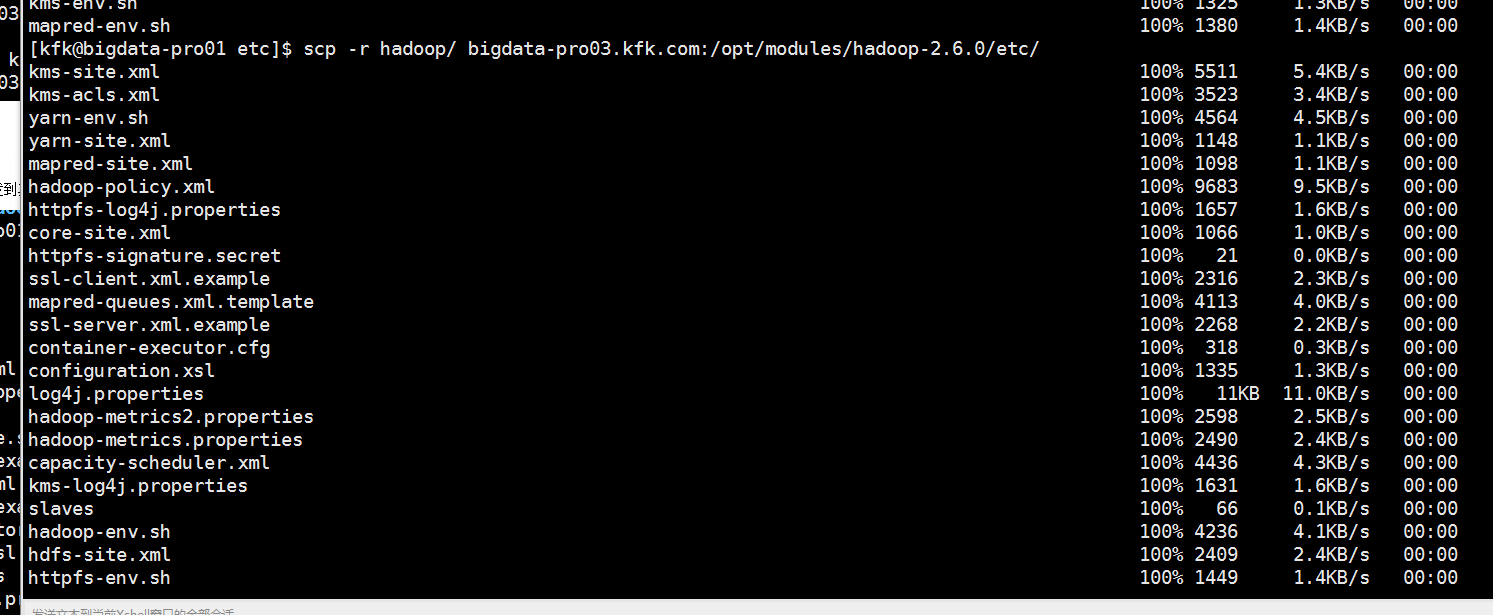
给3个节点分别启动journalnode



接下来在节点1上对namenode格式化
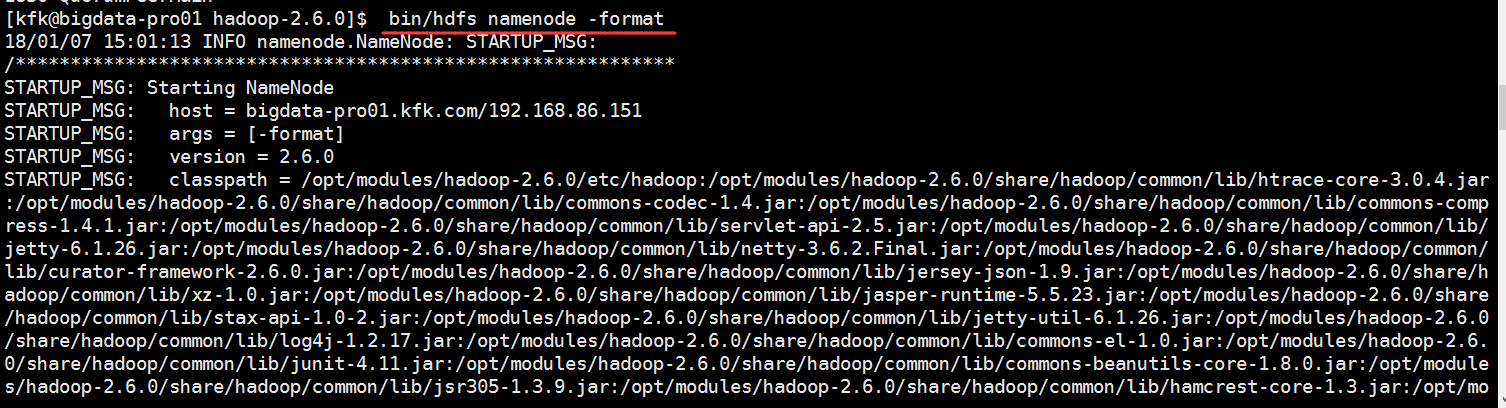

启动namenode

在nn2上同步nn1的元数据信息
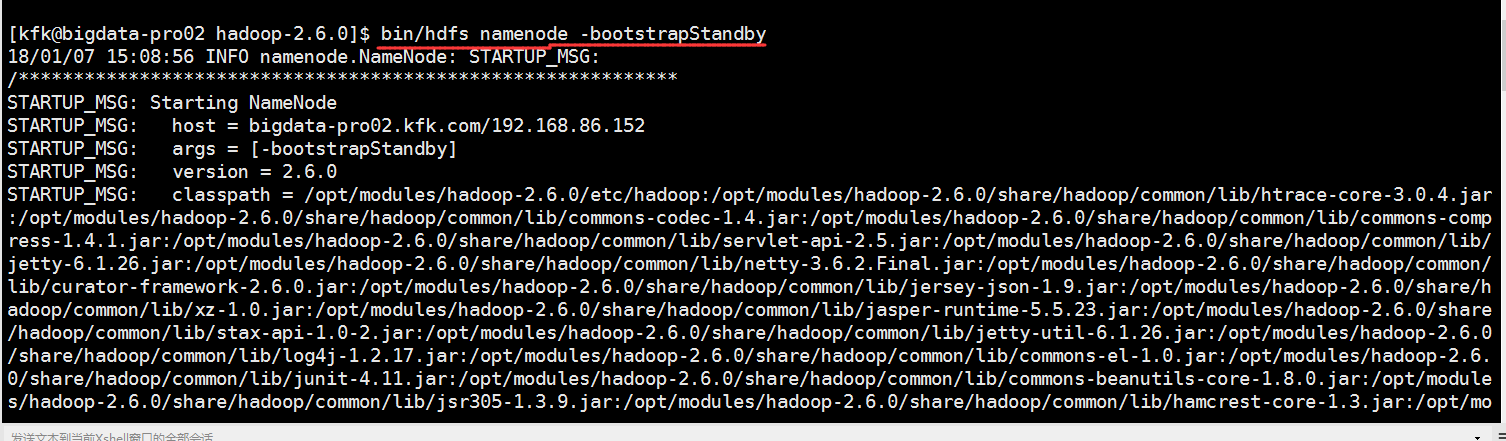

把节点2的namenode启动一下

打开测试页面看看

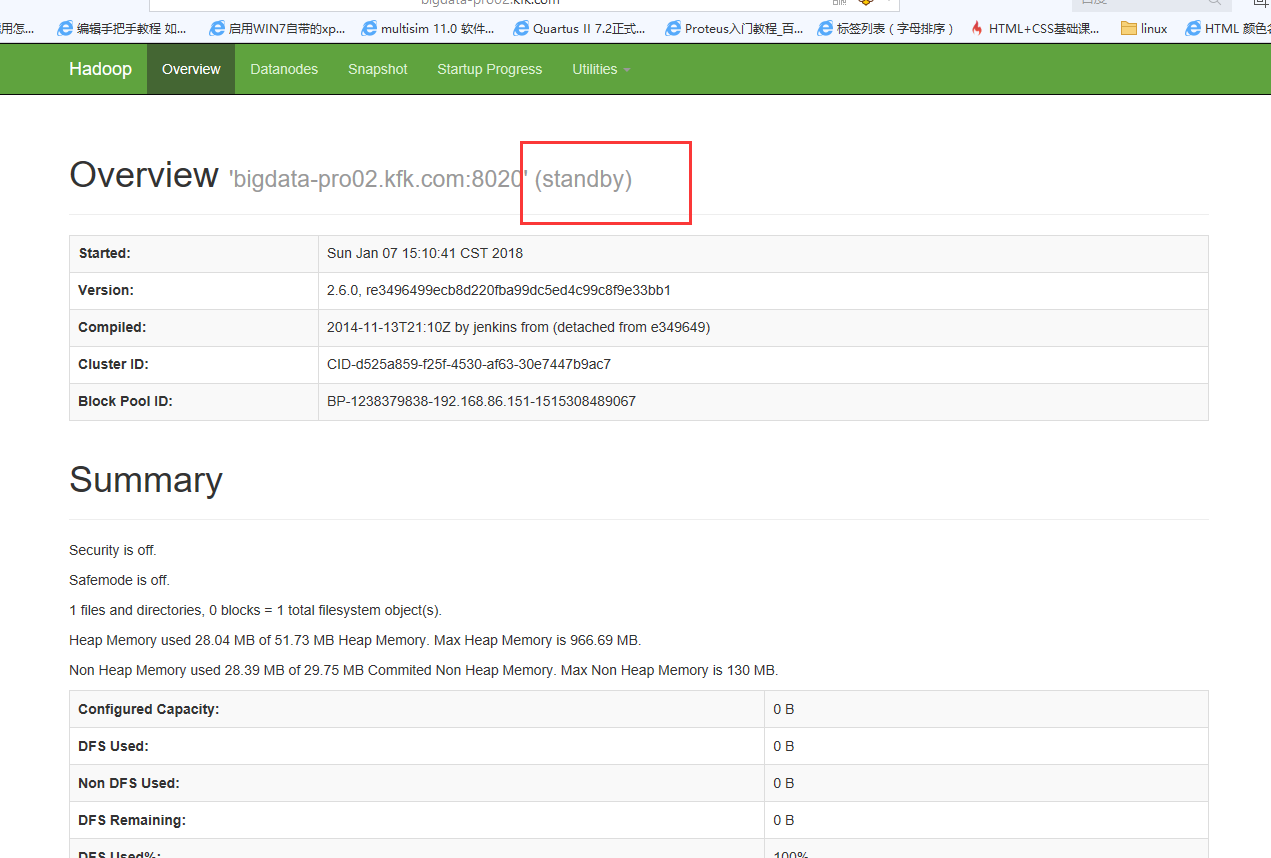
我们可以发现两个都是standby状态,是因为我们还没有设置哪个是active状态
现在我们将nn1设置为active状态


下面把namenode datanode都启动了
先把进程停止
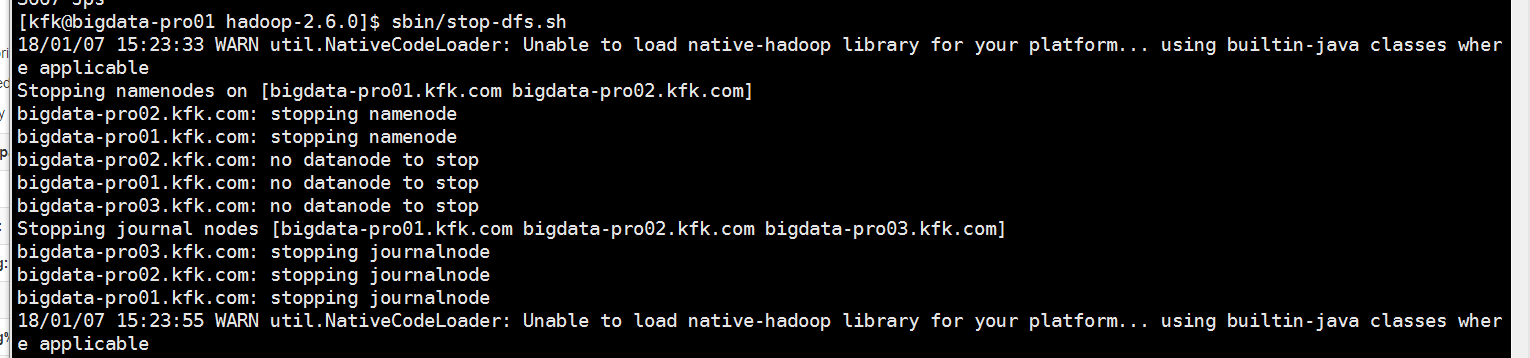
再启动



可以看到每次启动都需要我们手动去设置active状态

下一步要在hdfs上创建目录,那我们就先把nn1设置成active状态

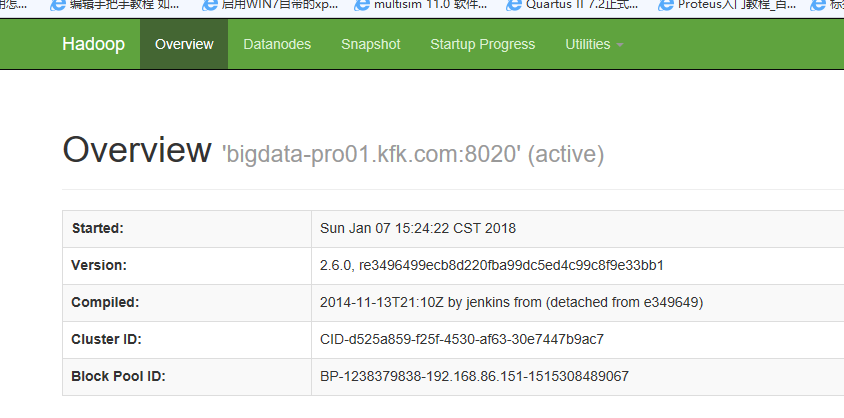
在hdfs上创建目录并且把本地文件上传


查看hdfs上的文件

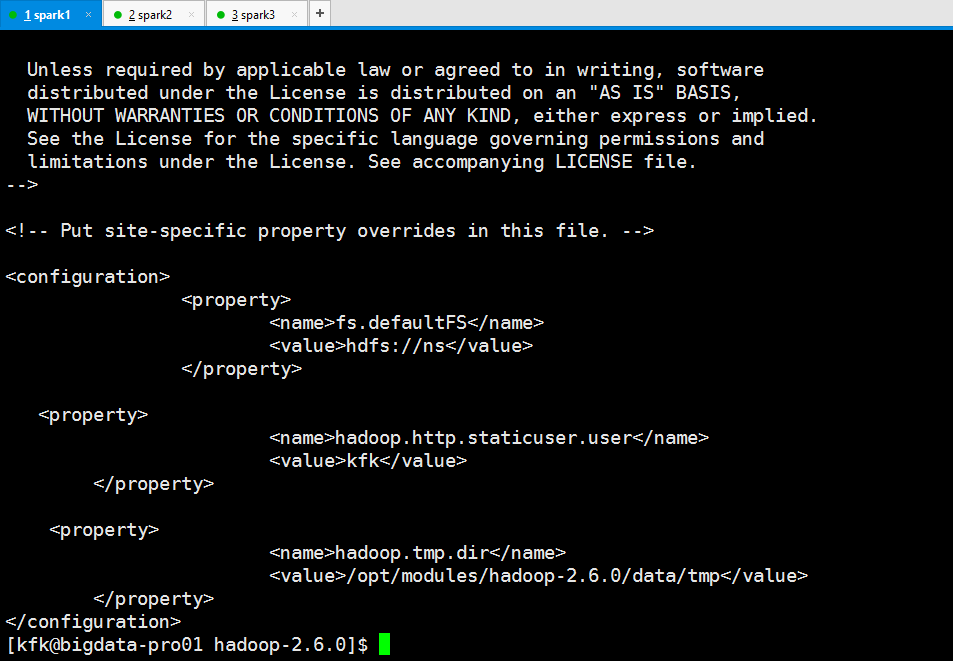
现在把节点1的namenode 进程杀掉
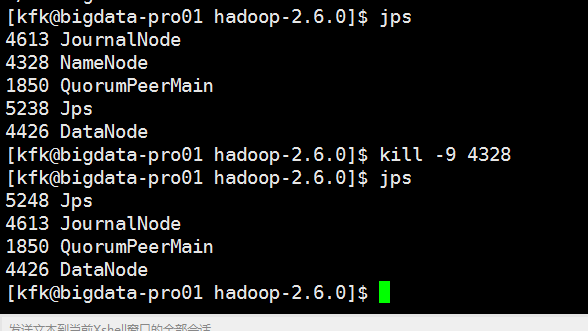
把nn2改成active状态

我们可以看到没有成功。

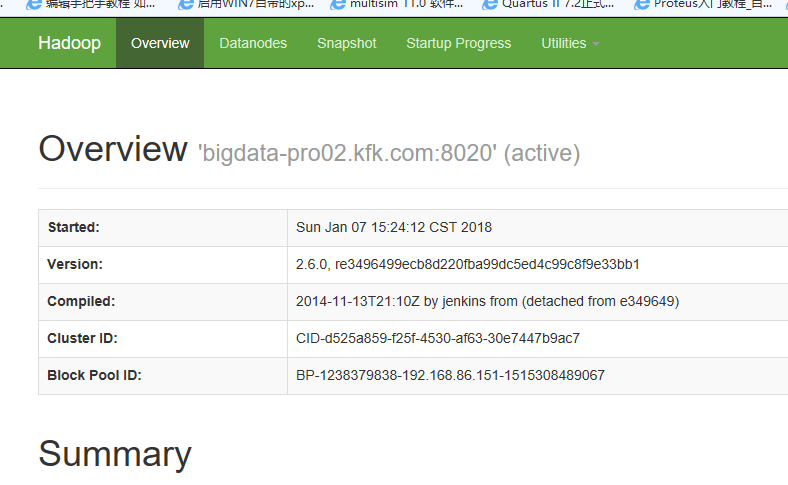
现在成功了!!
在节点1上能读取hdfs上的文件,说明这个HA配置成功!

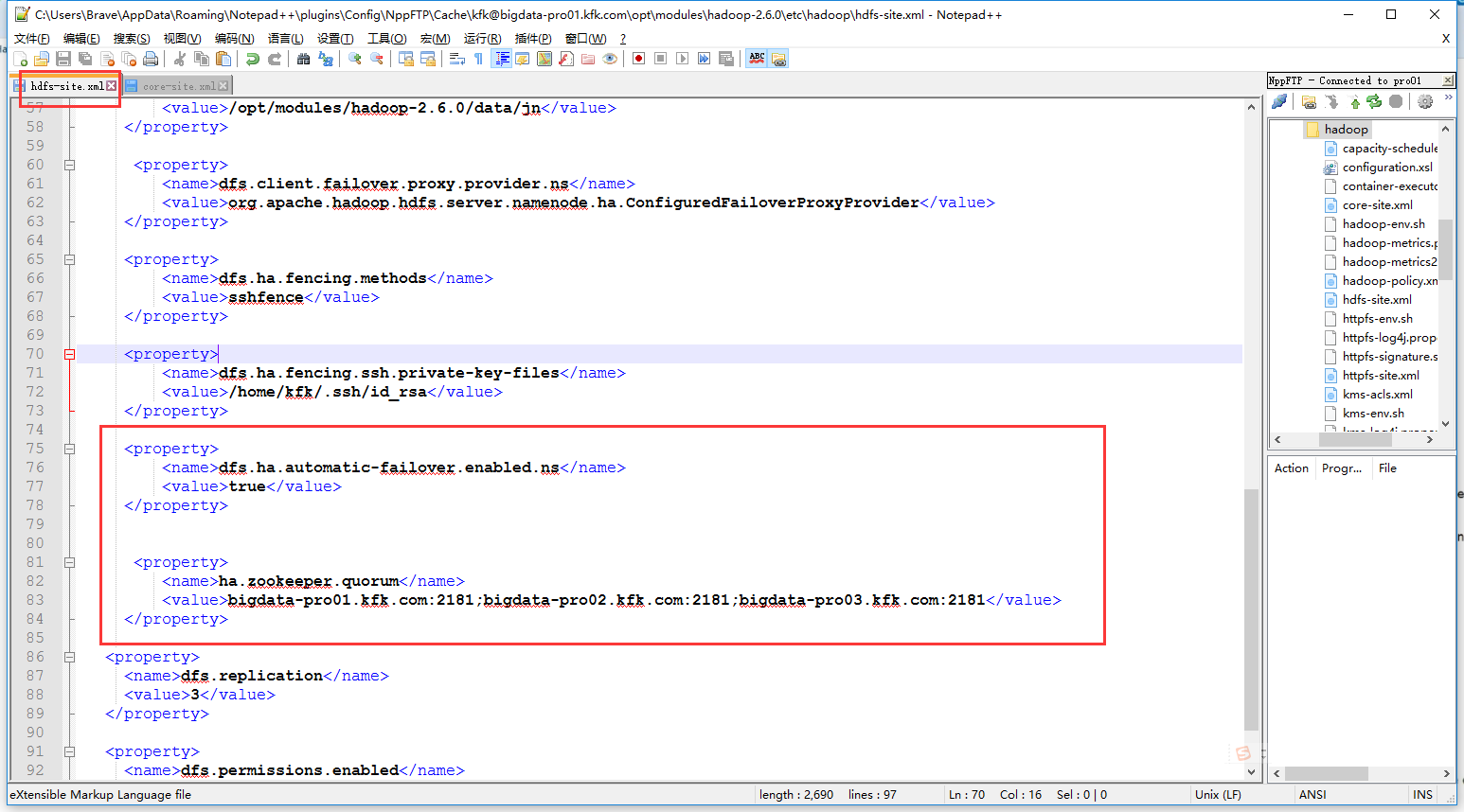
在配置文件添加以下内容(其实这里添加的配置内容有错误的,下面会讲到)

把进程都停下来
同时把zookeeper也停下来


现在所有进程都停止了,下面安装步骤分别启动进程。
先分别启动三台机器的zookeeper

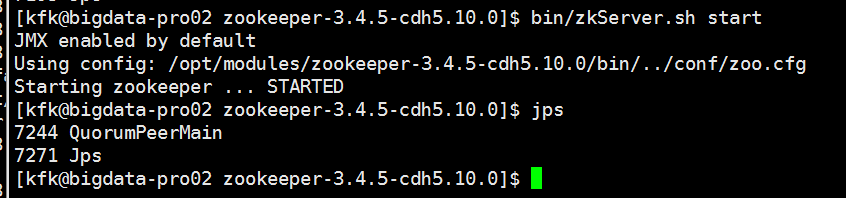
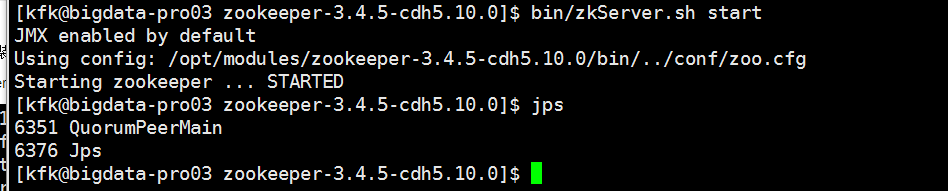
初始化HA在zookeeper中的状态
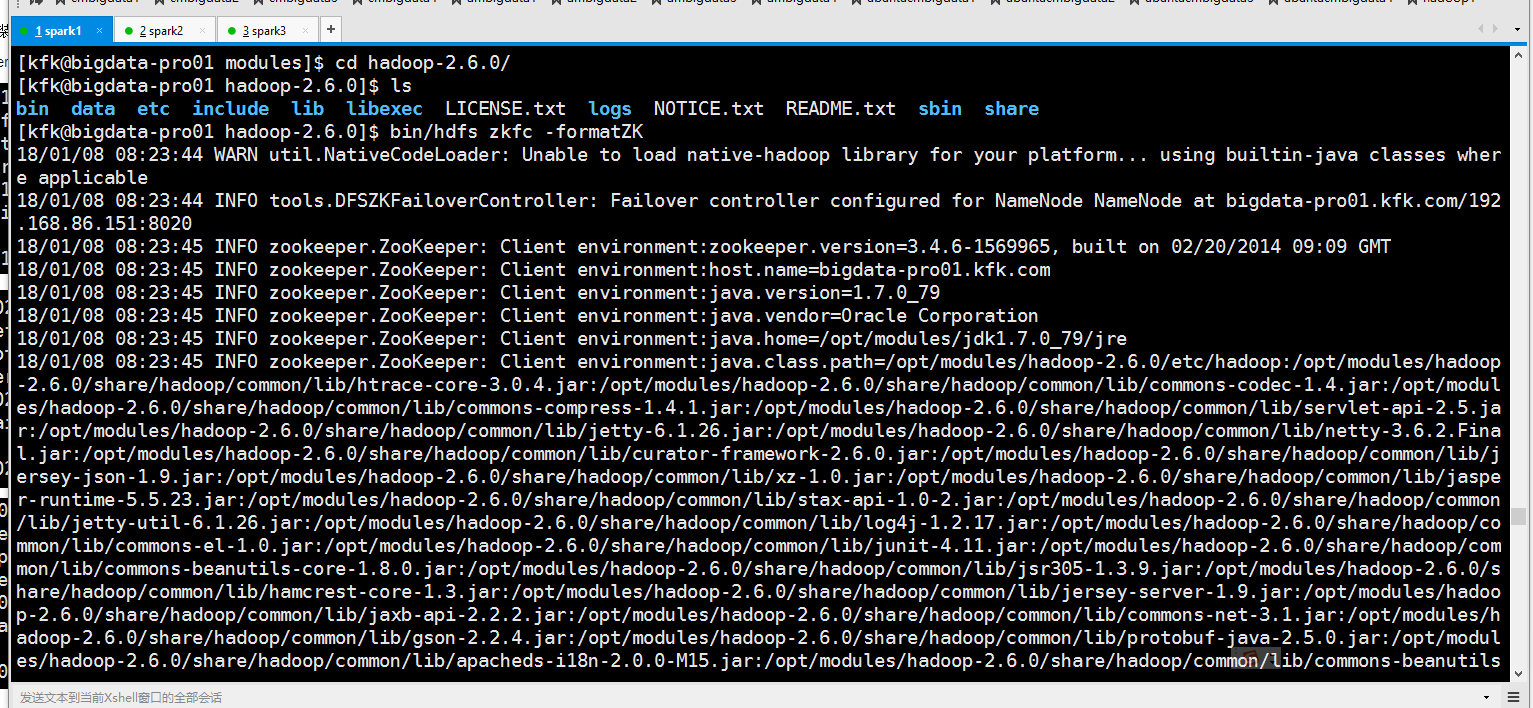

可以看到报错了!!,是之前的配置文件没有配好,正确的是这样的

修改后,再来一次
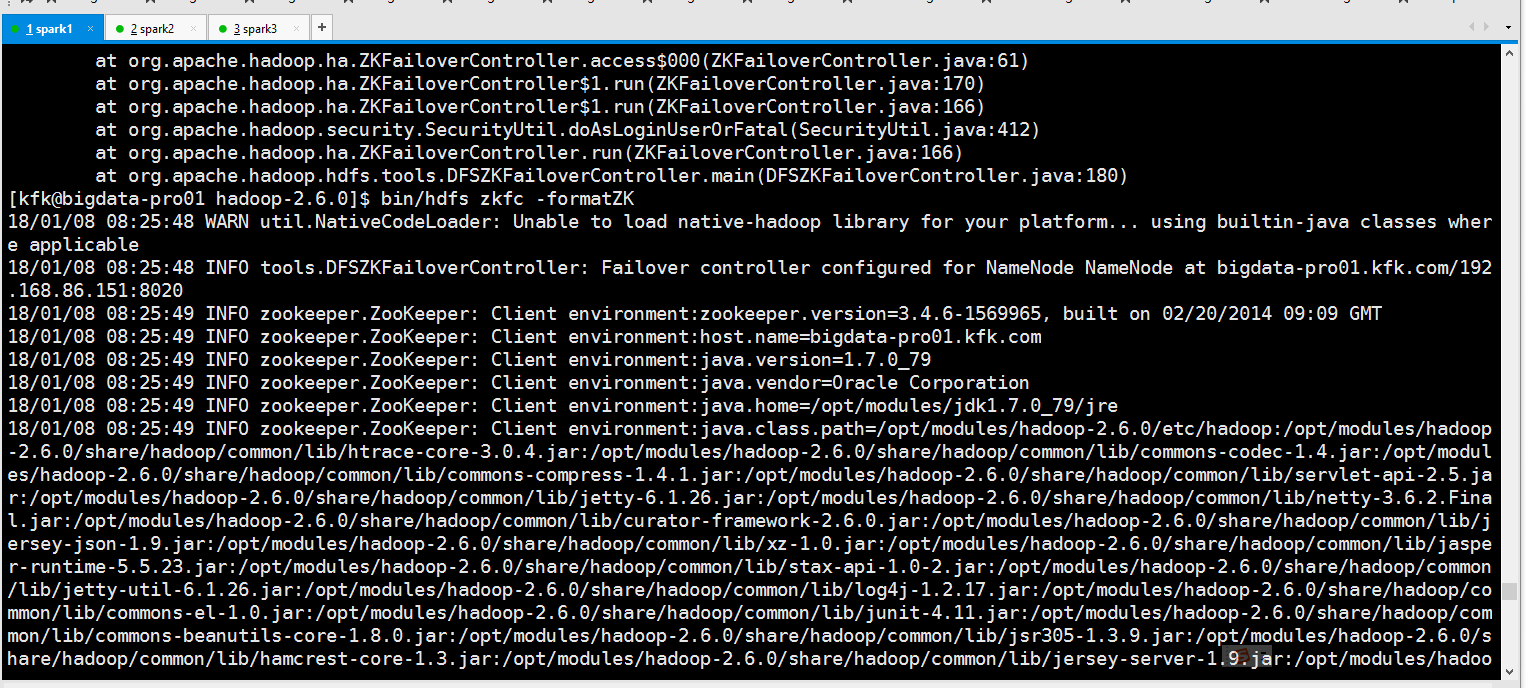
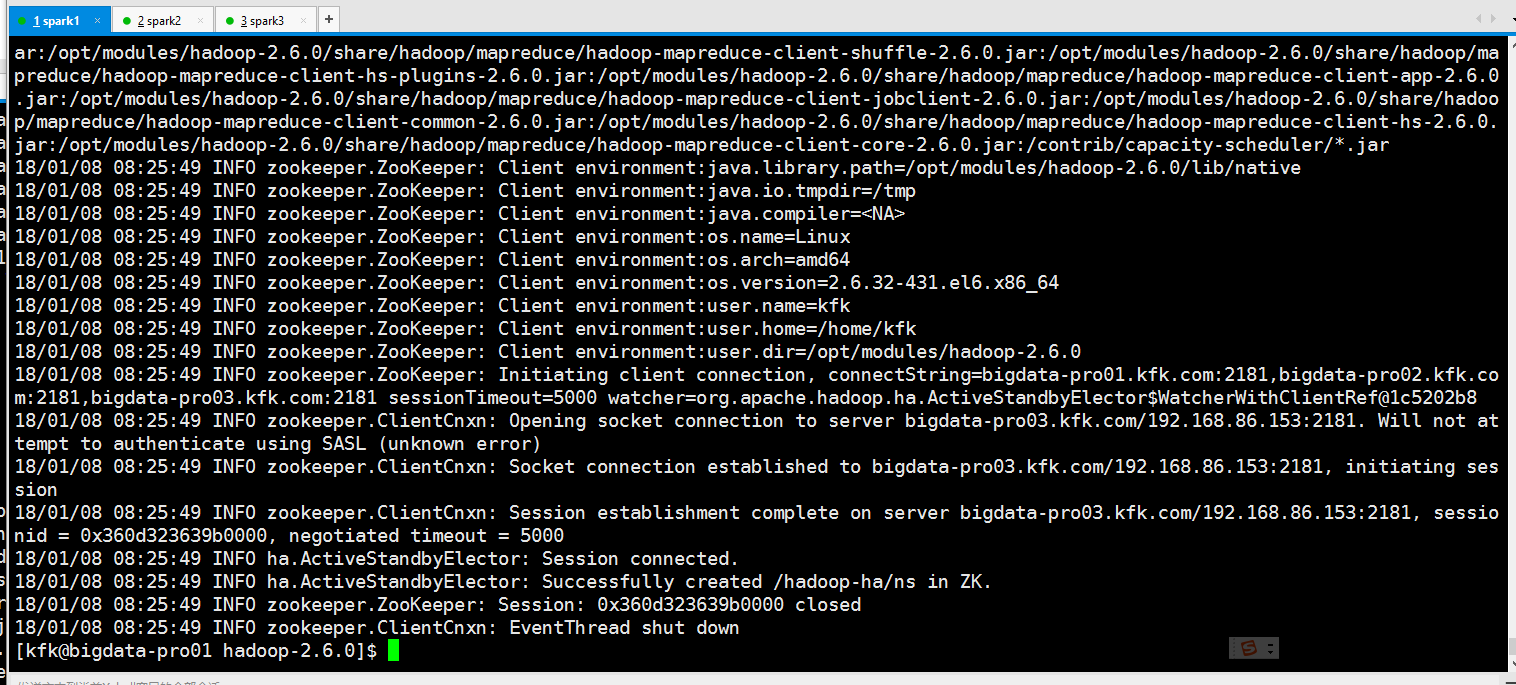
可以看到成功了!
启动HDFS服务
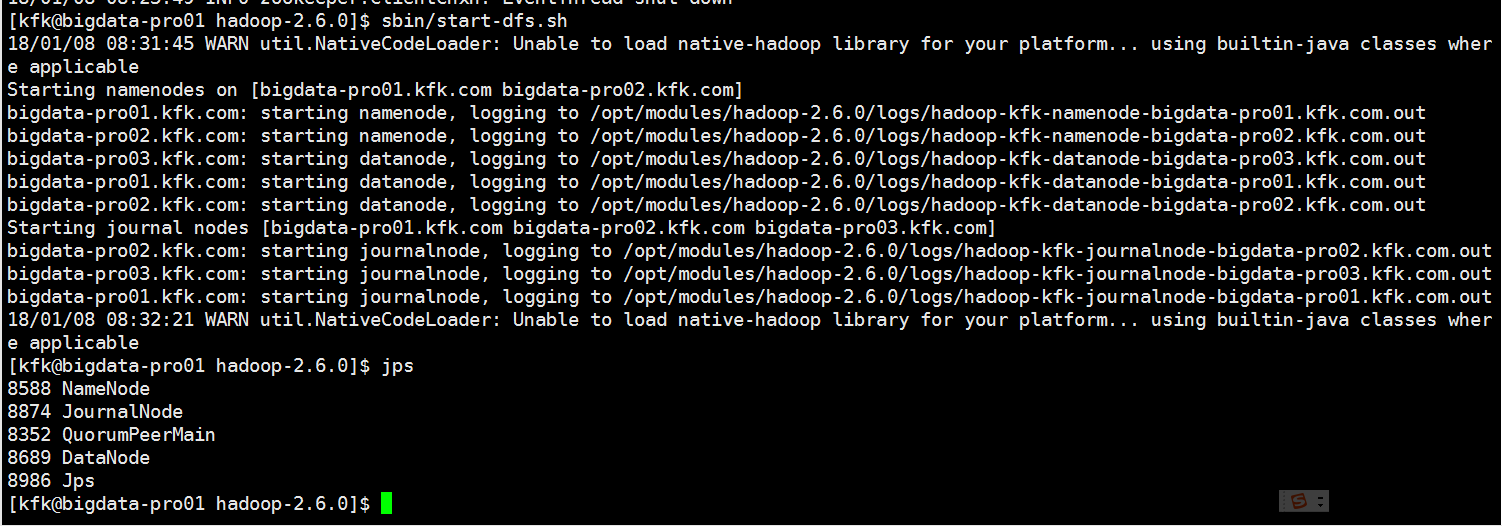


上传文件到hdfs上


这个时候我们把节点1的namenode停掉

看看能不能读取hdfs上的文件,结果报错了
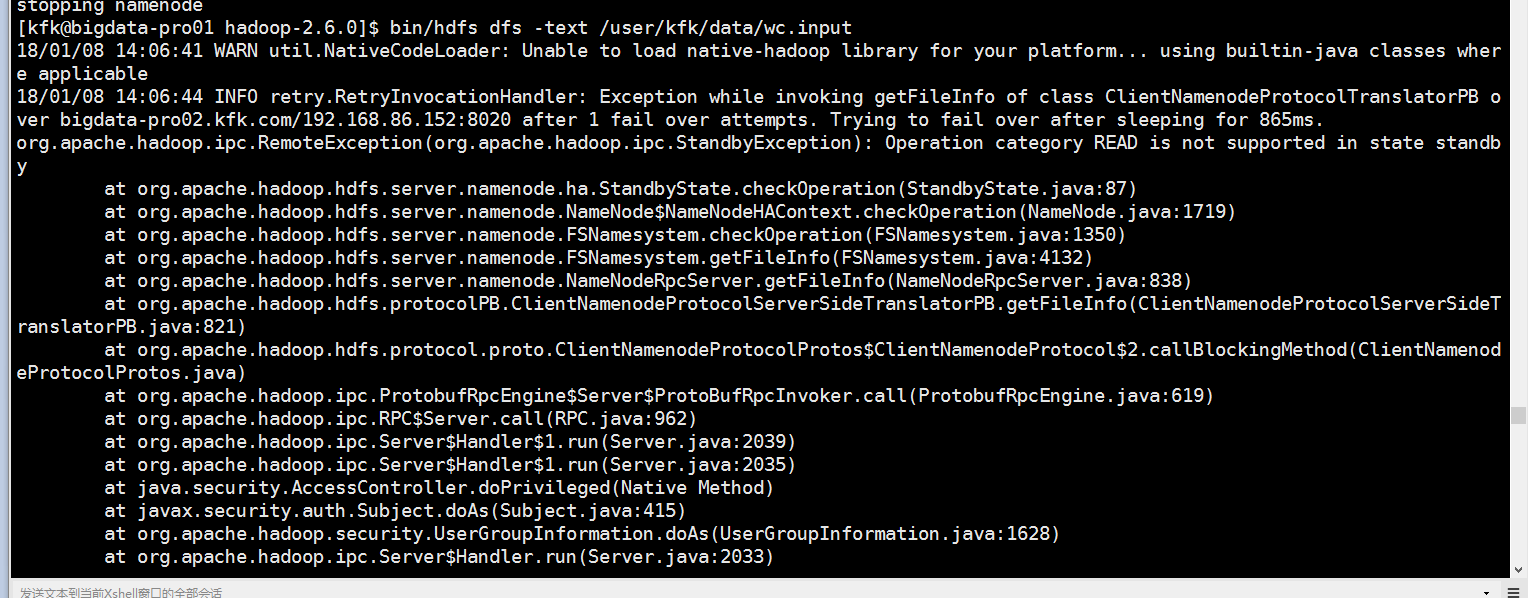
发现在节点2的zkfc进程没有启动

查看日志

原因是我们在节点1上配置了hdfs-site.xml没有同步到其他节点去。
现在我们把他分发到节点2去

在节点2再次启动zkfc,可以看到启动成功了
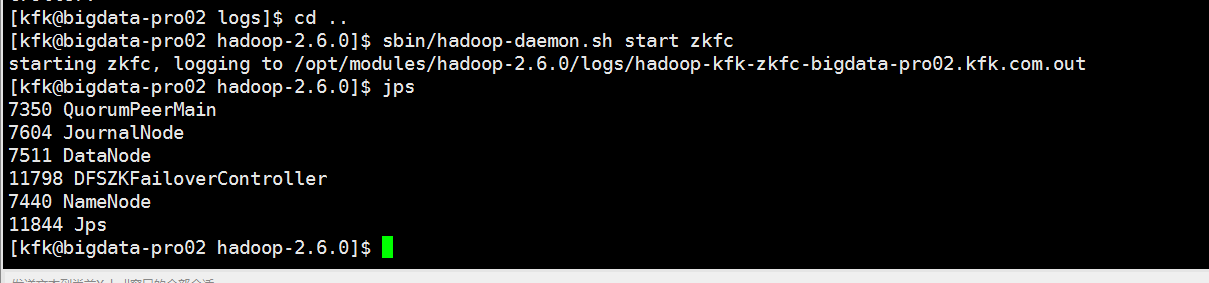
现在我们重新来把所有进程重启一下,先停掉所有进程
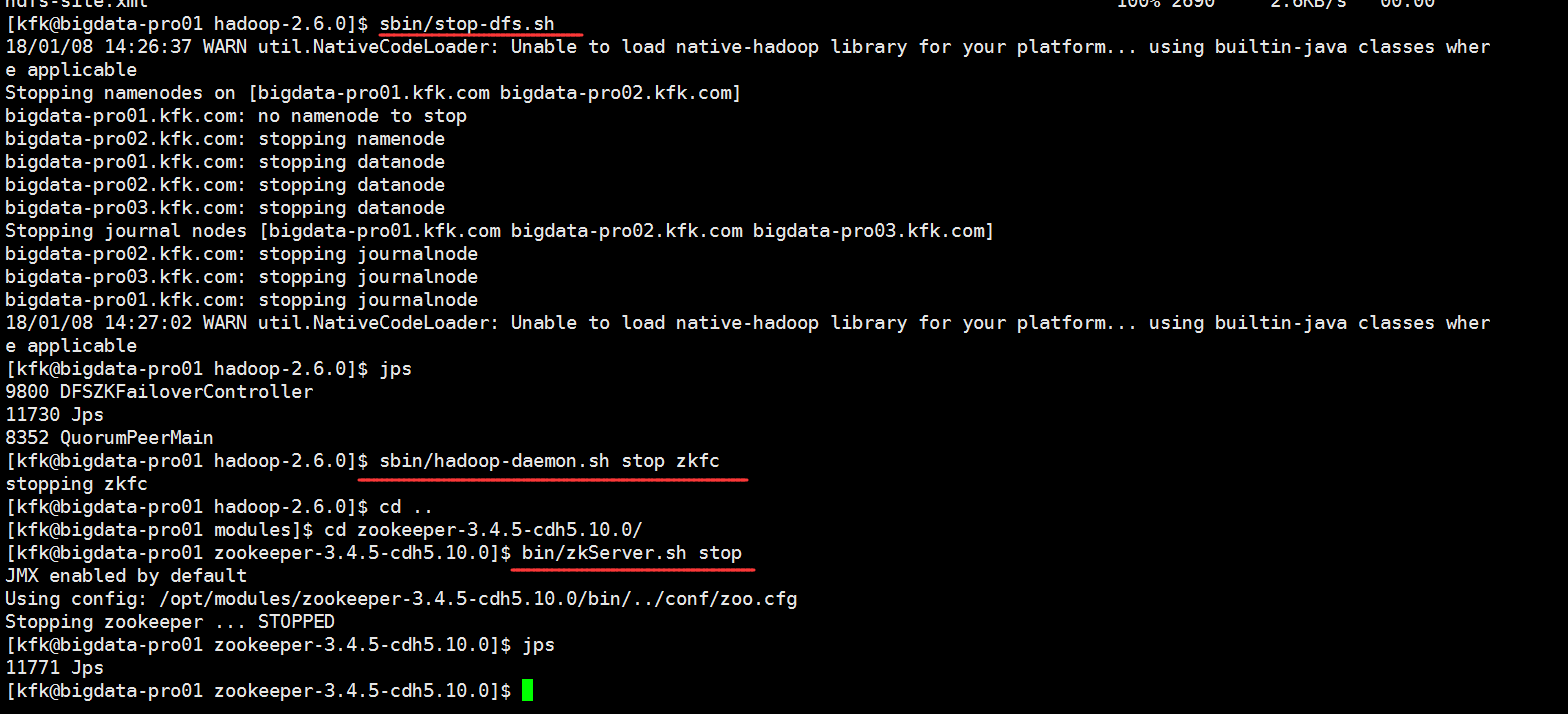
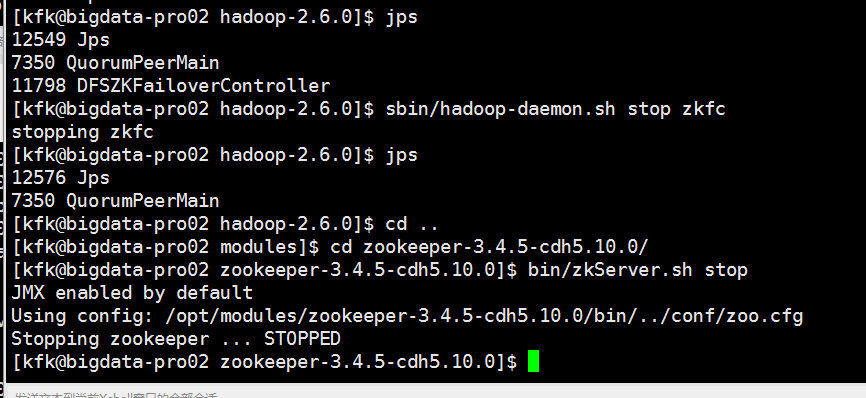

先启动zookeeper



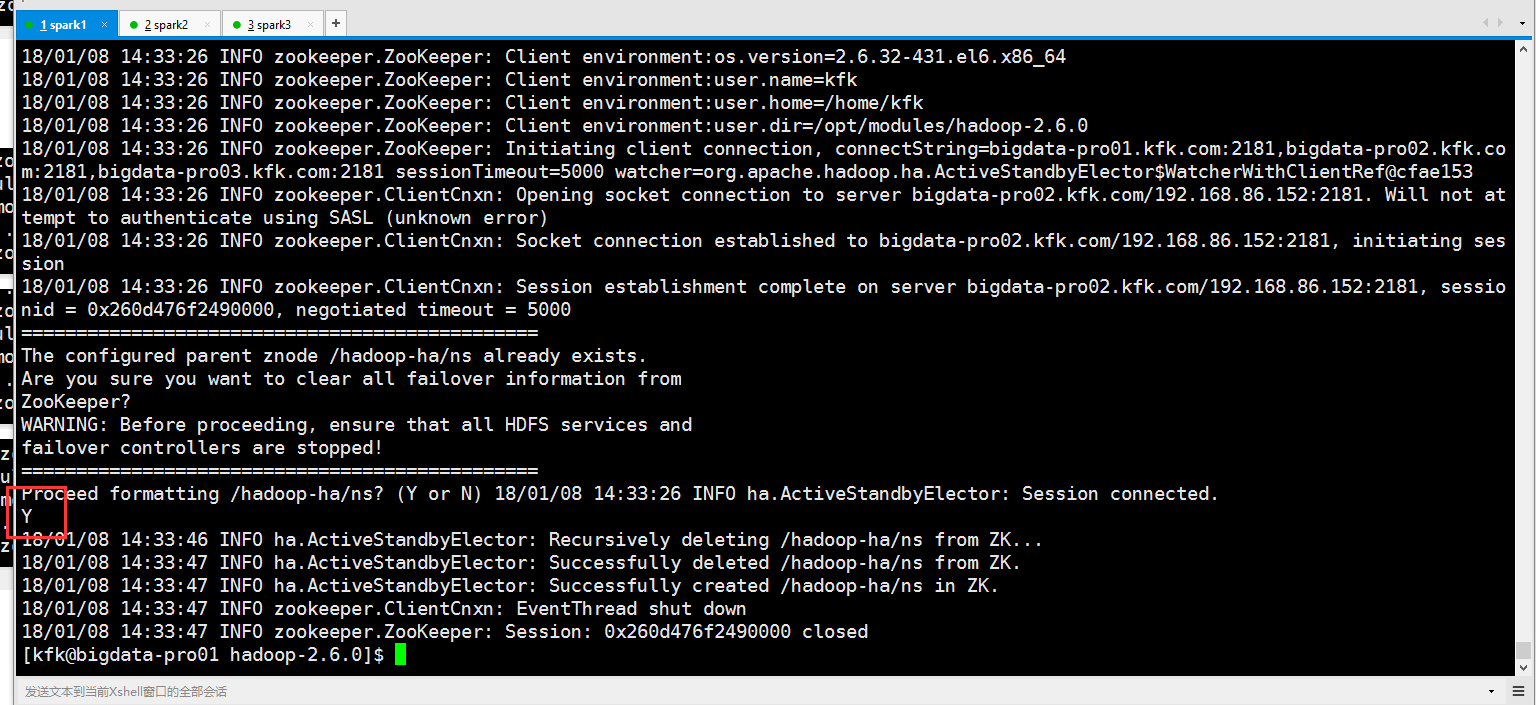
把zkfc重新格式化一次

输入Y
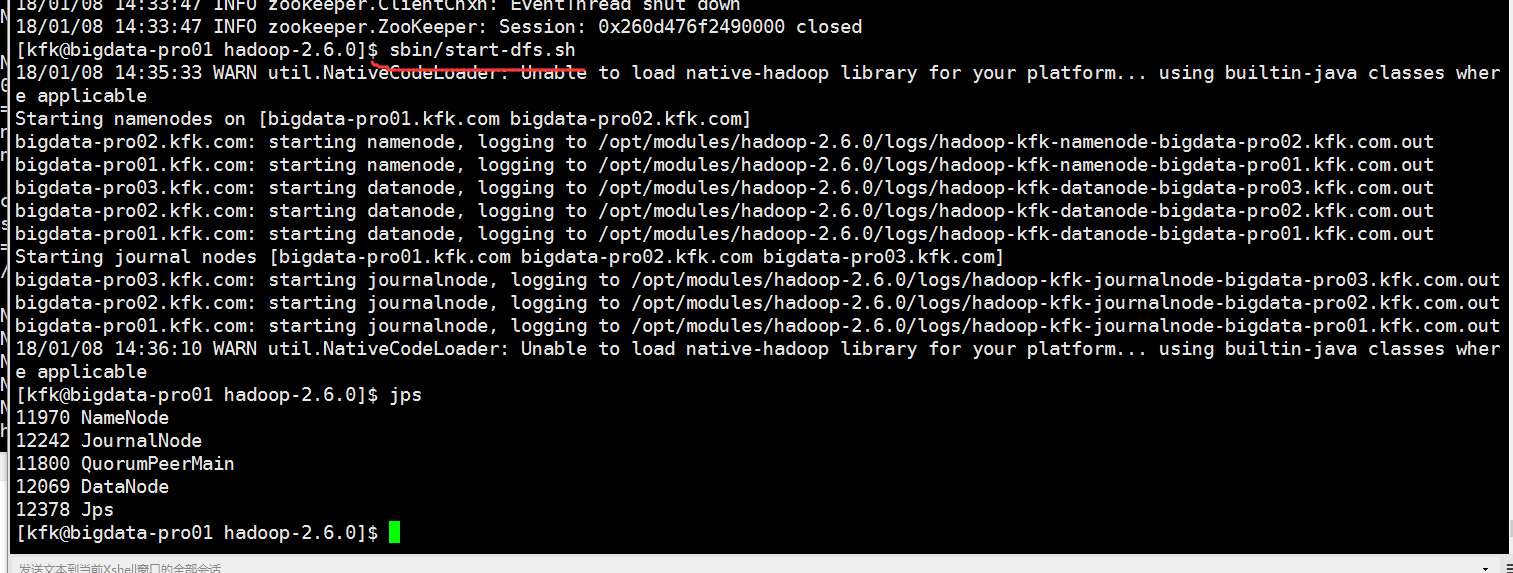
启动hdfs的所以服务
启动zkfc
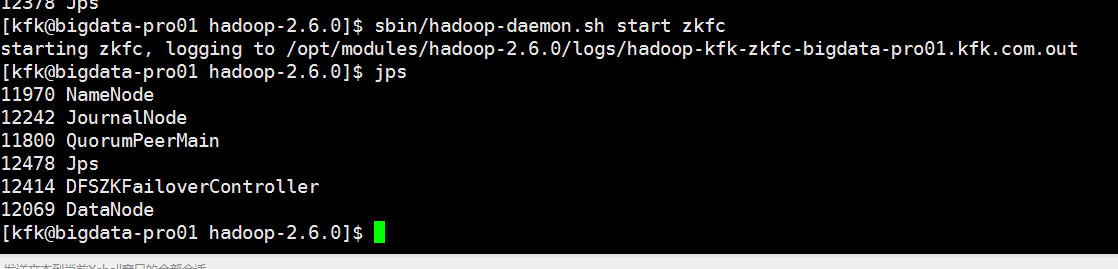
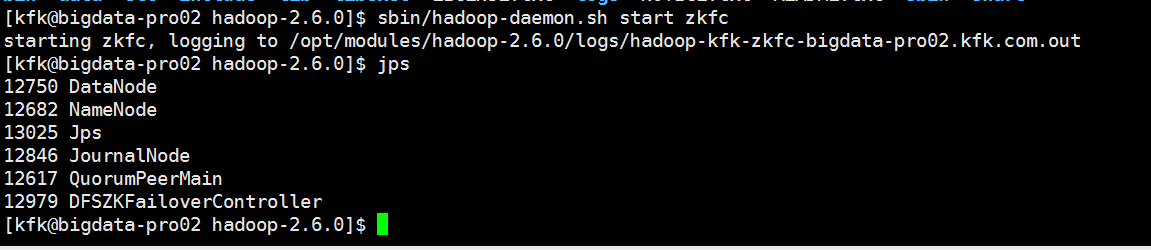
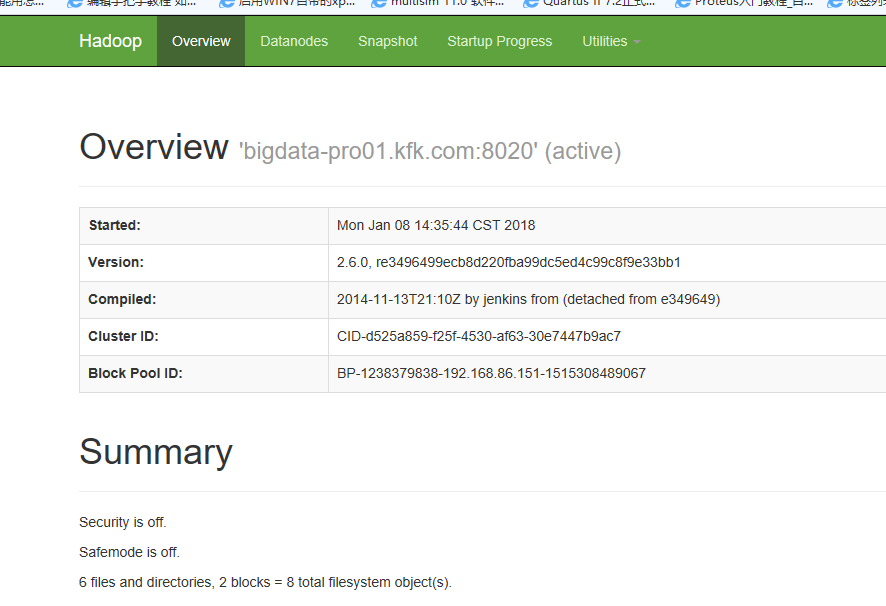

因为节点1是active状态,所以我们就把他的namenode进程干掉
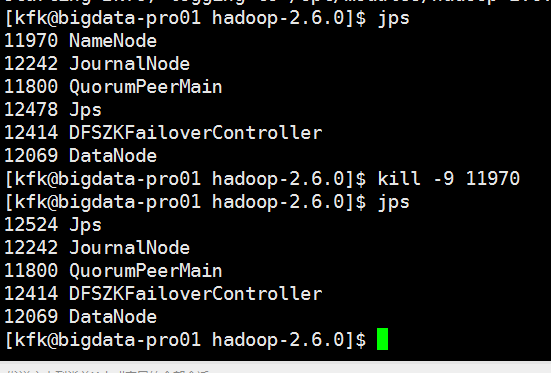
这个时候节点2变成active状态

现在我们完成了基于zookeeper的故障转移了!!!!!!


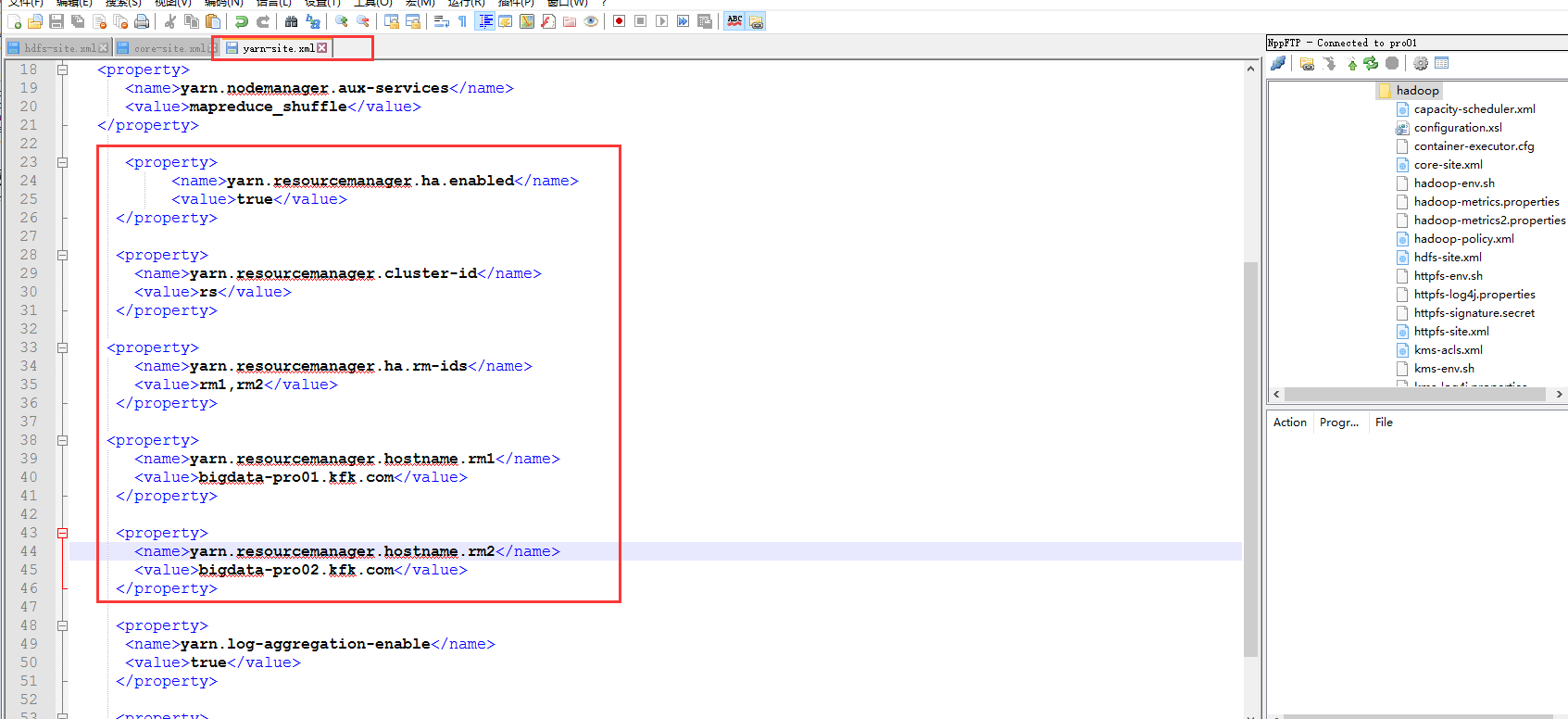
下面我们来配置yarn的HA
添加以下内容
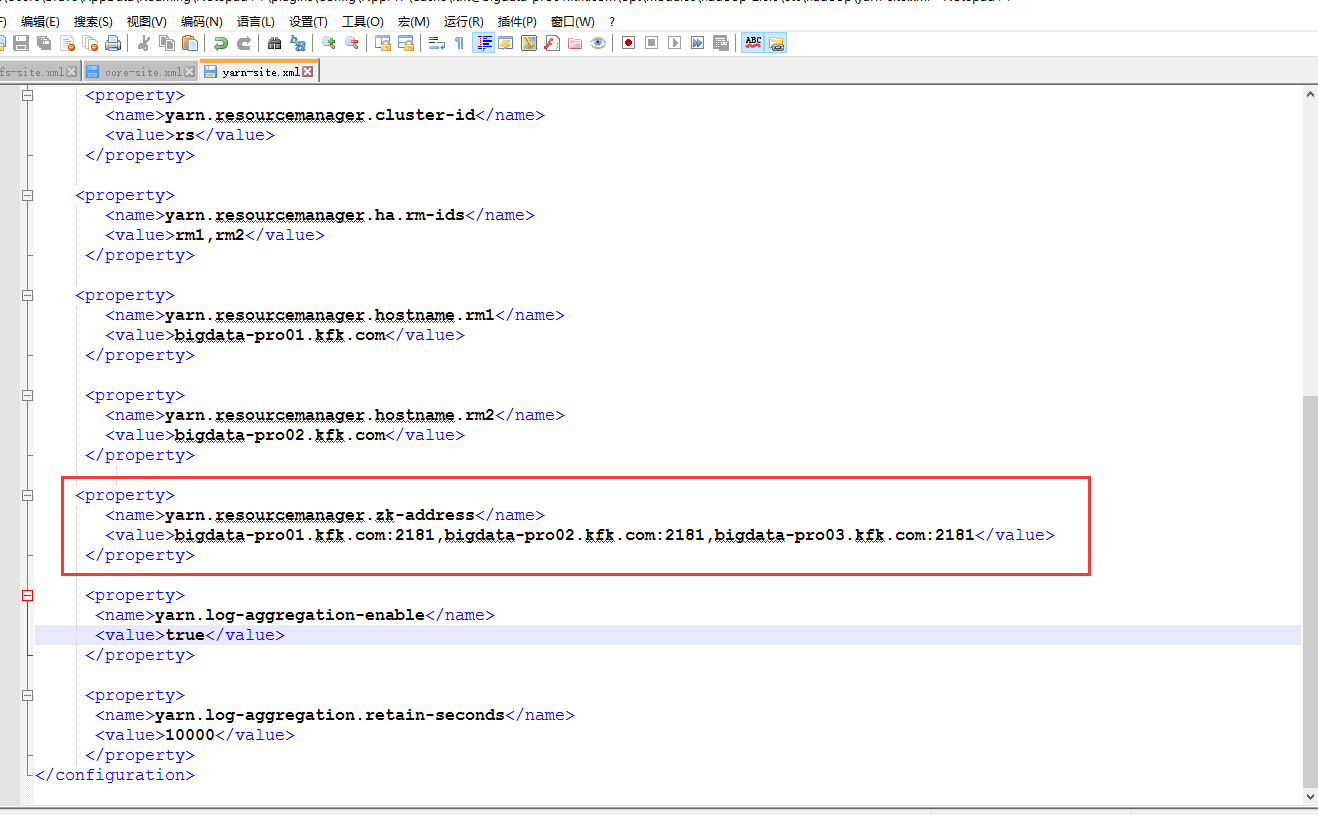
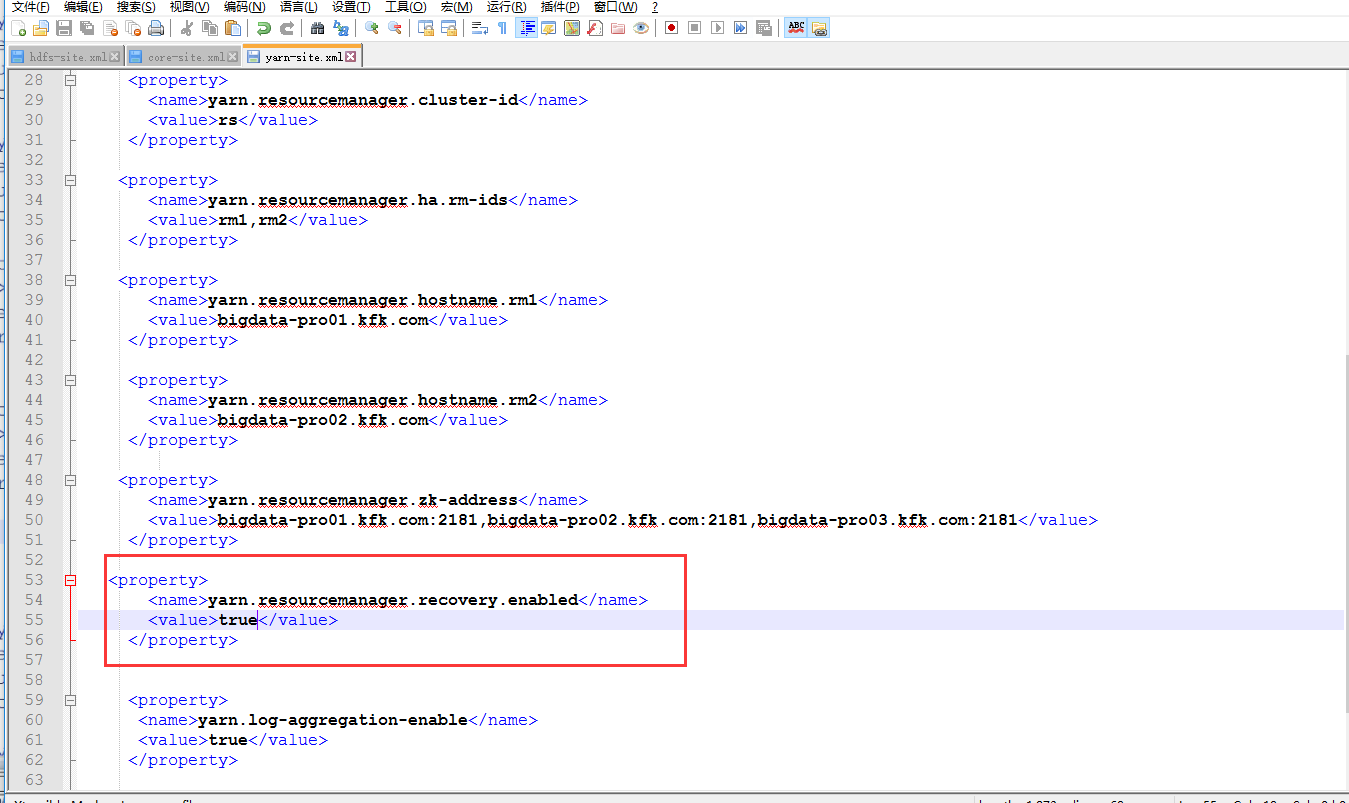
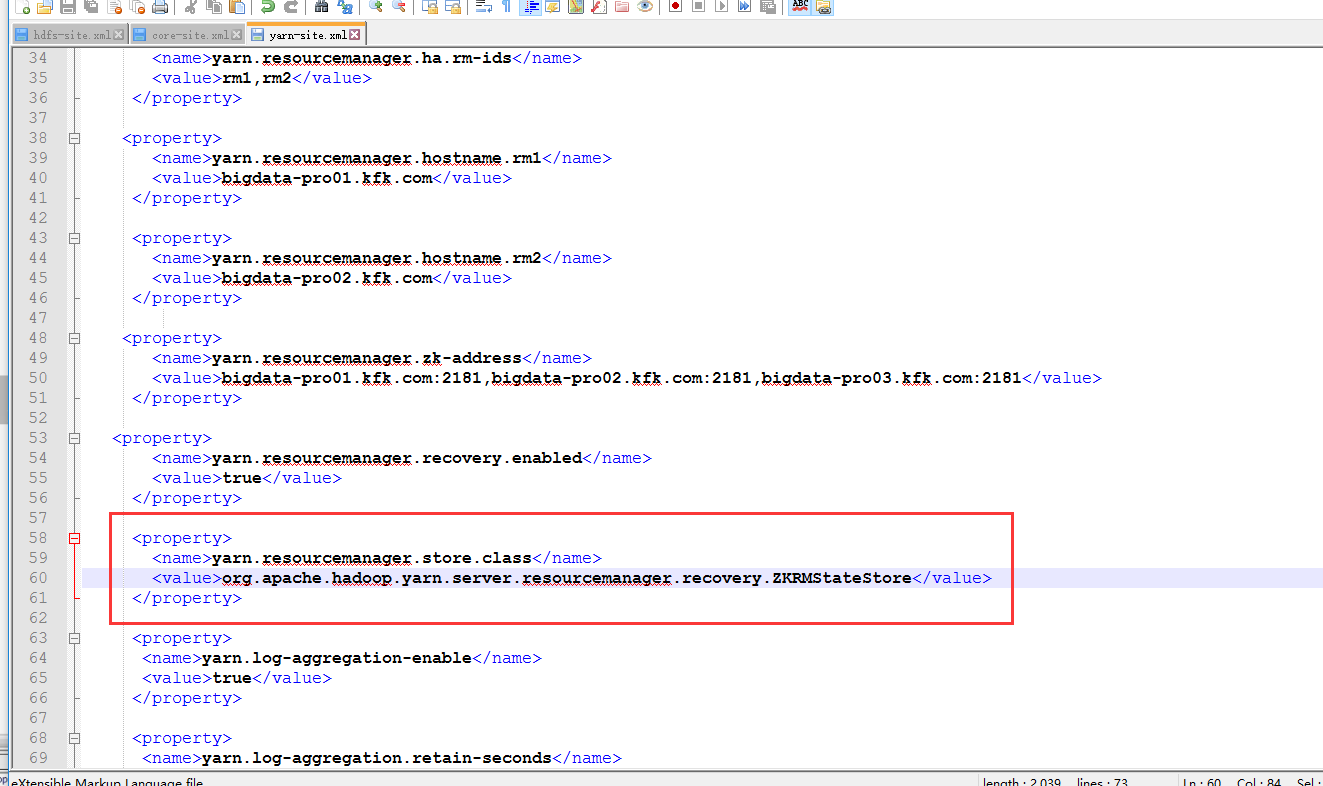
把配置文件分配给其他节点

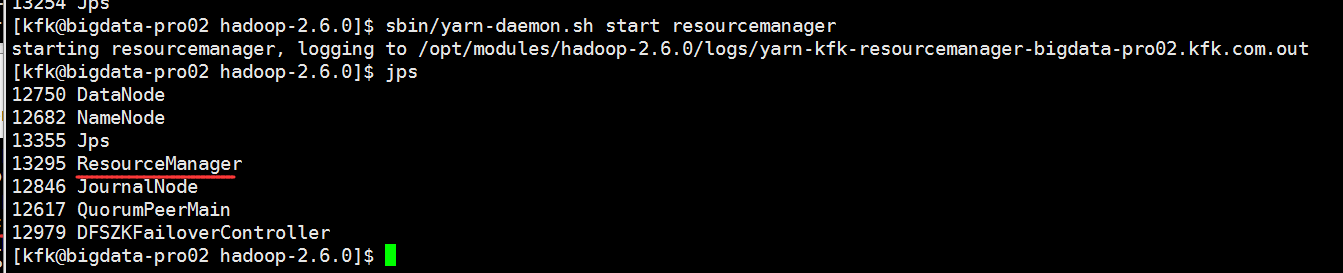
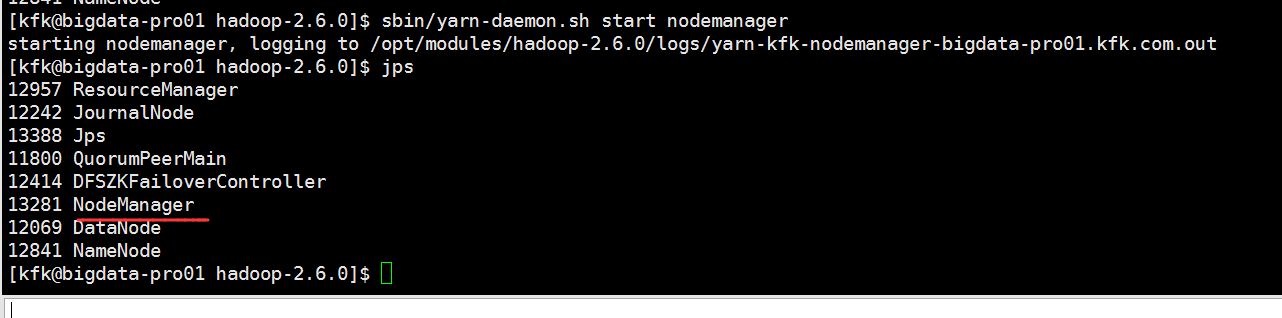
启动进程resourcemanager nodemanager


下面我们进行一个mapreduce程序,先创建一个输出目录在hdfs上


spark新闻项目环境搭建的更多相关文章
- spark JAVA 开发环境搭建及远程调试
spark JAVA 开发环境搭建及远程调试 以后要在项目中使用Spark 用户昵称文本做一下聚类分析,找出一些违规的昵称信息.以前折腾过Hadoop,于是看了下Spark官网的文档以及 github ...
- Spark+IDEA单机版环境搭建+IDEA快捷键
1. IDEA中配置Spark运行环境 请参考博文:http://www.cnblogs.com/jackchen-Net/p/6867838.html 3.1.Project Struct查看项目的 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- 第一周博客之二---OA项目环境搭建及开发包部署
OA项目环境搭建 一个项目想要能够在开发人员打包好项目包之后进行测试,就必须进行项目测试环境的搭建,要根据开发工程师的开发环境采用不同的测试环境,以下只是浅谈下Java项目OA(办公自动化平台)的环境 ...
- mac OS X下Java项目环境搭建+IntelliJ IDEA Jrebel插件安装与破解+Office 2016破解版安装
一.mac OS X下Java项目环境搭建 因为某些原因新入手了台最新版的MacBook Pro,意味着今天要花一天时间安装各种软件以及项目环境搭建╮(╯▽╰)╭ 项目环境搭建步骤: 1.安装jdk ...
- vue项目ide(vue项目环境搭建)
一.先介绍一下我接下来要做的项目 项目:ide可视化工具 技术应用: Vue2.0(js框架):https://cn.vuejs.org/ ElementUi(饿了吗ui框架基于vue的):http: ...
- Spark 集群环境搭建
思路: ①先在主机s0上安装Scala和Spark,然后复制到其它两台主机s1.s2 ②分别配置三台主机环境变量,并使用source命令使之立即生效 主机映射信息如下: 192.168.32.100 ...
- react 开发 PC 端项目(一)项目环境搭建 及 处理 IE8 兼容问题
步骤一:项目环境搭建 首先,你不应该使用 React v15 或更高版本.使用仍然支持 IE8 的 React v0.14 即可. 技术选型: 1.react@0.14 2.bootstrap3 3. ...
- Vue 项目环境搭建
Vue项目环境搭建 ''' 1) 安装node 官网下载安装包,傻瓜式安装:https://nodejs.org/zh-cn/ 2) 换源安装cnpm >: npm install -g cnp ...
随机推荐
- tomcat中配置https
HTTPS配置中分为单向连接和双向连接,单向连接只需要服务器安装证书,客户端不需要,双向连接需要服务器和客户端都安装证书: 一.Keytool命令: 1.生成密钥对: keytool -genkey ...
- uglifyjs-webpack-plugin 插件,drop_console 默认为 false(不清除 console 语句),drop_debugger 默认为 true(清除 debugger 语句)
uglifyjs-webpack-plugin 插件,drop_console 默认为 false(不清除console语句),drop_debugger 默认为 true(清除 debugger 语 ...
- react 实现路由按需加载
import() 方法: async.js 文件内容: import React from 'react'; // import "babel-polyfill"; //compo ...
- postman测试post请求参数为json类型
1. 设置Headers Content-Type类型为application/json 2.Body 设置如下.请求的数据类型为Json格式
- C/C++中带可变参数的函数
1.带可变参数的函数由来 当函数中的参数个数不确定时,这时候就需要带可变参数的函数! 如我们经常使用的C库函数printf()实际就是一个可变参数的函数, 其原型为: int printf( cons ...
- Linux重定向及nohup不输出的方法
转载自:http://blog.csdn.net/qinglu000/article/details/18963031 先说一下linux重定向: 0.1和2分别表示标准输入.标准输出和标准错误信 ...
- git 仓库相关命令
git配置文件 : .git/config 配置存储远程连接用户信息 [credential] helper = store 配置www用户下默认git pull账号和密码,这样每一个新加的项目都不用 ...
- linux 简单笔记
Linux查看端口使用状态.关闭端口方法 http://blog.csdn.net/wudiyi815/article/details/7473097
- pytest.7.常见套路
From: http://www.testclass.net/pytest/common_useage/ 在使用pytest的时候,下面这些问题我们可能会经常遇到,这里给出官方的解决方案,按照套路来执 ...
- hadoop-n.x.y.tar.gz、hadoop-n.x.y.tar.gz.asc 、hadoop-n.x.y.tar.gz.md5 、hadoop-n.x.y.tar.gz.mds分别是什么?
不多说,直接上干货! 我这里,以hadoop-2.6.0为例. hadoop-n.x.y.tar.gz.mds,此mds文件是为了检验在下载和移动文件过程中文件的完整性. 通过验证文件的md5值去检验 ...