python爬虫实践教学
一、前言
这篇文章之前是给新人培训时用的,大家觉的挺好理解的,所以就分享出来,与大家一起学习。如果你学过一些python,想用它做些什么又没有方向,不妨试试完成下面几个案例。
二、环境准备
安装requests lxml beautifulsoup4 三个库(下面代码均在python3.5环境下通过测试)
pip install requests lxml beautifulsoup4
三、几个爬虫小案例
- 获取本机公网IP地址
- 利用百度搜索接口,编写url采集器
- 自动下载搜狗壁纸
- 自动填写调查问卷
- 获取公网代理IP,并判断是否能用、延迟
3.1 获取本机公网IP地址
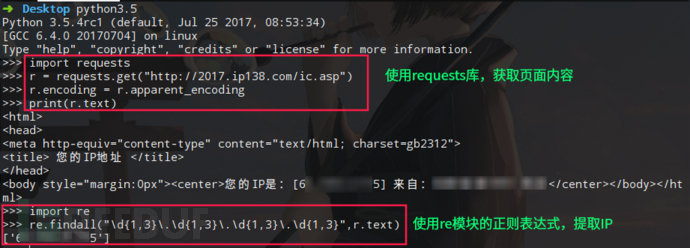
利用公网上查询IP的借口,使用python的requests库,自动获取IP地址。
import requests
r = requests.get("http://2017.ip138.com/ic.asp")
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}",r.text))
3.2 利用百度搜索接口,编写url采集器
这个案例中,我们要使用requests结合BeautifulSoup库来完成任务。我们要在程序中设置User-Agent头,绕过百度搜索引擎的反爬虫机制(你可以试试不加User-Agent头,看看能不能获取到数据)。注意观察百度搜索结构的URL链接规律,例如第一页的url链接参数pn=0,第二页的url链接参数pn=10…. 依次类推。这里,我们使用css选择器路径提取数据。
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,10):
bd_search = "https://www.baidu.com/s?wd=inurl:/dede/login.php?&pn=%s" % str(i)
r = requests.get(bd_search,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 下面的select使用了css选择器路径提取数据
url_list = soup.select(".t > a")
for url in url_list:
real_url = url["href"]
r = requests.get(real_url)
print(r.url)
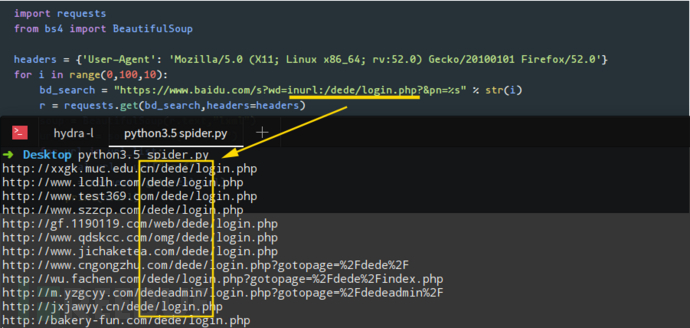
编写好程序后,我们使用关键词inurl:/dede/login.php 来批量提取织梦cms的后台地址,效果如下:
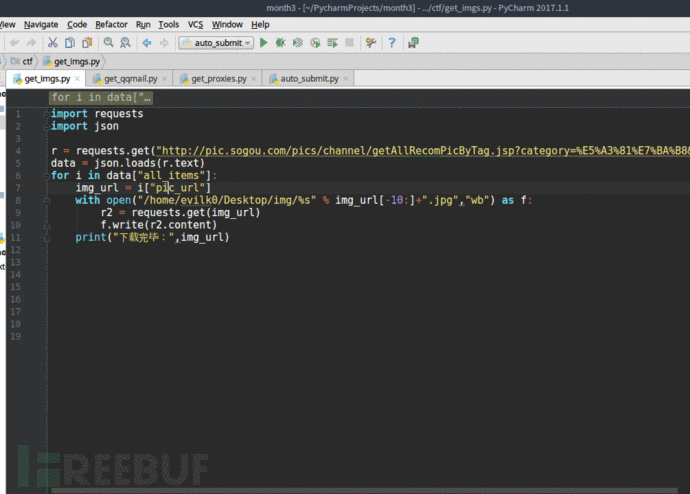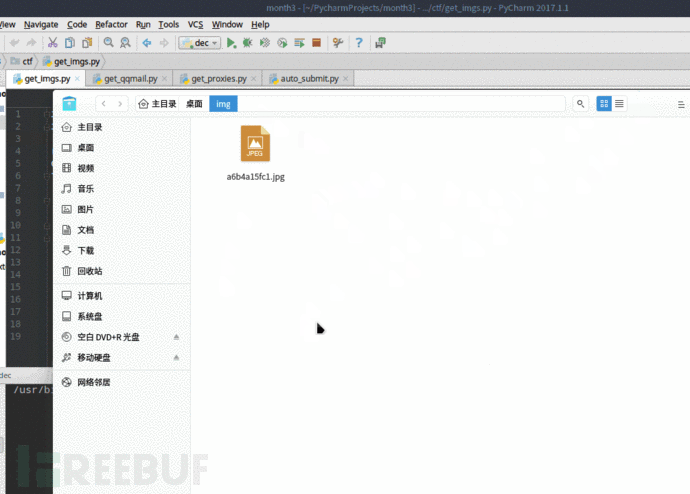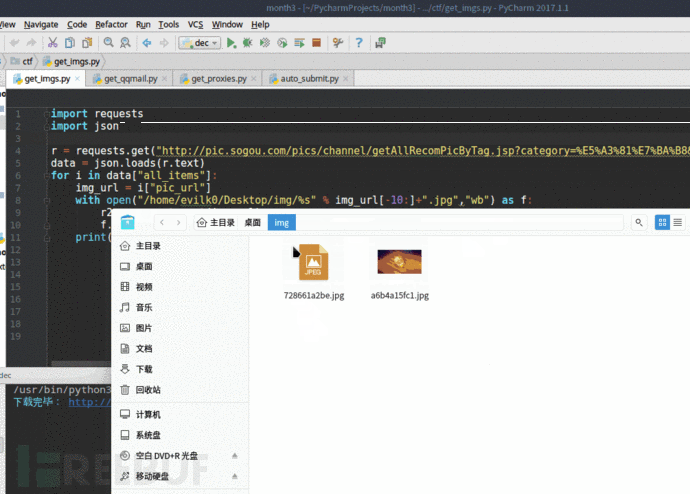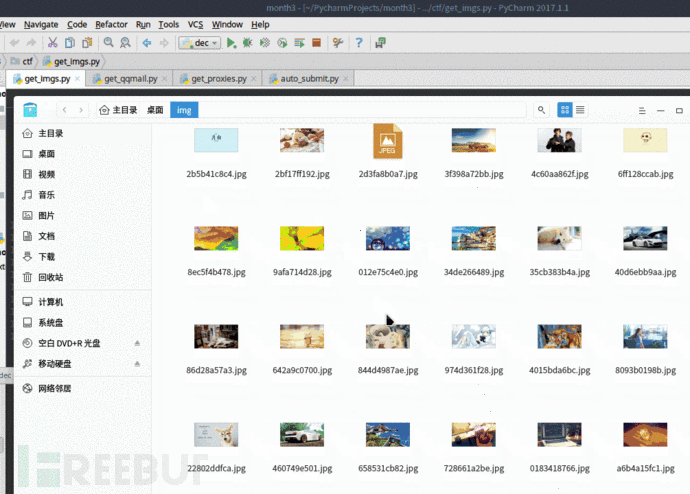
3.3 自动下载搜狗壁纸
这个例子,我们将通过爬虫来自动下载搜过壁纸,程序中存放图片的路径改成你自己想要存放图片的目录路径即可。还有一点,程序中我们用到了json库,这是因为在观察中,发现搜狗壁纸的地址是以json格式存放,所以我们以json来解析这组数据。
import requests
import json
#下载图片
url = "http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category=%E5%A3%81%E7%BA%B8&tag=%E6%B8%B8%E6%88%8F&start=0&len=15&width=1366&height=768"
r = requests.get(url)
data = json.loads(r.text)
for i in data["all_items"]:
img_url = i["pic_url"]
# 下面这行里面的路径改成你自己想要存放图片的目录路径即可
with open("/home/evilk0/Desktop/img/%s" % img_url[-10:]+".jpg","wb") as f:
r2 = requests.get(img_url)
f.write(r2.content)
print("下载完毕:",img_url)
3.4 自动填写调查问卷
目标官网:https://www.wjx.cn
目标问卷:https://www.wjx.cn/jq/21581199.aspx
import requests
import random url = "https://www.wjx.cn/joinnew/processjq.ashx?submittype=1&curID=21581199&t=1521463484600&starttime=2018%2F3%2F19%2020%3A44%3A30&rn=990598061.78751211"
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
} for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
r = requests.post(url = url,headers=header,data=data)
print(r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
当我们使用同一个IP提交多个问卷时,会触发目标的反爬虫机制,服务器会出现验证码。
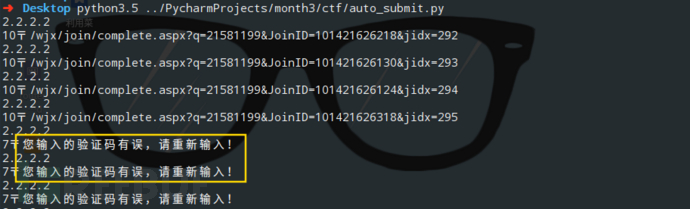
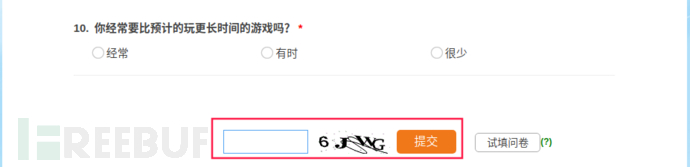
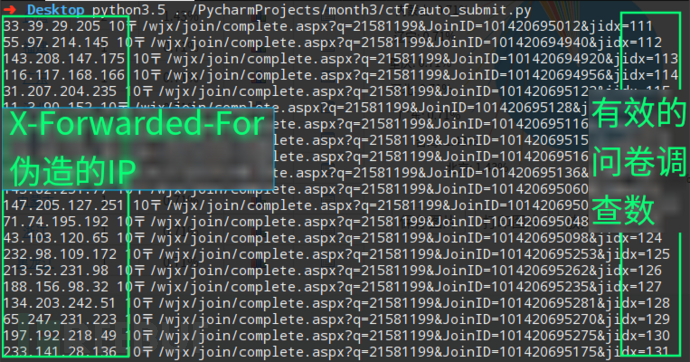
我们可以使用X-Forwarded-For来伪造我们的IP,修改后代码如下:
import requests
import random url = "https://www.wjx.cn/joinnew/processjq.ashx?submittype=1&curID=21581199&t=1521463484600&starttime=2018%2F3%2F19%2020%3A44%3A30&rn=990598061.78751211"
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
"X-Forwarded-For" : "%s"
} for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
header["X-Forwarded-For"] = (str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+str(random.randint(1,255))
r = requests.post(url = url,headers=header,data=data)
print(header["X-Forwarded-For"],r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
header["X-Forwarded-For"] = "%s"
效果图:
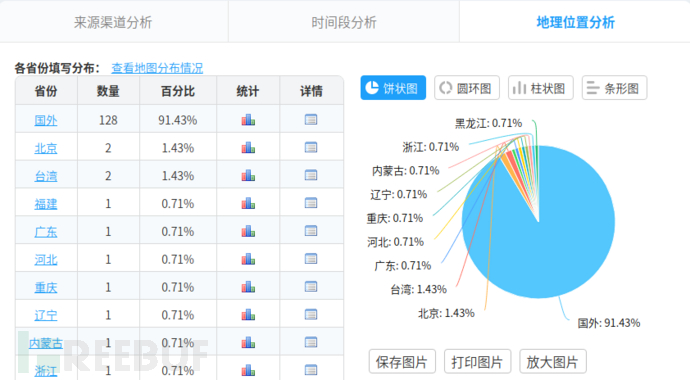
关于这篇文章,因为之前写过,不赘述,感兴趣直接看:【如何通过Python实现自动填写调查问卷】
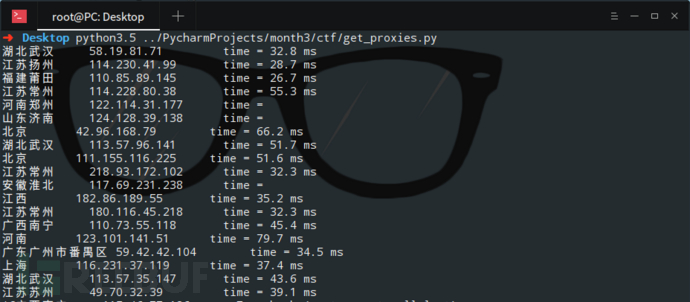
3.5 获取公网代理IP,并判断是否能用、延迟时间
这一个例子中,我们想爬取【西刺代理】上的代理IP,并验证这些代理的存活性以及延迟时间。(你可以将爬取的代理IP添加进proxychain中,然后进行平常的渗透任务。)这里,我直接调用了linux的系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - ,如果你想在Windows中运行这个程序,需要修改倒数第三行os.popen中的命令,改成Windows可以执行的即可。
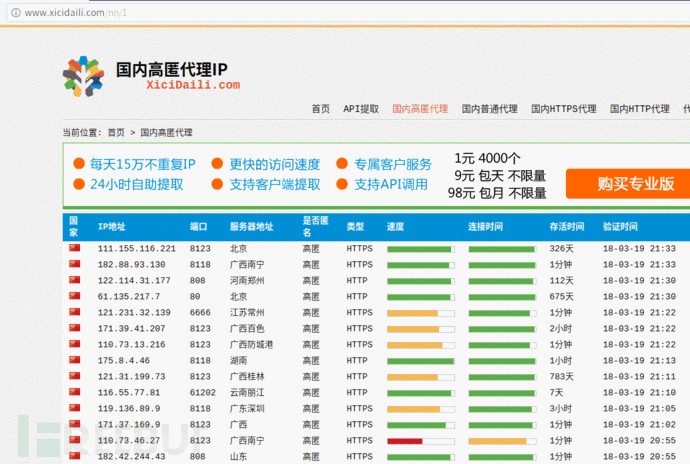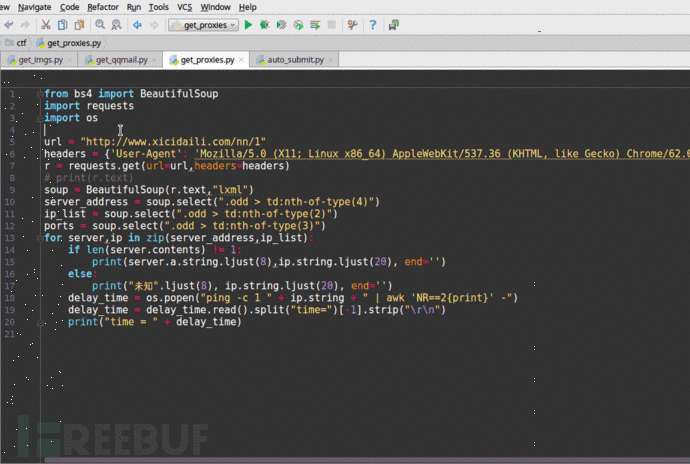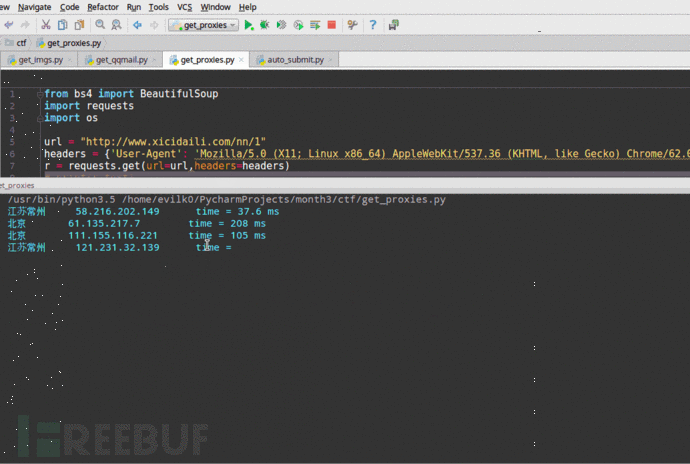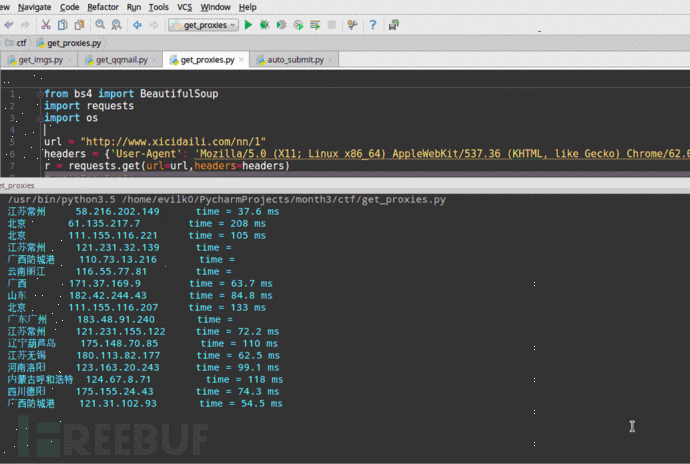
from bs4 import BeautifulSoup
import requests
import os url = "http://www.xicidaili.com/nn/1"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
server_address = soup.select(".odd > td:nth-of-type(4)")
ip_list = soup.select(".odd > td:nth-of-type(2)")
ports = soup.select(".odd > td:nth-of-type(3)")
for server,ip in zip(server_address,ip_list):
if len(server.contents) != 1:
print(server.a.string.ljust(8),ip.string.ljust(20), end='')
else:
print("未知".ljust(8), ip.string.ljust(20), end='')
delay_time = os.popen("ping -c 1 " + ip.string + " | awk 'NR==2{print}' -")
delay_time = delay_time.read().split("time=")[-1].strip("\r\n")
print("time = " + delay_time)
四、结语
当然,你还可以用python干很多有趣的事情。如果上面的这些例子你看的不是很懂,那我最后在送上一套python爬虫视频教程:【Python网络爬虫与信息提取】。现在网络上的学习真的很多,希望大家能够好好利用。
有问题大家可以留言哦,也欢迎大家到春秋论坛中来耍一耍 >>>点击跳转
python爬虫实践教学的更多相关文章
- python爬虫实践
模拟登陆与文件下载 爬取http://moodle.tipdm.com上面的视频并下载 模拟登陆 由于泰迪杯网站问题,测试之后发现无法用正常的账号密码登陆,这里会使用访客账号登陆. 我们先打开泰迪杯的 ...
- Python爬虫实践 -- 记录我的第二只爬虫
1.爬虫基本原理 我们爬取中国电影最受欢迎的影片<红海行动>的相关信息.其实,爬虫获取网页信息和人工获取信息,原理基本是一致的. 人工操作步骤: 1. 获取电影信息的页面 2. 定位(找到 ...
- python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记. 第 ...
- python爬虫实践(一)
最近在学习爬虫,学完后想实践一下,所以现在准备爬取校花网的一部分图片 第一步,导入需要的库 from urllib import request #用于处理request请求和获得响应 from ur ...
- Python爬虫+可视化教学:爬取分析宠物猫咪交易数据
前言 各位,七夕快到了,想好要送什么礼物了吗? 昨天有朋友私信我,问我能用Python分析下网上小猫咪的数据,是想要送一只给女朋友,当做礼物. Python从零基础入门到实战系统教程.源码.视频 网上 ...
- Python爬虫实践 -- 记录我的第一只爬虫
一.环境配置 1. 下载安装 python3 .(或者安装 Anaconda) 2. 安装requests和lxml 进入到 pip 目录,CMD --> C:\Python\Scripts,输 ...
- 《转载》python爬虫实践之模拟登录
有些网站设置了权限,只有在登录了之后才能爬取网站的内容,如何模拟登录,目前的方法主要是利用浏览器cookie模拟登录. 浏览器访问服务器的过程 在用户访问网页时,不论是通过URL输入域名或IP ...
- python爬虫实践--求职Top10城市
前言 从智联招聘爬取相关信息后,我们关心的是如何对内容进行分析,获取用用的信息.本次以上篇文章“5分钟掌握智联招聘网站爬取并保存到MongoDB数据库”中爬取的数据为基础,分析关键词为“python” ...
- Python爬虫实践~BeautifulSoup+urllib+Flask实现静态网页的爬取
爬取的网站类型: 论坛类网站类型 涉及主要的第三方模块: BeautifulSoup:解析.遍历页面 urllib:处理URL请求 Flask:简易的WEB框架 介绍: 本次主要使用urllib获取网 ...
随机推荐
- Selenium+python入门
在 WebDriver 中, 将这些关于鼠标操作的方法封装在 ActionChains 类提供 ActionChains 类提供了鼠标操作的常用方法: perform(): 执行所有 ActionCh ...
- C++程序生成.exe文件,在文件夹中运行时闪现问题
问题描述:在IDE(此为Dev-C++)中编写C++程序,运行时会产生如下文字 但我想取消这三行的显示. 解决方法:1:在IDE中运行时,“请按任意键继续”是消失不掉的,但在该程序的保存路径下可以消灭 ...
- Windows下用curl命令
一开始自己是下载curl的可执行文件来弄的,发现中文会乱码: 按照网上的用chcp 65001后中文还是乱码,蒙逼中. 后来直接用git bash执行curl,发现git bash自带了这个命令:(可 ...
- 空指针、NULL指针、零指针
1. 空指针.NULL指针.零指针 1.1 什么是空指针常量 0.0L.'\0'.3 - 3.0 * 17 (它们都是“integer constant expression”)以及 (void*)0 ...
- Windows窗口消息大全
////////////////////////////////////////////////////////////////////////// #include "AFXPRIV.H& ...
- java代码执行顺序
class HelloA { public HelloA() { System.out.println("HelloA"); } { System.out.println(&quo ...
- spring配置Bean
Bean 就是一个类 一下代码都是基于spring之IOC和DI实现案例基础上进行解析 Bean的实例化方式: 1.无参构造 <bean id="UserService" ...
- bash获得脚本当前路径
#!/bin/bashCMD_PATH=`dirname $0`echo "current cmd path:$CMD_PATH"cd $CMD_PATHecho $PWDecho ...
- java基础-day18
第07天 集合 今日内容介绍 u HashSet集合 u HashMap集合 第1章 HashSet集合 1.1 Set接口的特点 Set体系的集合: A:存入集合的顺序和取出集合的顺序不一 ...
- Naive Bayes 笔记
Naive Bayes (朴素贝叶斯) 属于监督学习算法, 它通过计算测试样本在训练样本各个分类中的概率来确定测试样本所属分类, 取最大概率为其所属分类. 优点 在数据较少的情况下仍然有效,可以处 ...