MyCat分库分表入门
1、分区
对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm。
根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后的表呢,还是一张表。分区可以把表分到不同的硬盘上,但不能分配到不同服务器上。
- 优点:数据不存在多个副本,不必进行数据复制,性能更高。
- 缺点:分区策略必须经过充分考虑,避免多个分区之间的数据存在关联关系,每个分区都是单点,如果某个分区宕机,就会影响到系统的使用。
2、分片
对业务透明,在物理实现上分成多个服务器,不同的分片在不同服务器上。如HDFS。
3、分表
同库分表:所有的分表都在一个数据库中,由于数据库中表名不能重复,因此需要把数据表名起成不同的名字。
- 优点:由于都在一个数据库中,公共表,不必进行复制,处理更简单。
- 缺点:由于还在一个数据库中,CPU、内存、文件IO、网络IO等瓶颈还是无法解决,只能降低单表中的数据记录数。表名不一致,会导后续的处理复杂(参照mysql meage存储引擎来处理)
不同库分表:由于分表在不同的数据库中,这个时候就可以使用同样的表名。
- 优点:CPU、内存、文件IO、网络IO等瓶颈可以得到有效解决,表名相同,处理起来相对简单。
- 缺点:公共表由于在所有的分表都要使用,因此要进行复制、同步。一些聚合的操作,join,group by,order等难以顺利进行。
4、分库
分表和分区都是基于同一个数据库里的数据分离技巧,对数据库性能有一定提升,但是随着业务数据量的增加,原来所有的数据都是在一个数据库上的,网络IO及文件IO都集中在一个数据库上的,因此CPU、内存、文件IO、网络IO都可能会成为系统瓶颈。
当业务系统的数据容量接近或超过单台服务器的容量、QPS/TPS接近或超过单个数据库实例的处理极限等。此时,往往是采用垂直和水平结合的数据拆分方法,把数据服务和数据存储分布到多台数据库服务器上。
分库只是一个通俗说法,更标准名称是数据分片,采用类似分布式数据库理论指导的方法实现,对应用程序达到数据服务的全透明和数据存储的全透明
5、MyCat入门
用于数据库分表分库,读写分离的中间件。从http://www.mycat.io/下载即可。
MyCat作为数据库中间件与代码是弱关联的,连接方式和普通数据库一样,如:jdbc:mysql://192.168.0.2:8066/
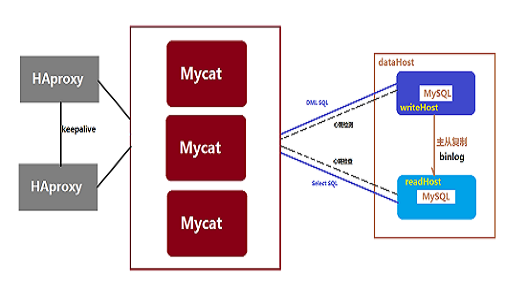
Mycat的配置文件都在conf目录里面,这里介绍几个常用的文件:
| 文件 | 说明 |
|---|---|
| server.xml | Mycat的配置文件,设置账号、参数等 |
| schema.xml | Mycat对应的物理数据库和数据库表的配置 |
| rule.xml | Mycat分片(分库分表)规则 |
server.xml:Mycat的配置文件,设置账号、参数等。
<user name="test">
<property name="password">test</property>
<property name="schemas">lunch</property>
<property name="readOnly">false</property> <!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
| user | 用户配置节点 |
| --name | 登录的用户名,也就是连接Mycat的用户名 |
| --password | 登录的密码,也就是连接Mycat的密码 |
| --schemas | 数据库名,这里会和schema.xml中的配置关联,多个用逗号分开,例如需要这个用户需要管理两个数据库db1,db2,则配置db1,dbs |
| --privileges | 配置用户针对表的增删改查的权限,具体见文档 |
schema.xml:Mycat对应的物理数据库和数据库表的配置。
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 数据库配置,与server.xml中的数据库对应 -->
<schema name="lunch" checkSQLschema="false" sqlMaxLimit="100">
<table name="lunchmenu" dataNode="dn1" />
<table name="restaurant" dataNode="dn1" />
<table name="userlunch" dataNode="dn1" />
<table name="users" dataNode="dn1" />
<!-- 分库写表 -->
<table name="dictionary" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long" />
</schema> <!-- 分片配置 -->
<dataNode name="dn1" dataHost="test1" database="lunch" />
<dataNode name="dn2" dataHost="test2" database="lunch" /> <!-- 物理数据库配置 -->
<dataHost name="test1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostM1" url="192.168.0.2:3306" user="root" password="123456">
</writeHost>
</dataHost> <dataHost name="test2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostS1" url="192.168.0.3:3306" user="root" password="123456">
</writeHost>
</dataHost> </mycat:schema>
| 参数 | 说明 |
|---|---|
| schema | 数据库设置,此数据库为逻辑数据库,name与server.xml中schema对应 |
| dataNode | 分片信息,也就是分库相关配置 |
| dataHost | 物理数据库,真正存储数据的数据库 |
| 属性 | 说明 |
|---|---|
| name | 逻辑数据库名,与server.xml中的schema对应 |
| checkSQLschema | 数据库前缀相关设置,建议看文档,这里暂时设为folse |
| sqlMaxLimit | select 时默认的limit,避免查询全表 |
| 属性 | 说明 |
|---|---|
| name | 表名,物理数据库中表名 |
| dataNode | 表存储到哪些节点,多个节点用逗号分隔。节点为下文dataNode设置的name |
| primaryKey | 主键字段名,自动生成主键时需要设置 |
| autoIncrement | 是否自增 |
| rule | 分片规则名,具体规则下文rule详细介绍 |
| 属性 | 说明 |
|---|---|
| name | 节点名,与table中dataNode对应 |
| datahost | 物理数据库名,与datahost中name对应 |
| database | 物理数据库中数据库名 |
| 属性 | 说明 |
|---|---|
| name | 物理数据库名,与dataNode中dataHost对应 |
| balance | 均衡负载的方式 |
| writeType | 写入方式 |
| dbType | 数据库类型 |
| heartbeat | 心跳检测语句,注意语句结尾的分号要加。 |
rule.xml:Mycat分片(分库分表)规则。
分表分库案例:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 数据库配置,与server.xml中的数据库对应 -->
<schema name="lunch" checkSQLschema="false" sqlMaxLimit="100">
<table name="lunchmenu" dataNode="dn1" />
<table name="restaurant" dataNode="dn1" />
<table name="userlunch" dataNode="dn1" />
<table name="users" dataNode="dn1" />
<table name="dictionary" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long" />
</schema> <!-- 分片配置 -->
<dataNode name="dn1" dataHost="test1" database="lunch" />
<dataNode name="dn2" dataHost="test2" database="lunch" /> <!-- 物理数据库配置 -->
<dataHost name="test1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostM1" url="192.168.0.2:3306" user="root" password="123456">
</writeHost>
</dataHost> <dataHost name="test2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostS1" url="192.168.0.3:3306" user="root" password="123456">
</writeHost>
</dataHost> </mycat:schema>
PS: lunchmenu、restaurant、userlunch、users这些表都只写入节点dn1,也就是192.168.0.2这个服务,而dictionary写入了dn1、dn2两个节点,也就是192.168.0.2、192.168.0.3这两台服务器。
读写分离案例:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 数据库配置,与server.xml中的数据库对应 -->
<schema name="lunch" checkSQLschema="false" sqlMaxLimit="100">
<table name="lunchmenu" dataNode="dn1" />
<table name="restaurant" dataNode="dn1" />
<table name="userlunch" dataNode="dn1" />
<table name="users" dataNode="dn1" />
<table name="dictionary" primaryKey="id" autoIncrement="true" dataNode="dn1" />
</schema> <!-- 分片配置 -->
<dataNode name="dn1" dataHost="test1" database="lunch" /> <!-- 物理数据库配置 -->
<dataHost name="test1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostM1" url="192.168.0.2:3306" user="root" password="123456">
<readHost host="hostS1" url="192.168.0.3:3306" user="root" password="123456"></readHost>
</writeHost>
</dataHost> </mycat:schema> ps:MyCat没有实现主从复制,需要使用数据库本身自带的这个功能来实现。
6、MyCat使用
##启动
mycat start ##停止
mycat stop ##重启
mycat restart
开发注意事项
1、非分片字段查询,整库查询导致性能极差
Mycat中的路由结果是通过分片字段和分片方法来确定的。例如下图中的一个Mycat分库方案:
- 根据 tt_waybill 表的 id 字段来进行分片
- 分片方法为 id 值取 3 的模,根据模值确定在DB1,DB2,DB3中的某个分片

如果查询条件中有 id 字段的情况还好,查询将会落到某个具体的分片。例如:
MySQL>select * from tt_waybill where id = 12330;
此时Mycat会计算路由结果
12330 % 3 = 0 –> DB1
并将该请求路由到DB1上去执行。
如果查询条件中没有 分片字段 条件,例如:
mysql>select * from tt_waybill where waybill_no =88661;
此时Mycat无法计算路由,便发送到所有节点上执行:
DB1 –> select * from tt_waybill where waybill_no =88661;
DB2 –> select * from tt_waybill where waybill_no =88661;
DB3 –> select * from tt_waybill where waybill_no =88661;
如果该分片字段选择度高,也是业务常用的查询维度,一般只有一个或极少数个DB节点命中(返回结果集)。示例中只有3个DB节点,而实际应用中的DB节点数远超过这个,假如有50个,那么前端的一个查询,落到MySQL数据库上则变成50个查询,会极大消耗Mycat和MySQL数据库资源。
如果设计使用Mycat时有非分片字段查询,请考虑放弃!
2、分页,没有排序的情况下统一sql执行结果随机选择不同库的查询结果
先看一下Mycat是如何处理分页操作的,假如有如下Mycat分库方案:
一张表有30份数据分布在3个分片DB上,具体数据分布如下
DB1:[0,1,2,3,4,10,11,12,13,14]
DB2:[5,6,7,8,9,16,17,18,19]
DB3:[20,21,22,23,24,25,26,27,28,29]
(这个示例的场景中没有查询条件,所以都是全分片查询,也就没有假定该表的分片字段和分片方法)

当应用执行如下分页查询时
mysql>select * from table limit 2;
Mycat将该SQL请求分发到各个DB节点去执行,并接收各个DB节点的返回结果
DB1: [0,1]
DB2: [5,6]
DB3: [20,21]
但Mycat向应用返回的结果集取决于哪个DB节点最先返回结果给Mycat。如果Mycat最先收到DB1节点的结果集,那么Mycat返回给应用端的结果集为 [0,1],如果Mycat最先收到DB2节点的结果集,那么返回给应用端的结果集为 [5,6]。也就是说,相同情况下,同一个SQL,在Mycat上执行时会有不同的返回结果。
在Mycat中执行分页操作时必须显示加上排序条件才能保证结果的正确性,下面看一下Mycat对排序分页的处理逻辑。
假如在前面的分页查询中加上了排序条件(假如表数据的列名为id)
mysql>select * from table order by id limit 2;
Mycat的处理逻辑如下图:

在有排序呢条件的情况下,Mycat接收到各个DB节点的返回结果后,对其进行最小堆运算,计算出所有结果集中最小的两条记录 [0,1] 返回给应用。
但是,当排序分页中有 偏移量 (offset)时,处理逻辑又有不同。假如应用的查询SQL如下:
mysql>select * from table order by id limit 5,2;
如果按照上述排序分页逻辑来处理,那么处理结果如下图:

Mycat将各个DB节点返回的数据 [10,11], [16,17], [20,21] 经过最小堆计算后返回给应用的结果集是 [10,11]。可是,对于应用而言,该表的所有数据明明是 0-29 这30个数据的集合,limit 5,2 操作返回的结果集应该是 [5,6],如果返回 [10,11] 则是错误的处理逻辑。
所以Mycat在处理 有偏移量的排序分页 时是另外一套逻辑——改写SQL 。如下图:

Mycat在下发有 limit m,n 的SQL语句时会对其进行改写,改写成 limit 0, m+n 来保证查询结果的逻辑正确性。所以,Mycat发送到后端DB上的SQL语句是
mysql>select * from table order by id limit 0,7;
各个DB返回给Mycat的结果集是
DB1: [0,1,2,3,4,10,11]
DB2: [5,6,7,8,9,16,17]
DB3: [20,21,22,23,24,25,26]
经过最小堆计算后得到最小序列 [0,1,2,3,4,5,6] ,然后返回偏移量为5的两个结果为 [5,6] 。
虽然Mycat返回了正确的结果,但是仔细推敲发现这类操作的处理逻辑是及其消耗(浪费)资源的。应用需要的结果集为2条,Mycat中需要处理的结果数为21条。也就是说,对于有 t 个DB节点的全分片 limit m, n 操作,Mycat需要处理的数据量为 (m+n)*t 个。比如实际应用中有50个DB节点,要执行limit 1000,10操作,则Mycat处理的数据量为 50500 条,返回结果集为10,当偏移量更大时,内存和CPU资源的消耗则是数十倍增加。
如果设计使用Mycat时有分页排序,请考虑放弃!
3、任意表JOIN,关联字段不在同一个库导致查询失败
先看一下在单库中JOIN中的场景。假设在某单库中有 player 和 team 两张表,player 表中的 team_id 字段与 team 表中的 id 字段相关联。操作场景如下图:

JOIN操作的SQL如下
mysql>select p_name,t_name from player p, team t where p.no = 3 and p.team_id = t.id;
此时能查询出结果
| p_name | t_name |
|---|---|
| Wade | Heat |
如果将这两个表的数据分库后,相关联的数据可能分布在不同的DB节点上,如下图:

这个SQL在各个单独的分片DB中都查不出结果,也就是说Mycat不能查询出正确的结果集。
设计使用Mycat时如果要进行表JOIN操作,要确保两个表的关联字段具有相同的数据分布,否则请考虑放弃!
4、分布式事务
Mycat并没有根据二阶段提交协议实现 XA事务,而是只保证 prepare 阶段数据一致性的 弱XA事务 ,实现过程如下:
应用开启事务后Mycat标识该连接为非自动提交,比如前端执行
mysql>begin;
Mycat不会立即把命令发送到DB节点上,等后续下发SQL时,Mycat从连接池获取非自动提交的连接去执行。

Mycat会等待各个节点的返回结果,如果都执行成功,Mycat给该连接标识为 Prepare Ready 状态,如果有一个节点执行失败,则标识为 Rollback 状态。

执行完成后Mycat等待前端发送 commit 或 rollback 命令。发送 commit 命令时,Mycat检测当前连接是否为 Prepare Ready 状态,若是,则将 commit 命令发送到各个DB节点。

但是,这一阶段是无法保证一致性的,如果一个DB节点在 commit 时故障,而其他DB节点 commit 成功,Mycat会一直等待故障DB节点返回结果。Mycat只有收到所有DB节点的成功执行结果才会向前端返回 执行成功 的包,此时Mycat只能一直 waiting 直至TIMEOUT,导致事务一致性被破坏。
设计使用Mycat时如果有分布式事务,得先看是否得保证事务得强一致性,否则请考虑放弃!
MyCat分库分表入门的更多相关文章
- MySQL+MyCat分库分表 读写分离配置
一. MySQL+MyCat分库分表 1 MyCat简介 java编写的数据库中间件 Mycat运行环境需要JDK. Mycat是中间件.运行在代码应用和MySQL数据库之间的应用. 前身 : cor ...
- 《MyCat分库分表策略详解》
在我们的项目发展到一定阶段之后,随着数据量的增大,分库分表就变成了一件非常自然的事情.常见的分库分表方式有两种:客户端模式和服务器模式,这两种的典型代表有sharding-jdbc和MyCat.所谓的 ...
- MyCat | 分库分表实践
引言 先给大家介绍2个概念:数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式. 切分模式 一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之 ...
- mycat 分库分表
单库分表已经在上篇写过了,这次写个分库分表,不同在于配置文件上的一点点不同 <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> &l ...
- 3.Mysql集群------Mycat分库分表
前言: 分库分表,在本节里是水平切分,就是多个数据库里包含的表是一模一样的. 只是把字段散列的分到不同的库中. 实践: 1.修改schema.xml 这里是在同一台服务器上建立了4个数据库db1,db ...
- 分布式数据库中间件 MyCat | 分库分表实践
MyCat 简介 MyCat 是一个功能强大的分布式数据库中间件,是一个实现了 MySQL 协议的 Server,前端人员可以把它看做是一个数据库代理中间件,用 MySQL 客户端工具和命令行访问:而 ...
- Mycat分库分表(一)
随着业务变得越来越复杂,用户越来越多,集中式的架构性能会出现巨大的问题,比如系统会越来越慢,而且时不时会宕机,所以必须要解决高性能和可用性的问题.这个时候数据库的优化就显得尤为重要,在说优化方案前,先 ...
- mycat分库分表 看这一篇就够了
之前我们已经讲解过了数据的切分,主要有两种方式,分别是垂直切分和水平切分,所谓的垂直切分就是将不同的表分布在不同的数据库实例中,而水平切分指的是将一张表的数据按照不同的切分规则切分在不同实例的相同 ...
- 【分库分表】sharding-jdbc实践—分库分表入门
一.准备工作 1.准备三个数据库:db0.db1.db2 2.每个数据库新建两个订单表:t_order_0.t_order_1 DROP TABLE IF EXISTS `t_order_x`; CR ...
随机推荐
- PAT甲题题解-1117. Eddington Number(25)-(大么个大水题~)
如题,大水题...贴个代码完事,就这么任性~~ #include <iostream> #include <cstdio> #include <algorithm> ...
- 2-Thirteenth Scrum Meeting-10151213
任务安排 成员 今日完成 明日任务 闫昊 获取视频播放进度 用本地数据库记录课程结构和学习进度 唐彬 阅读IOS代码+阅读上届网络核心代码 请假(编译……) 史烨轩 下载service开发 ...
- 《口算大作战 2》DLC:算法真奇妙
211614331 王诚荣 211614354 陈斌 --第一次结对作业 DLC DLC:三年级混合运算模块现已更新!现在您可以愉快的使用三年级题库啦.同时您必须拥有本体才能使用此DLC 单击此处查看 ...
- 第二个Spring冲刺周期团队进展报告
第一天:找识别不了的原因 第二天:继续找识别不了的原因 第三天:找文字库,找到tessdata语言包,放到手机SD卡根目录 第四天:了解OCR引擎 第五天:将导入tess-two导入到项目中,并进行测 ...
- javascript 函数的几种声明函数以及应用环境
本页只列出常用的几种方式,当然还有比如new Function()以及下面三种的组合. 1.函数式声明 例子:function sum(a,b){ return a+b; }; 2.函数表达式声明(匿 ...
- PAT 甲级 1115 Counting Nodes in a BST
https://pintia.cn/problem-sets/994805342720868352/problems/994805355987451904 A Binary Search Tree ( ...
- 【BOM】浏览器对象模型
1.navigator :保存浏览器配置信息的对象 常用 navigator.plugins: 显示浏览器中所有插件信息的集合 navigator.cookieEnabled: 判断是否开启cooki ...
- 前端开发【第5篇:JavaScript进阶】
语句 复合表达式和空语句 复合表达式意思是把多条表达式连接在一起形成一个表达式 { let a = 100; let b = 200; let c = a + b; } 注意这里不能再块级后面加分号, ...
- POJ 1062 昂贵的聘礼(最短路中等题)
昂贵的聘礼 Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 51879 Accepted: 15584 Descripti ...
- SSH & Git
SSH基本用法 SSH服务详解 work with git branch some tips for git setup and git config git and github ssh servi ...