Python之入门篇1
一、安装python解释器
官网: https://www.python.org/downloads/windows/
自行下载安装,添加环境变量
#测试安装是否成功
windows --> 运行 --> 输入cmd ,然后回车,弹出cmd程序,输入python,如果能进入交互环境 ,代表安装成功。
#多版本共存演示
注意:在安装目录下找到python.exe,拷贝一份,命名为python2.exe或python3.exe,一定要保留原版,因为pip工具会调用它。
二、变量的定义
1)例如
#变量名(相当于门牌号,指向值所在的空间),等号,变量值
name='Egon'
sex='male'
age=18
level=10
2)定义的规范
#1. 变量名只能是 字母、数字或下划线的任意组合
#2. 变量名的第一个字符不能是数字
#3 变量名为中文,拼音,变量名不宜过长,变量名词不达意
#4. 关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del',
'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import',
'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
3)定义的方式
#驼峰体
AgeOfOldboy = 56
NumberOfStudents = 80
#下划线(推荐使用)
age_of_oldboy = 56
number_of_students = 80
4)定义变量会有:id,type,value
#1 等号比较的是value,
#2 is比较的是id #强调:
#1. id相同,意味着type和value必定相同
#2. value相同type肯定相同,但id可能不同,如下
>>> x='Info Egon:18'
>>> y='Info Egon:18'
>>> id(x)
4376607152
>>> id(y)
4376607408
>>>
>>> x == y
True
>>> x is y
False
三、如何与用户交互(input)
#在python3中
input:用户输入任何值,都存成字符串类型 #在python2中
input:用户输入什么类型,就存成什么类型
raw_input:等于python3的input
四、基本数据类型
1)数字类型,实质指的是int 和 float
#int整型
定义:age=10 #age=int(10)
用于标识:年龄,等级,身份证号,qq号,个数 #float浮点型
定义:salary=3.1 #salary=float(3.1)
用于标识:工资,身高,体重,
2)字符串
#在python中,加了引号的字符就是字符串类型,python并没有字符类型。
定义:name='egon' #name=str('egon')
用于标识:描述性的内容,如姓名,性别,国籍,种族 #那单引号、双引号、多引号有什么区别呢? 让我大声告诉你,单双引号木有任何区别,只有下面这种情况 你需要考虑单双的配合
msg = "My name is Egon , I'm 18 years old!" #多引号什么作用呢?作用就是多行字符串必须用多引号
msg = '''
今天我想写首小诗,
歌颂我的同桌,
你看他那乌黑的短发,
好像一只炸毛鸡。
'''
print(msg)
字符串拼接
#数字可以进行加减乘除等运算,字符串呢?让我大声告诉你,也能?what ?是的,但只能进行"相加"和"相乘"运算。
>>> name='egon'
>>> age=''
>>> name+age #相加其实就是简单拼接
'egon18'
>>> name*
'egonegonegonegonegon' #注意1:字符串相加的效率不高
字符串1+字符串3,并不会在字符串1的基础上加字符串2,而是申请一个全新的内存空间存入字符串1和字符串3,相当字符串1与字符串3的空间被复制了一次, #注意2:只能字符串加字符串,不能字符串加其他类型
a)字符串中优先掌握的内容
#优先掌握的操作:
#1、按索引取值(正向取+反向取) :只能取
#2、切片(顾头不顾尾,步长)
#3、长度len
#4、成员运算in和not in
#5、移除空白strip
#6、切分split
#7、循环
案例
# # 、按索引取值(正向取+反向取):只能取
# name = 'bo dy'
# print(name[]) # o
# print(name[-]) # y
# # 、切片(顾头部顾尾,步长),可生成列表
# mag = 'hello world'
# print(mag[:]) # hell
# print(mag[::]) # hl
# # 、长度len
# mag = 'hello'
# print(len(mag))
# # 、成员运算 in 和 not in 判断正误
# mag = 'zhangsan lisi wangmazi'
# print('lisi' in mag) # True
# # 、移除空白strip。。移除左右两边的空白字符
# name = '*******user*****'
# print(name.strip('*')) # 删除左右两边的*,剩下的是user
# msg = '** * /user is sb */*** *'
# print(msg.strip('* /'))
# #======小例子========
# while True:
# # cmd = input('cmd>>:')
# # cmd = cmd.strip()
# cmd = input('cmd>>:').strip()
# if len(cmd) == :continue
# if cmd == 'q':break
# print('%s is running' %cmd)
# 、切分 split
# info = 'root:x:0:0::/root:/bin/bash'
# res = info.split(':')
# print(res[])
# 、循环
cmd = 'wera'
for i in cmd:
print(i)
案例
b)需要掌握的操作
# 1、strip , lstrip , rstrip
# 2、lower, upper
# 3、startswith, endwith 判断字符串开头和结尾的
# 4、format的三种用法
# 5、split, rsplit
# 6、join,只能连接包含元素全部为字符串类型的列表
# 7、replace
# 8、isdigit 判断字符串是否是纯数字
# 9、istitle 判断首字母是不是大写
# 、strip , lstrip , rstrip
print('****user****'.lstrip('*')) # user****
print('****user****'.rstrip('*')) # ****user
# 、lower, upper
msg = 'AvcEd'
print(msg.lower()) # avced
print(msg.upper()) # AVCED
# 、startswith, endwith 判断字符串开头和结尾的
msg = 'who is sb' # True
print(msg.startswith('who'))
print(msg.endswith('sb'))
# 、format的三种用法
print('my name is {x} my age is {y}'.format(y=,x='nb'))
print('my name is {name} my age is {age}'.format(age=,name='nb'))
print('my name is {1} my age is {0} {1} {0}'.format('nb',))
# 、split, rsplit
info = 'root:x:0:0::/root:/bin/bash'
print(info.split(':',)) # ['root', 'x:0:0::/root:/bin/bash']
print(info.rsplit(':',)) # ['root:x:0:0::/root', '/bin/bash']
# 、join,只能连接包含元素全部为字符串类型的列表
info = 'root:x:0:0::/root:/bin/bash'
str_to_list = info.split(':')
print(str_to_list) # ['root', 'x', '', '', '', '/root', '/bin/bash']
list_to_str=':'.join(str_to_list)
print(list_to_str)
# 、replace
msg = 'wxx say my name is wxx'
print(msg.replace('wxx','SB',))
# 、isdigit 判断字符串是否是纯数字
print(''.isdigit())
print('12sae3'.isdigit())
案例
c)其他操作(了解)
# 1、find,rfind,index,rindex,count
# 2、center,ljust,rjust,title
# 3、expandtabs
# 4、captalize,swapcase,title
# 5、is数字系列,isdigit,isnumeric,isdecimal
# 6、is 其他
# 、find,rfind,index,rindex,count
msg = 'hello mr.s hello'
print(msg.find('mr.s')) # 找的是 'mr.s' 在msg 中起始位置
print(msg.find('mr.s',,)) # 没有找到返回 -
print(msg.index('mr.s')) # 没有找到,报错,正常的情况下和find一样
print(msg.count('hello'))
# 、center,ljust,rjust,title
print('info'.center(,'='))
print('info'.ljust(,'='))
print('info'.rjust(,'='))
print('info'.zfill())
# 、expandtabs
print(r'a\tb')
print('a\tb')
print('a\tb'.expandtabs())
# 、captalize,swapcase,title
print('abc'.capitalize()) # 首字母大写
print('Ab'.swapcase()) # 字母大小写交互
print('my name is user'.title()) # 全部首字母大写
# 、is数字系列,isdigit,isnumeric,isdecimal
num1=b'' #bytes
num2=u'' #unicode,python3中无需加u就是unicode
num3='四' #中文数字
num4='Ⅳ' #罗马数字
print(num2.isdigit())
print(num2.isnumeric())
print(num2.isdecimal())
num3='肆'
print(num3.isnumeric())
# 、is 其他
print(' '.isspace()) # 判断字符串中是否有空格
print('agaga'.isalpha()) # 判断字符串中是否全部是字母
print('agaga123'.isalnum()) # 判断字符串是否由字母或数字组成
示例
d)字符串常用操作归纳
- upper() # 转换字符串中的小写字母为大写。
- title() # 返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle())。
- lower() # 转换字符串中所有大写字符为小写。
- rstrip() # 删除字符串字符串末尾的空格.
- lstrip() # 截掉字符串左边的空格或指定字符。
- max(str) # 返回字符串 str 中最大的字母。
- min(str) # 返回字符串 str 中最小的字母。
- join(seq) # 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串
3)列表
#在[]内用逗号分隔,可以存放n个任意类型的值
定义:students=['egon','alex','wupeiqi',] #students=list(['egon','alex','wupeiqi',])
用于标识:存储多个值的情况,比如一个人有多个爱好 #存放多个学生的信息:姓名,年龄,爱好
>>> students_info=[['egon',18,['play',]],['alex',18,['play','sleep']]]
>>> students_info[0][2][0] #取出第一个学生的第一个爱好
'play'
a)优先掌握的操作
#1、按索引存取值(正向存取+反向存取):即可存也可以改;超出索引就会报错
#2、切片(顾头不顾尾,步长)
#3、长度
#4、成员判断运算in和not in
#5、追加也插入
#6、删除
#从列表中取走一个元素,相当与删除,但有返回值
#7、循环
#、按索引存取值(正向存取+反向存取):即可存也可以改;超出索引就会报错
names = ['aa','bb','cc','dd']
print(names[])
print(names[-])
#、切片(顾头不顾尾,步长)
names = ['aa','bb','cc','dd']
print(names[::])
print(names[::-]) #取空了
print(names[::-])
print(names[-::-]) # 列表反转
#、长度
print(len(names))
#、成员判断运算in和not in
print('aa' in names)
print('xx' in names)
#、追加也插入
names = ['aa','bb','cc','dd']
names.append('ee')
print(names)
names.insert(,'user')
print(names)
#、删除
names = ['aa','bb','cc','dd']
del names[]
print(names)
names = ['aa','bb','cc','dd']
names.remove('bb')
print(names)
#从列表中取走一个元素,相当与删除,但有返回值
names = ['aa','bb','cc','dd']
res = names.pop() # 按照索引删除元素
print(res)
print(names)
#、循环
for name in names:
print(name)
示例
b) 熟悉练习的操作
1、反转
2、计数
3、清空
4、复制
5、查看索引
6、排序
names = ['aa','bb','cc','bb',,,,]
names.reverse() # 反转
print(names)
a = names.count('bb')
print(a)
names.clear() # 清空列表。相当于把列表的元素全部删除
print(names) names = ['aa','bb','cc','bb',,,,]
list = names.copy()
print(list)
print(names.index('cc')) names = [,,,-]
names.sort() # 列表中的元素必须是同一类型才能比较排序
print(names)
示例
列表综合练习
names = ["zhaoming","caojin","lengmengyun","xiaoyu","xiatian"]
#对应位置:
- - -
names = ["zhaoming","caojin","lengmengyun","xiaoyu","xiatian"]
del names[-] #删除
names.remove("xiatian") #删除
names.append("zhangsan") #追加
names.insert(,"lisi") #插入
names[] = "hongmao" #修改
names.pop() #默认删除最后一个 # del names[] = name.pop()
#names.pop() #默认删除最后一个
print(names) print(names[],names[],names[-])
print(names[:]) #护头不护尾,及打印位置为1和2的元素
print(names[:]) #打印,打印1,,3元素
print(names.index("caojin")) #找caojin在列表的位置
print(names.count("caojin")) #找曹进在这里面的个数 #names.clear() 清空列表
names.reverse() #反转
names.sort() #排序
print("--->",names)
names2 = [,,,]
names.extend(names2) #把别的列表内容添加进来
#del names2 #删除列表2 报错
print(names,names2)
names3 = names.copy()
print(names3)
带索引的循环列表
for i, school in enumerate(school_list):
print('%s : %s' % (i, school))
列表常用操作归纳
- list.append(obj) # 在列表末尾添加新的对象
- list.count(obj) # 统计某个元素在列表中出现的次数
- list.extend(seq) # 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
- list.index(obj) # 从列表中找出某个值第一个匹配项的索引位置
- list.insert(index, obj)# 将对象插入列表
- list.pop(obj=list[-]) # 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
- list.remove(obj) # 移除列表中某个值的第一个匹配项
- list.reverse() # 反向列表中元素
- list.sort([func])# 对原列表进行排序
- list.clear() # 清空列表
- list.copy() # 复制列表
不可变的列表(元组)tuple 类型
- len(tuple) # 计算元组元素个数。
- max(tuple) # 返回元组中元素最大值。
- min(tuple) # 返回元组中元素最小值。
- tuple(seq) # 将列表转换为元组。
4)字典的使用
info={
'name':'egon',
'hobbies':['play','sleep'],
'company_info':{
'name':'Oldboy',
'type':'education',
'emp_num':,
}
}
print(info['company_info']['name']) #取公司名
students=[
{'name':'alex','age':,'hobbies':['play','sleep']},
{'name':'egon','age':,'hobbies':['read','sleep']},
{'name':'wupeiqi','age':,'hobbies':['music','read','sleep']},
]
print(students[]['hobbies'][]) #取第二个学生的第二个爱好
a)dict优先掌握的操作
#1、按key存取值:可改可取,可存
#2、长度len
#3、成员运算in和not in,判断字典的key
#4、删除
#5、键keys(),值values(),键值对items()
#6、循环
#7、变量赋值
#、按key存取值:可改可取,可存
d = {'x':}
d['x'] =
print(d)
d['y'] =
print(d)
#、长度len
info = {'x': , 'y': }
print(len(info))
#、成员运算in和not in,判断字典的key
print('x' in info)
#、删除
info = {'x': , 'y': ,'z':}
# del info['x']
# print(info)
# print(info.popitem()) # 随机删除
print(info.pop('y'))
print(info)
print(info.pop('xxxx',None))
print(info)
#、键keys(),值values(),键值对items()
#、循环
info = {'x': , 'y': ,'z':}
for k in info:
print(k,info[k])
#、变量赋值
li = [,,]
x,y,z = li
print(x,y,z)
li2 = [,,,,,]
x,y,z,*_ = li2
print(x,y,z)
m =
n =
m,n = ,
print(m,n)
示例
b)熟悉了解的操作
info.get()
info.update()
info.fromkeys()
info.setdefault()
info = {'x': , 'y': ,'z':}
print(info['x'])
print(info.get('xxx')) # 即便key不纯在,也不报错
info.update({'x':,'f':})
print(info)
d = {}.fromkeys(['name','age','sex'],'初始值')
print(d)
print(info.setdefault('x',)) # key存在,则不改变key对应的值,返回原值
print(info)
print(info.setdefault('g',)) # key不存在,则增加值,返回增加的值
print(info)
示例
基于 setdefault 的小例题,用字典统计下面字符串的个数
s = 'hello user user say hello sb sb user sb'
s = 'hello user user say hello sb sb user sb'
words = s.split() # ['hello', 'user', 'user', 'say', 'hello', 'sb', 'sb']
d = {}
for word in words:
if word not in d:
d[word] =
else:
d[word] +=
print(d) # {'hello': , 'user': , 'say': , 'sb': }
# setdefault 优化
s = 'hello user user say hello sb sb user sb'
words = s.split() # ['hello', 'user', 'user', 'say', 'hello', 'sb', 'sb']
d = {}
for word in words:
# print(word,words.count(word))
d.setdefault(word,words.count(word))
print(d) # {'hello': , 'user': , 'say': , 'sb': }
例题
c)字典常用操作归纳
- popitem() # 随机返回并删除字典中的一对键和值(一般删除末尾对)。
- key in dict # 如果键在字典dict里返回true,否则返回false
- radiansdict.copy() # 返回一个字典的浅复制
- radiansdict.keys() # 以列表返回一个字典所有的键
- radiansdict.items() # 以列表返回可遍历的(键, 值) 元组数组
- radiansdict.clear() # 删除字典内所有元素
- radiansdict.values() # 以列表返回字典中的所有值
- radiansdict.fromkeys() # 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值
- radiansdict.update(dict2) # 把字典dict2的键/值对更新到dict里
- radiansdict.get(key, default=None) # 返回指定键的值,如果值不在字典中返回default值
- radiansdict.setdefault(key, default=None) # 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
- pop(key[,default]) # 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
5)布尔型
#布尔值,一个True一个False
#计算机俗称电脑,即我们编写程序让计算机运行时,应该是让计算机无限接近人脑,或者说人脑能干什么,计算机就应该能干什么,
人脑的主要作用是数据运行与逻辑运算,此处的布尔类型就模拟人的逻辑运行,即判断一个条件成立时,用True标识,不成立则用False标识
>>> a=3
>>> b=5
>>>
>>> a > b #不成立就是False,即假
False
>>>
>>> a < b #成立就是True, 即真
True 接下来就可以根据条件结果来干不同的事情了:
if a > b
print(a is bigger than b ) else
print(a is smaller than b )
上面是伪代码,但意味着, 计算机已经可以像人脑一样根据判断结果不同,来执行不同的动作。
布尔型的重要性
#所有数据类型都自带布尔值
1、None,0,空(空字符串,空列表,空字典等)三种情况下布尔值为False
2、其余均为真
6)类型的归纳重点
#所有数据类型都自带布尔值
1、None,0,空(空字符串,空列表,空字典等)三种情况下布尔值为False
2、其余均为真
四、字符串格式化,即用变量替代被格式化字符串的值
例如:
s = "I am %s" % "user"
print(s) # I am user
for i in range(3):
print("%s 次hello" %i)
# 打印结果
# 0 次hello
# 1 次hello
# 2 次hello
常见的字符串格式化
s = "I am %s,age %d" % ("user",) # 最常用的
print(s) # I am user,age
s = "I am %(name)s,age %(age)d" % {"name":"user","age":}
print(s) # I am user,age
s = "I am %(n1) + 10s adadgad" % {"n1":"user"} # 右对齐
print(s) # I am user adadgad
s = "I am %(n1)-10d adadgad" % {"n1":} # 左对齐
print(s) # I am adadgad
s = "I am %(n1)+010d adadgad" % {"n1":} # 0替代空格
print(s) # I am + adadgad
s = "I am %f user" % 1.2 # 默认6位的精度
print(s) # I am 1.200000 user
s = "I am %.2f user" % 1.2 # 指定2位的精度
print(s) # I am 1.20 user
s = "I am %(pp).2f %%" %{"pp":123.425556}
print(s) # I am 123.43 %
s = "I am {},age {},{}".format("user",,"chinese") # 非常常见
print(s) # I am user,age ,chinese
s = "I am {:.2%} love".format(0.99)
print(s) # I am 99.00% love
特殊的模板字符串格式化
MENU_START = """
--------------------------------------------
FTP SERVER
---------------------------------------------
{menu1} {menu2} {menu3}
"""
menu = MENU_START.format(menu1="[1] 启动服务",
menu2="[2] 添加用户",
menu3="[3] 结束程序")
print(menu)
# --------------------------------------------
# FTP SERVER
# ---------------------------------------------
# [] 启动服务 [] 添加用户 [] 结束程序
字符串作业
练习:用户输入姓名、年龄、工作、爱好 ,然后打印成以下格式
------------ info of Egon -----------
Name : Egon
Age :
Sex : male
Job : Teacher
------------- end -----------------
字符串综合练习
#!/usr/bin/env python
#-*-coding utf8-*-
#Author:caojin
info = {
'stu1001': 'caojin',
'stu1002': 'zhaoming',
'stu1003': 'zhansan',
'stu1004': 'lisi',
}
print(info)
print(info['stu1002'])
info['stu1003'] = "张山" #修改
print(info)
info['st112'] = "孙悟空" #如果没有则是添加
print(info)
del info['stu1004'] #删除
print(info)
info.pop('stu1003') #删除
print(info)
info.popitem() #随机删除
print(info)
print(info.get('stu00010')) #找元素,即便没有也没有错,出现none
print('stu1001' in info) #判断元素是否在
print('stu1005' in info) info.setdefault('stu1002',"贝吉塔") #先去找1002这个元素,如果有,直接返回值;如果没有,则增加新的值
print(info) b = {
'stu1001':'lengmengyun',
:,
:
}
print(b)
info.update(b) #把列表b的元素放进info里面,如果有同样的序列,则元素被替换。交叉的覆盖了
print(info)
print(info.items()) #把字典转成了列表
c = info.fromkeys([,,])
print(c)
e = dict.fromkeys([,,],"") #创建相同元素
print(e)
f = dict.fromkeys([,,],[,{"name":"caojin"},])
print(f)
f[][]['name'] = "zhaoming" #注意用fromkeys创建字典的守护,改一个则都改了
print(f)
print("-----",info,"------")
for i in info: #两个for效果一样,但是上面个高效,如果数据量上百万,下面个for循环可能会崩溃
print(i,info[i])
for k,v in f.items():
print(k,v)
五、基本运算符
1)算数运算
以下假设变量:a=10,b=20
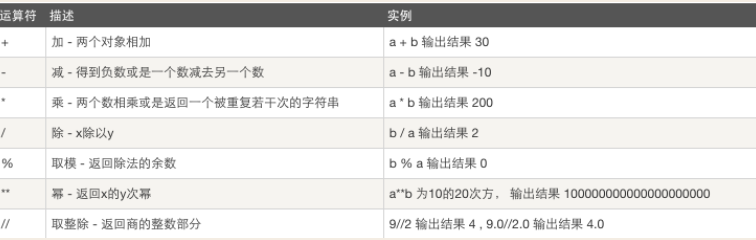
2)比较运算符
以下假设变量:a=10,b=20

3)赋值运算
以下假设变量:a=10,b=20
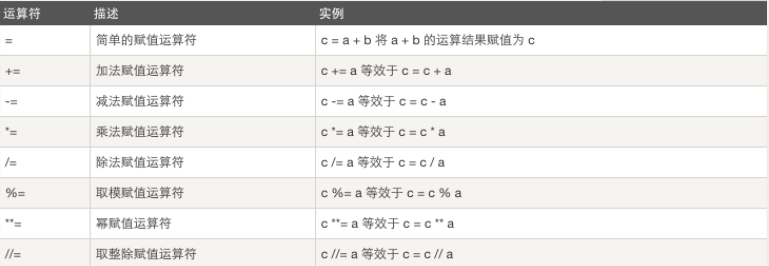
4)逻辑运算

>>> True or Flase and False
True
>>> (True or Flase) and False
False
4)身份比较运算
#is比较的是id
#而==比较的是值
六、流程控制之 if .....elif.....else
1) 基础条件语句,if
# 如果:女人的年龄>30岁,那么:叫阿姨
age_of_girl=31
if age_of_girl > 30:
print('阿姨好')
2) 如果,那么 即 if ....else...
# 如果:女人的年龄>30岁,那么:叫阿姨,否则:叫小姐
age_of_girl=18
if age_of_girl > 30:
print('阿姨好')
else:
print('小姐好')
3) 条件组合判断
#如果:女人的年龄>=18并且<22岁并且身高>170并且体重<100并且是漂亮的,那么:表白,否则:叫阿姨
age_of_girl=18
height=171
weight=99
is_pretty=True
if age_of_girl >= 18 and age_of_girl < 22 and height > 170 and weight < 100 and is_pretty == True:
print('表白...')else:
print('阿姨好')
4)if 嵌套 if
#在表白的基础上继续:
#如果表白成功,那么:在一起
#否则:打印。。。 age_of_girl=18
height=171
weight=99
is_pretty=True
success=False
if age_of_girl >= 18 and age_of_girl < 22 and height > 170 and weight < 100 and is_pretty == True:
if success:
print('表白成功,在一起')
else:
print('我跟你开玩笑而已...')
else:
print('阿姨好')
5)if ...elif...else
如果:成绩>=,那么:优秀
如果成绩>=80且<,那么:良好
如果成绩>=70且<,那么:普通
其他情况:很差 score=input('>>: ')
score=int(score) if score >= :
print('优秀')
elif score >= :
print('良好')
elif score >= :
print('普通')
else:
print('很差')
练习,简单的用户登录
name=input('请输入用户名字:')
password=input('请输入密码:')
if name == 'egon' and password == '':
print('egon login success')
else:
print('用户名或密码错误')
用户登录验证
七、流程控制之while循环
目的: 减少重复的代码
1)while的语法
while 条件:
# 循环体
# 如果条件为真,那么循环体则执行,执行完毕后再次循环,重新判断条件。。。
# 如果条件为假,那么循环体不执行,循环终止
2)打印数字练习,循环打印奇数,偶数等
#打印0-
count=
while count <= :
print('loop',count)
count+= #打印0-10之间的偶数
count=
while count <= :
if count% == :
print('loop',count)
count+= #打印0-10之间的奇数
count=
while count <= :
if count% == :
print('loop',count)
count+=
while练习
3)死循环
import time
num=0
while True:
print('count',num)
time.sleep(1)
num+=1
4)while + break :break的意思是结束本层循环
while True:
name = input('please input your name:')
pwd = input('please input your password:')
if name == 'user' and pwd == '':
print('登录成功')
break
else:
print('登录失败')
5)while + continue :continue的意思是结束本次循环
n =
while n <= :
if n == :
n +=
continue
print(n)
n +=
6)while + tag ===》 True 和 False
tag = True
while tag:
print('第一层')
while tag:
print('第二层')
while tag:
cmd = input('第三层>>:')
if cmd == 'q':
tag = False
break
八、练习作业
1)打印金字塔
x
xxx
xxxxx
xxxxxxx
xxxxxxxxx
# 方法一
n =
while n <= :
print(('x' * n).center(, ' '))
n +=
# 方法二
for i in range(,):
if i% == :
print(("x"*i).center(, ' '))
2)打印九九乘法表
# for i in range(,):
# for j in range(,i+):
# print('%s*%s=%s' %(i,j,i*j),end=' ')
# print()
# *=
# *= *=
# *= *= *=
# *= *= *= *=
# *= *= *= *= *=
# *= *= *= *= *= *=
# *= *= *= *= *= *= *=
# *= *= *= *= *= *= *= *=
# *= *= *= *= *= *= *= *= *= for i in range(,):
# 第一层循环
#print(i)
for j in range(, ):
# 第二层循环
c = i*j
print('%s*%s=%s' %(i,j,c),end='\t')
# end=' ' 的意义是在循环输出的后面加一个分割,例如 *= *= end=' '
print() # 意思在第二层循环的一次结束后换行,进行下一次循环
装B代码
print('\n'.join([' '.join(['%s*%s=%-2s' % (j, i, i * j) for j in range(, i + )]) for i in range(, )]))
3)打印3层菜单
python基础
python进阶
python框架
第一层:python基础
入门
语法结构
第二层:入门
简介
python版本
数据类型
第三层:b
返回上一级
入门
语法结构
第二层:q
==========欢迎再来==========
dict = {
'python基础':{
'入门':{
'简介':['python历史','编程语言','python简介'],
'python版本':['python2','python3','共存'],
'数据类型':['int','float','list','tuple','dict']
},
'语法结构':{
'条件判断':['if','if...else','if...elif...else'],
'循环语句':['for','while'],
'函数体系':['def','class']
}
},
'python进阶':{
'高级语法结构':{
'高级语法专题':['迭代器','生成器','装饰器'],
'函数进阶':['正则匹配','内置函数','自定义函数'],
'数据库操作':['SQL语法','查询','算法']
},
'前端知识学习':{
'html语法':['if','if...else','if...elif...else'],
'css语法':['for','while'],
'js语法':['def','class']
}
},
'python框架': {
'flask框架': {
'高级语法专题': ['迭代器', '生成器', '装饰器'],
'函数进阶': ['正则匹配', '内置函数', '自定义函数'],
'数据库操作': ['SQL语法', '查询', '算法']
},
'tonado框架': {
'html语法': ['if', 'if...else', 'if...elif...else'],
'css语法': ['for', 'while'],
'js语法': ['def', 'class']
},
'django框架': {
'html语法': ['if', 'if...else', 'if...elif...else'],
'css语法': ['for', 'while'],
'js语法': ['def', 'class']
}
}
}
tag = True
while tag:
for i in dict:
print(i)
choice1 = input('第一层:').strip()
if choice1 == 'q':
print('==========欢迎再来==========')
tag = False
elif choice1 not in dict:
print('===========请重新输入===========')
continue
while tag:
for k in dict[choice1]:
print(k)
choice2 = input('第二层:').strip()
if choice2 == 'q':
print('==========欢迎再来==========')
tag = False
elif choice2 == 'b':
print('返回上一级')
break
elif choice2 not in dict[choice1]:
print('===========请重新输入===========')
continue
while tag:
for m in dict[choice1][choice2]:
print(m)
choice3 = input('第三层:').strip()
if choice3 == 'q':
print('==========欢迎再来==========')
tag = False
elif choice3 == 'b':
print('返回上一级')
break
elif choice3 not in dict[choice1][choice2]:
print('===========请重新输入===========')
continue
while tag:
list = dict[choice1][choice2][choice3]
print(list)
choice4 = input('======确定你的选择,请输入q=====:')
if choice4 == 'q':
print('==========欢迎再来==========')
tag = False
else:
continue
精简版
利用了列表的特性,list.pop()和list.append()
dict = {
'python基础':{
'入门':{
'简介':['python历史','编程语言','python简介'],
'python版本':['python2','python3','共存'],
'数据类型':['int','float','list','tuple','dict']
},
'语法结构':{
'条件判断':['if','if...else','if...elif...else'],
'循环语句':['for','while'],
'函数体系':['def','class']
}
},
'python进阶':{
'高级语法结构':{
'高级语法专题':['迭代器','生成器','装饰器'],
'函数进阶':['正则匹配','内置函数','自定义函数'],
'数据库操作':['SQL语法','查询','算法']
},
'前端知识学习':{
'html语法':['if','if...else','if...elif...else'],
'css语法':['for','while'],
'js语法':['def','class']
}
},
'python框架': {
'flask框架': {
'高级语法专题': ['迭代器', '生成器', '装饰器'],
'函数进阶': ['正则匹配', '内置函数', '自定义函数'],
'数据库操作': ['SQL语法', '查询', '算法']
},
'tonado框架': {
'html语法': ['if', 'if...else', 'if...elif...else'],
'css语法': ['for', 'while'],
'js语法': ['def', 'class']
},
'django框架': {
'html语法': ['if', 'if...else', 'if...elif...else'],
'css语法': ['for', 'while'],
'js语法': ['def', 'class']
}
}
}
layers=[dict]
while True:
if len(layers) == : break
current_layer=layers[-]
# print(current_layer)
for key in current_layer:
print(key)
choice = input('>>: ').strip()
if choice == 'b':
layers.pop(-)
continue
if choice == 'q':break
if choice not in current_layer:continue
layers.append(current_layer[choice])
Python之入门篇1的更多相关文章
- 《python开发技术详解》|百度网盘免费下载|Python开发入门篇
<python开发技术详解>|百度网盘免费下载|Python开发入门篇 提取码:2sby 内容简介 Python是目前最流行的动态脚本语言之一.本书共27章,由浅入深.全面系统地介绍了利 ...
- python正则表达式入门篇
文章来源于:https://www.cnblogs.com/chuxiuhong/p/5885073.html Python 正则表达式入门(初级篇) 本文主要为没有使用正则表达式经验的新手入门所写. ...
- 人生苦短,我用 python 之入门篇
Python 是一种跨平台的,开源的,免费的,解释型的高级编程语言,它具有丰富和强大的库,其应用领域也非常广泛,在 web 编程/图形处理/黑客编程/大数据处理/网络爬虫和科学计算等领域都能找到其身影 ...
- python——django入门篇
要做一只有自学能力的pythoner,尽管大多数自学都是野生并不规范的,会遇到诸多坑,最后用稀奇古怪的方法解决了,但是先了解一些为以后真正学习道路填坑方便了简直不只一点点...重点来了:感觉以班里同学 ...
- Python学习 - 入门篇1
前言 学习渠道:慕课网:Python入门 记录原因:人总归要向记忆低头[微笑再见.gif] 记录目标:形成简洁的知识点查阅手册 变量和数据类型 变量 赋值 在Python中,可以把任意数据类型赋值给变 ...
- python pyspark入门篇
一.环境介绍: 1.安装jdk 7以上 2.python 2.7.11 3.IDE pycharm 4.package: spark-1.6.0-bin-hadoop2.6.tar.gz 二.Setu ...
- Python学习 - 入门篇2(更新中)
前言 学习渠道:慕课网:Python进阶 记录原因:我只是想边上课边做笔记而已,呵呵哒 食用提示:教程环境基于Python 2.x,有些内容在Python 3.x中已经改变 函数式编程 定义:一种抽象 ...
- Python 图像识别入门篇
一.安装Python依赖 pip install pytesseract pyocr pillow Image pip安装:https://www.cnblogs.com/Javame/p/10918 ...
- python爬虫入门篇
优质爬虫入门源码:https://github.com/lining0806/PythonSpiderNotes Python Spider:https://www.cnblogs.com/wangy ...
随机推荐
- 二维数组中的查找(python)
题目描述 在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序.请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数 ...
- 第十章 优先级队列 (b3)完全二叉堆:删除与下滤
- SSH 连接很慢
相信很多朋友在使用Linux系统的时候因为安全性的原因摒弃了telnet rlogin 或者 X-window,而把openssh作为自己默认的远程登录方式.然而经常会遇到的一个情况是telnet到s ...
- NumPy Ndarray 对象
NumPy Ndarray 对象 NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引. ndarray 对象是用于存放 ...
- PHP连接数据库(mysql)
前端链接后台,数据库几乎必不可少.所以本文总结了PHP链接数据库的常用方法步骤. 首先 链接数据库:mysqli_connect参数①主机地址 ②mysql用户名③nysql密码④选择连接的数据库⑤端 ...
- java序列化的认识(从多本书和多个博客中的总结)
Serializable接口是java.io下的一个标记接口,一个类要被序列化必须实现这个接口.
- 用户管理系统之class
接着上一篇博客继续往下总结,上一篇博客的地址:https://www.cnblogs.com/bainianminguo/p/9189324.html 我们开始吧 这里我们就需要先看下我们设计的数据库 ...
- EasyUI Dialog 对话框默认不弹出和关闭清空对话框内容
EasyUI中文网: http://www.jeasyui.net/plugins/181.html 默认不弹出:closed:true 模式化窗口(有遮罩):modal:true <div c ...
- linux查看本服务端口开放情况
在Linux使用过程中,需要了解当前系统开放了哪些端口,并且要查看开放这些端口的具体进程和用户,可以通过netstat命令进行简单查询. 1.netstat命令各个参数说明如下: -t : 指明显示T ...
- python读写剪贴板
#coding:utf-8 import os import time import win32api import win32con import win32clipboard as w impor ...