吴裕雄 python 爬虫(4)
import requests user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'
headers = {'User-Agent':user_agent}
r = requests.get("http://www.gov.cn/zhengce/content/2017-11/23/content_5241727.htm",headers = headers)
print(r.text)

print('\n\n\n')
print('代码运行结果:')
print('==============================\n')
print('编码方式:',r.encoding)
print('\n==============================')
print('\n\n\n')
#修改encoding为utf-8
r.encoding = 'utf-8'
#重新打印结果
print(r.text)

#指定保存html文件的路径、文件名和编码方式
with open ('E:\\requests.html','w',encoding = 'utf8') as f:
#将文本写入
f.write(r.text)
import re pattern = re.compile(r'\d+')
result1 = re.match(pattern, '你说什么都是对的23333')
# print('\n\n\n')
print('代码运行结果:')
# print('==============================\n')
if result1:
print(result1.group())
else:
print('匹配失败')
result2 = re.match(pattern, '23333你说什么都是对的')
if result2:
print(result2.group())
else:
print('匹配失败')
# print('\n==============================')
# print('\n\n\n')

#用.search()来进行搜索
result3 = re.search(pattern, '你说什么23333都是对的')
print('代码运行结果:')
print('==============================\n')
#如果匹配成功,打印结果,否则打印“匹配失败”
if result3:
print(result3.group())
else:
print('匹配失败')

print('代码运行结果:')
# print('==============================\n')
#使用.split()把数字之间的文本拆分出来
print (re.split(pattern, '你说双击666都是对的23333哈哈'))
# print('\n==============================')
# print('\n\n\n')

# print('\n\n\n')
print('代码运行结果:')
# print('==============================\n')
#使用.findall找到全部数字
print (re.findall(pattern, '你说双击666都是对的23333哈哈'))
# print('\n==============================')
# print('\n\n\n')

matchiter = re.finditer(pattern, '你说双击666都是对的23333哈哈')
for match in matchiter:
print(match.group())

p = re.compile(r'(?P<word1>\w+) (?P<word2>\w+)')
s = 'i say, hello world!'
print (p.sub(r'\g<word2> \g<word1>',s))
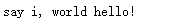
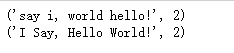
p = re.compile(r'(\w+) (\w+)')
print(p.sub(r'\2 \1',s))

def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print(p.sub(func,s))

print(p.subn(r'\2 \1', s))
print(p.subn(func,s))
#导入BeautifulSoup
from bs4 import BeautifulSoup
#创建一个名为soup的实例
soup = BeautifulSoup(r.text, 'lxml', from_encoding='utf8')
print(soup)

# print('\n\n\n')
print('代码运行结果:')
# print('==============================\n')
#使用.'标签名'即可提取这部分内容
print(soup.title)
# print('\n==============================')
# print('\n\n\n')

# print('\n\n\n')
print('代码运行结果:')
# print('==============================\n')
#使用.string即可提取这部分内容中的文本数据
print(soup.title.string)
# print('\n==============================')
# print('\n\n\n')

# print('\n\n\n')
print('代码运行结果:')
# print('==============================\n')
#使用.get_text()也可提取这部分内容中的文本数据
print(soup.title.get_text())
# print('\n==============================')
# print('\n\n\n')
# print('\n\n\n')
print('代码运行结果:')
# print('==============================\n')
#打印标签<p>中的内容
print(soup.p.string)
# print('\n==============================')
# print('\n\n\n')

#使用find_all找到所有的<p>标签中的内容
texts = soup.find_all('p')
#使用for循环来打印所有的内容
for text in texts:
print(text.string)

............................................

#找到倒数第一个<a>标签
link = soup.find_all('a')[-1]
# print('\n\n\n')
print('BeautifulSoup提取的链接:')
# print('==============================\n')
print(link.get('href'))
# print('\n==============================')
# print('\n\n\n')
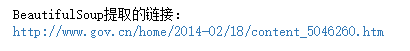
print(soup.title.name)
print(soup.title.string)
print(soup.attrs)
print(soup.a.string)
print(soup.p.string)
print(type(soup.a.string))

print(soup.head.contents)

print(len(soup.head.contents))
# print(soup.head.contents[3].string)
50
for child in soup.head.children:
print(child)

for child in soup.head.descendants:
print(child)

print(soup.head.string)
print(soup.title.string)
print(soup.html.string)

for string in soup.strings:
print(repr(string))

print(soup.title,'\n')
print(soup.title.parent)

print(soup.a)
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)

print(soup.p.next_sibling.next_sibling)

for sibling in soup.a.next_siblings:
print(sibling)

for element in soup.a.next_elements:
print(element.string)

print(soup.find_all('b'))
print(soup.find_all('p'))

..................................................................

for tag in soup.find_all(re.compile('^b')):
print(tag.name)
#print(soup.find_all(re.compile('^p')))
print(soup.find_all(['a','b']))

for tag in soup.find_all(True):
print(tag.name)

....................................................
def hasclass_id(tag):
return tag.has_attr('class') and tag.has_attr('id')
print(soup.find_all(hasclass_id))

print(soup.find_all(style='text-indent: 2em; font-family: 宋体; font-size: 12pt;'))
print(soup.find_all(href=re.compile('gov.cn')),'\n')

print(soup.find_all(text=re.compile('通知')))

print(soup.find_all('p',limit=2))

policies = requests.get('http://www.gov.cn/zhengce/zuixin.htm',headers = headers)
policies.encoding = 'utf-8'
print(policies.text)

p = BeautifulSoup(policies.text,'lxml',from_encoding='utf8')
print(p)

contents = p.find_all(href = re.compile('content'))
吴裕雄 python 爬虫(4)的更多相关文章
- 吴裕雄 python 爬虫(3)
import hashlib md5 = hashlib.md5() md5.update(b'Test String') print(md5.hexdigest()) import hashlib ...
- 吴裕雄 python 爬虫(2)
import requests from bs4 import BeautifulSoup url = 'http://www.baidu.com' html = requests.get(url) ...
- 吴裕雄 python 爬虫(1)
from urllib.parse import urlparse url = 'http://www.pm25x.com/city/beijing.htm' o = urlparse(url) pr ...
- 吴裕雄--python学习笔记:爬虫基础
一.什么是爬虫 爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息. 二.Python爬虫架构 Python 爬虫架构主要由五个部分组成,分别是调度器.URL管理器.网页下载器.网 ...
- 吴裕雄--python学习笔记:爬虫包的更换
python 3.x报错:No module named 'cookielib'或No module named 'urllib2' 1. ModuleNotFoundError: No module ...
- 吴裕雄--python学习笔记:爬虫
import chardet import urllib.request page = urllib.request.urlopen('http://photo.sina.com.cn/') #打开网 ...
- 吴裕雄 python 神经网络——TensorFlow pb文件保存方法
import tensorflow as tf from tensorflow.python.framework import graph_util v1 = tf.Variable(tf.const ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(4)
# -*- coding: utf-8 -*- import glob import os.path import numpy as np import tensorflow as tf from t ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(3)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
随机推荐
- JavaScript之函数,词法分析,内置对象和方法
函数 函数定义 JavaScript中的函数和Python中的非常类似,只是定义方式有点区别. // 普通函数定义 function f1() { console.log("Hello wo ...
- python 函数传递可变参数的用法
可变参数 在Python函数中,还可以定义可变参数.顾名思义,可变参数就是传入的参数个数是可变的,可以是1个.2个到任意个,还可以是0个. 我们以数学题为例子,给定一组数字a,b,c……,请计算a2 ...
- 零基础学习python_字符串(14-15课)
今天回顾下我之前学习python的第一个对象——字符串,这个对象真蛋疼,因为方法是最多的,也是最常见的类型,没有之一... 内容有点多,我就搜了下网上的资料,转载下这个看起来还不错的网址吧:http: ...
- gentoo openrc 开机打印信息
gentoo openrc 开机的时候,最开始 一些硬件的信息, 后面是一些内核和驱动的信息. 硬件的信息是默认保存到 /var/log/dmesg 中, 可以使用 dmesg | less 来查看硬 ...
- 实战ELK(1) 安装ElasticSearch
第一步:环境 linux 系统 Java 1.8.0 elasticsearch-6.5.1 第二步:下载 2.1 JDK:https://mirrors.aliyun.com/centos/7.5 ...
- 阿里云实现putty私钥登录全过程
阿里云实现putty私钥登录全过程 1 putty生成公钥和私钥 1)putty生成公钥和私钥 记得在空白区域 滑动 2 公钥上传到阿里云 1)公钥上传 私钥存到本地 3 公钥绑定要登录的实例 4 ...
- 1.正则re
正则 :规则表达式 一般在匹配非结构化的数据时用的比较多,结构化的数据一般用xpath,bs4.但具体使用起来都是视情况而定,相对而言.正则规则平时涉及最多也就是匹配邮箱,电话,及特殊字符串.规则相对 ...
- C#面向对象基础2
一.属性 作用:保护字段,对字段的赋值取值进行限定 意思是在初始化对象的时候防止出现不是事实的违规操作 如将性别赋值为‘中’ 本质:两个方法 get方法和set方法. p ...
- HTTP协议之认证
认证方式有: basic ntlm digest
- 图片 base64转byte[]
/// <summary> /// 保存base64图片,返回阿里云地址 /// </summary> /// <param name="imgCode&quo ...