hive 的理解
什么是Hive
转自: https://blog.csdn.net/qingqing7/article/details/79102691
1、Hive简介
Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用戶查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
首先,我来说说什么是hive(What is Hive?),请看下图:
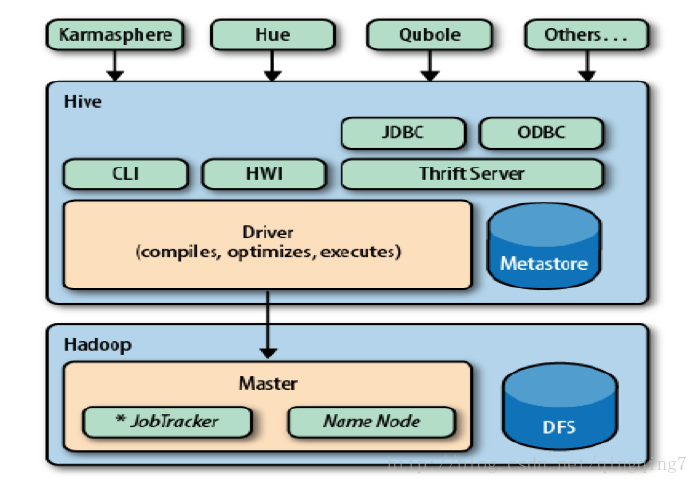
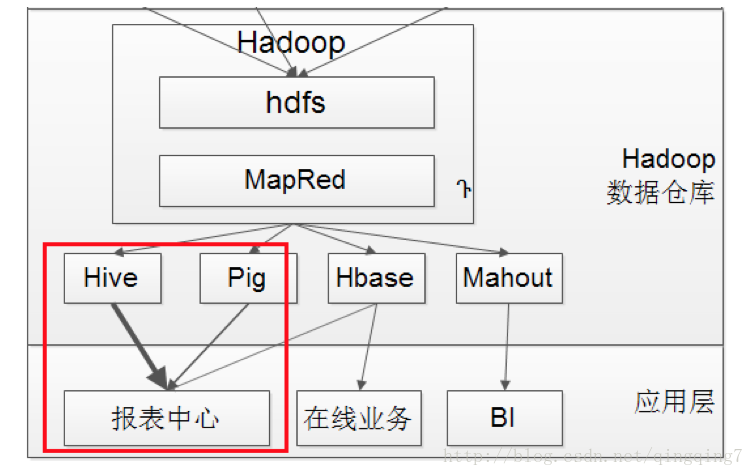
Hive构建在Hadoop的HDFS和MapReduce之上,用于管理和查询结构化/非结构化数据的数据仓库。
- 使用HQL作为查询接口
- 使用HDFS作为底层存储
- 使用MapReduce作为执行层
Hive的应用,如下图所示
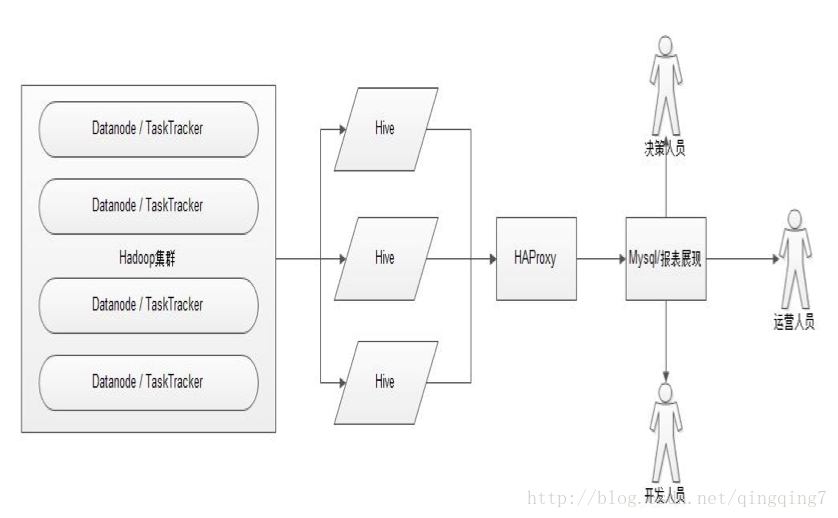
这里集群搭建Hive时用到了HA,最后用HAProxy来做代理。
1.1、结构描述
Hive 的结构可以分为以下几部分:
- 用戶接口:包括 CLI, Client, WU
- 元数据存储。通常是存储在关系数据库如 mysql, derby 中
- 解释器、编译器、优化器、执行器
- Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算
1、 用戶接口主要有三个:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客戶端,用戶连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
2、 Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
3、 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
1.2、Hive和普通DB的异同
| Hive | RDBMS |
|---|---|
| 查询语句 | HQL |
| 数据存储 | HDFS |
| 索引 | 1.0.0版本支持 |
| 执行延迟 | 高 |
| 处理数据规模 | 大(或海量) |
| 执行 | MapReduce |
1.3、元数据
Hive 将元数据存储在 RDBMS 中,一般常用的有MYSQL和DERBY。由于DERBY只支持单客戶端登录,所以一般采用MySql来存储元数据。
1.4、数据存储
首先,Hive 没有专门的数据存储格式,也没有为数据建立索引,用戶可以非常自由的组织 Hive 中的表,只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
其次,Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:Table,External Table,Partition,Bucket。
1. Hive 中的 Table 和数据库中的 Table 在概念上是类似的,每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 app,它在 HDFS 中的路径为:/ warehouse /app,其中,wh是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
安装hive后,会在hdfs上创建如/user/hive/warehouse/这样的的属于hive的文件夹;如果我们在hive中创建数据库,则会在warehouse下产生一个子目录,形如/user/hive/warehouse/xxx.db;如果接着在该数据库中创建一个表,则会继续产生子目录,形如/user/hive/warehouse/xxx.db/yyyyyy;
2. Partition 对应于数据库中的 Partition 列的密集索引,但是 Hive 中 Partition 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。例如:xiaojun 表中包含 dt 和 city 两个 Partition,则对应于 dt = 20100801, ctry = US 的 HDFS 子目录为:/ warehouse /app/dt=20100801/ctry=US;对应于 dt = 20100801, ctry = CA 的 HDFS 子目录为;/ warehouse /app/dt=20100801/ctry=CA
这里对应了Hive将数据分块的方式,它是以某一个变量的取值来分枝的,一个值对应一个枝,即对应一个目录,,然后再用下一个变量进一步分枝,即进一步分出更多目录;
如果创建表时有分区,则会在目录中产生分区标识来区分的文件,形如/user/hive/warehouse/xxx.db/yyyyyy/date=20180521,文件中即保存着相关的内容,以一定的分隔符区分字段;
3. Buckets 对指定列计算 hash,根据 hash 值切分数据,目的是为了并行,每一个 Bucket 对应一个文件。将 user 列分散至 32 个 bucket,首先对 user 列的值计算 hash,对应 hash 值为 0 的HDFS 目录为:/ warehouse /app/dt =20100801/ctry=US/part-00000;hash 值为 20 的 H
DFS 目录为:/ warehouse /app/dt =20100801/ctry=US/part-00020
如果指定Buckets,则date=20180521不是文件,而是文件名,然后再它的下级会产生以某一列值的hash 值为区分的文件,形如/user/hive/warehouse/xxx.db/yyyyyy/date=20180521/part-00000,文件中即保存着相关的内容
4. External Table 指向已经在 HDFS 中存在的数据,可以创建 Partition。它和 Table 在元数据的组
织上是相同的,而实际数据的存储则有较大的差异。
Table (内部表)的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。
External Table 只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在 LOCATION 后面指定的 HDFS 路径中,并不会移动到数据仓库目录中。当删除一个 External Table 时,仅删除hive的元数据,不会删除hdfs上对应的文件。
hive 的理解的更多相关文章
- hive元数据库理解
在hive2.1.1 里面一共有59张表 表1 VERSION ; version表存hive的版本信息,该表中数据只有一条,如果存在多条,会造成hive启动不起来. 表2 DBS select * ...
- hive的简单理解--笔记
Hive的理解 数据仓库的工具 Hive仅仅是在hadoop上面包装了SQL: Hive的数据存储在hadoop上 Hive的计算由MR进行 Hive批量处理数据 Hive的特点 1 可扩展性(h ...
- hive权威指南<一>
一.ETL介绍: 数据抽取:把不同的数据源数据抓取过来,存到某个地方 数据清洗:过滤那些不符合要求的数据或者修正数据之后再进行抽取 不完整的数据:比如数据里一些应该有的信息缺失,需要补全后再写入数据仓 ...
- Hive与Hbase关系整合
近期工作用到了Hive与Hbase的关系整合,虽然从网上参考了很多的资料,但是大多数讲的都不是很细,于是决定将这块知识点好好总结一下供大家分享,共同掌握! 本篇文章在具体介绍Hive与Hbase整合之 ...
- 第1节 hive安装:2、3、4、5、(多看几遍)
第1节 hive安装: 2.数据仓库的基本概念: 3.hive的基本介绍: 4.hive的基本架构以及与hadoop的关系以及RDBMS的对比等 5.hive的安装之(使用mysql作为元数据信息存储 ...
- Hive 3.x 配置&详解
Hive 1. 数据仓库概述 1.1 基本概念 数据仓库(英语:Data Warehouse,简称数仓.DW),是一个用于存储.分析.报告的数据系统. 数据仓库的目的是构建面向分析的集成化数据环境,分 ...
- Hive的基本知识与操作
Hive的基本知识与操作 目录 Hive的基本知识与操作 Hive的基本概念 为什么使用Hive? Hive的特点: Hive的优缺点: Hive应用场景 Hive架构 Client Metastor ...
- 数据仓库与hive
数据仓库与hive hive--数据仓库建模工具之一 一.数据库.数据仓库 1.1 数据库 关系数据库本质上是一个二元关系,说的简单一些,就是一个二维表格,对普通人来说,最简单的理解就是一个Excel ...
- 在Hadoop-2.2.0集群上安装 Hive-0.13.1 with MySQL
fesh个人实践,欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3872872.html 软件环境 操作系统:Ubuntu14.04 JDK版本:jdk1 ...
随机推荐
- vue搭配axios踩坑
客户端项目中有一个小需求“我的卡券”,有单独入口,所以综合考虑之后,采用了vue来实现,因为是初次使用,导致了选型不当,先用了SUI-Mobile来搭建页面,当决定使用vue的时候,页面也搭建完毕了, ...
- Vue.js模拟百度下拉框
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- tkinter面板切换
- JAVA 中文 unicode 相互转换 文件读取
package com.test; import org.junit.Test; public class JunitTest { @Test public void test(){ String p ...
- 学习笔记: js插件 —— fullPage.js (页面全屏滚动)
fullPage.js (页面全屏滚动) 必须依赖 jquery-ui.min.js, 233K 14760个星. 以后有时间再看. API挺全 https://github.com/alvaro ...
- python中len 小练习:获取并输出集合中的索引及对应元素
len()用来获取长度.字节等数值 1 a = ["hello", "world", "dlrb"] 2 b = len(a) 3 for ...
- python中 将你的名字转化成为二进制并输出
1 name = "吴彦祖" 2 for i in name: 3 i_by = bytes(i, encoding = "utf-8") 4 for i_bi ...
- web session 原理1
原理 我们都知道,浏览器无状态的.浏览器是操作不了session的,浏览器能够做的只是传递cookie,每次都传递. 把当前主机下的,和当前请求相同域下的cookie 传递到服务器去,只要cooki ...
- 序列化 (实现RPC的基础)
public interface ISerializer { <T> byte[] serializer(T obj); <T> T deSerializer(byte[] d ...
- spark核心原理
spark运行结构图如下: spark基本概念 应用程序(application):用户编写的spark应用程序,包含驱动程序(Driver)和分布在集群中多个节点上运行的Executor代码,在执行 ...