Java 内存模型 ,一篇就够了!
Java 虚拟机
我们都知道 Java 语言的可以跨平台的,这其中的核心是因为存在 Java 虚拟机这个玩意。虚拟机,顾名思义就是虚拟的机器,这不是真实存在的硬件,但是却可以和不同的底层平台进行交互。而且 Java 虚拟机模拟的还比较全面,它想象了自己拥有硬件,处理器,寄存器和堆栈等,还具有相应的指令系统,以此来对接不同的底层操作系统。
Java 内存模型(Java Memory Model)
上次已经说过了底层硬件中内存的相关结构和处理,那同样的对于 Java 虚拟机这个“机器”来说,是不是也应该会有相应的结构呢?因为说到底虚拟机玩的再花,要什么有什么,最终还是要和底层 RAM 进行交互的嘛。
怎么交互?这就是一个大问题,有一群专家就定义了一套规范,定义 Java 内存模型并不是一件容易的事情,这个模型必须定义得足够严谨,才能让 Java 的并发操作不会产生歧义;但是,也必须得足够宽松,使得虚拟机的实现能有足够的自由空间去利用硬件的各种特性(寄存器、高速缓存等)来获取更好的执行速度。
Java 内存模型的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样底层细节。此处的变量与 Java 编程时所说的变量不一样,只包括了实例字段、静态字段和构成数组对象的元素,但是不包括局部变量与方法参数,后者是线程私有的,不会被共享。
Java 内存模型中规定了所有的变量都存储在主内存中,每个线程还有自己的工作内存(类比缓存理解),线程的工作内存中保存了该线程使用到主内存中的变量拷贝,线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存中的变量。不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递(通信)均需要在主内存来完成,线程、主内存和工作内存的交互关系如下图所示
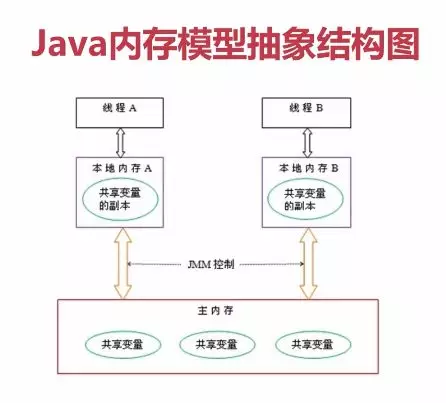
这个图和 CPU 与缓存的图非常类似,搞不好 JMM 的构建就是仿照硬件系统来的。同样的道理我们要思考一下在多线程的环境中,JMM 又是如何保证主内存和工作内存中的变量一致性?回忆一下 CPU 是如何保证缓存一致性的,使用 MESI 协议。那在这里呢,Java 内存模型就定义了 8 种操作和 8 个规则。
回头想想,JMM 是一套规则呀,它只会给你定义规范,模型,具体的实现自己玩去!理解这一点很重要。我们来看看它给出了哪些操作和必须满足的规则吧。
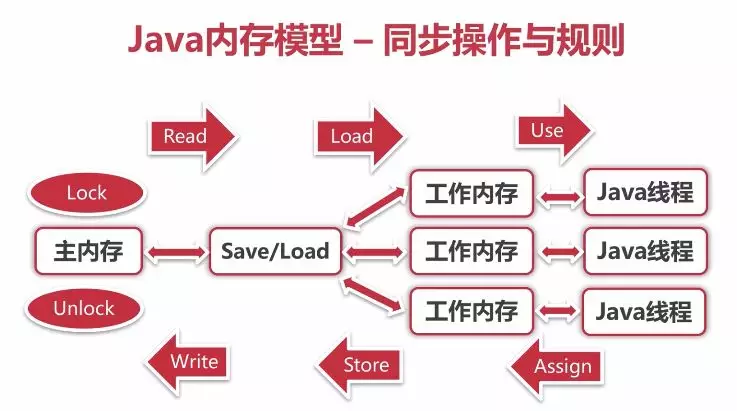
lock(锁定):作用于主内存的变量,把一个变量标识为一条线程独占状态。
unlock(解锁):作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
read(读取):作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的 load 动作使用
load(载入):作用于工作内存的变量,把 read 操作从主内存中得到的变量值放入工作内存的变量副本中。
use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的 write 的操作。
write(写入):作用于主内存的变量,它把 store 操作从工作内存中一个变量的值传送到主内存的变量中。
如果要把一个变量从主内存中复制到工作内存,就需要按顺序地执行 read 和 load 操作,如果把变量从工作内存同步回主内存中,就要按顺序地执行 store 和 write 操作。Java 内存模型只要求上述操作必须按顺序执行,而没有保证必须是连续执行。也就是 read 和 load 之间,store 和 write 之间是可以插入其他指令的,如对主内存中的变量 a、b 进行访问时,可能的顺序是 read a,read b,load b, load a。Java 内存模型还规定了在执行上述八种基本操作时,必须满足如下规则:
1 不允许 read 和 load、store 和write 操作之一单独出现
2 不允许一个线程丢弃它的最近 assign 的操作,即变量在工作内存中改变了之后必须同步到主内存中。
3 不允许一个线程无原因地(没有发生过任何 assign 操作)把数据从工作内存同步回主内存中。
4 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load 或 assign)的变量。即对一个变量实施 use 和 store 操作之前,必须先执行过了 assign 和 load 操作。
5 一个变量在同一时刻只允许一条线程对其进行 lock 操作,lock 和 unlock 必须成对出现
6 如果对一个变量执行 lock 操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行 load 或 assign 操作初始化变量的值
7 如果一个变量事先没有被 lock 操作锁定,则不允许对它执行 unlock 操作;也不允许去 unlock 一个被其他线程锁定的变量
8 对一个变量执行 unlock 操作之前,必须先把此变量同步到主内存中(执行 store 和 write 操作)
好了,到这里看似我们可以完美的保证多线程情况下主内存和工作内存中数据的一致性了(也就是线程安全),But 醒醒好不好,JMM 只是一套规则呀,请问你实现了么???并没有……
对了,还是要说明一下,我从开始到现在都在介绍 JMM 看清楚这不是 JVM 啊,我的理解啊,JMM 是灵魂,是规范,是一个标准,那我们说的 JVM 其实是一个个的实现,其中比较著名的一个实现就是 HotSpot VM,好了,现在的问题就比较清楚了,接口中已经告诉你了,你只需要满足 8 个操作和 8 条规则,你就是线程安全的。
问题是,我们的 HotSpot VM 怎么实现???先别急,还有一个事请呢!
你难道忘了吗,在 CPU 执行指令的时候会存在乱序执行优化,这里也是一样啊,也会为了提高执行效率而对我们写的代码进行优化,但是呢,这里换一个叫法,改名指令重排。
而且这里重排的范围变的更大了,即可以指编译器的优化,也可以指指令的优化。上次举个【买饮料喝】的例子,但是我忘记说指令优化之后可能带来的问题了。继续说一下上次那个例子;一个人的时候:去店里->点单->付钱->喝饮料 ,嗯,这没毛病;优化之后: 【去店里,路上随便下单,付钱】->喝饮料。嗯,确实提高了效率。
两个人的时候:小A此时在店里,小B:去店里->点单->付钱->【小A喝饮料】,此时小B的心情,WTF ? 好了,看出来了吧,虽然优化是好,但是容易出问题啊!
我这例子举的很粗糙,主要是为了让大家可以快速理解在多线程中指令重排虽能提高效率,但是容易出现 bug 啊,有兴趣的同学可以自己去看看关于指令重排具体的说明。
那 JMM 又是怎么来处理多线程下的指令重排呢?想想 CPU 是怎么处理的,内存屏障,JMM 直接搬过来,嗯,我也使用一些特殊的指令来达到某些指令的顺序执行。JMM 提供了一个关键字 volatile 来解决指令重排问题。
关于 volatile 关键字,JMM 专门定义了一套特殊的访问规则,主要为达到两个目的,一是保证此变量对所有变量的可见性。二是禁止指令重排优化。解释一下第一个目的,我们知道在主内存和工作内存中变量交互的时候,假如线程将变量 a + 1,还没有写入主内存的时候,其它线程是不知道 a 的值被修改了。那现在就是希望我在工作内存改了变量之后,其它的线程能看到变量被改了。
具体怎么实现的呢?还记得 CPU 是怎么解决缓存一致性的不,使用 MESI 啊,所以这里的逻辑就是在解释执行到 volatile 关键字之后,会被解释成相关的指令,而这个指令就可以触发 CPU 将其它线程的 cache line 变为 invalid。
我们经常会误用 volatile 关键字,虽然被 volatile 修饰的变量 i 是可见的,我们也保证 i 的值是可以实时从主存中获取,但是这并不代表 i ++ 就是线程安全的,因为 i ++ 不是原子性操作,可以被拆成 geti addi puti 3步。
好了,到这里 JMM 就有了一套解决多线程安全问题的方案,这套方案又有哪些特性呢,或者说,线程安全的特性有哪些呢?
首先是原子性,我们要求一个线程在操作数据的时候,不能被打断,不能出现付钱之后饮料被人家拿走的情况。Java 内存模型定义的 8 种操作,就要求虚拟机的实现每一步都必须是原子性的,即不可分割的。
对于基本数据类型的读或写可以看成是原子性操作,但是有例外,对于32位的机器来说,一次只能处理32位,但是 double 和 long 类型的数据长度为 64,理论上会可能会被拆分,但实际运行中没有这种情况,所以可以认为对 double 和 long 来说,读或写也是线程安全的。
其次是可见性,因为在多线程环境下主内存和工作内存中数据不一致可能会导致问题,可见性要求一个线程修改了主内存中的值之后,其它的线程能立即得知这个修改。
最后是有序性,主要体现在在单线程时逻辑上的有序,在定义 8 种操作规则的时候的有序,还有最后的指令重排中的有序。
总结一下,以上我们说了 Java 内存模型的结构,以及在多线程情况下由于主内存和工作内存的不同功能和指令重排而出现的问题,以及基本的解决方案。最后,我们总结出 JMM 保证线程安全是围绕原子性、可见性、有序性这 3 个特性来建立的。
体贴的 JMM 在满足这 3 个特性的时候给了很多关键字或预定规则,比方说,在原子性中的 8 种操作,这样我们在操作基本数据类型的读和写就可以看成是线程安全的。其中的 lock 和 unlock 指令在 Java 语言中的体现就是 synchronized 关键字,所以 synchronized 块之间的操作也是原子性的。
可见性的体现,volatile 关键字,上面已经说过了,还有两个关键字 synchronized 和 final。因为被 synchronized 包围的代码被线程执行的前提是要 lock,对应的有条规则说到“对一个变量执行 unlock 之前,要先把其写回主存”。而 final 定义的变量,一旦初始化完成,其它线程都能看到(当然这里假设不出现对象逃逸,就是不会在对象初始化没有完成的时候被其它线程拿到 this 对象进行操作。)
最后一个有序性,提供了关键字 volatile 和 synchronized,volatile 禁止重排序来达到有序,而 synchronized 则是基于 “一个变量在同一时刻只允许一条线程对其进行 lock 操作,lock 和 unlock 必须成对出现” 这个规则。
另外,JMM 为了保证有序,还内置了一套先行发生规则(happens-before)两个操作间具有 happens-before 关系,并不意味着前一个操作必须要在后一个操作之前执行。happens-before 仅仅要求前一个操作对后一个操作可见,和一般意义上时间的先后是不一样的,达到逻辑上的顺序执行即可。
如果 A 线程的写操作 a 与 B 线程的读操作 b 之间存在 happens-before 关系,尽管 a 操作和 b 操作在不同的线程中执行,但 JMM 向程序员保证 a 操作将对 b 操作可见。我们实际只想知道某线程的操作对另一个线程是否可见,于是就规定了 happens-before 这个可见性原则,程序员可以基于这个原则进行可见性的判断。
具体的规则如下:
1 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生与书写在后面的操作。【保证单线程的有序】
2 锁定规则:一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。
3 volatile 变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作。【先写后读】
4 传递规则:A 先于 B 且 B 先于 C 则 A 先于 C
5 线程启动规则:Thread 对象的 start 方法先行发生于此线程的每一个动作。
6 线程中断规则:对线程 interrupt 方法的调用先行发生于被中断线程的代码检测到中断事件的发生。【先中断,后检测】
7 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过 Thread.join() 方法结束,Thread.isAlive() 的返回值手段检测线程已经终止执行。
8 对象终结规则:一个对象的初始化完成先行发生于它的 finalize 方法的开始。
如果两个操作的执行顺序不能通过 happens-before 原则推导出来,就不能保证他们的执行次序,虚拟机就可以随意的对他们进行重排序。
小结一下,以上说了在 Java 内存模型,以及为了保证多线程情况下的安全 JMM 做了哪些设定。
但是我们经常听的都是一些堆,栈,方法区,本地方法栈之类的描述。这说的是【Java 内存区域】,而上面说的是【Java 内存模型】,这两者有什么区别呢?大家都说是不同层级的分类,我自己的理解是工作内存和主内存的分类侧重点主要体现在与底层的数据交互方式上,但是我们在编程中具体涉及到的数据具体又是怎么分的呢?这也就是 Java 内存区域的价值了。
Java 内存区域主要分为 Java堆,虚拟机栈,方法区,本地方法栈,程序计数器,这些区域存放的是什么待会再说,先说明白了,这些都是虚拟的!不存在的,因为 Java 虚拟机本身就是虚拟的一个机器,但是真正在运行的时候虚拟机为了追求更高的速度,会把这些区域尽可能的分配在硬件的寄存器或缓存上,因为这样运行速度更快。
但是一般分布都不是确定的,都有可能,所以要能理解这张图的意思。

接下来说说 Java 内存中的各个区域都是干什么的。
程序计数器
程序计数器是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里,字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
如果线程正在执行的是一个 Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是 natvie 方法,这个计数器值则为空(Undefined)。此内存区域是唯一一个在 Java 虚拟机规范中没有规定任何 OutOfMemoryError 情况的区域。
Java 虚拟机栈
与程序计数器一样,Java 虚拟机栈也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是 Java 方法执行的内存模型:每个方法被执行的时候都会同时创建一个栈帧用于存储局部变量表、操作栈、动态链接、方法出口等信息。每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
我们常说的栈其实指的是“局部变量表”局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(它可能是一个指向对象起始地址的引用指针,也可能指向一个代表对象的句柄)和 returnAddress 类型(指向了一条字节码指令的地址)。其中64 位长度的 long 和 double 类型的数据会占用 2 个局部变量空间(Slot),其余的数据类型只占用 1 个。
局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
在 Java 虚拟机规范中,对这个区域规定了两种异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出 StackOverflowError 异常;当无法申请到足够的内存时会抛出 OutOfMemoryError 异常。
本地方法栈
本地方法栈与虚拟机栈所发挥的作用是非常相似的,其区别不过是虚拟机栈为虚拟机执行 Java 方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的 native 方法服务。与虚拟机栈一样,本地方法栈区域也会抛出 StackOverflowError 和 OutOfMemoryError 异常。
Java 堆
对于大多数应用来说,Java 堆是 Java 虚拟机所管理的内存中最大的一块。Java 堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都要在堆上分配内存。根据 Java 虚拟机规范的规定,Java 堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出 OutOfMemoryError 异常。
方法区
方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。根据 Java 虚拟机规范的规定,当方法区无法满足内存分配需求时,将抛出 OutOfMemoryError 异常。
运行时常量池
运行时常量池是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述等信息外,还有一项信息是常量池,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。既然运行时常量池是方法区的一部分,自然会受到方法区内存的限制,当常量池无法再申请到内存时会抛出 OutOfMemoryError 异常。
到这里为止,已经介绍了 Java 内存模型和 Java 内存区域并介绍了它们之间的区别。更重要的是搞清楚了在多线程情况下如何才能保证线程安全,那就是要保证 3 个特性,原子性、可见性、有序性。
能看到这里的小伙伴真的不容易哈,给你一个大大的赞,小伙伴们可能会纳闷,哎,这些知识都是在哪里的啊,为什么我都不知道呢?那我就偷偷的告诉你,有一本秘籍,我都已经为你们准备好了。需要你们关注我的公号呦,后台回复关键字【虚拟机】就行了~
Java 内存模型 ,一篇就够了!的更多相关文章
- 了解Java内存模型,看完这一篇就够了
前言(此文草稿是年前写的,但由于杂事甚多一直未完善好.清明假无事,便收收尾发布了) 年关将近,个人工作学习怠惰了不少.两年前刚做开发的时候,信心满满想看看一个人通过自己的努力,最终能达到一个什么样的高 ...
- 再有人问你Java内存模型是什么,就把这篇文章发给他
前几天,发了一篇文章,介绍了一下JVM内存结构.Java内存模型以及Java对象模型之间的区别.有很多小伙伴反馈希望可以深入的讲解下每个知识点.Java内存模型,是这三个知识点当中最晦涩难懂的一个,而 ...
- 《成神之路-基础篇》JVM——Java内存模型(已完结)
Java内存模型 本文是<成神之路系列文章>的第一篇,主要是关于JVM的一些介绍. 持续更新中 Java内存模型 JVM内存结构 VS Java内存模型 VS Java对象模型(Holli ...
- 【Java虚拟机6】Java内存模型(Java篇)
什么是Java内存模型 <Java虚拟机规范>中曾试图定义一种"Java内存模型"(Java Memory Model,JMM)来屏蔽各种硬件和操作系统的内存访问差异, ...
- 深入理解Java内存模型之系列篇[转]
原文链接:http://blog.csdn.net/ccit0519/article/details/11241403 深入理解Java内存模型(一)——基础 并发编程模型的分类 在并发编程中,我们需 ...
- 深入理解Java内存模型之系列篇
深入理解Java内存模型(一)——基础 并发编程模型的分类 在并发编程中,我们需要处理两个关键问题:线程之间如何通信及线程之间如何同步(这里的线程是指并发执行的活动实体).通信是指线程之间以何种机制来 ...
- (转)深入理解Java内存模型之系列篇
原文地址: http://blog.csdn.net/ccit0519/article/details/11241403 深入理解Java内存模型(一)——基础 并发编程模型的分类 在并发编程中,我们 ...
- Java内存模型JMM 高并发原子性可见性有序性简介 多线程中篇(十)
JVM运行时内存结构回顾 在JVM相关的介绍中,有说到JAVA运行时的内存结构,简单回顾下 整体结构如下图所示,大致分为五大块 而对于方法区中的数据,是属于所有线程共享的数据结构 而对于虚拟机栈中数据 ...
- Java内存模型(转载)
本文章节: 1.JMM简介 2.堆和栈 3.本机内存 4.防止内存泄漏 1.JMM简介 i.内存模型概述 Java平台自动集成了线程以及多处理器技术,这种集成程度比Java以前诞生的计算机语言要厉害很 ...
随机推荐
- 20181111 Quartz(慕课网)
Quartz体系结构 三个核心概念 调度器 任务 触发器 重要组成 Job JobBuilder JobDetail JobStore Trigger TriggerBuilder ThreadPoo ...
- js监听浏览器tab窗口切换
js监听浏览器tab窗口切换 ——IT唐伯虎 摘要:js监听浏览器tab窗口切换. if (document.hidden !== undefined) { document.addEventLis ...
- Spark记录-Spark on mesos配置
1.安装mesos #用centos6的源yum安装 # rpm -Uvh http://repos.mesosphere.io/el/6/noarch/RPMS/mesosphere-el-repo ...
- JAVA记录-JSP指令
JSP中有三种类型的指令标签 - 序号 指令 说明 1 <%@ page ... %> 定义页面相关属性,如脚本语言,错误页面和缓冲要求. 2 <%@ include ... %&g ...
- SHELL (3) —— 变量知识进阶和实践
摘自:Oldboy Linux运维——SHELL编程实战 SHELL中特殊切重要的变量 位置变量 作用说明 $0 获取当前执行的Shell脚本的文件名,如果执行脚本包含了路径,那么就包括脚本路径 $n ...
- 集成maven和Spring boot的profile功能
思路:maven支持profile功能,当使用maven profile打包时,可以打包指定目录和指定文件,且可以修改文件中的变量.spring boot也支持profile功能,只要在applica ...
- bzoj千题计划190:bzoj4300: 绝世好题
http://www.lydsy.com/JudgeOnline/problem.php?id=4300 f[i] 表示第i位&为1的最长长度 #include<cstdio> # ...
- 流媒体技术学习笔记之(十四)FFmpeg进行笔记本摄像头+麦克风实现流媒体直播服务
FFmpeg推送视频流,Nginx RTMP模块转发,VLC播放器播放,实现整个RTMP直播 查看本机电脑的设备 ffmpeg -list_devices true -f dshow -i dummy ...
- [转载]AngularJS 开发者最常犯的 10 个错误
http://www.oschina.net/translate/top-10-mistakes-angularjs-developers-make
- 20155315 2016-2017-2 《Java程序设计》第七周学习总结
教材学习内容总结 第12章 Lambda语法 Lambda定义 一个不用被绑定到一个标识符上,并且可能被调用的函数. 在只有Lambda表达式的情况下,参数的类型必须写出来,如果有目标类型的话,在编译 ...