全网最详细的Hadoop HA集群启动后,两个namenode都是standby的解决办法(图文详解)
不多说,直接上干货!
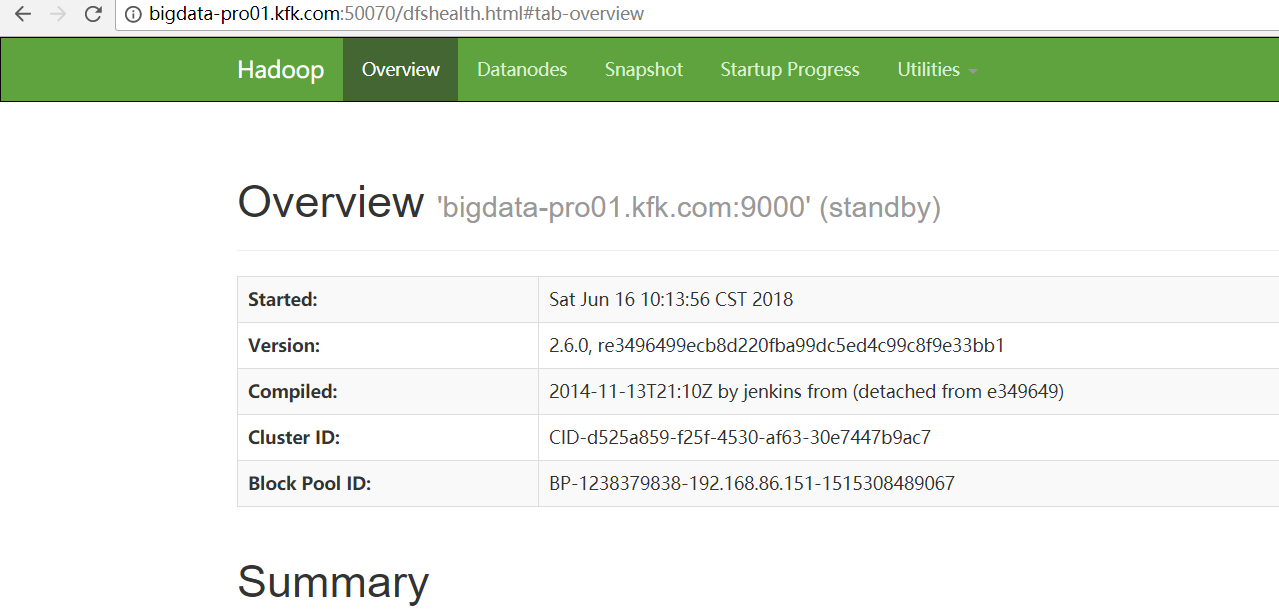
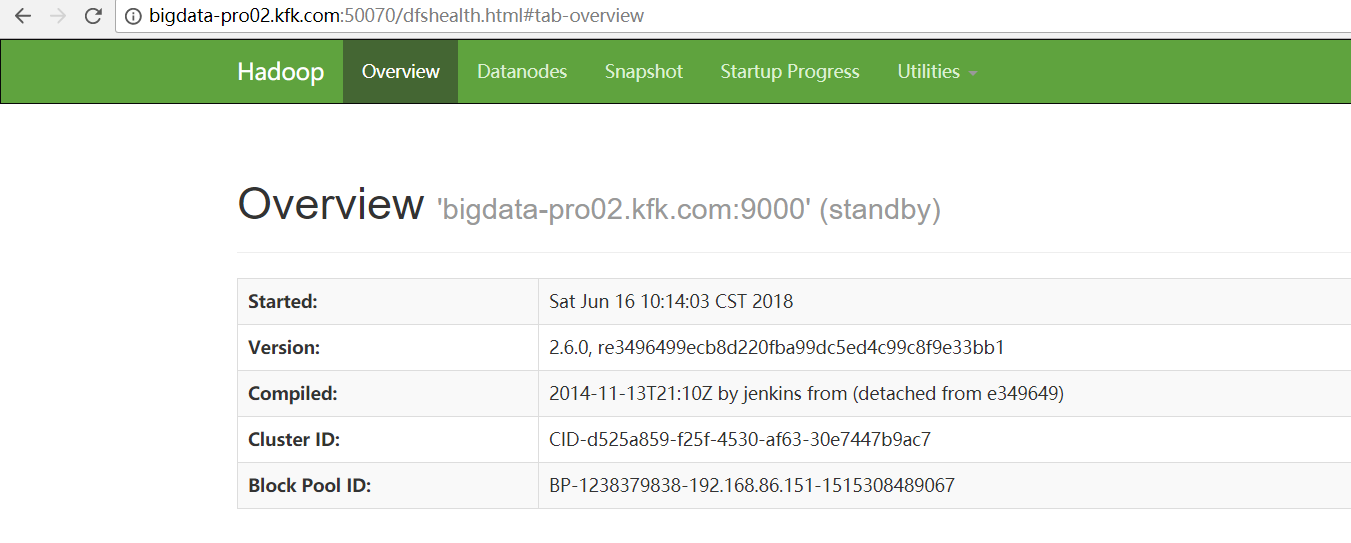
解决办法
因为,如下,我的Hadoop HA集群。
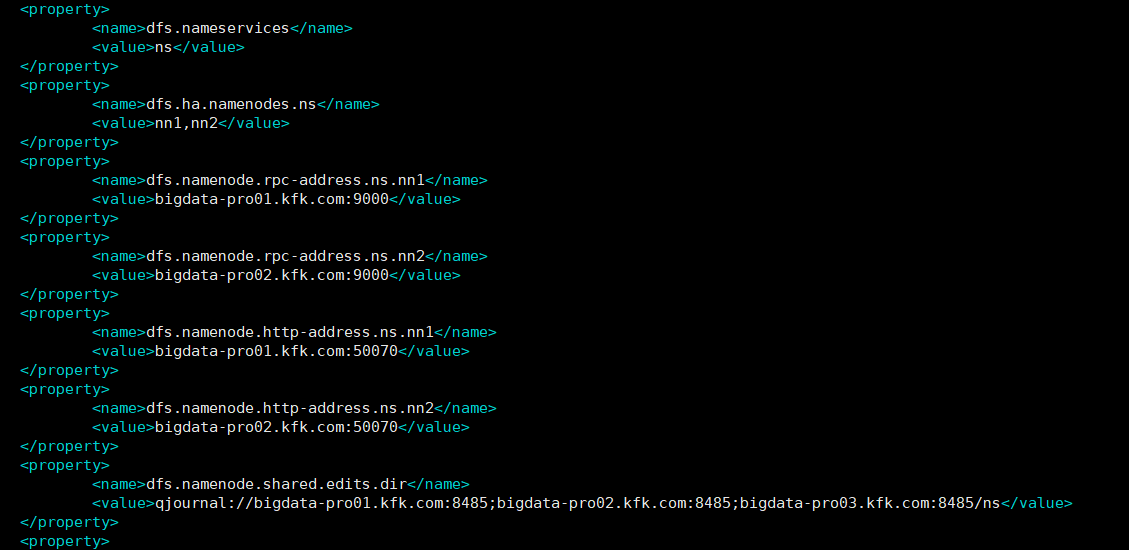
1、首先在hdfs-site.xml中添加下面的参数,该参数的值默认为false:

<property>
<name>dfs.ha.automatic-failover.enabled.ns</name>
<value>true</value>
</property>
2、在core-site.xml文件中添加下面的参数,该参数的值为ZooKeeper服务器的地址,ZKFC将使用该地址。

在HA或者HDFS联盟中,上面的两个参数还需要以NameServiceID为后缀,比如dfs.ha.automatic-failover.enabled.mycluster。除了上面的两个参数外,还有其它几个参数用于自动故障转移,比如ha.zookeeper.session-timeout.ms,但对于大多数安装来说都不是必须的。
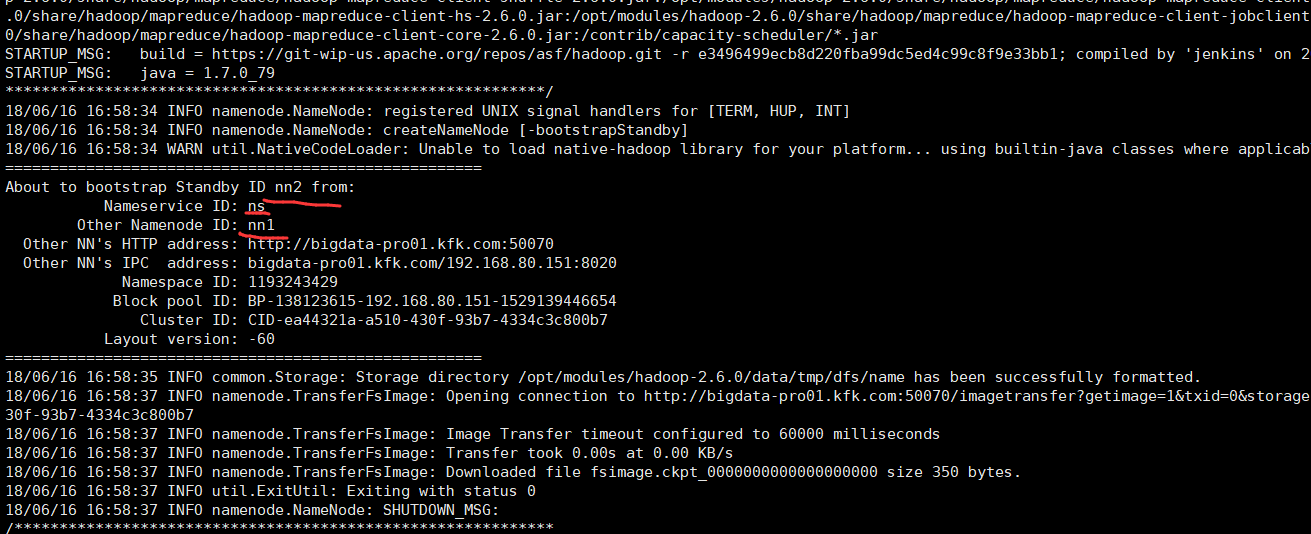
在添加了上述的配置参数后,下一步就是在ZooKeeper中初始化要求的状态,可以在任一NameNode中运行下面的命令实现该目的,该命在ZooKeeper中创建znode:
执行该命令需要进入Hadoop的安装目录下面的bin目录中找到hdfs这个命令,输入上面的命令执行,然后就可以修复这个问题了。
注意:之前,先得启动好,每台机器的zookeeper进程。

[kfk@bigdata-pro01 bin]$ pwd
/opt/modules/hadoop-2.6./bin
[kfk@bigdata-pro01 bin]$ ./hdfs zkfc -formatZK
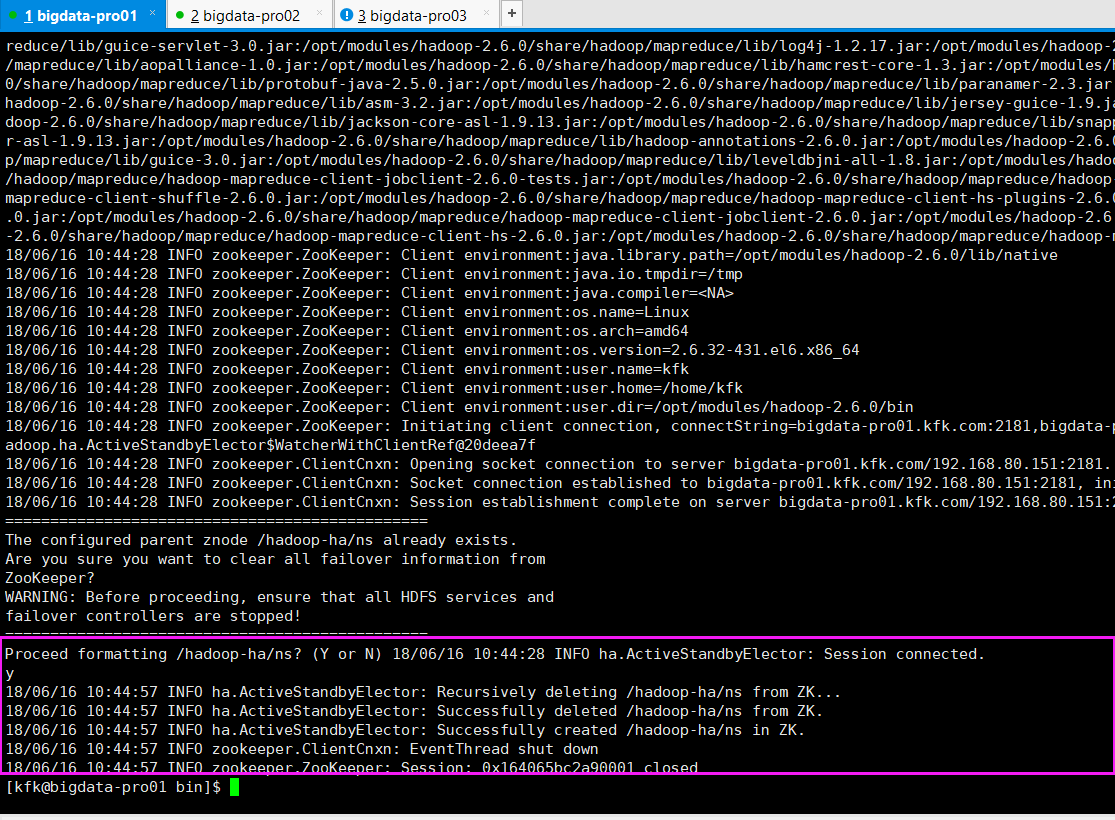
// :: INFO zookeeper.ZooKeeper: Initiating client connection, connectString=bigdata-pro01.kfk.com:,bigdata-pro02.kfk.com:,bigdata-pro03.kfk.com: sessionTimeout= watcher=org.apache.hadoop.ha.ActiveStandbyElector$WatcherWithClientRef@20deea7f
// :: INFO zookeeper.ClientCnxn: Opening socket connection to server bigdata-pro01.kfk.com/192.168.80.151:. Will not attempt to authenticate using SASL (unknown error)
// :: INFO zookeeper.ClientCnxn: Socket connection established to bigdata-pro01.kfk.com/192.168.80.151:, initiating session
// :: INFO zookeeper.ClientCnxn: Session establishment complete on server bigdata-pro01.kfk.com/192.168.80.151:, sessionid = 0x164065bc2a90001, negotiated timeout =
===============================================
The configured parent znode /hadoop-ha/ns already exists.
Are you sure you want to clear all failover information from
ZooKeeper?
WARNING: Before proceeding, ensure that all HDFS services and
failover controllers are stopped!
===============================================
Proceed formatting /hadoop-ha/ns? (Y or N) // :: INFO ha.ActiveStandbyElector: Session connected.
y
// :: INFO ha.ActiveStandbyElector: Recursively deleting /hadoop-ha/ns from ZK...
// :: INFO ha.ActiveStandbyElector: Successfully deleted /hadoop-ha/ns from ZK.
// :: INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/ns in ZK.
// :: INFO zookeeper.ClientCnxn: EventThread shut down
// :: INFO zookeeper.ZooKeeper: Session: 0x164065bc2a90001 closed
[kfk@bigdata-pro01 bin]$
启动并测试
1、先停止掉Hadoop和zookeeper的进程。
2、启动zookeeper进程。
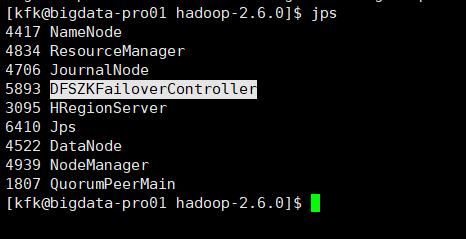
3、开启zkfc进程

[kfk@bigdata-pro01 hadoop-2.6.]$ pwd
/opt/modules/hadoop-2.6.
[kfk@bigdata-pro01 hadoop-2.6.]$ sbin/hadoop-daemon.sh start zkfc
starting zkfc, logging to /opt/modules/hadoop-2.6./logs/hadoop-kfk-zkfc-bigdata-pro01.kfk.com.out
4、进入Hadoop的安装目录下面的sbin目录中,找到start-dfs.sh命令可以启动NameNode,当然这里需要你在配置了NameNode主节点的Hadoop节点上面来执行他。
或者,直接sbin/start-all.sh
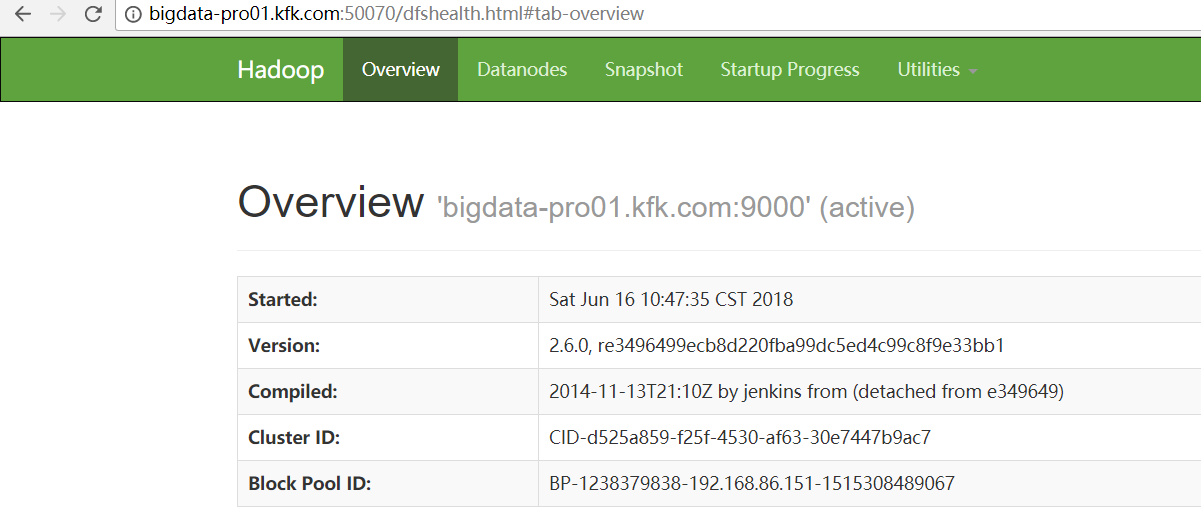
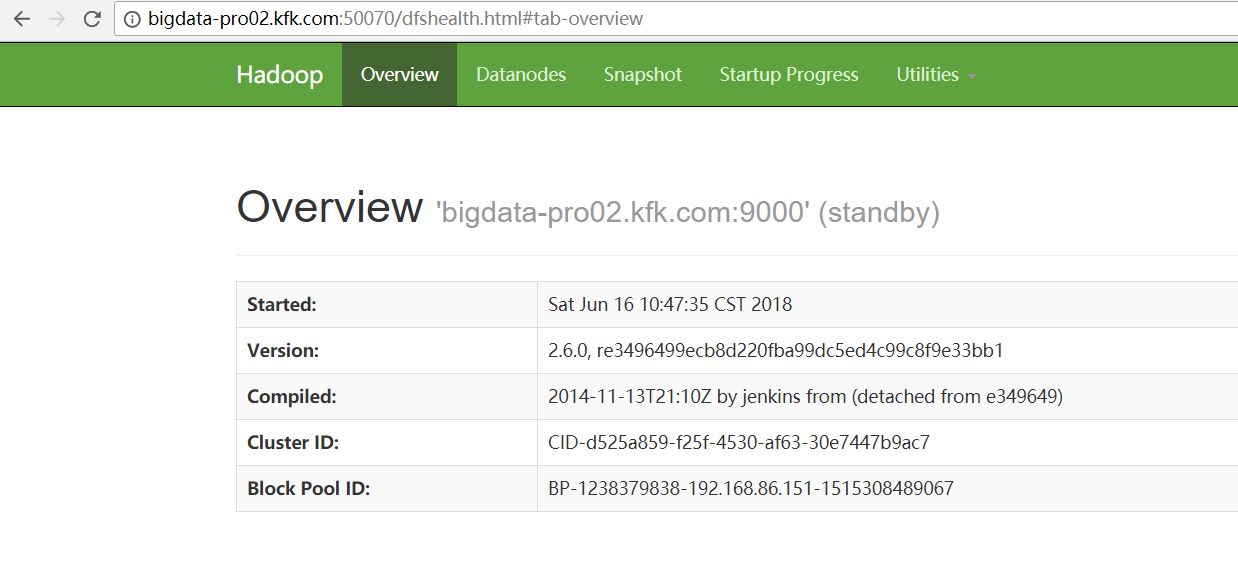
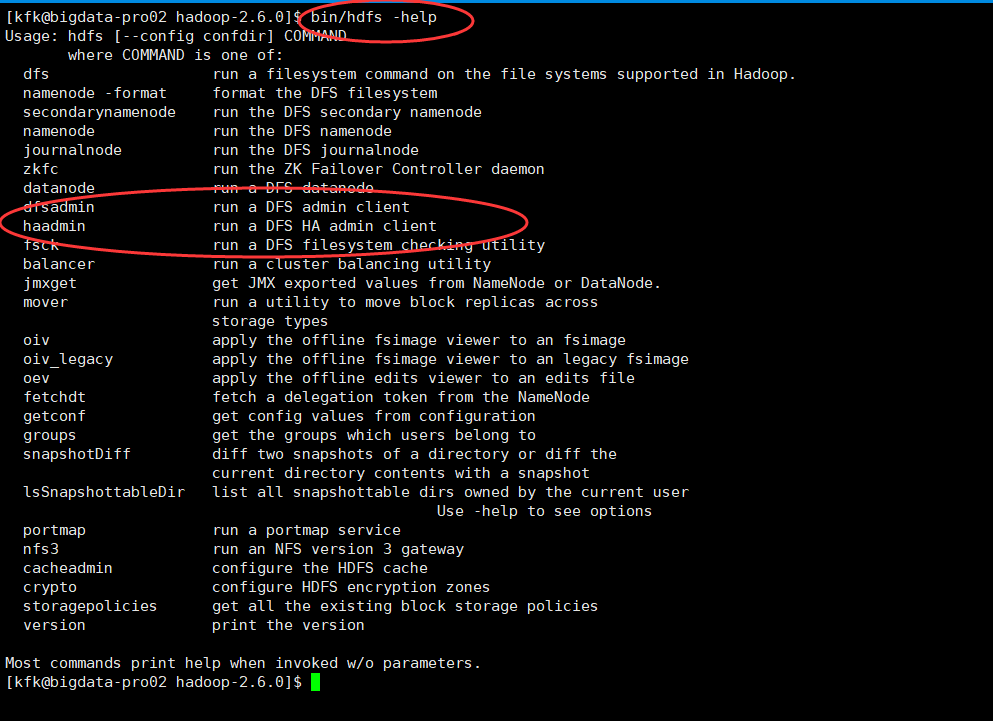
[kfk@bigdata-pro02 hadoop-2.6.]$ bin/hdfs -help
Usage: hdfs [--config confdir] COMMAND
where COMMAND is one of:
dfs run a filesystem command on the file systems supported in Hadoop.
namenode -format format the DFS filesystem
secondarynamenode run the DFS secondary namenode
namenode run the DFS namenode
journalnode run the DFS journalnode
zkfc run the ZK Failover Controller daemon
datanode run a DFS datanode
dfsadmin run a DFS admin client
haadmin run a DFS HA admin client
fsck run a DFS filesystem checking utility
balancer run a cluster balancing utility
jmxget get JMX exported values from NameNode or DataNode.
mover run a utility to move block replicas across
storage types
oiv apply the offline fsimage viewer to an fsimage
oiv_legacy apply the offline fsimage viewer to an legacy fsimage
oev apply the offline edits viewer to an edits file
fetchdt fetch a delegation token from the NameNode
getconf get config values from configuration
groups get the groups which users belong to
snapshotDiff diff two snapshots of a directory or diff the
current directory contents with a snapshot
lsSnapshottableDir list all snapshottable dirs owned by the current user
Use -help to see options
portmap run a portmap service
nfs3 run an NFS version gateway
cacheadmin configure the HDFS cache
crypto configure HDFS encryption zones
storagepolicies get all the existing block storage policies
version print the version Most commands print help when invoked w/o parameters.

[kfk@bigdata-pro02 hadoop-2.6.]$
[kfk@bigdata-pro02 hadoop-2.6.]$ bin/hdfs haadmin -help
Usage: DFSHAAdmin [-ns <nameserviceId>]
[-transitionToActive <serviceId> [--forceactive]]
[-transitionToStandby <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState <serviceId>]
[-checkHealth <serviceId>]
[-help <command>] Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines. The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions] [kfk@bigdata-pro02 hadoop-2.6.]$
注意,其实自带的命令里,都提供了,若两者都是standby状态怎么执行。若两者都是active状态怎么执行。这里,不多赘述。
如果,还是没解决的话,则

bin/hdfs haadmin -transitionToActive nn1
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



全网最详细的Hadoop HA集群启动后,两个namenode都是standby的解决办法(图文详解)的更多相关文章
- 全网最详细的Hadoop HA集群启动后,两个namenode都是active的解决办法(图文详解)
不多说,直接上干货! 这个问题,跟 全网最详细的Hadoop HA集群启动后,两个namenode都是standby的解决办法(图文详解) 是大同小异. 欢迎大家,加入我的微信公众号:大数据躺过的坑 ...
- 全网最详细的Windows系统里Oracle 11g R2 Client(64bit)的下载与安装(图文详解)
不多说,直接上干货! 环境: windows10系统(64位) 最好先安装jre或jdk(此软件用来打开oracle自带的可视化操作界面,不装也没关系:可以安装plsql,或者直接用命令行操作) Or ...
- Apache版本的Hadoop HA集群启动详细步骤【包括Zookeeper、HDFS HA、YARN HA、HBase HA】(图文详解)
不多说,直接上干货! 1.先每台机器的zookeeper启动(bigdata-pro01.kfk.com.bigdata-pro02.kfk.com.bigdata-pro03.kfk.com) 2. ...
- 全网最详细的一款满足多台电脑共用一个鼠标和键盘的工具Synergy(图文详解)
不多说,直接上干货! 前言 如今无论你是在公司做大数据开发还是实验室里搞科研,这个软件确实好用,作为正在通往大数据架构师路上的我们没有几台电脑怎么行?台式机.笔记本,都放在写字台上,笔记本内置键盘鼠标 ...
- 全网最详细的Oracle10g/11g的官方下载地址集合【可直接迅雷下载安装】(图文详解)
不多说,直接上干货! 方便自己,也方便他人查阅. Oracle 11g的官网下载地址: http://www.oracle.com/technetwork/database/enterprise-e ...
- Hadoop的HA集群启动和停止流程
假设我们有3台虚拟机,主机名分别是hadoop01.hadoop02和hadoop03. 这3台虚拟机的Hadoop的HA集群部署计划如下: 3台虚拟机的Hadoop的HA集群部署计划 hadoop0 ...
- Hadoop ha CDH5.15.1-hadoop集群启动后,集群容量不正确,莫慌,这是正常的表现!
Hadoop ha CDH5.15.1-hadoop集群启动后,集群容量不正确,莫慌,这是正常的表现! 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.集群启动顺序 1>. ...
- Hadoop ha CDH5.15.1-hadoop集群启动后,两个namenode都是standby模式
Hadoop ha CDH5.15.1-hadoop集群启动后,两个namenode都是standby模式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一说起周五,想必大家都特别 ...
- 基于zookeeper的高可用Hadoop HA集群安装
(1)hadoop2.7.1源码编译 http://aperise.iteye.com/blog/2246856 (2)hadoop2.7.1安装准备 http://aperise.iteye.com ...
随机推荐
- AngularJS实战之ngAnimate插件实现轮播
第一步:引入angular-animate.js 第二步:注入ngAnimate var lxApp = angular.module("lxApp", [ 'ngAnimate' ...
- ArcGIS API 和GIServer
ArcGIS API 和GIServer 先后以ArcGIS Server(9.3)和GIServer(2.2)为服务端,以ArcGIS API for Flex(1.2).ArcGIS API f ...
- mac终端的命令都失效的解决方法
step1. 在terminal里面输入: export PATH="/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin:/usr/X11/bin&qu ...
- day32(表单校验js和jquery表单校验)
校验用户名.密码.密码一直性. <style> .error { color: red } .success { color: green } </style> <scr ...
- CountDownLatch同步辅助类
CountDownLatch,一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待. 主要方法 public CountDownLatch(int count); pu ...
- 20155326 2016-2017-2 《Java程序设计》第7周学习总结
20155326 2016-2017-2 <Java程序设计>第7周学习总结 教材学习内容总结 Lambda (1)如果使用JDK8的话,可以使用Lambda特性去除重复的信息. (2)在 ...
- 《mysql必知必会》学习_第七章_20180730_欢
第七章:数据过滤 P43 select prod_id,prod_price,prod_name from products where vend_id =1003 and prod_price &l ...
- Java 理论与实践: 用弱引用堵住内存泄漏
弱引用使得表达对象生命周期关系变得容易了 虽然用 Java™ 语言编写的程序在理论上是不会出现“内存泄漏”的,但是有时对象在不再作为程序的逻辑状态的一部分之后仍然不被垃圾收集.本月,负责保障应用程序健 ...
- node-lessons
教程:https://github.com/alsotang/node-lessons 0 nvm 的全称是 Node Version Manager,之所以需要这个工具,是因为 Node.js 的各 ...
- 测试pc大、小端
判断计算机的大.小端存储方式 1 int main() { ; char* p=(char*)&a; ) printf("little\n");//小端存储:高位存在地地址 ...